自由学习记录(89)
LearnOpenGL - Coordinate Systems
要将顶点坐标从视图空间转换为裁剪空间,我们定义一个称为投影矩阵的矩阵,该矩阵指定了坐标的范围,例如每个维度上的-1000和1000。然后,投影矩阵将此指定范围内的坐标转换为归一化设备坐标(-1.0,1.0)(不是直接转换,中间有一个称为透视除法的步骤)。所有超出此范围的坐标将不会映射到-1.0和1.0之间,因此将被裁剪。使用投影矩阵中指定的这个范围,坐标为(1250,500,750)的坐标将不可见,因为x坐标超出了范围,因此被转换为NDC中的坐标高于1.0,因此被裁剪。
裁剪(clipping)是光栅化阶段的固定功能在做
流水线里谁干了什么(精简版)
-
顶点着色器把位置变到齐次裁剪空间,写到
SV_Position/gl_Position。Stack Overflow+1 -
光栅化/栅格器读取这些裁剪空间坐标,对视锥体做裁剪(完全在外就丢,穿过就切三角形),然后再做 w 分量除法(透视除法)和视口变换,再决定调用像素着色器的哪些像素。Microsoft LearnMicrosoft GitHubMDN Web Docs
Microsoft 的 Direct3D 文档直接写明:栅格器假定输入就是裁剪空间,执行裁剪、透视除法和视口缩放/偏移。Microsoft GitHub
概念不要混了:
-
裁剪(clipping):GPU 光栅化阶段对单个图元做的事。Microsoft Learn
-
(物体级)视锥剔除 / 遮挡剔除(culling):多在CPU/引擎侧做,用来减少提交到 GPU 的物体;Unity 的遮挡剔除是引擎特性。Unity Documentation
-
你在片元里
clip()/discard只是丢像素,已经过了光栅化,不能替代硬件裁剪。
如果您正在手动使用裁剪空间(Z深度),您可能还想通过使用以下宏来抽象平台差异:
float clipSpaceRange01 = UNITY_Z_0_FAR_FROM_CLIPSPACE(rawClipSpace);
Note: This macro does not alter clip space on OpenGL or OpenGL ES platforms, so it returns within “-near”1 (near) to far (far) on these platforms.
注意:此宏在OpenGL或OpenGL ES平台上不会更改裁剪空间,因此在这些平台上返回“-near”1(近)到远(far)。
GL.GetGPUProjectionMatrix() returns a z-reverted matrix if you are on a platform where the depth (Z) is reversed. However, if you’re composing from projection matrices manually (for example, for custom shadows or depth rendering), you need to revert depth (Z) direction yourself where it applies via script.
GL.GetGPUProjectionMatrix() 返回一个z反转的矩阵,如果您所在的平台深度(Z)被反转。 但是,如果您是手动组合投影矩阵(例如,用于自定义阴影或深度渲染),您需要通过脚本自行反转深度(Z)方向。
“平台使用 clip space 有差异”,指的是不同图形 API 对“裁剪空间/归一化设备坐标(NDC)的 Z 定义不一样。
顶点阶段你把位置乘到 clip space 就行;平台差异/反转 Z 这些“额外的东西”,Unity 会在投影矩阵和内置宏里替你兜住,只有当你手动用到 Z(自己算雾/深度、采样深度图、写 SV_Depth、自建投影矩阵)时才需要管。
仅当你手动碰 Z 时,才需要用 Unity 提供的宏/函数来“抽象平台差异”:
-
采样深度纹理 / 需要线性化
用Linear01Depth/LinearEyeDepth,内部已处理 D3D/GL 范围和反转 Z 的方向。Unity DocumentationUnity User Manual -
自己用“裁剪空间的 z/w”做运算(比如雾、顶点偏移)
用UNITY_Z_0_FAR_FROM_CLIPSPACE(rawClipSpace)把裁剪空间 Z 统一成 0..1 的语义(在 GL/ES 上它会按规范返回对应范围)。Unity Documentation+1 -
你要写入/解读“反转 Z”方向
用宏UNITY_REVERSED_Z做分支,或在取深度后z = 1 - z(Unity 文档示例)。Unity Documentation -
你在脚本里自己构投影矩阵(自定义阴影/深度通道等)
先按数学意义构好投影,再用GL.GetGPUProjectionMatrix转成“GPU 实际使用”的矩阵,确保和 shader 里的UNITY_MATRIX_P一致。Unity Documentation
这么一看,,clip space是一个中间的space,,vert里要返回clip pos
view space到clip space需要矩阵,这个矩阵可以自定义
不同 的平台,对里面的数据要求不同,有坐标范围的,z深度的范围的,这些东西是unity自己写了函数让我们调用,从而去统一各个平台的-----shader文件效果?
