视觉语言模型应用开发——Qwen 2.5 视觉语言模型的零样本学习能力在多模态内容审核中的实践研究
概述
在当今数字时代,随着互联网用户规模的持续扩张和内容创作门槛的不断降低,用户生成内容呈现出指数级增长态势。这种爆炸式增长既为信息传播和知识共享带来了便利,也使得维护在线平台的完整性和安全性面临前所未有的挑战。
数字平台作为信息交互的核心枢纽,每天都要应对数十亿计的帖子、评论、图像、视频等多样化内容。传统的内容审核模式高度依赖人工审核员的经验判断,或通过标注数据进行模型蒸馏来构建审核系统。然而,面对海量且实时更新的内容,人工审核不仅成本高昂、效率低下,还可能因审核员的主观差异导致标准不一;而基于特定标注数据训练的模型,又难以应对不断涌现的新型有害内容形式,适应性较差。
视觉语言模型(如Qwen 2.5)的出现为解决这一困境提供了新思路。这类模型融合了视觉感知与自然语言理解能力,能够同时处理文本、图像、视频等多模态信息。尤为重要的是,其具备的零样本学习能力使其无需依赖大规模特定任务标注数据,就能对各类内容中的不当信息进行准确检测和判断,为多模态内容审核领域注入了强大的技术动力。
通过本系列博客文章,我们将系统探讨Qwen 2.5视觉语言模型(VLMs)在内容审核、PDF文档摘要、目标检测等一系列视觉及多模态任务中的应用潜力,揭示其如何推动相关领域的技术变革与效率提升。
内容审核是数字平台运营中不可或缺的关键环节,其核心在于对用户生成内容进行全面监控、细致审查和科学管理,确保所有内容严格符合平台既定的社区准则与行业标准。这一过程的最终目标是为广大用户营造一个安全、尊重、包容的在线环境,具体体现在多个方面:过滤含有攻击性、侮辱性的语言;及时检测并删除仇恨言论;有效遏制错误信息的传播扩散;保护用户免受网络骚扰、欺凌等不良行为的侵害。内容审核的执行方式主要分为两类,一是由专业人工审核员进行手动操作,二是借助人工智能驱动的自动化系统完成。
在社交媒体平台的语境下(图 1),内容审核的重要性尤为凸显。社交媒体作为用户互动交流的主要阵地,涵盖了文本分享、图像发布、视频上传等多种形式的内容交互。尽管这些平台为人们提供了自由表达和沟通的广阔空间,但同时也潜藏着诸多与有害内容相关的风险,例如仇恨言论的蔓延、暴力画面的传播、露骨色情内容的出现以及各类错误信息的泛滥等。因此,高效的内容审核机制是保障社交媒体健康发展的基石。
图 1: 什么是内容审核?探索其好处和最佳实践。
内容审核的挑战:以Facebook仇恨表情包挑战为例
Facebook 仇恨表情包挑战 是一项具有广泛影响力的行业倡议,其核心目标是推动多模态表情包中仇恨言论检测技术的发展。表情包作为一种融合视觉元素与文本信息的独特内容形式,给内容审核工作带来了诸多独特且复杂的挑战。这是因为表情包的含义往往依赖于特定的上下文背景、文化传统和微妙的语言表达,传统的AI模型由于难以捕捉这些深层次的关联,往往无法准确解读其真实含义。
