S 3.1深度学习--卷积神经网络
卷积层
图像原理
卷积神经网络(Convolutional Neural Network, CNN)


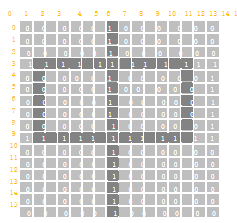
图像在计算机中是一堆按顺序排列的数字,数值为 0 到 255。0 表示最暗,255 表示最亮。
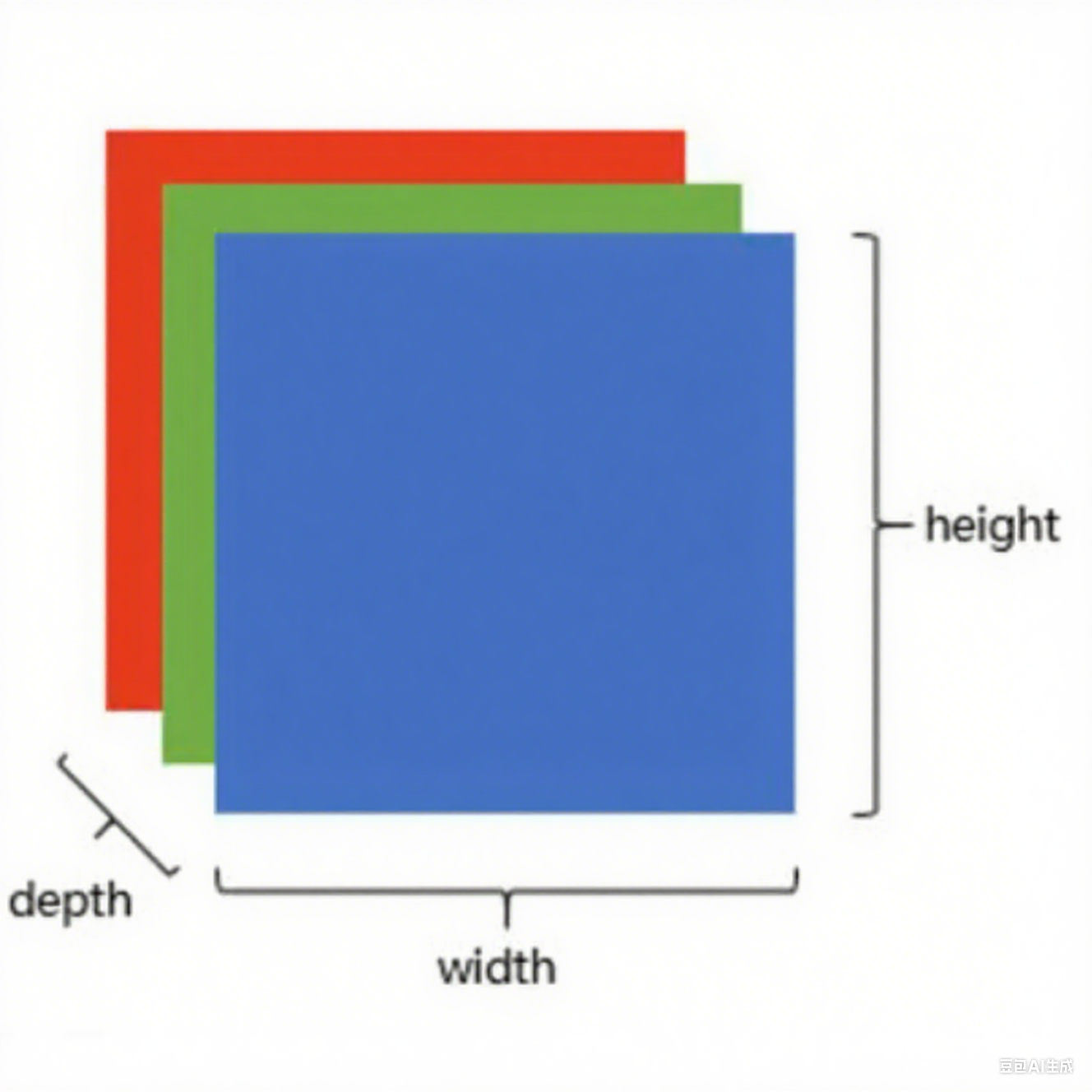
图像识别
上图是只有黑白颜色的灰度图,而更普遍的图片表达方式是 RGB 颜色模型,即红、绿、蓝三原色的色光以不同的比例相加,以产生多种多样的色光。RGB 颜色模型中,单个矩阵就扩展成了有序排列的三个矩阵,也可以用三维张量去理解。其中的每一个矩阵又叫这个图片的一个 channel(通道),宽,高,深来描述。
