【大语言模型 22】Tokenization深度技术:BPE、WordPiece、SentencePiece
【大语言模型 22】Tokenization深度技术:BPE、WordPiece、SentencePiece完全指南
关键词: Tokenization, BPE, WordPiece, SentencePiece, 分词算法, 子词切分, 大语言模型预处理
摘要: 本文深入剖析大语言模型中的三大主流Tokenization技术:BPE、WordPiece和SentencePiece,从算法原理到代码实现,再到实际应用案例。通过对比分析这三种算法的优缺点和适用场景,帮助读者全面理解Tokenization在NLP中的关键作用,并掌握如何为不同语言和任务选择最合适的分词策略。
文章目录
- 【大语言模型 22】Tokenization深度技术:BPE、WordPiece、SentencePiece完全指南
- 1. 引言:为什么Tokenization如此重要?
- 2. BPE算法:从压缩算法到NLP的华丽转身
- 2.1 BPE的历史与原理
- 2.2 BPE算法详解
- 训练阶段步骤:
- 编码阶段步骤:
- 2.3 BPE算法Python实现
- 2.4 BPE的优缺点
- 3. WordPiece算法:Google的语言模型利器
- 3.1 WordPiece的起源与发展
- 3.2 WordPiece与BPE的区别
- 3.3 WordPiece算法流程
- 3.4 WordPiece算法Python实现
- 3.5 WordPiece的优缺点
- 4. SentencePiece:无语言边界的通用分词方案
- 4.1 SentencePiece的创新之处
- 4.2 Unigram算法原理
- 4.3 SentencePiece的使用方法
- 4.4 SentencePiece的优缺点
- 5. 三种算法的对比与选择指南
- 5.1 性能对比
- 5.2 应用场景对比
- 5.3 选择指南
- 6. 实际应用案例分析
- 6.1 GPT系列中的BPE应用
- 6.2 BERT中的WordPiece应用
- 6.3 多语言模型中的SentencePiece应用
- 7. 高级话题与前沿发展
- 7.1 上下文相关的分词
- 7.2 字符级与子词级的权衡
- 7.3 Tokenization-free模型
- 8. 实用技巧与最佳实践
- 8.1 词表大小的选择
- 8.2 特殊标记的处理
- 8.3 多语言模型的分词策略
- 9. 总结与展望
- 9.1 三种算法的核心差异
- 9.2 Tokenization的未来发展
- 10. 参考资料
1. 引言:为什么Tokenization如此重要?
想象一下,如果你要教一个外星人学习人类语言,但这个外星人只认识数字,你会怎么做?你可能会创建一个词典,把每个单词映射到一个唯一的数字。但很快你就会发现一个问题:人类语言中的词汇量实在太庞大了,而且不断有新词出现。
这正是大语言模型面临的核心挑战之一。模型不能直接处理文本,它需要将文本转换为数字序列。这个转换过程就是Tokenization(分词)。一个好的Tokenization策略应该:
- 词表大小可控:不能无限膨胀
- 覆盖率高:能处理未见过的词汇
- 语义保留:保持词的语义完整性
- 计算效率高:快速处理大规模文本
传统的基于词的分词方法(Word-level Tokenization)在这些方面都存在明显不足,尤其是面对开放域文本和多语言场景时。这就是为什么现代大语言模型几乎都采用了子词(Subword)分词技术,其中BPE、WordPiece和SentencePiece是三种最主流的算法。
本文将带你深入理解这三种算法的工作原理、实现细节和应用场景,帮助你在实际项目中做出最佳选择。
2. BPE算法:从压缩算法到NLP的华丽转身
2.1 BPE的历史与原理
Byte Pair Encoding(字节对编码)最初是由Philip Gage在1994年提出的一种数据压缩算法。它的核心思想非常简单:找出数据中最常出现的字节对,并用一个新的、未使用过的字节替换它们。
2016年,Rico Sennrich等人在论文《Neural Machine Translation of Rare Words with Subword Units》中将BPE算法引入到NLP领域,用于解决神经机器翻译中的罕见词问题。在NLP中的BPE算法与原始压缩算法有所不同,但核心思想相似:迭代地合并最频繁出现的字符对,直到达到预设的词表大小。
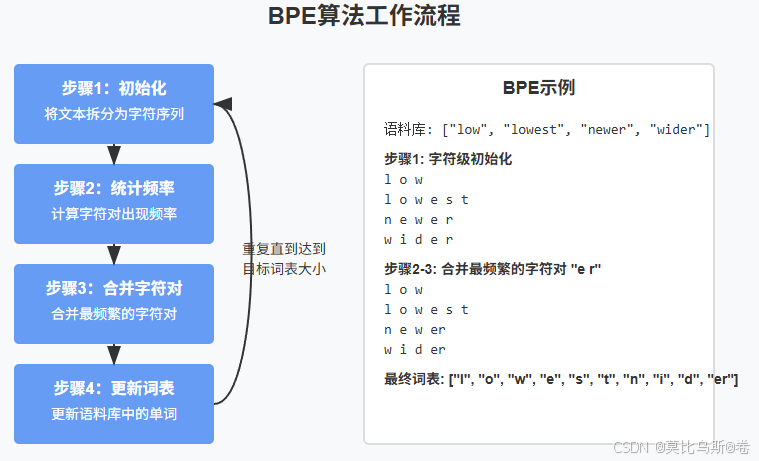
2.2 BPE算法详解
BPE算法分为两个主要阶段:
- 训练阶段:从语料库中学习合并规则
