深度学习(二):数据集定义、PyTorch 数据集定义与使用(分板块解析)
文章目录
- 数据集:AI 的「学习素材库」
- 一、什么是数据集?
- 二、三种核心数据集:分工明确的「学习三件套」
- 1. 训练集(train):AI 的「练习册」
- 2. 验证集(valid):AI 的「小测验卷」
- 3. 测试集(test):AI 的「期末考试卷」
- 三、k 折交叉验证:数据不够时的「聪明用法」
- 核心步骤(用 “100 条数据分 5 折” 举例):
- PyTorch 数据集定义与使用(分板块解析)
- 一、核心知识点清单(先明确重点)
- 二、第一步:导入依赖库(代码基础)
- 三、自定义数据集:继承 Dataset 类(核心步骤)
- 3.1 类的定义与初始化(**init** 方法)
- 3.2 返回数据集长度(**len** 方法)
- 3.3 单条数据获取(**getitem** 方法)
- 四、批量加载数据:使用 DataLoader(实用工具)
- 4.1 DataLoader 基础用法(代码示例)
- 4.2 DataLoader 关键参数解析
- 五、划分数据集:Subset 与 random_split(拆分训练 / 验证集)
- 5.1 方法 1:Subset(指定具体索引,灵活但麻烦)
- 5.2 方法 2:random_split(按比例随机划分,常用)
- 六、整体流程总结(从定义到使用)
数据集:AI 的「学习素材库」
一、什么是数据集?
简单说,数据集就是 AI “学习时用的素材库”—— 就像我们上学要靠课本、练习册积累知识,AI 要学会识别图片、预测结果,也得靠一堆数据 “喂” 进去,这些用来教 AI 的所有数据,合起来就是数据集。
二、三种核心数据集:分工明确的「学习三件套」
AI 的学习过程分 “练习、检查、考核” 三步,对应三种功能不同的数据集,缺一不可:
1. 训练集(train):AI 的「练习册」
- 作用:AI 主要的 “学习资料”,用来反复练习、调整自身参数(比如学 “猫的图片长什么样”)。
2. 验证集(valid):AI 的「小测验卷」
-
来源:通常从训练集里拆分出来(比如 1000 条训练数据,拆 100 条当验证集),但 AI 在 “练习阶段” 从没碰过这些数据。
-
作用:每次练完一段,用验证集 “小测一下”,看 AI 学得好不好(比如会不会把狗认成猫),再根据测验结果调整 “学习方法”(比如调整训练时的超参数)。
3. 测试集(test):AI 的「期末考试卷」
-
作用:等 AI 彻底练完(训练结束),用它来最终检验 AI 的真实水平。
-
核心要求:测试集必须是 AI “从没见过的全新数据”
三、k 折交叉验证:数据不够时的「聪明用法」
有时候数据太少(比如只有 100 条),要是硬拆成 “练习册、小测验卷、期末卷”,每部分数据就更少了,AI 练不透也测不准。这时候就用 “k 折交叉验证”,把有限的数据 “物尽其用”。
核心步骤(用 “100 条数据分 5 折” 举例):
1.先拆分数据:把仅有的 100 条数据平均分成 5 堆,给每堆起个名字(比如 A、B、C、D、E),每堆 20 条。
2.轮流当 “小测验卷”:
-
第 1 轮:拿 A 堆当 “小测验卷”(验证集),剩下的 B、C、D、E 堆当 “练习册”(训练集),让 AI 练完再测;
-
第 2 轮:换 B 堆当 “小测验卷”,剩下的 A、C、D、E 堆当 “练习册”,再练再测;
-
第 3-5 轮:继续轮流,让 C、D、E 堆各当一次 “小测验卷”,其他堆当 “练习册”。
3.最终效果:每堆数据都当了一次 “小测验卷”,既保证 AI 练过所有 100 条数据(没浪费),又能通过 5 次小测看出真实水平 —— 解决了 “数据少不够分” 的问题。
PyTorch 数据集定义与使用(分板块解析)
一、核心知识点清单(先明确重点)
在看代码前,先记住 3 个核心工具的作用,后续代码都是围绕它们展开:
torch.utils.data.Dataset:自定义数据集的 “模板”,必须实现 3 个方法才能用torch.utils.data.DataLoader:批量加载数据的 “工具”,解决单条取数据效率低的问题torch.utils.data.Subset/random_split:划分数据集的 “助手”,用于拆分训练集 / 验证集
二、第一步:导入依赖库(代码基础)