画面不变性

知道一个物体不管在画面左侧还是右侧,都会被识别为同一物体,这一特点就是不变性,希望所建立的网络可以尽可能的满足这些不变性特点

传统神经网络
解决办法是:用大量物体位于不同位置的数据训练,同时增加网络的隐藏层个数从而扩大网络学习这些变体的能力。
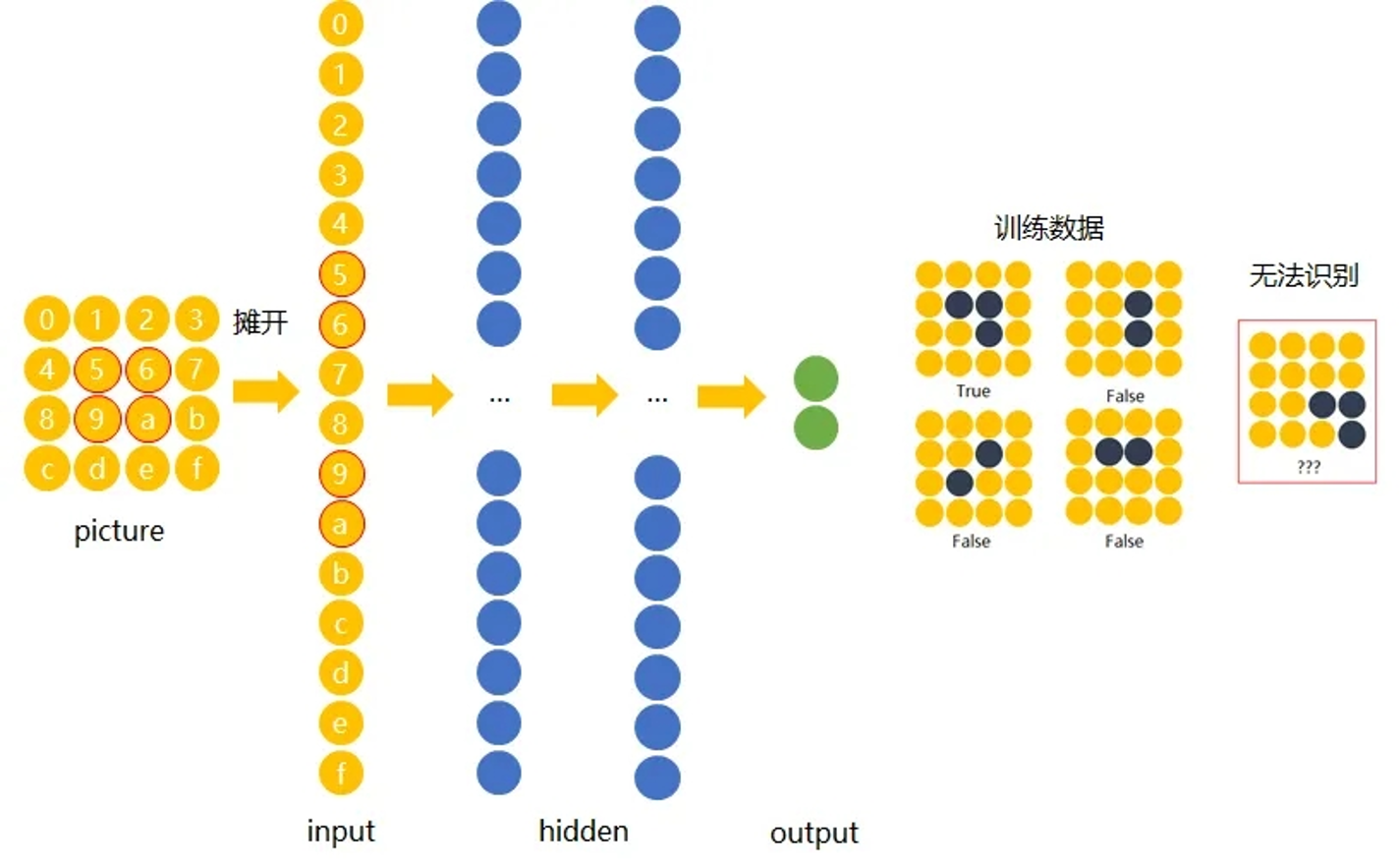
卷积层
1、什么是卷积?
对图像(不同的窗口数据)和卷积核(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。
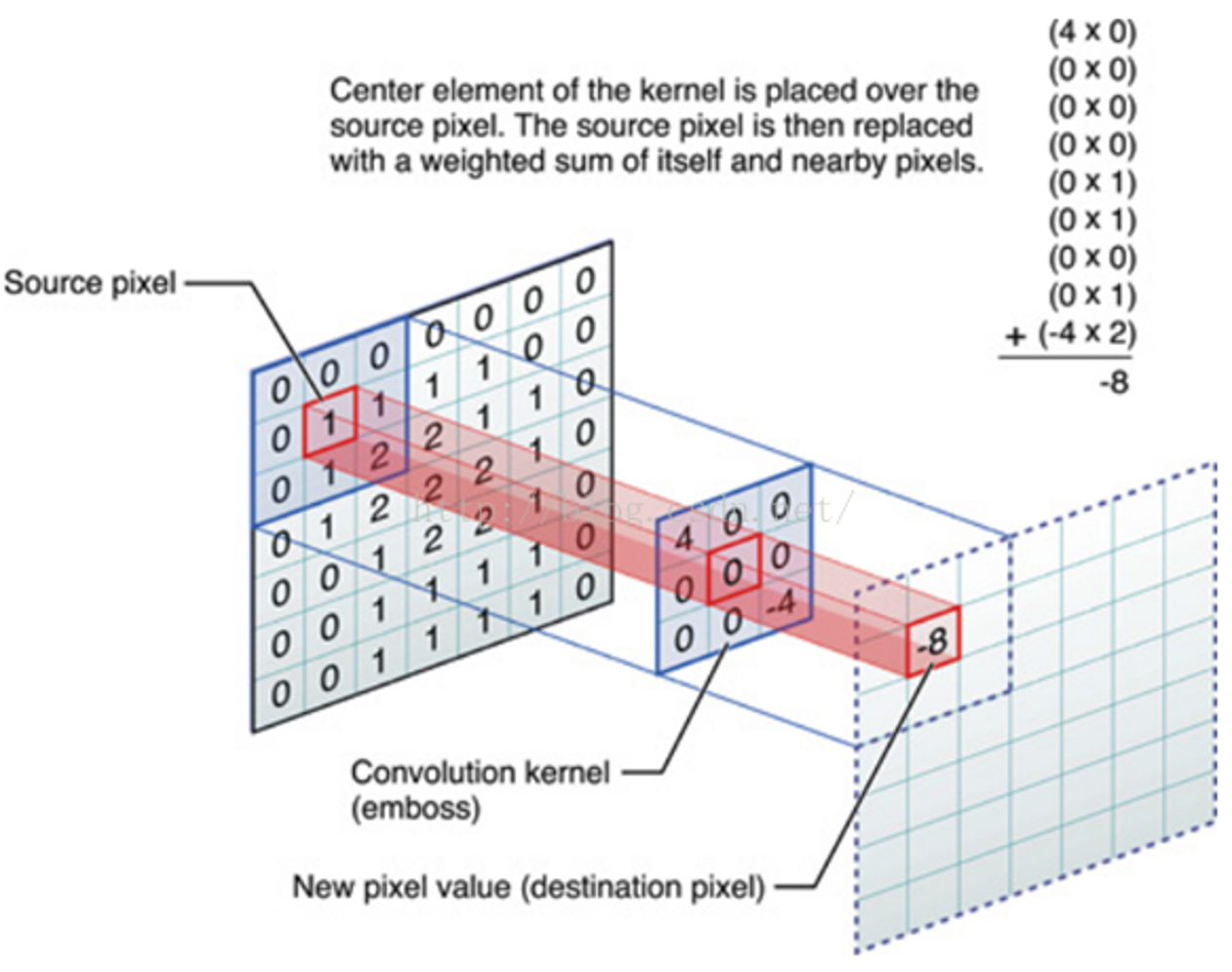
Convolution kernel就是权重w
卷积操作存在的问题?