- 编码阶段:使用学习到的规则对新文本进行分词
训练阶段步骤:
- 将所有单词拆分为字符序列,并在每个单词末尾添加特殊符号(如"")表示单词结束
- 统计所有字符对的出现频率
- 合并出现最频繁的字符对,形成一个新的子词
- 更新语料库中的所有单词,将最频繁的字符对替换为新的子词
- 重复步骤2-4,直到达到预设的合并次数或词表大小
编码阶段步骤:
- 将待编码的单词拆分为字符序列
- 按照训练阶段学到的合并规则,从最早学到的规则开始,依次应用
- 最终得到单词的子词表示
2.3 BPE算法Python实现
下面是BPE算法的简化Python实现:
def get_stats(vocab):"""统计所有相邻符号对的频率"""pairs = {}for word, freq in vocab.items():symbols = word.split()for i in range(len(symbols) - 1):pair = (symbols[i], symbols[i + 1])pairs[pair] = pairs.get(pair, 0) + freqreturn pairsdef merge_vocab(pair, vocab_in):"""根据给定的符号对合并词表"""vocab_out = {}bigram = ' '.join(pair)replacement = ''.join(pair)for word, freq in vocab_in.items():new_word = word.replace(bigram, replacement)vocab_out[new_word] = freqreturn vocab_outdef learn_bpe(vocab, num_merges):"""学习BPE合并规则"""# 初始化词表,将每个单词拆分为字符序列vocab = {' '.join(word) + ' </w>': freq for word, freq in vocab.items()}merges = []for i in range(num_merges):pairs = get_stats(vocab)if not pairs:break# 找出频率最高的字符对best_pair = max(pairs, key=pairs.get)vocab = merge_vocab(best_pair, vocab)merges.append(best_pair)return merges, vocabdef segment_word(word, merges):"""使用学习到的合并规则对单词进行分词"""word = ' '.join(word) + ' </w>'for pair in merges:bigram = ' '.join(pair)replacement = ''.join(pair)word = word.replace(bigram, replacement)return word.split()
2.4 BPE的优缺点
优点:
- 能有效处理未登录词(OOV)问题
- 可以平衡词表大小和序列长度
- 对形态丰富的语言(如德语)效果较好
- 实现简单,训练速度快
缺点:
- 合并规则完全基于频率,不考虑语言学特性
- 可能产生语义上不合理的分词
- 对于亚洲语言(如中文、日文)需要额外的预处理
3. WordPiece算法:Google的语言模型利器
3.1 WordPiece的起源与发展
WordPiece算法最初由Google团队在2012年为语音识别系统开发,后来在2016年的论文《Japanese and Korean Voice Search》中正式发表。它在BERT、DistilBERT等模型中得到广泛应用,成为Google NLP模型的标准分词方法。
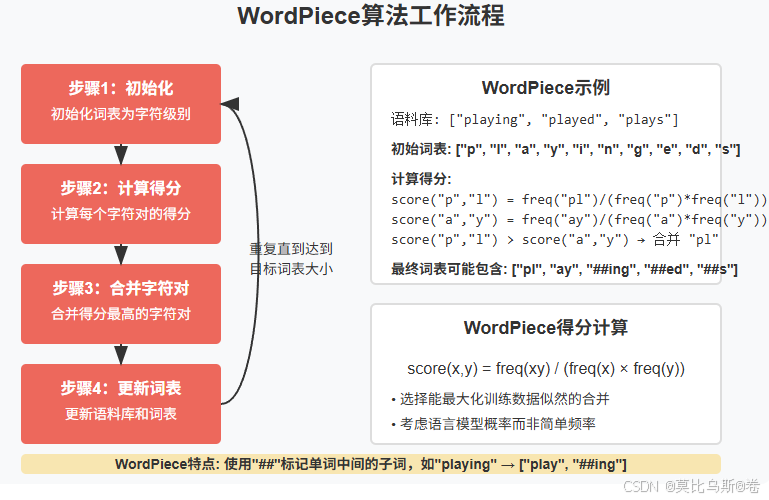
3.2 WordPiece与BPE的区别
WordPiece算法与BPE非常相似,主要区别在于合并标准:
- BPE:选择频率最高的字符对合并
- WordPiece:选择能够最大化训练数据似然的字符对合并
具体来说,WordPiece使用的是一种基于概率的评分机制,计算每个可能的合并对的得分:
score(x,y)=freq(xy)freq(x)×freq(y)score(x,y) = \frac{freq(xy)}{freq(x) \times freq(y)}score(x,y)=freq(x)×freq(y)freq(xy)
这个公式本质上是在计算合并后的单元相对于独立出现时的概率增益。
3.3 WordPiece算法流程
- 初始化词表为所有字符
- 对于每个可能的字符对,计算合并后的得分
