C标准库 ---- locale.h
🌟作者介绍:友友们好我是钓鱼的猫猫,可以叫我小猫💕
⏳作者主页:钓鱼的猫猫-CSDN博客🎉
👀项目专栏:标准库_钓鱼的猫猫的博客-CSDN博客
🎉小猫和友友们一样喜欢代码🤭。很荣幸能向大家分享我的所学所感,和大家一起进步,成为合格的卷王。✨如果文章有错误,欢迎在评论区✏️指正。那么开始今天的学习吧!😘
想要迅速浏览本文章内容,请看 !!!总结全文!!!
目录
一.引言
二.类项介绍
2.1 类项
2.2 LC_COLLATE
2.2.1 总结先行
2.2.2 简单理解
2.2.3 详细解释
2.3 LC_CTYPE
2.3.1 总结先行
2.3.2 简单理解
2.3.3 详细解释
2.4 LC_MONETARY
2.4.1 总结先行
2.4.2 简单解释
2.4.3 详细解释
2.5 LC_NUMERIC
2.5.1 总结先行
2.5.2 简单解释
2.5.3 详细解释
2.6 LC_TIME
2.6.1 总结先行
2.6.2 简单解释
2.6.3 详细解释
2.7 LC_ALL
2.7.1 总结先行
2.7.2 简单解释
2.7.3 详细解释
2.7.4 警告和注意事项
三. setlocale 函数
3.1 函数简介
3.2 函数详解
四. 宽字符
4.1 简单解释
4.2 详细解释
五.总结全文
六.最后
一.引言
简介:<locale.h>可以提供一些函数,这些函数在不同地区有不同的结果表达。
C语⾔最初假定字符都是单字节的。但是这些假定并不是在世界的任何地⽅都适⽤。 C语⾔字符默认是采⽤ASCII编码的,ASCII字符集采⽤的是单字节编码,且只使⽤了单字节中的低7 位,最⾼位是没有使⽤的,可表⽰为0xxxxxxxx;可以看到,ASCII字符集共包含128个字符,在英语 国家中,128个字符是基本够⽤的,但是,在其他国家语⾔中,⽐如,在法语中,字⺟上⽅有注⾳符 号,它就⽆法⽤ASCII码表⽰。于是,⼀些欧洲国家就决定,利⽤字节中闲置的最⾼位编⼊新的符 号。⽐如,法语中的é的编码为130(⼆进制10000010)。这样⼀来,这些欧洲国家使⽤的编码体 系,可以表⽰最多256个符号。
但是,这⾥⼜出现了新的问题。不同的国家有不同的字⺟,因此,哪怕它们都使⽤256个符号的编码⽅式,代表的字⺟却不⼀样。⽐如,130在法语编码中代表了é,在希伯来语编码中却代表了字⺟Gimel,在俄语编码中⼜会代表另⼀个符号。但是不管怎样,所有这些编码⽅式中,0--127表⽰的符号是⼀样的,不⼀样的只是128--255的这⼀段。 ⾄于亚洲国家的⽂字,使⽤的符号就更多了,汉字就多达10万左右。⼀个字节只能表⽰256种符号, 肯定是不够的,就必须使⽤多个字节表达⼀个符号。⽐如,简体中⽂常⻅的编码⽅式是GB2312,使 ⽤两个字节表⽰⼀个汉字,所以理论上最多可以表⽰256x256=65536个符号。
后来为了使C语⾔适应国际化,C语⾔的标准中不断加⼊了国际化的⽀持。⽐如:加⼊了宽字符的类型 wchar_t 和宽字符的输⼊和输出函数,加⼊了头⽂件,其中提供了允许程序员针对特定 地区(通常是国家或者说某种特定语⾔的地理区域)调整程序⾏为的函数
二.类项介绍
2.1 类项
类项是什么?类项就是例如时间,字符格式,字母格式之类的东西的集合(统称)。由于不同的地区时间,字符等等不同,我们可以修改某些类项进而时间,字符这些。
因此我们可以定义很多宏,这些不同的宏存储着不同信息。例如这个宏里面存储着时间,这个宏里面存储着货币信息,那个宏存储着时间信息。
因此我们把一个宏称为一个类项
2.2 LC_COLLATE
2.2.1 总结先行
LC: 是 Locale 的缩写,中文常翻译为“区域设置”或“本地化环境”。COLLATE: 源自动词 Collate,中文意思是“整理、核对、排序”。在计算机语境下,特指字符串的排序规则。
因此,LC_COLLATE 合起来的意思就是:定义区域设置(Locale)中的字符串排序和比较规则。
2.2.2 简单理解
LC_COLLATE:影响字符串的比较函数 strcoll() 和 strxfrm()
2.2.3 详细解释
1. LC (Locale - 区域设置)
“Locale”是一个综合性的设置集合,它定义了与特定语言、地区和文化传统相关的规则。一个完整的 Locale 通常包含以下多个方面的规则。
2. COLLATE (Collation - 排序规则)
“Collation”特指字符串的比较和排序序列。它回答了这样一个问题:“在排序时,哪个字符应该排在哪个字符的前面?”
