cuda编程笔记(16)--使用 cuDNN 实现卷积、激活、池化等反向操作
这一节介绍卷积 (Convolution)、池化 (Pooling)、激活 (Activation)、线性层 (全连接/fully-connected) 的 反向传播函数 API
卷积 (Convolution) 反向传播
卷积反向传播分 两部分:
w 的梯度 (filter gradient):给定输入
x和输出梯度dy,算卷积核的梯度dwx 的梯度 (data gradient):给定卷积核
w和输出梯度dy,算输入的梯度dx
卷积对输入的反向传播
cudnnStatus_t cudnnConvolutionBackwardData(cudnnHandle_t handle,const void *alpha,const cudnnFilterDescriptor_t wDesc, const void *w,const cudnnTensorDescriptor_t dyDesc, const void *dy,const cudnnConvolutionDescriptor_t convDesc,cudnnConvolutionBwdDataAlgo_t algo,void *workSpace, size_t workSpaceSizeInBytes,const void *beta,const cudnnTensorDescriptor_t dxDesc, void *dx);功能
计算输入梯度 dx = α * Conv^T(dy, w) + β * dx
参数解释
wDesc, w:卷积核描述子和数据dyDesc, dy:输出梯度张量convDesc:卷积描述子(stride, pad, dilation)algo:选择的反向算法(类似 forward,有 workspace 需求)dxDesc, dx:输入梯度的张量描述子和数据alpha, beta:同 forward,控制缩放
卷积对权重的反向传播
cudnnStatus_t cudnnConvolutionBackwardFilter(cudnnHandle_t handle,const void *alpha,const cudnnTensorDescriptor_t xDesc, const void *x,const cudnnTensorDescriptor_t dyDesc, const void *dy,const cudnnConvolutionDescriptor_t convDesc,const void *beta,const cudnnFilterDescriptor_t dwDesc, void *dw);
功能
计算卷积核梯度 dw = α * (x ⊗ dy) + β * dw
参数解释
xDesc, x:输入数据dyDesc, dy:输出梯度dwDesc, dw:卷积核梯度张量其他参数同上
cudnnGetConvolutionBackwardFilterAlgorithm_v7
选择一个适合的 反向传播 w.r.t. 卷积核 (Filter Gradient) 算法。用于计算卷积核的梯度。
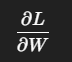
cudnnStatus_t cudnnGetConvolutionBackwardFilterAlgorithm_v7(cudnnHandle_t handle,const cudnnTensorDescriptor_t xDesc, // 输入数据 xconst cudnnTensorDescriptor_t dyDesc, // 输出梯度 dYconst cudnnConvolutionDescriptor_t convDesc,const cudnnFilterDescriptor_t dwDesc, // 权重梯度 dWconst int requestedAlgoCount, // 请求的算法个数 (一般 =1)int* returnedAlgoCount, // 返回的实际数量cudnnConvolutionBwdFilterAlgoPerf_t* perfResults // 返回的算法性能结果数组
);
xDesc: 前向的输入 (activation x) 的张量描述符。dyDesc: 反向传播时来自上层的梯度 (∂L/∂y)。反向传播里“输出梯度”指的就是 上一层的梯度 dY,形状和正向输出 Y 一模一样,所以用正向输出描述符就可以了。
convDesc: 卷积参数 (stride, pad, dilation, mode)。dwDesc: 权重梯度的形状描述符。requestedAlgoCount: 想要返回多少个候选算法。returnedAlgoCount: 实际返回的算法个数。perfResults: 数组,里面是cudnnConvolutionBwdFilterAlgoPerf_t,包含:algo: 算法 IDstatus: 是否成功time: 运行时间memory: 需要的 GPU 内存等信息。
cudnnGetConvolutionBackwardDataAlgorithm_v7
用于计算前一层输入的梯度。
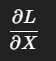
cudnnStatus_t cudnnGetConvolutionBackwardDataAlgorithm_v7(cudnnHandle_t handle,const cudnnFilterDescriptor_t wDesc, // 卷积核描述const cudnnTensorDescriptor_t dyDesc, // 输出梯度const cudnnConvolutionDescriptor_t convDesc,const cudnnTensorDescriptor_t dxDesc, // 输入梯度const int requestedAlgoCount,int* returnedAlgoCount,cudnnConvolutionBwdDataAlgoPerf_t* perfResults
);
cudnnGetConvolutionBackwardDataWorkspaceSize
作用:
给定 反向传播 w.r.t. 输入 (Data Gradient) 的算法,查询所需的临时工作空间大小。
cudnnStatus_t cudnnGetConvolutionBackwardDataWorkspaceSize(cudnnHandle_t handle,const cudnnFilterDescriptor_t wDesc, // 卷积核const cudnnTensorDescriptor_t dyDesc, // 输出梯度 dYconst cudnnConvolutionDescriptor_t convDesc,const cudnnTensorDescriptor_t dxDesc, // 输入梯度 dXcudnnConvolutionBwdDataAlgo_t algo, // 已选择的算法size_t* sizeInBytes // 返回的空间大小
);
wDesc: 卷积核描述符 (前向时的 W)。dyDesc: 来自上层的梯度 (∂L/∂y)。convDesc: 卷积配置。dxDesc: 输入梯度 (∂L/∂x) 的形状描述符。algo: 你要使用的反向传播算法(由cudnnGetConvolutionBackwardDataAlgorithm_v7选出来的)。sizeInBytes: 返回该算法所需的 workspace 大小(单位字节)。
这个函数不执行运算,只是告诉你 选定的反向传播算法需要多少显存。
你要用 cudaMalloc 申请对应大小的 workspace,然后才能调用
cudnnGetConvolutionBackwardFilterWorkspaceSize
计算 反向传播卷积 w.r.t. 卷积核 (∂W) 所需的 临时工作空间大小,单位是字节(Bytes)。
