【ElasticSearch】原理分析
【ElasticSearch】原理分析
- 【一】核心原理与细节
- 【1】倒排索引 (Inverted Index)
- (1)与传统正排索引的区别:
- (2)构建过程:
- 【2】近实时 (NRT) 搜索的实现
- 【3】段合并 (Segment Merging)
- 【二】架构设计
- 【1】 集群 (Cluster)、节点 (Node) 与角色
- 【2】分片 (Shard) - 分布式的基础
- 【3】写流程
- 【4】读流程 (Search)
- 【三】性能分析、优化与权衡
- 【1】写性能优化
- 【2】读性能(搜索)优化
- (1)优化 Mapping:
- (2)优化查询 DSL:
- (3)硬件:
- (3)预热:
- 【3】集群设计与容量规划
- 【4】性能瓶颈识别
【一】核心原理与细节
【1】倒排索引 (Inverted Index)
这是 Elasticsearch 和 Lucene 最核心的原理,也是其高速搜索的基石。
(1)与传统正排索引的区别:
(1)正排索引(如数据库):文档 -> 内容。通过文档ID找到其内容。
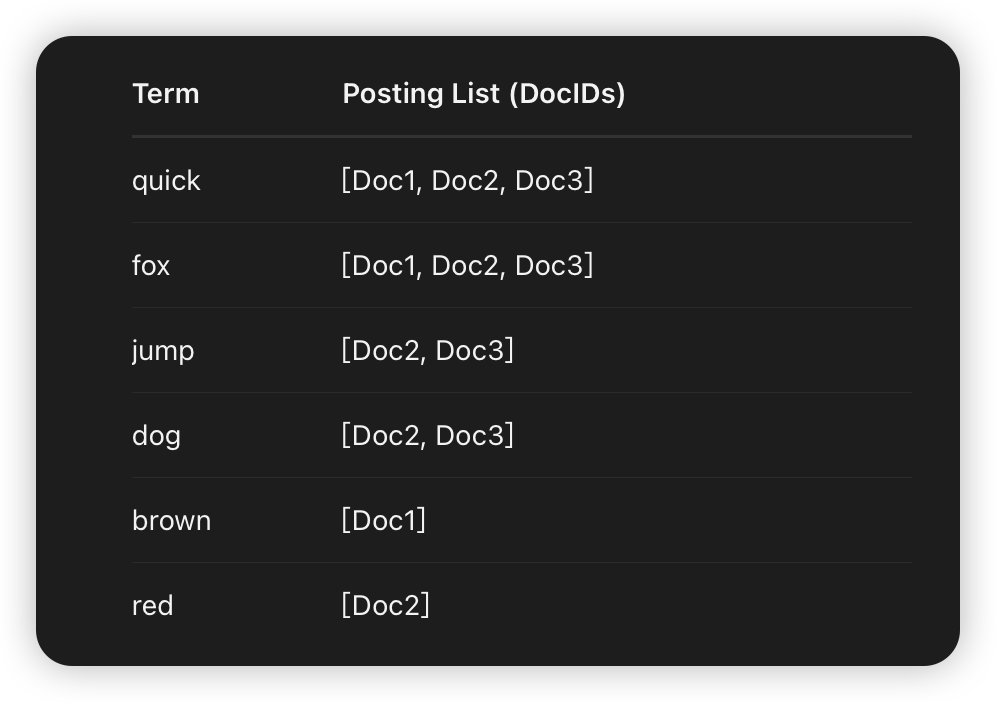
(2)倒排索引:词条 (Term) -> 文档列表。通过内容中的词条,快速找到包含它的所有文档ID。
(2)构建过程:
(1)文本分析 (Analysis):将原始文本(如 “The quick brown fox”)通过分析器 (Analyzer) 处理。
1-组成:Character Filters-> Tokenizer-> Token Filters。
2-结果:生成标准化的词条 (Terms)(如 “quick”, “brown”, “fox”)。这个过程称为归一化,包括转小写、去除停用词(a, the)、提取词干(running -> run)等。
(2)创建映射:每个词条被映射到包含它的文档列表(Posting List)。这个列表不仅包含文档ID,还可能包含词频(TF)、位置(Position)、偏移量(Offset)等信息,用于计算相关性和执行短语查询。
(3)示例
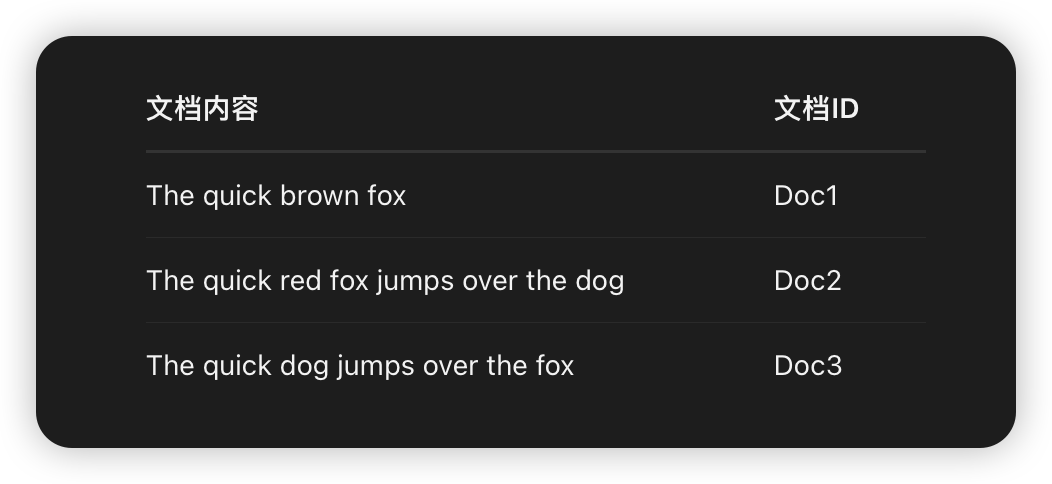
倒排索引:
【2】近实时 (NRT) 搜索的实现
Lucene 索引一旦写入磁盘就是不可变的。这种设计简化了并发控制,易于缓存,但不利于实时更新。ES 通过以下方式实现近实时性:
(1)内存缓冲区 (In-memory Buffer):新写入的文档首先存放在这里。
(2)Translog (事务日志):所有操作都会被追加写入到磁盘上的 Translog 中,用于防止数据丢失(类似于数据库的 WAL)。
(3)Refresh:默认每 1 秒,将内存缓冲区中的文档创建一个新的、不可变的 Lucene 段 (Segment) 并放入文件系统缓存(OS Cache)。此时文档可以被搜索到。这是 “近实时” 的来源。
(4)Flush:默认每 30 分钟或 Translog 达到一定大小时,执行一次 Flush:
1-将文件系统缓存中的所有段持久化到磁盘。
