深度学习卷积神经网络项目实战
卷积神经网络项目实战
1.项目简介
1.1项目名称
基于CNN实现超市商品的混合颗粒度分类(500分类)
1.2 项目简介
该项目旨在通过卷积神经网络(CNN)实现超市商品的混合颗粒度分类,主要针对商品的不同种类进行分类,应用场景主要为大型超市的自助收银台,设备通过模型的嵌入快速识别商品种类并为顾客提供结账操作,降低了超市的人力资源,以及提高人员流通性。
本项目引入深度学习中的CNN模型,构建一个专门用于超市常见商品分类的网络架构,充分利用卷积层的局部特征提取能力以及深层网络的高阶特征融合能力,其包含了数据收集、数据预处理、模型训练、模型评估、模型移植、可视化等步骤,使用RP2K数据集进行模型训练,模型通过反复地特征学习提高分类精确度。同时,由于其中也包含部分细粒度难区分的类目(如不同水果、同种包装的不同饮料),项目中使用了数据增强等技术手段提高模型的泛化能力,最终达到高精度地分类结果。
2.数据集
本次项目所使用的数据集为RP2K数据集
RP2K数据集
RP2K (Retail Product 2000K) 是一个用于零售场景的 大规模细粒度商品图像分类数据集。
提出背景:在超市、便利店等零售场景中,存在数千上万种商品,很多商品的外观极其相似(比如不同口味的可乐、不同包装的方便面),这使得计算机视觉中的 细粒度图像分类(Fine-grained Image Classification, FGIC)成为一个关键挑战。
RP2K数据集包含了2000+商品类别,数据总量超过 200 万张商品图片,图片来源于真实零售场景(货架拍摄、收银台、监控视频帧)以及部分网络采集,覆盖了多角度(正面、侧面、倾斜)、不同分辨率与清晰度、光照差异、遮挡(部分商品被挡住)等环境。
本项目节选了其中的500类数据作为该项目的数据集。
下载
官网:RP2K链接 – 品览科技
下载的数据集已经被划分好,无需自己手动进行数据清洗

3.模型训练
3.1加载训练集数据/数据预处理
(1)设置数据增强:包含了改变图片大小、随机裁剪、随机水平翻转、颜色改变、随机翻转、归一化操作
transform = transforms.Compose([transforms.Resize((224, 224)), # 改变图片大小transforms.RandomCrop((224, 224)), # 随机裁剪transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ColorJitter(0.2, 0.2, 0.2, 0.1), # 改变颜色transforms.RandomRotation(10), # (-10°, 10°)随机旋转transforms.ToTensor(), # 归一化transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# 标准化
transforms.Compose() 是 PyTorch torchvision 中用于组合多个图像预处理/增强操作的工具。它的作用就是把多个 transform 按顺序串起来,让图像数据在加载时依次经过这些操作。
详细参数介绍参考pytorch官方文档:Illustration of transforms — Torchvision 0.23 documentation
(2)使用pytorch框架的ImageFolder加载训练数据
data_train = ImageFolder(root='./data/train', transform=transform)
transform参数为(1)中的数据增强设置,即加载的每一张图片都经过transform中的操作处理。
(3)使用数据加载器分批次加载数据
创建数据加载器对象:
train_loader = DataLoader(data_train, batch_size=32, num_workers=4, shuffle=True)
返回的train_loader是由数据包装成的可迭代对象。
batch_size为每批次数据的数量大小,根据个人电脑GPU性能进行设置,一般设置为2n2^n2n。
num_workers为数据加载的子进程数,>0 表示用多进程加载,能加快训练速度,一般设置为 0 或小于 CPU 核数。
shuffle决定是否打乱数据顺序,一般在训练时设置为True,测试时设置为False。
