【Linux 34】Linux-主从复制
一、主从复制基础知识
在 标准的 MySQL 主从复制架构 中,主从复制默认是单向的,且遵循 “主库可写、从库只读” 的核心原则。
1.作用:
读写分离:主库负责写操作,从库承担读操作
数据备份:从库可作为主库的实时备份,避免备份操作对主库性能的影响(如锁表
2.工作原理
- 主从复制的核心是通过二进制日志(binlog)实现数据同步,完整流程如下:
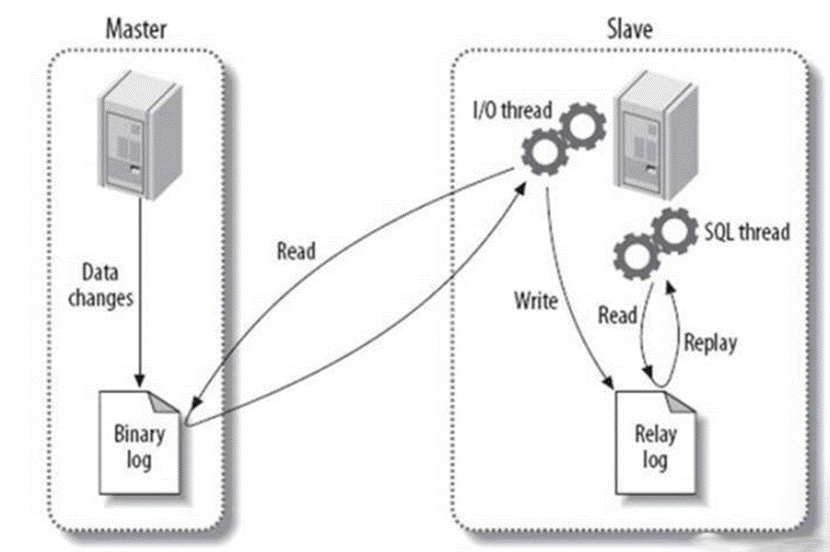
(1)主库生成 binlog:主库执行写操作(增删改)后,会将操作以事件(event)形式记录到二进制日志中,并维护一个 binlog 索引文件(.index)记录所有 binlog 文件列表。
(2)从库 I/O 线程连接主库:从库启动后,从库的I/O 线程会根据配置的主库信息(IP、用户、密码)建立 TCP 连接,请求主库发送 binlog。
(3)主库 dump 线程响应:主库接收到从库请求后,启动 dump 线程,根据从库指定的 binlog 文件名和位置,将后续的 binlog 事件推送给从库(或从库主动拉取)。
(4)从库写入中继日志:从库 I/O 线程将接收到的 binlog 事件写入本地中继日志(Relay log),并记录当前同步到的 binlog 位置(便于中断后继续同步)。
(5)从库 SQL 线程执行同步:从库 SQL 线程读取中继日志中的事件,按顺序在从库中重新执行(模拟主库的写操作),最终保证主从数据一致。
核心:数据一致、同步
存在的问题:时间复制延迟(不能过大)(无法避免)
① 延迟原因
- 网络延迟:主从库跨机房或网络带宽不足,导致 binlog 传输缓慢。
- 主库写入密集:主库短时间内大量写操作(如批量插入),binlog 生成速度超过从库同步速度。
- 从库负载过高:从库同时承担大量查询或其他任务,导致 SQL 线程执行缓慢。
- 大事务影响:主库执行长事务(如耗时 10 分钟的更新),从库需等整个事务 binlog 传输完成后才能执行,造成一次性延迟。
- 参数配置不合理:如从库 innodb_buffer_pool_size 过小,导致 SQL 线程执行时频繁磁盘 IO。
② 解决方法(详细措施)
- 优化网络:主从库部署在同一机房,增加网络带宽(使用万兆网络);通过压缩 binlog(MySQL 8.0 支持 binlog 压缩)减少传输量。
- 从库性能升级:提升从库硬件配置(如使用高IO的磁盘,SSD),避免从库承担非必要查询。
- 并行复制:MySQL 5.6 + 支持基于库的并行复制,MySQL 5.7 + 支持基于组提交的并行复制,让 SQL 线程多线程并行执行,缩短同步时间。
- 拆分大事务:将主库大事务拆分为多个小事务,避免单次同步阻塞。
- 半同步复制:主库开启半同步复制(需安装插件),确保至少一个从库接收 binlog 后,主库才返回写操作成功,减少数据丢失风险(但会增加主库写延迟,需权衡)。
- 监控延迟并告警:通过 Seconds_Behind_Master 监控延迟,超过阈值(如 10 秒)时告警,及时排查。
3.常见复制架构:
3.双主复制:双向的主从复制(两个主句库互为对方的主从,两个数据库都可以执行写操作并且都可以复制给对方)
二、主从复制的配置
前提配置:两个机子,不同ip和不同Mysql数据库。
关闭SELinux、时间同步
1、主库配置(前提:主从库 MySQL 版本一致,建议 8.0+)
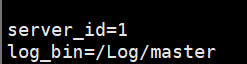
①开启二进制日志 //编辑主库配置文件(my.cnf ,之后systemctl restart mysqld重启

