论文阅读:Code as Policies: Language Model Programs for Embodied Control
地址:Code as Policies: Language Model Programs for Embodied Control
摘要
针对代码补全任务训练的大型语言模型(LLMs)已被证实能够从文档字符串(docstrings)中合成简单的 Python 程序。研究发现,这些具备代码编写能力的 LLM 可被重新赋能,在给定自然语言指令的情况下生成机器人策略代码。具体而言,策略代码能够表示处理感知输出(例如来自目标检测器的输出)并对控制原语 API 进行参数化的函数或反馈循环。当向 LLM 输入若干个以注释格式呈现的自然语言指令示例及其对应的策略代码(通过少样本提示实现)后,LLM 可接收新的指令并自主重组 API 调用,分别生成新的策略代码。通过链接经典逻辑结构并引用第三方库(如 NumPy、Shapely)执行算术运算,此类用法下的 LLM 能够生成具备以下能力的机器人策略:(i)展现空间几何推理;(ii)泛化到新指令;(iii)根据上下文(即行为常识)为模糊描述(如 “更快”)指定精确值(如速度)。本文提出 “代码即策略(Code as Policies, CaP)”:一种以机器人为中心的语言模型生成程序(Language Model Programs, LMPs)形式化方案,该方案可表示反应式策略(如阻抗控制器)以及基于路径点的策略(视觉引导的拾取放置、基于轨迹的控制),并在多个真实机器人平台上完成验证。该方法的核心是 “提示分层代码生成(prompting hierarchical code-gen)”—— 递归定义未定义函数,这不仅能生成更复杂的代码,还能将 HumanEval基准测试的问题解决率提升至 39.8%(当前最优水平)。相关代码与视频可在https://code-as-policies.github.io获取。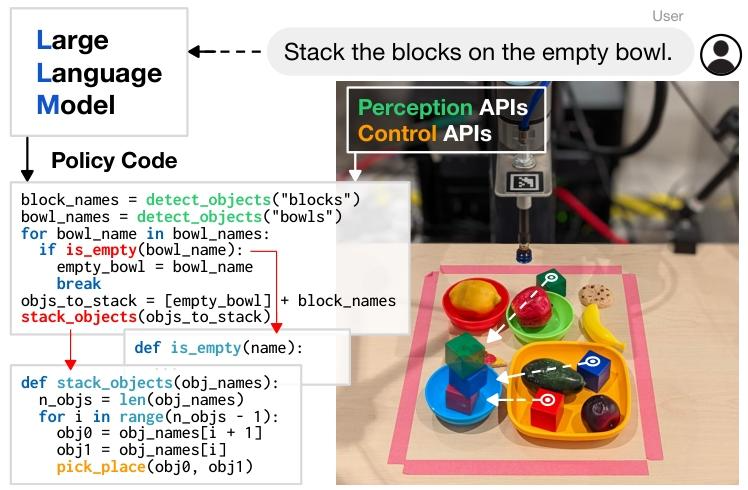
一、概述
1. 研究背景与问题
机器人需将自然语言 “接地(grounded)” 到物理世界,以建立语言、感知与动作的关联。传统方法存在两大局限:
- 经典方法(如词汇分析提取语义表示)难以处理未见过的指令;
- 端到端学习方法(语言直接映射到动作)需大量真实机器人训练数据,成本高昂。
现有 LLM 在机器人领域的应用仅局限于 “规划技能序列”,无法直接参与感知 - 动作反馈循环,导致难以实现:①感知 - 动作模式的泛化(如从 “把苹果放在橙子上” 到 “看到橙子就放下苹果”);②控制常识的表达(如 “更快移动”“更用力推”);③空间关系理解(如 “把苹果往左移一点”)。
2. 核心方法:代码即策略(CaP)
将具备代码生成能力的 LLM(如 Codex)重新赋能,通过少样本提示生成机器人策略代码(即 LMPs),直接作为可执行的机器人策略。LMPs 通过以下方式实现感知 - 控制闭环:
- 输入:自然语言指令(格式化为代码注释);
- 生成:调用感知 API(如目标检测、位置获取)和控制原语 API(如速度设置、拾取放置)的 Python 代码;
- 关键创新:分层代码生成—— 递归定义未定义函数,逐步积累函数库,提升代码复杂度与泛化能力。
3. 核心贡献
- 提出 “代码即策略(CaP)” 方案:将 LLM 生成的代码直接作为机器人策略,实现语言 - 感知 - 动作的深度关联;
- 分层代码生成方法:在机器人代码生成与通用代码生成(HumanEval)中均突破当前最优,HumanEval 的 P@1 达 39.8%;
- 构建机器人专属代码生成基准(RoboCodeGen):包含空间推理、几何推理、控制等 37 个任务,用于评估 LLM 在机器人领域的代码生成能力;
- 验证泛化能力与缩放定律:CaP 在未见过的指令 / 目标上表现优异,且 LLM 模型规模越大,性能越好。
4. 实验结果
| 实验场景 | 关键结论 |
|---|---|
| 代码生成基准(RoboCodeGen) | 分层方法在各模型上均优于扁平方法,Codex davinci 模型分层方法通过率达 95%; |
| 通用代码基准(HumanEval) | 分层方法 P@1 达 39.8%,优于扁平方法(34.9%)及现有工作 [1,11,58]; |
| 真实机器人验证(UR5e、移动机器人) | 完成桌面操作、白板绘图、厨房移动操作,支持空间推理(如 “画更小的金字塔”)与长序列任务; |
| 仿真桌面操作对比 | 面对未见过的属性 / 指令,CaP 成功率(62%-97.6%)显著优于 CLIPort(0%-36.8%)与自然语言规划器(64%-88%); |
5. 局限性
- 依赖感知 API 与控制原语:无法处理感知 API 无法描述的属性(如轨迹 “颠簸”)或未定义的控制原语;
- 指令复杂度限制:难以处理远超示例抽象层级或长度的指令(如 “用积木建房子”);
- 可行性假设:默认指令可执行,无法预先判断生成代码的正确性;
- 跨具身鲁棒性不足:虽能适配不同机器人 API,但对差异过大的 API 适配能力较弱。
二、研究动机
1. 传统语言 - 机器人控制方法的 “泛化能力不足” 问题
传统机器人语言控制方法分为两类,均存在泛化短板:
- 经典语义解析方法(如词汇分析提取语义表示 [5]-[7]):需预先定义语言与动作的映射规则,无法处理未见过的指令(如未训练 “将积木排成对角线”,则无法执行该指令);
- 端到端学习方法(语言直接映射到动作 [8]-[10]):需在真实机器人上收集大量训练数据(如数万次 “拾取 - 放置” 演示),数据获取成本极高,且跨场景泛化能力弱(如桌面操作模型无法迁移到移动导航)。
论文通过 “代码即策略(CaP)” 方案,利用 LLM 的少样本泛化能力,仅需少量指令 - 代码示例即可生成新任务策略,无需额外训练数据,解决泛化与数据成本的矛盾。
2. 现有 LLM 机器人应用的 “感知 - 动作闭环缺失” 问题
现有 LLM 在机器人领域的应用仅局限于 “高层级技能序列规划”(如 “拿起苹果→移动到桌子→放下”[14],[17],[18]),无法直接参与感知 - 动作反馈循环,导致三大关键需求无法满足:
