【Day 33】Linux-Mysql日志
一、数据库日志的核心作用
故障恢复:当数据库因崩溃(如断电、进程异常)、误操作(如删表)导致数据丢失时,通过日志恢复数据至一致状态。
数据一致性保障:确保事务的 ACID 特性(尤其是原子性、持久性),避免部分操作未提交或重复执行。
审计与追溯:记录用户对数据库的关键操作(如登录、删改数据),用于安全审计或定位 “谁在何时做了什么”。
性能诊断:通过日志分析慢查询、锁等待、资源瓶颈等问题,优化数据库性能。
二、主流数据库日志分类与详解
1. 二进制日志(Binary Log)
- 记录规则:二进制日志仅记录增删改数据(DML)、修改库表结构(DDL)等写操作,不记录 SELECT、SHOW 等纯查询操作;
- 路径建议:需提前规划 binlog 存储路径,推荐单独挂载磁盘存放(远离系统盘和数据盘),避免空间不足或 IO 冲突,同时配置自动清理规则,保障稳定可用。
//建议将二进制日志存放到不同的存储设备上。
(1)格式:二进制格式(非明文),需通过 mysqlbinlog 工具解析查看。
(2)作用:
- 主从复制:主库通过 binlog 将修改同步到从库,保证主从数据一致。
- 时间点恢复(PITR):当数据误删 / 误改时,可通过 binlog 恢复到指定时间点或操作前的状态。
(3)修改日志配置:
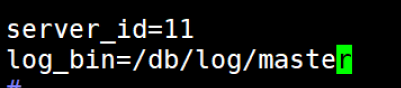
//_id=1...2^32;_bin=文件名 自定
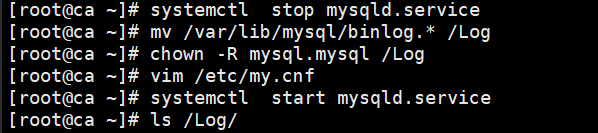
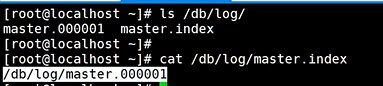
(4)二进制日志的记录格式
MySQL 的binlog_format 配置用于指定二进制日志的记录格式,决定如何记录数据库的修改操作。
格式 | 特点 |
|---|---|
STATEMENT | 直接记录执行的 SQL 语句,不记录数据行的具体变化。 |
ROW | 不记录SQL语句本身,记录数据行的 “修改前后变化” |
MIXED | 自动根据 SQL 语句类型 选择STATEMENT/ROW 简单 SQL 用 STATEMENT,复杂 SQL用 ROW |
# at 1780:当前事件在 binlog 文件中的起始字节位置(1780 字节处开始)。#250825 16:19:01:事件发生的时间戳(2025 年 8 月 25 日 16:19:01)。server id 11:生成该事件的 MySQL 服务器 IDend_log_pos 1841:当前事件在 binlog 中的结束字节位置(到 1841 字节处结束)。CRC32 0x727df518:事件内容的 CRC32 校验值(用于验证日志完整性,防止篡改或损坏)。Table_map:sul123.storemapped to number 97:事件类型为Table_map(表映射),表示后续操作的表是库名sul123.表名store,MySQL 内部为其分配的临时 ID 是 97(复制时从库通过该 ID 匹配本地表)。# has_generated_invisible_primary_key=0:附加属性,说明该表没有生成 “不可见主键”(MySQL 8.0 + 特性,自动为无主键表添加隐藏主键,此处为 0 表示未启用)。SET @@SESSION.GTID_NEXT= 'AUTOMATIC':mysqlbinlog工具自动添加的语句,临时写。# End of log file:标识当前 binlog 文件解析结束。
(5)常用操作:
>SHOW BINARY LOGS; //查看当前 MySQL 服务器上所有二进制日志文件的列表
>SHOW MASTER STATUS; //查看当前主库的二进制日志状态,主要用于主从复制场景
>SHOW BINLOG EVENTS IN '日志文件名' [ FROM 位置] [ LIMIT 行数]; //查看指定二进制日志文件中的具体事件(操作记录)
# mysqlbinlog /Log/master.000002 //直接解析指定的二进制日志文件
# mysqlbinlog --start-datetime="2025-08-25 08:00:00" --stop-datetime="2025-08-25 11:00:00" 二进制日志文件 //按时间范围筛选日志内容,只输出两个时间点之间的事件
# mysqlbinlog --start-position=13 --stop-position=63 二进制日志文件
//按日志位置(偏移量)筛选内容,只输出从