② 登录主库 ,创建允许从库连接的用户(限制从库 IP,增强安全性
- >CREATE USER '用户名'@'从库IP' IDENTIFIED WITH mysql_native_password BY '123456';
- //创建用户(repl为用户名,从库IP替换为实际地址)
- //明确使用mysql_native_password函数 便于从库连接
- >GRANT REPLICATION SLAVE ON *.* TO '用户名'@'从库IP'; //授权复制权限
- 这是 MySQL 专门用于主从复制的权限,作用只有一个 —— 允许客户端(从库 IO 进程)连接主库,拉取主库的二进制日志(binlog),没有其他任何权限。
- 用户被限制在 “从库 IP” 登录,登录主体是 “从库进程”,不是人,权限仅够 “复制”,无其他权限。
- >FLUSH PRIVILEGES; // 刷新权限

③主库完全备份 //master-data=2会在备份文件中记录binlog文件名和位置
- # mysqldump -uroot -p --all-databases --master-data=2 --single-transaction > full_backup.sql
- # mysqldump -uroot -p --lock-all-tables --source-data=2 --all-databases > /Log/data.sql
- //替换过时的 --master-data 为 --source-data
--single-transaction 是 “快照读”(适合 InnoDB,不阻塞写),--lock-all-tables 是 “全局锁”(适合全引擎,阻塞写)。
备份文件中会包含类似如下记录(后续从库需用到):
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=154;
- 检查
- (1)基础检查
- # ls -lh /Log/data.sql //输出中能看到该文件
- # du -sh /Log/data.sql //正常备份文件大小应 远大于 0 字节
- # head -n 20 /Log/data.sql //正常的 MySQL 备份文件头部会包含版本信息和备份参数

- (2)深度检查
创建临时数据库(测试用)
# mysql -uroot -p //登录MySQL
>CREATE DATABASE test_backup; exit; //创建测试库
恢复备份到测试库
# mysql -uroot -p test_backup < /Log/data.sql //将备份文件恢复到test_backup库
// 若恢复过程无报错(如 “语法错误”“表已存在” 等),说明备份文件无损坏。
验证恢复的数据
# mysql -uroot -p test_backup //登录测试库,检查关键表和数据是否完整
>SHOW TABLES; //查看库中表是否存在
>SELECT COUNT(*) FROM user; //查看表数据量(与原库对比)
>SELECT * FROM user WHERE username = 'admin'; //查看具体数据(与原库对比)
// 若表结构、数据量、具体记录与原库一致,说明备份完全有效。
# scp /opt/data.sql root@从库ip:/opt/ //将备份文件拷贝到从库

2、从库配置
用从库的普通账号登录 MySQL,该账号没有 SUPER、REPLICATION_SLAVE_ADMIN 等权限,无法执行 CHANGE MASTER TO、START SLAVE 等复制操作,提示 Access denied。
解决:改用从库的 root 账号(拥有最高权限)操作,才能执行复制配置命令。
前提:安装Mysql并设置开启自启动

![]()
①配置从库基础参数 //编辑从库配置文件并且重启,修改密码

MySQL 主从复制要求主库和从库的 server_id 必须唯一(用于识别主从身份)
②从库恢复主库的备份 //将主库的 /opt/data.sql 复制到从库,恢复数据
- # mysql -u root -p < /opt/data.sql
![]()
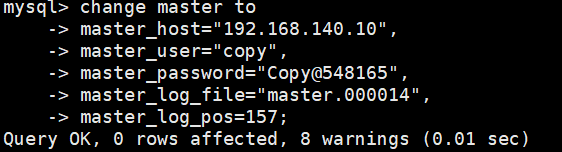
③从库连接主库 //登录从库 MySQL,设置主库信息(备份文件中的 binlog 文件名和位置)
去10机子搜

- # head -n 100 /Log/data.sql | grep "CHANGE MASTER TO"
- 此记录通常位于备份文件的 前 100 行内(因为--source-data=2 或 --master-data=2参数会在备份开头记录主库的 binlog 位置),可以直接查看文件头部