p矩阵可以自定义,,其他的矩阵应该也可以吧
我默认不管的情况下,想使用深度图,取里面的值,,这个操作应该不用很关注这些平台的差异吧,不对,,应该还是要关注的,换句话说,我觉得这些东西都太空了,,没有过度记忆的必要,,应该差不多就放掉----
所以目前了解到的就是,shader文件里用的矩阵,是unity的cs文件传过去的
shader文件会交给不同的dx或者OpenGL,所以问题在于,graphic API对于shader文件的解读是不同的
unity传给shader文件里的矩阵值,在这个传的过程中,需要注意的就是unity对于这个P矩阵的计算,基于的是某一个平台的,自己没有自动调节(或者说记住这里可能没有自动调节,下次出问题了,记得这一块是可以查验的)
重点新认识是---graphic API只和.shader文件有关,,其余的c#脚本都可以当做unity写的,而c#可以传值给.shader文件,在second layer上影响graphic API对于.shader文件的解读
图形 API 不只“执行 .shader”。它还负责整个管线的固定功能 & 状态:栅格化、深度/模板/混合、采样器、RT 绑定、常量/纹理绑定等。C#(Unity)在每帧不停地设置这些 API 状态并把常量传给着色器;驱动把 HLSL/GLSL 编译成硬件码去跑。3D Game Engine ProgrammingMicrosoft Learn
实操记三条就够
-
顶点位置:
UnityObjectToClipPos/UNITY_MATRIX_MVP;无需关心平台差异。documentation-service.arm.com -
读相机深度:采样
_CameraDepthTexture后用Linear01Depth/LinearEyeDepth,别手算。Unity Documentation -
自建投影矩阵(脚本):最后过
GL.GetGPUProjectionMatrix()再设给相机,保证与着色器一致。Unity Documentation


-
D3D/Metal/Vulkan 规定 NDC 的 z 在 [0,1];OpenGL/ES 的 z 在 [-1,1];裁剪规则也随之不同(GL 是
-w≤x,y,z≤w,D3D 的 z 是0≤z≤w)。这些是标准写死的。Unity能做的是在投影矩阵与宏里帮你适配,而不是改标准。Microsoft Learn+1learnopengl.comStack Overflow -
Unity 还在多数 D3D/Metal 等平台开启了反转 Z(near=1, far=0)来提升深度精度;当你需要手工用到深度时,才会看见相关宏(
UNITY_REVERSED_Z)和函数。Unity Documentation
实操上,Unity 已经把“平台差异”折到
UNITY_MATRIX_P/UNITY_MATRIX_MVP、以及Linear01Depth/LinearEyeDepth等 helper 里了;正常写法基本感觉不到。Unity Documentation+1
-
Clip space 是顶点着色器输出的齐次坐标(还没除以 w);
-
NDC 是光栅器自动做透视除法后的结果(已除以 w),然后再做视口映射。Microsoft GitHubcarmencincotti.com
算是白看,,效果很差
这里也不是一下看懂的,,太超前了吧
clip是raw投影,什么都没做,xyzw都正常,没有齐次除法
NDC才是最终的判断,dx是0到1的z
OpenGL是-1到1的z
xxxxxxxxxxxxxxxxxxxx
深度 + 逆 ViewProj 反投影回世界坐标”的常规套路
喂给矩阵的 Z 值必须是 NDC/设备深度的正确区间(处理好 D3D/GL 与 Reversed-Z 的差异);
float d = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv_depth);
float4 H = float4(i.uv*2-1, d*2-1, 1); // <-- 直接 z*2-1 假定了 D3D 风格
float4 D = mul(_CurrentViewProjectionInverseMatrix, H);
float4 worldPos = D / D.w;
_CameraDepthTexture 里拿到的是设备深度,其范围/方向会随平台变化(D3D/Metal/Vulkan:z∈[0,1];OpenGL/ES:z∈[-1,1];很多平台还用了反转 Z:近=1 远=0)。不能一律 z*2-1。
xxxxxx
先到视空间,再到世界
完全回避了“不同 API 的 NDC z 差异”,用 Unity 提供的 _ZBufferParams 把深度直接线性化到视空间 z(眼空间前向正距),再用 invP 还原射线比例。
#include "UnityCG.cginc"fixed4 frag (v2f i) : SV_Target
{float rawDepth = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, i.uv_depth);// 1) 线性化成视空间深度(单位:从相机出发的正距离)float viewZ = LinearEyeDepth(rawDepth, _ZBufferParams); // 平台无关// 2) 从屏幕点构造视空间射线方向(用 invP)float4 clip = float4(i.uv * 2.0 - 1.0, 1.0, 1.0);float3 viewDir = mul(UNITY_MATRIX_I_P, clip).xyz; // 未归一,z 分量与投影一致// 3) 沿射线按 z 比例求视空间位置float3 viewPos = viewDir * (viewZ / viewDir.z);// 4) 视→世float3 worldPos = mul(unity_CameraToWorld, float4(viewPos, 1)).xyz;// 5) 上一帧投影到 NDCfloat4 prevH = mul(_PreviousViewProjectionMatrix, float4(worldPos,1));float2 prevNDC = prevH.xy / prevH.w;float2 currNDC = i.uv * 2.0 - 1.0;float2 velocity = (currNDC - prevNDC) * 0.5;// 6) 同上,按速度做采样float2 uv = i.uv;float4 c = tex2D(_MainTex, uv);uv += velocity * _BlurSize;[unroll] for (int it = 1; it < 3; ++it, uv += velocity * _BlurSize)c += tex2D(_MainTex, uv);c *= 1.0/3.0;return fixed4(c.rgb, 1.0);
}
世界坐标的 w 应该为 1,所以需要做除法。---存在0.95这样的小误差,补除才精确
在图形学管线中,经过矩阵变换(如视图投影逆矩阵)后,得到的是齐次坐标(homogeneous coordinates),此时 w 分量不一定是 1。
要得到真正的三维世界坐标,需要除以 w,即:
float4 worldPos = mul(_CurrentViewProjectionInverseMatrix, H);
worldPos /= worldPos.w; // 归一化,得到实际世界坐标
这样 worldPos.xyz 才是正确的世界空间位置。
这是标准的透视除法(perspective divide)步骤。
xxxxx
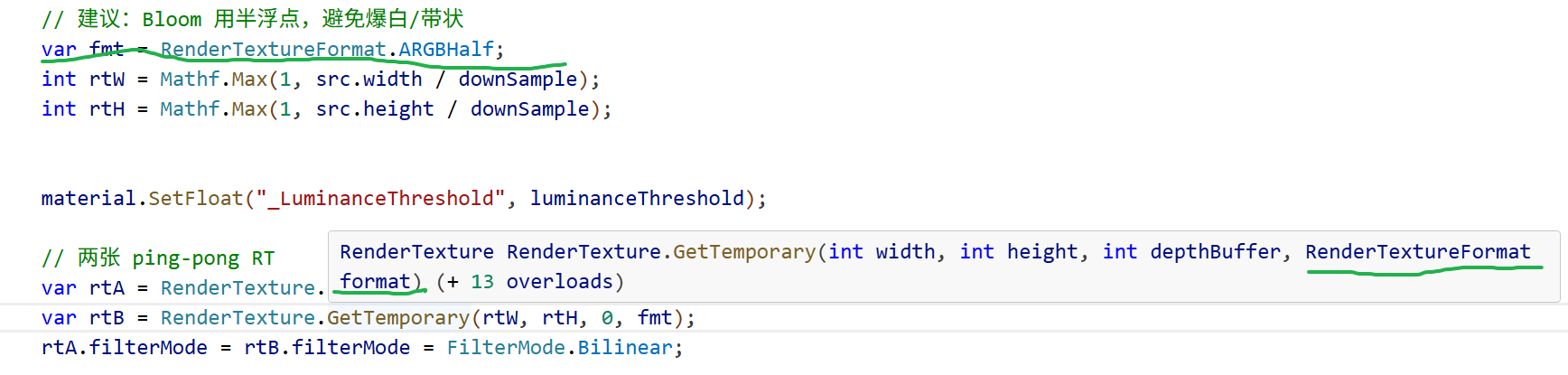
var fmt = RenderTextureFormat.ARGBHalf;
然后把它传进 RenderTexture.GetTemporary(rtW, rtH, 0, fmt),作用是:让整条 Bloom 的中间 RT 用半浮点 HDR 精度,避免 8bit LDR 的夹断和条带。核心影响:
动态范围:
ARGB32(默认 8bit)会把颜色钳到 [0,1],高亮信息被截断,Bloom 的能量和层次丢失,很容易“死白”。
ARGBHalf(16bit/通道)能保存 >1 的亮度与细节,提亮/上采样时更自然,减少 banding。
精度 & 观感:半浮点在反复下采样 / 模糊 / 累加时,误差更小、过渡更平滑。