不同的语言和文化有不同的排序习惯:
英语 (en_US.UTF-8): 基本的排序顺序是 A, B, C, D, ... Z, a, b, c, ... z。
德语 (de_DE.UTF-8): 德语中有变音字母,如 ä, ö, ü。在字典排序中,它们通常被视为 ae, oe, ue。所以正确的顺序可能是 ... A, Ä, B, C, ... O, Ö, P, Q, ... U, Ü, V, W, ...
中文 (zh_CN.UTF-8): 中文排序通常基于拼音字母顺序或笔画顺序。
LC_COLLATE可以定义是按“啊 (a)”、“百 (bai)”、“才 (cai)”的顺序,还是按其他规则排序。大小写敏感/不敏感: 排序规则还可以定义是否区分大小写。在某些场景下,‘apple’ 和 ‘Apple’ 可能被视为相同,排在相邻位置;而在另一些场景下,所有大写字母可能都排在小写字母之前(ASCII顺序)。
所以,
COLLATE特指 Locale 中负责定义字符串比较和排序行为的那个部分。3.实际应用举例
在编程和系统中,
LC_COLLATE的设置直接影响以下行为:
命令行工具: 在 Linux/Unix 系统下,
ls命令列出文件、sort命令排序文本时,其默认的排序行为就由LC_COLLATE决定。数据库查询: 在 SQL 语句中(如 PostgreSQL, MySQL),当你使用
ORDER BY对文本字段进行排序时,数据库的排序结果就取决于它使用的 collation 规则。编程语言: 在 Python、C 等编程语言中,字符串比较函数(如
strcmp())和排序函数(如sorted())的行为可能会受到系统或程序设置的LC_COLLATE影响。示例:
假设你有一个单词列表:apple,Äpfel,banana,Zoë。
在 英语 排序规则下,顺序可能是:
apple,banana,Zoë,Äpfel(因为 ASCII 中Z之后是[,而[在_之前,_又在A之前)。在 德语 排序规则下,顺序更符合逻辑:
apple(或Apfel),Äpfel,banana,Zoë(因为Ä被视作与Ae等价,紧跟在A之后)。在 瑞典语 排序规则下,
Z之后可能就是Ä,Ö,Å。
2.3 LC_CTYPE
2.3.1 总结先行
LC: 是 Locale 的缩写,中文翻译为“区域设置”或“本地化环境”。它是一个规则集合的总称。
CTYPE: 是 Character Type 的缩写,中文意思是“字符类型”。它特指对字符的分类和转换规则。
因此,
LC_CTYPE合起来的意思就是:定义区域设置(Locale)中的字符分类、转换规则以及哪些字符被视为有效。
2.3.2 简单理解
LC_CTYPE:影响字符处理函数的行为
2.3.3 详细解释
1. LC (Locale - 区域设置)
和
LC_COLLATE中的LC一样,它代表了一整套与特定语言、地区和文化传统相关的规则集合。Locale 包含了多个分类,LC_CTYPE是其中至关重要的一个。2. CTYPE (Character Type - 字符类型)
这是
LC_CTYPE的核心。它决定了系统如何解释和操作单个字符。具体来说,它定义了以下规则:
字符分类 (Character Classification):
如何判断一个字符属于哪种类型?
