面向机器人推动与抓取任务自适应算法研究
本文提出的方法是基于深度强化学习(DRL)的物体推动方法,核心就是在“奖励函数”里加入“接触力信息”,让机器人高效把东西从初始位置推动到目标位置
接触力信息作用:它能反应机器人和物体之间是怎么交互的,能判断推动动作好不好,利用它设计奖励函数,就能引导机器人学咋推动,比如奖励函数鼓励机器人产生朝着目标方向的接触力(还得控制着物体别乱转,走直线等)
用深度神经网络训练机器人推动策略,结合SAC算法(Soft-Actor-Critic,软演员,评论家算法),SAC算法与传统的强化学习算法区别在于,Soft意思是别光盯着“当前最优”,也给探索留点空间,它引入了“熵”的概念(“不确定性、探索欲”)鼓励策略网络多试试新动作,别总走老路,而传统的有点就是“死磕最优”
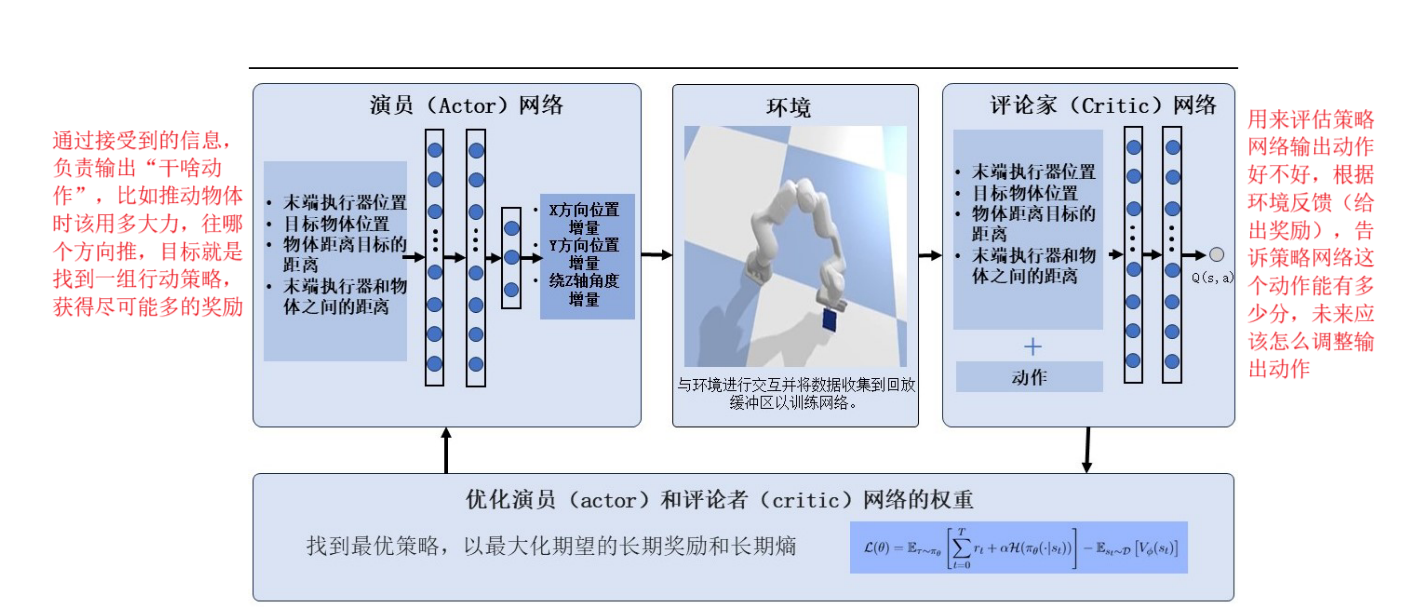
整体的运行:
互动收集数据:机器人用当前策略和环境互动,做动作拿奖励,记录状态变化
评论家评估:根据收集的数据,评估每一个状态-动作组合的价值,给演员反馈
演员调整策略:结合评论家的反馈,还有熵带来的探索需求,调整好自己的动作策略,争取下次做的更好,同时保存一定的探索性
循环优化:不断重复以上步骤,慢慢的让演员的策略越来越厉害
通过一个接触模型(看物体质心、接触力方向啥的)获得接触信息,设计奖励函数

碰到物体时:奖励和“接触力方向与物体质心到目标点连线的角度”、“物体质心到接触力方向的距离”有关,角度越小,距离越短,奖励函数设计上就越鼓励,这样能够让推力尽量通过质心,别打转
没碰到物体时:奖励设计鼓励机器人赶紧碰到物体,别瞎转悠