cudnnStatus_t cudnnGetConvolutionBackwardFilterWorkspaceSize(cudnnHandle_t handle,const cudnnTensorDescriptor_t xDesc, // 前向输入 X 的描述符const cudnnTensorDescriptor_t dyDesc, // 输出梯度 dY 的描述符const cudnnConvolutionDescriptor_t convDesc,const cudnnFilterDescriptor_t dwDesc, // 权重梯度 dW 的描述符cudnnConvolutionBwdFilterAlgo_t algo, // 已选定的算法size_t* sizeInBytes // 输出所需 workspace 大小
);
池化 (Pooling) 反向传播
cudnnStatus_t cudnnPoolingBackward(cudnnHandle_t handle,const cudnnPoolingDescriptor_t poolingDesc,const void *alpha,const cudnnTensorDescriptor_t yDesc, const void *y, // forward 输出const cudnnTensorDescriptor_t dyDesc, const void *dy, // 输出梯度const cudnnTensorDescriptor_t xDesc, const void *x, // forward 输入const void *beta,const cudnnTensorDescriptor_t dxDesc, void *dx); // 输入梯度
功能
计算输入梯度 dx,支持 Max Pooling 和 Avg Pooling。
Max Pooling:反向时梯度只传给 forward 时取最大值的那个位置。
Avg Pooling:梯度均匀分配到池化窗口内。
参数解释
poolingDesc:池化方式、窗口大小、stride、paddingyDesc, y:前向输出(Max Pooling 需要索引信息)dyDesc, dy:输出梯度xDesc, x:前向输入(部分模式需要)dxDesc, dx:计算得到的输入梯度
激活 (Activation) 反向传播
cudnnStatus_t cudnnActivationBackward(cudnnHandle_t handle,cudnnActivationDescriptor_t activationDesc,const void *alpha,const cudnnTensorDescriptor_t yDesc, const void *y, // forward 输出const cudnnTensorDescriptor_t dyDesc, const void *dy, // 输出梯度const cudnnTensorDescriptor_t xDesc, const void *x, // forward 输入const void *beta,const cudnnTensorDescriptor_t dxDesc, void *dx); // 输入梯度
功能
计算激活函数的输入梯度 dx。
常见的激活函数:
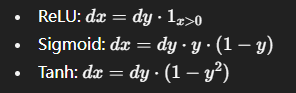
参数解释
activationDesc:激活类型 (ReLU, Sigmoid, Tanh, Clipped ReLU, ELU 等)y:forward 的输出(有些函数更适合用y来反向,而不是x)dy:输出梯度dx:输入梯度
线性层 (Fully Connected / Dense Layer)
cuDNN 没有直接提供 Linear/FC 的 API。
但 FC 层 = 矩阵乘法 (GEMM),所以我们通常用 cuBLAS 来实现。
前向传播
y=Wx+by
反向传播
输入梯度:
dx=dy
权重梯度:
dW=dy⋅
偏置梯度:
db=ReduceSum(dy)
在 CUDA/C++ 里一般用 cublasSgemm 来做矩阵乘法。
示例代码:LeNet模型的一次训练
这里演示执行一次LeNet模型的前向+训练的过程;代码风格是面向过程的,后续可以将模型封装成类使用
LeNet 模型结构(C1-ReLU-P1 → C2-ReLU-P2 → FC1-ReLU → FC2 → Softmax)
数据:N=1(单样本,MNIST 风格)
NCHW = 1×1×28×28结构:
Conv1: 1→6, kernel 5×5, stride 1, pad 0(“valid”),输出 24×24
Pool1: 2×2, stride 2 → 12×12
Conv2: 6→16, kernel 5×5, stride 1, pad 0,输出 8×8
Pool2: 2×2, stride 2 → 4×4
FC1: 1644=256 → 120 → ReLU
FC2: 120 → 10(10 类)
Softmax + CrossEntropy(手写 CUDA kernel)
#ifndef __CUDACC__
#define __CUDACC__
#endif
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
#include <cudnn.h>
#include <cublas_v2.h>
#include <iostream>
#include<cstdio>
#include <cmath>
#include <cstdlib>
#include <vector>void error_handling(cudaError_t res) {if (res !=cudaSuccess) {std::cout << "error! " << cudaGetErrorString(res) << std::endl;exit(EXIT_FAILURE);}
}
void error_handling(cudnnStatus_t status) {if (status != CUDNN_STATUS_SUCCESS) {std::cout<<"error! "<< cudnnGetErrorString(status) << std::endl;exit(EXIT_FAILURE);}
}
void error_handling(cublasStatus_t status) {if (status != CUBLAS_STATUS_SUCCESS) {std::cout << "error! " << (status) << std::endl;exit(EXIT_FAILURE);}
}
//功能:将数组 p 初始化为 [a,b] 区间的均匀分布随机数。
__global__ void init_uniform(float* p, int n, unsigned seed, float a = -0.05f, float b = 0.05f) {int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < n) {// 线性同余伪随机(教学用)unsigned s = seed ^ (i * 747796405u + 2891336453u);s ^= s >> 17; s *= 0xed5ad4bbU; s ^= s >> 11; s *= 0xac4c1b51U; s ^= s >> 15; s *= 0x31848babU; s ^= s >> 14;float r = (s & 0x00FFFFFF) / float(0x01000000); // [0,1)p[i] = a + (b - a) * r;}
}
//张量清零 功能:把数组 p 清零。常用于梯度初始化。
__global__ void zero_kernel(float* p, int n) {int i= blockIdx.x * blockDim.x + threadIdx.x;if (i < n) {p[i] = 0.0f;}
}//功能:在卷积 / 全连接的输出上加上对应的 bias 偏置。
//原理:根据 idx 反推当前像素属于哪个通道 c,然后加上对应的 b[c]。(因为bias是根据通道划分的,一个通道共用一个bias)
__global__ void add_bias_nchw(float* y, const float* b, int N, int C, int H, int W) {//b数组的大小是Cint i= blockIdx.x * blockDim.x + threadIdx.x;int total = N * C * H * W;if (i < total) {int c = (i / (H * W)) % C;//计算当前像素属于哪个同搭配channely[i] += b[c];}
}// Softmax 前向 + 交叉熵损失(单样本),logits->prob, 返回loss
