【Task04】:向量及多模态嵌入(第三章1、2节)
【项目地址】https://github.com/datawhalechina/all-in-rag
第一节 向量嵌入
一、向量嵌入基础
1. 核心概念
- 定义:向量嵌入(Embedding)是将文本、图像等复杂高维数据,转换为低维、稠密连续数值向量的技术,每个数据对象对应向量空间中唯一 “坐标”,该向量承载原始数据关键信息。
- 语义表示核心原则:向量空间中,语义相似的数据对象(如 “猫” 和 “猫咪”)向量距离更近,不相关对象(如 “猫” 和 “汽车”)向量距离更远。
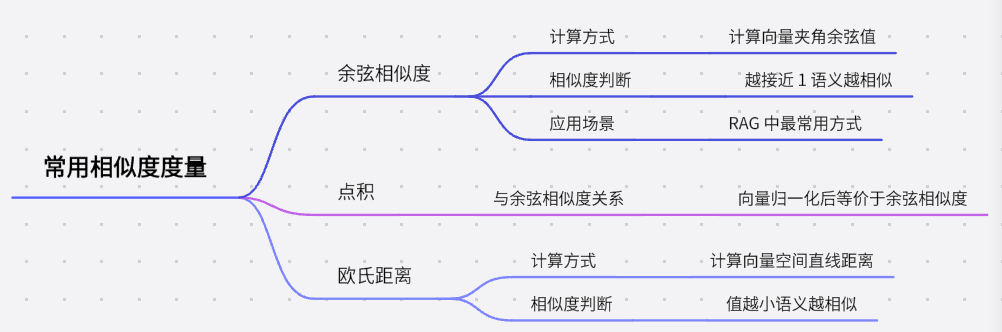
- 常用相似度度量:
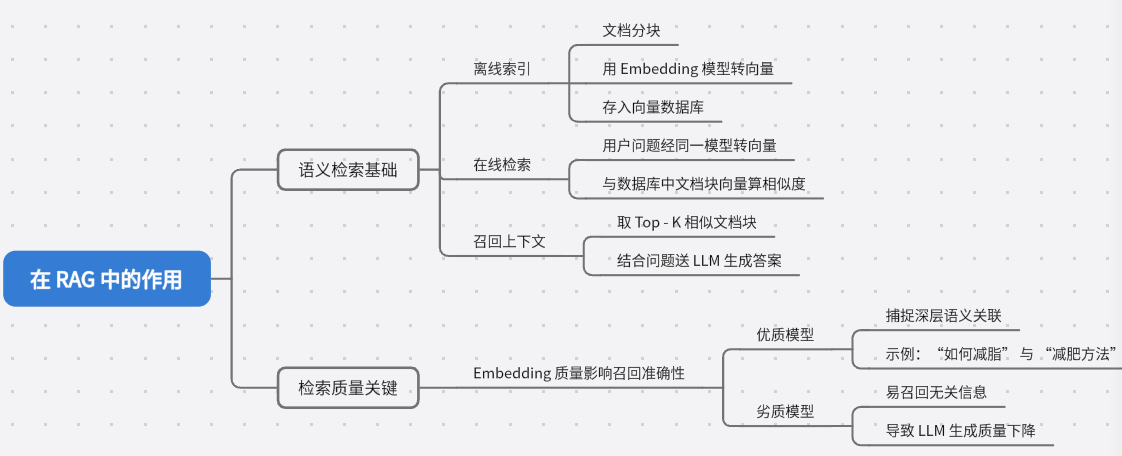
2. 在 RAG 中的作用
二、Embedding 技术发展历程
| 阶段 | 代表模型 | 核心特点 | 局限性 |
|---|---|---|---|
| 静态词嵌入(2013-2014) | Word2Vec、GloVe | 为每个单词生成固定向量,支持基础语义运算(如 “国王 - 男人 + 女人≈王后”) | 无法处理一词多义(如 “苹果” 的公司 / 水果含义向量相同) |
| 动态上下文嵌入(2017 后) | BERT(基于 Transformer) | 结合自注意力机制,生成上下文相关向量,解决一词多义问题 | 依赖大量预训练数据,早期未针对检索优化 |
| RAG 适配阶段(2020 后) | INSTRUCTOR、BGE-M3 | 支持领域自适应(如法律 / 医疗)、多模态(文本 + 图像)、混合检索(稠密 + 稀疏) | 对模型大小、向量维度的资源消耗要求更高 |
三、嵌入模型训练原理
四、嵌入模型选型指南
1. 参考 MTEB 排行榜
MTEB(Massive Text Embedding Benchmark)是核心评测基准,需关注四个维度:
- 横轴(模型参数量):参数量越大性能潜力越强,但资源消耗越高;
- 纵轴(平均任务得分):得分越高通用语义理解能力越强;
- 气泡大小(嵌入维度):维度越高语义编码越丰富,但存储 / 计算成本越高;
- 气泡颜色(最大 Token 数):颜色越深支持文本长度越长,需匹配文本分块策略。
2. 关键评估维度
| 维度 | 说明 |
|---|---|
| 任务适配性 | RAG 需重点关注 “检索(Retrieval)” 任务排名 |
| 语言支持 | 中文场景选明确支持中文或多语言的模型(如 BAAI/bge-small-zh-v1.5) |
| 资源成本 | 模型大小(显存需求)、向量维度(存储消耗)、API 调用成本(若用云服务) |
| 文本长度支持 | 最大 Token 数需大于文本分块大小,避免截断导致信息丢失 |
| 机构与口碑 | 优先选择知名机构(如 BAAI、Hugging Face)发布的模型,质量更有保障 |
3. 迭代测试流程
- 确定基线:筛选 2-3 个符合上述维度的模型作为初始基准;
- 构建私有评测集:用真实业务数据创建 “用户问题 - 标准答案 / 相关文档块” 样本;
- 优化验证:在私有集上测试模型召回准确率,迭代更换模型或调整分块策略,最终选最优模型。
第二节 多模态嵌入
一、多模态嵌入的核心价值与目标
1. 需求背景:打破 “模态墙”
- 现实信息的多模态属性:真实世界信息包含文本、图像、音频、视频等,传统文本嵌入无法理解 “红色汽车图片” 这类跨模态查询 —— 文本与图像向量处于隔离空间,形成 “模态墙”。
- 核心目标:将不同模态数据(如文本、图像)映射到同一共享向量空间,实现跨模态语义对齐。例如,“奔跑的狗” 的文本向量与对应图片向量在空间中距离极近,解决 “跨模态对齐” 的核心挑战。
二、关键模型:CLIP(图文多模态典范)
1. 架构设计:双编码器架构
- 核心组成:包含「图像编码器」和「文本编码器」,分别将图像、文本转换为共享向量空间中的向量,确保不同模态数据在同一维度下可比。
2. 训练策略:对比学习