3.2模型选择
这里我选择了googlenet模型。我们的训练思路是使用已经训练好的模型参数,只对最后的输出层进行训练,也就是参数更新,具体操作如下。
加载预训练参数
# 加载预训练参数pretrained = googlenet(pretrained=True)pre_weights = pretrained.state_dict()pre_weights = {k: v.to(device) for k, v in pre_weights.items()}
state_dict()是模型通用方法,作用是返回参数字典
字典推导式的作用为遍历原字典的每个键值对 (k,v),对每个 tensor v 调用 .to(device) 方法,把它移动到指定设备,device一般设置为:
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
参数和模型默认存放在CPU中,使用to(device)可将其转移至GPU。
清除预训练参数的最后一层:
# 清除预训练参数最后一层数据pre_weights.pop('fc.weight')pre_weights.pop('fc.bias')
创建新模型:
# 创建模型model = googlenet(pretrained=False)num_classes = 500 # 分类类别数model.fc = nn.Linear(model.fc.in_features, num_classes)model = model.to(device)
model.fc = nn.Linear(model.fc.in_features, num_classes)的作用是将原本网络结构中的最后一层输出(即类别数)改为500。
更新模型参数:
# 更新模型参数weigths = model.state_dict()weigths.update(pre_weights)model.load_state_dict(weigths)
将预训练参数更新到模型中。
冻结层:
# 冻结层for name, param in model.named_parameters():if name != 'fc.weight' and name != 'fc.bias':param.requires_grad = False
将模型最后一层之前的参数的梯度计算禁用。
model.named_parameters() 是一个 生成器(generator),它会遍历模型中的所有参数,并返回 (参数名, 参数张量) 这样的键值对。
设置优化器:
# 优化器parameters = [x for x in model.parameters() if x.requires_grad]optimizer = opt.Adam(parameters, lr=1e-3)
优化器用于模型进行参数更新,这里我们只更新最后一层参数,并且使用的是Adam优化器。
设置损失函数:
# 损失函数criterion = nn.CrossEntropyLoss(reduction='sum')
选择交叉熵损失函数作为多分类损失函数。reduction 参数,它决定了 批次(batch)里多个样本的损失要如何合并,这里选择的是进行求和。
定义训练轮次:
epochs = 50
设置学习率调度器:
# 学习率调度器scheduler = opt.lr_scheduler.CosineAnnealingLR(optimizer, T_max=epochs, eta_min=1e-5)
这里选择的是余弦学习率调度器,目的是对每轮训练的学习率进行更新,让学习率从 高学习率非线性地逐渐减小到低学习率。
3.3训练
