1. 并发产生背景 并发解决原理
文章目录
- 一. 并发产生背景
- 1.1 单核CPU
- 1.2 多核CPU
- 1.3 并发引入
- 二. 并发解决
- 2.1 总线锁
- 2.2 缓存行锁
- 2.3 原子性
一. 并发产生背景
为什么现在普遍流行并发的说法?那何为并发呢?
1.1 单核CPU
那我们思维回到最初始的单核CPU,单核CPU(抛开切换上下文)操控一个数据会产生数据问题么?答案是否定的。因为单核CPU操控数据,只有一个进程在串行的操作数据。那我们从汇编层面看下数据如何操作。就拿对一个内存数据int a = 1进行+1操作举例。
拿intel cpu举例,因为我们服务器基于intel实现较多,intel的汇编指令是risc,精简指令集,笔者在这里写汇编伪代码,目的是带大家感受底层的操作原理。
addl $1, (%ebp - 4)
而对于CPU而言,它要操作的是微指令(μop),所以risc会被译码成多个步骤的汇编
# 笔者这里省略开辟栈帧,直接写个伪代码,感受汇编的操作
movl (%ebp - 4), eax // 将内存数据,放入eax寄存器中
addl 1, eax // 进行+1操作
movl eax, (%ebp - 4) // 放回内存
所以就通过简单的单核CPU就可看出,它操作一个内存数据,是要有大致的3个步骤。
有了这节的铺垫,我们可以更好后面章节的并发引入。
1.2 多核CPU
拿2个CPU举例,同时操作一个内存数据,会发生什么?
首先,我们需要分2个场景
- 场景1:读数据
若2个CPU同时读一个内存数据,而不进行更改,那会不会产生数据问题?这就可以联想一个上层应用的场景,读redis缓存数据,是否会考虑并发问题?
答案是否定的,因为这里只涉及读时的性能问题,而不会导致实质性的数据问题。
- 场景2:写数据
ps:这里就要引入[1.1 单核CPU](# 1.1 单核CPU)时讲解的汇编指令,但读者也不用担心会非常难以理解,因为笔者也不是汇编层面的开发人员。这里只是做个了解。
当2个CPU同时执行自己的cu,alu,mu来开始操作写数据,进行+1操作时,会发生什么?
比如一个CPU执行+1操作,会衍生3条汇编指令,而2个CPU同时CPU同时操作,每个CPU3条汇编指令,那么总共是6条汇编指令。在同一时刻有可能是CPU-1执行了第一条汇编,而CPU-2执行到了第2条汇编,有诸多排列组合。
若此时,CPU-1,CPU-2,都把内存数据读到了各自的EAX中,这时内存数据读取的操作都是一样,若同时进行+1操作时,CPU-1执行后是2,CPU-2执行后也是2,那么写回内存,最后结果就是2,而非期望的结果3。
1.3 并发引入
由前面2节引申的概念,可以推理出,当多核CPU同时执行操作一个可读可写的数据,会导致数据紊乱,而造成紊乱的原因:汇编指令的穿插执行。
二. 并发解决
2.1 总线锁
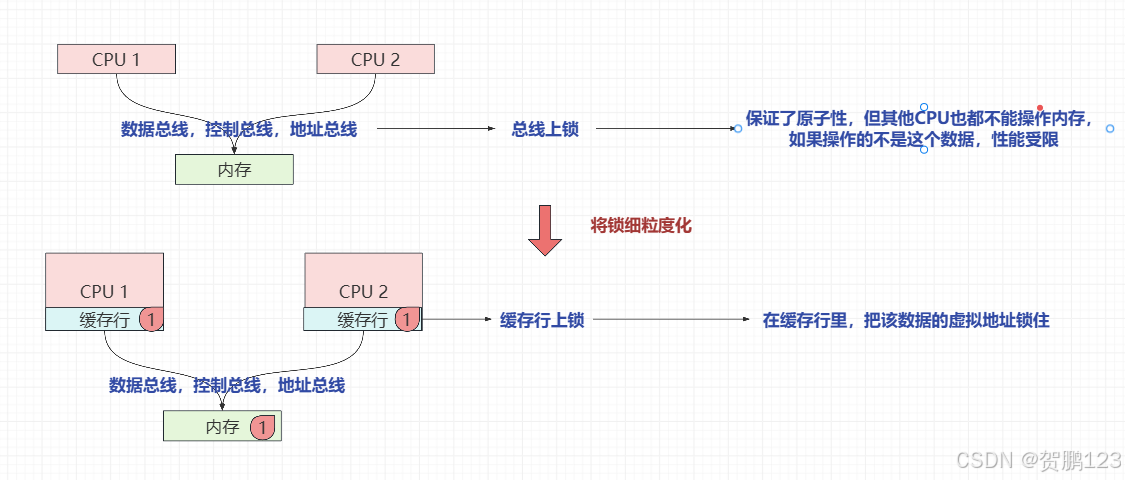
既然是穿插执行导致的数据紊乱问题,那么我们不让它紊乱就行了。比如CPU执行这个数据读/写内存,需要通过数据总线,控制总线,地址总线。多核CPU共享总线,那么我们就把总线锁住是否可以?答案是肯定的,因为CPU-1执行时,把总线锁住,导致CPU-2操作不了该数据。这就叫总线锁
那么会衍生出一个新的问题。若其他CPU不操作该数据,也会被锁住阻塞等待。直至CPU-1操作完,这样的操作很消耗性能,减少吞吐量。
2.2 缓存行锁
那么为了解决这种粗粒度的锁性能问题,但又想保证汇编指令的不可被插入性,那该怎么办呢?
每个CPU内部都有自己的L1缓存行,若我把数据的虚拟地址读入到缓存行中,进行缓存行的锁定该数据虚拟地址,那么其他CPU若访问该虚拟地址就会被阻塞,性能就会增加,这就叫缓存行锁。
2.3 原子性
上面引申了2个锁的概念,现在就需要说明一下汇编指令的不可插入行为的术语,该术语叫做原子性。
原子性:一段指令要么不执行,要么都执行完毕并且执行时不被穿插别的指令。也就是一串不被拆散的操作。
那么每个CPU厂商肯定要实现自己的原子性操作,会提供CPU级别的原子性指令来保证并发操作数据时带来的紊乱性。那么上层应用使用该CPU提供的原子性操作,即可实现自己的并发操作保证多段指令间的并发问题。