PDF处理控件Spire.PDF系列教程:在 C# 中实现 PDF 与字节数组的互转

在 C# 开发中,处理 PDF 的字节数组是一种常见需求。开发者常常需要将 PDF 文档存储到数据库、通过 API 传输,或者完全在内存中进行处理而不依赖文件系统。在这些场景下,在 C# 中实现 PDF 与字节数组的互转 就显得尤为重要。
E-iceblue旗下Spire系列产品,是文档开发组件领域的佼佼者,支持国产化信创。本文将通过 Spire.PDF for .NET 演示具体实现步骤。你将学习如何将字节数组转换为 PDF,如何将 PDF 转换为字节数组,以及如何直接在内存中使用 C# 代码编辑 PDF。
Spire.PDF for .NET
为什么在 C# 中要处理 PDF 与字节数组?
使用 byte[] 作为传输格式,可以避免生成临时文件,使代码更适配云环境和容器环境。
- 数据库存储 (BLOB): 将 PDF 以原始字节形式存储,仅在需要时加载。
- Web API: 通过 HTTP 发送或接收 PDF,无需磁盘读写。
- 内存处理: 在流中完成 PDF 的转换或加水印操作。
- 安全与隔离: 减少文件 I/O,降低临时文件风险。
准备工作: 在运行示例前,请先在项目中安装 Spire.PDF for .NET 的 NuGet 包。
Install-Package Spire.PDF
安装完成后,即可通过 byte[] 或 Stream 加载 PDF,编辑页面,并将结果写回内存或磁盘,无需额外转换器。
在 C# 中将字节数组转换为 PDF
当上游服务(如 API 或消息队列)传递一个代表 PDF 的 byte[] 时,通常需要将其还原为文档,便于进一步处理或保存到磁盘。使用 Spire.PDF for .NET,这个过程可以直接在内存中完成,无需中间临时文件。
应用场景与方法: 从数据库或 API 获取一个 byte[],在内存中构建 PdfDocument,可选地验证一些基础信息,然后保存为 PDF。
using Spire.Pdf;
using System.IO;class Program
{static void Main(){// 示例来源:从数据库或 API 获取的字节数组byte[] pdfBytes = File.ReadAllBytes("Sample.pdf"); // 请替换为实际数据来源// 1) 从字节数组加载 PDF(内存中完成)PdfDocument doc = new PdfDocument();doc.LoadFromBytes(pdfBytes);// 2) (可选)在保存或处理前查看文档信息// int pageCount = doc.Pages.Count;// 3) 保存为文件doc.SaveToFile("Output.pdf");doc.Close();}
}
下图展示了字节数组到 PDF 的转换流程:
代码解析:
- LoadFromBytes(byte[]) 可直接在内存中初始化 PDF,适合无写入权限的服务环境。
- 加载完成后可以进行多种操作:验证页面、打码、加盖印章或路由到其他流程。
- SaveToFile(string) 将文档保存到磁盘,便于后续处理或存储。
在 C# 中将 PDF 转换为字节数组
反向转换时,将 PDF 转换为 byte[] 便于写入数据库、缓存,或通过 HTTP 响应返回文件。Spire.PDF for .NET 支持将 PDF 保存到 MemoryStream,再通过 ToArray() 转换为字节数组。
应用场景与方法: 加载现有 PDF,将其保存到 MemoryStream,再提取 byte[]。这种方式特别适用于 API 返回 PDF 或持久化存储。
using Spire.Pdf;
using System.IO;class Program
{static void Main(){// 1) 从磁盘、网络或资源文件加载 PDFPdfDocument doc = new PdfDocument();doc.LoadFromFile("Input.pdf");// 2) 保存到内存流,避免生成临时文件byte[] pdfBytes;using (var ms = new MemoryStream()){doc.SaveToStream(ms);pdfBytes = ms.ToArray();}doc.Close();// pdfBytes 现在包含完整文档(可直接写入数据库或 API 返回)// 示例:return File(pdfBytes, "application/pdf");}
}