什么是字母?(
isalpha()函数)什么是数字?(
isdigit()函数)什么是空格?(
isspace()函数)什么是可打印字符?(
isprint()函数)什么是小写或大写字母?(
islower(),isupper()函数)大小写转换 (Case Conversion):
如何将一个字符从小写转换为大写?(
toupper()函数)如何从大写转换为小写?(
tolower()函数)这对于一些只有单一大小写形式的语言(如中文)可能不重要,但对拉丁字母、西里尔字母等语言至关重要。
字符编码的有效性 (Valid Character Encoding):
在当前区域设置下,什么样的字节序列是一个合法的字符?这在与字符编码(如 UTF-8, ISO-8859-1, GBK)交互时尤为重要。
核心区别:
LC_CTYPEvs.LC_COLLATE这是一个非常重要的概念区分,可以帮助你更好地理解两者:
LC_CTYPE关心的是“字符是什么?”
它是一个关于单个字符身份和属性的问题。
例如:这个字节
0x41代表什么?它是一个字母吗?它是大写还是小写?它的对应小写形式是什么?
LC_COLLATE关心的是“字符/字符串如何排序?”
它是一个关于多个字符或字符串之间顺序和比较的问题。
例如:在排序时,单词 “äpple” 应该放在 “apple” 之后还是 “zebra” 之前?
实际应用举例
LC_CTYPE的设置直接影响以下行为:
命令行通配符扩展:
在 Linux Shell 中,当你使用[a-z]这样的模式来匹配文件名时,范围a-z的具体含义由LC_CTYPE决定。在某些语言环境下,它可能只包含 26 个英文字母;在另一些环境下,它可能包含所有小写字母,包括ä,ö,ü等。正则表达式:
编程语言中的正则表达式元字符如\w(单词字符)、\d(数字)、\s(空白符) 的行为,都依赖于LC_CTYPE的规则。\w在英语环境下可能等于[a-zA-Z0-9_],但在法语环境下,它可能还会包含é,è,à等字母。字符串处理函数:
任何使用像isalpha(),toupper()这类函数的程序,其行为都取决于LC_CTYPE。例如,将字符串 “straße” 转换为大写,在德语环境下会得到 “STRASSE”(ß 的大写是 SS),而在其他环境下可能无法正确处理。输入验证:
如果一个程序检查用户输入是否只包含“字母”,那么“字母”的定义就来自LC_CTYPE。这对于支持多语言输入的程序至关重要。
2.4 LC_MONETARY
2.4.1 总结先行
LC: 是 Locale 的缩写,中文翻译为“区域设置”或“本地化环境”。它是一个规则集合的总称。
MONETARY: 源自 Monetary,中文意思是“货币的”。它特指与货币格式相关的规则。
因此,
LC_MONETARY合起来的意思就是:定义区域设置(Locale)中与货币金额相关的格式化规则。
2.4.2 简单解释
LC_MONETARY:影响货币格式
2.4.3 详细解释
1. LC (Locale - 区域设置)
和之前解释的
LC_COLLATE、LC_CTYPE一样,LC是所有这些分类的共同前缀,代表了一整套与特定语言、地区和文化传统相关的规则集合。2. MONETARY (货币格式)
这是
LC_MONETARY的核心。它专门定义了如何格式化一个货币金额,使其符合特定地区的文化和习惯。它不关心货币之间的汇率转换,只关心如何显示一个金额。具体来说,它定义了以下规则:
货币符号 (Currency Symbol):
使用什么符号?例如:
$,€,¥,£。符号放在金额的哪一边?例如:
$100(前缀) 或100 €(后缀)。小数点字符 (Decimal Point):
整数与小数部分之间用什么分隔?例如:
100.99(使用点) 或100,99(使用逗号)。千位分隔符 (Thousands Separator):
数字每三位用什么分隔?例如:
1,000,000.00(使用逗号) 或1.000.000,00(使用点)。正负号格式 (Sign Positioning):
正数如何显示?(通常不显示符号)
负数如何显示?是使用括号
($100.00),还是前置负号-$100.00,或者是后置负号100.00-$?国际货币符号 (International Currency Symbol):
三字母的ISO 4217代码,如USD(美元)、EUR(欧元)、CNY(人民币)、JPY(日元)。这在需要避免符号歧义时使用。
与
LC_NUMERIC的区别这是一个非常重要的概念区分:
LC_MONETARY: 只控制货币金额的显示格式。
例如:将数字
1234567.89格式化为$1,234,567.89或1.234.567,89 €。
LC_NUMERIC: 控制普通数字的显示格式(不包括货币符号等)。
例如:将数字