acc = []best_acc = 0# 训练for epoch in range(epochs):acc_total = 0loss_total = 0for i, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)output = model(data)main_out = output[0] # 主输出aux1_out = output[1] # 辅助输出1aux2_out = output[2] # 辅助输出2# 选取最大值作为分类结果,返回的pred为标签下标pred = torch.argmax(main_out, dim=1)acc_total += torch.sum(pred == target).item()# 梯度清零optimizer.zero_grad()# 计算综合损失loss = criterion(main_out, target) + 0.3 * (criterion(aux1_out, target) + criterion(aux2_out, target))loss_total += loss# 反向传播loss.backward()# 参数更新optimizer.step()# 学习率更新scheduler.step()# 将当前轮次模型准确率记录在acc中acc.append(acc_total / len(data_train))current_acc = acc[epoch]# 判断当前轮次参数准确率是否为最佳,若为最佳则保存该参数if current_acc > best_acc:# 更新最佳准确率best_acc = current_acctorch.save(model.state_dict(), './model/model.pth')# 打印每轮训练结果print(f'epoch--->{epoch + 1},'f'loss---> {loss_total.item() / len(data_train):.4f},'f' acc---> {acc_total / len(data_train):.4f}')acc用于保存每轮训练后的参数,best_acc用于保存历史最高准确率- 由于Googlenet模型内置有辅助选择器,所以其输出结果为一个元组,为一个主要输出和两个辅助输出,在进行损失函数计算的过程中,需要考虑辅助分类的损失,通过分配不同权重比得到最终的损失函数。
- 判断当前准确率是否为历史最佳准确率,若为最佳准确率则保存参数,方便后续进行模型迁移。
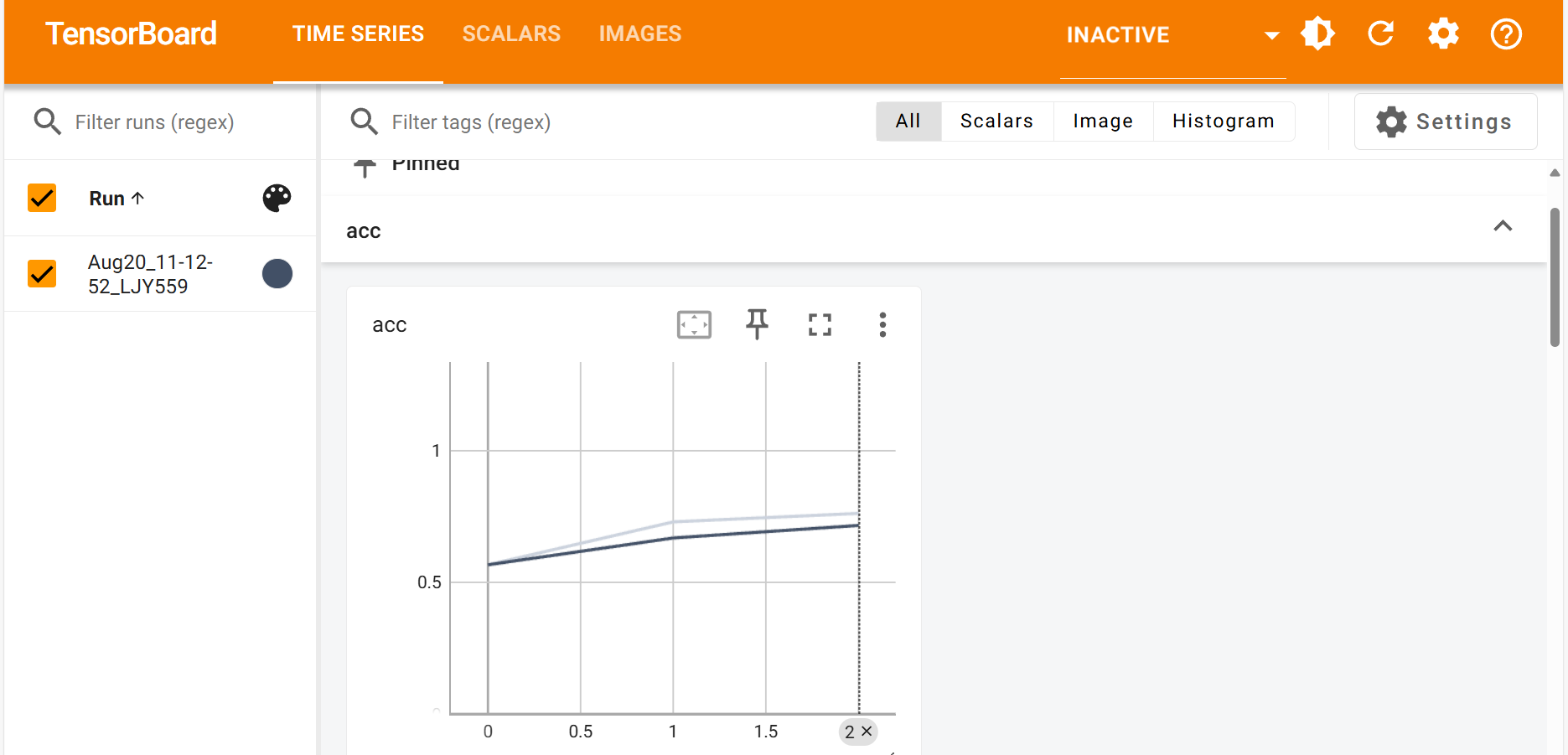
3.4训练过程可视化
使用tensorboard模块将训练过程可视化:
from torch.utils.tensorboard import SummaryWriter
创建tensorboard对象:
# 创建tensorboard对象writer = SummaryWriter()
SummaryWriter(log_dir=tbpath)log_dir为tensorboard日志保存路径,未设置保存路径会保存至当前文件夹下自动创建的runs文件夹下。
绘制过程曲线:
writer.add_scalar('loss', loss_total, epoch)writer.add_scalar('acc', acc_total / len(data_train), epoch)
显示数据增强后的图片:
if i % 100 == 0:img_grid = torchvision.utils.make_grid(data)writer.add_image(f'r_m_{epoch}', img_grid, i)
运行后会在runs文件夹内生成可视化的文件。
接下来打开终端,输入命令:
tensorboard --logdir=runs
也可将runs改为指定路径。
随后点击生成的本地网站即可查看绘制的曲线图以及图片:
4.模型评估
4.1加载预测集数据
同加载训练集类似,只不过在数据增强时一般只进行重新设置图片大小和标准化以及归一化操作,因为模型预测是在真实数据分布下的表现,因此我们 不能引入随机性,而resize图片大小是为了让数据的shape和模型的输入shape一致。
# 加载预测数据集
transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
data_test = ImageFolder(root='./data/test', transform=transform)
test_loader = DataLoader(data_test, batch_size=32, shuffle=False)
4.2加载模型
加载之前训练好的模型参数
# 加载训练好的模型
model = googlenet(pretrained=False)
model.fc = nn.Linear(model.fc.in_features, 500)