代价:显存/带宽↑(ARGBHalf ≈ 8 bytes/px;ARGB32 ≈ 4 bytes/px),但对 Bloom 这类在降分辨率下运行的 pass,通常完全可接受。
平台兼容:大多数平台都支持 ARGBHalf。更轻的 HDR 选项还可以是 RGB111110Float(更省内存但无 Alpha)。
xxxxx
一个应该完善的写法,对于 motion blur拿上一帧的vp矩阵
直接用 camera.projectionMatrix。在不同图形 API(D3D/GL/Metal,正反 Z、NDC z 范围)下,GPU 实际用到的投影矩阵和 C# 看到的可能不同。建议用
GL.GetGPUProjectionMatrix(camera.projectionMatrix, /*renderIntoTexture:*/ false)
来构造 VP / invVP,避免平台偏差。
-
public Camera camera会和Component.camera(虽已过时)混淆,建议改名Cam。 -
每帧用字符串
SetFloat("_BlurSize")会有查找开销,建议用Shader.PropertyToID缓存 property id。 -
CheckShaderAndCreateMaterial每帧赋值可以,但最好只在需要时创建,OnDisable时销毁。
using UnityEngine;
using System.Collections;public class DepthMotionBlur : PostEffectsBase
{public Shader motionBlurShader;private Material motionBlurMaterial = null;public Material material{get{motionBlurMaterial = CheckShaderAndCreateMaterial(motionBlurShader, motionBlurMaterial);return motionBlurMaterial;}}private Camera myCamera;public Camera camera{get{if (myCamera == null){myCamera = GetComponent<Camera>();}return myCamera;}}[Range(0.0f, 1.0f)]public float blurSize = 0.5f;private Matrix4x4 previousViewProjectionMatrix;void OnEnable(){camera.depthTextureMode |= DepthTextureMode.Depth;previousViewProjectionMatrix = camera.projectionMatrix * camera.worldToCameraMatrix;}void OnRenderImage(RenderTexture src, RenderTexture dest){if (material != null){material.SetFloat("_BlurSize", blurSize);material.SetMatrix("_PreviousViewProjectionMatrix", previousViewProjectionMatrix);Matrix4x4 currentViewProjectionMatrix = camera.projectionMatrix * camera.worldToCameraMatrix;Matrix4x4 currentViewProjectionInverseMatrix = currentViewProjectionMatrix.inverse;material.SetMatrix("_CurrentViewProjectionInverseMatrix", currentViewProjectionInverseMatrix);previousViewProjectionMatrix = currentViewProjectionMatrix;//previous frame matrix Graphics.Blit(src, dest, material);}else{Graphics.Blit(src, dest);}}
}
CommandBuffer 画一张“人物 Mask 贴图”(也不加相机)
目标:在 BeforeImageEffects 用命令缓冲只把人物渲到一张 R8 mask(=1 表示人物),后处理读这张贴图来限制描边。
优点:不用改人物材质;兼容性强。
代价:多一次只对人物的绘制(通常很便宜)。
-
能改人物材质 → Stencil(方案 A)最简单、最快。
-
不能动人物材质 → CommandBuffer Mask(方案 B)最稳。
-
URP:不想写代码可用 Render Objects Renderer Feature 把“渲染层=人物”的对象输出到一张 R8 Mask,再在自定义后处理里读这张 Mask——同样无需额外相机。
-
只改 OnRenderImage 不够:后处理阶段已经是“屏幕像素”,不知道哪些像素来自人物;必须提前做一次标记(Stencil 或 Mask RT)。
-
描边核 & 边界:我们只是限制合成区域;你的边缘检测仍用全场景深度/法线,这样人物与背景的深度/法线落差会在“人物内侧”产生轮廓,视觉上正好是“描在人上”。
-
多相机/UI:如果有叠加相机/Canvas,注意它们可能覆盖或清掉模板/Mask;把命令缓冲挂在最终做后处理的那台相机上。
我的想法是,通过skinrenderer对象,获取场景中的人物材质
然后人物材质获取到了,,就没有然后了,,靠shader文件做不到啊,跨材质去得到场景里的信息
我你想要的就是当人物的材质渲染完之后,,渲染完的信息交给c#,此时就被存着,直到后处理,用这个,,,等等,这个存的东西就是commandbuffer啊
那问题就是我要怎么在人物的材质渲染完之后给出信息到buffer里面呢,,不干涉人物材质,,,对,,,c#里面有类似的方法,,可以做
正确做法是:在相机的某个渲染阶段,由 C# 主动再绘制一次(只绘制人物),把“人物覆盖的像素”写进一块你自己创建的 GPU 纹理(RT)。这块 RT(或 stencil)就是你说的“存着等后处理用的 buffer”。整个过程不需要改人物原材质,也不需要加新相机。
思路(一步到位)
-
时机:把命令缓冲挂在
CameraEvent.BeforeImageEffects。这一步发生在所有场景几何(含透明)画完之后、你的OnRenderImage之前。 -
动作:用
CommandBuffer.DrawRenderer(r, overrideMat, submeshIndex)覆盖材质再画人物一次——但颜色不是画到屏幕,而是画到你自己的 R8 mask RT(或只写 stencil)。 -
深度:把 color 目标设为 mask RT,depth 目标仍用相机的深度,配合
ZTest LEqual,这样只把可见的那部分人物写进 mask。 -
消费:在
OnRenderImage的后处理里采样_OutlineMask,只在人像区域输出描边。
-
LODGroup 的原理
-
Unity 在运行时只会启用(enable)LODGroup 里当前选中的 LOD 的 Renderer;其它 LOD 的 Renderer 会被禁用(
enabled = false)。 -
所以同一帧内,人物只会有一个 LOD(比如 LOD0 或 LOD1)真正处于渲染状态。
-
-
命令缓冲的
DrawRenderer行为-
DrawRenderer本质是:只要你传入的 Renderer 有效,它就会画出来,不管 LODGroup 的状态。 -
但如果 Renderer 的
enabled = false,它不会被 Unity 的正常渲染管线绘制。你自己在 CommandBuffer 里强行调用时,也要小心避免画到被禁用的 LOD。
-
sampler2D _OutlineMask;
// ...
float mask = tex2D(_OutlineMask, i.uv).r;
if (mask < 0.5) discard; // 或 edge *= step(0.5, mask);
“人物材质渲染完之后的信息”就被C# 下发的命令缓冲“接住”写进了 _OutlineMask,并一直有效到你的 OnRenderImage。整个过程不读取 GPU→CPU,全在 GPU 内完成。
Shader.PropertyToID("_OutlineMask") 是什么、为什么要这样写?
