微软研究院最新tts模型VIBEVOICE解析
1. 引言:长篇多人对话——TTS的“圣杯”挑战
传统的TTS系统通常通过拼接单个合成的句子来生成长音频。这种方法存在诸多问题:
- 韵律不连贯:句子间的停顿、语调和节奏难以自然衔接。
- 缺乏内容感知:模型无法根据上下文调整说话风格和情感。
- 难以处理多人对话:自然的说话人轮转(turn-taking)、抢话等动态难以模拟。
- 稳定性差:在长序列生成中容易出现错误累积,导致音质下降或生成失败。
VIBEVOICE旨在通过一个统一的、端到端的框架来解决这些问题,其核心目标是实现可扩展的、高质量的长篇多人语音合成。
2. VIBEVOICE架构概览:LLM驱动的下一Token扩散
VIBEVOICE的架构非常简洁,其核心思想借鉴了LatentLM中提出的下一Token扩散框架,将LLM和扩散模型无缝地结合在了一起。
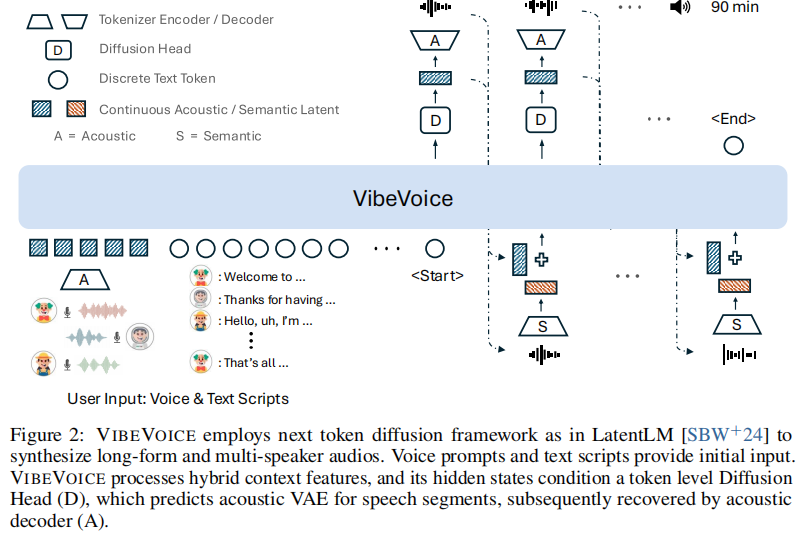
(VIBEVOICE的推理流程。用户输入语音提示(Voice Prompts)和文本脚本(Text Scripts),这些