- 感知 - 动作模式泛化:无法从 “静态指令”(如 “把苹果放在橙子上”)扩展到 “动态反馈指令”(如 “看到橙子就放下苹果”);
- 控制常识表达:无法为模糊自然语言描述(如 “更快移动”“更用力推”)分配精确控制参数(如速度值、力值);
- 空间几何推理:无法处理需数值计算的空间指令(如 “将积木排成 20cm 长的竖直线”“在金字塔左侧画更小的金字塔”)。
论文通过让 LLM 生成直接调用感知 API(如目标检测、位置获取)与控制 API(如速度设置、拾取放置)的代码,构建语言 - 感知 - 动作的直接闭环,解决上述需求。
3. 机器人策略的 “可解释性与灵活性不足” 问题
传统机器人策略(如端到端神经网络、预定义技能库)存在两大缺陷:
- 可解释性差:端到端模型的决策过程黑箱化,难以调试(如 “为何未将苹果放入碗中” 无法追溯原因);
- 灵活性低:预定义技能库需覆盖所有可能动作(如 “左移 1cm”“左移 2cm” 需分别定义),无法动态调整逻辑(如 “直到看到苹果才停止移动” 需额外开发反馈逻辑)。
论文以 “代码” 作为机器人策略载体,代码逻辑透明可追溯(可解释性),且通过循环、条件等逻辑结构实现动态反馈(灵活性),解决上述缺陷。
三、方法架构
1. 设计方法:LMPs 的生成与执行框架
CaP 的核心是 “语言模型程序(LMPs)”—— 由 LLM 生成、可在机器人上直接执行的代码,其生成与执行分为 3 个关键步骤:
(1)提示工程:构建 LMP 生成的输入
提示(Prompt)包含两类核心元素,确保 LLM 理解 API 用法与指令 - 代码映射规则:
- 提示语(Hints):告知 LLM 可用 API 与类型提示,如导入第三方库(NumPy、Shapely)或机器人专属 API(
get_pos、put_first_on_second); 示例:import numpy as np; from utils import get_pos, put_first_on_second - 示例(Examples):指令 - 代码对的少样本演示,格式为 “自然语言注释 + 对应代码”,让 LLM 学习映射逻辑; 示例:
# 把紫色碗往左移;target_pos = get_pos('purple bowl') + [-0.3, 0]; put_first_on_second('purple bowl', target_pos)
(2)分层代码生成:提升代码复杂度与泛化
通过 “递归定义未定义函数” 实现分层生成,核心流程:
- 高层 LMP 生成调用未定义函数的代码(如
stack_objs_in_order(obj_names)); - 解析抽象语法树(AST),识别未定义函数;
- 调用专用 LMP 生成未定义函数的实现(如
def stack_objs_in_order(obj_names): ...); - 深度优先递归执行上述步骤,直至所有函数均定义,形成完整代码库。
该方法本质是 “函数式编程风格的思维链(Chain of Thought)”,既降低单步代码生成复杂度,又支持代码复用。
(3)LMP 执行:安全检查与作用域管理
为确保机器人执行安全,LMP 执行前需经过两步处理:
- 安全检查:禁止包含
import、__开头的特殊变量、exec/eval调用,避免恶意代码或环境污染; - 作用域管理:通过两个字典定义执行作用域:
globals:存储所有可用 API(感知、控制);locals:空字典,执行中动态存储生成的变量与函数;
- 执行:调用 Python 的
exec函数执行 LMP 代码,若需返回值则从locals中提取。
2. 设计内容:LMPs 的核心组成与层级示例
LMPs 通过 “逻辑结构 + 库调用 + 分层设计” 实现复杂机器人任务,分为低层级与高层级两类:
(1)低层级 LMP:基础功能实现
聚焦 “感知输出处理” 与 “控制原语参数化”,依赖第三方库与基础 API:
- 算术与坐标计算:基于 NumPy 处理空间坐标,如计算中心点、最左点; 示例:中心点计算
ret_val = np.mean(pts_np, axis=0);最左点计算ret_val = pts_np[np.argmin(pts_np[:, 0]), :] - 语言推理:关联自然语言描述与目标(如 “海蓝色积木”→“蓝色积木”); 示例:
# 海蓝色积木;ret_val = 'blue block' - 一阶 API 调用:直接调用机器人感知 / 控制 API,如移动指定目标; 示例:
# 把红色积木往右移一点;target_pos = get_pos('red block') + [0.1, 0]; put_first_on_second('red block', target_pos)
(2)高层级 LMP:复杂行为与控制流
通过控制结构(循环、条件)与函数嵌套,实现反应式策略与长序列任务:
- 控制流(循环 / 条件):构建反馈策略,如 “直到看到苹果才停止右移”; 示例:
while not detect_object("apple"): robot.set_velocity(x=0, y=0.1, z=0) - 函数嵌套:调用其他 LMP(如
parse_obj)解析复杂语言描述,如 “最左侧的积木”; 示例:block_name = parse_obj('the left most block'); while block_name == 'red block': ... - 反应式控制器:生成 PD 控制、阻抗控制等低层级控制器,如倒立摆平衡; 示例:PD 控制函数生成
(3)LMP 的核心特性
| 特性 | 描述 |
|---|---|
| 感知 - 控制接地 | 直接调用感知 API(如 MDETR/ViLD 目标检测)与控制 API,建立语言到物理世界的映射; |
| 常识嵌入 | 基于 LLM 训练数据中的代码与注释,为模糊描述(如 “更快”)分配精确值(如速度 - 0.2); |
| 人机交互能力 | 通过robot.say(text) API 实现对话与问答(如 “解释为何停止移动”); |
| 跨平台适配 | 仅需替换感知 / 控制 API,即可适配 UR5e 机械臂、Everyday Robots 移动机器人等; |
3. 设计原理:为何 “代码即策略” 可行?
