推荐系统王树森(四)特征交叉+行为序列
github--PPT
特征交叉01:Factorized Machine (FM) 因式分解机_哔哩哔哩_bilibili
目录
0. 什么是特征交叉
特征交叉01:Factorized Machine (FM) 因式分解机 拆矩阵
特征交叉02:DCN 深度交叉网络(适配交叉)
特征交叉03:LHUC (PPNet) 用户特征加权
特征交叉04:Squeeze-and-Excitation Network(SENet)
特征交叉05:Bilinear 交叉 (中间加W矩阵)
1. LastN 用户行为序列(最近交互的N个物品)
行为序列01:DIN模型(注意力机制)
行为序列02:SIM模型(长序列建模)
0. 什么是特征交叉
-
在推荐系统中,输入一般是很多离散特征的 embedding(比如用户 ID、性别、城市、视频类别等)。
-
单个特征 embedding 只能表达“独立语义”,但很多效果来自于 交叉关系:
-
“女性用户 × 美妆视频” → 点击率高 “男性用户 × 美妆课程” → 点击率低
-
所以模型需要显式或隐式地建模 特征交互。
特征交叉01:Factorized Machine (FM) 因式分解机 拆矩阵
线性模型 特征的加权和![]()
二阶交叉特征 拟合变量中还有乘积(是线性回归 逻辑回归的优化 引入二阶项表达能力更强)

为了减少参数量 进行矩阵分解
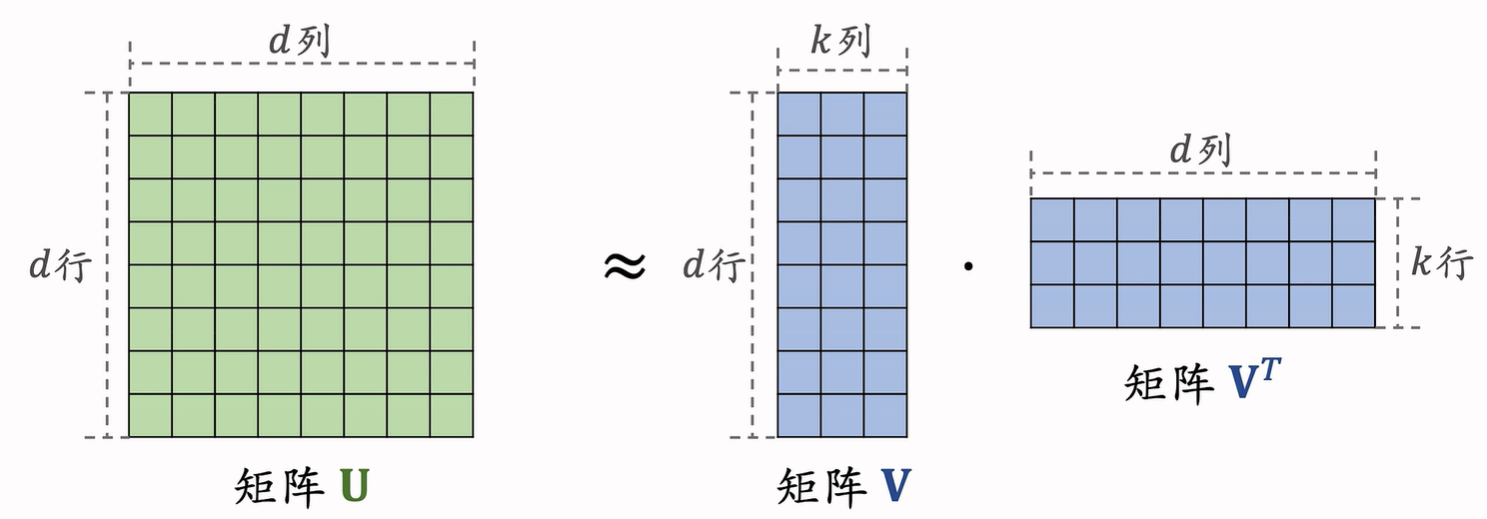
换成两个扁矩阵的内积 将d^2 参数变成 2*k*d 在k<<d时显著减少参数量

在神经网络 网络架构压缩中也有类似的手法
李宏毅深度学习教程 第16-18章 终身学习+网络压缩+可解释性人工智能 -CSDN博客