model = model.to(device)
weights = torch.load('./model/model.pth')
model.load_state_dict(weights)
4.3结果预测
首先将模型切至验证模式:
# 验证模式
model.eval() # 关闭 Dropout 和辅助分类器
注意:这一步至关重要,模型默认会处于训练模式下,这会使得google网络结构中的辅助分类和Dropout没有关闭,dropout未关闭会导致预测时神经元丢失,影响最终结果。
进行验证:
with torch.no_grad():acc = 0for data, label in test_loader:data, label = data.to(device), label.to(device)output = model(data)# 选取最大值作为分类结果,返回的pred为标签下标pred = torch.argmax(output, dim=1)acc += torch.sum(pred == label).item()
with torch.no_grad():作用:关闭参数梯度计算,加速预测,节省内存。
4.4预测评估
打印结果:
acc = acc / len(data_test)
print(f"acc:{acc:.5f}")
4.5预测结果可视化
可引入numpy和pandas将预测的数据转变成excel表格(csv格式文件),具体操作如下:
创建一个列数为502的numpy空二维数组:
data_csv = np.empty((0, 502))
因为模型的输出为每个类别下所对应的输出值,取最大的输出值的类别作为分类结果,所以需要500列存放模型输出值,1列存放预测标签,1列存放实际标签。
将每一批次训练的数据存入numpy数组:
output_csv = output.cpu().detach().numpy()
pred_csv = np.expand_dims(pred.cpu().detach().numpy(), axis=1)
label_csv = np.expand_dims(label.cpu().detach().numpy(), axis=1)
batch_csv = np.concatenate((output_csv, pred_csv, label_csv), axis=1)
data_csv = np.concatenate((data_csv, batch_csv), axis=0)
取出标签:
labels = data_test.classes
将结果转换为Datafream再导出为csv文件:
# 将结果转为csv文件
column = [*labels, 'pred', 'label']
data_csv = pd.DataFrame(data=data_csv, columns=column)
data_csv.to_csv('./data_pred_result/result.csv', index=False)
同时把标签存为csv文件:
# 将标签存为csv文件
df = pd.DataFrame({"index": list(range(len(labels))), "label": [*labels]})
df.to_csv('./labels.csv', index=False)
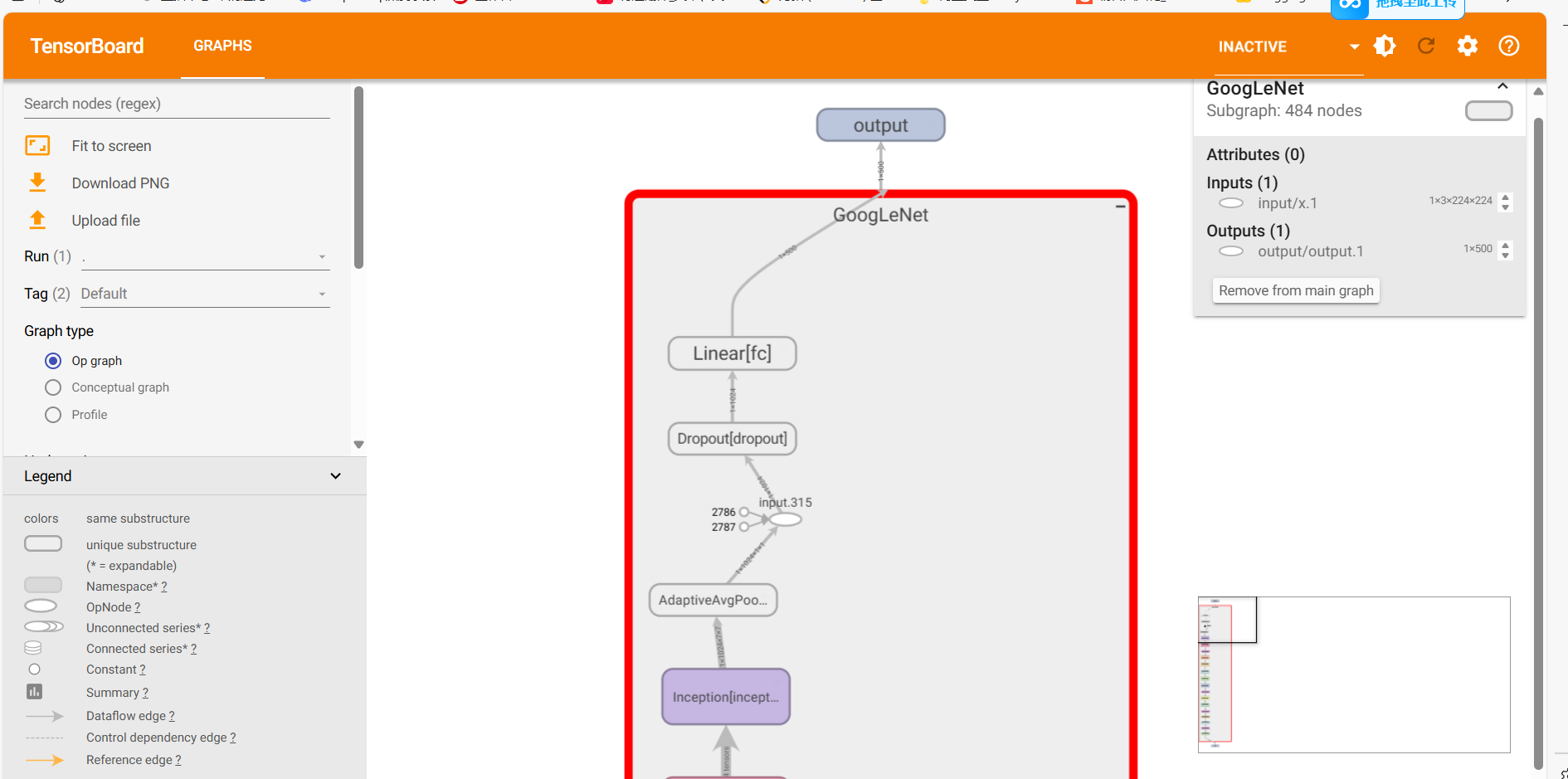
也可以将网络结构进行可视化观察网络结构:
writer = SummaryWriter("./net_frame")
dummy_input = torch.randn(1, 3, 224, 224)
writer.add_graph(model, dummy_input.to(device))
writer.close()
同样的用终端生成本地网站,进入网站查看可视化结果:
tensorboard --logdir=文件绝对路径
4.6生成分类报告
导入matplotlib模块和pandas模块,读到之前预测生成的csv文件,获取标签:
# csv文件地址
data_path = './data_pred_result/result.csv'
# 读取csv数据
data = pd.read_csv(data_path)
