视频号存在争议了...
目前实测到:视频号里那套 争议信息提示加AI真相雷达,已经在不少视频下上线了(这是一个非常火爆的趋势!)

伙伴们都知道,短视频里的观点来得快、走得也快,很多人看完就转发。你想想看,要是在这一步前,屏幕底下弹出一句此内容存在争议,再配一段可读的说明,心里会不会先刹一脚?
今天小索奇就专门聊聊这个功能本身:它到底帮了我们什么忙,哪里还不够用,接下来该往哪儿升级。
关键词先摆明:视频号争议信息提示、AI真相雷达、事实核查、创作者合规,这些都是大家容易搜索到、也愿意讨论的点。
先把原理说清楚。平台会先让模型把视频里的重要说法找出来,像X会致癌、Y百分百有效,这种一句话定结论的主张最容易被抓到。简单说就是,先抽主张,再去找证据。模型会去比对公开资料、权威报告、过往判例,像是抓关键词做召回,然后做支持/反驳/不确定的判断。
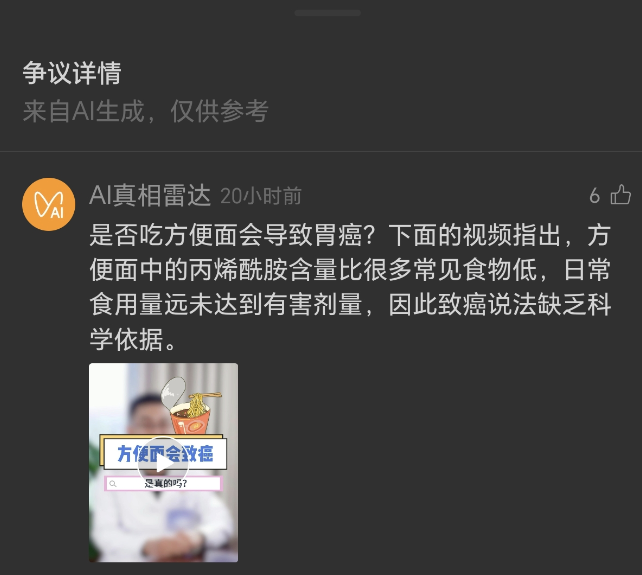
说白了,就是把我听说变成我给出处。当结论没有那么稳或者不能随意得罪一些商业品牌时,系统会给一个争议提示,再配一段 仅供参考 的说明,提醒你别急着站队。这个流程不神秘,但很实用。
从用户角度看,这东西最大的价值是省事。很多人不是不愿意求证,而是没时间。点开争议详情,能先拿到一份大白话的背景卡:相关概念是啥,研究大概怎么说,有没有明显的夸大。对吧,有这一步,错误传播的速度就会被按下去一点。
更重要的是,平台把当事人/热心用户补充”的通道放在同一层,信息不再是一锤子买卖,你可以看到另一边怎么解释,甚至附证据。你想想看,以前我们要在评论区翻半天,如今一页就能看到两个视角,体验上是进步的,是多数平台发展的趋势。
说到专业性,很多朋友关心AI真相雷达到底靠不靠谱。这里得专业点讲一句:模型做的是主张评估,不是判案。它会受到语境、资料新旧、训练数据覆盖面的影响。严格的做法,是把证据分层级,像权威指南/系统综述/随机对照研究/观察研究/个人经验,越靠上的权重越高。
理想状态下,说明里会把证据等级写清楚,还会给出时间戳,告诉你 这条依据更新时间到哪一年。这样你一看就明白:是基本板上钉钉,还是 目前证据不够。只要把这两件事做清楚,读者的信任感会稳很多。
当然,功能有用不代表没有坑。这背后的难点是AI自信但不一定完全对。模型在没有充分证据时,也可能给出像模像样的解释,这就是大家常说的幻觉。另一个难点是证据的新鲜度。热点话题的研究更新很快,今天还在不能确定,明天可能就有重量级的新结论。
平台如果同步不及时,提示就会滞后。还有一个现实问题:用户是否愿意点开看。很多人看到争议三个字,可能会直接滑走,不愿意在事实和观点之间花额外几秒。你看,技术之外的人性问题,才是决定效果的关键。
创作者这边也很微妙。不少朋友可能会说:提示挂在视频下,会不会影响完播率和商业化?小索奇的看法是,短期可能有波动,长期反而是筛选机制。能把出处讲清、能接受证据审阅的创作者,粉丝留存会更稳。

就拿 OpenAI 的 ChatGPT 为例,大家不是只看它会不会答题,而是看它给的步骤和引用靠不靠谱。同理,视频里的观点经得起验证,品牌形象就更耐打。你要是做健康、财经、教育这些领域,干脆主动把证据卡片放出来,省得被动挨提醒,亲测有效。

前面忘了提一句,观众也不是被动的一方。平台已经把当事人/用户补充的入口做得更顺手了,你如果看到明显的误导,完全可以把证据提交上去。说白了,这是一场“人机共建”的活儿。AI负责第一时间把球抛出来,大家再把球传到位。到最后留在页面上的,不该是吵闹的情绪,而是可核验的事实。是不是觉得很有意思?从“我觉得”到“我有证据”,这个小小的动作,慢慢能把整个内容池的水质变清。
接下来会怎么演进?我更看好三个方向。第一个是证据可追溯。不止一句研究显示,而是能点到原文、看到关键段落,最好还标出研究类型。第二个是争议分级。并不是所有争议都一样严重,标注高不确定、结论初步、证据充分,观众判断会更快。第三个是创作者侧工具化。上传时就能一键生成引用清单,平台再做一次合规扫描,减少误伤,也减少被误导的概率。工具一旦好用,大家自然会用起来。
不知道大家站哪边?小索奇是站 透明 这一边。

观点可以不同,但证据得摆出来。AI真相雷达是个好起点,它把证据意识带进了短视频,提醒我们别被一句标题牵着走。它不是法官,却能做一个靠谱的提醒员。真实世界里,争议很正常,关键是让争议有材料、有逻辑,而不是靠音量大小赢输。
最后抛个话题,你更希望提示出现在开头,还是在评论区置顶?你觉得证据卡片应该由平台统一生成,还是由创作者先提交、平台复核?哪种做法更公平?
这两个问题,直接决定了我们以后刷到的事实核查到底只是摆设,还是能真正在关键时刻拉我们一把的~