-
它把属性名(字符串)转换成一个整型 ID。
Unity 在底层用整型查询 Shader 属性更快、更省 GC(不反复做字符串哈希/比较)。 -
CommandBuffer 系列 API 需要“名字ID”来创建/绑定 RT。
GetTemporaryRT/SetGlobalTexture/SetRenderTarget等很多命令都不是直接收RenderTexture对象,而是收“一个 nameID”。所以我们先把"_OutlineMask"变成 ID,后面所有命令都用这个 ID 指代同一块临时 RT。
-
把它声明成
static readonly的原因:
只做一次名字→ID 的转换,避免每次 OnEnable/每帧都重新哈希,同时保证全程用的都是同一个 ID,不会写错到别的属性上。
一句话:
PropertyToID= 名字到“句柄”的映射。_OutlineMask这个 int 就是你在 CB 里指向那张临时 Mask 纹理的“钥匙”。
cb.SetRenderTarget(_OutlineMask, BuiltinRenderTextureType.CameraTarget);
是 SetRenderTarget(color, depth) 的重载:
-
color:把“颜色目标”设为
_OutlineMask(我们刚GetTemporaryRT得到的那张 R8 纹理)。 -
depth:把“深度目标”设为当前相机的深度缓冲(这里用的是
CameraTarget,等价于“这台相机正在用的深度 RT”)。
-
为什么要把深度设成相机的?
我们画 Mask 时用ZTest LEqual、ZWrite Off,要借用相机已经算好的深度,这样只把可见的人物像素写到 Mask(被前景挡住的部分不会写进去)。
更稳的写法(避免 MSAA 不匹配):把第二个参数写成
BuiltinRenderTextureType.Depth,并且让临时 RT 的 MSAA 与相机一致(见下方“推荐改法”)。
cb.ClearRenderTarget(false, true, Color.black);
-
这是 ClearRenderTarget(clearDepth, clearColor, backgroundColor):
-
false:不清深度(我们要保留相机的深度来做 ZTest)。 -
true:清颜色(把 Mask 清为纯黑)。 -
Color.black:清到黑;之后人物像素会把 R 通道写成 1。
-
还有一个扩展重载可以指定清深度的数值与 stencil 值;我们这里不用,默认即可。
一下子掉到 1–2 帧,主因几乎肯定是命令缓冲用法的问题:你在 Update() 里每帧都在
-
重复
AddCommandBuffer到相机(会把同一个 CB 挂上去很多次,随后每帧都会执行 N 次) -
给同一个 CB 一直追加命令(没
Clear(),命令列表越积越大)
这两个一叠加,几秒钟就能把一帧塞进成百上千条命令,自然爆掉。Unity 官方和开发者讨论里都强调:CB 只创建/添加一次,之后每帧 Clear() 再重录命令,而不是每帧新加(或追加)一个 CB。Unity DocumentationUnity Discussion+1
把深度目标设成 BuiltinRenderTextureType.CameraTarget,在某些设置(尤其开 MSAA)会导致目标不匹配、状态混乱,进一步拖慢甚至报错。应当绑定到相机的深度缓冲并让临时 RT MSAA 与相机一致。Unity Documentation
GetTemporaryRT 最好配对 ReleaseTemporaryRT。没显式释放 Unity 也会在相机渲染后清掉,但你现在同一帧执行了 N 次 CB,就会 N 次分配,等于制造分配风暴。Unity Documentation+1
-
CommandBuffer 本身只是“录好的命令列表”,不绑定谁也不会自动执行。
-
在 内置管线(Built-in) 里,最常见做法是把它挂到相机或灯光上,让引擎在指定阶段执行:
camera.AddCommandBuffer(CameraEvent, cb)/light.AddCommandBuffer(LightEvent, cb)。Unity Documentation+2Unity Documentation+2 -
CameraEvent就是执行时机(例如BeforeImageEffects会在OnRenderImage之前执行、AfterSkybox在画完天空盒之后等)。Unity Documentation
https://docs.unity3d.com/ScriptReference/MonoBehaviour.OnPreRender.html
-
它什么时候被调用?
在 相机开始渲染场景之前,并且是在该相机完成剔除(culling)之后调用。Unity Documentation+1 -
会不会每帧调用?
只要这台相机当帧要渲,就会调用一次;如果场景里有多台相机、或一次渲染包含左右眼/反射等,多次调用也属正常(每台相机各调用一次)。Unity Documentation+1 -
脚本必须挂在哪?(内置管线)
在 Built-in Render Pipeline 下,只有当脚本挂在带Camera组件的同一个 GameObject 上时,OnPreRender才会被调用;否则用不到这个回调。若想不挂在相机上也收到“相机将要渲”的事件,可以订阅Camera.onPreRender委托。Unity Documentation
-
拿到哪些状态?
调用时 相机的 render target / 深度纹理还没设置好,如果你需要在更靠后的位置访问或操作这些缓冲,应该改在更晚的阶段执行(例如通过 CommandBuffer 安排在后面)。Unity Documentation -
URP/HDRP(SRP)里怎么办?
在 SRP 中不要依赖OnPreRender;推荐改用RenderPipelineManager.beginCameraRendering(可在任何脚本里订阅,每帧每台相机渲前触发)。Unity DocumentationUnity Documentation
// 和相机 MSAA 一致
int msaa = (cam.allowMSAA && QualitySettings.antiAliasing > 1)
? QualitySettings.antiAliasing : 1;
这行代码是在把你临时的 Mask 贴图做成“和相机一样的 MSAA 采样数”,这样后面 SetRenderTarget(color=你的Mask, depth=相机深度) 才不会颜色/深度采样数不匹配——一不匹配,轻则自动做 resolve 变慢,重则 Unity 直接报错并跳过渲染。
-
相机开了 MSAA 时,相机的深度缓冲也是多重采样。你把一个非 MSAA 的颜色 RT 绑到一个 MSAA 的深度上(或反过来),很多平台/管线会报:
“Color and Depth buffer MSAA flags doesn’t match, no rendering will occur.”(颜色和深度的 MSAA 标志不一致,不会渲染)Unity Discussion -
即便能“勉强跑”,Unity/驱动也可能隐式 resolve,导致每次绘制都多一步,帧时间爆掉。Unity Discussion
msaa = (cam.allowMSAA && QualitySettings.antiAliasing > 1) ? QualitySettings.antiAliasing : 1;
-
这句只是把相机当前的采样数(2x/4x/8x)拿来给你的临时 RT。
-
GetTemporaryRT的文档就有 antiAliasing 参数,默认是不抗锯齿(1x),你需要手动指定和相机一致。Unity Documentation
能不管 MSAA 吗?