具体而言,该挑战聚焦于如何精准识别多模态表情包中蕴含的仇恨言论,这一任务本质上是一个复杂的多模态信息融合问题。例如,“喜欢你今天的味道”或“看看有多少人喜欢你”这样的句子,单独来看并无恶意,属于中性表达。但是,当这些句子与看似无害的臭鼬图像或风滚草图像结合时,整个表情包的含义就会发生根本性转变,传递出刻薄、嘲讽甚至具有攻击性的意味(图 2)。这种视觉元素与文本元素的协同作用,构建了一个全新的语义环境,而传统的仅依赖文本分析或仅依赖图像识别的审核方法,由于无法综合处理这种多模态信息,往往会遗漏其中的有害内容。

图 2: Facebook AI 仇恨表情包数据集用于社交媒体审核的示例
为了应对这一挑战,Facebook仇恨表情包挑战提供了一个包含大量标注信息的多模态表情包数据集,该数据集涵盖了丰富的真实案例,为研究人员和开发人员提供了宝贵的实验资源,激励他们开发出能够有效检测此类表情包中仇恨言论的先进AI模型。
视觉语言模型的发展与趋势
近年来,以OpenAI GPT-4o、Gemini、Llama、Claude等为代表的大型语言模型在各个领域都展现出了令人惊叹的性能。然而,这些大型模型往往伴随着极高的硬件配置要求和高昂的运营维护成本,这使得许多中小型企业、研究机构以及个人开发者难以企及,在一定程度上限制了先进AI技术的普及与应用。
如今,人工智能领域正经历着一场深刻的变革,即从追求超大模型规模向开发更小巧、更高效的开源视觉语言模型(VLMs)转变。 Phi3.5-Vision、PaliGemma 3B、InternVL2-2B、Qwen2.5-VL-3B、Llava、SmolVLM等一系列小型视觉语言模型的涌现,标志着这一变革的深入推进(图 3)。
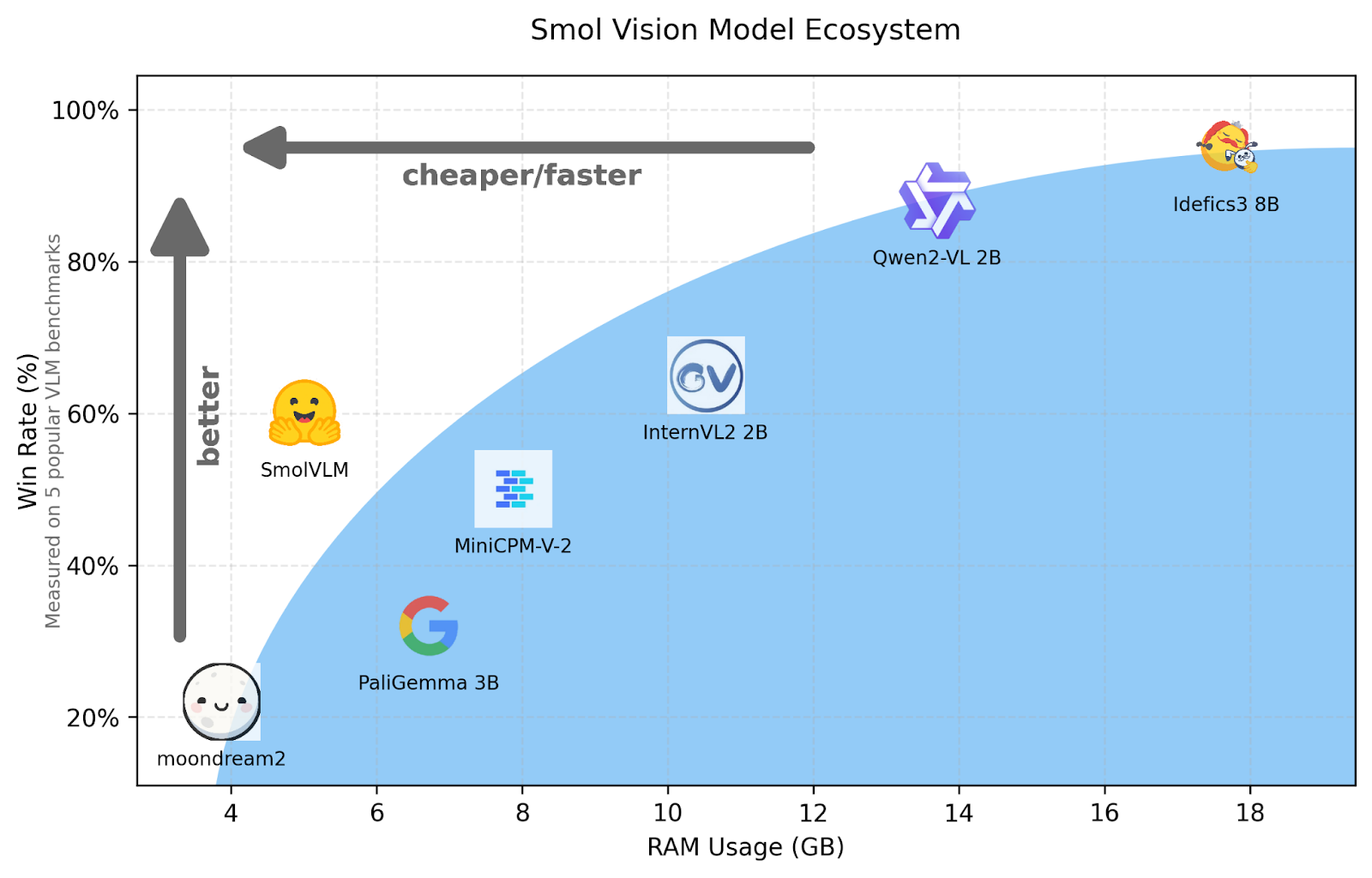
图 3: 近期小型视觉语言模型的性能图表。
这个新的发展时代以紧凑高效的模型为显著特征,这些模型在不依赖大型模型所需的高昂计算资源的前提下,依然能够提供强大的多模态处理能力。推动视觉语言模型向小型化发展的核心动力,源于社会对更易获取、更具成本效益且能灵活适应各种资源受限环境的AI模型的迫切需求。这种趋势不仅降低了AI技术的应用门槛,也为其在更广泛的场景中发挥作用创造了条件。
Qwen-VL 2.5:先进的视觉语言模型系列
Qwen 2.5是阿里巴巴Qwen团队在其前身Qwen2-VL的基础上,推出的最新一代视觉语言模型系列。该系列模型致力于在提升性能的同时,增强模型的可访问性,通过引入多项关键技术改进,有效解决了前代模型存在的局限性,并极大地扩展了其在各个行业和领域的潜在应用场景。