(1)LLM 代码生成能力的迁移性
代码补全 LLM(如 Codex)在数十亿行代码与注释上训练,具备:
- 理解自然语言与代码的映射关系(从注释生成代码);
- 掌握 Python 语法、第三方库(NumPy/Shapely)用法,可直接用于空间几何推理;
- 少样本学习能力:通过少量指令 - 代码示例,泛化到新任务。
(2)“代码” 作为策略的天然优势
相比传统机器人策略(如端到端模型、预定义技能库),代码策略具备:
- 可解释性:代码逻辑透明,便于调试与修改;
- 灵活性:通过逻辑结构(循环、条件)实现动态反馈,无需预定义所有技能;
- 精确性:支持数值计算(如 “20cm 长的竖直线”),解决自然语言规划器的模糊性问题。
(3)分层代码生成的性能提升原理
- 复杂度分解:将复杂任务(如 “堆叠积木到空碗”)拆解为子函数(
is_empty、stack_objects),降低单步生成难度; - 知识积累:生成的函数可被后续 LMP 引用,逐步构建专属函数库,提升长任务处理能力;
- 符合 LLM 输入长度限制:分层生成避免单条提示过长,适配 LLM 的 token 长度约束。
四、数据集
1. LMP 生成依赖的 LLM 预训练数据集
本文用于生成机器人策略代码(LMPs)的大语言模型(LLM)均为复用现有预训练模型,未自行构建预训练数据集,模型及对应预训练数据来源如下:
- OpenAI Codex(code-davinci-002、code-cushman):预训练数据为互联网规模的代码库与自然语言文本,包含数十亿行 Python 代码、注释及文档字符串,覆盖第三方库(如 NumPy、Shapely)用法、编程逻辑(循环、条件控制)等,具备从自然语言注释生成代码的能力 [1];
- GPT-3(6.7B 参数)与 InstructGPT(175B 参数):预训练数据为互联网文本(含部分代码),用于对比不同模型规模对代码生成性能的影响 [12,22];
- PaLM Coder:预训练数据包含大规模代码与文本,用于 HumanEval 基准对比 [11]。
上述预训练数据集均为模型原有训练数据,本文未对其进行额外补充或修改,仅通过 “提示工程(Prompt Engineering)” 引导模型生成机器人相关代码。
2. 实验验证数据集
本文实验分为代码生成基准测试与机器人任务验证,两类实验的数据集来源不同,具体如下:
(1)代码生成基准数据集
用于评估 LMPs 的代码生成性能,包含两个公开基准与一个自定义基准:
- HumanEval [1]:公开通用代码生成基准,包含 164 个 Python 函数生成任务,覆盖字符串处理、数组操作、数学计算等通用场景,用于验证分层代码生成方法在通用代码任务上的性能;
- RoboCodeGen(自定义):本文构建的机器人专属代码生成基准,包含 37 个函数生成任务,聚焦机器人领域核心需求,具体任务类型及数据来源如下:
- 空间推理任务:如 “计算点集中最近点”“生成两点间插值点”,基于机器人操作中的坐标计算需求设计;
- 几何推理任务:如 “判断一个边界框是否包含另一个”“生成指定半径的圆形”,依赖 Shapely 库与目标检测边界框(bbox)处理逻辑设计;
- 控制任务:如 “PD 控制器实现”“末端阻抗控制函数生成”,基于机器人低层级控制算法设计;
- 数据特点:无显式文档字符串或类型提示,要求 LLM 通过函数名与任务描述推断逻辑,支持调用未定义函数(分层生成)与第三方库(NumPy/Shapely)。
(2)机器人任务验证数据集
用于在真实 / 仿真机器人上验证 CaP 的有效性,数据集均为自定义场景配置,无公开数据集依赖,具体如下:
- 桌面操作场景(真实 + 仿真):
- 物体集:10 个彩色积木(红、蓝、绿等)+10 个彩色碗(对应颜色),物体属性(颜色、位置)随机采样;
- 任务集:分为 “长序列任务”(如 “将积木放入匹配颜色的碗”)与 “空间几何任务”(如 “将积木排成 20cm 长的竖直线”),任务指令模板及属性(如 “<block>”“<direction>”)分为 “已见(Seen)” 与 “未见(Unseen)”,用于测试泛化能力;
- 数据来源:仿真环境复用 [16,18] 的 UR5e 机械臂 + Robotiq 2F85 夹爪仿真场景,真实环境基于 UR5e 机械臂 + Intel Realsense D435 深度相机搭建,物体位置通过 MDETR [2](真实)/ 脚本化检测器(仿真)获取。
- 白板绘图场景(真实):
- 场景配置:UR5e 机械臂 + 白板 + 干擦笔,额外物体(如蓝色积木)用于参考定位;
- 任务集:自定义绘图指令(如 “画 5cm 六边形”“在金字塔左侧画更小的金字塔”), Waypoint 坐标通过 LMPs 调用 NumPy 计算生成。
- 移动操作场景(真实):
- 场景配置:Everyday Robots 移动机器人(带 7DoF 机械臂)+ 办公室厨房环境,物体(水瓶、可乐罐、水果)随机放置;