1234567.89格式化为1,234,567.89(英语)或1 234 567,89(法语)或1.234.567,89(德语)。它定义了通用的小数点和千分位分隔符。简单来说:
LC_MONETARY是LC_NUMERIC的超集,它在数字格式的基础上增加了货币符号和金融格式(如负数表示法)的规则。实际应用举例
LC_MONETARY的设置直接影响以下行为:
命令行工具:
某些系统工具或脚本在输出货币信息时会遵循此规则。编程语言函数:
这是最主要的影响领域。例如,在C语言中,strfmon()函数专门用于格式化货币字符串,其行为完全由LC_MONETARY决定。
例如代码:
#include <monetary.h>
#include <locale.h>
#include <stdio.h>int main()
{setlocale(LC_MONETARY, "en_US.UTF-8");// 输出: $1,234,567.89strfmon(buffer, sizeof(buffer), "%.2n", 1234567.89);setlocale(LC_MONETARY, "de_DE.UTF-8");// 输出: 1.234.567,89 €strfmon(buffer, sizeof(buffer), "%.2n", 1234567.89);setlocale(LC_MONETARY, "ja_JP.UTF-8");// 输出: ¥1,234,568 (日元通常没有小数位)strfmon(buffer, sizeof(buffer), "%.0n", 1234567.89);return 0;
}2.5 LC_NUMERIC
2.5.1 总结先行
LC: 是 Locale 的缩写,中文翻译为“区域设置”或“本地化环境”。它是一个规则集合的总称。
NUMERIC: 源自 Numeric,中文意思是“数字的”。它特指与非货币数字格式相关的规则。
因此,
LC_NUMERIC合起来的意思就是:定义区域设置(Locale)中普通数字的格式化规则。
2.5.2 简单解释
LC_NUMERIC:影响 printf()的数字格式
2.5.3 详细解释
1. LC (Locale - 区域设置)
和
LC_COLLATE、LC_CTYPE、LC_MONETARY一样,LC是所有这些分类的共同前缀,代表了一整套与特定语言、地区和文化传统相关的规则集合。2. NUMERIC (数字格式)
这是
LC_NUMERIC的核心。它专门定义了如何格式化一个普通的、非货币的数字。它控制的是数字本身的显示方式,不涉及任何货币符号。具体来说,它主要定义了两个关键规则:
小数点字符 (Decimal Point Character):
整数与小数部分之间用什么符号分隔?
例如:英语地区使用点号 (
.) ->3.14例如:许多欧洲大陆地区使用逗号 (
,) ->3,14千位分隔符 (Thousands Separator):
数字每三位用什么符号分隔以提高可读性?
例如:英语地区使用逗号 (
,) ->1,000,000例如:许多欧洲大陆地区使用点号 (
.) 或空格 () ->1.000.000或1 000 000与
LC_MONETARY的核心区别(非常重要)这是理解
LC_NUMERIC的关键。很多人会混淆这两者。
特性
LC_NUMERIC
LC_MONETARY作用对象
普通数字
货币金额
示例输入
1234567.89
1234567.89示例输出(en_US)
1,234,567.89
$1,234,567.89示例输出(de_DE)
1.234.567,89
1.234.567,89 €包含内容
小数点、千分位分隔符
包含
LC_NUMERIC的规则,并额外增加:
1. 货币符号 ($,€)
2. 符号位置(前缀/后缀)
3. 负数的特殊表示法(如括号)简单比喻:
LC_NUMERIC像是定义了一本数学课本的数字书写规范。
LC_MONETARY像是定义了一本会计账本的数字书写规范,它继承了数学课本的规则,并额外增加了“货币符号”和“账目负数表示法”等财务特有的规则。
实际应用举例
LC_NUMERIC 的设置会深刻影响以下行为:
-
命令行工具的输出:
-
像
printf这样的命令在输出浮点数时会使用当前的分隔符规则。
-
# 设置为美国英语
export LC_NUMERIC="en_US.UTF-8"
printf "%'f\n" 1234567.89
# 输出: 1,234,567.890000# 设置为德国德语
export LC_NUMERIC="de_DE.UTF-8"
printf "%'f\n" 1234567.89
# 输出: 1.234.567,8900002. 编程语言中的输入/输出函数:
在C语言中,printf(), scanf(), atof() 等函数的行为受 LC_NUMERIC 影响。
