HiRAG:用分层知识图解决复杂推理问题
分层检索增强生成系统(Hierarchical Retrieval-Augmented Generation, HiRAG)是一种先进的知识推理框架,专门用于处理复杂知识图中的多层次推理问题。在处理大规模科学文献(如天体物理学或广义相对论相关论文)时,传统的平面知识图往往难以建立远距离概念间的有效连接,例如将星系形成理论与大爆炸膨胀期的基本粒子物理学关联起来。HiRAG通过构建分层结构有效解决了这一难题,实现了更深入、更连贯的知识推理。

该系统基于图检索增强生成(GraphRAG)的核心思想,通过引入层次化架构来处理不同抽象层次的知识复杂度。HiRAG由香港中文大学计算机科学与工程系的研究团队开发,特别适用于理论物理学等需要多层次分析的专业领域。
从技术实现角度看,HiRAG采用两阶段工作模式:首先从原始文档构建分层索引结构,然后通过结构化方式执行信息检索。这种设计确保了答案的事实依据性,通过依赖数据本身的预定义推理路径来有效减少大型语言模型的幻觉现象。
核心概念与技术基础
HiRAG的实现基于几个关键的技术概念。知识图是由实体网络构成的结构化表示,其中实体(如"黑洞"或"引力波")通过特定关系(如"产生")相互连接。实体提取过程从文本中识别出独特的概念项,特别是科学论文中的专业术语。聚类技术采用高斯混合模型等算法将语义相似的实体分组,形成主题化的概念集合。
摘要生成环节利用强大的语言模型为实体聚类创建更高层次的抽象表示。社区检测算法(如Louvain方法)用于识别跨层的相关实体组合。嵌入技术通过Sentence-BERT等模型将文本转换为数值向量,支持高效的相似度计算。
基于这些技术组件,HiRAG构建了多层次的知识图谱结构,其中底层包含详细的具体实体,而高层则包含抽象的概念摘要,形成了从具体到抽象的知识层次体系。
系统架构设计
HiRAG系统由两个核心模块组成:分层索引构建模块和分层检索模块。这种模块化设计确保了系统的可扩展性和维护性。
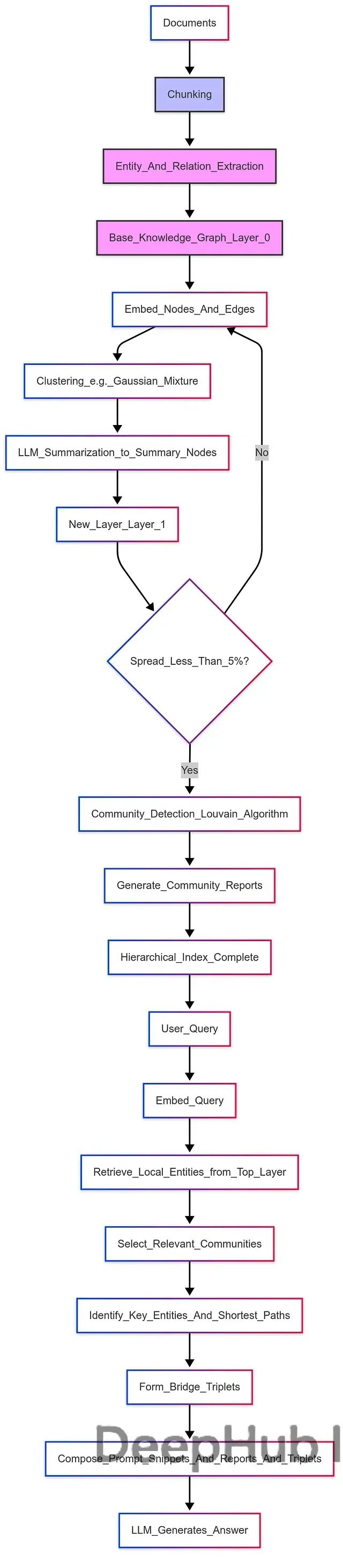
1、分层索引构建流程
分层索引构建是将原始文档转换为结构化分层知识图的关键过程。该流程首先对输入文档进行预处理,将大型文档(如广义相对论相关的PDF文件)分割为适当大小的文本片段。以10篇论文为例,系统可以生成约300个文本块。
实体和关系提取阶段使用大型语言模型识别文档中的关键实体和它们之间的语义关系。例如系统可以从文档中提取出520个独特实体,如"史瓦西度量"或"爱因斯坦场方程",这些实体及其关系构成了基础层(Layer 0)的知识图G0。
嵌入计算过程使用Sentence-BERT等预训练模型为所有节点和边生成高维向量表示,为后续的相似度计算和聚类分析提供数学基础。
聚类和摘要循环是该系统的核心创新。系统首先使用高斯混合模型等聚类算法将Layer 0中的实体分组为主题相关的集合,例如将520个实体分为40个聚类。然后大型语言模型为每个聚类生成摘要,形成Layer 1的新摘要节点。系统对这些新节点进行嵌入计算,然后重复聚类过程,将Layer 1的摘要进一步聚类(例如形成6个聚类)并生成Layer 2的元摘要节点。当聚类分布的变化小于预设阈值(通常为5%)时,迭代过程结束。
社区检测阶段在所有层次上运行Louvain算法,识别出跨层的实体社区结构。假设系统可能识别出8个社区,如"紧凑恒星对象和引力波特征"等。系统随后使用大型语言模型为每个社区生成详细的描述报告。
这个过程最终创建了一个多层次的知识图谱,其中不同层次代表不同的抽象程度:Layer 0包含详细的具体实体,Layer 1包含主题摘要,Layer 2包含更高层次的元摘要。
2、分层检索机制
当分层索引构建完成后,系统通过多层视图处理用户查询。查询嵌入过程首先将用户查询转换为向量表示,以支持与知识图中节点的相似度匹配。
本地实体检索从顶层开始检索与查询最相似的节点,这些节点包含了来自下层的聚合知识。这种设计有效结合了细粒度的具体信息和高层次的抽象信息。
社区选择机制基于查询相似度选择相关的实体社区,每个社区都提供全局上下文报告,为答案生成提供宏观背景。
全局桥接三元组生成是HiRAG的另一个重要创新。系统首先识别每个相关社区中的关键实体,然后计算它们之间的最短路径,形成"桥接三元组"(主语-关系-宾语结构,如"Kerr度量确定准正常模式")。这些三元组构建了基于事实的推理路径,确保答案的逻辑连贯性。
最终的答案生成阶段将本地片段、社区报告和桥接三元组整合为结构化的提示,输入给大型语言模型生成最终答案。这种设计确保推理轨迹来源于知识图结构,而不仅仅依赖于语言模型的内部参数知识。
实际应用案例:天体物理学查询处理