- 任务集:导航任务(如 “绕办公椅走 3m×2m 矩形”)与操作任务(如 “将可乐罐放入回收箱”),物体位置通过 ViLD [3] 目标检测获取,导航坐标基于机器人自身定位系统。
五、实验设计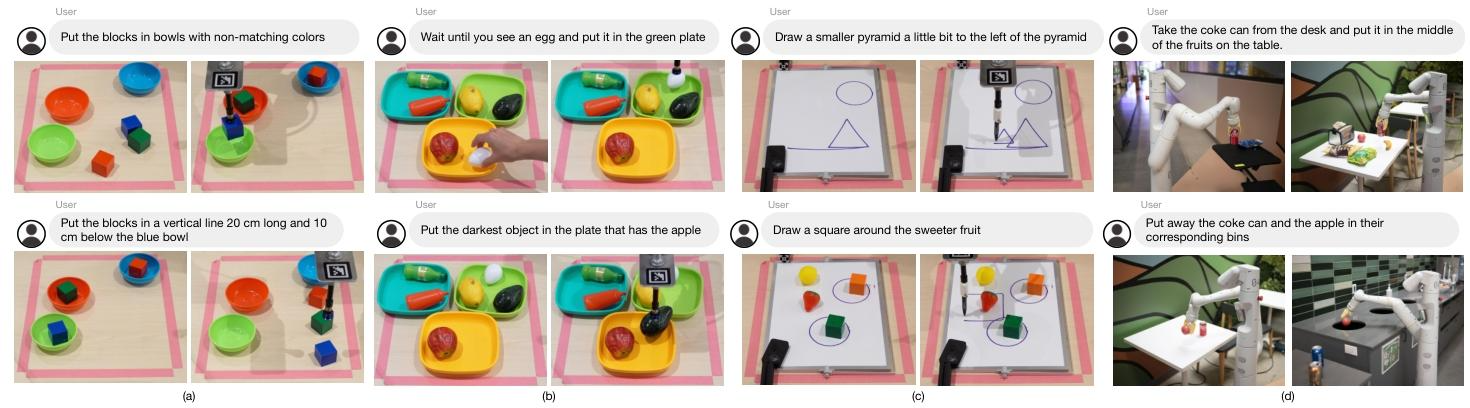
1. 代码生成基准实验对照组(RoboCodeGen + HumanEval)
(1)模型规模对照组
用于验证 “缩放定律(larger models perform better)”,即 LLM 模型规模对代码生成性能的影响,选择 4 个不同规模 / 类型的 LLM:
- GPT-3(6.7B 参数):纯文本 LLM,代码生成能力较弱,作为基础对照;
- InstructGPT(175B 参数):大参数量文本 LLM,具备更好的语言理解能力;
- Codex cushman:小型代码专用 LLM,训练数据以代码为主;
- Codex davinci:大型代码专用 LLM(规模大于 cushman),代码生成能力最优 [1];
- 控制变量:均采用 “扁平代码生成(Flat)” 或 “分层代码生成(Hierarchical)” 方法,提示结构一致。
(2)代码生成方法对照组
用于验证 “分层代码生成” 的优势,针对同一 LLM(如 Codex davinci)设置两种方法:
- 扁平代码生成(Flat):禁止调用未定义函数,要求 LLM 一次性生成完整代码,无分层拆解;
- 分层代码生成(Hierarchical,CaP 核心):允许调用未定义函数,通过递归提示生成子函数,逐步构建完整代码;
- 控制变量:模型参数、提示中的示例数量 / 格式、任务输入一致。
(3)通用代码生成基准对照组
在 HumanEval 基准中,对比 CaP 与现有代码生成方法的性能:
- code-davinci-001 [11]:早期 Codex 模型,无分层生成能力;
- PaLM Coder [11]:Google 大参数量代码 LLM;
- Flat CodeGen + No Prompt:直接使用 Codex davinci 生成代码,无额外提示;
- Flat CodeGen + Flat Prompt:使用扁平提示(含 2 个示例)生成代码,无分层逻辑;
- 控制变量:HumanEval 任务集一致,评估指标(通过率)计算方式相同。
2. 机器人任务实验对照组(仿真 + 真实)
(1)仿真桌面操作对照组
用于验证 CaP 在结构化任务中的泛化能力,选择 2 类主流机器人控制方法:
- CLIPort [36]:语言条件下的端到端模仿学习方法,需 30k 条演示数据训练,分为两个子对照:
- CLIPort(oracle termination):使用仿真环境 “先知信息”,任务完成时自动停止策略执行(优化性能上限);
- CLIPort(no oracle):无先知信息,固定执行 10 步动作后评估(模拟真实场景);
- NL Planner(自然语言规划器):基于 LLM 的任务规划方法,仅输出 “技能序列”(如 “拿起可乐罐→右移→放下”),依赖预定义技能库 [14,17,18];
- 控制变量:仿真环境(UR5e 机械臂 + 10 积木 + 10 碗)、任务指令模板、物体初始位置采样方式一致。
(2)真实机器人任务
- 任务设计:包含 “已见指令 / 属性”(如 “将积木放入匹配颜色的碗”)与 “未见指令 / 属性”(如 “将积木放入不匹配颜色的碗”);
- 验证逻辑:若 CaP 在未见任务上的成功率显著高于 “需预训练的 CLIPort” 与 “依赖预定义技能的 NL Planner”,则证明其泛化优势;
- 控制变量:真实机器人硬件(UR5e、Everyday Robots)、感知 API(MDETR/ViLD)、控制原语 API 一致。
3. 空间几何推理对照组(Code vs. 自然语言)
用于验证 “代码推理” 相比 “自然语言推理” 的精确性优势,设计 2 类自然语言推理方法:
- Vanilla NL(纯自然语言推理):直接输入场景描述(如物体位置列表)与问题,LLM 输出自然语言答案(如 “红色积木”);
- Chain of Thought(CoT)[47]:提示 LLM 分步推理(如 “先列出所有积木的 y 坐标→找出 y 最大的积木”),输出自然语言推理过程与答案;
- 控制变量:推理任务集(28 个物体选择任务 + 23 个位置选择任务)、场景上下文(物体位置、属性)一致,均使用 Codex davinci 模型。
六、评价指标
1. 代码生成基准指标(RoboCodeGen + HumanEval)
(1)通过率(% Pass Rate)
- 定义:通过单元测试的任务数占总任务数的百分比,核心指标,反映代码生成的正确性;
- 示例:HumanEval 中,CaP 分层方法的 Greedy 通过率为 53.0%,P@1 为 39.8%[]。