313到463位置之间的事件。# mysqlbinlog binlog 二进制日志 >binlog.txt // 将二进制日志内容解析并保存到文本文件
# mysqlbinlog --start-datetime="2024-05-01 00:00:00" --stop-datetime="2024-05-01 12:00:00" 二进制日志文件 | mysql -uroot -p
2. 错误日志(Error Log)
// 故障排查核心
错误日志记录 MySQL 服务器的启动 / 关闭过程、严重错误(如崩溃、连接失败)、警告信息,是定位数据库无法启动、进程异常等问题的首要依据。
(1)格式:明文文本格式,可直接用 cat/tail 查看。
(2)记录内容:
服务器启动时的配置加载信息(如 “加载 my.cnf 成功”“InnoDB 引擎初始化完成”)。
运行中的错误(如 “内存不足”“磁盘空间满”“主从复制连接失败”)。
服务器关闭时的状态信息。
(3)配置
![]()
# 启用错误日志(指定日志路径)
log_error = /var/lib/mysql/mysql-error.log
# 日志级别(可选:DEBUG/INFO/NOTICE/WARNING/ERROR/CRITICAL/ALERT/EMERGENCY,默认 ERROR)
log_error_verbosity = 3 # 3=记录 ERROR/WARNING/NOTICE,适合日常排查
(4)常用操作
# tail -f /var/lib/mysql/mysql-error.log //实时查看错误日志
# grep "ERROR" /var/lib/mysql/mysql-error.log | tail -10 //查看最近错误
3. 慢查询日志(Slow Query Log)
慢查询日志记录执行时间超过long_query_time变量定义的时长的 SQL 语句,定位 “拖慢数据库的低效查询”。默认不启用。
(1)格式:明文文本格式,记录查询时间、执行时长、SQL 语句等信息。
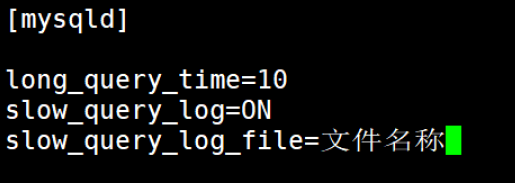
(2)关键配置
>SHOW GLOBAL VARIABLES LIKE '匹配模式'; //查看数据库的配置信息
匹配模式 支持通配符
%(匹配任意字符序列)和_(匹配单个字符)
//如果去掉 GLOBAL,则查询的是当前会话的变量
大量慢查询会直接导致:
数据库卡慢,正常查询也变慢
应用响应延迟,用户操作卡顿
服务器资源(CPU、内存、IO)被占满
严重时可能引发数据库崩溃或连接失败,影响整个系统运行
常用操作:
# cat /var/lib/mysql/mysql-slow.log //查看慢查询日志:
# mysqldumpslow -s t /var/lib/mysql/mysql-slow.log //按执行时间排序,工具分析慢查询
4. 查询日志(General Query Log):全操作记录
5. 中继日志(Relay Log):主从复制专属
(三)通用日志类型:事务日志与归档日志
除了数据库专属日志,以下两类日志是所有 DBMS 的通用概念:
1. 事务日志(Transaction Log)
2. 归档日志(Archive Log)
三、日志管理的关键注意事项
磁盘空间控制:
日志(尤其是 binlog、查询日志)会快速占用磁盘,需配置自动过期。
避免将日志与数据存储在同一磁盘,防止日志占满导致数据库无法写入。
安全性:
日志可能包含敏感数据(如用户密码、业务数据),需限制日志文件权限(如 MySQL 日志设为
600权限,仅 root 可读写)。归档日志建议加密存储(如 AES 加密),防止泄露。
性能平衡:
慢查询日志的阈值需合理设置(如高并发场景设为 500ms,避免记录过多正常查询)。
定期备份与测试:
归档日志需定期备份到异地,避免本地磁盘损坏导致日志丢失。
定期测试 “基于日志的恢复流程”(如 MySQL 用 binlog 恢复、PostgreSQL 用 WAL 恢复),确保日志可用。