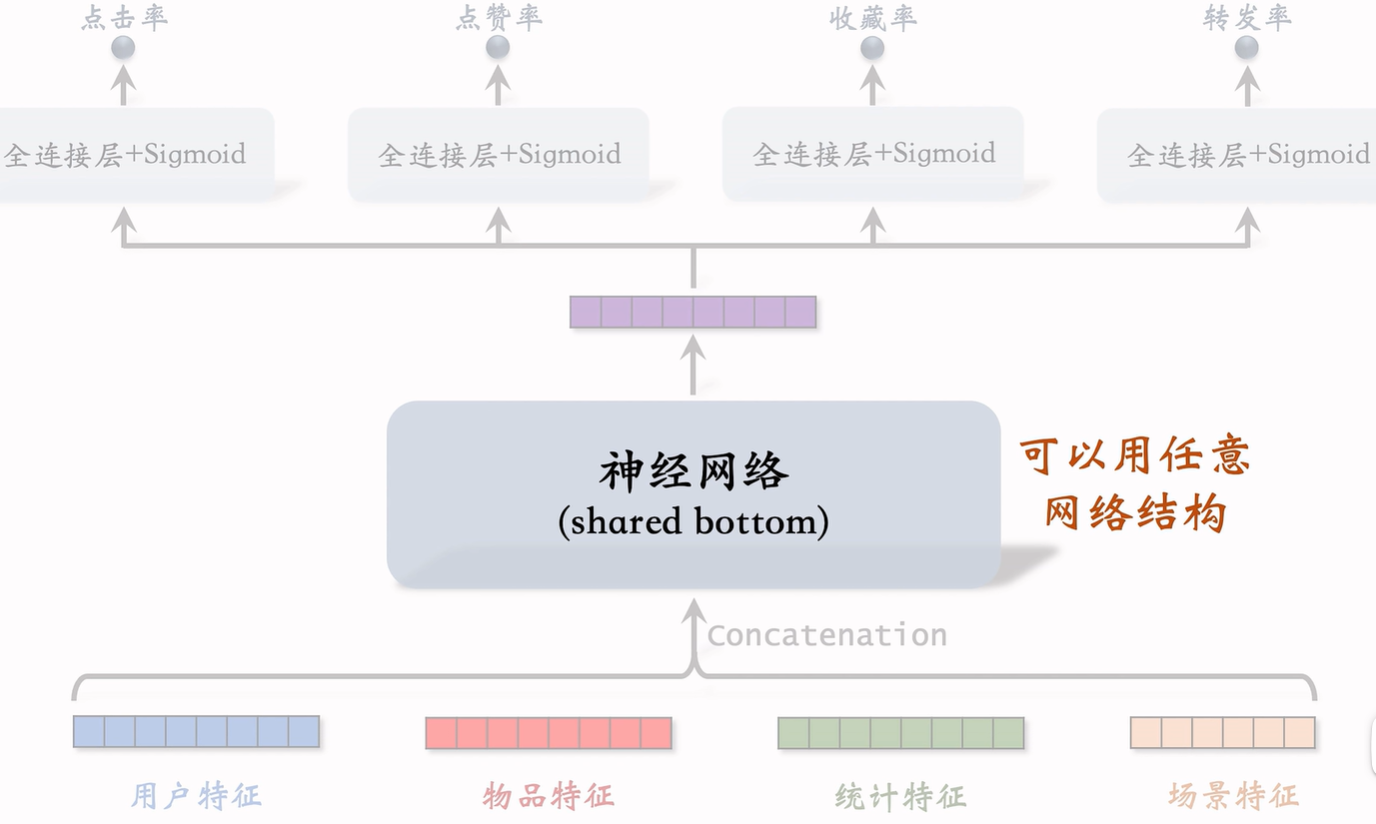
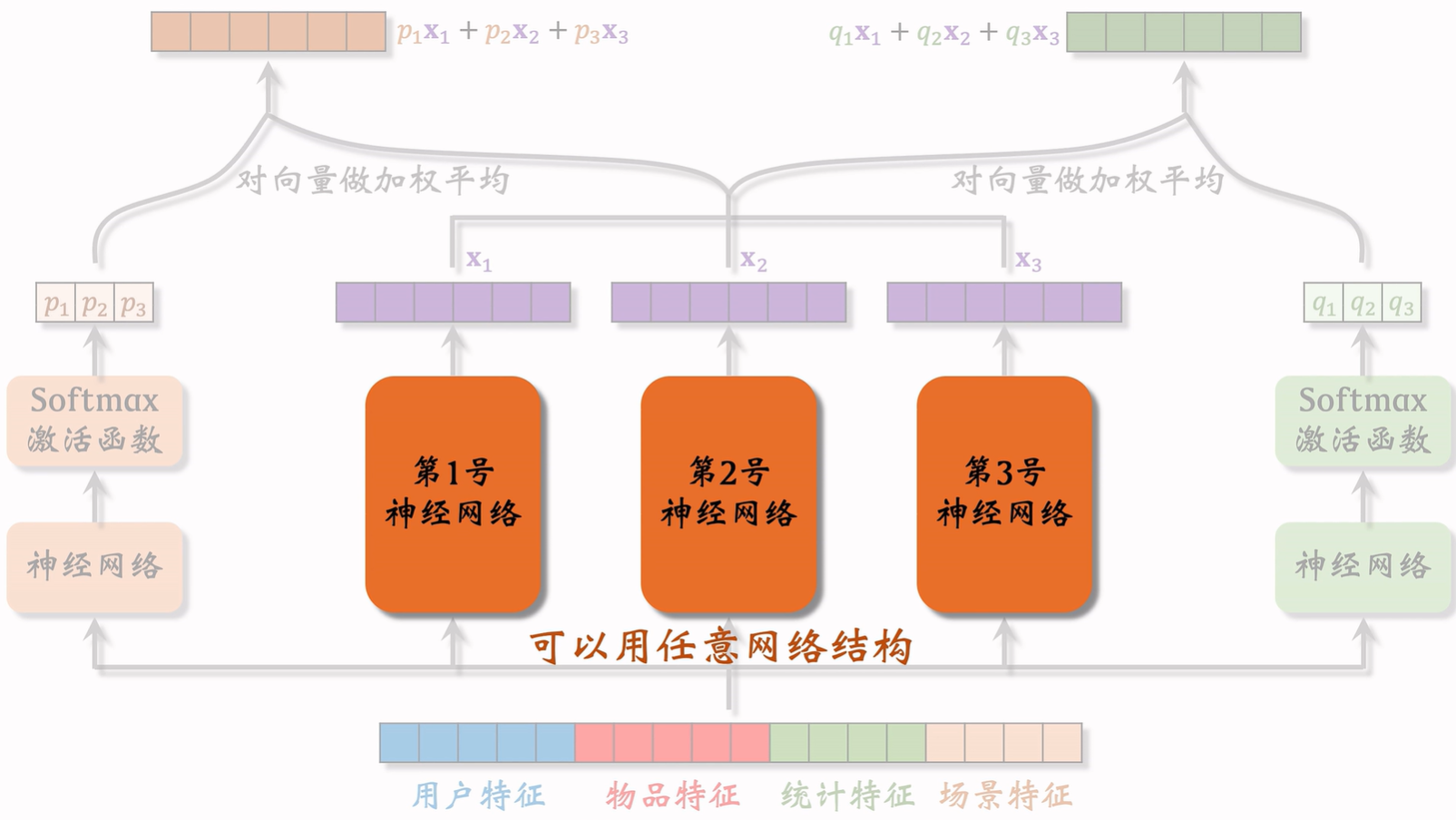
特征交叉02:DCN 深度交叉网络(适配交叉)
原来排序中的神经网络 全连接层可替换为交叉层
MLP 通过多层非线性叠加,可以近似任何函数,但:
-
参数量大,学习高阶特征交叉的效率不高。
-
在推荐系统这种高维稀疏特征下,MLP 需要很多层才能学到「特征交互关系」
交叉架构优势
(1) 显式建模特征交叉
-
层数对应交叉阶数:第 1 层是一阶交叉,第 2 层是二阶交叉…… 显式学习交叉
(2) 参数量小
-
每层参数量和输入维度线性相关,而不是全连接那种平方级别。
-
非常适合推荐系统这种高维稀疏输入。
![]()