④启动从库复制线程
- >START SLAVE; //启动I/O线程和SQL线程

⑤验证复制线程启动成功 //查看复制线程(IO线程和SQL线程)的状态
- >SHOW SLAVE STATUS\G;
![]()
| 字段名 | 正常取值 | 含义与异常排查 |
|---|---|---|
| Slave_IO_Running | Yes | 负责从主库拉取 binlog 日志的线程。 若为 No/Connecting:需检查主库 IP / 端口是否通、从库 CHANGE MASTER TO 配置的主库账号密码是否正确、主库 binlog 是否开启。 |
| Slave_SQL_Running | Yes | 负责执行从主库拉取的 binlog 日志(SQL 语句) 的线程。 若为 No:通常是从库执行 SQL 时出错(如主从数据不一致、表结构不匹配),需看下方 Last_SQL_Error 定位问题。 |
| 字段名 | 正常状态 | 含义与异常排查 |
|---|---|---|
| Master_Log_File | 与主库 SHOW MASTER STATUS; 的 File 一致(或接近) | 从库当前正在拉取的主库 binlog 文件名。 若与主库差异过大:说明从库拉取 binlog 缓慢(可能网络延迟、主库 binlog 生成过快)。 |
| Read_Master_Log_Pos | 接近主库 SHOW MASTER STATUS; 的 Position | 从库已从主库拉取到的 binlog 位置(字节数)。 若与主库 Position 差距大:表示 “拉取延迟”,需排查网络带宽、主库 IO 压力。 |
| Relay_Master_Log_File | 与 Master_Log_File 一致(或仅差 1 个文件) | 从库正在执行的 relay log 对应的主库 binlog 文件名(relay log 是从库本地存储的主库 binlog 副本)。 |
| Exec_Master_Log_Pos | 接近 Read_Master_Log_Pos | 从库已执行完成的 binlog 位置。若与 Read_Master_Log_Pos 差距大:表示 “执行延迟”(从库 SQL 线程执行慢,可能从库 CPU/IO 压力大、存在大事务)。 |
| Seconds_Behind_Master | 0(或接近 0) | 从库相对于主库的数据同步延迟时间(秒)。若持续大于 0:说明存在同步延迟,需结合上述 Read/Exec 位置差判断是 “拉取延迟” 还是 “执行延迟”;若为 NULL:表示复制线程未正常运行(需回头检查 Slave_IO_Running/Slave_SQL_Running)。 |
若异常
| 字段名 | 作用 | 常见异常示例与解决思路 |
|---|---|---|
| Last_IO_Error | Slave_IO_Running 异常的原因 | 示例 1:Access denied for user 'repl'@'从库IP' → 主库给从库的复制账号密码错误,需重新在主库授权并更新从库配置。 示例 2:Can't connect to MySQL server on '主库IP' (113) → 主从网络不通,检查防火墙、主库绑定地址(bind-address 是否允许从库访问)。 |
| Last_SQL_Error | Slave_SQL_Running 异常的原因 | 示例 1:Duplicate entry '123' for key 'PRIMARY' → 主从数据不一致(从库已存在主库要插入的主键数据),需手动同步不一致的数据后重启复制。示例 2:Table 'test.t1' doesn't exist → 主库有表 test.t1 但从库没有,需先在从库创建相同表结构。 |
Master_Host/Master_User /Master_Port | 校验从库配置的主库信息 | 确认是否与主库实际 IP、复制账号、端口一致(若配置错误,直接导致 IO 线程连不上主库)。 |
| Skip_Counter | 通常为 0 | 若手动执行过 SET GLOBAL sql_slave_skip_counter = N(跳过 N 个错误事务),此处会显示非 0 值,需注意:跳过错误可能导致数据不一致,仅临时应急使用。 |
// 通过这两个值的差,判断数据是否一致 数字一样就是同步了,不一样就是延迟很大
>SHOW SLAVE Hosts; //在主库上查看连接的从库信息验证

三、读写分离
(一)读写分离介绍
- 加快数据库工作效率
- 在主从复制环境 ,主库执行写操作,从库执行读操作,写操作(如订单创建)和读操作(如数据分析)在不同库执行,避免长查询阻塞事务提交。尤其适合读多写少场景(如电商商品详情页、新闻资讯)。
- 提升查询性能:多从库可分担读请求(横向扩展),用户查询可被分发到不同从库,减少单库负载。
2、实现方案
| 方案 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
在业务代码中 固定写数据库地址 | 实现简单,无需额外组件 | 耦合业务逻辑,改造成本高,难维护 | 小型项目、临时过渡 |
数据中间件 | |||
MySQL- Proxy | 官方工具,轻量 | 功能简单,性能一般,社区维护较弱 | 简单测试环境 |
Amoeba(阿里) | 开源,轻量,专注读写分离 | 停止维护,不支持 MySQL 8.0 新特性 | legacy 系统兼容 |
MyCAT | 国内开源,成熟,支持分库分表 + 读写分离,中文文档丰富 | 配置稍复杂,需 JDK 环境 | 中大型生产环境,需扩展性 |
Atlas(360) | 基于 MySQL Proxy 优化,性能好 | 功能较单一,定制化能力弱 | 纯读写分离需求,对性能敏感 |
ProxySQL | 高性能,功能全(读写分离、故障切换等),支持 MySQL 8.0,动态配置 | 配置复杂,学习成本高,文档以英文为主 | 中大型高并发场景,核心业务 |
(二)前置环境准备(主从复制确认)
ProxySQL
核心功能:读写分离、 支持基于 “用户、Schema(数据库)、SQL 语句特征” 的多层路由、结果缓存(减轻后端压力)、健康状态检测(保障高可用)
1、环境描述
192.168.140.10 作为主库 MySQL 8.0
192.168.140.20 作为从库 MySQL 8.0
192.168.140.30 作为 proxysql
2、基础配置
(1)主库(192.168.140.10)、从库(192.168.140.20)已完成主从复制。
(2)从库已添加read_only参数(避免从库写入)。
①临时
- # mysql -uroot -pRoot@548165 -h192.168.140.11
- >SET GLOBAL read_only = 1; //开启只读模式(限制普通用户写入,root 等超级用户仍可写入)
- >SET GLOBAL super_read_only = 1; //同时开启 `super_read_only`,限制超级用户写入
②永久