二、MySQL 备份与恢复详解
(一)备份基础:核心概念与分类
在选择备份方案前,需先明确备份的核心维度,避免盲目操作。
维度 | 确认项 |
|---|---|
需求明确 | 要保多久数据、故障后能接受丢多少数据(RPO)、多久能恢复业务(RTO)、需要恢复全库还是单表 / 单条数据; |
环境适配 | 数据库是什么引擎、数据量多大、业务忙不忙、服务器空间够不够、有没有从库可用、是否支持增量备份和时间点恢复、备份工具兼容和方案是否适配 |
风险规避 | 备份时数据会不会被修改、备份时会不会影响业务、备份后文件会不会损坏、恢复时能不能用(比如定期测试) |
1. 按备份数据范围分类
备份类型 | 定义 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
全量备份 | 备份整个数据库实例(所有数据库、表、结构 + 数据) | 恢复简单(直接恢复即可) | 备份文件大、耗时久、占用资源多 | 基础备份、小型数据库 |
增量备份 | 仅备份上一次备份(全量 / 增量)后变化的数据 必须按顺序恢复增量备份 | 备份文件小、速度快、资源占用低 | 恢复复杂(需先恢复全量 + 按顺序恢复增量) | 大型数据库 |
差异备份 | 仅备份上一次全量备份后变化的数据 | 恢复较增量简单(全量 + 最新差异)、文件比增量大但比全量小 | 备份文件随时间增大(直到下一次全量) | 中型数据库 |
2. 按备份时数据库状态分类
冷备份(离线备份):备份前需停止 MySQL 服务,确保数据无写入。
优点:备份文件一致性极高;缺点:业务中断,适用于非核心低峰期或测试环境。热备份(在线备份):备份时数据库可正常读写,无感知。
优点:零业务中断;缺点:需特定工具(如mysqldump --single-transaction、Percona XtraBackup),仅支持 InnoDB 引擎(MyISAM 不支持事务,无法热备份)。温备份(半在线备份):备份时数据库可读取,但禁止写入。
优点:业务只读不中断;缺点:影响写操作,适用于读多写少场景。
3. 按备份文件格式分类
逻辑备份:将操作备份为 SQL 语句文件,可跨版本、跨平台恢复。mysqldump
物理备份:直接拷贝数据文件。直接拷贝 MySQL 存储引擎的物理文件(如 .ibd .frm 文件),恢复速度快,但仅支持相同版本、相同架构的 MySQL。Percona XtraBackup
(二)核心备份工具与方法
MySQL 官方及第三方提供了多种备份工具,不同工具适配不同场景,以下是最常用的 3 类工具。
1. mysqldump
// MySQL 自带的逻辑备份工具,通过导出 SQL 语句实现备份,支持全量、单库、单表备份,适用于中小型数据库(数据量 < 10GB)。
1.1 基础语法
- mysqldump 选项 数据库名 表名 > 备份文件.sql
需求 | 命令 | 说明 |
|---|---|---|
全量备份(所有库) | mysqldump -uroot -p --all-databases > | 备份所有数据库(含系统库 mysql),需输入密码 |
单库备份 | mysqldump -uroot -p 库名 > | 仅备份此数据库 |
多库备份 | mysqldump -uroot -p --databases 库名1 库名2 > | 仅备份此数据库 |
单表备份 | mysqldump -uroot -p 库名 表名 > | 仅备份此库中的此表 |
热备份(InnoDB 引擎) | mysqldump -uroot -p --single-transaction 库名 | 通过事务快照实现热备份,不锁表(仅 InnoDB 生效) |
温备份(锁表) | mysqldump -uroot -p --lock-all-tables 库名 > | 加全局读锁,禁止写入,确保数据一致性,直到备份结束 |
备份时包含存储过程 / 函数 | mysqldump -uroot -p --routines 库名 > | 默认不备份存储过程,需加 --routines |
在备份文件中记录备份时 MySQL 二进制日志(binlog)的文件名和位置 | mysqldump -uroot -p --master-date=1 > |
|
1.2 案例显示
(0) 准备存放备份数据的目录
![]()
(1)周一全量备份
- # mysqldump -uroot -p --lock-all-tables --master-data=2 --all-databases > /db/bak/data_$(date +%F_%T).sql