(2)泛化类型通过率(基于 [23] 的 5 类泛化)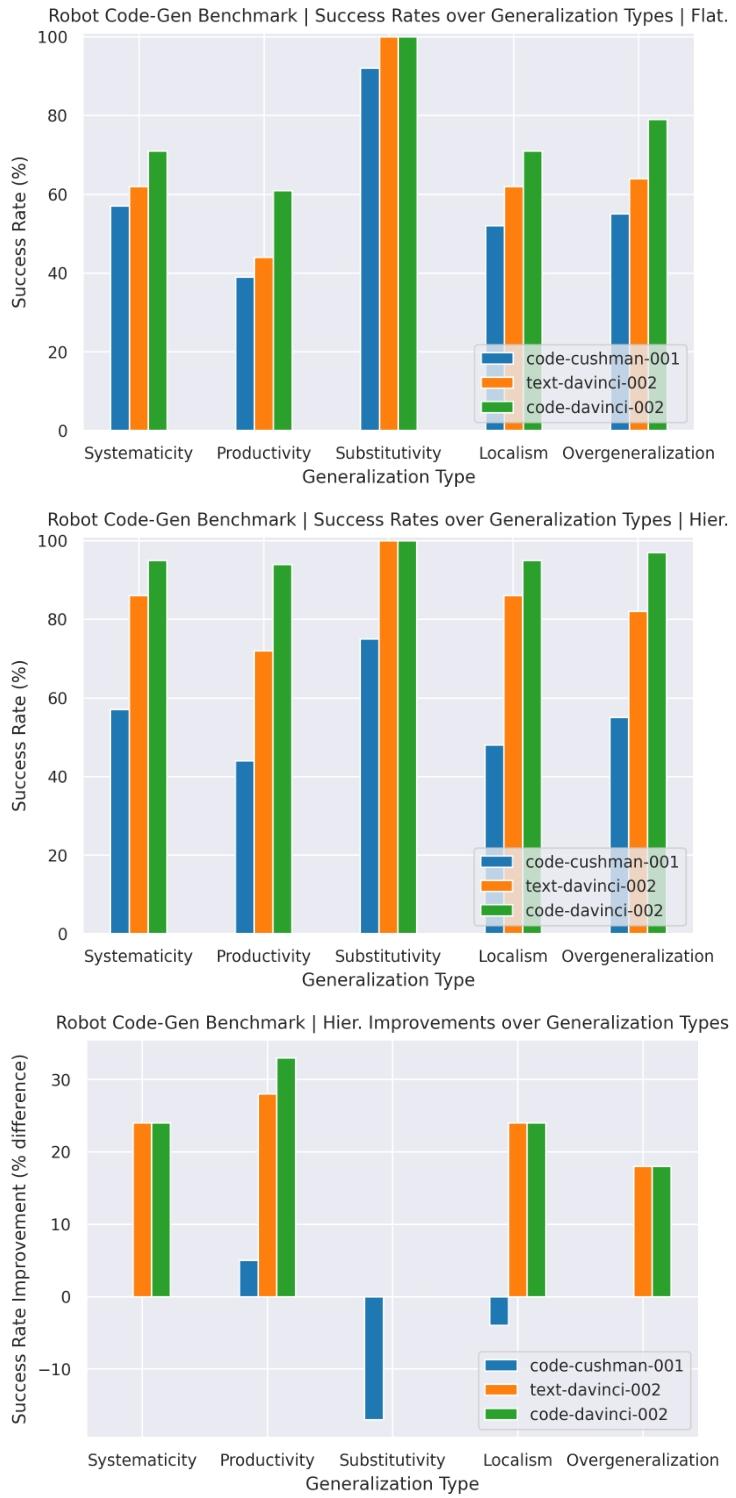
- 定义:评估代码生成在不同泛化场景下的性能,细分 5 类泛化:
- Systematicity(系统性):重组示例中的代码片段(如 “将‘左移’逻辑重组为‘右移’”);
- Productivity(扩展性):生成比示例更长 / 逻辑层级更多的代码(如 “从‘2 个积木堆叠’到‘5 个积木堆叠’”);
- Substitutivity(替代性):替换示例中的同义词 / 同类词(如 “‘碗’替换为‘容器’”);
- Localism(局部性):将示例中的局部概念用于新场景(如 “将‘计算中心点’用于‘计算边界框中心’”);
- Overgeneralization(过度泛化):使用示例中未出现的 API / 语法(如 “示例用 NumPy,生成用 Shapely”);
- 计算方式:对每类泛化场景,单独统计通过率,分析分层方法的优势领域(如 Productivity 提升最显著 [])。
2. 机器人任务评价指标
(1)任务成功率(Task Success Rate)
- 定义:完成指定任务的实验次数占总实验次数的百分比,核心指标;
- 任务完成条件(细分场景):
- 桌面操作:物体最终位置满足指令要求(如 “积木放入碗中” 则积木中心与碗中心距离 < 2cm);
- 绘图任务:生成形状与指令偏差 <1cm(如 “5cm 六边形” 的边长偏差 < 0.5cm);
- 移动任务:导航轨迹与指令路径偏差 < 0.3m,操作任务中物体成功放置到目标位置;
- 示例:仿真中 “UA-UI 空间几何任务”,CaP 成功率为 62.0%,而 CLIPort 仅为 0.01%[]。
(2)泛化能力指标(未见任务 / 属性成功率)
- 定义:在 “未见指令” 或 “未见属性” 任务上的成功率,反映 CaP 的泛化优势;
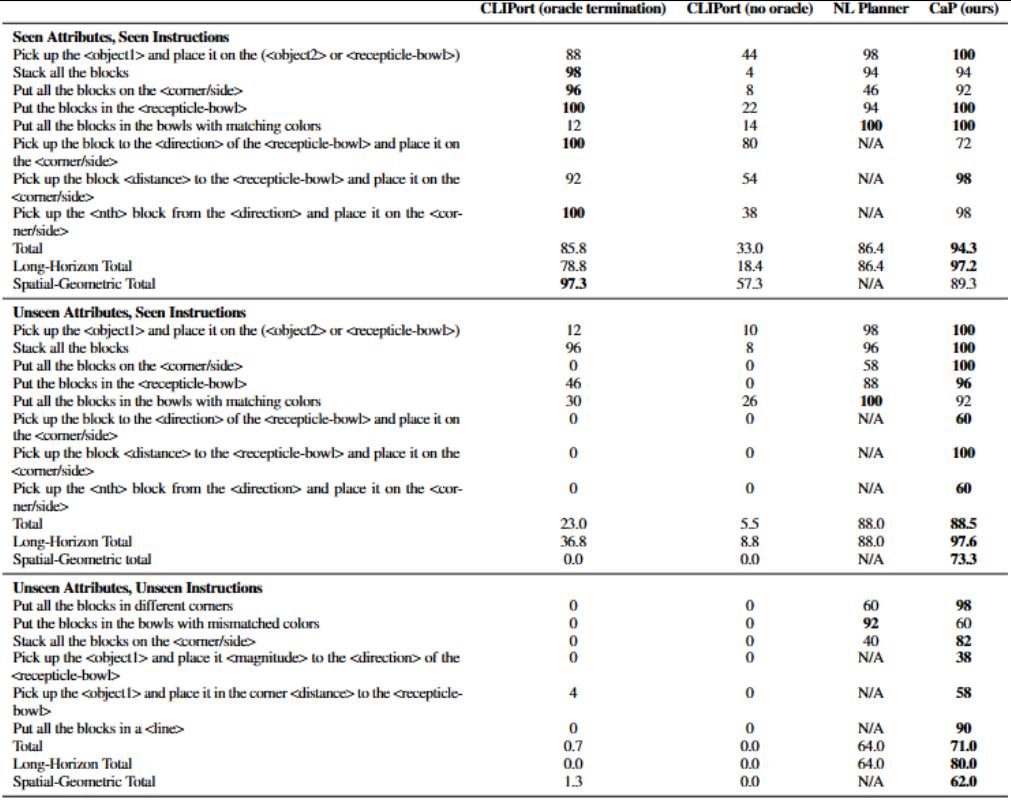
- 计算方式:分别统计 “SA-SI”“UA-SI”“UA-UI” 三类任务的成功率,对比 CaP 与对照组(如 CLIPort 在 UA-SI 长序列任务中成功率 36.8%,CaP 达 97.6%[])。
3. 空间几何推理评价指标
(1)推理正确率(Reasoning Accuracy)
- 定义:正确完成推理任务的数量占总任务数的百分比;
- 细分维度:
- 物体选择正确率:如 “找出离蓝色碗最近的积木”,答案与标注一致则正确;
- 位置选择正确率:如 “插值 3 个点”,所有点坐标与真值误差 < 1cm 则正确;
- 示例:位置选择任务中,LMP 正确率 100%,CoT 为 48%,Vanilla NL 为 30%。
(2)位置误差(Position Error)
- 定义:仅用于位置选择任务,量化推理结果的精确性;
- 评价标准:误差 <1cm 视为正确,统计平均误差与最大误差(LMP 平均误差 < 0.5cm,自然语言推理平均误差> 3cm )。
七、创新点分析
1. 方法创新:提出 “代码即策略(Code as Policies, CaP)” 的形式化方案
(1)核心思想:将 LLM 生成的代码直接作为可执行的机器人策略
突破 “LLM 仅用于规划” 的传统定位,将具备代码生成能力的 LLM(如 Codex)重新赋能为 “机器人策略生成器”:
- 输入:自然语言指令(格式化为 Python 注释,如
# 把红色积木往左移5cm); - 输出:可直接执行的 Python 代码(即 LMPs,Language Model Programs),代码中调用:
- 感知 API:如
get_pos(obj_name)(获取物体位置,基于 MDETR [2]/ViLD [3] 目标检测)、detect_object(obj_name)(检测物体是否存在); - 控制 API:如
put_first_on_second(obj1, obj2)(拾取 obj1 并放置到 obj2)、robot.set_velocity(x, y, z)(设置机器人速度);
- 感知 API:如
- 优势:无需预定义技能库,代码逻辑直接关联语言、感知与动作,实现 “语言指令→代码策略→机器人动作” 的端到端闭环。
(2)策略表示能力:覆盖反应式与路径点两类核心机器人策略
CaP 生成的 LMPs 可灵活表示机器人领域两类关键策略,无需修改框架:
-
反应式策略:通过循环、条件控制实现实时反馈,如 PD 控制器、阻抗控制器,示例为倒立摆平衡的 PD 控制函数:
def keep_pole_upright_with_pd_control(x, x_dot, theta, theta_dot):kp = 1 # 比例增益kd = 1 # 微分增益error = theta # 摆杆角度误差error_dot = theta_dot # 摆杆角速度误差control = kp * error + kd * error_dot # PD控制量计算direction = 1 if control >= 0 else 0 # 1=右移,0=左移return direction -