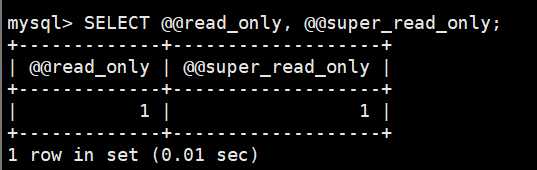
- read_only=1 // 限制非超级用户(没有 SUPER 权限的普通用户)执行写入操作
- super_read_only=1 //MySQL 8.0+ 新增在 read_only=1 的基础上,进一步限制超级用户(包括 root)执行写入操作,实现 “彻底只读”。
- >SELECT @@read_only, @@super_read_only; //查看当前只读状态
3、30机,安装proxysql并启动
cat > /etc/yum.repos.d/proxysql.repo << EOF
[proxysql]
name=ProxySQL YUM repository
baseurl=https://repo.proxysql.com/ProxySQL/proxysql-2.6.x/centos/\$releasever
gpgcheck=1
gpgkey=https://repo.proxysql.com/ProxySQL/proxysql-2.6.x/repo_pub_key
EOF
- # yum clean all //清理 YUM 缓存
- // 当 YUM 源配置修改后(如更换了 proxysql.repo 内容),旧缓存可能导致 YUM 读取到过时的源信息,从而安装失败或版本错误;清理缓存可以释放磁盘空间(尤其是长期使用的服务器,缓存的 .rpm 文件可能占用较多空间)。
- # yum makecache //生成 YUM 缓存
- // YUM 安装软件时,需要先读取软件包的元数据来确认版本、依赖等信息。
makecache提前将这些信息缓存到本地,后续安装时无需重复从网络获取,加快操作速度;在修改 YUM 源配置后(如添加了 ProxySQL 源),执行makecache可以让新配置的源立即生效,确保能获取到对应的软件包列表。 - # yum install -y proxysql mariadb
- // ProxySQL 本身是中间件,不自带 mysql 客户端工具。而后续配置 ProxySQL 时,必须使用 mysql 客户端工具。mariadb 包提供的 mysql 命令与 MySQL 客户端完全兼容,因此在安装 ProxySQL 时,通常会一并安装 mariadb 以满足后续操作需求。
- # systemctl enable --now proxysql //启动

- netstat -tunlp | grep proxysql //验证端口监听(6032=管理端,6033=业务端)