//功能:计算 softmax 概率,同时得到交叉熵损失。
//原理:标准 softmax + CE,做了 max 平移避免指数溢出。
__global__ void softmax_forward_loss(const float* logits, const int* label, float* prob, float* loss, int num_classes) {// 单样本简化// 1) 减去最大值防溢出float mx = logits[0];for (int i = 1; i < num_classes; i++)mx = fmaxf(mx, logits[i]);float sum = 0.f;for (int i =0; i < num_classes; i++) {float e = expf(logits[i] - mx);prob[i] = e;sum += e;}for (int i = 0; i < num_classes; i++)prob[i] /= sum;int y = *label;float l = -logf(fmaxf(prob[y], 1e-12f));//这是损失*loss = l;
}// softmax + CE 的反向:dlogits(损失函数对logits的导数) = prob - onehot(推导过程自行学习)
//功能:计算 dL / dlogits。
__global__ void softmax_ce_backward(const float* prob, const int* label, float* dlogits, int num_classes) {int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < num_classes) {int y = *label;dlogits[i] = prob[i] - (i == y ? 1.f : 0.f);//详见softmax的梯度公式}
}// SGD 参数更新:W -= lr * dW
//功能:梯度下降更新参数。
__global__ void sgd_update(float* W, const float* dW, float lr, int n) {int i= blockIdx.x * blockDim.x + threadIdx.x;if (i < n) {W[i] -= lr * dW[i];}
}
// 功能是计算卷积层的 bias 梯度
// 逻辑:把输出梯度 dy 在 N、H、W 上做 sum,得到每个通道的偏置梯度。**每个通道一个线程**
//dy:上层传下来的梯度,形状是(N, C, H, W)
//数学上,db[c]=dy在N*H*W维度上的总和
__global__ void reduce_bias_grad(const float* dy, float* db, int N, int C, int H, int W) {int c = blockIdx.x * blockDim.x + threadIdx.x;if (c >= C) return;float s = 0.f;for (int n = 0; n < N; n++) {//遍历 batch 内的每个样本 nconst float* p = dy + (n * C + c) * H * W;//p 指向第 n 个样本、第 c 个通道的起始地址for (int i = 0; i < H * W; i++)//内层循环:遍历该通道的所有空间位置(H * W)s += p[i];//累加梯度到 s}db[c] = s;
}//张量展平 (Flatten): 将特征图 (N,C,H,W) flatten 成 (N, C*H*W) 行优先缓冲(简单拷贝)
//这里简化为 N=1,只是拷贝。
__global__ void nchw_to_nxk(const float* x, float* y, int N, int C, int H, int W) {// N=1 简化int k = C * H * W;int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < k) y[i] = x[i];
}
//功能:反展平,主要用在调试或反向传播时。
__global__ void nxk_to_nchw(const float* x, float* y, int N, int C, int H, int W) {int k = C * H * W;int i = blockIdx.x * blockDim.x + threadIdx.x;if (i < k) y[i] = x[i];
}
int main() {// ----------------- 基础句柄 -----------------cudnnHandle_t cudnn;cublasHandle_t cublas;error_handling(cudnnCreate(&cudnn));error_handling(cublasCreate(&cublas));// 训练超参const float lr = 0.01f;const int N = 1, C = 1, H = 28, W = 28;const int num_classes = 10;// ----------------- 描述子 -----------------// Tensor desccudnnTensorDescriptor_t x0Desc, c1OutDesc, p1OutDesc, c2OutDesc, p2OutDesc;error_handling(cudnnCreateTensorDescriptor(&x0Desc));error_handling(cudnnCreateTensorDescriptor(&c1OutDesc));error_handling(cudnnCreateTensorDescriptor(&p1OutDesc));error_handling(cudnnCreateTensorDescriptor(&c2OutDesc));error_handling(cudnnCreateTensorDescriptor(&p2OutDesc));//设置输入的维度信息error_handling(cudnnSetTensor4dDescriptor(x0Desc,CUDNN_TENSOR_NCHW,CUDNN_DATA_FLOAT,N,C,H,W));//卷积描述子cudnnFilterDescriptor_t c1WDesc, c2WDesc;//两层卷积的卷积核描述子cudnnTensorDescriptor_t c1BiasDesc, c2BiasDesc;//两层卷积的biascudnnConvolutionDescriptor_t c1ConvDesc, c2ConvDesc;//卷积描述子error_handling(cudnnCreateFilterDescriptor(&c1WDesc));error_handling(cudnnCreateFilterDescriptor(&c2WDesc));error_handling(cudnnCreateTensorDescriptor(&c1BiasDesc));error_handling(cudnnCreateTensorDescriptor(&c2BiasDesc));error_handling(cudnnCreateConvolutionDescriptor(&c1ConvDesc));error_handling(cudnnCreateConvolutionDescriptor(&c2ConvDesc));//池化层描述字cudnnPoolingDescriptor_t p1Desc, p2Desc;error_handling(cudnnCreatePoolingDescriptor(&p1Desc));error_handling(cudnnCreatePoolingDescriptor(&p2Desc));//激活层描述子(ReLU)该描述子可复用cudnnActivationDescriptor_t