基于路径点的策略:通过第三方库(NumPy/Shapely)计算空间坐标,生成路径点序列,如白板绘图的 Waypoint 生成:
import numpy as np # 生成5cm六边形的Waypoint def generate_hexagon_pts(center, radius):angles = np.linspace(0, 2*np.pi, 6, endpoint=False) # 6个顶点角度x = center[0] + radius * np.cos(angles)y = center[1] + radius * np.sin(angles)return np.column_stack((x, y)) # 输出6个顶点坐标
2. 技术创新:提出 “分层代码生成(Hierarchical Code-Gen)” 方法
(1)核心逻辑:递归定义未定义函数,突破代码生成复杂度限制
针对 “复杂任务难以一次性生成完整代码” 的问题,设计分层生成流程:
- 高层代码生成:输入任务指令,生成调用 “未定义函数” 的框架代码,如 “堆叠积木到空碗” 的高层代码:
# 堆叠积木到空碗 empty_bowl = find_empty_bowl(bowl_names) # 未定义函数 stack_objs([empty_bowl] + block_names) # 未定义函数 - 未定义函数识别:解析代码抽象语法树(AST),定位
find_empty_bowl、stack_objs等未定义函数; - 递归生成子函数:针对每个未定义函数,生成专属提示并调用 LLM 生成实现代码,如:
# 定义find_empty_bowl函数 def find_empty_bowl(bowl_names):for bowl in bowl_names:if is_empty(bowl): # 进一步递归生成is_emptyreturn bowl - 作用域管理:生成的子函数存储于执行环境的
locals字典,供后续代码调用,逐步构建 “机器人专属函数库”。
(2)性能突破:刷新代码生成基准的当前最优水平
- HumanEval 基准:分层方法将通用代码生成的 P@1(单次生成正确率)提升至 39.8%,优于扁平生成(34.9%)及现有工作 [1],[11],[58];贪心解码(温度 = 0)通过率达 53.0%,同样为当前最优 ;
- RoboCodeGen 基准:在机器人专属代码生成任务中,分层方法的通过率显著提升,如 Codex davinci 模型的通过率从扁平生成的 81% 提升至 95%,且模型规模越大,分层方法的优势越显著;
- 泛化能力:分层方法对 “扩展性(Productivity)” 泛化的提升最显著 —— 可生成比示例更长、逻辑层级更多的代码(如从 “2 个物体堆叠” 扩展到 “10 个物体堆叠”),而这是扁平生成无法实现的。
3. 应用创新:构建 “零训练成本、跨平台适配” 的机器人控制框架
(1)零训练成本:无需真实机器人数据,仅依赖少样本提示
CaP 无需任何机器人训练数据,仅通过 2-5 个 “指令 - 代码” 示例(少样本提示)即可泛化到新任务,具体优势体现在:
- 未见指令泛化:如训练 “将积木放入匹配颜色的碗”,可泛化执行 “将积木放入不匹配颜色的碗”;
- 未见物体泛化:如训练 “红色 / 蓝色积木操作”,可泛化到 “粉色 / 青色积木”;
- 实验验证:在仿真桌面操作中,面对 “未见属性 - 未见指令” 任务,CaP 成功率达 62.0%-80.0%,而端到端方法 CLIPort 仅为 0.01%-0.0%。
(2)跨平台适配:仅需替换 API,适配多类机器人
CaP 的核心逻辑与机器人硬件无关,仅需替换感知 / 控制 API 即可适配不同平台,论文已验证三类机器人:
- UR5e 机械臂:用于桌面操作(拾取 - 放置)与白板绘图(生成 Waypoint),感知 API 基于 MDETR [2];
- Everyday Robots 移动机器人:用于办公室厨房的导航(如 “绕椅子走矩形”)与移动操作(如 “分类回收垃圾”),感知 API 基于 ViLD [3];
- 仿真 UR5e 机械臂:用于大规模泛化实验,感知 API 为脚本化目标检测器;
- 适配示例:跨机器人执行 “移动目标” 任务,仅需替换控制 API(机械臂用
put_first_on_second,移动机器人用goto_pos + pick_obj),核心代码逻辑不变。
(3)人机交互增强:支持自然语言对话与常识问答
通过在控制 API 中加入robot.say(text)接口,CaP 具备人机对话能力,可解释决策过程:
- 示例 1:输入指令