以下是Qwen 2.5模型系列的一些关键特性:
- 大规模预训练数据:Qwen2.5模型的预训练数据规模实现了大幅跨越,从Qwen2系列的7万亿令牌猛增至18万亿令牌(图 4)。这一庞大的数据集增长并非无序扩张,而是有针对性地集中在知识领域、编码领域和数学领域等关键方向,使得模型能够在这些专业领域形成更深层次的理解能力和更熟练的处理技能。丰富且高质量的训练数据为Qwen2.5奠定了坚实的基础,使其能够在广泛的主题范围内提供更准确、更全面、更复杂的响应。
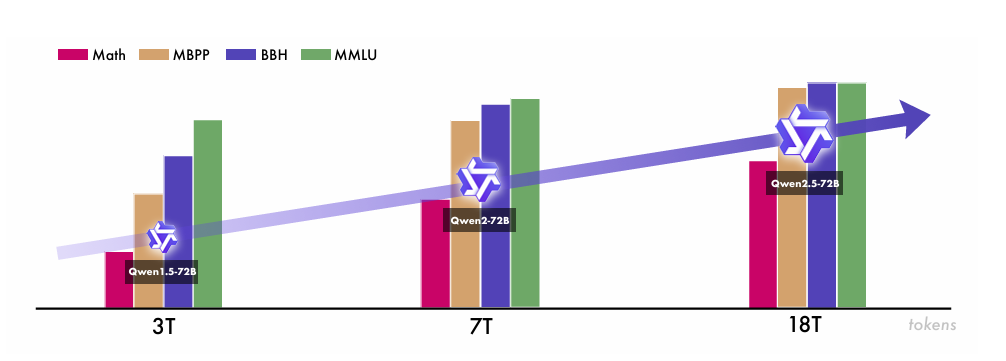
图 4: Qwen 系列随着预训练数据增加的迭代发展。
-
扩展的最大生成长度:Qwen2.5的一个重要增强点是将模型的最大生成长度从2,000个令牌提升至8,000个令牌。这一扩展带来了显著的优势,使得模型能够生成更长篇幅、更连贯流畅的文本输出。对于那些需要详细解释说明、复杂报告撰写或大规模内容生成的任务,如长篇文档摘要、详细的技术分析报告等,这一特性显得尤为实用。
-
增强的结构化数据处理能力:Qwen2.5在处理结构化数据格式方面表现更为出色,能够高效处理表格、JSON等多种结构化数据。这种改进的支持能力促进了模型与各类依赖结构化数据的应用程序之间的无缝集成,使得用户能够更便捷地输入复杂的结构化数据,并获得组织有序、格式规范的输出结果,极大地提升了工作效率。
-
超长上下文长度支持:Qwen2.5-Turbo模型具备一项突出特性,即能够支持长达100万个令牌的上下文长度。这种卓越的容量使其能够轻松处理大规模的文档资料或长时间的对话历史记录,在大规模文档分析、全面的聊天机器人交互、复杂的多轮对话系统等应用场景中展现出独特的优势。
-
高效的大模型性能:旗舰模型Qwen2.5-72B-Instruct(表 1)在性能上可与最先进的开放权重模型Llama-3-405B-Instruct相媲美,但其模型体积却大约小了五倍。这种高效性充分展示了Qwen团队在模型优化方面的先进技术,实现了在不依赖超大模型尺寸的情况下,达到甚至超越同类大型模型的能力水平,大幅降低了模型部署和运行的成本。
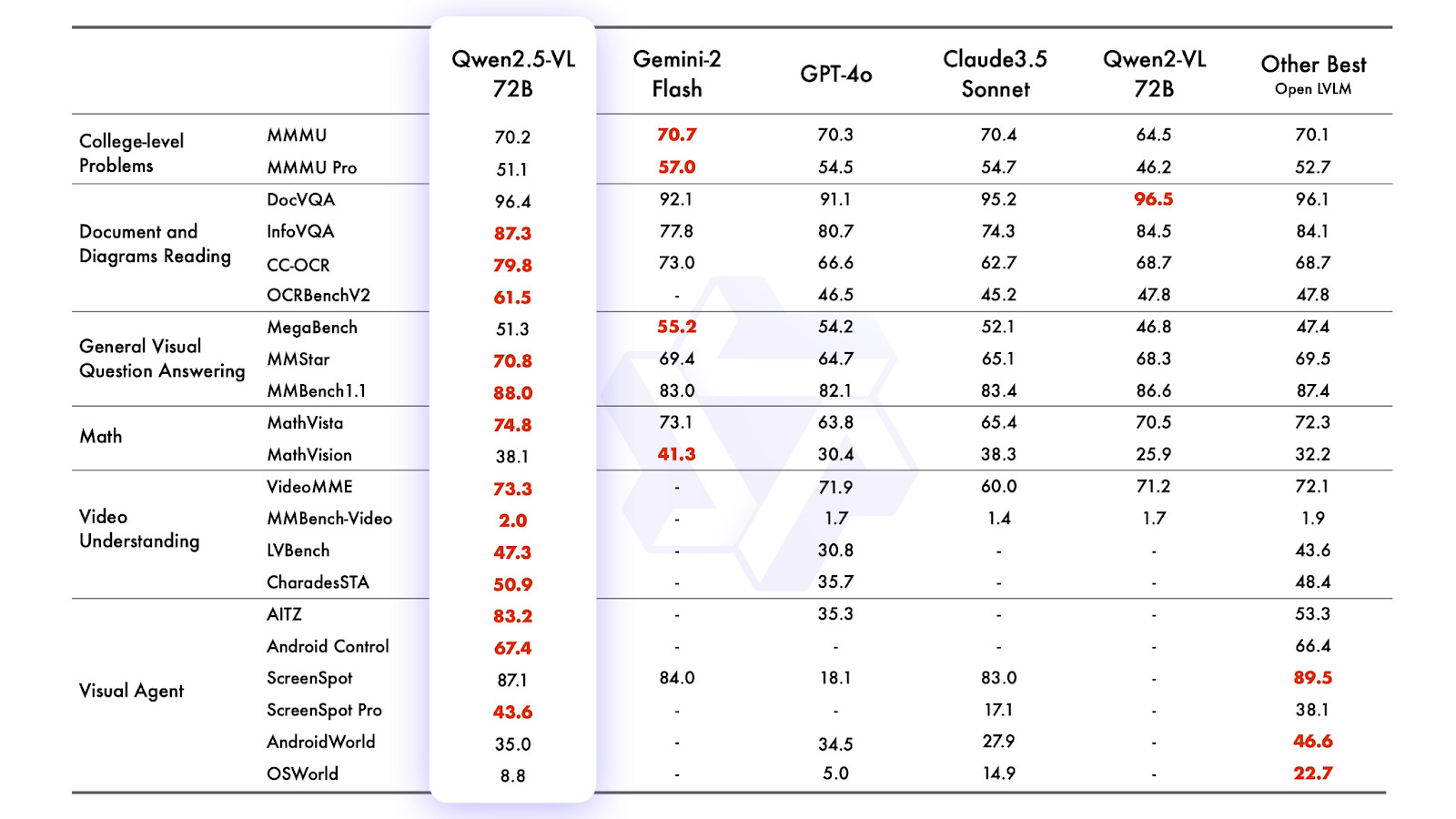
表 1: Qwen2.5-72B-Instruct 与近期最先进(SOTA)旗舰视觉语言模型的比较
-
专有混合专家(MoE)模型:Qwen2.5引入了Qwen2.5-Turbo和Qwen2.5-Plus这两款专有混合专家(MoE)模型。这些模型同样支持长达100万个令牌的上下文长度,能够处理海量文档或长对话历史,非常适合大规模文档分析、深度聊天机器人交互等应用。在性能上,它们分别与行业领先的GPT-4o-mini和GPT-4o等模型具有竞争力。MoE架构的优势在于能够使模型根据不同的任务需求,有效地分配计算资源,从而在各种任务上均能保持较高的性能表现。