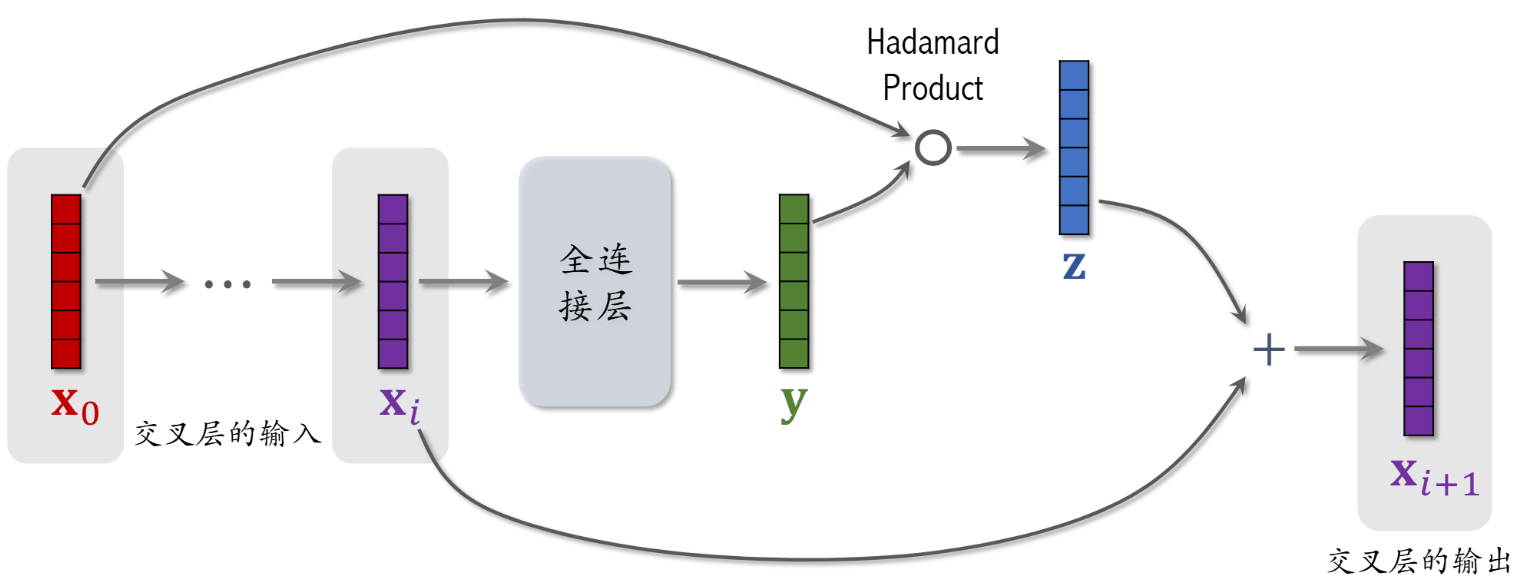
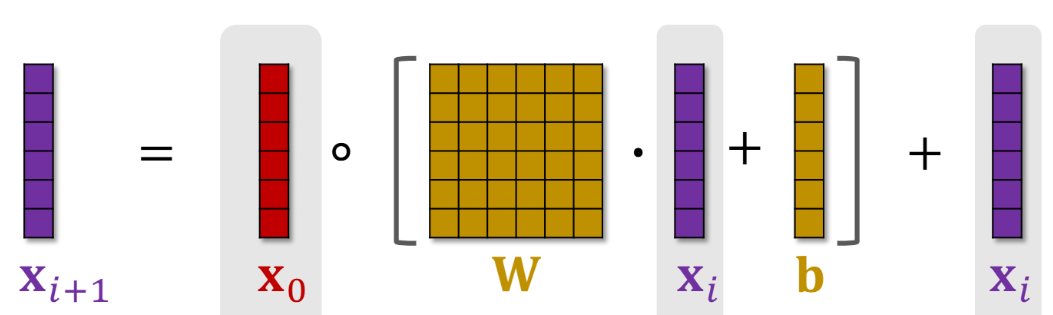
写成下面的矩阵形式 原来全连接层是 WX+b 现在按元素乘x0 再加xi
![]()

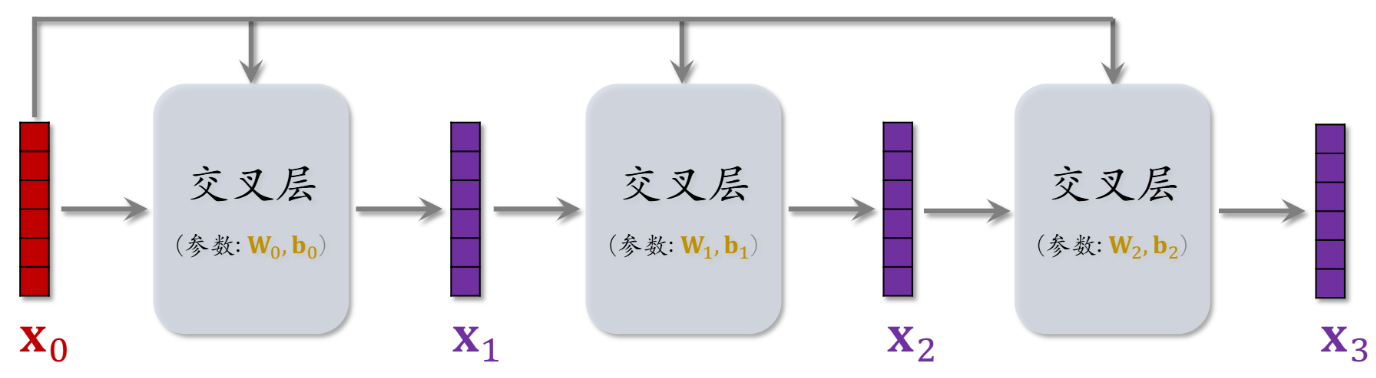
交叉网络 每层都这么递推下一层
特征交叉03:LHUC (PPNet) 用户特征加权
Learning Hidden Unit Contributions (LHUC)
提出背景:语音识别中,训练的声学模型往往是「说话人无关」(speaker-independent),但是在不同说话人、口音、噪声下,性能会下降。每次输出前 相当于加权说话人特征。
核心思想:在保留原始网络参数的前提下,只对 隐层单元的贡献系数 做缩放调整。