- 6032端口: proxysql管理端口,管理和配置 ProxySQL,或查看其运行状态与统计信息等。
- 6033端口: proxysql业务连接端口,是 ProxySQL 面向应用程序提供数据库服务的端口。
proxysql的后台
- # mysql -uadmin -padmin -h127.0.0.1 -P6032 //连接 ProxySQL 管理端口 ,默认账号admin 密码:admin,端口:6032
- > show databases; //ProxySQL 内置的核心库
| 数据库名 | 核心作用 |
|---|---|
| main | 核心配置库,所有 ProxySQL 的配置都保存在此库的表中 特点:内存级存储,修改后需执行 LOAD ... TO RUNTIME 生效,SAVE ... TO DISK 持久化到 disk 库。 |
| disk | 持久化配置库,是 main 库的磁盘备份。作用:当 ProxySQL 重启时,会从 disk 库加载配置,避免配置丢失(通过 SAVE ... TO DISK 命令将 main 库配置同步至此)。 |
| stats | 实时统计信息库,记录 ProxySQL 的运行指标和 SQL 执行情况。 |
| monitor | 健康检查库,存储对后端 MySQL 服务器的健康检查结果。 |
| stats_history | 历史统计库,持久化存储 stats 库的历史数据(如过去的连接数、SQL 执行统计等)。作用:用于分析 ProxySQL 的长期运行趋势,默认保留一定时间的历史数据。 |
| 表名 | 核心作用 | 关键字段与使用场景 |
|---|---|---|
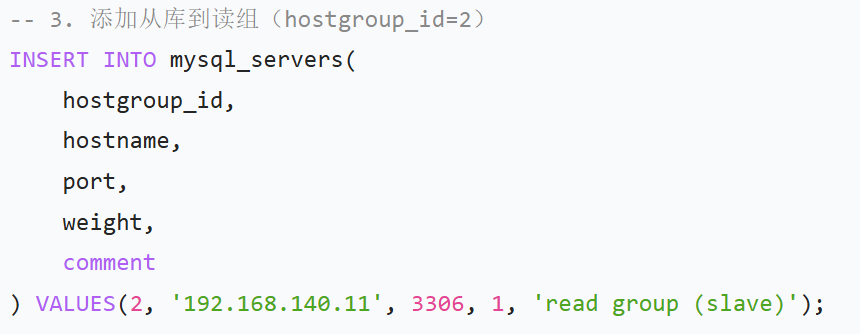
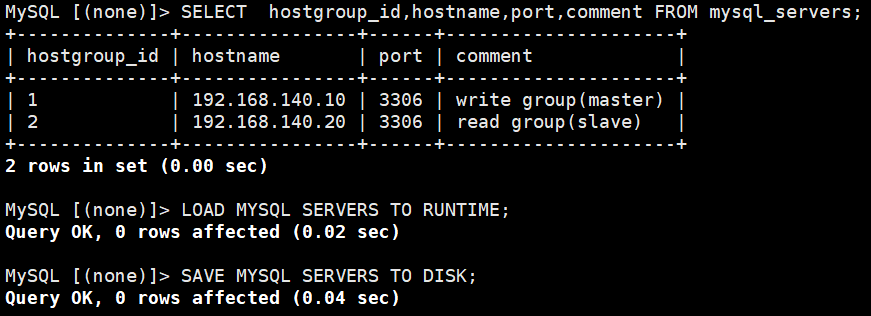
| mysql_servers | 存储后端 MySQL 服务器(主库、从库)的连接信息 | - hostgroup_id:服务器组 ID(如 1 = 写组,2 = 读组) - hostname/port:数据库 IP 和端口 - weight:权重(负载均衡时控制请求分配比例) - 场景:添加主从库到对应的分组,实现读写分离的基础 |
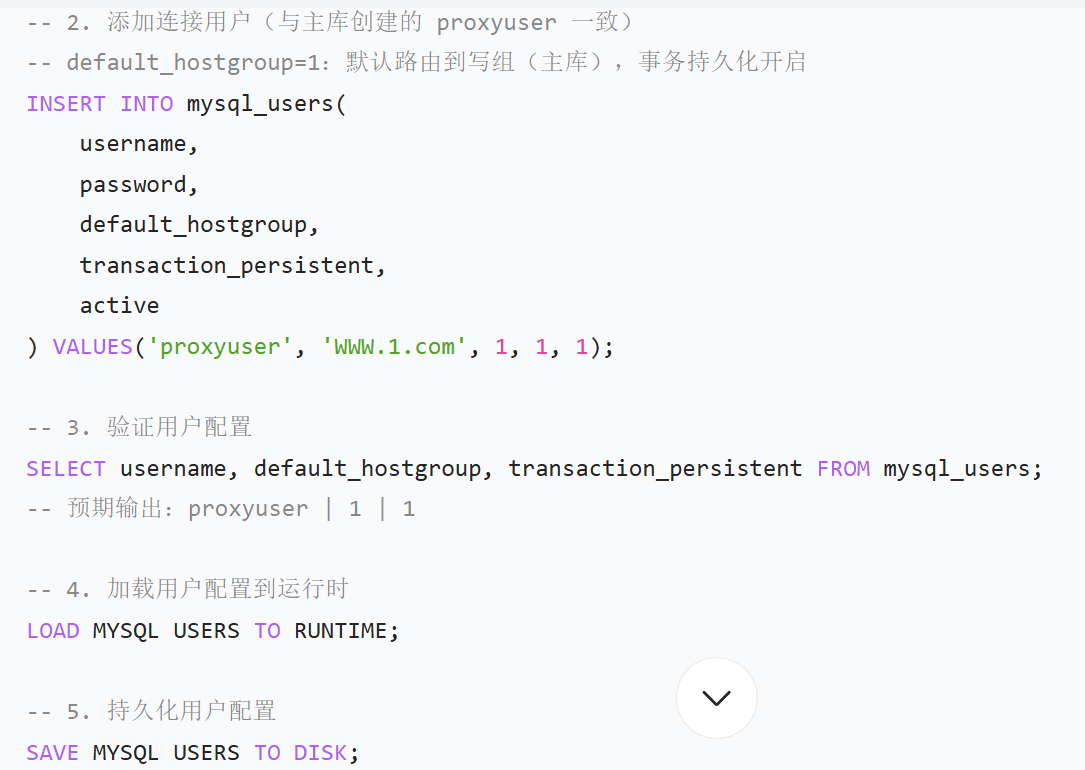
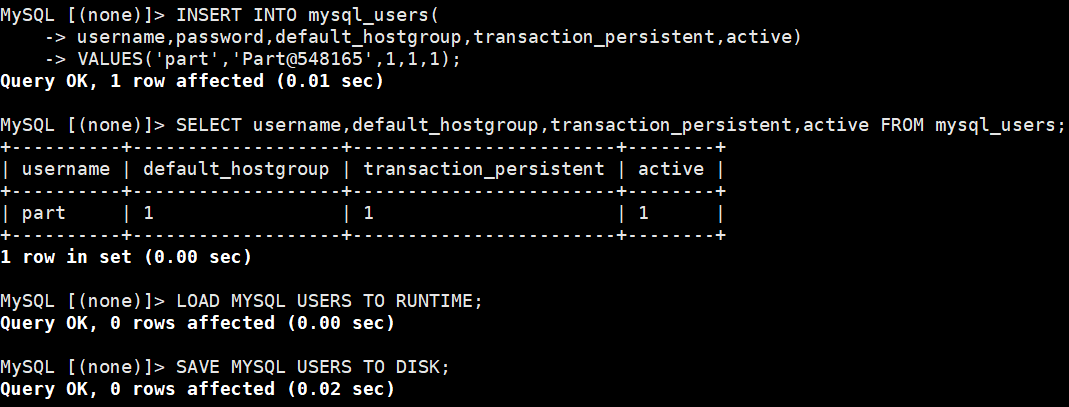
| mysql_users | 存储连接后端数据库的用户信息(ProxySQL 用这些用户连接主从库) | - username/password:后端数据库的用户名和密码(如你创建的 proxyuser)- default_hostgroup:默认路由组(如默认路由到写组 1)- transaction_persistent:事务持久性(1 = 开启,确保事务内的 SQL 路由到同一节点)- 场景:配置 ProxySQL 连接主从库的用户,确保权限正确 |
| mysql_query_rules | 定义 SQL 语句的路由规则(核心的读写分离规则配置表) | - rule_id:规则 ID(数字越小优先级越高) - match_digest:匹配 SQL 语句的正则表达式(如 ^SELECT 匹配查询) - destination_hostgroup:目标分组(如匹配后路由到读组 2) - apply:1 = 匹配后不再执行后续规则 - 场景:配置 SELECT 路由到读组、INSERT/UPDATE 路由到写组 |
| global_variables | 存储 ProxySQL 的全局配置参数(如端口、日志、健康检查等) | - mysql-monitor_username:健康检查用户(如 healthuser)- mysql-monitor_password:健康检查密码- admin-admin_credentials:管理端账号密码- 场景:配置健康检查用户、修改管理端密码等 |
| mysql_replication_hostgroups | 自动管理主从复制的分组(适用于主从切换场景) | - writer_hostgroup:写组 ID - reader_hostgroup:读组 ID - check_type:主从状态检查方式(如 read_only 检查从库是否只读) - 场景:当主库故障时,自动将从库提升为写组(需配合健康检查) |
| runtime_* 系列表(如 runtime_mysql_servers) | 运行时配置表(main 库配置 LOAD 后生效的实际运行状态) | 只读表,用于查看当前生效的配置(如 runtime_mysql_query_rules 显示正在使用的路由规则),修改需通过对应的非 runtime 表(如 mysql_query_rules)- 场景:验证配置是否已 LOAD 到运行时 |
4、主库
①创建 ProxySQL 授权用户(192.168.140.10)
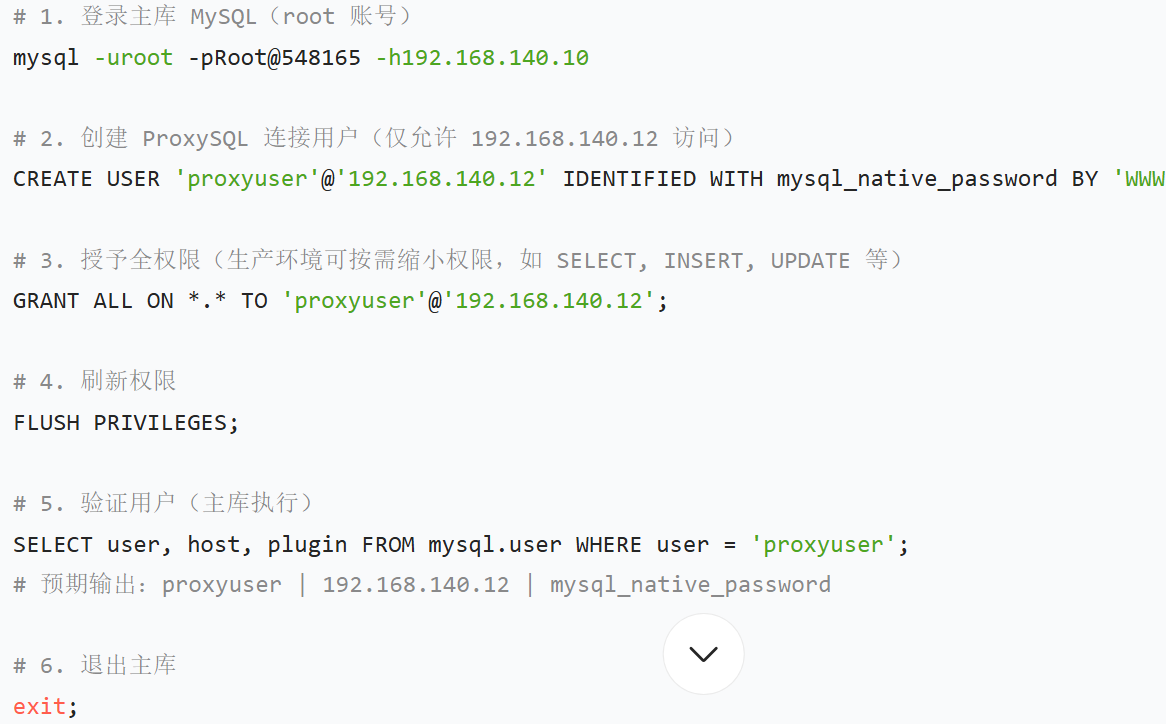
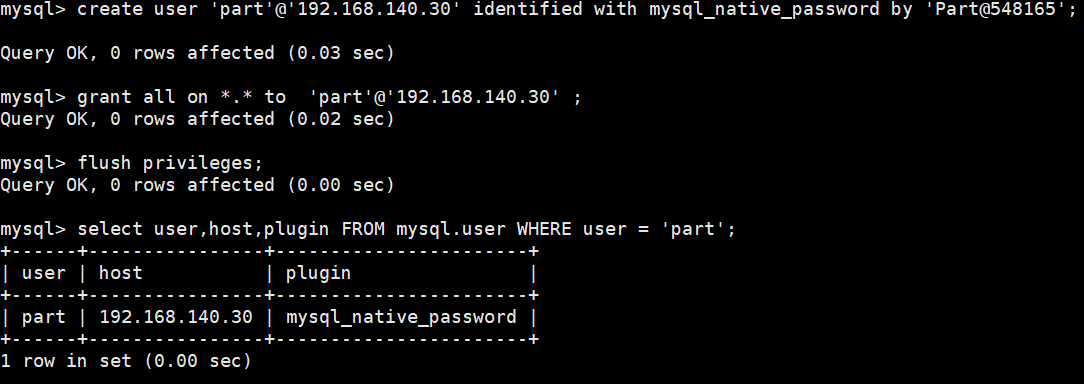
②主库上配置健康用户
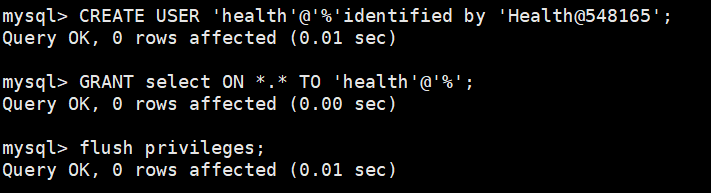
5、ProxySQL 管理端(6032 端口)
配置后端数据库、用户、路由规则
核心步骤:添加服务器组 → 配置连接用户 → 健康检查 → 读写路由。
(1)添加后端数据库服务器(区分读写组)
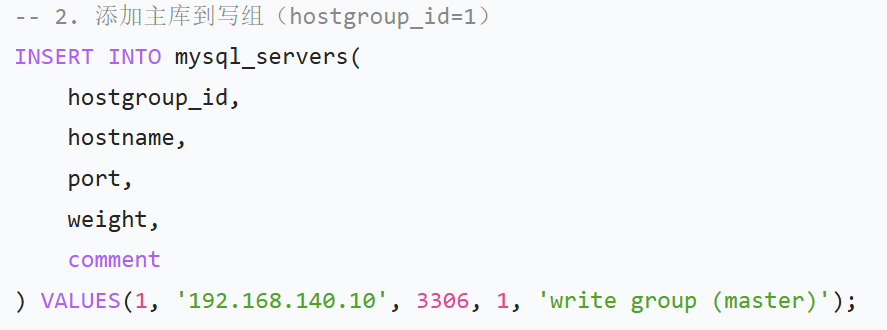