-
复杂视觉元素分析能力:Qwen2.5 VL不仅能够识别常见的物体,如花卉、鸟类、鱼类和昆虫等,更擅长深入分析图像中复杂的视觉元素,包括图像中的文本信息、各类图表、图标符号、图形元素以及整体布局结构等。这种强大的能力使其在需要对图像进行详细解释的任务中,如图像内容理解、图表信息提取等,表现得极为高效。
-
长视频理解能力:该模型具备理解时长超过1小时的视频内容的能力,并引入了通过精确定位相关视频片段来捕捉关键事件的新功能。这一功能对于视频内容摘要生成、视频内容索引建立以及自动生成精彩片段等应用具有极高的实用价值,能够大幅提升视频处理的效率和质量。
-
精确的目标定位能力:Qwen2.5 VL(图 5)能够通过生成边界框或定位点的方式,精确定位图像中的目标对象。它可以提供包含坐标信息和对象属性的稳定JSON格式输出,这种结构化的输出便于与其他需要利用这些数据进行进一步处理或分析的系统进行集成,为后续的应用开发提供了便利。
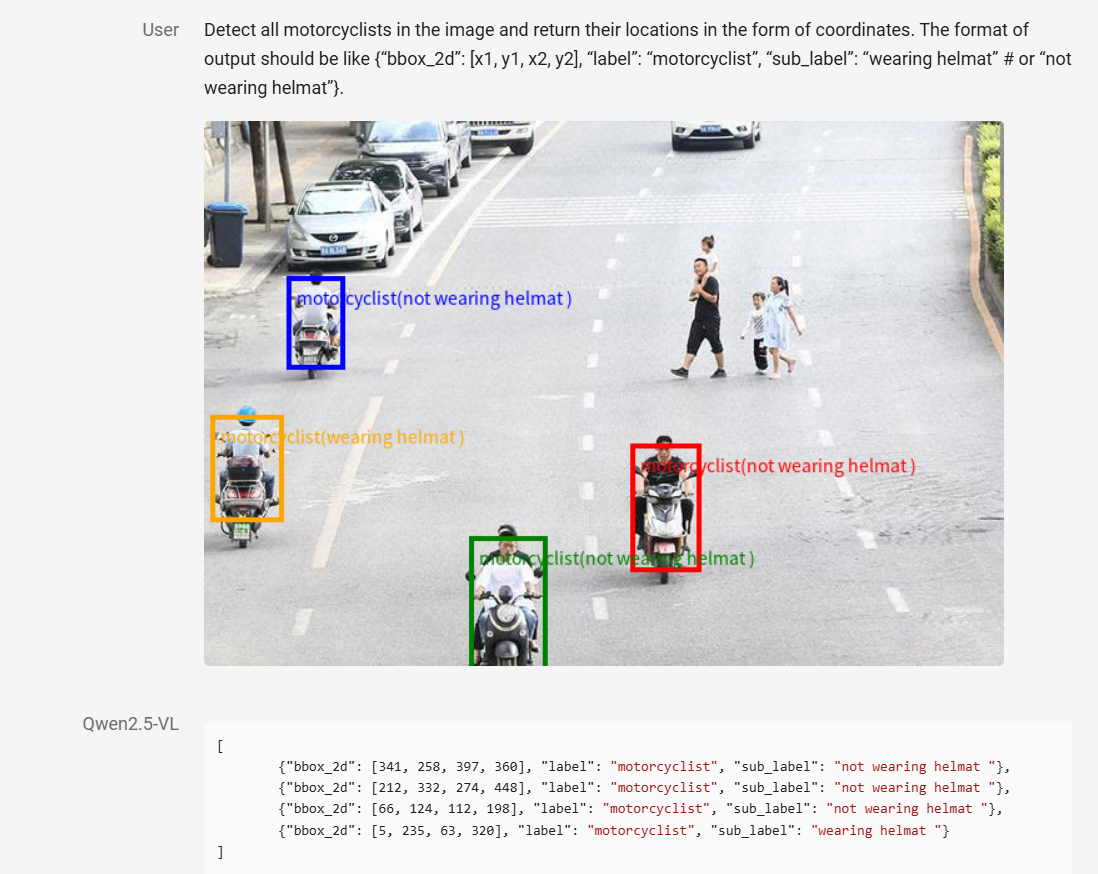
图 5: Qwen 2.5 系列的精确目标定位(来源:Qwen Team, 2025)。
- 多样化的开源密集模型:Qwen2.5系列包含了一系列不同参数规模的开源密集模型,参数数量从0.5B、1.5B、3B、7B、14B、32B到72B不等。这种丰富的多样性为用户提供了极大的选择灵活性,用户可以根据自身的计算资源条件和特定的应用需求,选择最适合的模型进行部署和应用。这些密集模型均基于transformer的解码器架构,如GPT或其前身Qwen2,该架构包含分组查询注意力、SwiGLU激活函数、旋转位置嵌入等多个关键组件,以不断改进模型的学习过程和性能表现。
表 2 显示了Qwen2.5系列中不同开放权重模型的配置详情。

表 2: Qwen 2.5 系列的各种模型配置(来源:Qwen Team, 2025)。
- 开创性的图像处理方法:Qwen2.5 VL在图像处理方面引入了一种开创性的方法,通过更动态地处理空间维度来提升性能。与传统方法不同,该模型不依赖坐标归一化(即将坐标缩放到标准范围),而是直接使用每个图像的实际大小和比例信息。这一方法带来了两方面的重要意义:
- 动态令牌化:不同大小的图像会被转换为相应长度的令牌序列,较大的图像能够生成更多的令牌,从而保留高分辨率输入中固有的详细信息,避免了因归一化处理导致的信息丢失。
- 直接坐标表示:图像中的检测框和定位点使用真实的、未经过归一化处理的坐标进行表示。通过这种方式,Qwen2.5-VL能够让模型更好地学习和理解每个图像中的真实比例关系和空间位置关系。