以下通过一个具体的天体物理学查询案例展示HiRAG系统的工作流程。假设输入数据为10篇广义相对论相关论文,经过文档分块处理后产生300个文本片段,从中提取出520个实体。
在分层索引构建阶段,Layer 0包含520个具体实体,如"Kerr度量"和"准正常模式"。聚类过程形成40个主题聚类,其中一个可能专注于黑洞自旋相关的概念。Layer 1阶段,大型语言模型将这些聚类摘要为40个节点,例如"爱因斯坦方程的精确解"。进一步聚类形成6个更高层次的集合,生成Layer 2的6个元节点,如"宇宙学解"。当聚类分布变化小于5%时,系统停止迭代。社区检测算法识别出8个跨层社区,如"紧凑对象和引力波"。
对于查询"黑洞如何产生引力波?“,系统的分层检索过程如下:首先将查询转换为嵌入向量;然后检索相关的本地实体,包括"Kerr度量”(Layer 0)、“精确解”(Layer 1)和"紧凑对象"(Layer 2)等节点;接着选择2个最相关的社区(如引力动力学相关社区);生成桥接三元组,如"黑洞合并 → 产生 → 引力波"等推理路径;最后整合片段、报告和路径信息生成最终提示,输出关于黑洞合并和引力波环状特征的事实性答案,有效避免了幻觉问题。
HiRAG工作流程
以下代码展示了实体聚类和摘要的基本实现方法,使用scikit-learn进行聚类分析,并包含大型语言模型的调用接口。需要注意的是,这是一个简化的演示版本;在实际的HiRAG实现中,需要使用完整的嵌入模型和GPT-4等强大的语言模型。
import numpy as np
from sklearn.mixture import GaussianMixture
from sklearn.metrics.pairwise import cosine_similarity # Sample entities and embeddings (in real case, use Sentence-BERT)
entities = ["Kerr metric", "Quasi-normal modes", "Black hole spin", "Einstein field equations", "Gravitational waves"]
embeddings = np.random.rand(5, 10) # Fake 10-dim embeddings # Clustering with Gaussian Mixture
gm = GaussianMixture(n_components=2, random_state=0)
gm.fit(embeddings)
clusters = gm.predict(embeddings) # Group entities by cluster
cluster_groups = {}
for i, cluster in enumerate(clusters): if cluster not in cluster_groups: cluster_groups[cluster] = [] cluster_groups[cluster].append(entities[i]) # Placeholder LLM summarization
def llm_summarize(group): return f"Summary of {', '.join(group)}: Exact solutions in general relativity." # Create summary nodes for next layer
summary_nodes = []
for cluster, group in cluster_groups.items(): summary = llm_summarize(group) summary_nodes.append(summary) print("Clusters:", cluster_groups) print("Summary Nodes:", summary_nodes)
输出结果:
Clusters: {0: ['Kerr metric', 'Black hole spin', 'Einstein field equations'], 1: ['Quasi-normal modes', 'Gravitational waves']} Summary Nodes: ['Summary of Kerr metric, Black hole spin, Einstein field equations: Exact solutions in general relativity.', 'Summary of Quasi-normal modes, Gravitational waves: Exact solutions in general relativity.']