下图展示了 PDF 转换为字节数组的流程:
关键点总结:
- SaveToStream → ToArray 是在 C# 中获取 PDF 字节的标准方式,无需生成临时文件。
- 这种方法适合大文件处理,内存使用量仅受限于系统资源。
- 在 ASP.NET 中尤其实用,可直接返回字节数组给前端或 API 调用方。
直接从字节数组创建和编辑 PDF
更强大的场景是直接在内存中编辑 PDF。你可以从 byte[] 加载 PDF,添加文字或图片、加水印、填写表单,再将结果保存为新的 byte[]。这种无文件管道非常适合微服务。
应用场景与方法: 从字节数组加载 PDF,在第一页添加文字标记,最后输出新的字节数组。
using Spire.Pdf;
using Spire.Pdf.Graphics;
using System.Drawing;
using System.IO;class Program
{static void Main(){// 来源可以是数据库、API 或文件,这里用 byte[] 表示byte[] inputBytes = File.ReadAllBytes("Input.pdf");// 1) 内存加载 PDFvar doc = new PdfDocument();doc.LoadFromBytes(inputBytes);// 2) 编辑:在第一页写入一个小标记PdfPageBase page = doc.Pages[0];page.Canvas.DrawString("编辑后的PDF文档",new PdfTrueTypeFont(new Font("HarmonyOS Sans SC", 26f), true),PdfBrushes.DarkBlue,new PointF(100, page.Size.Height - 100));// 3) 保存为新的字节数组byte[] editedBytes;using (var ms = new MemoryStream()){doc.SaveToStream(ms);editedBytes = ms.ToArray();}doc.Close();// editedBytes 可持久化存储或由 API 返回}
}
下图展示了编辑后的 PDF 页面:
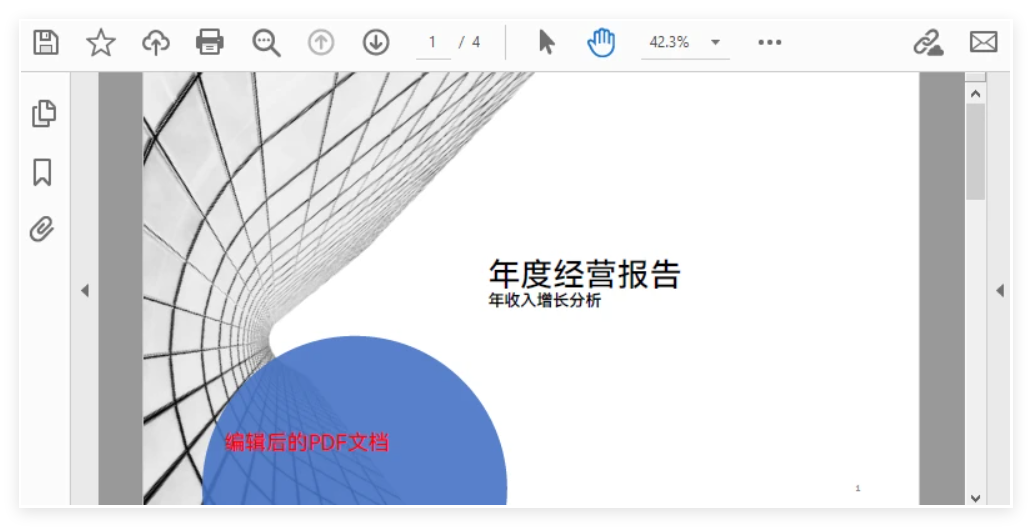
要点说明:
- 同样的方式可应用于 文本、图片、水印、批注、表单字段 等编辑操作。
- 建议保持操作幂等(如检查是否已加盖印章),避免重复处理。
- 在 ASP.NET 中非常适合 即时加印 或 条件脱敏,再返回给调用方。
使用 Spire.PDF for .NET 的优势
下表总结了该 API 在字节数组处理中的优势:
| 需求点 | Spire.PDF for .NET 的优势 |
|---|---|
| I/O 灵活性 | 同一个 PdfDocument API 支持从文件路径、Stream 或 byte[] 加载与保存 |
| 内存编辑 | 可绘制文本/图片、管理批注/表单、添加水印等,无需临时文件 |
| 服务友好 | 轻松集成到 ASP.NET 接口和后台任务 |
| 处理真实文档 | 支持多页 PDF,可通过流控制内存消耗 |
| 代码简洁 | 避免手动字节操作和复杂互操作,简化实现 |
总结
本文演示了如何在 C# 中 将字节数组转换为 PDF、如何 将 PDF 转换为字节数组,以及如何 直接在内存中编辑 PDF。通过流和字节数组操作,可以让 API 设计更简洁、响应更高效,同时兼顾数据库和云环境的适配性。Spire.PDF for .NET 提供了一套一致的无文件化工作流,既适合快速转换,也能扩展为完整的内存文档处理。
常见问题
可以在不保存到磁盘的情况下,通过字节数组创建 PDF 吗?
可以。使用 LoadFromBytes 从 byte[] 加载 PDF,然后保存到 MemoryStream 或直接在 API 中返回,无需落盘。
如何在 C# 中将 PDF 转换为字节数组以便存入数据库?
使用 PdfDocument.SaveToStream 方法,并调用 MemoryStream.ToArray() 获取字节数组,再存储为 BLOB 或传递给其他服务。
能否编辑仅存在于字节数组中的 PDF?
完全可以。先通过字节数组加载 PDF,再进行文字、图片、水印、批注或表单填写等编辑,最后保存为新的 byte[]。
有哪些性能与可靠性建议?
及时释放流、在合适的场景重用缓冲区、每个操作/线程单独创建 PdfDocument。对于大文件,建议使用流式 I/O 控制内存使用,保证可预测性。