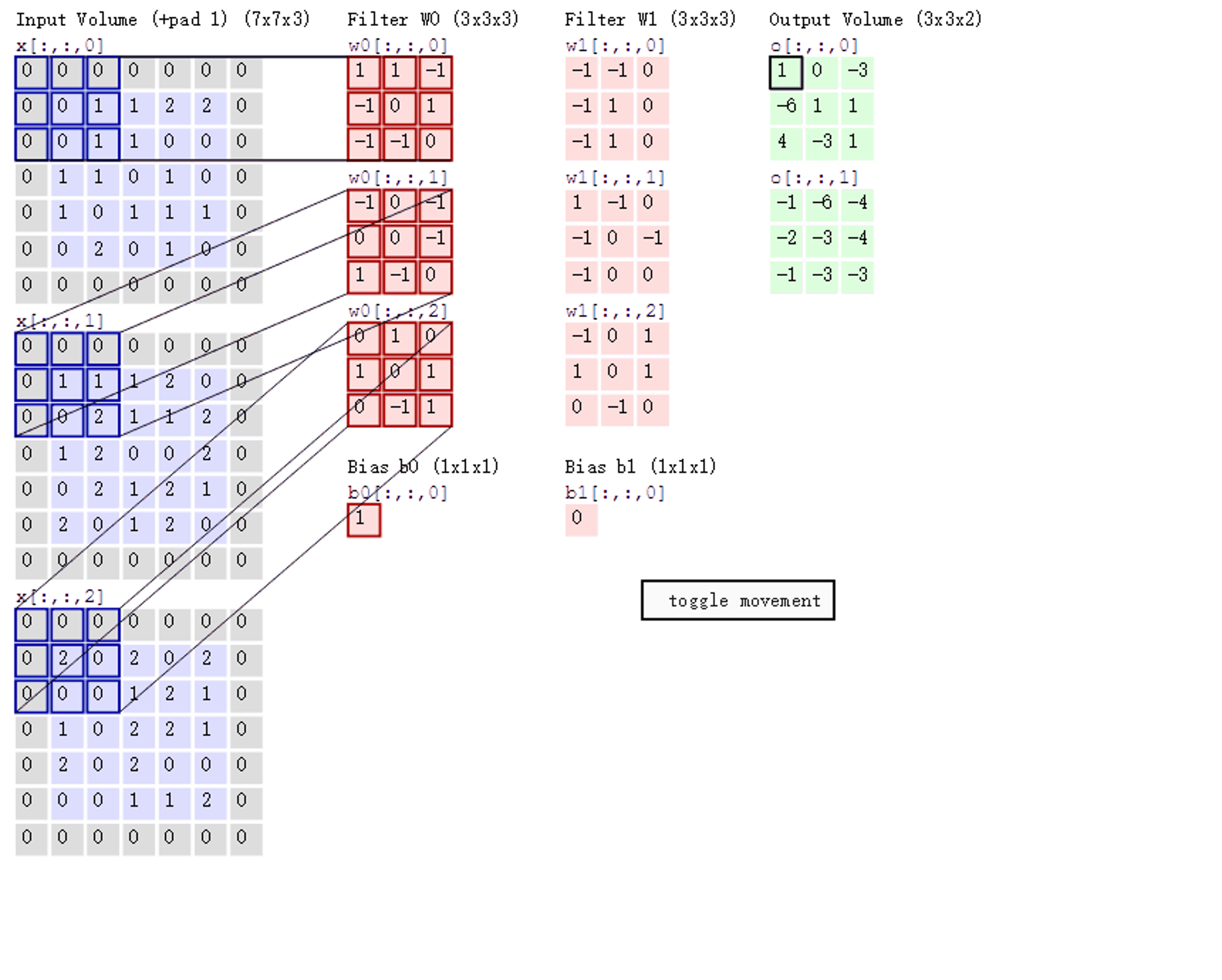
图中所显示的就是RGB,在蓝色的那一列从上到下顺序是 R G B 三个通道,Filer w0 w1 就是卷积核,
WeiJing-Yu个人动态-WeiJing-Yu动态记录-哔哩哔哩视频
这个是动画图
a.步长stride:每次滑动的位置步长。
b. 卷积核的个数:决定输出的depth厚度。同时代表卷积核的个数。
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。
- 数据窗口每次移动两个步长取 3*3 的局部数据,即 stride=2。
- 两组神经元(卷积核),即 depth=2,意味着有两个滤波器。
- zero-padding=1。
网络构造
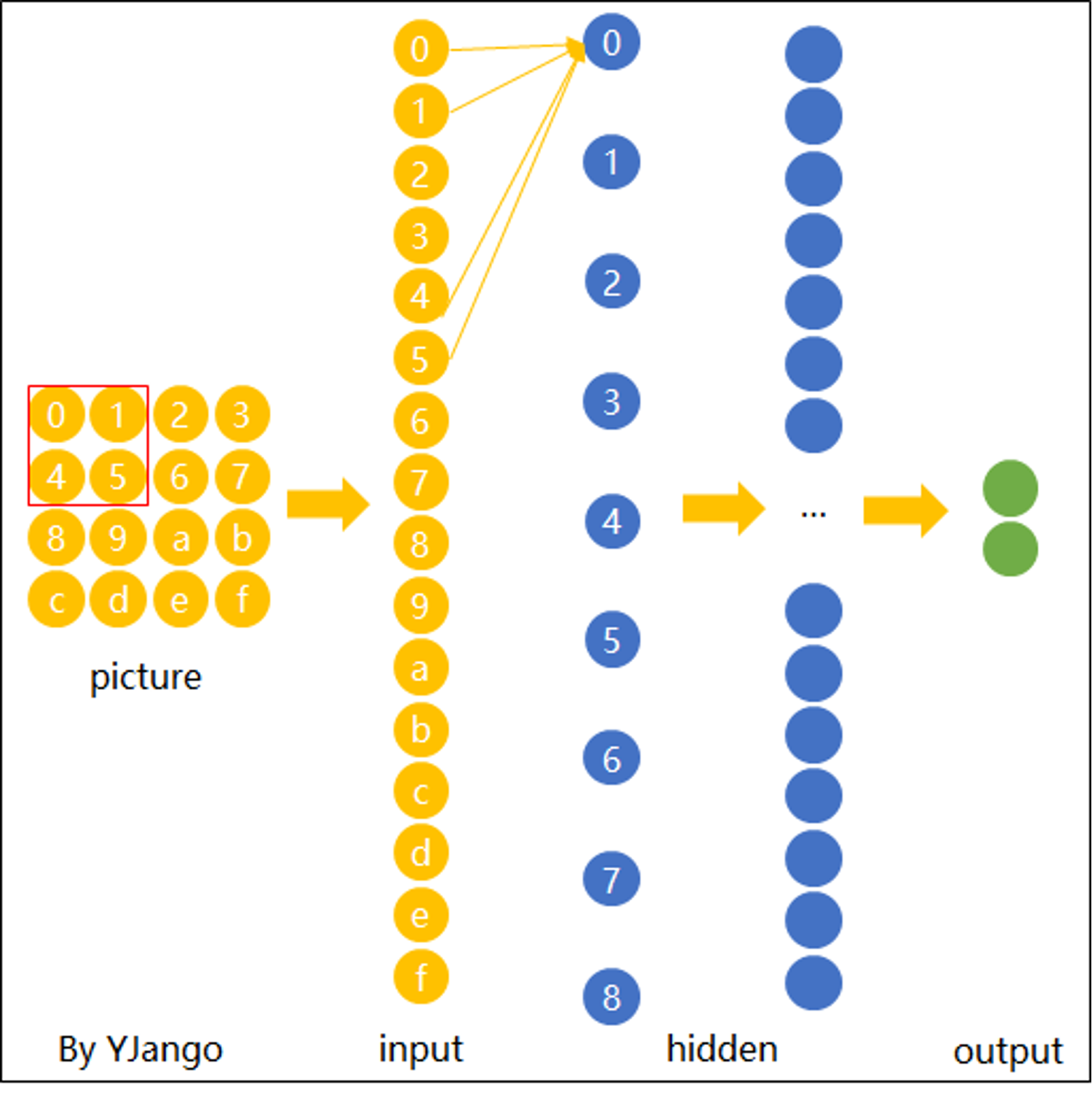
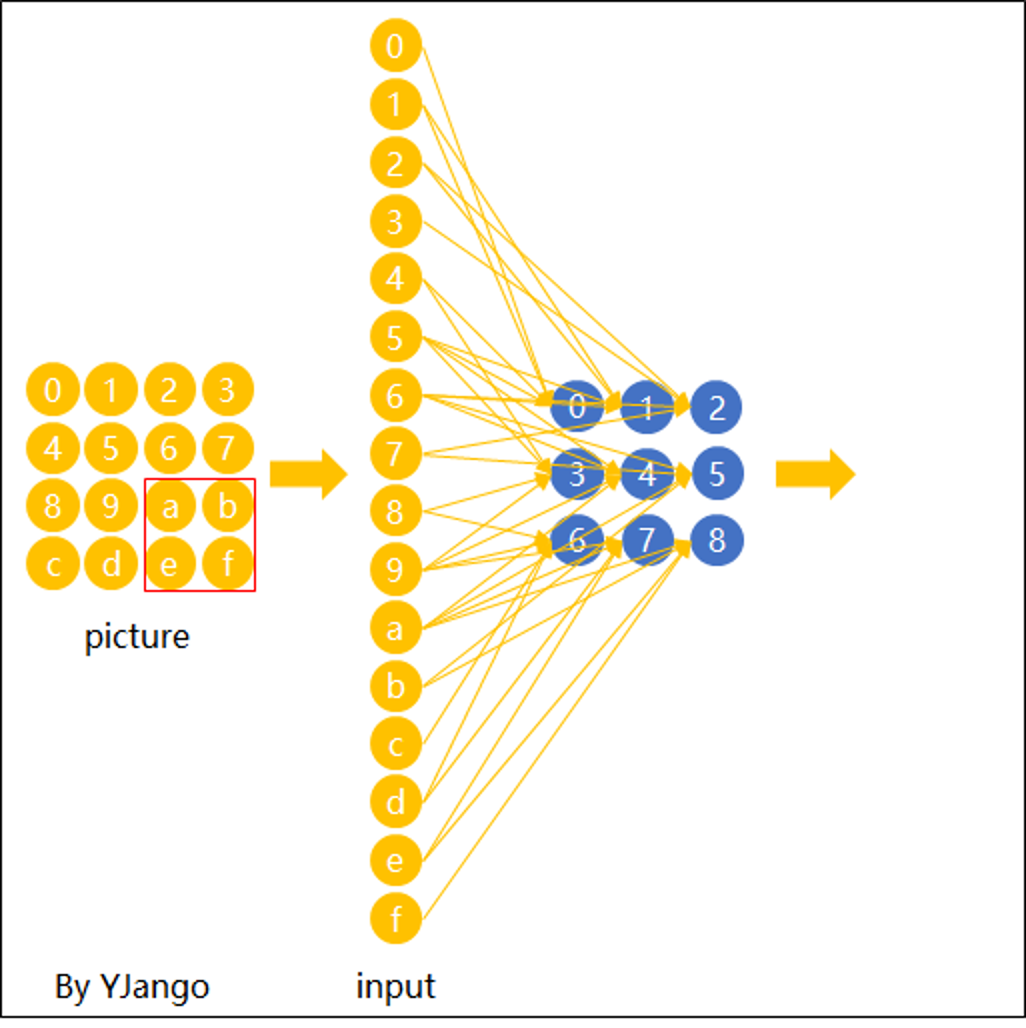
动画演示