- 选择得分最高的字符对合并
- 更新语料库和词表
- 重复步骤2-4,直到达到预设的词表大小或无法继续提高似然
3.4 WordPiece算法Python实现
def get_word_counts(text):"""统计单词频率"""word_counts = {}for word in text.split():word_counts[word] = word_counts.get(word, 0) + 1return word_countsdef initialize_vocab(word_counts):"""初始化词表为字符级别"""vocab = set()subword_counts = {}for word, count in word_counts.items():# 将单词拆分为字符,并添加词尾标记chars = list(word) + ['_']for char in chars:vocab.add(char)# 统计子词频率for i in range(len(chars)):for j in range(i + 1, min(i + 10, len(chars) + 1)):subword = ''.join(chars[i:j])subword_counts[subword] = subword_counts.get(subword, 0) + countreturn vocab, subword_countsdef calculate_scores(subword_counts, vocab):"""计算每个可能合并对的得分"""scores = {}for subword in subword_counts:if len(subword) == 1 or subword in vocab:continue# 尝试所有可能的分割方式for i in range(1, len(subword)):first, second = subword[:i], subword[i:]if first in vocab and second in vocab:# 计算得分:合并后频率 / (第一部分频率 * 第二部分频率)score = subword_counts[subword] / (subword_counts.get(first, 1) * subword_counts.get(second, 1))scores[(first, second)] = scorereturn scoresdef train_wordpiece(text, vocab_size):"""训练WordPiece模型"""word_counts = get_word_counts(text)vocab, subword_counts = initialize_vocab(word_counts)while len(vocab) < vocab_size:scores = calculate_scores(subword_counts, vocab)if not scores:break# 选择得分最高的合并对best_pair = max(scores, key=scores.get)first, second = best_pairnew_token = first + second# 更新词表和计数vocab.add(new_token)subword_counts[new_token] = subword_counts.get(first, 0) + subword_counts.get(second, 0)return vocab
3.5 WordPiece的优缺点
优点:
- 考虑了语言模型的似然,产生的分词更符合语言学直觉
- 对于英语等拼写规则相对固定的语言效果好
- 在BERT等模型中表现出色
缺点:
- 计算复杂度高于BPE
- 对于形态变化丰富的语言可能不如BPE
- 实现细节在Google论文中没有完全公开
4. SentencePiece:无语言边界的通用分词方案
4.1 SentencePiece的创新之处
SentencePiece是由Google在2018年提出的开源分词库,它的最大创新在于实现了完全语言无关的端到端分词。与BPE和WordPiece不同,SentencePiece:
- 将空格视为普通字符:这使得它可以处理任何语言,包括没有明确词边界的语言(如中文、日文)
- 直接从原始文本学习:无需语言特定的预处理
- 支持多种算法:内置了BPE和Unigram两种算法

4.2 Unigram算法原理
SentencePiece除了支持BPE外,还实现了Unigram语言模型算法。Unigram算法基于概率模型,与BPE和WordPiece的贪婪合并策略不同,它采用了一种基于概率的子词分割方法:
- 初始化一个足够大的词表(通常从BPE算法得到)
- 计算每个子词的损失,即从词表中移除该子词导致的模型似然下降
- 按损失排序,移除损失最小的一部分子词
- 重复步骤2-3,直到达到目标词表大小
这种方法的一个重要特点是它可以为同一个单词产生多种可能的分词方式,并根据概率选择最优的一种。
4.3 SentencePiece的使用方法
SentencePiece提供了简单易用的Python接口:
import sentencepiece as spm# 训练模型
spm.SentencePieceTrainer.train(input='corpus.txt', # 输入语料库model_prefix='m', # 模型文件前缀vocab_size=8000, # 词表大小model_type='bpe', # 算法类型:'bpe'或'unigram'normalization_rule_name='nmt_nfkc' # 标准化规则
)# 加载模型
sp = spm.SentencePieceProcessor()
sp.load('m.model')# 编码文本
encoded = sp.encode('This is a test', out_type=int)
print(encoded) # 输出token ID列表# 解码回文本
decoded = sp.decode(encoded)
print(decoded) # 输出 'This is a test'# 获取子词表示
pieces = sp.encode('This is a test', out_type=str)
print(pieces) # 输出子词列表
4.4 SentencePiece的优缺点
优点:
- 完全语言无关,适用于任何语言
- 端到端处理,无需语言特定的预处理
- 支持多种算法(BPE和Unigram)
- 提供了完整的训练和推理API
- 支持直接导出为TensorFlow和PyTorch模型
缺点:
- 将空格视为普通字符可能导致英语等以空格分词的语言的词边界信息丢失
- 在某些特定语言任务上可能不如专门设计的分词器
- Unigram算法的计算复杂度较高
5. 三种算法的对比与选择指南
5.1 性能对比
| 算法 | 训练速度 | 编码速度 | 内存占用 | 多语言支持 | 实现复杂度 |
|---|---|---|---|---|---|
| BPE | 快 | 快 | 低 | 中等 | 简单 |
| WordPiece | 中等 | 快 | 中等 | 中等 | 中等 |
| SentencePiece | 慢 | 快 | 高 | 优秀 | 复杂 |
5.2 应用场景对比
| 算法 | 主要应用模型 | 适用语言 | 特点 |
|---|---|---|---|
| BPE | GPT系列, RoBERTa | 形态丰富的语言 | 基于频率的贪婪合并 |
| WordPiece | BERT, DistilBERT | 英语等拼写规则固定的语言 | 基于似然的合并 |
| SentencePiece | XLM, mBART, mT5 | 任何语言,尤其是多语言模型 | 语言无关的端到端处理 |
5.3 选择指南
根据不同的应用场景,我们可以给出以下选择建议:
-
单语言模型(英语):
- 小规模项目:WordPiece
- 大规模项目:BPE
-
单语言模型(非英语):
- 有明确词边界的语言(如俄语):BPE
- 无明确词边界的语言(如中文):SentencePiece + Unigram
-
多语言模型:
- SentencePiece(几乎是唯一选择)
-
特定领域模型(如医学、法律):
- 考虑使用领域自适应的BPE或WordPiece
6. 实际应用案例分析
6.1 GPT系列中的BPE应用
OpenAI的GPT系列模型使用了一种改进版的BPE算法,称为Byte-level BPE。它的主要特点是:
- 以字节而非Unicode字符为基本单位
- 使用了一种特殊的合并规则来处理UTF-8编码
- 能够处理任何Unicode字符,甚至包括表情符号
这种方法使GPT模型能够处理几乎任何语言和符号,而不会出现未登录词问题。
6.2 BERT中的WordPiece应用
BERT使用WordPiece算法,词表大小为30,522。它的一些特点包括:
- 使用"##"前缀标记单词中间的子词
- 保留了常见的完整单词
- 对英语文本有很好的分词效果
例如,"unaffable"会被分词为[“un”, “##aff”, “##able”],保留了词缀的语义信息。
6.3 多语言模型中的SentencePiece应用