该代码示例清晰展示了实体如何通过聚类算法分组,然后通过语言模型生成摘要的完整流程。
性能评估与基准测试
HiRAG在多个基准测试中表现优异,显著超越了基础的RAG等传统方法。根据系统评估结果,HiRAG在各种测试场景中都展现出卓越的性能表现:
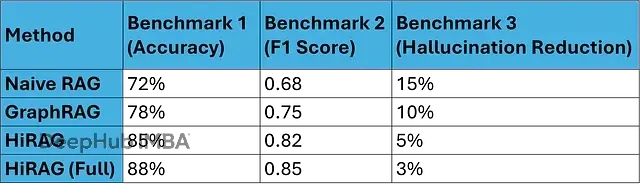
实验结果表明,HiRAG通过桥接机制实现的多尺度推理在减少答案矛盾方面表现突出,这主要归功于其基于结构化知识图的事实验证机制。
系统间对比分析
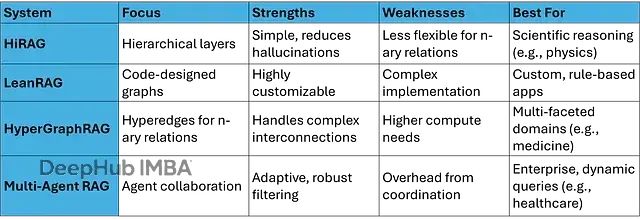
检索增强生成系统正在快速发展,不同的技术变体针对特定挑战提供解决方案,包括复杂关系处理、幻觉减少和大规模数据扩展等。HiRAG凭借其在知识图分层结构方面的专业化设计而独树一帜。通过与LeanRAG、HyperGraphRAG和多智能体RAG系统的对比分析,可以更好地理解HiRAG在简单性、深度和性能方面的平衡策略。
HiRAG与LeanRAG的技术对比:设计复杂度与分层简化
LeanRAG作为一个更加复杂的系统架构,强调基于代码设计的知识图构建方法。该系统通常采用程序化图构造策略,其中代码脚本或算法根据数据中的规则或模式动态构建和优化图结构。LeanRAG可能使用自定义代码来实现实体提取、关系定义和任务特定的图优化,这使得系统具有高度的可定制性,但同时也增加了实现的复杂度和开发成本。
相比之下,HiRAG采用了更加简化但技术上相关的设计方案。该系统优先考虑分层架构而非平面或代码密集型设计,利用强大的大型语言模型(如GPT-4)进行迭代摘要构建,减少了对大量编程工作的依赖。HiRAG的实现流程相对直观:文档分块、实体提取、聚类分析(使用高斯混合模型等),并利用语言模型为更高层次创建摘要节点,直到达到收敛条件(如聚类分布变化小于5%)。
在复杂性管理方面,LeanRAG的代码中心方法允许精细的控制调节,例如在代码中集成特定领域的专业规则,但这可能导致更长的开发周期和潜在的系统错误。HiRAG的语言模型驱动摘要方法减少了这种开销,依赖模型的推理能力进行知识抽象。在性能表现上,HiRAG在需要多层次推理的科学领域表现优异,能够在天体物理学等领域中有效连接基本粒子理论与宇宙膨胀现象,而无需LeanRAG的过度工程化设计。HiRAG的主要优势包括更简单的部署流程,以及通过从分层结构派生的基于事实的推理路径更有效地减少幻觉现象。
以量子物理学如何影响星系形成的查询为例,LeanRAG可能需要编写自定义提取器来处理量子实体并手动建立链接关系。而HiRAG会自动将低级实体(如"夸克")聚类为中级摘要(如"基本粒子")和高级摘要(如"大爆炸膨胀"),通过检索桥接路径来生成连贯的答案。两个系统的工作流程差异明显:LeanRAG采用代码实体提取、程序化图构建和查询检索的流程;而HiRAG采用语言模型实体提取、分层聚类摘要和多层检索的流程。
HiRAG与HyperGraphRAG的架构对比:多实体关系处理与分层深度
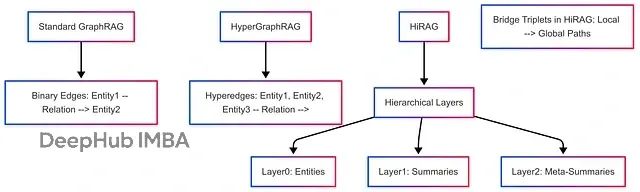
HyperGraphRAG在2025年发表的arXiv论文(2503.21322)中被首次介绍,该系统采用超图结构替代传统的标准图。在超图架构中,超边可以同时连接两个以上的实体,能够捕获n元关系(即涉及三个或更多实体的复杂关系,如"黑洞合并产生LIGO检测到的引力波")。这种设计对于处理复杂的多维知识特别有效,能够克服传统二元关系(标准图边)的局限性。