这种创新的图像处理方法使模型能够更准确地解释图像中的空间信息,进而在目标定位和理解图像中与比例相关的特征等任务上取得更好的效果。
- 先进的视频和时间数据处理能力:在处理视频和时间数据时,Qwen2.5 VL取得了显著的技术进展:
- 动态FPS训练:模型在训练过程中采用动态的每秒帧数(FPS)设置,而非固定的帧率。这使得模型能够灵活适应不同帧率的视频内容,增强了对各类视频的适应性。
- 绝对时间编码:模型通过将修改后的旋转位置嵌入(mRoPE)标识符直接与时间进度进行对齐,采用了绝对时间编码方式。从本质上讲,模型内部的时间标识符与实际的时间间隔相对应,这使得模型能够自然地学习视频中事件的节奏和发展流程。
通过整合这些先进的时间处理技术,Qwen2.5-VL(图 6)能够更有效地理解视频中事件的时间顺序和发展脉络,这对于事件检测等对时间准确性要求极高的任务而言,具有至关重要的意义。
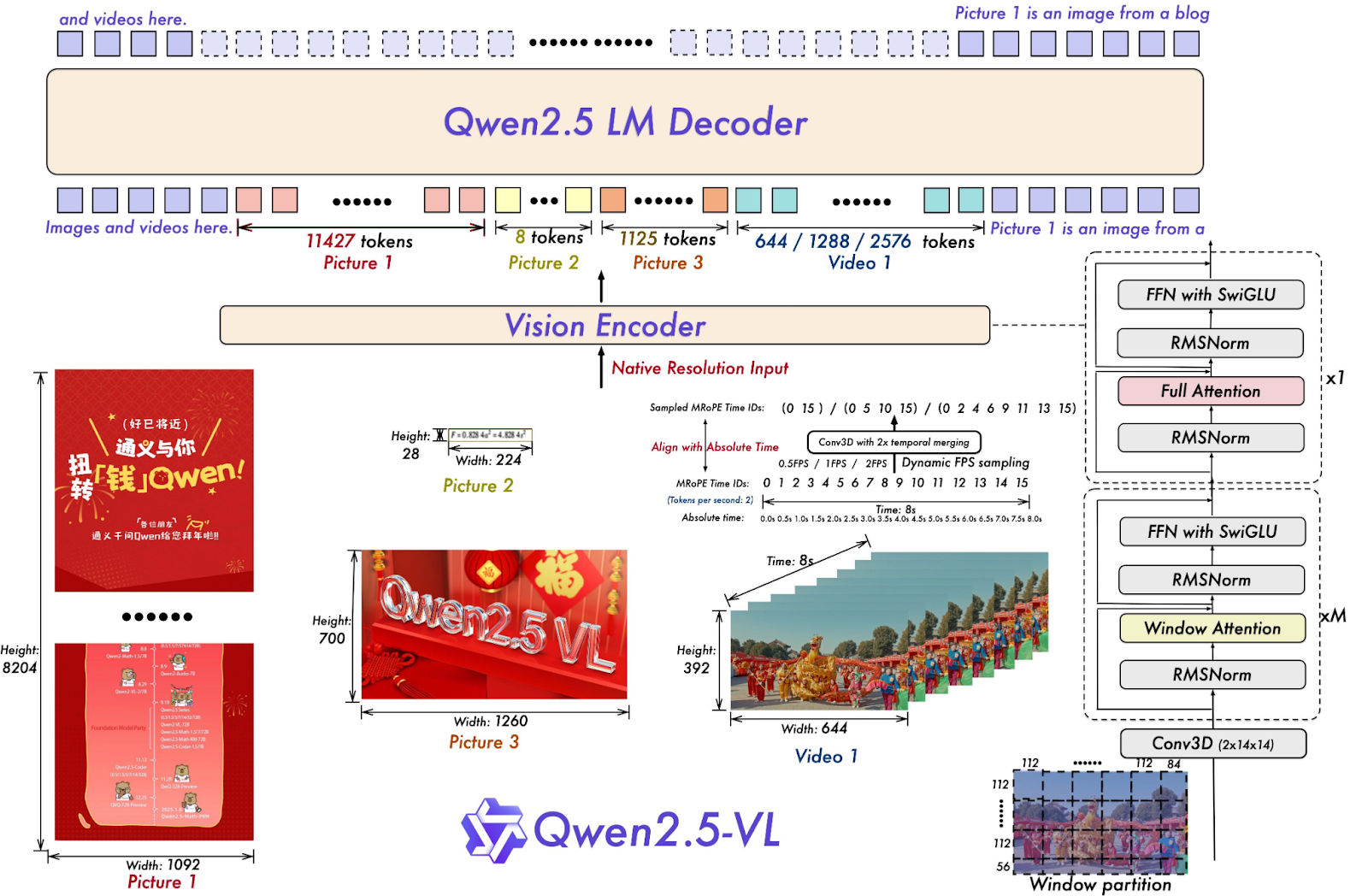
图 6: Qwen 2.5 系列的架构更新和创新
在本节中,我们将详细介绍如何利用Qwen 2.5模型的零样本学习能力,来检测社交媒体表情包中的仇恨言论。为此,我们将采用仇恨表情包数据集,这是一个专门用于仇恨表情包检测的多模态数据集(包含图像和文本信息),其中包含了由Facebook AI创建的10,000多个全新的多模态示例。首先,我们需要安装必要的库文件。
pip install git+https://github.com/huggingface/transformerspip install qwen-vl-utilspip install kagglehub
接下来,我们将加载仇恨表情包数据集。该数据集的训练集包含10,000个带有标注信息的表情包,验证集包含500个带有标注的示例。在本次实践中,我们将使用Qwen 2.5模型,在验证集上评估零样本学习的性能表现。
import kagglehub# Download latest version
path = kagglehub.dataset_download("parthplc/facebook-hateful-meme-dataset", force_download=True)import torchtorch.cuda.empty_cache()
torch.manual_seed(42)import json
import os
from PIL import Image
import numpy as np
import pandas as pd