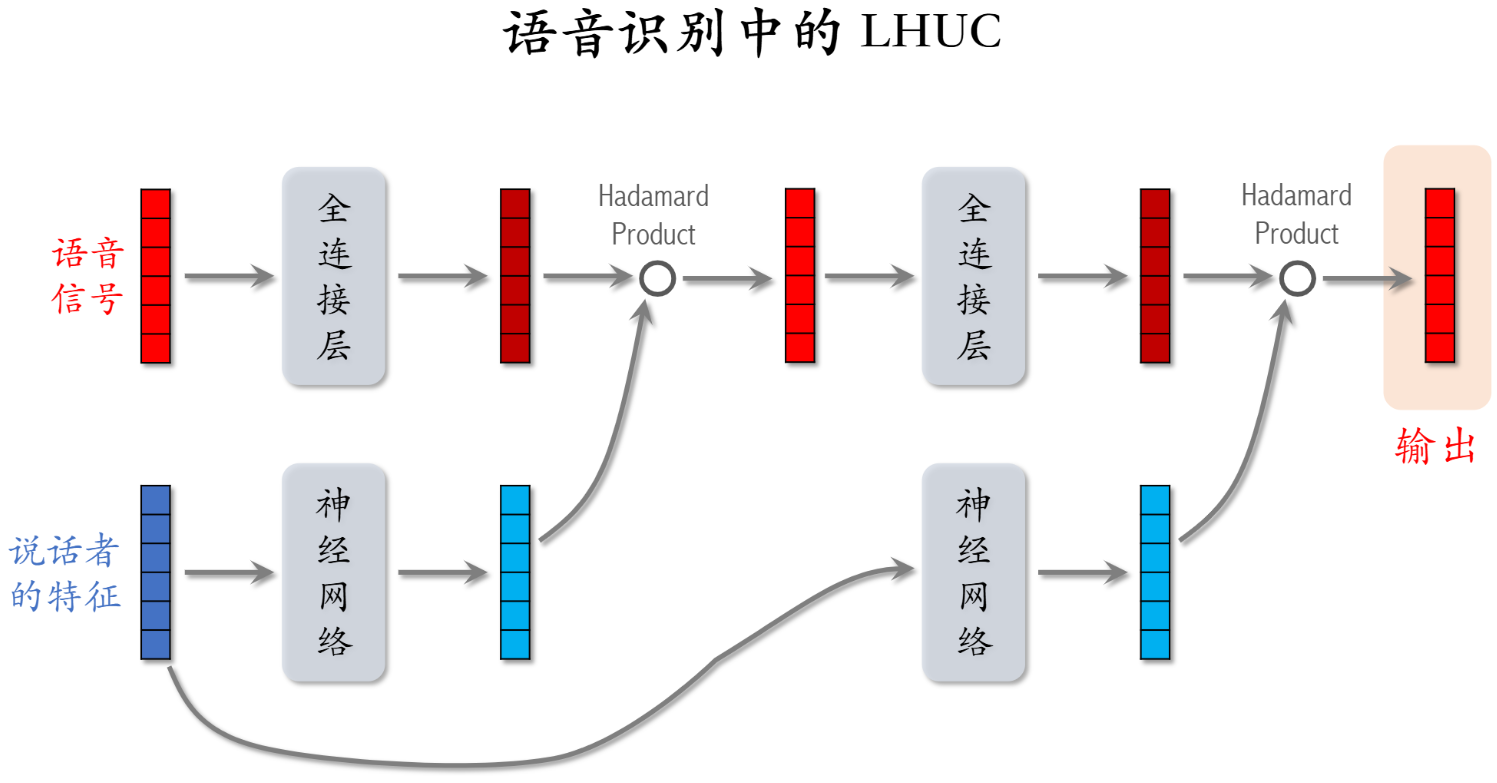
输出为sigmoid*2 把输出范围设置为(0,2) 可以积累放大特征。
把语音信号 -> 物品特征(基本); 说话者特征 -> 用户特征(加权) 则变为推荐系统
用户特征加权适用精排。
特征交叉04:Squeeze-and-Excitation Network(SENet)
-
核心思想(本来在CV):让网络自己学会哪些通道(channel)更重要。
-
Squeeze:对每个通道做全局平均池化,得到全局统计信息。
-
Excitation:用两层全连接网络,生成每个通道的权重系数(0~1)。
-
Re-weight:对原特征图的每个通道乘上权重,实现通道注意力。
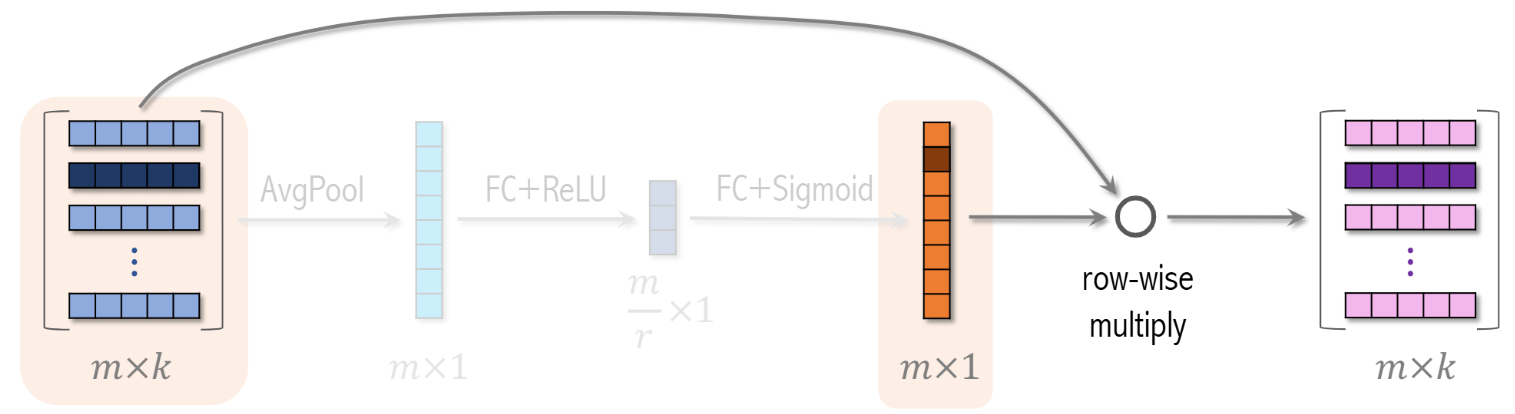