(2)ProxySQL 上配置连接后端数据库的用户
// username 和 password 必须与主库(及从库)中实际存在的用户完全一致
(3)ProxySQL 上配置健康检查用户(监控后端数据库状态)
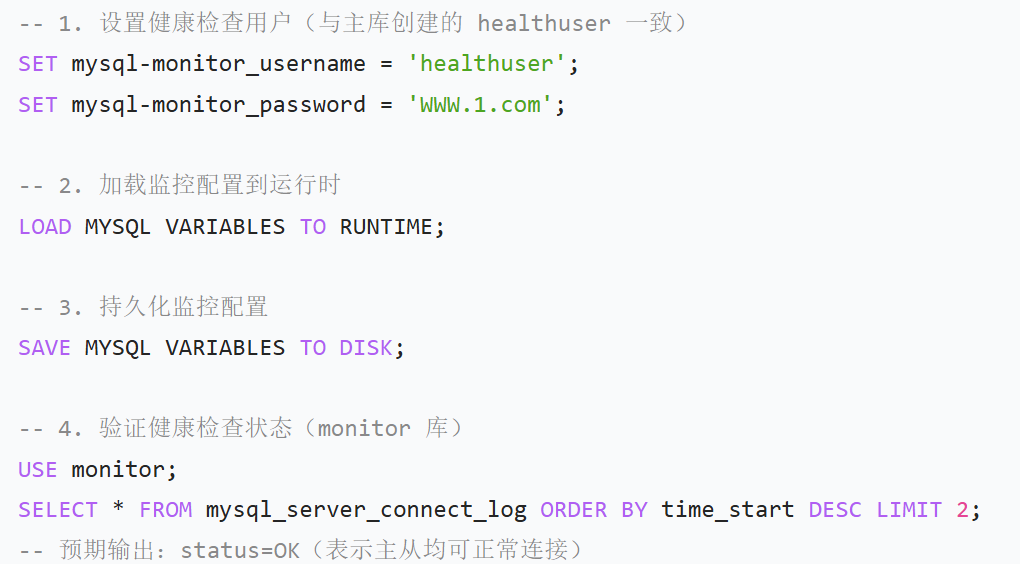