在Python中,locale 模块的 format_string(), atoi(), atof() 等函数会使用该设置。但请注意:Python 内置的 float() 和 print() 函数通常不受此设置影响,它们始终使用点号。你必须显式使用 locale 模块。
3. 最危险且重要的影响:数据转换:
这可能是 LC_NUMERIC 最需要小心的地方。函数如 atof()(ASCII to float)会使用当前的区域设置来解析字符串。
#include <locale.h>
#include <stdlib.h>
#include <stdio.h>int main()
{setlocale(LC_NUMERIC, "en_US.UTF-8");double val1 = atof("123.45"); // 正确解析为 123.45setlocale(LC_NUMERIC, "de_DE.UTF-8");double val2 = atof("123.45"); // 错误!点号不是小数点,解析为 123// 正确的德国数字字符串是 "123,45"printf("val1 = %f, val2 = %f\n", val1, val2);return 0;
} 如果在读取数据文件(如CSV)时区域设置不正确,会导致灾难性的数据解析错误。因此,在处理数据交换时,通常建议将 LC_NUMERIC 设置为 "C"(即默认的POSIX locale,使用点号),以确保一致性。
4. 数据库和可视化工具:
一些数据库客户端和数据分析工具(如某些模式的PostgreSQL、R语言、某些BI工具)在显示数字时可能会遵循系统的 LC_NUMERIC 设置。
2.6 LC_TIME
2.6.1 总结先行
LC: 是 Locale 的缩写,中文翻译为“区域设置”或“本地化环境”。它是一个规则集合的总称。
TIME: 代表 Time,中文意思是“时间”。它特指与时间和日期格式相关的规则。
因此,
LC_TIME合起来的意思就是:定义区域设置(Locale)中时间和日期的显示格式、名称以及星期起始日等规则。
2.6.2 简单解释
LC_TIME:表示影响时间格式 strtime() 和 wcsftime()
2.6.3 详细解释
1. LC (Locale - 区域设置)
和之前解释的所有
LC_*变量一样,LC是所有这些分类的共同前缀,代表了一整套与特定语言、地区和文化传统相关的规则集合。2. TIME (时间与日期格式)
这是
LC_TIME的核心。它定义了如何表示和格式化时间与日期信息,使其符合特定地区的文化和习惯。它包含的规则非常丰富,远不止是简单的数字排列。具体来说,它定义了以下规则:
日期格式 (Date Format):
年、月、日的排列顺序是什么?
美国格式 (MM/DD/YYYY):
04/25/2023大部分欧洲和亚洲格式 (DD/MM/YYYY):
25/04/2023国际标准/中国格式 (YYYY-MM-DD):
2023-04-25时间格式 (Time Format):
使用12小时制还是24小时制?
12小时制 (en_US):
03:45:30 PM24小时制 (de_DE, zh_CN):
15:45:30星期名称 (Day Names):
一周七天的全称和缩写是什么?
例如:英语是
Monday,Tue.;中文是星期一,周二。月份名称 (Month Names):
十二个月的全称和缩写是什么?
例如:英语是
January,Jan.;中文是一月,1月。AM/PM 指示符:
在12小时制中,上午和下午用什么表示?
英语是
AM/PM,中文也可以是上午/下午。一周的第一天:
哪一天被视为一周的开始?这更多是文化习惯,但会影响日历的显示。
在美国,一周的第一天是星期日。
在欧洲和中国等大多数地区,一周的第一天是星期一。
实际应用举例
LC_TIME的设置会直接影响以下行为,其效果非常直观:
命令行工具:
date命令的输出格式完全由LC_TIME决定。示例:
# 设置为美国英语 export LC_TIME="en_US.UTF-8" date # 输出: Wed Apr 26 15:45:30 EDT 2023# 设置为简体中文 export LC_TIME="zh_CN.UTF-8" date # 输出: 2023年 04月 26日 星期三 15:45:30 EDT# 设置为德国德语 export LC_TIME="de_DE.UTF-8" date # 输出: Mi 26. Apr 15:45:30 EDT 2023编程语言函数:
在C语言中,
strftime()函数用于格式化时间和日期,其行为完全由LC_TIME控制。在Python中,
time.strftime()的行为同样受此影响。示例(Python):