每个特征 embedding 向量称作一个 field;推荐系统 则是自主学习哪些field更重要
每个field 若干个元素 先压缩成一个元素;再通过 FC+ReLU → FC+Sigmoid 得到权重;再圈乘
特征交叉05:Bilinear 交叉 (中间加W矩阵)
内积和哈达玛积 都要求两个向量维度相同。 还可以中间夹一个矩阵W 变成x1Wx2 可以对任意维度。相当于先对x2乘以W矩阵 转化为和x1相同维度,再内积或哈达码积。
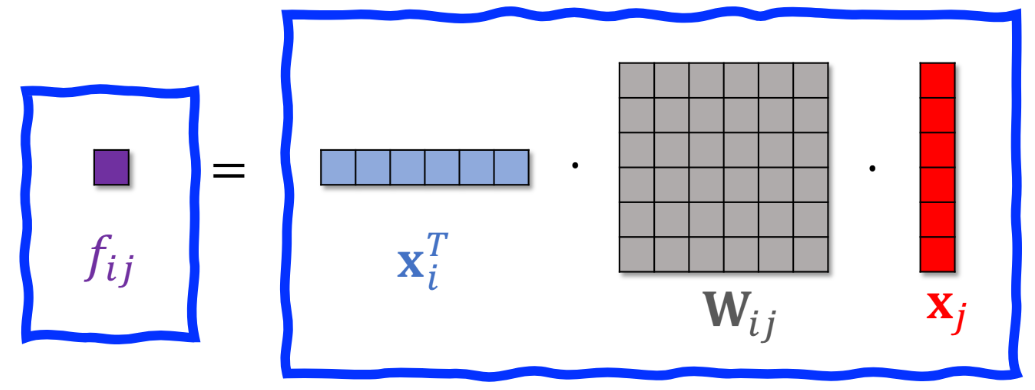
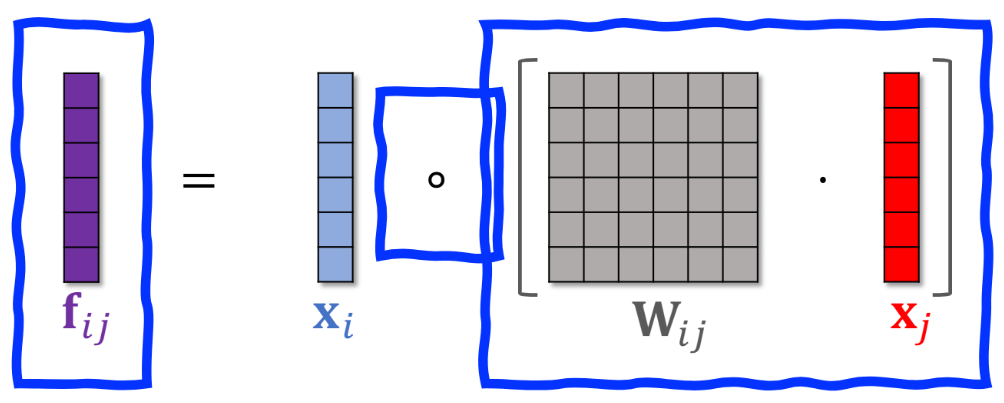
每个组合对应矩阵n*m参数 k个特征则 所有都两两交叉k*k/2个组合 总参数量太多了,通过人工指定哪些参数需要进行交叉。
![]()
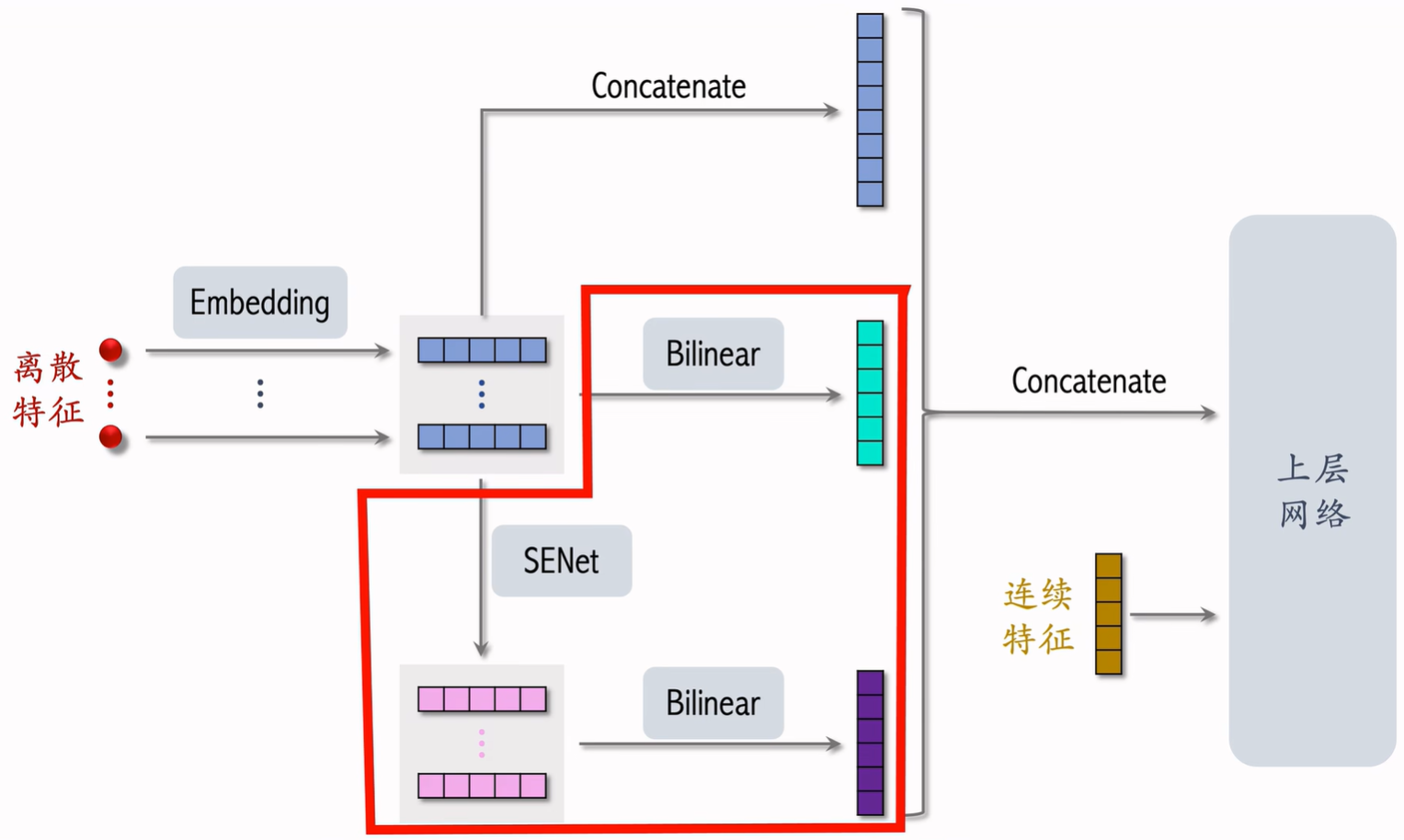