import randomdata_dir = '/root/.cache/kagglehub/datasets/parthplc/facebook-hateful-meme-dataset/versions/1/data/'
img_path = data_dir + "data_dir"
train_path = data_dir + "train.jsonl"
dev_path = data_dir + "dev.jsonl"
test_path = data_dir + "test.jsonl"def get_sample(data_path):data = [json.loads(l) for l in open(data_path)]random.shuffle(data)images, texts, answers = [], [], []for index in range(len(data)):image = Image.open(os.path.join(data_dir, data[index]["img"])).convert("RGB")text = data[index]["text"]answer = "yes" if data[index]["label"] == 1 else "no"images.append(image)texts.append(text)answers.append(answer)return images, texts, answersimages, texts, answers = get_sample(data_path=dev_path)
上面的代码主要包含两个部分:
在第一部分(第1-24行),我们首先导入所需的库并设置数据集的路径。通过kagglehub下载facebook-hateful-meme-dataset数据集(第1-4行),确保我们能够获取到实验所需的数据。随后,导入torch、json、os、PIL.Image、numpy、pandas和random等必要的库(第6-17行),这些库将分别用于数据处理、图像操作、数值计算等任务。接下来,定义存储数据集的数据目录,并设置训练、开发(验证)和测试JSONL文件的具体路径(第19-24行),为后续的数据加载和处理做好环境准备。
在第二部分(第26-50行),定义了get_sample函数,该函数的作用是从指定的JSONL文件中提取图像、文本和对应的标签答案。函数首先读取并解析JSONL数据(第27行),将每一行的JSON字符串转换为可操作的数据结构。然后,对数据进行随机打乱,以增加数据的随机性。接着,通过循环遍历数据中的每个样本,加载相应的图像并将其转换为RGB格式(第33-35行),同时提取文本信息和对应的标签答案(将标签1转换为"yes",0转换为"no")。最后,将加载的图像、文本和答案分别存储在初始化的列表中,并作为函数的输出返回(第41行)。通过使用dev_path调用该函数(第42行),我们获得了用于后续模型评估和推理的验证集数据。