HiRAG坚持使用传统图结构,但通过添加分层架构来实现知识抽象。系统从基础实体构建多层次结构直至元摘要级别,并使用跨层社区检测算法(如Louvain算法)形成知识的横向切片。HyperGraphRAG专注于在相对平坦的结构中实现更丰富的关系表示,而HiRAG则强调垂直深度的知识层次。
在关系处理能力方面,HyperGraphRAG的超边能够建模复杂的多实体连接,例如医学领域的n元事实:“药物A与蛋白质B和基因C相互作用”。HiRAG使用标准的三元组结构(主语-关系-宾语),但通过分层桥接来建立推理路径。在效率表现上,HyperGraphRAG在具有复杂交织数据的领域表现出色,如农业领域中"作物产量取决于土壤、天气和害虫"等多因素关系,在准确性和检索速度方面优于传统GraphRAG。HiRAG更适合抽象推理任务,通过多尺度视图减少大规模查询中的噪声干扰。HiRAG的优势包括与现有图工具的更好集成性,以及通过分层结构减少大规模查询中的信息噪声。HyperGraphRAG可能需要更多的计算资源来构建和维护超边结构。
以"引力透镜对恒星观测的影响"查询为例,HyperGraphRAG可能使用单个超边同时链接"时空曲率"、"光路径"和"观察者位置"等多个概念。HiRAG则会采用分层处理:基础层(曲率实体)、中间层(爱因斯坦方程摘要)、高层(宇宙学解),然后通过桥接这些层次来生成答案。根据HyperGraphRAG论文的测试结果,该系统在法律领域查询中达到了更高的准确率(85% vs. GraphRAG的78%),而HiRAG在多跳问答基准测试中显示出88%的准确率。
HiRAG与多智能体RAG系统的对比:协作机制与单流设计
多智能体RAG系统,如MAIN-RAG(基于arXiv 2501.00332),采用多个大型语言模型智能体协作的方式来完成检索、过滤和生成等复杂任务。在MAIN-RAG架构中,不同智能体独立对文档进行评分,使用自适应阈值过滤噪声信息,并通过共识机制实现稳健的文档选择。其他变体,如Anthropic的多智能体研究成果或LlamaIndex的实现方案,采用角色分配策略(例如,一个智能体负责检索,另一个负责推理)来处理复杂的问题求解任务。
HiRAG采用更偏向单流的设计模式,但仍然具备智能体特性,因为其大型语言模型在摘要生成和路径构建中发挥智能体的作用。该系统不采用多智能体协作模式,而是依赖分层检索机制来提升效率。
在协作能力方面,多智能体系统能够处理动态任务(例如一个智能体负责查询优化,另一个负责事实验证),特别适合长上下文问答场景。HiRAG的工作流程更加简化:离线构建分层结构,在线通过桥接机制执行检索。在稳健性表现上,MAIN-RAG通过智能体共识机制将不相关文档的比例降低2-11%,从而提高答案准确性。HiRAG通过预定义的推理路径减少幻觉现象,但可能缺乏多智能体系统的动态适应能力。HiRAG的优势包括单查询处理的更高速度,以及无需智能体协调的更低系统开销。多智能体系统在企业级应用中表现优秀,特别是在医疗保健等领域,能够协作检索患者数据、医学文献和临床指南。
以商业报告生成为例,多智能体系统可能让Agent1负责检索销售数据,Agent2负责趋势过滤,Agent3负责洞察生成。HiRAG则会将数据进行分层处理(基础层:原始数据;高层:市场摘要),然后通过桥接机制生成直接答案。
实际应用场景中的技术优势
HiRAG在天体物理学和理论物理学等科学研究领域展现出显著优势,这些领域中大型语言模型能够构建准确的知识层次结构(例如从详细的数学方程到宏观的宇宙学模型)。HiRAG论文中的实验证据表明,该系统在多跳问答任务中优于基线系统,通过桥接推理机制有效减少了幻觉现象。