(2)模拟数据库变化,登录 MySQL,手动插入测试数据(生成 binlog 事件)
(3)周二增量备份
①方法1:指定起始位置备份(精准)
- # mysqlbinlog --start-position=157 /db/log/binlog.000021 > /db/bak/data_$(date +%F_%T).sql //导出binlog.000021中从1325位置到当前的所有事件(即周二新增的数据)
![]()
![]()

②方法2:按 binlog 文件备份(适用于多文件场景)
若全量备份后生成了多个 binlog 文件,可直接备份新增的文件:
- # cp /db/log/binlog.000021 /backup/ // 直接复制文件(后续恢复时用mysqlbinlog解析)
查看所有 binlog 文件,结合文件名的生成顺序,大致判断哪些文件包含需要的日志
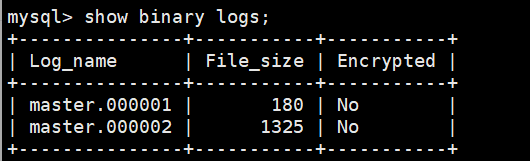
- 假设全量备份在
20:05:30结束,增量的起始位置就是 备份结束后第一个事件的起点。
![]()
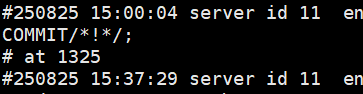
// 这里可知是1325

(4)模拟数据变化
(5)周三增量备份
- # grep "end_log_pos" /db/bak/increment_tue_*.sql | tail -1
- //查看周二增量备份的最后位置(假设周二增量结束位置是2500)
- # mysqlbinlog --start-position=2500 /db/log/binlog.000021 > /db/bak/increment_wed_2025-08-27_10:00:00.sql
- //从2500位置开始备份周三的新增数据(假设binlog仍为000021)
(6)模拟报错
- >DROP TABLE sul123.store; // 模拟故障:误删除store表

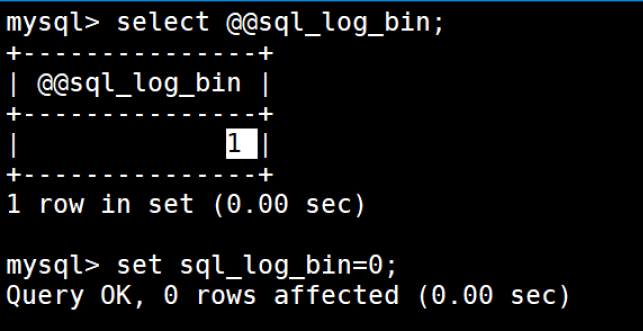
(7)临时关闭二进制功能(防止恢复过程生成新日志干扰)
(8)恢复周一的全局

(9)依次恢复增量


(10)根据二进制日志恢复未备份的数据
假设故障发生在周三增量备份后,需提取 “周三增量结束位置” 到 “故障发生前” 的 binlog 事件:


意思是备份到了8582

- SET sql_log_bin = 1; // 恢复binlog记录(可选,根据业务需求)
恢复后若用户无法使用,执行FLUSH PRIVILEGES;或重新授权。
跨版本恢复时避免直接恢复 mysql 库:若从 5.7 恢复到 8.0,建议:
- 仅恢复业务库(排除
mysql库); - 手动在新库中重新创建用户并授权(避免版本兼容问题)。
2. Percona XtraBackup(第三方物理热备份工具)
Percona XtraBackup(简称 PXB)是 Percona 推出的免费物理备份工具,支持 InnoDB 引擎的热备份,备份 / 恢复速度远快于 mysqldump,适用于大型数据库(数据量 > 10GB)。
(1)下载

![]()

(2)自动拷贝(会自动锁表)

(3)完全备份

(4)增量备份




(5)模拟损坏
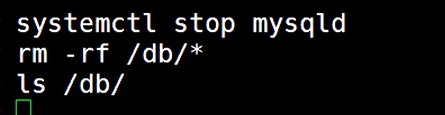
(6)恢复备份数据
- # xtrabackup --prepare --apply-log-only --target-dir=/db/bak/data_2024-11-05_full/
- # xtrabackup --prepare --apply-log-only --target-dir=/db/bak/data_2024-11-05_full/ --incremental-dir=<第一次增量目录>
- # xtrabackup --prepare --target-dir=/db/bak/data_2024-11-05_full/ --incremental-dir=<最后一次增量目录> //准备最后一次增量备份时,不需要加--apply-log-only参数
- # xtrabackup --no-defaults --copy-back --target-dir=/db/bak/data_2024-11-05_full/ --datadir=原始数据目录 //恢复数据
- # chown -R mysql.mysql /db/data/ //修改权限并重启






(7)将未备份的数据恢复