卷积神经网络-网络构造对比图_哔哩哔哩_bilibili
原理
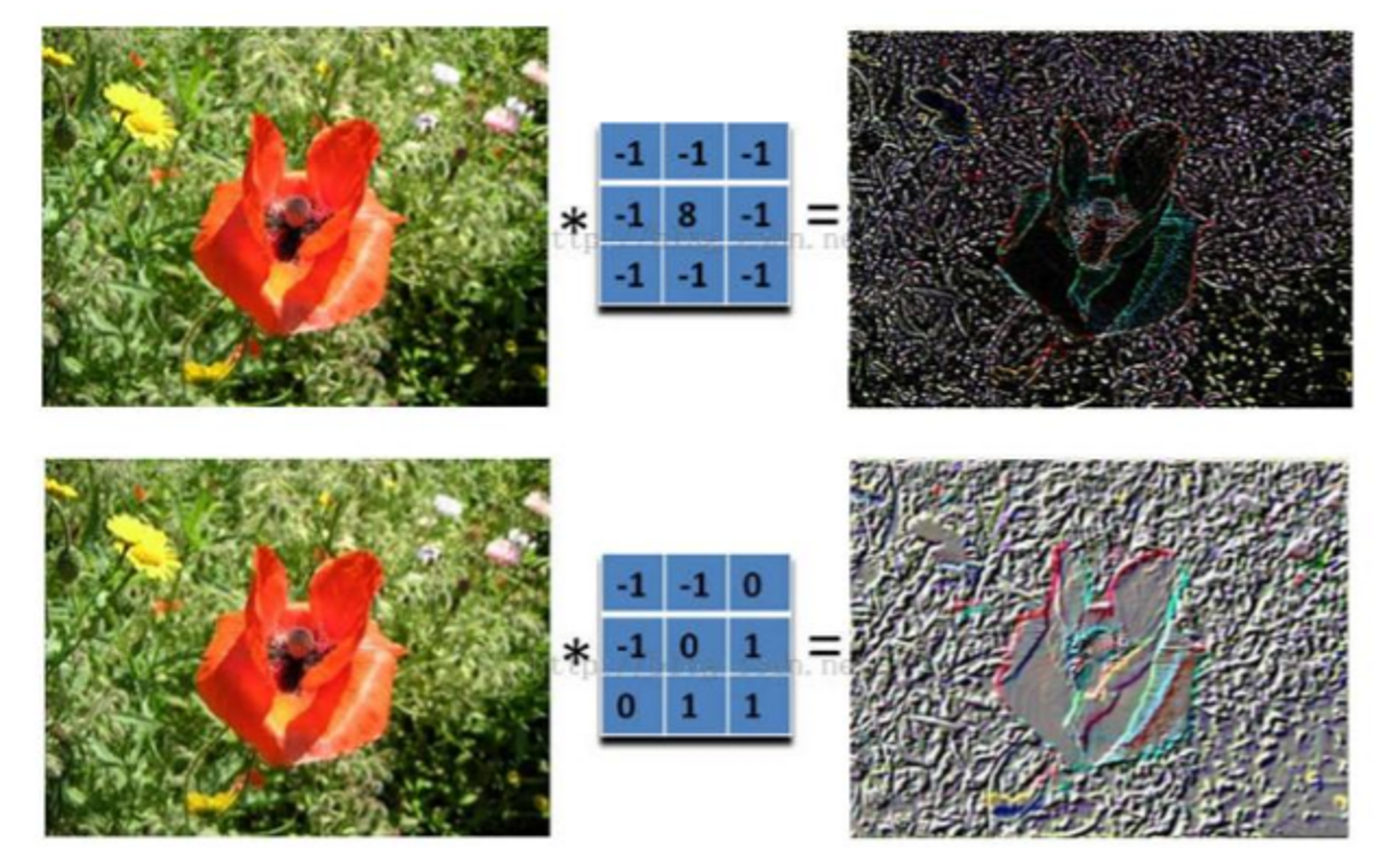
与人眼观看事物原理相似,先看事物的轮廓,可以看出花周围有很多的噪声点,这时候需要滤波器把噪声点都去掉就可以保留花的形状
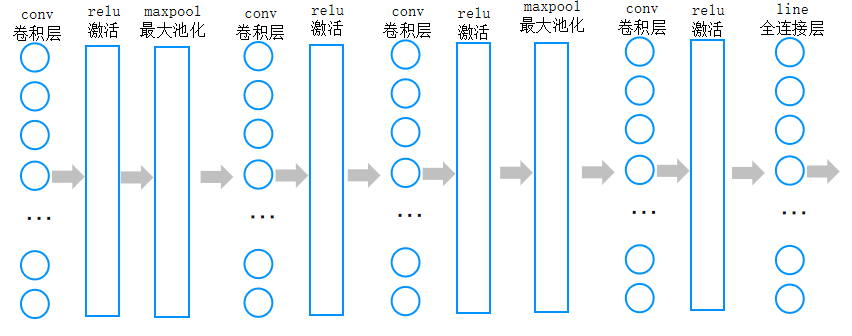
卷积神经网络的系统
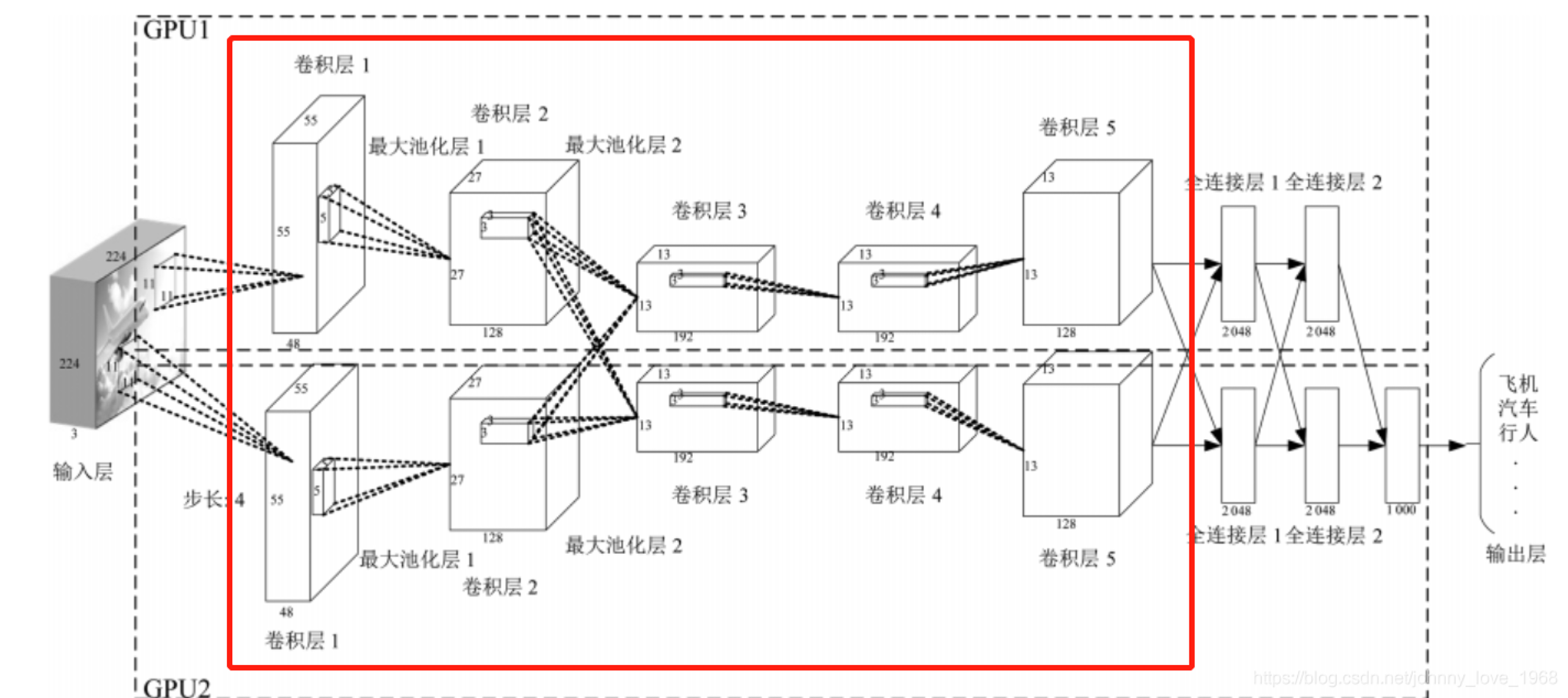
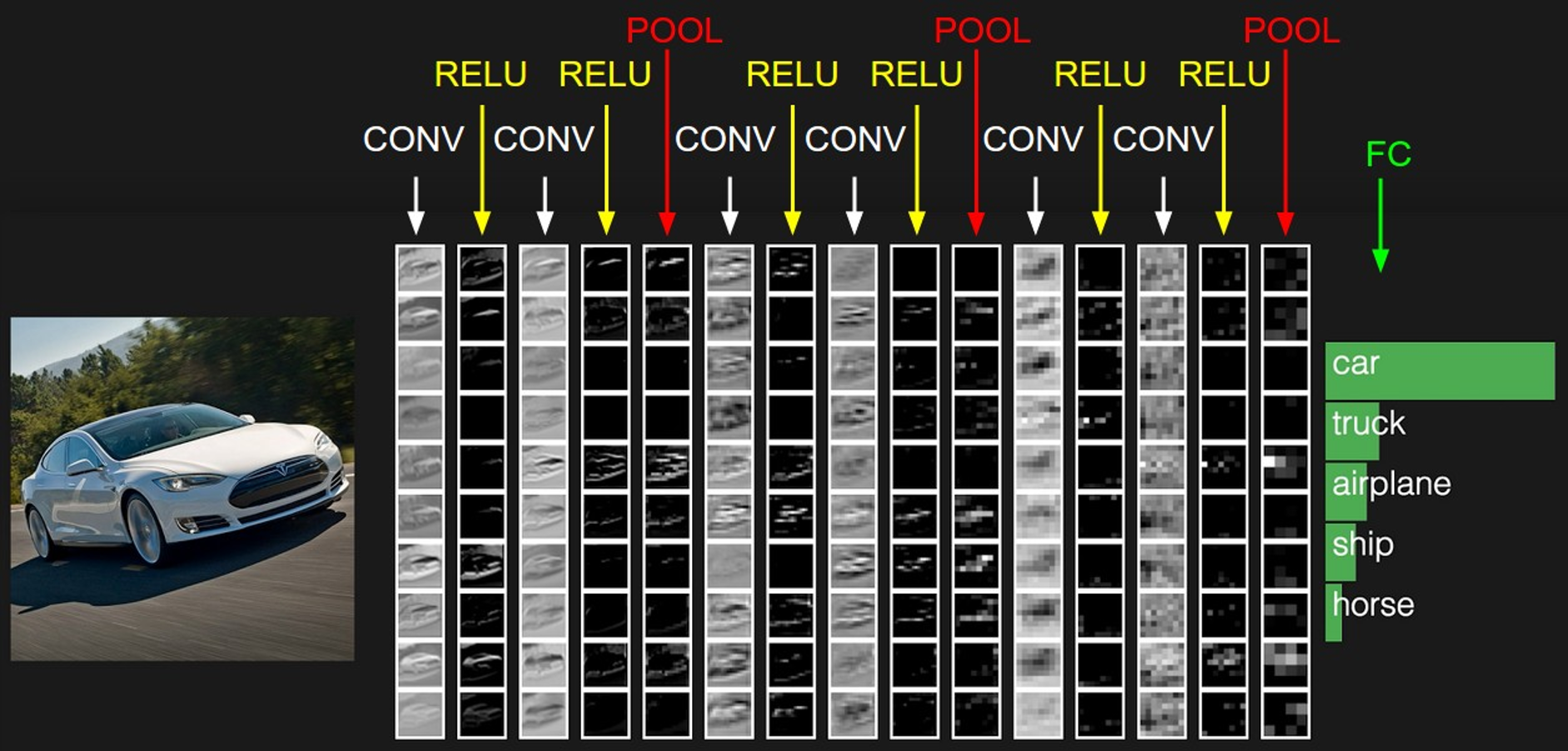
conv就是卷积的意思,RELU就是非线性激活,POOL是池化层,压缩。FC就是全连接

例如输入数据为32*32*3的图像,用10个5*5*3的卷积核来进行操作,步长为1,边界0填充为2,最终输出结果为?
(32-5+2*2)/1 +1 =32,输出规模为32*32*10的特征图
池化层Pooling
池化层的作用:一种降采样,减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。