先导入需要的 PyTorch 工具类,相当于 “提前准备好要用的工具”
import torch # PyTorch核心库,用于生成数据、张量操作等
from torch.utils.data import Dataset, Subset, random_split # 数据集相关核心工具
三、自定义数据集:继承 Dataset 类(核心步骤)
要让 PyTorch 识别我们的数据集,必须创建一个类继承Dataset,并实现3 个强制方法:__init__、__len__、__getitem__。
3.1 类的定义与初始化(init 方法)
作用:读取 / 加载数据集的 “元数据”(描述数据的数据)和实际数据(如图像、标签)
# 自定义数据集类,必须继承 torch.utils.data.Dataset
class MyDataset(Dataset):def __init__(self):super().__init__() # 调用父类Dataset的初始化方法,固定写法# 1. 加载“图像数据”(示例用随机数据模拟,实际中会读本地文件如.jpg/.png)# torch.rand(10050, 3, 32, 32):生成10050张图片,每张是3通道(RGB)、32x32像素self.images = torch.rand(10050, 3, 32, 32)# 2. 加载“标签数据”(示例用随机整数模拟,实际中标签需与图像一一对应)# torch.randint(0, 3, (10050,)):生成10050个标签,取值范围0-2(对应3个类别)self.labels = torch.randint(0, 3, (10050,))
- 关键细节:
- 实际项目中,
self.images不会用torch.rand(随机数据无意义),而是用PIL.Image.open()或torchvision.io.read_image()读取本地图片文件; self.labels通常从标签文件(如.csv、.txt)中读取,确保每个标签对应一张图像。
- 实际项目中,
3.2 返回数据集长度(len 方法)
作用:告诉 PyTorch “这个数据集一共有多少条数据”,方便后续迭代和划分
def __len__(self):# 数据集长度 = 标签数量(因为每个数据对应一个标签,一一对应)return len(self.labels)
- 示例:当前数据集有 10050 个标签,所以
len(ds)会返回 10050。
3.3 单条数据获取(getitem 方法)
作用:根据索引idx,返回 “单条数据 + 对应标签”,是 PyTorch 读取数据的核心接口
def __getitem__(self, idx):# idx:传入的索引(比如idx=0表示取第1条数据,idx=1表示第2条)img = self.images[idx] # 根据索引取1张图像label = self.labels[idx] # 根据同一索引取对应标签return img, label # 返回(图像,标签)对
- 关键细节:
- 调用方式:
img, label = ds[0](直接用 “数据集对象 [索引]” 即可取单条数据); - 必须返回 “数据 + 标签”,后续模型训练时会按这个格式接收数据。
- 调用方式:
四、批量加载数据:使用 DataLoader(实用工具)
自定义好数据集后,用DataLoader将数据 “批量打包”,避免每次训练都单条取数据(效率极低)。
4.1 DataLoader 基础用法(代码示例)
if __name__ == '__main__': # 当脚本直接运行时执行以下代码from torch.utils.data import DataLoader # 导入DataLoader(也可在开头统一导入)# 1. 实例化自定义数据集ds = MyDataset()print(len(ds)) # 打印数据集总长度:输出10050# 2. 测试单条数据获取img, label = ds[0] # 调用__getitem__(0)print(img.shape) # 输出图像形状:torch.Size([3, 32, 32])(3通道、32x32像素)print(label) # 输出标签:比如tensor(1)(0-2之间的随机整数)# 3. 