import locale import timelocale.setlocale(locale.LC_TIME, 'en_US.UTF-8') print(time.strftime('%c')) # 输出: Wed Apr 26 15:45:30 2023 print(time.strftime('%A')) # 输出: Wednesdaylocale.setlocale(locale.LC_TIME, 'de_DE.UTF-8') print(time.strftime('%c')) # 输出: Mi 26 Apr 15:45:30 2023 print(time.strftime('%A')) # 输出: Mittwoch图形用户界面 (GUI):
操作系统桌面、网页应用程序、手机App中显示日期和时间的地方,都会遵循
LC_TIME规则(或其等效设置)来向用户展示信息,以确保符合用户的本地习惯。日志文件和分析工具:
一些系统日志或应用程序日志的时间戳格式可能会受到此设置的影响。在进行跨区域的数据分析时,统一时间格式至关重要。
2.7 LC_ALL
2.7.1 总结先行
LC: 是 Locale 的缩写,中文翻译为“区域设置”或“本地化环境”。它是一个规则集合的总称。
ALL: 英文单词,中文意思是“所有的”、“全部的”。
因此,
LC_ALL合起来的意思就是:一个总开关,用于一次性设置所有区域设置(Locale)分类的规则。
2.7.2 简单解释
LC_ALL:针对所有类项进行修改,将以上所有类别设置为给定的语言环境
2.7.3 详细解释
1. LC (Locale - 区域设置)
和之前解释的所有
LC_*变量一样,LC是所有这些分类的共同前缀,代表了一整套与特定语言、地区和文化传统相关的规则集合。2. ALL (所有的)
这是
LC_ALL的核心和特殊之处。它不是一个独立的分类(如CTYPE,TIME),而是一个覆盖器或主开关。它的行为有两个关键特点:
覆盖所有单独设置:
当
LC_ALL被设置后,它的值会覆盖所有其他LC_*环境变量(如LC_CTYPE,LC_TIME,LC_NUMERIC等)以及LANG变量的值。系统在决定使用哪个区域设置时,会按以下优先级从高到低检查:
LC_ALL(最高优先级,强制覆盖一切)
LC_*(如LC_TIME,LC_MONETARY,用于精细控制)
LANG(最低优先级,用于设置默认值)用于命令执行的临时环境:
在命令行中,它常被用来为单条命令临时指定一个区域环境,确保该命令的输出和行为是可预测的,不受当前用户环境设置的影响。
LC_ALL的实际用途和示例用途 1:强制使用一个统一的环境(最高优先级)
这是最常见的用途。当你希望确保程序在所有方面(排序、货币、时间、字符处理等)都使用同一种区域规则,并且不希望受到任何其他单独设置的影响时,就使用
LC_ALL。示例:获取标准的英文输出
如果你想确保date命令的输出是英文格式,而不管你的系统当前是什么语言,可以这样做:# 临时为一条命令设置 LC_ALL=C date # 输出: Thu Apr 27 10:30:15 EDT 2023# 或者在脚本中设置整个脚本的环境 export LC_ALL="en_US.UTF-8"用途 2:与
locale命令配合使用,生成区域信息
locale命令本身的行为就受LC_ALL支配。你可以用它来查看特定区域的完整设置信息。示例:查看德语区域的所有设置
LC_ALL=de_DE.UTF-8 locale用途 3:解决脚本或程序的本地化问题(使用
C或POSIX)
LC_ALL=C或LC_ALL=POSIX是一个特殊的用法,它将区域设置为最小化的默认环境(通常就是纯英文ASCII环境)。这非常有用:
保证可预测的行为:确保排序、字符范围(如
[a-z])、数字格式等是脚本期望的,避免因用户环境不同而导致错误。提高处理速度:因为
Clocale的规则非常简单。兼容性:处理需要解析特定格式(如代码、配置文件、数据文件)的场景,这些格式通常基于ASCII和点号小数点。
2.7.4 警告和注意事项
-
谨慎设置:在你的 Shell 配置文件(如
.bashrc)中设置export LC_ALL时要非常小心,因为它会覆盖所有精细的LC_*控制,可能会破坏某些需要特定本地化功能的程序。 -
并非所有程序都遵守:极少数程序可能会忽略
LC_ALL或自己实现一套本地化规则,但绝大多数遵循 POSIX 标准的命令行工具和库函数(如 glibc)都会尊重它。
三. setlocale 函数
setlocale - C++ Reference

3.1 函数简介
头文件:locale.h
setlocale函数是用来设置 各种信息 是否 要转换地区 的函数
char* setlocale(int category,const char* locale)①setlocale的返回值是一个字符串指针,来标记已经设置好的格式。如果调用失败了,则返回空指针NULL
②setlocale() 可以用来查询当前地区,这时第二个参数设为NULL就可以了