# 获取真实标签
true_label = data["label"].values
# 获取预测标签
pred_label = data["pred"].values
接着导入sklearn.metrics模块生成分类报告:
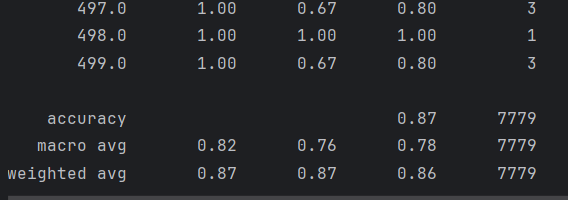
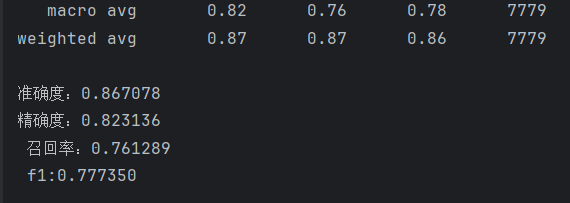
# 生成分类报告report = classification_report(true_label, pred_label)print(report)acc = accuracy_score(true_label, pred_label)precision = precision_score(true_label, pred_label, average='macro')recall = recall_score(true_label, pred_label, average='macro')f1 = f1_score(true_label, pred_label, average='macro')print(f"准确度:{acc:.6f}\n"f"精确度:{precision:.6f}\n",f"召回率:{recall:.6f}\n",f"f1:{f1:.6f}\n")
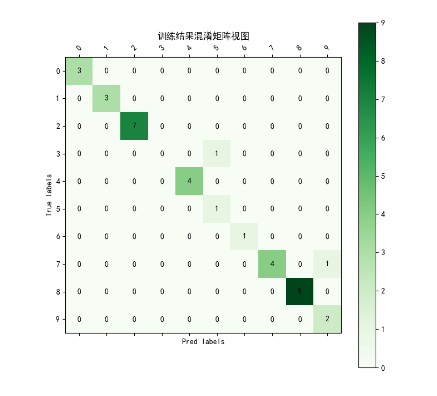
用matlplotlib生成混淆矩阵(由于原始数据的混淆矩阵太大,500分类即500*500矩阵,这里只生成前十分类的混淆矩阵作为演示):
def vision_martix(true_label, pred_label, num_classes=10):labels = [x for x in range(num_classes)]matrix = confusion_matrix(true_label, pred_label)print(matrix)plt.figure(figsize=(8, 8))plt.matshow(matrix[:10, :10], cmap=plt.cm.Greens, fignum=1)# 显示颜色条plt.colorbar()# 显示具体的数字的过程for i in range(len(matrix)):for j in range(len(matrix)):plt.annotate(matrix[i, j],xy=(j, i),horizontalalignment="center",verticalalignment="center",)# 美化的东西plt.xlabel("Pred labels")plt.ylabel("True labels")plt.xticks(range(len(labels)), labels, rotation=45)plt.yticks(range(len(labels)), labels)plt.title("训练结果混淆矩阵视图")plt.show()
效果:
5.模型应用
首先读取图片,这里我导入了opencv模块进行读图,并且将读取到的图片进行预处理操作:
# 读图处理img = cv.imread(img_path)img = cv.resize(img, (224, 224))transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))])img = transform(img)img = torch.unsqueeze(img, 0).to(device)
加载训练好的模型:
net = googlenet(pretrained=False)net.fc = nn.Linear(net.fc.in_features, 500)net.load_state_dict(torch.load("./model/model.pth"))net.to(device)
进行预测:
# 预测net.eval()output = net(img)output = torch.argmax(output, dim=1)print(output)
可以用Imagefolder导入训练集或输出集获取标签映射表,将标签映射转换为下标映射:
idx_to_class = {v: k for k, v in data.class_to_idx.items()}