2-清空 Translog。
3-执行 fsync,确保数据安全。
【3】段合并 (Segment Merging)
随着 Refresh 的进行,会产生大量的小段,降低性能。ES 会在后台自动进行段合并:
(1)将多个小段合并成更大的段。
(2)合并过程中会清除被标记为删除的文档。
(3)合并后的新段会被写入磁盘,旧的段被删除。
【二】架构设计
【1】 集群 (Cluster)、节点 (Node) 与角色
(1)集群:一个或多个节点的集合,共同持有全部数据。
(2)节点:集群中的一个服务器实例,存储数据并参与集群的索引和搜索。
(3)节点角色(ES 7.x 后可配置):
1-Master-eligible Node:负责管理集群状态(如创建/删除索引、分配分片)、维护节点信息。一个集群只有一个活跃的 Master(通过选举产生)。
2-Data Node:存储数据,执行与数据相关的操作(CRUD、搜索、聚合)。这是计算和IO密集型角色。
3-Ingest Node:可以在索引前对文档进行预处理(如数据提取、转换)。
4-Coordinating Node(默认所有节点都是):接收客户端请求,将请求路由到正确的节点,收集结果并返回。生产环境中可设置独立的仅协调节点来均衡负载。
【2】分片 (Shard) - 分布式的基础
(1)主分片 (Primary Shard):
1-每个文档都存储在一个主分片中。
2-索引创建时指定,后续不可更改(除非重建索引)。
3-数据水平扩展的根本。
(2)副本分片 (Replica Shard):
1-每个主分片的拷贝。
2-提供高可用性:主分片挂掉后,副本可以提升为主分片。
3-提供读扩展:所有读请求(搜索、查询)都可以由主分片或副本分片处理。
【3】写流程
(1)客户端发送写请求到协调节点。
(2)协调节点通过文档 _id路由(默认 _id % number_of_primary_shards)到对应的主分片所在的数据节点。
(3)该数据节点在主分片上执行写入操作(写入内存缓冲区和 Translog)。
(4)操作被并行地同步到所有副本分片。(只有在所有副本分片都确认后,主分片才向客户端返回成功。这是 consistency 的保证,可配置)。
(5)主分节点报告成功给协调节点,协调节点再返回给客户端。
【4】读流程 (Search)
(1)客户端发送搜索请求到协调节点。
(2)协调节点将请求广播到所有相关分片(主分片或副本分片)的一个副本上。
(3)每个分片在本地执行查询(在各自的倒排索引中查找),并创建一个优先级队列(根据相关性评分排序),将结果(from+size条文档的 _id和 score)返回给协调节点。
(4)协调节点合并和排序所有分片的结果,生成一个全局排序列表。
(5)协调节点根据全局排序列表中的 _id,去相关分片 Fetch 实际的文档内容。
(6)协调节点将最终结果返回给客户端。
Query then Fetch:上述过程称为两阶段查询,可以有效减少网络数据传输。
【三】性能分析、优化与权衡
Elasticsearch 的性能取决于 计算(CPU)、内存(Memory)、磁盘 I/O(Disk I/O)和网络(Network) 的平衡。