-
可以,但前提是相机没开 MSAA(
cam.allowMSAA=false或项目QualitySettings.antiAliasing=0)。这时把antiAliasing设成 1 就没事。 -
相机开了 MSAA 就别忽略:要么匹配采样数(上面那行代码),要么改用Stencil 方案(只写模板不分配颜色 RT,天然规避 MSAA 匹配问题)。
-(URP/HDRP 旁注)某些模式下 TAA 和 MSAA 互斥,如果你切到 TAA,本来就不会用 MSAA;这时 antiAliasing=1 即可。Unity Documentation+1
长期方案:让你的 Mask 着色器支持 skinning
保持 DrawRenderer(r, overrideMaskMat, i),但把 overrideMaskMat 的 shader 换成支持 SkinnedMesh 的版本。要点:
-
顶点输入需要包含 BLENDWEIGHTS / BLENDINDICES 这些语义,并按权重把骨骼矩阵混合后再变换到裁剪空间;Unity 的 GPU skinning 就是这么在顶点着色器里完成的。Unity Documentationdocumentation-service.arm.com
-
如果用 URP/HDRP/ShaderGraph,Unity 在不支持 skinning 的 shader 上会直接报:“Shader … does not support skinning”,并提示使用支持 Linear Blend Skinning 的节点/路径。你的覆写 shader 也需要具备同等能力。Unity Discussions+1
简化建议:
先用 A 方案确认“问题就是 skinning 缺失”。一旦 BakeMesh 版本能跟着动,就坐实结论。
再决定是否投入时间写一个“仅写 R 通道、支持 skinned 顶点变换”的轻量 shader;或者继续用 BakeMesh(通常一个主角开销不大)。
CommandBuffer.GetTemporaryRT 创建在 CB 内部 的临时 RT,然后在 BeforeImageEffects 执行完 就被释放 了;你的后处理在 CB 之外采样 _OutlineMask,此时已经没了 ⇒ 看起来“没有红色”。
解决:不要用 GetTemporaryRT 管这个贴图;改用持久化 RenderTexture 成员,
立刻定位的小技巧
-
关掉深度测试验证是否“画到了 RT”:
把overrideMaskMat的 shader 临时改成ZTest Always,如果这时能看到整个人(甚至穿透背景),说明目标/采样都通了,之前是深度绑定的问题。再改回LEqual。 -
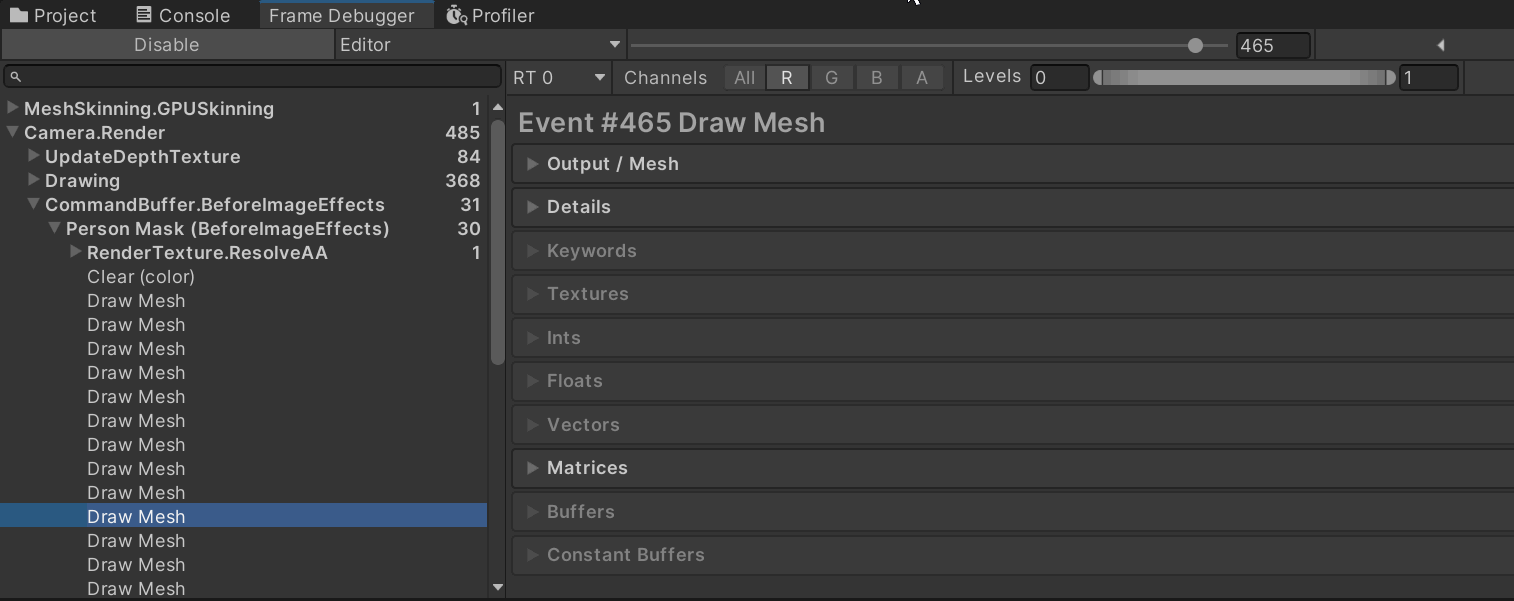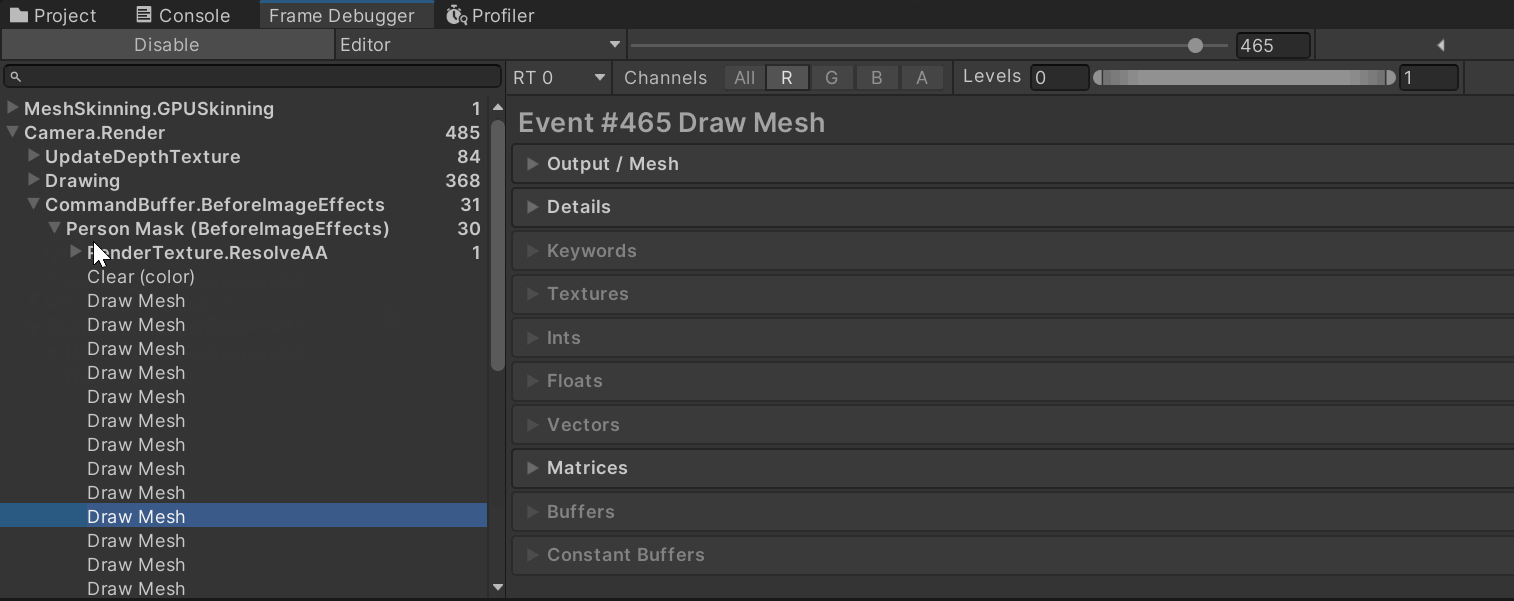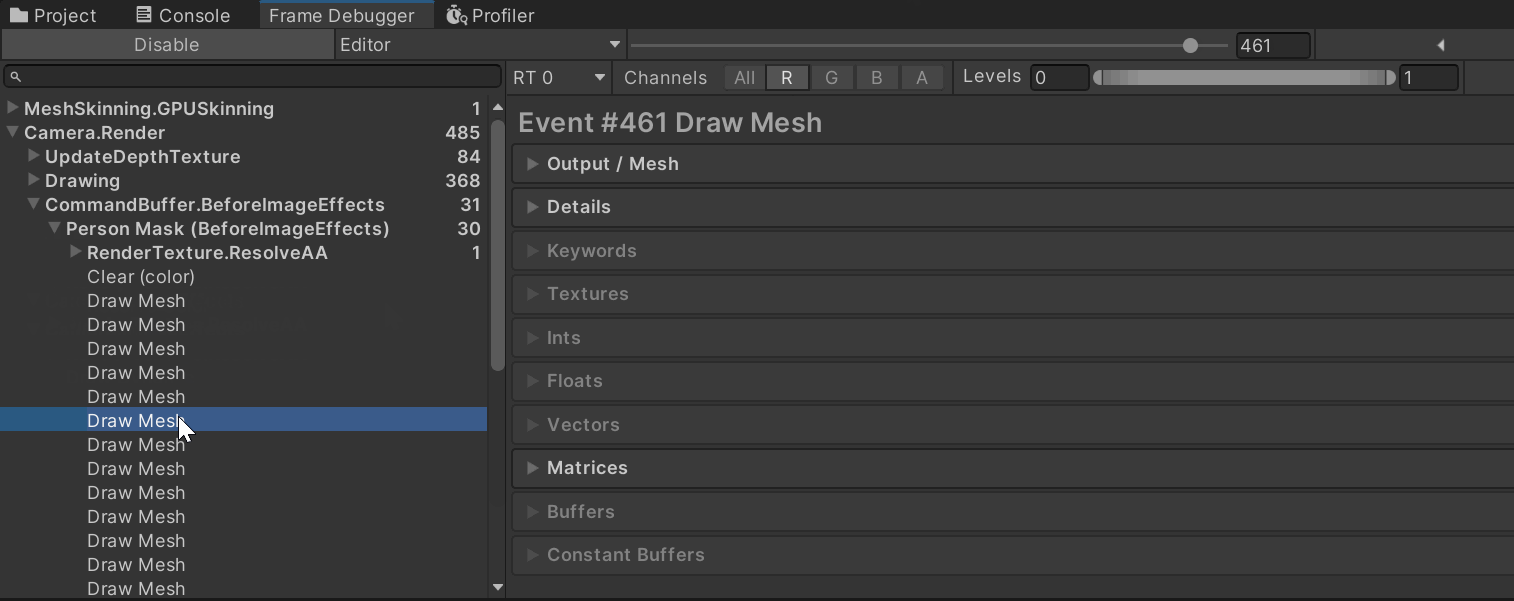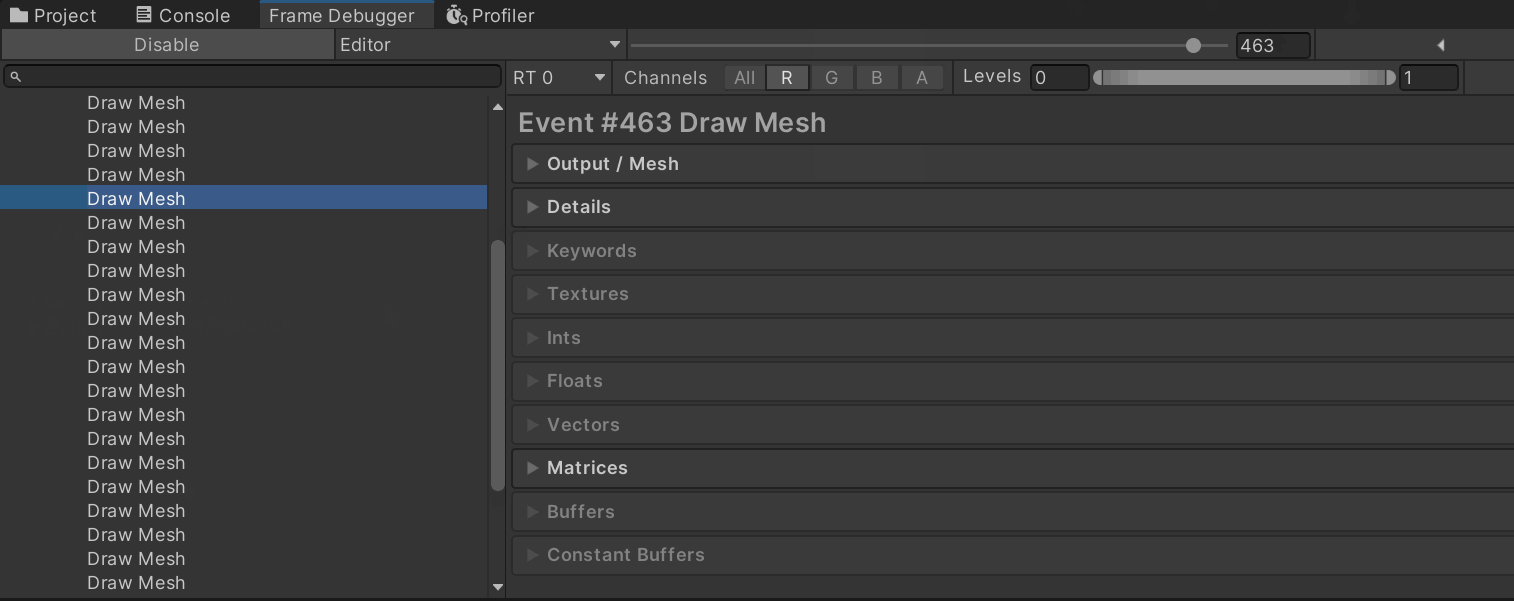
Frame Debugger:在
BeforeImageEffects是否能看到你的 “Person Mask…” CB 和若干 DrawCall?点进去看它的 RenderTarget 是否就是OutlineMask_RT。
如果连 CB 都没有 → 你没 Add 或被移除了。
有 CB 但 draw 数为 0 → 循环里没找到启用的 Renderer、break还没删,或子网格索引越界。 -
子网格:把循环临时改成只画
i=0,排除 submesh 越界:cb.DrawMesh(m, smr.localToWorldMatrix, overrideMaskMat, 0);