# 告诉我为什么停止移动,生成代码robot.say("I stopped moving because I saw a banana."); - 示例 2:输入问题
# 桌子上有多少个水果,生成代码调用get_obj_names统计水果数量,并通过robot.say反馈结果; - 优势:突破传统机器人 “仅执行、不解释” 的局限,提升人机协作安全性与易用性。
4. 验证创新:构建机器人专属代码生成基准(RoboCodeGen)
为填补 “机器人领域缺乏代码生成评估基准” 的空白,论文设计 RoboCodeGen 基准,包含 37 个机器人专属函数生成任务,具备以下特点:
- 任务类型聚焦:覆盖空间推理(如 “计算点集中最近点”)、几何推理(如 “判断边界框包含关系”)、控制算法(如 “PD 控制器实现”)三大机器人核心需求;
- 评估难度适配:无显式文档字符串或类型提示,要求 LLM 通过函数名与任务描述推断逻辑,更贴近真实机器人应用场景;
- 支持分层生成:允许调用未定义函数,可评估分层代码生成的性能;
- 实用价值:为后续 LLM 在机器人领域的代码生成研究提供统一评估标准,避免 “各方法自定数据集、无法对比” 的问题。
八、相关工作
1. 领域一:语言驱动机器人控制(传统方法)
传统语言驱动机器人控制方法聚焦 “语言到动作的映射”,但存在泛化能力弱或数据成本高的局限,论文将其分为三类:
(1)高层级语言解释(语义解析与规划)
- 核心思路:通过 lexical analysis(词汇分析)、semantic parsing(语义解析)将自然语言指令转化为结构化表示(如逻辑规则、任务序列),再映射到机器人动作;
- 代表性工作:
- Tellex et al. [4]:提出 “语言接地” 概念,通过语义解析建立语言与物理世界实体的关联,为后续语言 - 机器人控制奠定理论基础;
- Kollar et al. [25]、Thomason et al. [28,32]:开发基于对话的语义解析系统,让机器人通过人机交互修正指令理解误差,但依赖预定义的语义规则库;
- 局限性:需手动设计语义映射规则,无法处理未见过的指令(如未定义 “对角线排列” 的语义,则无法执行该指令);
- 与本论文的差异:本论文无需预定义语义规则,通过 LLM 生成代码直接关联语言与动作,泛化能力更强。
(2)端到端语言 - 动作映射(模仿学习 / 强化学习)
- 核心思路:通过大量机器人演示数据(模仿学习)或奖励信号(强化学习),训练端到端模型直接将语言指令映射到动作(如关节角度、末端速度);
- 代表性工作:
- Lynch et al. [8]、Jang et al. [9]:提出语言条件模仿学习方法,需收集数万次真实机器人 “语言 - 动作” 演示数据,成本极高;
- Mees et al. [15](Calvin 基准):构建长序列语言控制任务数据集,但模型仅在特定场景(如厨房操作)中有效,跨场景泛化差;
- Jiang et al. [43]、Misra et al. [46]:基于强化学习设计语言引导的机器人策略,需大量环境交互采样,训练周期长;
- 局限性:依赖海量真实机器人数据,跨场景泛化能力弱,且模型决策过程黑箱化,难以调试;
- 与本论文的差异:本论文(CaP)无需任何机器人训练数据,仅通过少样本提示生成代码策略,且代码逻辑透明可解释。
(3)低层级语言条件策略(模型 - based / 力控)
- 核心思路:针对特定控制任务(如抓取、轨迹跟踪),设计语言条件的低层级控制器,直接输出控制量(如力矩、速度);
- 代表性工作:
- Sharma et al. [40]:通过自然语言反馈修正机器人轨迹,但需预训练轨迹优化模型;
- Bobu et al. [56]:基于人类查询学习感知概念(如 “红色物体”“圆形区域”),但仅适用于简单拾取任务;
- 局限性:仅针对单一控制任务,无法组合成复杂行为(如 “导航 + 拾取 + 放置” 长序列任务);
- 与本论文的差异:本论文通过代码的逻辑结构(循环、条件、函数调用)组合低层级控制 API(如 PD 控制、拾取放置),可实现复杂长序列任务,且无需预训练控制模型。
2. 领域二:LLM 在机器人中的应用(现有 LLM 相关工作)
近年来 LLM(如 GPT-3、PaLM)在机器人领域的应用逐步兴起,但均局限于 “高层级规划”,无法直接参与感知 - 动作闭环,论文将其分为三类:
(1)LLM 作为任务规划器(技能序列生成)
- 核心思路:利用 LLM 的语言理解与推理能力,将自然语言指令分解为 “预定义技能序列”(如 “pick→move→place”),再调用预训练的技能执行;
- 代表性工作:
- Huang et al. [14](Language Models as Zero-Shot Planners):首次证明 LLM 可零样本生成机器人任务序列,但依赖预定义的技能库(如 “grasp”“stack”);