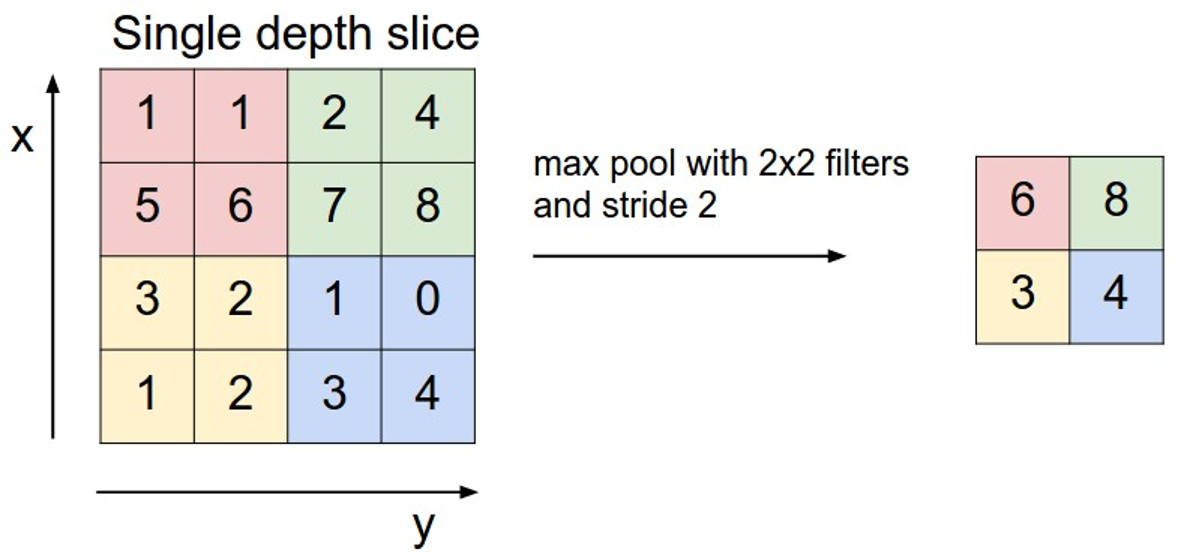
常见的池化层:最大池化、平均池化、全局平均池化、全局最大池化。 平均池化(average pooling):计算图像区域的平均值作为该区域池化后的值。 最大池化(max pooling):选图像区域的最大值作为该区域池化后的值。是最为常见的。 通常来说,CNN的卷积层之间都会周期性地插入池化层。
池化层操作方法:与卷积层类似,池化层运算符由一个固定形状的窗口组成,该窗口根据其步幅大小在输入的所有区域上滑动,为固定形状窗口(有时称为 池化窗口)遍历的每个位置计算一个输出。 然而,不同于卷积层中的输入与卷积核之间的互相关计算,池化层不包含参数。
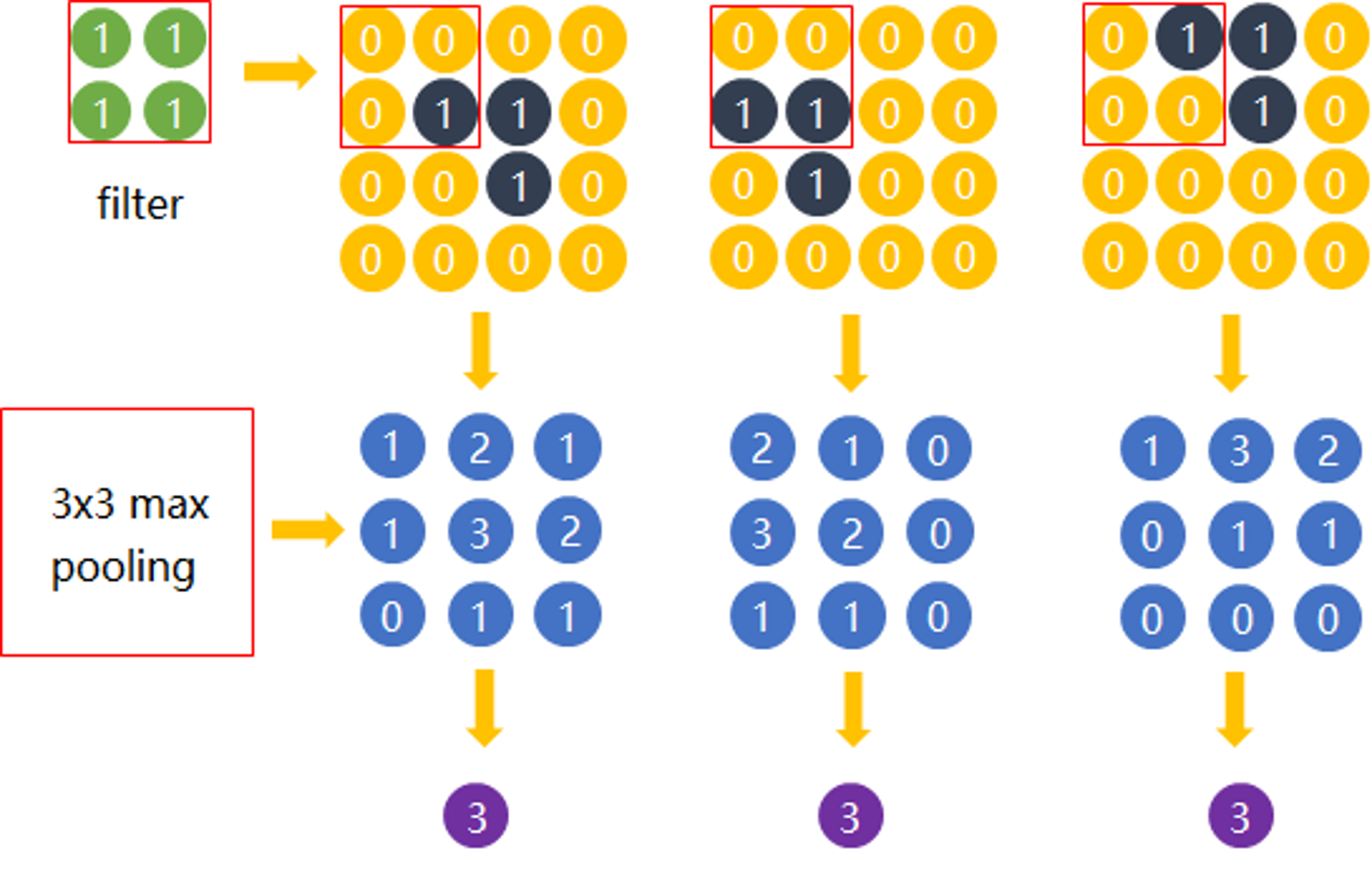
最大池化的原理分析
Max pooling的主要功能是压缩,却不会损坏识别结果。这意味着卷积后的Feature Map中有对于识别物体不必要的冗余信息。那么我们就反过来思考,这些“冗余”信息是如何产生的。