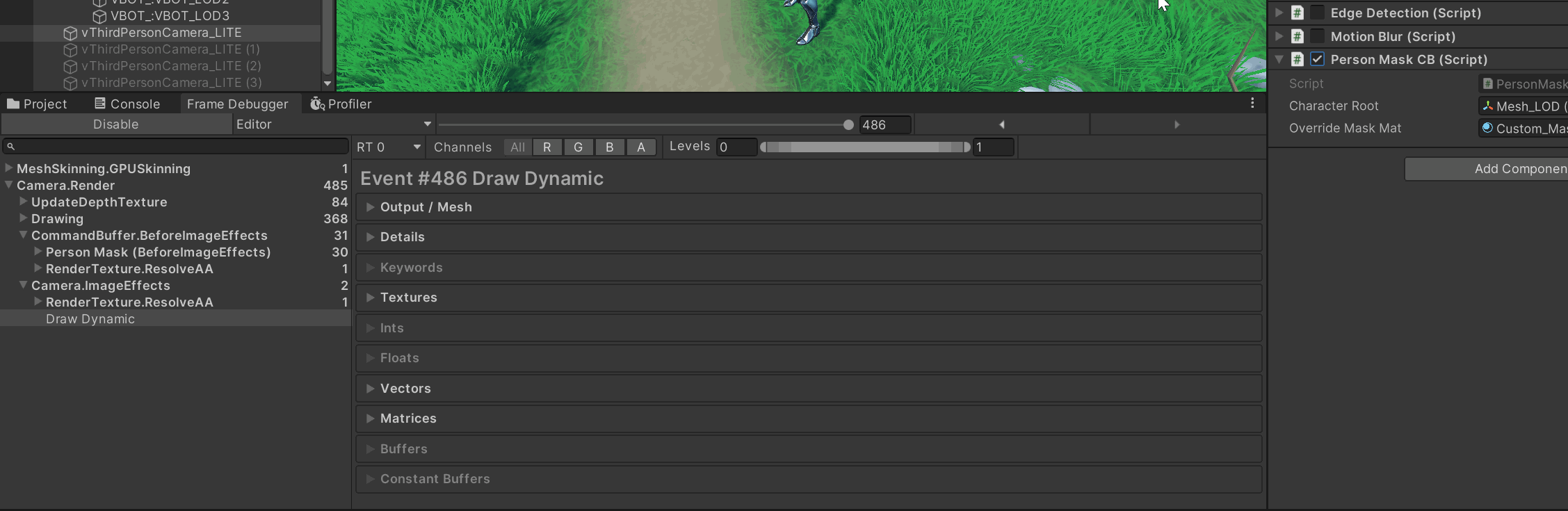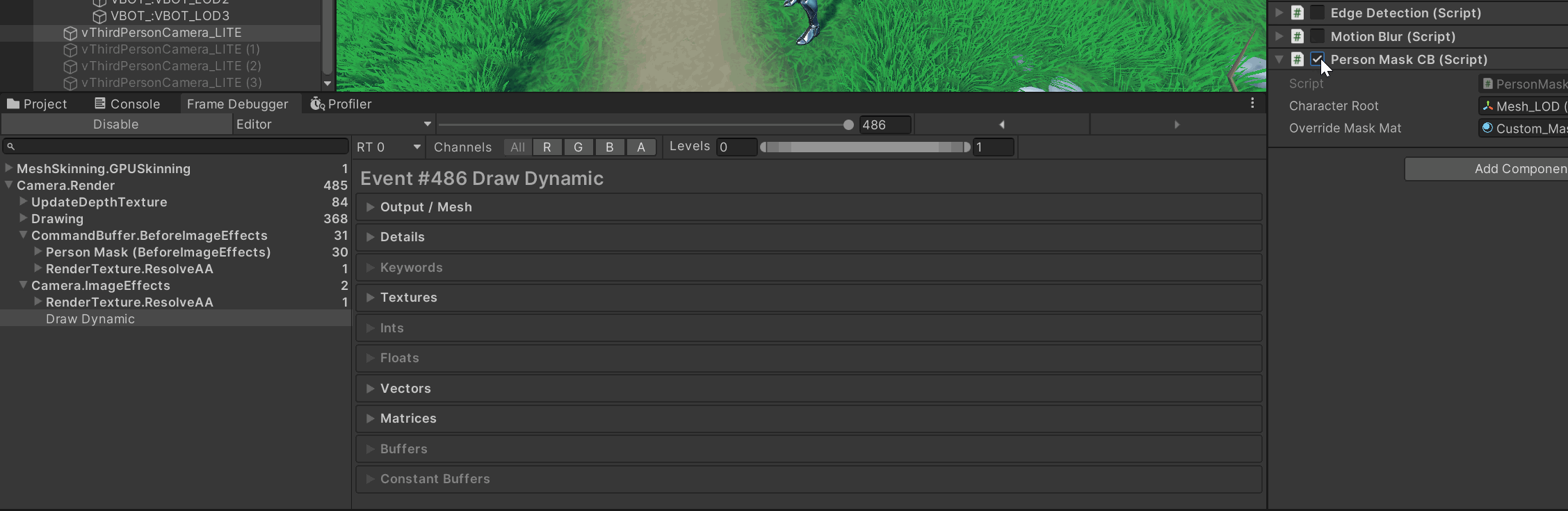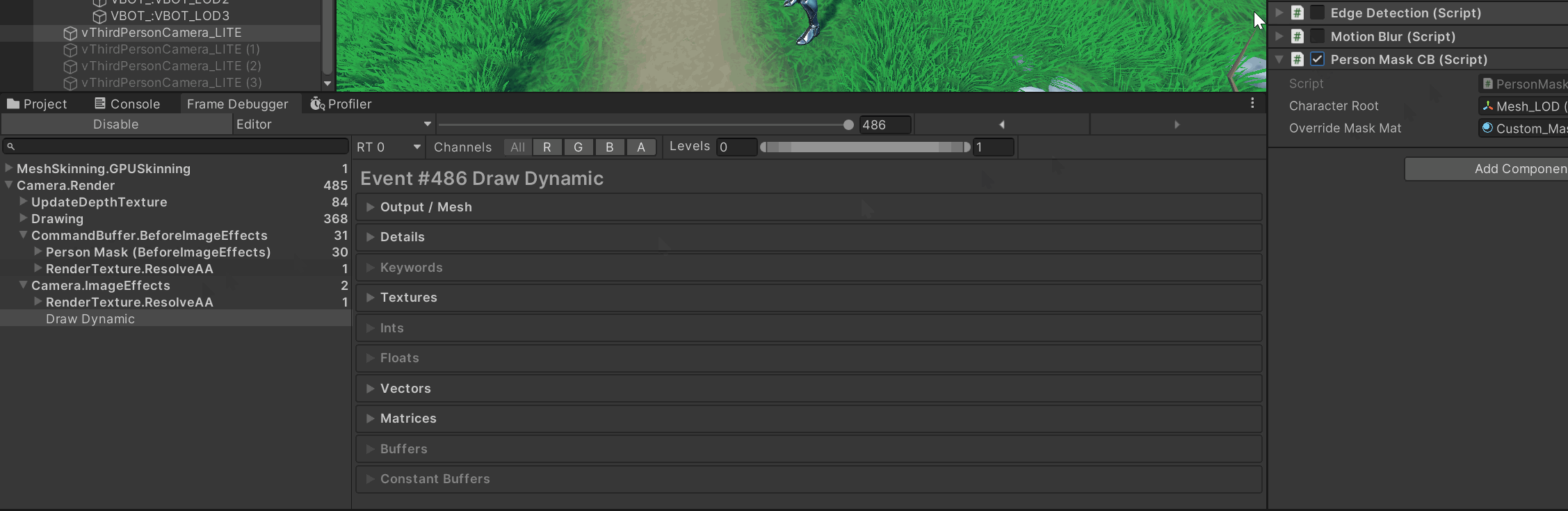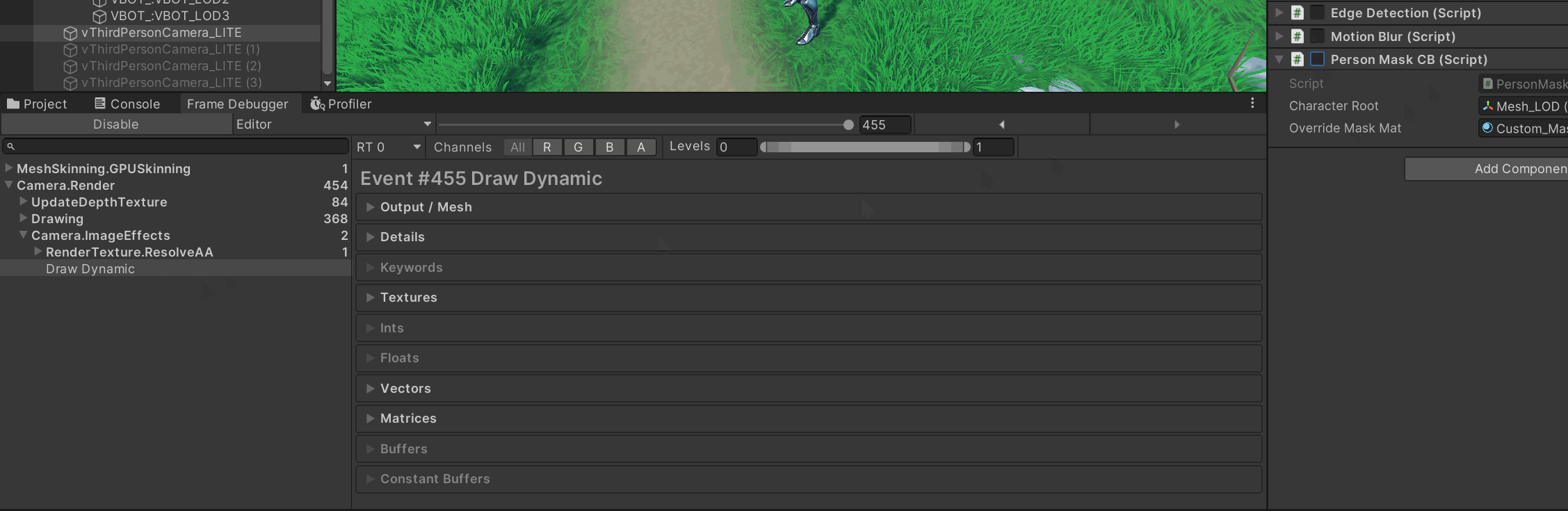
-
RT 生命周期 或 深度绑定/MSAA 不当,再叠加 submesh 索引/残留
break。 -
用持久化 RT +
SetRenderTarget(_maskRT, Depth)+BakeMesh→DrawMesh(submesh 用m.subMeshCount)这套,基本一次到位。 -
验证路径:
ZTest Always→ Frame Debugger 看 draw → 恢复LEqual。
通常不是一处小问题,而是“目标没被写进去”。按经验最常见有 4 个原因。
快速判定:到底是“目标没绑好”还是“Draw 没画出来”
先做一个一步到位的自检——在 CB 里直接把整张 Mask RT 涂成红色。如果这都不显示,说明RenderTarget 绑定/创建有问题;如果能显示,再看 DrawMesh/DrawRenderer。
xxxxxxx
xxxxxxx2bad