mT5和XLM-R等多语言模型使用SentencePiece进行分词,通常词表大小在10万到25万之间。这些模型能够同时处理100多种语言,而不需要语言特定的预处理。
7. 高级话题与前沿发展
7.1 上下文相关的分词
传统的Tokenization方法都是上下文无关的,即同一个单词无论在什么上下文中都会被相同地分词。一些研究开始探索上下文相关的分词方法,例如:
- 动态分词:根据上下文动态调整分词策略
- 自适应分词:在训练过程中学习最优的分词方式
7.2 字符级与子词级的权衡
字符级模型可以完全避免OOV问题,但序列长度会大大增加;词级模型序列短但词表巨大且有OOV问题;子词级是一种折中方案。一些研究尝试结合多种粒度的表示:
- 混合粒度模型:同时使用字符、子词和词级表示
- 层次化分词:先分词再分字符
7.3 Tokenization-free模型
一些研究尝试完全绕过Tokenization步骤,直接在原始文本或字节序列上训练模型:
- ByteNet:直接在字节序列上操作
- CharFormer:字符级Transformer
- Canine:无需分词的预训练模型
这些方法虽然理论上更加灵活,但目前在大多数任务上的性能仍不如基于子词的方法。
8. 实用技巧与最佳实践
8.1 词表大小的选择
词表大小是一个关键超参数,它影响模型的性能、训练速度和内存占用:
- 太小:会导致序列过长,信息碎片化
- 太大:会增加模型参数,降低泛化能力
一般建议:
- 单语言模型:1万-5万
- 多语言模型:5万-25万
8.2 特殊标记的处理
在实际应用中,需要特别注意特殊标记的处理:
- [UNK]:未登录词标记
- [CLS]:分类标记
- [SEP]:分隔标记
- [PAD]:填充标记
- [MASK]:掩码标记
这些标记需要在词表中保留特定的ID,并在预处理和后处理中正确处理。
8.3 多语言模型的分词策略
对于多语言模型,一些实用策略包括:
- 使用足够大的词表(至少10万)
- 确保各语言的训练数据平衡
- 考虑使用语言ID前缀
- 对低资源语言进行过采样
9. 总结与展望
9.1 三种算法的核心差异
- BPE:基于频率的贪婪合并,简单高效
- WordPiece:基于似然的合并,更符合语言学直觉
- SentencePiece:语言无关的端到端处理,支持多种算法
这三种算法各有优缺点,选择哪一种应该基于具体的应用场景和需求。
9.2 Tokenization的未来发展
Tokenization技术仍在不断发展,未来可能的方向包括:
- 更智能的上下文相关分词
- 多模态分词:处理文本、图像、音频等多种模态
- 可微分分词:将分词过程纳入端到端训练
- 个性化分词:根据用户或领域自适应调整
随着大语言模型的不断发展,Tokenization技术也将继续演进,为更强大、更灵活的模型奠定基础。
10. 参考资料
- Sennrich, R., Haddow, B., & Birch, A. (2016). Neural Machine Translation of Rare Words with Subword Units.
- Kudo, T. (2018). Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates.
- Kudo, T., & Richardson, J. (2018). SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing.
- Wu, Y., et al. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
- Radford, A., et al. (2019). Language Models are Unsupervised Multitask Learners.
ization: Improving Neural Network Translation Models with Multiple Subword Candidates. - Kudo, T., & Richardson, J. (2018). SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing.
- Wu, Y., et al. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
- Radford, A., et al. (2019). Language Models are Unsupervised Multitask Learners.
- Devlin, J., et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.