3.2 函数详解
头文件 locale.h
① setlocale 函数用于修改当前地区,可以针对一个类项修改,也可以针对所有类项修改
② setlocale的第一个参数可以是前面说明的类项中的一个,那么每次只会影响一个类项,如果每一个参数LC_ALL,就会影响所有类项
③C标准给第二个参数仅仅定义了两种可能的值:"C"(正常模式或者叫英语模式)
"" (本地模式)
在任意程序开始的时候都会隐藏执行该段话
setlocale(LC_ALL,"C");
注意:
当程序运行起来后想改变地区,就只能显示调用setlocale函数,用 "" 作为第二个参数调用 setlocale 函数就可以切换到本地模式,这种模式情况下程序就会适应本地环境
比如我们要切换到本地模式,后就支持宽字符串的输出
setlocale(LC_ALL,""); //切换到本地模式这个函数到底什么作用,怎么用,例如
#define _CRT_SECURE_NO_WARNINGS 1
/* setlocale example */
#include <stdio.h> /* printf */
#include <time.h> /* time_t, struct tm, time, localtime, strftime */
#include <locale.h> /* struct lconv, setlocale, localeconv */int main()
{time_t rawtime;struct tm* timeinfo;char buffer[80];struct lconv* lc;time(&rawtime);timeinfo = localtime(&rawtime);int twice = 0;do {printf("Locale is: %s\n", setlocale(LC_ALL, NULL));strftime(buffer, 80, "%c", timeinfo);printf("Date is: %s\n", buffer);lc = localeconv();printf("Currency symbol is: %s\n-\n", lc->currency_symbol);setlocale(LC_ALL, "");} while (!twice++);return 0;
}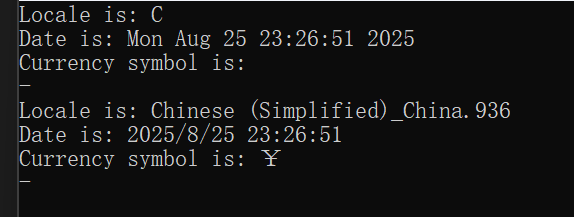
可以分析该代码,该代码会执行两次,第一次是在 “C”标准情况下,第二次是在 "" 本地模式下,可以看到时间信息不同,钱的信息不同,时间标准不同,数字表示不同,模式不同
四. 宽字符
4.1 简单解释
宽字符就是普通字符(窄字符)宽度 × 2;即 宽字符的宽 = 字符的宽 × 2
4.2 详细解释
宽字符的字母量必须加上前缀L,否则C语言会把字面常量当作字符类项处理。前缀L在单引号前面,表示宽字符,宽字符的打印wprintf(),对于wprintf()占位符为%lc
例如:
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{setlocale(LC_ALL,"");wchar_t ch1 = L'.';wchar_t ch2 = L'袁';wchar_t ch3 = L'浩';wchar_t ch4 = L'然';printf("%c%c\n", 'a', 'b');wprintf(L"%lc\n",ch1);wprintf(L"%lc\n", ch2);wprintf(L"%lc\n", ch3);wprintf(L"%lc\n", ch4);return 0;
}
很明显看得出来宽字符是一般普通字符的两倍大小

五.总结全文
①介绍了locale.h 可以提供一些函数,这些函数在不同地区有不同的结果表达
②详细说明了
LC_COLLATE:影响字符串的比较函数 strcoll() 和 strxfrm()
LC_CTYPE :影响字符处理函数的行为
LC_MONETARY:影响货币格式
LC_NUMERIC:影响 printf()的数字格式
LC_TIME :表示影响时间格式 strtime() 和 wcsftime()
LC_ALL:针对所有类项进行修改,将以上所有类别设置为给定的语言环境
③介绍了setlocale函数,是用来设置 各种信息 是否 要转换地区 的函数
④介绍了宽字符 :普通字符(窄字符)宽度 × 2;即 宽字符的宽 = 字符的宽 × 2
六.最后
小猫尽力了,请见谅!😘
那么今天的学习就到这里了。友友们觉得不错的可以给个关注,点赞或者收藏哦!😘感谢各位友友们的支持。希望各位大佬们自行检验哦,毕竟亲手操作让记忆更加深刻。
你的❤️点赞是我创作的动力的源泉
你的✨收藏是我奋斗的方向
你的🙌关注是对我最大的支持
你的✏️评论是我前进的明灯
创作不易,希望友友们支持一下小猫吧😘