reluDesc;error_handling(cudnnCreateActivationDescriptor(&reluDesc));//设置激活层error_handling(cudnnSetActivationDescriptor(reluDesc, CUDNN_ACTIVATION_RELU, CUDNN_PROPAGATE_NAN,0.f));// ----------------- 定义各层尺寸 -----------------// C1: 通道从1->6, k 5x5, validconst int C1_K = 6, C1_R = 5, C1_S = 5, C1_pad = 0, C1_stride = 1;error_handling(cudnnSetFilter4dDescriptor(c1WDesc,CUDNN_DATA_FLOAT,CUDNN_TENSOR_NCHW,C1_K,C,C1_R,C1_S));error_handling(cudnnSetConvolution2dDescriptor(c1ConvDesc,C1_pad,C1_pad,C1_stride,C1_stride,1,1,CUDNN_CROSS_CORRELATION,CUDNN_DATA_FLOAT));int c1N, c1C, c1H, c1W;error_handling(cudnnGetConvolution2dForwardOutputDim(c1ConvDesc,x0Desc,c1WDesc, &c1N, &c1C, &c1H, &c1W));//其实可以手算,结果是1,6,24,24//设置第一层卷积后的张量的维度error_handling(cudnnSetTensor4dDescriptor(c1OutDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, c1N, c1C, c1H, c1W));//设置第一层卷积偏差的维度(偏差针对的是每个通道,所以只有C1_K需要填)error_handling(cudnnSetTensor4dDescriptor(c1BiasDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, C1_K, 1, 1));// P1: 2x2 s=2 -> 12x12error_handling(cudnnSetPooling2dDescriptor(p1Desc,CUDNN_POOLING_MAX,CUDNN_PROPAGATE_NAN,2,2,0,0,2,2));int p1N, p1C, p1H, p1W;error_handling(cudnnGetPooling2dForwardOutputDim(p1Desc, c1OutDesc, &p1N, &p1C, &p1H, &p1W)); // 1,6,12,12//设置第一个池化层后张量的维度error_handling(cudnnSetTensor4dDescriptor(p1OutDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, p1N, p1C, p1H, p1W));// C2: 通道6->16, k5x5, validconst int C2_K = 16, C2_R = 5, C2_S = 5, C2_pad = 0, C2_stride = 1;error_handling(cudnnSetFilter4dDescriptor(c2WDesc, CUDNN_DATA_FLOAT, CUDNN_TENSOR_NCHW, C2_K, C1_K, C2_R, C2_S));error_handling(cudnnSetConvolution2dDescriptor(c2ConvDesc, C2_pad, C2_pad, C2_stride, C2_stride, 1, 1, CUDNN_CROSS_CORRELATION, CUDNN_DATA_FLOAT));int c2N, c2C, c2H, c2W;error_handling(cudnnGetConvolution2dForwardOutputDim(c2ConvDesc, p1OutDesc, c2WDesc, &c2N, &c2C, &c2H, &c2W)); // 1,16,8,8error_handling(cudnnSetTensor4dDescriptor(c2OutDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, c2N, c2C, c2H, c2W));error_handling(cudnnSetTensor4dDescriptor(c2BiasDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, C2_K, 1, 1));// P2: 2x2 s=2 -> 4x4error_handling(cudnnSetPooling2dDescriptor(p2Desc, CUDNN_POOLING_MAX, CUDNN_PROPAGATE_NAN, 2, 2, 0, 0, 2, 2));int p2N, p2C, p2H, p2W;error_handling(cudnnGetPooling2dForwardOutputDim(p2Desc, c2OutDesc, &p2N, &p2C, &p2H, &p2W));error_handling(cudnnSetTensor4dDescriptor(p2OutDesc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, p2N, p2C, p2H, p2W)); // 1,16,4,4// FC 尺寸const int F_flat = p2C * p2H * p2W;const int FC1_out = 120;const int FC2_out = num_classes;// ----------------- 设备内存 -----------------// 输入与标签float* d_x0; int* d_label;//输入的张量error_handling(cudaMalloc(&d_x0, N * C * H * W * sizeof(float)));error_handling(cudaMalloc(&d_label, sizeof(int)));//中间层的输出float* d_c1, * d_p1, * d_c2, * d_p2;error_handling(cudaMalloc(&d_c1, c1N * c1C * c1H * c1W * sizeof(float)));error_handling(cudaMalloc(&d_p1, p1N * p1C * p1H * p1W * sizeof(float)));error_handling(cudaMalloc(&d_c2, c2N * c2C * c2H * c2W * sizeof(float)));error_handling(cudaMalloc(&d_p2, p2N * p2C * p2H * p2W * sizeof(float)));// Flattenfloat* d_flat;error_handling(cudaMalloc(&d_flat, F_flat * sizeof(float)));// FC buffers//d_fc1_w: FC1 的权重矩阵(形状 FC1_out × F_flat)//d_fc1_b : FC1 的 bias(形状 FC1_out)//d_fc1_out : FC1 的线性输出(还没激活)//d_fc1_relu : FC1 的 ReLU 激活结果float* d_fc1_w, * d_fc1_b, * d_fc1_out, * d_fc1_relu;//d_fc2_w: FC2 的权重矩阵(形状 FC2_out × FC1_out)//d_fc2_b : FC2 的 bias(形状 FC2_out)//d_logits : 最后一层未 softmax 的输出(分类分数)//d_prob : softmax 后的概率分布float* d_fc2_w, * d_fc2_b, * d_logits, * d_prob;error_handling(cudaMalloc(&d_fc1_w, FC1_out* F_flat * sizeof(float)));error_handling(cudaMalloc(&d_fc1_b, FC1_out * sizeof(float)));error_handling(cudaMalloc(&d_fc1_out, FC1_out * sizeof(float)));error_handling(cudaMalloc(&d_fc1_relu, FC1_out * sizeof(float)));error_handling(cudaMalloc(&d_fc2_w, FC2_out* FC1_out * sizeof(float)));error_handling(cudaMalloc(&d_fc2_b, FC2_out * sizeof(float)));error_handling(cudaMalloc(&d_logits, FC2_out * sizeof(float)));error_handling(cudaMalloc(&d_prob, FC2_out * sizeof(float)));// Grad buffers//d_c1_w: 卷积层1的卷积核(shape : C1_K × C × C1_R × C1_S)//d_c1_b : 卷积层1的 bias//d_c2_w : 卷积层2的卷积核(shape : C2_K × C1_K × C2_R × C2_S)//d_c2_b : 卷积层2的 biasfloat* d_c1_w, * d_c1_b, * d_c2_w, * d_c2_b;error_handling(cudaMalloc(&d_c1_w, C1_K* C* C1_R* C1_S * sizeof(float)));error_handling(cudaMalloc(&d_c2_w, C2_K* C1_K* C2_R* C2_S * sizeof(float)));error_handling(cudaMalloc(&d_c1_b, C1_K * sizeof(float)));error_handling(cudaMalloc(&d_c2_b, C2_K * sizeof(float)));//这些就是 参数的梯度,训练时反向传播会写入这里,之后优化器(SGD/Adam)用它们更新权重:float* d_c1_w_grad, * d_c2_w_grad, * d_c1_b_grad, * d_c2_b_grad;error_handling(cudaMalloc(&d_c1_w_grad, C1_K* C* C1_R* C1_S * sizeof(float)));error_handling(cudaMalloc(&d_c2_w_grad, C2_K* C1_K* C2_R* C2_S * sizeof(float)));error_handling(cudaMalloc(&d_c1_b_grad, C1_K * sizeof(float)));error_handling(cudaMalloc(&d_c2_b_grad, C2_K * sizeof(float)));float* d_fc1_w_grad, * d_fc1_b_grad, * d_fc2_w_grad, * d_fc2_b_grad;error_handling(cudaMalloc(&d_fc1_w_grad, FC1_out* F_flat * sizeof(float)));error_handling(cudaMalloc(&d_fc1_b_grad, FC1_out * sizeof(float)));error_handling(cudaMalloc(&d_fc2_w_grad, FC2_out* FC1_out * sizeof(float)));error_handling(cudaMalloc(&d_fc2_b_grad, FC2_out * sizeof(float)));// 反向临时梯度//d_dlogits: 最后一层 softmax + loss 的梯度(对 logits)//d_dfcrelu : 经过 ReLU 的 FC1 梯度//d_dfcout : FC1 线性输出的梯度//d_dflat : flatten 张量的梯度//d_dp2 : pool2 层输出的梯度//d_dc2 : conv2 层输出的梯度//d_dp1 : pool1 层输出的梯度//d_dc1 : conv1 层输出的梯度//这些相当于 PyTorch 里每层的.grad,只是我们手动开 buffer。float* d_dlogits, * d_dfcrelu, * d_dfcout, * d_dflat, * d_dp2, * d_dc2, * d_dp1, * d_dc1;error_handling(cudaMalloc(&d_dlogits, FC2_out * sizeof(float)));error_handling(cudaMalloc(&d_dfcrelu, FC1_out * sizeof(float)));error_handling(cudaMalloc(&d_dfcout, FC1_out * sizeof(float)));error_handling(cudaMalloc(&d_dflat, F_flat * sizeof(float)));error_handling(cudaMalloc(&d_dp2, p2N* p2C* p2H* p2W * sizeof(float)));error_handling(cudaMalloc(&d_dc2, c2N* c2C* c2H* c2W * sizeof(float)));error_handling(cudaMalloc(&d_dp1, p1N* p1C* p1H* p1W * sizeof(float)));error_handling(cudaMalloc(&d_dc1, c1N* c1C* c1H* c1W * sizeof(float)));float* d_loss;error_handling(cudaMalloc(&d_loss, sizeof(float)));// ----------------- 初始化参数 -----------------int block = 256;init_uniform << <(C1_K * C * C1_R * C1_S + block - 1) / block, block >> > (d_c1_w, C1_K* C* C1_R* C1_S, 123);init_uniform << <(C2_K * C1_K * C2_R * C2_S + block - 1) / block, block >> > (d_c2_w, C2_K* C1_K* C2_R* C2_S, 456);init_uniform << <(FC1_out * F_flat + block - 1) / block, block >> > (d_fc1_w, FC1_out* F_flat, 789);init_uniform << <(FC2_out * FC1_out + block - 1) / block, block >> > (d_fc2_w, FC2_out* FC1_out, 1011);//偏差初始化0zero_kernel << <(C1_K + block - 1) / block, block >> > (d_c1_b, C1_K);zero_kernel << <(C2_K + block - 1) / block, block >> > (d_c2_b, C2_K);zero_kernel << <(FC1_out + block - 1) / block, block >> > (d_fc1_b, FC1_out);zero_kernel << <(FC2_out + block - 1) / block, block >> > (d_fc2_b, FC2_out);// 伪造输入与标签(教学)init_uniform << <(N * C * H * W + block - 1) / block, block >> > (d_x0, N* C* H* W, 2025, 0.f, 1.f);int h_label = 3; // 预测的真实结果 = 3error_handling(cudaMemcpy(d_label, &h_label, sizeof(int), cudaMemcpyHostToDevice));// ----------------- 选择卷积算法 + 工作空间 -----------------cudnnConvolutionFwdAlgoPerf_t fwdPerf[8]; int retFwd = 0;error_handling(cudnnGetConvolutionForwardAlgorithm_v7(cudnn, x0Desc, c1WDesc, c1ConvDesc, c1OutDesc, 8, &retFwd, fwdPerf));cudnnConvolutionFwdAlgo_t c1Algo = fwdPerf[0].algo;error_handling(cudnnGetConvolutionForwardAlgorithm_v7(cudnn, p1OutDesc, c2WDesc, c2ConvDesc, c2OutDesc, 8, &retFwd, fwdPerf));cudnnConvolutionFwdAlgo_t c2Algo = fwdPerf[0].algo;size_t ws1 = 0, ws2 = 0;error_handling(cudnnGetConvolutionForwardWorkspaceSize(cudnn, x0Desc, c1WDesc, c1ConvDesc, c1OutDesc, c1Algo, &ws1));error_handling(cudnnGetConvolutionForwardWorkspaceSize(cudnn, p1OutDesc, c2WDesc, c2ConvDesc, c2OutDesc, c2Algo, &ws2));size_t ws_bytes = std::max(ws1, ws2);void* d_workspace = nullptr;if (ws_bytes > 0) error_handling(cudaMalloc(&d_workspace, ws_bytes));// 反向算法与 workspacecudnnConvolutionBwdFilterAlgoPerf_t bwdFiltPerf[8]; int retBF = 0;cudnnConvolutionBwdDataAlgoPerf_t bwdDataPerf[8]; int retBD = 0;error_handling(cudnnGetConvolutionBackwardFilterAlgorithm_v7(cudnn, x0Desc, c1OutDesc, c1ConvDesc, c1WDesc, 8, &retBF, bwdFiltPerf));cudnnConvolutionBwdFilterAlgo_t c1BwdFiltAlgo = bwdFiltPerf[0].algo;error_handling(cudnnGetConvolutionBackwardDataAlgorithm_v7(cudnn, c1WDesc, c1OutDesc, c1ConvDesc, x0Desc, 8, &retBD, bwdDataPerf));cudnnConvolutionBwdDataAlgo_t c1BwdDataAlgo = bwdDataPerf[0].algo;error_handling(cudnnGetConvolutionBackwardFilterAlgorithm_v7(cudnn, p1OutDesc, c2OutDesc, c2ConvDesc, c2WDesc, 8, &retBF, bwdFiltPerf));cudnnConvolutionBwdFilterAlgo_t c2BwdFiltAlgo = bwdFiltPerf[0].algo;error_handling(cudnnGetConvolutionBackwardDataAlgorithm_v7(cudnn, c2WDesc, c2OutDesc, c2ConvDesc, p1OutDesc, 8, &retBD, bwdDataPerf));cudnnConvolutionBwdDataAlgo_t c2BwdDataAlgo = bwdDataPerf[0].algo;size_t ws_bf1 = 0, ws_bd1 = 0, ws_bf2 = 0, ws_bd2 = 0;error_handling(cudnnGetConvolutionBackwardFilterWorkspaceSize(cudnn,x0Desc,c1OutDesc,c1ConvDesc, c1WDesc, c1BwdFiltAlgo,&ws_bf1));error_handling(cudnnGetConvolutionBackwardDataWorkspaceSize(cudnn, c1WDesc, c1OutDesc, c1ConvDesc, x0Desc, c1BwdDataAlgo, &ws_bd1));error_handling(cudnnGetConvolutionBackwardFilterWorkspaceSize(cudnn, p1OutDesc, c2OutDesc, c2ConvDesc, c2WDesc, c2BwdFiltAlgo, &ws_bf2));error_handling(cudnnGetConvolutionBackwardDataWorkspaceSize(cudnn, c2WDesc, c2OutDesc, c2ConvDesc, p1OutDesc, c2BwdDataAlgo, &ws_bd2));size_t ws_bwd = std::max(std::max(ws_bf1, ws_bd1), std::max(ws_bf2, ws_bd2));if (ws_bwd > ws_bytes) {//更新工作区大小if (d_workspace) cudaFree(d_workspace);error_handling(cudaMalloc(&d_workspace, ws_bwd));ws_bytes = ws_bwd;}// 标量 alpha/betaconst float alpha1 = 1.f, beta0 = 0.f, beta1f = 1.f;// ----------------- 前向 -----------------// C1error_handling(cudnnConvolutionForward(cudnn,&alpha1,x0Desc,d_x0,c1WDesc,d_c1_w,c1ConvDesc,c1Algo,d_workspace,ws_bytes,&beta0,c1OutDesc,d_c1));add_bias_nchw << <(c1N * c1C * c1H * c1W + 255) / 256, 256 >> > (d_c1,d_c1_b,c1N,c1C,c1H,c1W);error_handling(cudnnActivationForward(cudnn,reluDesc,&alpha1,c1OutDesc,d_c1,&beta0, c1OutDesc, d_c1));// P1error_handling(cudnnPoolingForward(cudnn,p1Desc,&alpha1,c1OutDesc,d_c1,&beta0,p1OutDesc,d_p1));// C2error_handling(cudnnConvolutionForward(cudnn, &alpha1, p1OutDesc, d_p1, c2WDesc, d_c2_w,c2ConvDesc, c2Algo, d_workspace, ws_bytes, &beta0,c2OutDesc, d_c2));add_bias_nchw << <(c2N * c2C * c2H * c2W + 255) / 256, 256 >> > (d_c2, d_c2_b, c2N, c2C, c2H, c2W);error_handling(cudnnActivationForward(cudnn, reluDesc, &alpha1, c2OutDesc, d_c2, &beta0, c2OutDesc, d_c2));// P2error_handling(cudnnPoolingForward(cudnn, p2Desc, &alpha1, c2OutDesc, d_c2, &beta0, p2OutDesc, d_p2));// Flattennchw_to_nxk << <(F_flat + 255) / 256, 256 >> > (d_p2, d_flat, N, C2_K, p2H, p2W);// FC1: y = W*x + b (注意 cuBLAS 默认列主序,这里用转置把行主序等价起来)// 我们把向量当作矩阵 (m=FC1_out, k=F_flat, n=1),计算: (m x k) * (k x n) = (m x n)//其中,把x当作F_flat*1的维度来理解这个函数error_handling(cublasSgemm(cublas,CUBLAS_OP_N,CUBLAS_OP_N,FC1_out,1,F_flat,&alpha1,d_fc1_w,FC1_out,d_flat,F_flat,&beta0,d_fc1_out,FC1_out));// 加偏置// 这里直接用 kernel,真实工程可以用 cudnnAddTensoradd_bias_nchw << <(FC1_out + 255) / 256, 256 >> > (d_fc1_out, d_fc1_b, 1, FC1_out, 1, 1);//ReLUcudnnTensorDescriptor_t fc1Desc; error_handling(cudnnCreateTensorDescriptor(&fc1Desc));//在 FC 层:batch size = 1 → N = 1 输出神经元个数 = FC1_out。没有空间结构,所以 H = 1, W = 1。所以一般维度写在Channel上error_handling(cudnnSetTensor4dDescriptor(fc1Desc, CUDNN_TENSOR_NCHW, CUDNN_DATA_FLOAT, 1, FC1_out, 1, 1));error_handling(cudnnActivationForward(cudnn, reluDesc, &alpha1, fc1Desc, d_fc1_out, &beta0, fc1Desc, d_fc1_relu));// FC2: (num_classes x FC1_out) * (FC1_out x 1) = (num_classes x 1)error_handling(cublasSgemm(cublas,CUBLAS_OP_N,CUBLAS_OP_N,FC2_out,1,FC1_out,&alpha1,d_fc2_w,FC2_out,d_fc1_relu,FC1_out,&beta0,d_logits, FC2_out));add_bias_nchw << <(FC2_out + 255) / 256, 256 >> > (d_logits, d_fc2_b, 1, FC2_out, 1, 1);// Softmax + Losssoftmax_forward_loss << <1, 1 >> > (d_logits, d_label, d_prob, d_loss, num_classes);float h_loss = 0.f;error_handling(cudaMemcpy(&h_loss,d_loss,sizeof(float),cudaMemcpyDeviceToHost));std::cout << "Loss (before update): " << h_loss << "\n";// ----------------- 反向 -----------------// dL/dlogits = prob - onehotsoftmax_ce_backward << <(num_classes + 255) / 256, 256 >> > (d_prob, d_label, d_dlogits, num_classes);// FC2 backward:// dW2 = dY * X^T (num_classes x 1) * (1 x FC1_out) = (num_classes x FC1_out)error_handling(cublasSgemm(cublas,CUBLAS_OP_N,CUBLAS_OP_T,FC2_out,FC1_out,1,&alpha1,d_dlogits,FC2_out,d_fc1_relu,FC1_out,&beta0,d_fc2_w_grad,FC2_out));// db2 = sum(dY) -> 这里单样本就是拷贝error_handling(cudaMemcpy(d_fc2_b_grad,d_dlogits,FC2_out*sizeof(float), cudaMemcpyDeviceToDevice));// dX2 = W2^T * dY (FC1_out x num_classes) * (num_classes x 1) = (FC1_out x 1)error_handling(cublasSgemm(cublas, CUBLAS_OP_T, CUBLAS_OP_N,FC1_out, 1, FC2_out,&alpha1, d_fc2_w, FC2_out, d_dlogits, FC2_out, &beta0, d_dfcrelu, FC1_out));// ReLU (FC1) backward: dx = dy * 1(y>0)error_handling(cudnnActivationBackward(cudnn, reluDesc, &alpha1,fc1Desc, d_fc1_relu, // yfc1Desc, d_dfcrelu, // dyfc1Desc, d_fc1_out, // x&beta0,fc1Desc, d_dfcout)); // dx// FC1 backward:// dW1 = dY * X^T (FC1_out x 1) * (1 x F_flat) = (FC1_out x F_flat)error_handling(cublasSgemm(cublas, CUBLAS_OP_N, CUBLAS_OP_T,FC1_out, F_flat, 1,&alpha1, d_dfcout, FC1_out, d_flat, F_flat, &beta0, d_fc1_w_grad, FC1_out));// db1 = dYerror_handling(cudaMemcpy(d_fc1_b_grad, d_dfcout, FC1_out * sizeof(float), cudaMemcpyDeviceToDevice));// dX1 = W1^T * dY (F_flat x FC1_out) * (FC1_out x 1) = (F_flat x 1)error_handling(cublasSgemm(cublas, CUBLAS_OP_T, CUBLAS_OP_N,F_flat, 1, FC1_out,&alpha1, d_fc1_w, FC1_out, d_dfcout, FC1_out, &beta0, d_dflat, F_flat));// 将 d_flat -> d_p2nxk_to_nchw << <(F_flat + 255) / 256, 256 >> > (d_dflat, d_dp2, N, C2_K, p2H, p2W);// P2 backwarderror_handling(cudnnPoolingBackward(cudnn, p2Desc, &alpha1,p2OutDesc, d_p2, p2OutDesc, d_dp2,c2OutDesc, d_c2, &beta0,c2OutDesc, d_dc2));// C2 backward: bias, filter, data// db2 (conv) = sum over N,H,W of dC2reduce_bias_grad << <(C2_K + 255) / 256, 256 >> > (d_dc2, d_c2_b_grad, c2N, c2C, c2H, c2W);// dW2error_handling(cudnnConvolutionBackwardFilter(cudnn, &alpha1,p1OutDesc, d_p1, c2OutDesc, d_dc2, c2ConvDesc,c2BwdFiltAlgo,d_workspace,ws_bytes, &beta0, c2WDesc, d_c2_w_grad));// dP1error_handling(cudnnConvolutionBackwardData(cudnn, &alpha1,c2WDesc, d_c2_w, c2OutDesc, d_dc2, c2ConvDesc, c2BwdDataAlgo, d_workspace, ws_bytes,&beta0, p1OutDesc, d_dp1));// ReLU(C1) backward: 先把 pool1 的梯度反传回来error_handling(cudnnPoolingBackward(cudnn, p1Desc, &alpha1,p1OutDesc, d_p1, p1OutDesc, d_dp1,c1OutDesc, d_c1, &beta0,c1OutDesc, d_dc1));// C1 backward: bias, filter, datareduce_bias_grad <<<(C1_K + 255) / 256, 256 >> > (d_dc1, d_c1_b_grad, c1N, c1C, c1H, c1W);error_handling(cudnnConvolutionBackwardFilter(cudnn, &alpha1,x0Desc, d_x0, c1OutDesc, d_dc1, c1ConvDesc, c1BwdFiltAlgo, d_workspace, ws_bytes, &beta0, c1WDesc, d_c1_w_grad));// dX0(通常训练第一层也要把梯度传回去,这里演示)error_handling(cudnnConvolutionBackwardData(cudnn, &alpha1,c1WDesc, d_c1_w, c1OutDesc, d_dc1, c1ConvDesc, c1BwdDataAlgo, d_workspace, ws_bytes,&beta0, x0Desc, d_x0 /*写回到同缓冲仅演示,不建议覆盖真实输入*/));// ----------------- SGD 更新 -----------------sgd_update << <(C1_K * C * C1_R * C1_S + 255) / 256, 256 >> > (d_c1_w, d_c1_w_grad, lr, C1_K * C * C1_R * C1_S);sgd_update << <(C2_K * C1_K * C2_R * C2_S + 255) / 256, 256 >> > (d_c2_w, d_c2_w_grad, lr, C2_K * C1_K * C2_R * C2_S);sgd_update << <(C1_K + 255) / 256, 256 >> > (d_c1_b, d_c1_b_grad, lr, C1_K);sgd_update << <(C2_K + 255) / 256, 256 >> > (d_c2_b, d_c2_b_grad, lr, C2_K);sgd_update << <(FC1_out * F_flat + 255) / 256, 256 >> > (d_fc1_w, d_fc1_w_grad, lr, FC1_out * F_flat);sgd_update << <(FC2_out * FC1_out + 255) / 256, 256 >> > (d_fc2_w, d_fc2_w_grad, lr, FC2_out * FC1_out);sgd_update << <(FC1_out + 255) / 256, 256 >> > (d_fc1_b, d_fc1_b_grad, lr, FC1_out);sgd_update << <(FC2_out + 255) / 256, 256 >> > (d_fc2_b, d_fc2_b_grad, lr, FC2_out);// 再前向一次看看 loss 是否下降(可选)// 这里只示意再计算 softmax+losssoftmax_forward_loss << <1, 1 >> > (d_logits, d_label, d_prob, d_loss, num_classes);error_handling(cudaMemcpy(&h_loss, d_loss, sizeof(float), cudaMemcpyDeviceToHost));std::cout << "(Same logits buffer; to observe drop, re-run full forward after update.) Loss now: " << h_loss << "\n";// ----------------- 清理 -----------------if (d_workspace) cudaFree(d_workspace);cudaFree(d_x0); cudaFree(d_label);cudaFree(d_c1); cudaFree(d_p1); cudaFree(d_c2); cudaFree(d_p2);cudaFree(d_flat);cudaFree(d_fc1_w); cudaFree(d_fc1_b); cudaFree(d_fc1_out); cudaFree(d_fc1_relu);cudaFree(d_fc2_w); cudaFree(d_fc2_b); cudaFree(d_logits); cudaFree(d_prob);cudaFree(d_c1_w); cudaFree(d_c2_w); cudaFree(d_c1_b); cudaFree(d_c2_b);cudaFree(d_c1_w_grad); cudaFree(d_c2_w_grad); cudaFree(d_c1_b_grad); cudaFree(d_c2_b_grad);cudaFree(d_fc1_w_grad); cudaFree(d_fc1_b_grad); cudaFree(d_fc2_w_grad); cudaFree(d_fc2_b_grad);cudaFree(d_dlogits); cudaFree(d_dfcrelu); cudaFree(d_dfcout); cudaFree(d_dflat);cudaFree(d_dp2); cudaFree(d_dc2); cudaFree(d_dp1); cudaFree(d_dc1);cudaFree(d_loss);cudnnDestroyTensorDescriptor(x0Desc);cudnnDestroyTensorDescriptor(c1OutDesc);cudnnDestroyTensorDescriptor(p1OutDesc);cudnnDestroyTensorDescriptor(c2OutDesc);cudnnDestroyTensorDescriptor(p2OutDesc);cudnnDestroyTensorDescriptor(c1BiasDesc);cudnnDestroyTensorDescriptor(c2BiasDesc);cudnnDestroyActivationDescriptor(reluDesc);cudnnDestroyPoolingDescriptor(p1Desc);cudnnDestroyPoolingDescriptor(p2Desc);cudnnDestroyFilterDescriptor(c1WDesc);cudnnDestroyFilterDescriptor(c2WDesc);cudnnDestroyConvolutionDescriptor(c1ConvDesc);cudnnDestroyConvolutionDescriptor(c2ConvDesc);cudnnDestroy(cudnn);cublasDestroy(cublas);std::cout << "Done one training step of LeNet-like.\n";return 0;
}