全连接层
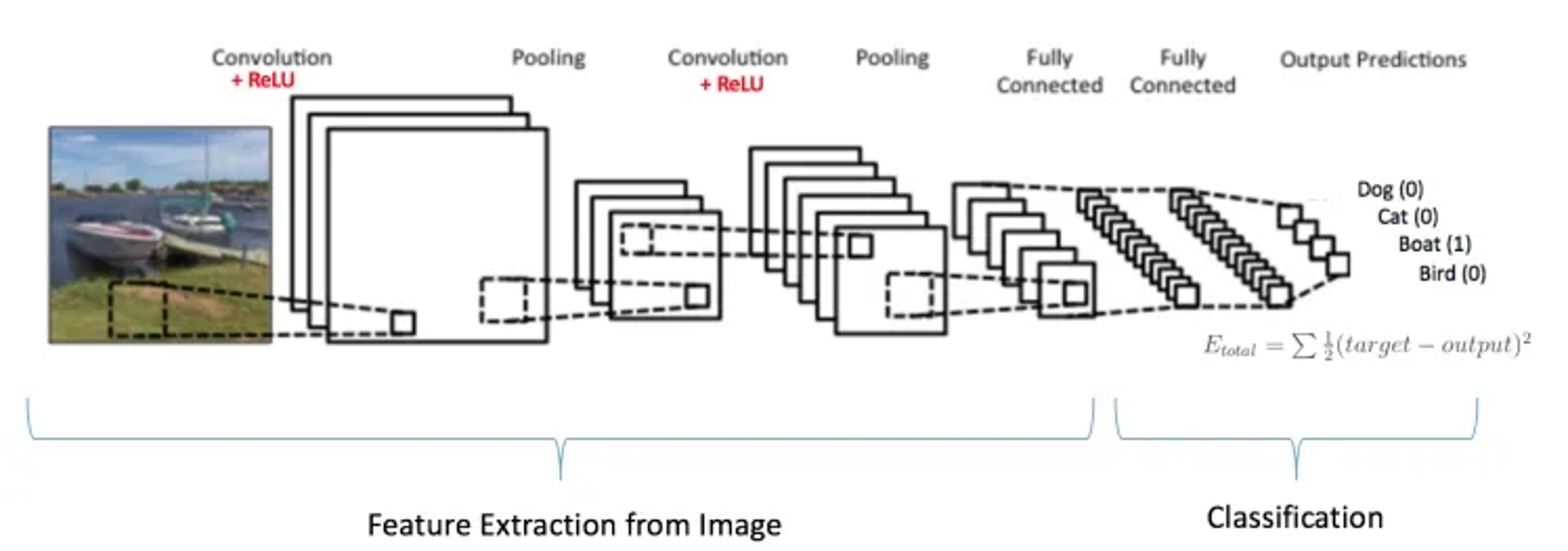
当抓取到足以用来识别图片的特征后,接下来的就是如何进行分类。 全连接层(也叫前馈层)就可以用来将最后的输出映射到线性可分的空间。 通常卷积网络的最后会将末端得到的长方体平摊(flatten)成一个长长的向量,并送入全连接层配合输出层进行分类预测。
感受野
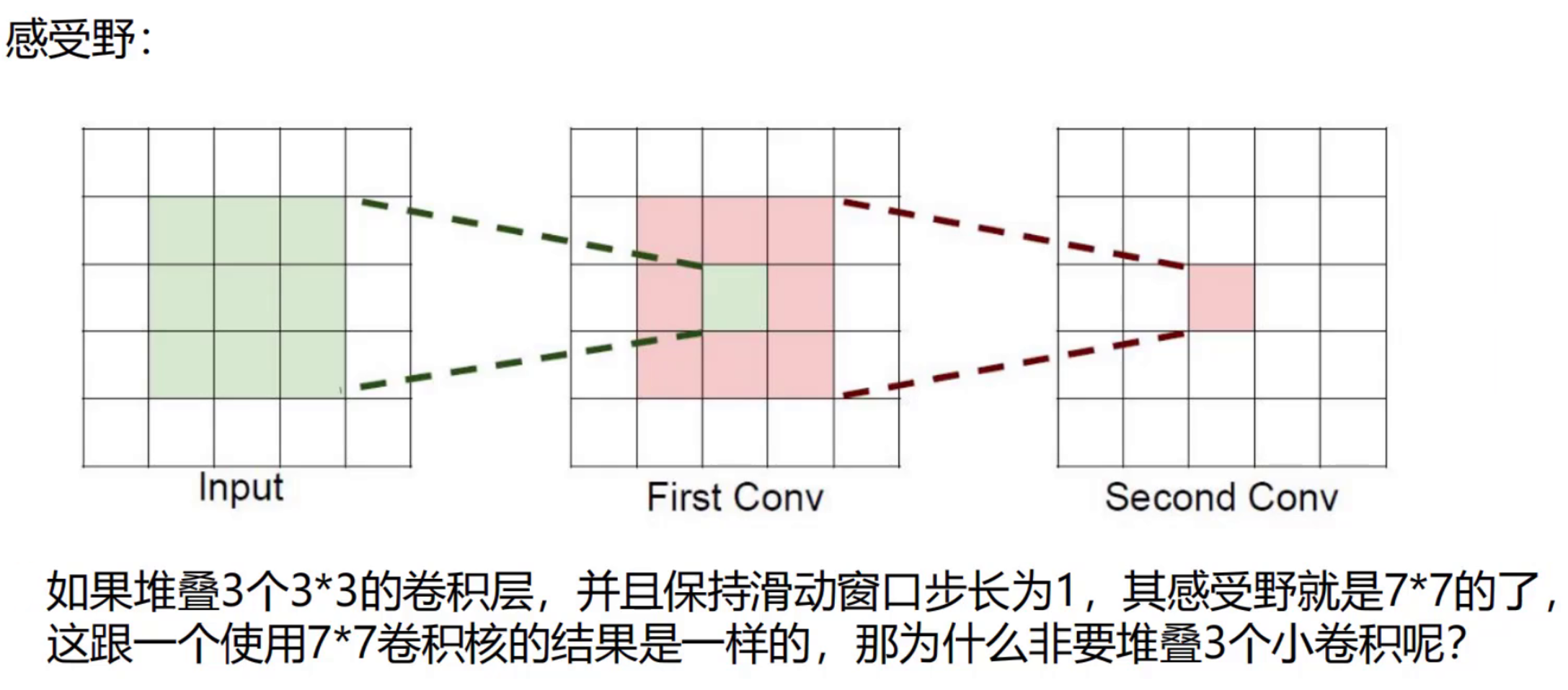
例如图片是3通道: 卷积核为7*7的,则卷积核所需要的参数个数为:7*7=49个 卷积核为3个3*3的,则卷积核所需要的参数个数为:(3*3*3) =27
一张250*250的图片和一张500*500的图片,卷积层的权重参数数谁多?
当卷积核大小为 3×3,输入通道数为 3(RGB 图像),输出通道数为 10 时,卷积层的权重参数数量为((3×3×3 + 1)×10=280)个,这个数量与输入图片的分辨率大小无关。