【1】写性能优化
(1)目标:提高吞吐量(Indexing Rate)。
(2)方法:
1-批量写入 (Bulk API):减少网络往返次数和创建段的开销。
2-调整 Refresh Interval:增大 refresh_interval(如到 30s),减少 Refresh 产生的段数量,降低段合并压力。适用于大批量导入场景。
3-禁用 Refresh/Replica:初始导入大量数据时,可暂时禁用刷新 (refresh_interval = -1) 和设置副本数为 0,导入完成后再恢复。
4-使用自动生成的 ID:使用显式 _id需要检查冲突,使用自动生成 _id可以跳过这一步。
5-硬件:使用 SSD 硬盘。写性能严重依赖磁盘 I/O 速度。
【2】读性能(搜索)优化
目标:降低延迟(Latency),提高查询速度(QPS)。
方法:
(1)优化 Mapping:
(1)避免使用 nested类型(每个嵌套文档都是独立的隐藏文档,查询开销大)。
(2)谨慎使用 fielddata: true(用于聚合和排序的文本字段,会消耗大量堆内存)。
(2)优化查询 DSL:
(1)避免深度分页:from + size方式越深越慢。使用 search_after或滚动查询 Scroll API。
(2)使用过滤器 (Filter) 上下文:Filter 查询会被缓存,不计算分数,效率远高于计算分数的 Query 上下文。
(3)避免通配符前缀查询 (wildcard: text) ,它们会遍历所有词条。
(3)硬件:
为文件系统缓存(OS Cache) 分配足够的内存。ES 的性能极度依赖缓存。官方建议堆内存(Heap)不超过物理内存的 50%,其余留给 Lucene 做文件系统缓存。
(3)预热:
对于不常变化的索引,使用 Index Warmers预先加载(缓存)常用的查询结果。
【3】集群设计与容量规划
(1)分片策略:
1-分片大小:建议每个分片大小在 10GB - 50GB 之间。太小则元数据开销大;太大则恢复和再平衡慢。
2-分片数量:分片数最好等于或略高于集群节点数,以便均衡分布。避免单个索引分片过多。
(2)热点问题:确保数据均匀分布。如果默认路由(_id)导致数据倾斜,需使用自定义路由。
(3)脑裂问题 (Split-brain):在分布式 Master 选举中,网络分区可能导致出现多个 Master。通过配置 discovery.zen.minimum_master_nodes(在 7.x 之前)或基于投票的配置(7.x 之后)来避免。通常设置为 (master_eligible_nodes / 2) + 1。
【4】性能瓶颈识别
(1)CPU 瓶颈:常见于复杂的搜索、脚本计算、高聚合分析。
(2)内存瓶颈:
(3)堆内存不足:导致 GC 频繁,甚至 OOM。
(4)文件系统缓存不足:导致查询需要从磁盘读取,延迟急剧上升。
(5)磁盘 I/O 瓶颈:段合并、写入 Translog、Fetch 阶段数据读取时发生。表现为写入速度慢或查询慢。
(6)网络瓶颈:节点间数据复制(Recovery)、跨分片查询时发生。