1. LastN 用户行为序列(最近交互的N个物品)
LastN:用户最近的n次交互(点击、点赞等)的物品ID 做embedding后向量取平均,作为一个用户特征输入到召回和排序模型。
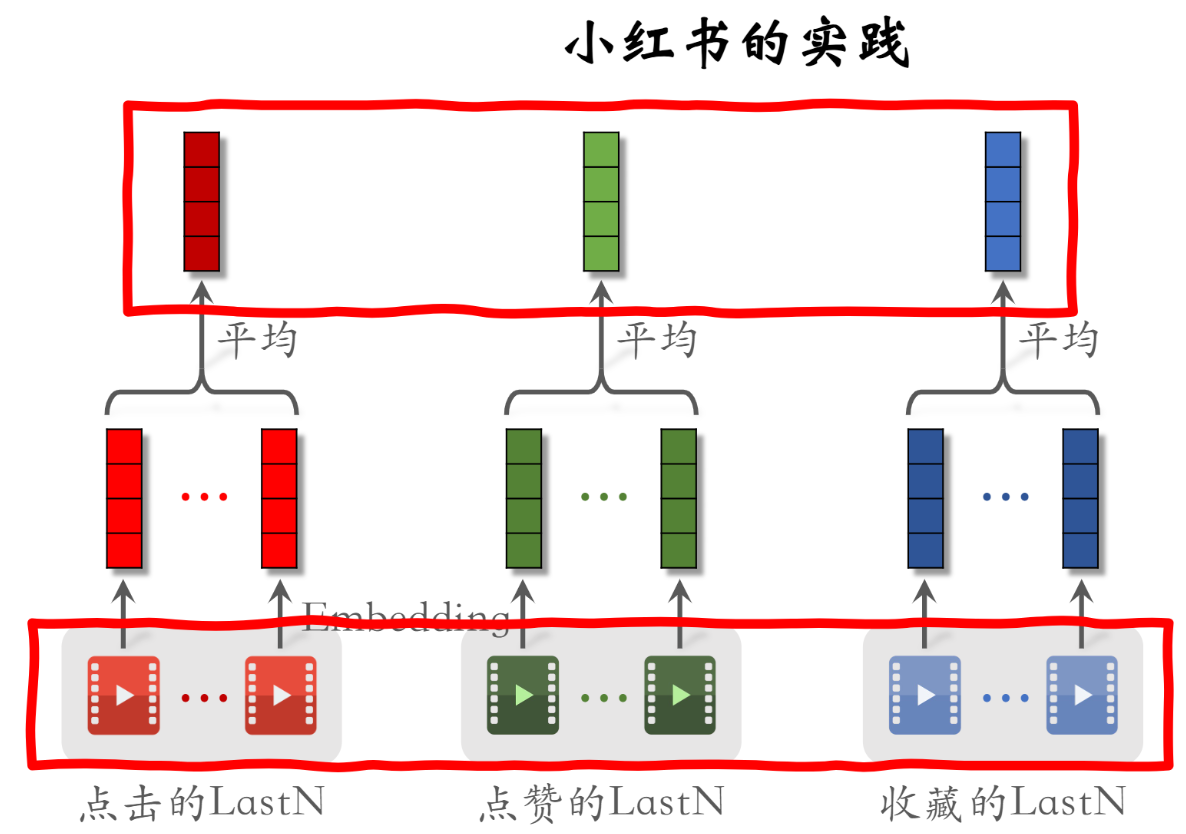
行为序列01:DIN模型(注意力机制)
简单平均的弊端: 不同候选物品对用户兴趣的触发是不一样的。LastN也有各种类型物品。
例:用户买过化妆品 + 手机配件,当候选是口红时,化妆品历史更相关;当候选是耳机时,数码配件历史更相关。而简单平均会丢失这种“候选相关性”。
DIN 的目标就是:让用户历史行为 根据候选物品动态加权,更精确地建模兴趣。(类似注意力机制)
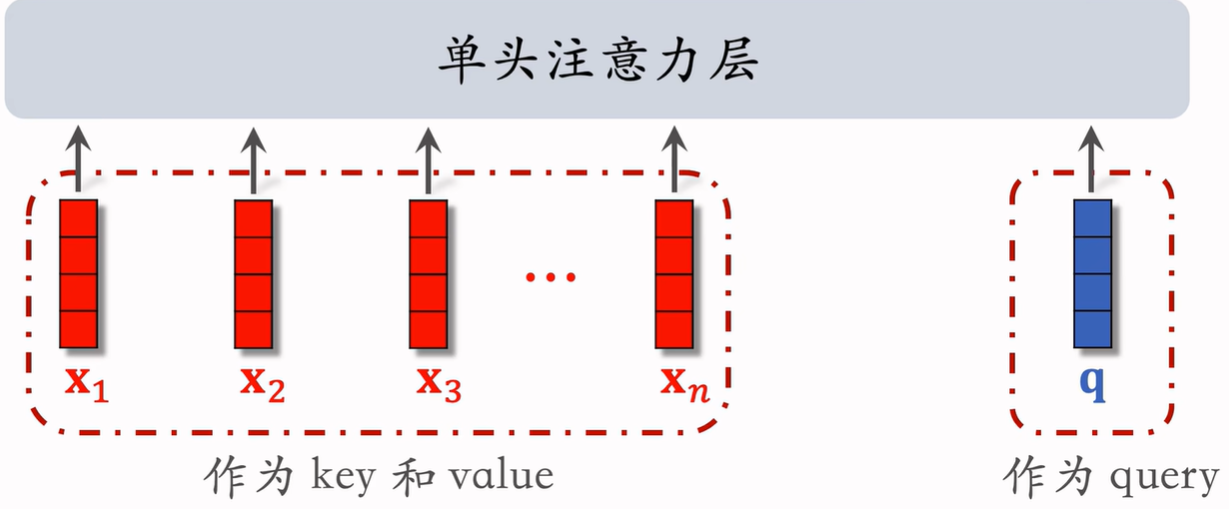