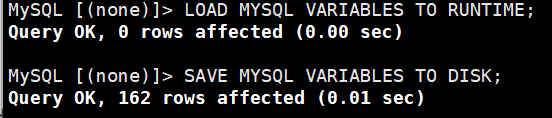

(4)添加读写分离路由规则
- 规则 1:
SELECT ... FOR UPDATE(行锁查询)→ 路由到写组(主库) - 规则 2:普通
SELECT→ 路由到读组(从库)
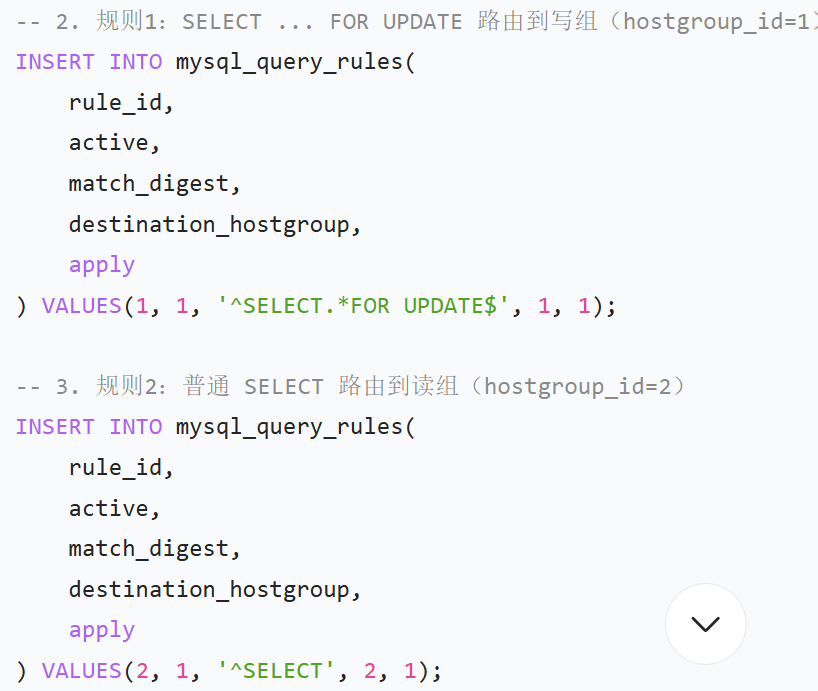