用DataLoader批量加载数据dl = DataLoader(dataset=ds, # 要加载的数据集(必须是Dataset类的实例)batch_size=100,# 每批加载100条数据shuffle=True # 每次加载前是否打乱数据(训练集建议True,验证/测试集建议False))# 4. 迭代获取批量数据(训练时会这么用)for i, (images, labels) in enumerate(dl): # 每次循环取1批数据print(f'第 {i + 1} 批次')print(images.shape) # 输出批次图像形状:torch.Size([100, 3, 32, 32])(100条/批)print(labels.shape) # 输出批次标签形状:torch.Size([100])(100个标签/批)
4.2 DataLoader 关键参数解析
| 参数名 | 作用 |
|---|---|
dataset | 传入自定义的数据集实例(如MyDataset()的结果),必须是Dataset子类 |
batch_size | 每批数据的条数,比如100表示每次给模型喂 100 条数据训练 |
shuffle | 是否打乱数据顺序: - 训练集:True(避免模型学顺序规律,提升泛化能力) - 验证 / 测试集:False(结果可复现) |
五、划分数据集:Subset 与 random_split(拆分训练 / 验证集)
当需要把数据集拆分成训练集(train)和验证集(val)时,用Subset(指定索引)或random_split(按比例随机划分)。
5.1 方法 1:Subset(指定具体索引,灵活但麻烦)
作用:从原数据集中 “截取指定索引的子集”,适合需要精确控制数据划分的场景
if __name__ == '__main__':ds = MyDataset() # 实例化原数据集# 创建子集:从ds中取索引为0、1、2的3条数据sub_ds = Subset(dataset=ds, # 原数据集indices=[0,1,2]# 要截取的索引列表)print(len(sub_ds)) # 输出3,子集只有3条数据img, label = sub_ds[0] # 取子集的第1条数据(对应原数据集的索引0)
5.2 方法 2:random_split(按比例随机划分,常用)
作用:按指定 “长度比例” 随机拆分数据集,适合快速划分训练 / 验证集
if __name__ == '__main__':ds = MyDataset() # 实例化原数据集total_len = len(ds) # 原数据集总长度:10050# 1. 按8:2比例计算训练集和验证集长度train_len = int(total_len * 0.8) # 训练集长度:10050*0.8=8040(int()取整)val_len = total_len - train_len # 验证集长度:10050-8040=2010# 2. 随机划分:返回两个子集(训练集、验证集)train_ds, val_ds = random_split(dataset=ds, # 原数据集lengths=[train_len, val_len]# 子数据集的长度列表(顺序对应返回结果))# 3. 查看划分后的数据量print(len(train_ds)) # 输出8040(训练集长度)print(len(val_ds)) # 输出2010(验证集长度)
- 关键细节:
random_split会随机打乱原数据集后再拆分,每次运行结果可能不同(若需固定结果,可设置随机种子:torch.manual_seed(42));- 划分后的
train_ds和val_ds也是Dataset子类,可直接传入DataLoader批量加载。
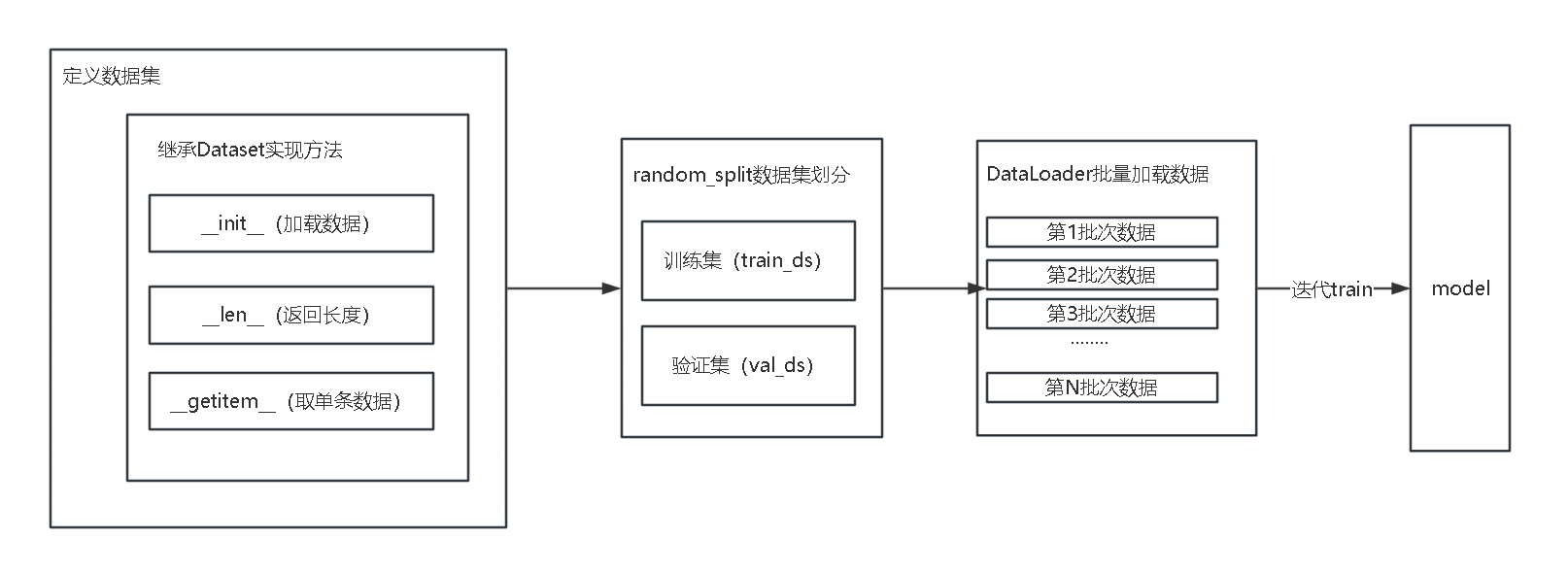
六、整体流程总结(从定义到使用)
- 定义数据集:继承
Dataset,实现__init__(加载数据)、__len__(返回长度)、__getitem__(取单条数据); - 划分数据集:用
random_split按比例拆分为训练集(train_ds)和验证集(val_ds); - 批量加载:用
DataLoader分别对训练集、验证集做批量处理(设置batch_size和shuffle); - 模型训练:迭代
DataLoader,每次获取 1 批数据喂给模型训练。