加载数据集后,我们可以开始加载Qwen 2.5模型。在本次实践中,我们将使用"Qwen/Qwen2.5-VL-3B-Instruct",这是Qwen2.5系列中具有3B参数的模型。
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct", torch_dtype="auto", device_map="auto"
)# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
在这里,我们首先从transformers库中导入Qwen2_5_VLForConditionalGeneration、AutoTokenizer、AutoProcessor等必要的类和函数,同时从qwen_vl_utils中导入process_vision_info实用函数(第43和44行),这些组件将用于模型的加载、预处理和推理操作。
然后,使用from_pretrained方法从"Qwen/Qwen2.5-VL-3B-Instruct"存储库加载预训练的Qwen2_5_VLForConditionalGeneration模型(第47行)。其中,torch_dtype="auto"参数确保模型能够根据运行环境自动选择适当的数据类型,以优化计算效率;device_map="auto"参数则使模型能够自动加载到可用的设备(如GPU)上,充分利用硬件资源提升性能。
在第二部分,我们设置了min_pixels和max_pixels值,用于定义图像处理的令牌范围(第52和53行)。用户可以根据实际的性能需求和计算成本,灵活调整这些值。随后,使用来自同一存储库的AutoProcessor类创建一个processor对象(第54行),该处理器将负责对与视觉相关的信息进行预处理,例如将图像大小调整到指定的像素范围内,为模型的输入做好准备。模型和处理器的协同工作,使我们能够基于输入的图像和文本信息,有效地生成符合要求的条件输出。
现在我们的模型已加载完毕,接下来可以在验证数据集上进行推理操作。
prompt = "Answer in only yes or no whether the following meme is hateful or offensive towards a religion, race, community, gender, caste etc. Think twice before you answer."