卷积神经网络的多种模型
以下是几个比较有名的卷积神经网络结构
LeNet:第一个成功的卷积神经网络应用
AlexNet:类似LeNet,但更深更大。使用了层叠的卷积层来抓取特征(通常是一个卷积层马上一个max pooling层)
ZF Net:增加了中间卷积层的尺寸,让第一层的stride和filter size更小。
GoogLeNet:减少parameters数量,最后一层用max pooling层代替了全连接层,更重要的是Inception-v4模块的使用。
VGGNet:只使用3x3 卷积层和2x2 pooling层从头到尾堆叠。
ResNet:引入了跨层连接和batch normalization。(这个目前是常用的)
DenseNet:将跨层连接从头进行到尾。
李飞飞,1976 年出生于中国北京,后移居美国。她是美国国家工程院院士、美国国家医学院院士、美国艺术与科学院院士,也是斯坦福大学计算机科学系的首位 “红杉资本教授”,以及斯坦福大学 “以人为本人工智能研究院” 的联席院长。
李飞飞在人工智能领域成就卓越,2007 年,她与普林斯顿大学教授李凯发起 ImageNet。ImageNet 是一个大型图像数据集,旨在推动计算机视觉技术的发展。它收集了超过 1000 万个标注图像,涵盖超过 2000 个类别。ImageNet 成为新一代人工智能技术的三大基石之一,为深度学习和人工智能的发展做出了巨大贡献,没有 ImageNet,就没有生成式人工智能,其重要性如同人类的眼睛。2012 年,在李飞飞发起举办的 “ImageNet 大型视觉识别挑战赛” 第三届比赛上,杰弗里・辛顿团队提交的算法 AlexNet 图片识别准确率高达 85%,创造了计算机视觉领域的世界纪录,也让世人见识到 ImageNet 的力量。
Beyond ILSVRC workshop 2017
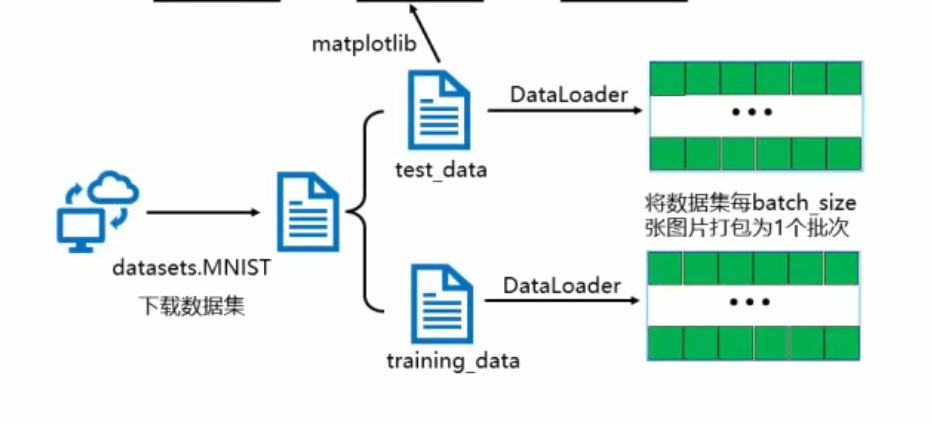
搭建卷积神经网络
利用mnist数据集实现卷积神经网络的图像识别。