- 训练逻辑:处理一批图文数据时,通过 “拉近正例、推远负例” 优化 —— 最大化正确图文对(如 “猫” 文本 + 猫图片)的向量相似度,最小化错误配对(如 “猫” 文本 + 狗图片)的相似度。
- 核心能力:零样本识别:无需针对特定任务微调,可将分类任务转化为 “图文检索”。例如,判断某图是否为猫,只需计算图片向量与 “a photo of a cat” 文本向量的相似度,实现视觉概念的泛化理解。
三、常用多模态模型:BGE-M3(现代多模态代表)
1. 模型定位
由北京智源(BAAI)开发,是兼顾多语言、多功能、多粒度的现代多模态嵌入模型,适配更复杂的跨模态场景。
2. 核心特性(“M3” 特性)
| 特性 | 说明 |
|---|---|
| 多语言性(Multi-Linguality) | 原生支持 100 + 语言的文本与图像处理,可实现跨语言图文检索(如中文 “狗” 文本与英文 “dog” 图片对齐)。 |
| 多功能性(Multi-Functionality) | 单模型支持三种检索模式:密集检索(语义相似)、多向量检索(多片段匹配)、稀疏检索(关键词匹配),适配不同场景需求。 |
| 多粒度性(Multi-Granularity) | 支持从短句到 8192 Token 长文档的处理,覆盖短文本查询、长文档分析等广泛需求。 |
3. 技术创新:网格嵌入(Grid-Based Embeddings)
- 区别于 CLIP:CLIP 对整张图像编码,BGE-M3 将图像分割为多个网格单元并独立编码,大幅提升对图像局部细节的捕捉能力(如多物体重叠场景),语义表示更精准。
四、代码实践:BGE-M3(visual_bge)基础应用
1. 环境准备
- 安装依赖:进入
visual_bge目录,执行pip install -e .安装模块。 - 下载模型:运行
download_model.py,自动从 Hugging Face 镜像站下载模型权重至指定目录(如../../models/bge/)。
2. 核心代码逻辑与解读
(1)模型初始化
from visual_bge.visual_bge.modeling import Visualized_BGE
import torch# 加载模型:指定底层BGE文本模型和视觉权重
model = Visualized_BGE(model_name_bge="BAAI/bge-base-en-v1.5", # 继承BGE文本嵌入能力model_weight="../../models/bge/Visualized_base_en_v1.5.pth" # 视觉编码器参数
)
model.eval() # 推理模式
(2)多模态编码能力
支持三种输入格式,统一输出共享空间向量:
- 纯文本编码:
text_emb = model.encode(text="datawhale开源组织的logo") - 纯图像编码:
img_emb_1 = model.encode(image="../../data/C3/imgs/datawhale01.png") - 图文联合编码:
multi_emb_1 = model.encode(image="xxx.png", text="xxx")
(3)相似度计算与结果
- 计算逻辑:向量已标准化,通过矩阵乘法(
@)计算余弦相似度,值越接近 1 表示语义越相似。 - 示例结果:
对比场景 相似度值 结论 纯图像 1 vs 纯图像 2 0.8318 同主题图像语义相近 图文结合 1 vs 纯图像 1 0.8291 图文与图像语义一致性高 图文结合 1 vs 纯文本 0.7627 图文与文本语义关联较强 图文结合 1 vs 图文结合 2 0.9058 同主题图文组合语义最相近
(4)练习方向
替换文本(如将 “datawhale 开源组织的 logo” 改为 “蓝鲸”),观察相似度变化 —— 文本与图像语义匹配度下降时,相似度值会显著降低。
=== 相似度计算结果 ===
纯图像 vs 纯图像: tensor([[0.8318]])
图文结合1 vs 纯图像: tensor([[0.9926]])
图文结合1 vs 纯文本: tensor([[0.5061]])
图文结合1 vs 图文结合2: tensor([[0.8323]])