- Ahn et al. [17](SayCan):结合 LLM 规划与技能可用性(affordance)评估,生成可行的技能序列,但仍需预训练技能模型(如行为克隆、强化学习训练的 “pick” 技能);
- Huang et al. [18](Inner Monologue):通过 “成功检测器” 反馈修正 LLM 规划结果,提升长序列任务鲁棒性,但未改变 “LLM 仅规划、不控制” 的定位;
- 局限性:LLM 不直接调用感知 API 与控制 API,无法参与感知 - 动作反馈循环,导致无法处理动态指令(如 “看到橙子就放下苹果”)、模糊控制描述(如 “更快移动”);
- 与本论文的差异:本论文让 LLM 生成直接调用感知 / 控制 API 的代码,构建 “语言 - 感知 - 动作” 闭环,可处理动态反馈与精确数值控制,无需预定义技能库。
(2)LLM 结合多模态感知(视觉 - 语言融合)
- 核心思路:将 LLM 与视觉语言模型(如 CLIP、VL-BERT)结合,用视觉信息补充 LLM 的物理世界认知,提升规划准确性;
- 代表性工作:
- Zeng et al. [16](Socratic Models):通过视觉语言模型(如 ViLD)获取物体位置信息,代入 LLM 提示生成规划,但 LLM 仅输出技能序列,不直接生成控制逻辑;
- Shah et al. [30](LM-nav):结合 LLM 与视觉导航模型,让机器人根据语言指令生成导航路径,但控制逻辑仍由预定义导航模块实现;
- 局限性:视觉信息仅用于 “修正规划”,未融入控制环节,LLM 仍无法输出精确控制参数(如 “20cm 位移”“0.2m/s 速度”);
- 与本论文的差异:本论文将视觉感知 API(如 MDETR/ViLD 的目标位置输出)直接嵌入 LLM 生成的代码中,实时处理感知数据并调整控制参数,实现感知 - 控制闭环。
3. 领域三:LLM 代码生成与程序合成
LLM 代码生成与程序合成研究为 “代码即策略(CaP)” 提供了技术基础,论文重点分析了两类相关工作:
(1)LLM 代码生成基准与方法
- 核心思路:研究 LLM 在通用代码生成任务(如函数实现、脚本编写)中的能力,建立评估基准(如 HumanEval);
- 代表性工作:
- Chen et al. [1](Evaluating Large Language Models Trained on Code):提出 HumanEval 基准,首次系统验证代码补全 LLM(如 Codex)的函数生成能力,为本论文选择 LLM 模型(Codex davinci-002)提供依据;
- Chowdhery et al. [11](PaLM)、Austin et al. [48]:证明大参数量 LLM(如 PaLM Coder)在代码生成任务中具备零样本泛化能力,但未将其应用于机器人控制;
- 与本论文的差异:本论文将通用 LLM 代码生成能力迁移到机器人领域,提出 “分层代码生成” 方法,不仅提升通用代码生成性能(HumanEval P@1 达 39.8%),还实现了机器人专属代码(如 PD 控制器、空间几何计算)的生成。
(2)程序合成在机器人中的初步应用
- 核心思路:通过程序合成(program synthesis)生成结构化程序(如有限状态机、简单脚本),作为机器人策略;
- 代表性工作:
- Ellis et al. [49](Dreamcoder)、Tian et al. [50]:提出基于贝叶斯程序学习的程序合成方法,可生成简单绘图、2D 任务的控制程序,但需手动设计程序语法模板;
- Trivedi et al. [51]:将程序合成用于 2D 机器人任务(如推块),但程序结构固定,无法处理 3D 真实机器人场景;
- 局限性:依赖预定义程序语法模板,无法生成复杂逻辑(如递归函数、第三方库调用),且不支持自然语言输入;
- 与本论文的差异:本论文无需预定义程序模板,通过自然语言指令直接生成调用第三方库(NumPy/Shapely)、支持递归的 Python 代码,可适配 3D 真实机器人场景。
4. 本论文与相关工作的核心差异总结
| 相关工作类别 | 核心方法 | 数据依赖 | 泛化能力 | 控制深度(感知 - 动作闭环) |
|---|---|---|---|---|
| 传统语义解析 | 预定义语义规则 | 无(人工规则) | 弱(仅支持已知指令) | 无(仅输出任务序列) |
| 端到端语言 - 动作映射 | 模仿学习 / 强化学习 | 海量真实数据 | 弱(仅支持训练场景) | 有(但黑箱化) |
| LLM 作为任务规划器(SayCan 等) | 生成预定义技能序列 | 无(LLM 预训练) | 中(支持未知指令但依赖技能库) | 无(不参与控制) |
| 本论文(CaP) | LLM 生成代码直接作为策略 | 无(少样本提示) | 强(支持未知指令 / 物体) | 有(代码透明,实时反馈) |