视觉语言模型(VLM)
文章目录
- 一、视觉语言模型
- 二、模型架构
- 三、应用场景
一、视觉语言模型
视觉语言模型(VLM)是融合大语言模型(LLM)与视觉编码器的复合型AI模型,核心能力在于打破文本与视觉信息的壁垒,实现“看图说话”的智能交互。
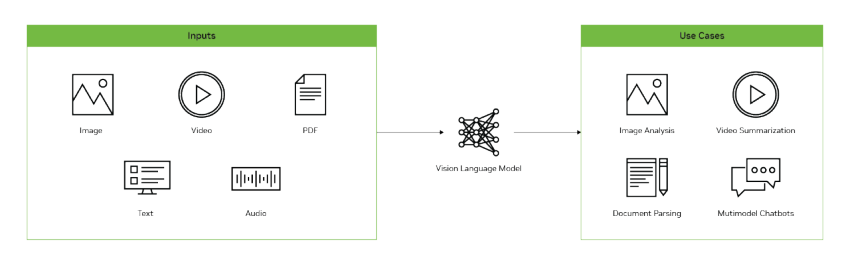
从输入输出逻辑来看,VLM支持图像、视频与文本的混合输入,最终以文本形式输出结果。具体应用场景包括为图像生成精准描述、解答与视觉内容相关的问题,以及识别图像或视频中的关键元素,覆盖从“感知”到“理解”的视觉处理全流程。
与传统计算机视觉模型(如YOLO)相比,二者在技术路径与功能边界上存在显著差异:传统模型多针对特定任务(如图像分类、目标检测)或依赖固定标签集合设计,任务适应性较窄;而VLM依托LLM的强大语言理解能力,在大规模图文配对数据上完成训练,不仅能解读自然语言指令,还可灵活适配多种视觉任务,无需针对单一场景重复优化。
在交互体验上,VLM延续了LLM(如ChatGPT)的便捷性——用户可提交图文混合的提示信息,让模型生成回答、总结核心内容或解释视觉细节,还能基于历史对话进行多轮交互,并在对话过程中随时补充新图像以拓展讨论维度。此外,VLM也可作为核心模块集成至视觉智能体中,为复杂视觉任务(如场景规划、动态目标跟踪分析)提供底层技术支撑。
二、模型架构
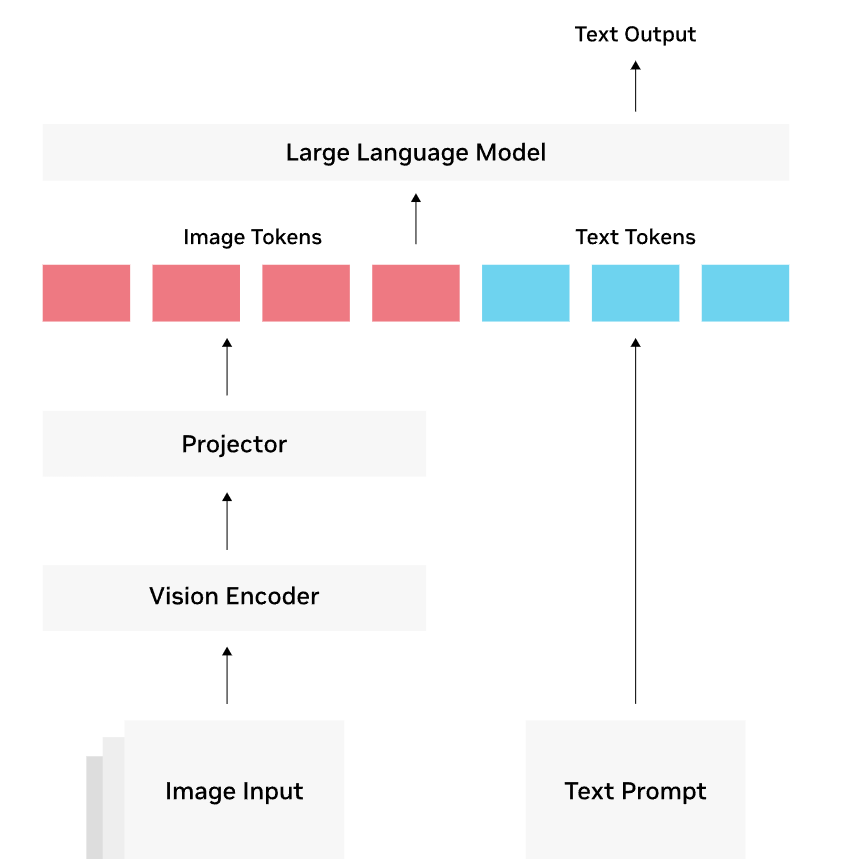
大多数视觉语言模型(VLM)由三部分组成:
- 视觉编码器:通常是一个基于 transformer 架构的 CLIP(Contrastive Language–Image Pre-training) 模型,该模型已在数百万个图像-文本对进行了训练,具有图像与文本的关联能力。
- 投影器(Projector):由一组网络层构成,将视觉编码器的输出转换为 LLM 可以理解的方式,一般解读为图像标记 (tokens)。。
- 大语言模型(LLM):用来理解和生成自然语言,几乎所有已有的 LLM 都可以用于构建 VLM。
三、应用场景
- 视觉问答
- 目标检测

- OCR

参考:
- https://www.bilibili.com/video/BV1NP8xzrEDa/
- https://www.cnblogs.com/O-ll-O/articles/18893317
- https://www.cnblogs.com/wujianming-110117/p/19037023