predictions = []
for i in range(len(images)):image = images[i]messages = [{"role": "user","content": [{"type": "image","image": image,},{"type": "text", "text": prompt},],}]# Preparation for inferencetext = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)image_inputs, video_inputs = process_vision_info(messages)inputs = processor(text=[text],images=image_inputs,videos=video_inputs,padding=True,return_tensors="pt",)inputs = inputs.to("cuda")# Inference: Generation of the outputgenerated_ids = model.generate(** inputs, max_new_tokens=20)generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
通过 Qwen 2.5 的零样本学习实现内容审核(2)
)[0]predictions.append(output_text)print(f"Images inferred : {i+1}/{len(images)}")
我们首先精心设计了一个提示词,明确要求模型对表情包是否针对宗教、种族、社区、性别、种姓等群体具有仇恨性或攻击性给出“是”或“否”的回答,并提示模型在回答前进行慎重思考(第55行),以提高模型判断的准确性。
对于images列表中的每个图像,我们构建了一条包含图像和上述提示词的消息(第61-72行),模拟真实的用户查询场景。接着,我们利用处理器对输入进行推理前的准备工作:通过应用聊天模板将消息转换为模型可理解的文本格式(第75行),同时使用process_vision_info函数处理消息中的视觉信息(第76行)。
随后,将处理后的文本、图像输入等整合为模型的输入数据(第77-84行),并将输入数据迁移至GPU设备以进行高效的并行计算(第86行)。
在推理阶段,模型根据输入生成输出令牌序列(第89行)。为了获取纯粹的模型生成结果,我们对生成的令牌进行修剪,去除输入部分对应的令牌(第90-92行),然后对修剪后的令牌序列进行解码,得到最终的文本答案(第93-95行)。
将每个图像的预测结果存储在predictions列表中,并实时打印当前的推理进度(第97-99行)。通过这一过程,我们可以基于模型的输出,全面评估每个表情包是否被判定为具有仇恨性或攻击性。
推理完成后,我们将使用scikit-learn库来评估零样本分类器的各项性能指标,包括准确率、精确率、召回率和F1分数。
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scorey_true = [1 if answers[i] == "yes" else 0 for i in range(len(answers))]
y_pred = [1 if predictions[i] == "Yes." else 0 for i in range(len(predictions))]print("Total positives : ", sum(y_true))
print("Total Negatives : ", len(y_true) - sum(y_true))
print("Accuracy : ", np.round(accuracy_score(y_true, y_pred), 3))
print("Precision : ", np.round(precision_score(y_true, y_pred), 3))
print("Recall : ", np.round(recall_score(y_true, y_pred), 3))
print("F1 Score : ", np.round(f1_score(y_true, y_pred), 3))
输出:
Total positives : 250
Total Negatives : 250
Accuracy : 0.622
Precision : 0.593
Recall : 0.78
F1 Score : 0.674
从输出结果可以看出,我们的零样本学习方法在将表情包分类为仇恨性或非仇恨性方面,实现了78%的召回率和约59.3%的精确率,F1分数达到67.4%,准确率为62.2%。与BERT、Visual BERT、ViLBERT等多种单模态和多模态现有技术(表 3)相比,Qwen 2.5仅仅通过零样本学习(无需采用后期融合、微调等复杂技术手段)就取得了62%的准确率,这一结果充分证明了Qwen 2.5模型在处理现实世界中复杂的视觉语言问题时具备强大的推理能力。
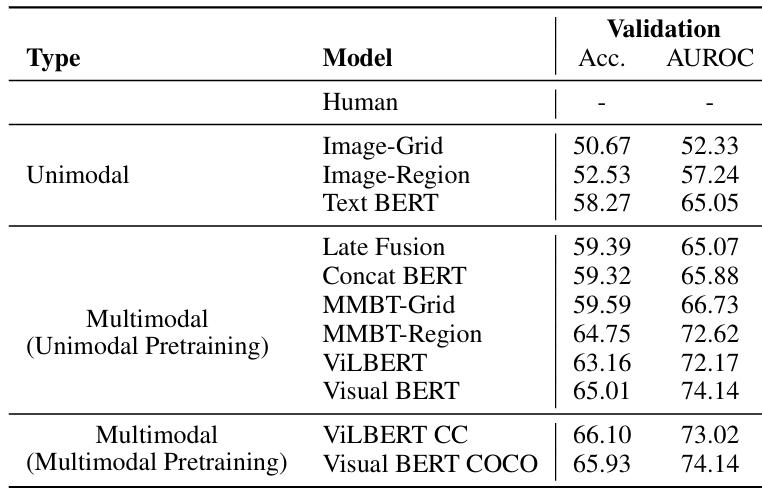
表 3: 各种现有技术在仇恨表情包挑战中的性能。
结论
在本篇博客文章中,我们首先全面探讨了内容审核的概念及其在维护社交媒体安全方面的关键作用,强调了在当前复杂的网络环境下,高效内容审核机制的重要性。随后,我们深入分析了诸如Facebook仇恨表情包挑战之类的行业倡议,该倡议旨在推动利用先进的AI模型来处理日益复杂的有害内容形式。
接下来,我们概述了视觉语言模型的发展历程与趋势,重点介绍了Qwen 2.5视觉语言模型系列,该系列凭借其创新的技术特性和显著增强的能力,在众多视觉语言模型中脱颖而出。
我们详细阐述了Qwen 2.5模型的关键特性,包括其大规模扩展的预训练数据集、显著增加的生成长度、对结构化输入和输出的高级支持能力等。同时,我们强调了Qwen2.5-Turbo带来的超长上下文长度等显著改进,以及Qwen2.5-72B-Instruct模型在性能与效率方面的突出表现。
最后,我们介绍了Qwen 2.5系列中多样化的模型尺寸所带来的应用灵活性,以及其在空间和时间维度处理能力上的增强,特别是零样本学习能力。通过具体的实践案例,我们详细解释了加载仇恨表情包数据集、使用Qwen 2.5执行零样本推理的完整过程,并对预测结果进行了全面评估。
本篇博客文章充分展示了视觉语言模型的这些技术进步,如何为实现更高效、更准确的内容审核提供有力支持,进而促进社交媒体平台的整体安全与健康发展。未来,随着技术的不断迭代,Qwen 2.5系列模型有望在更多领域发挥重要作用,为解决复杂的多模态信息处理问题提供更加强大的技术支撑。