候选物品 与LastN的相似度作为权重;将LastN向量的加权和作为新用户特征。
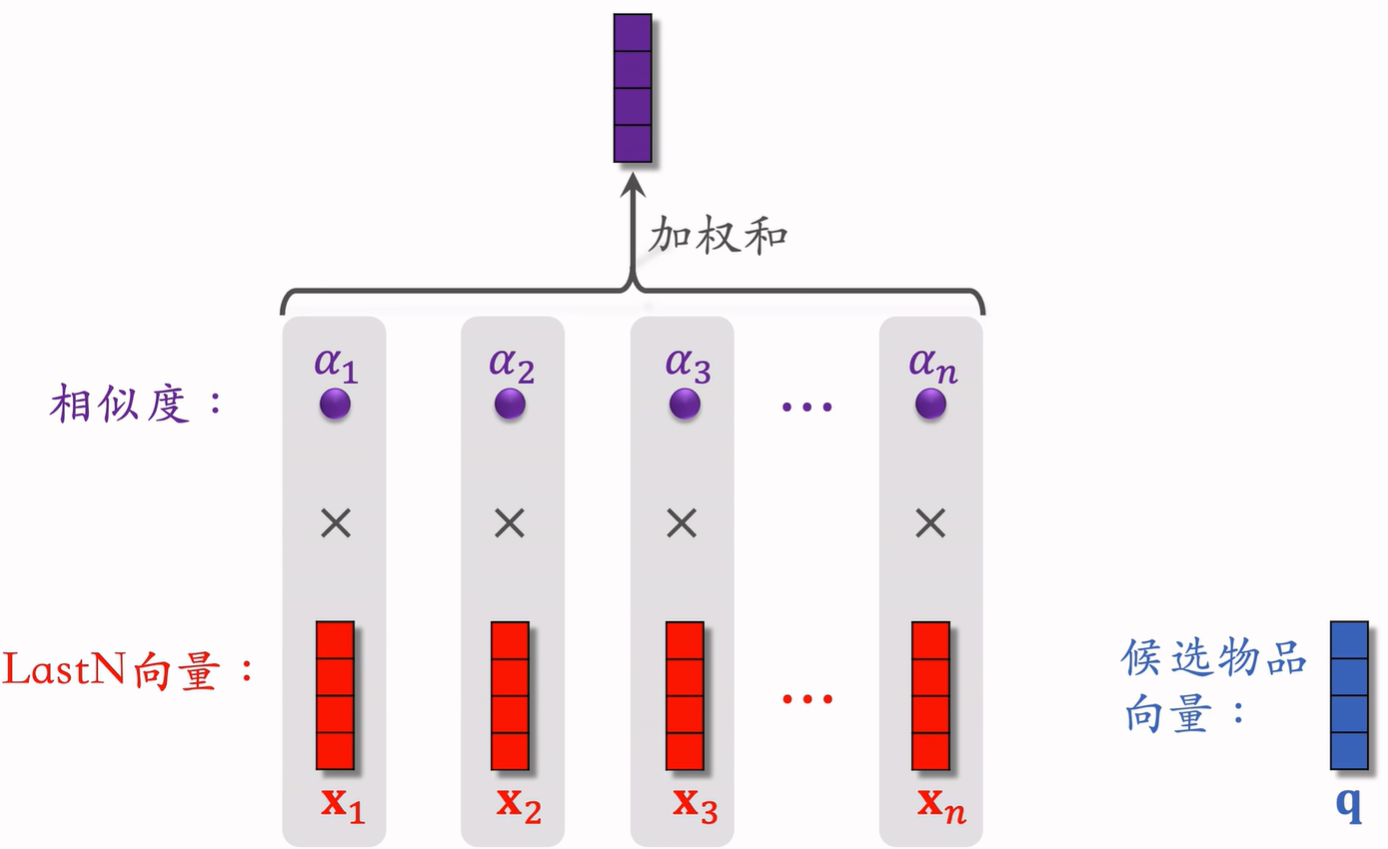
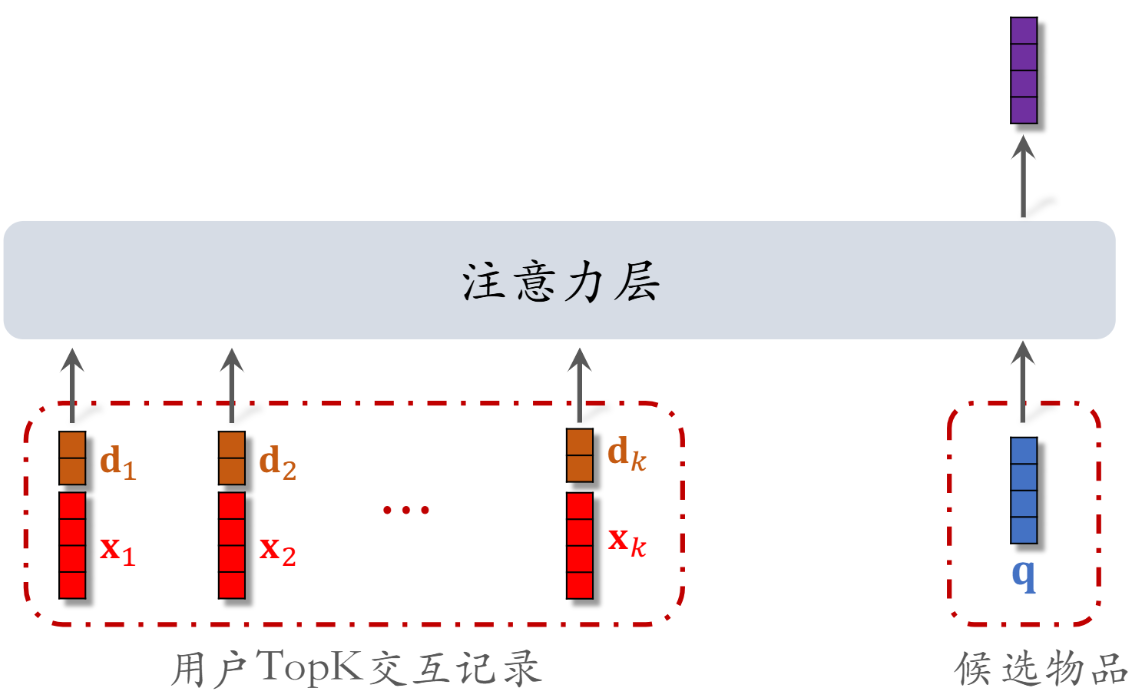
行为序列02:SIM模型(长序列建模)
DIN模型注意力层的计算量 正比于n(用户行为序列的长度) 只能记录最近几百个物品,否则计算量太大。
缺点:关注短期兴趣,遗忘长期兴趣。
改进方向:快速排除掉与候选物品无关的LastN物品,找到前k个相似物品TopK,降低注意力层的计算量。SIM则适用于长序列建模。
找TopK可以通过 方法一:根据类别分类 在同类别里找;方法二:进行k邻近查找
用户与某个LastN物品的交互时刻距今为δ。 对δ做离散化,再做embedding,变成向量d。物品本身变成向量x。