kubectl 客户端访问 Kubernetes API Server 不通的原因排查与解决办法
文章目录
- 一、问题描述
- 二、原因分析
- 2.1、API Server 没有运行
- 2.2、kubelet 没有把 Pod 拉起来
- 2.3、端口/防火墙问题
- 2.4、证书或 kubeconfig 错误
- 2.5、Master 节点 IP 配置不对
- 三、快速修复
- 3.1、重置 master
- 3.2、work node 初始化
- 3.3、测试
一、问题描述
虚拟机搭建的K8S一主两从集群,由于主机突然蓝屏导致机子重启后,访问kubectl 客户端访问 192.168.31.101:6443 的 Kubernetes API Server 不通:报错信息如下:
92.168.31.101:6443: connect: connection refused" E0825 11:19:17.068068 7734 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: Get \"https://192.168.31.101:6443/api?timeout=32s\": dial tcp 192.168.31.101:6443: connect: connection refused" The connection to the server 192.168.31.101:6443 was refused - did you specify the right host or port?
从报错信息来看,kubectl 客户端访问 192.168.31.101:6443 的 Kubernetes API Server 不通,常见原因如下:
二、原因分析
2.1、API Server 没有运行
登录到 master 节点:
docker ps | grep kube-apiserver
# 或
crictl ps | grep kube-apiserver
如果没有进程,说明 kube-apiserver 挂了,需要检查 kubeadm/kubelet 的日志:
journalctl -u kubelet -f
此问题原因排除!!
2.2、kubelet 没有把 Pod 拉起来
查看 kubelet 状态:
systemctl status kubelet -l
重点看是不是因为证书过期、配置文件错了,导致 apiserver 起不来。
此问题原因排除!!
2.3、端口/防火墙问题
API Server 默认监听 6443,确认端口是否在监听:
netstat -ntlp | grep 6443
ss -lntp | grep 6443
如果监听了但外部不通,检查防火墙:
iptables -L -n | grep 6443
firewall-cmd --list-ports
此问题原因排除!!
2.4、证书或 kubeconfig 错误
检查 ~/.kube/config 中的 server: https://192.168.31.101:6443
如果是 Rancher 导入的集群,有可能 kubeconfig 已失效,需重新下载。
此问题原因排除!!
2.5、Master 节点 IP 配置不对
如果 master 实际 IP 不是 192.168.31.101,可能是 kubeadm init 时 --apiserver-advertise-address 参数没设置正确。
检查 kube-apiserver 的启动参数:
ps -ef | grep kube-apiserver
看监听地址是否是 0.0.0.0 或者正确的内网 IP。
此问题原因排除!!
以上问题都排除,只能重置k8s集群
三、快速修复
3.1、重置 master
在master 节点主机运行重置命令:
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock
清理以前安装的数据:
cd ~ 进入根目录ll -a 查看是否存在.kube文件
rm -rf /root/.kube
重启docker和kubelet服务
systemctl restart docker ## 重启docker
systemctl restart kubelet ## 重启kubelet
删除以前安装的网络插件数据目录
rm -rf /etc/cni/net.d
运行以下k8s master节点初始化命令:
kubeadm init --kubernetes-version=v1.33.3 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --apiserver-advertise-address=192.168.31.101 --image-repository registry.aliyuncs.com/google_containers --cri-socket=unix:///var/run/cri-dockerd.sock遇到如下问题:
[root@k8s-master01-101 ~]# kubeadm reset found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the 'criSocket' field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock To see the stack trace of this error execute with --v=5 or higher
遇到的这个报错是 kubeadm reset/init 的常见问题:
它发现了两个 CRI(容器运行时接口):
unix:///var/run/containerd/containerd.sockunix:///var/run/cri-dockerd.sock
kubeadm 不知道该用哪个,所以报错。
解决方法:临时在命令行里指定 CRI
# 如果你集群实际用的是 containerd
kubeadm reset --cri-socket=unix:///var/run/containerd/containerd.sock -f# 如果你用的是 docker + cri-dockerd
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock -f
初始化成功后,拷贝重要信息:
Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user:mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/configAlternatively, if you are the root user, you can run:export KUBECONFIG=/etc/kubernetes/admin.confYou should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:https://kubernetes.io/docs/concepts/cluster-administration/addons/Then you can join any number of worker nodes by running the following on each as root:kubeadm join 192.168.31.101:6443 --token hgmadd.4c33bzmievu7xdtr \--discovery-token-ca-cert-hash sha256:d16149d494cc8cfcca8e43d727991261c72499ccaec04f30c97a109003f61b82
master节点主机继续运行以下命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看节点信息:
kubectl get node
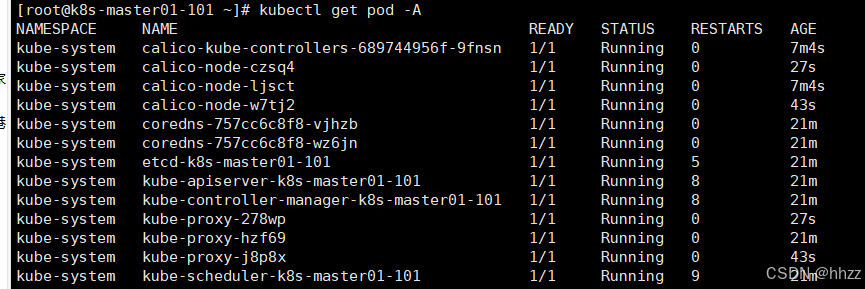
kubectl get pod -A

##安装网络插件calico.yaml
calico.yaml文件太大,需要的可以私聊我获取
kubectl apply -f calico.yaml
3.2、work node 初始化
(两个工作节点主机都运行)
#初始化命令
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock#删除以前的信息
rm -rf /root/.kube
rm -rf /etc/cni/net.d
rm -rf /etc/kubernetes/*
#加入k8s集群命令(两个工作节点主机都运行)
kubeadm join 192.168.31.101:6443 --token hgmadd.4c33bzmievu7xdtr \--discovery-token-ca-cert-hash sha256:d16149d494cc8cfcca8e43d727991261c72499ccaec04f30c97a109003f61b82 --cri-socket=unix:///var/run/cri-dockerd.sock
3.3、测试
[root@k8s-master01-101 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01-101 Ready control-plane 21m v1.33.3
k8s-node01-201 Ready <none> 26s v1.33.3
k8s-node02-202 Ready <none> 10s v1.33.3

“人的一生会经历很多痛苦,但回头想想,都是传奇”。