在非科学领域,如商业报告分析或法律文档处理,需要进行充分的测试验证。HiRAG能够减少开放式查询中的问题,但其效果很大程度上依赖于所使用的大型语言模型的质量(如其GitHub仓库中使用的DeepSeek或GLM-4模型)。在医学应用中(基于HyperGraphRAG的测试结果),HiRAG能够很好地处理抽象知识;在农业领域,该系统能够有效连接低级数据(如土壤类型)与高级预测(如产量预测)。
与其他技术方案相比,各系统都有其特定的优势领域:LeanRAG更适合需要自定义编码的专业应用,但部署设置相对复杂;HyperGraphRAG在多实体关系场景中表现更优,特别是在法律领域处理复杂交织的条款关系;多智能体系统非常适合需要协作和自适应处理的任务,特别是在企业AI应用中处理不断演进的数据。
技术对比总结
综合分析表明,HiRAG的分层方法使其成为一个技术上平衡且实用的解决方案起点。未来的发展方向可能包括将不同系统的优势元素进行融合,例如将分层结构与超图技术相结合,从而在下一代系统中实现更强大的混合架构。
总结
HiRAG系统代表了基于图的检索增强生成技术的重要进展,通过引入分层架构根本性地改变了复杂数据集的处理和推理方式。该系统将知识组织为从详细实体到高级抽象概念的分层结构,实现了深度多尺度推理能力,能够有效连接表面上不相关的概念,例如在天体物理学研究中建立基本粒子物理学与星系形成理论之间的关联。这种分层设计不仅增强了知识理解的深度,还通过将答案建立在直接从结构化数据派生的事实推理路径基础上,最大程度地减少了对大型语言模型参数知识的单纯依赖,从而有效控制了幻觉现象。
HiRAG的技术创新在于其简单性与功能性之间的优化平衡。与需要复杂代码驱动图构造的LeanRAG系统,或者需要大量计算资源进行超边管理的HyperGraphRAG系统相比,HiRAG提供了一个更加易于实现的技术路径。开发人员可以通过标准化的工作流程来部署该系统:文档分块处理、实体提取、使用高斯混合模型等成熟算法进行聚类分析,并利用强大的大型语言模型(如DeepSeek或GLM-4)构建多层摘要结构。系统进一步采用Louvain方法等社区检测算法来丰富知识表示,通过识别跨层主题横截面确保查询检索的全面性。
在理论物理学、天体物理学和宇宙学等科学研究领域,HiRAG的技术优势表现得尤为突出。系统从低级实体(如"Kerr度量")抽象到高级概念(如"宇宙学解")的能力促进了精确且富含上下文的答案生成。在处理引力波特征等复杂查询时,HiRAG通过桥接三元组构建逻辑推理路径,确保了答案的事实准确性。基准测试结果显示,该系统超越了朴素RAG方法,甚至在与先进变体的竞争中表现优异,在多跳问答任务中达到88%的准确率,并将幻觉率降低至3%。
除了科学研究领域,HiRAG在法律分析、商业智能等多样化应用场景中都展现出良好的发展前景,尽管其在开放性非科学领域的效果很大程度上取决于所使用的大型语言模型的领域知识覆盖程度。对于希望探索该技术的研究人员和开发人员,活跃的GitHub开源仓库(如https://github.com/hhy-huang/HiRAG)提供了基于DeepSeek或GLM-4等模型的完整实现方案,包含详细的基准测试和示例代码。
对于物理学、医学等需要结构化推理的专业领域的研究人员和开发人员而言,尝试使用HiRAG来发现其相对于平面GraphRAG或其他RAG变体的技术优势具有重要价值。通过结合实现简单性、系统可扩展性和事实依据性,HiRAG为构建更可靠、更具洞察力的AI驱动知识探索系统奠定了技术基础,推动了我们在利用复杂数据解决现实世界问题方面的技术创新能力。
https://avoid.overfit.cn/post/928f5b924d6e46c09804b16488f9b953
作者:Tamanna