6、读写分离测试
- # mysql -upart -pPart@548165 -h127.0.0.1 -P6033 // 连接 ProxySQL 业务端口
①写/读操作
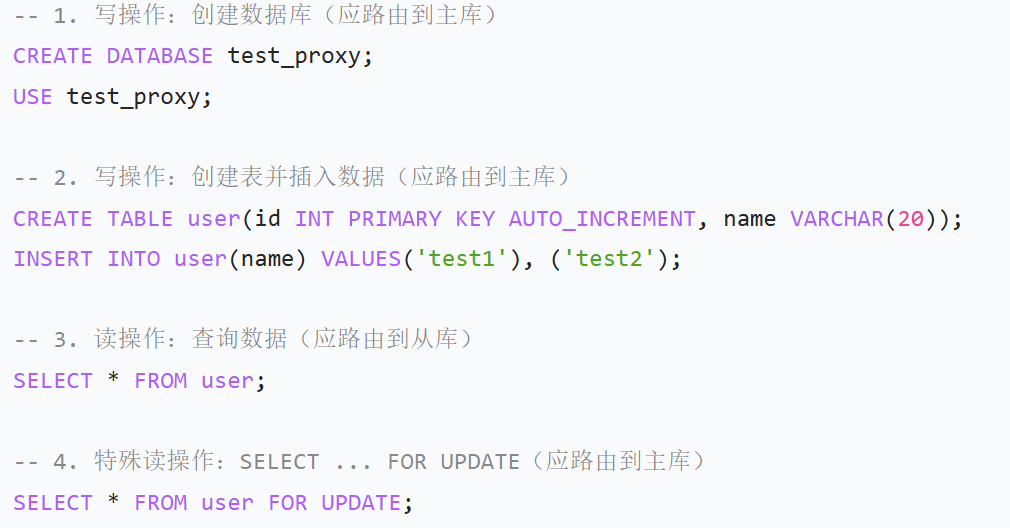
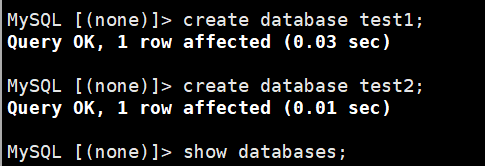
![]()
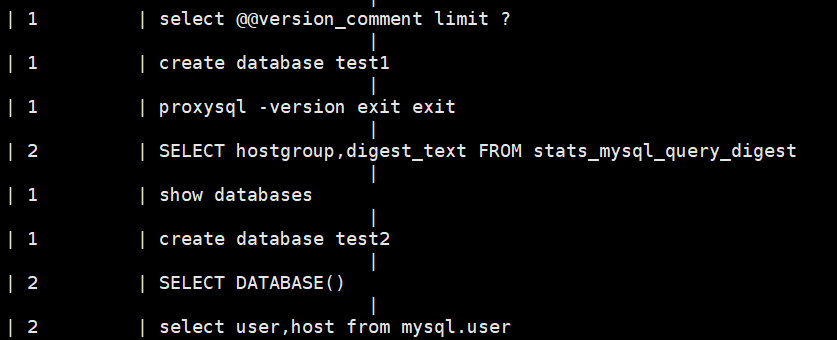
② 验证读写分离效果(ProxySQL 管理端)
- >mysql -uadmin -padmin -h127.0.0.1 -P6032 // 注意参数间无特殊字符
![]()
- SELECT hostgroup, digest_text FROM stats.stats_mysql_query_digest; //查询 stats 库中表
![]()
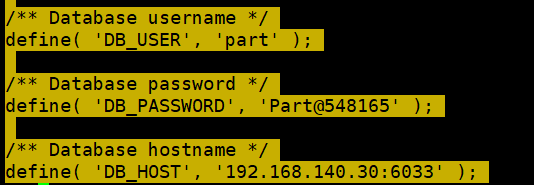
7、WordPress 配置 ProxySQL 连接
修改 WordPress 配置文件 wp-config.php,将数据库连接指向 ProxySQL 业务端(192.168.140.12:6033)
验证 WordPress 连接
- 访问 WordPress 前端页面,确认能正常加载;
- 在 WordPress 后台发布一篇文章(写操作,路由到主库);
- 前端刷新页面查看文章(读操作,路由到从库);
- 通过 ProxySQL 管理端 stats_mysql_query_digest 确认路由记录。