print(idx_to_class[pred])
最后得到结果:

6.模型迁移
6.1导出onnx模型
首先需要提前在环境内安装依赖包
pip install onnx
pip install onnxruntime
导入训练好的模型:
# 导入训练好的模型
net = googlenet(pretrained=False)
net.fc = nn.Linear(in_features=net.fc.in_features, out_features=500)
weight_path = "./model/model.pth"
net.load_state_dict(torch.load(weight_path))
创建一个实例输入:
x = torch.randn(1, 3, 224, 224)
用torch.onnx.export导出onnx:
torch.onnx.export(net,x,onnx_path,verbose=True,input_names=['input'],output_names=['output']
)
6.2使用onnx推理
加载onnx模型:
# 加载onnx模型
onnx_path = './model_onnx/model.onnx'
session = rt.InferenceSession(onnx_path)
对要进行推理的图片进行预处理:
def read_img(path):# 处理输入图片img = cv.imread(path)img = cv.resize(img, (224, 224))img = img.transpose((2, 0, 1))img = img.astype(np.float32) / 255.0 # 代替Totensor()操作img = np.expand_dims(img, axis=0)return imgimg_path = "./apply/1.jpg"
img1 = read_img(img_path)
进行推理:
# 获取输入输出名
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name# 推理
result = session.run([output_name], {input_name: img1})
得到结果并且将结果从下标值映射为标签名:
# 取出分类标签下标
result = np.argmax(result[0], axis=1)
print(result)# 读取保存好的标签csv文件建立 index->label 映射表
df = pd.read_csv("labels.csv")
idx2label = dict(zip(df["index"], df["label"]))
print(f"img的分类为:{idx2label[result.item()]}")
项目源代码仓库:卷积神经网络项目实战: 卷积神经网络个人实战项目
注意:训练集以及生成文件夹需要自己手动创建,具体文件夹已在file_expression文档中说明。
ply/1.jpg"
img1 = read_img(img_path)
进行推理:```python
# 获取输入输出名
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name# 推理
result = session.run([output_name], {input_name: img1})
得到结果并且将结果从下标值映射为标签名:
# 取出分类标签下标
result = np.argmax(result[0], axis=1)
print(result)# 读取保存好的标签csv文件建立 index->label 映射表
df = pd.read_csv("labels.csv")
idx2label = dict(zip(df["index"], df["label"]))
print(f"img的分类为:{idx2label[result.item()]}")
项目源代码仓库:卷积神经网络项目实战: 卷积神经网络个人实战项目
注意:训练集以及生成文件夹需要自己手动创建,具体文件夹已在file_expression文档中说明。
如果博主的文档和源代码对你有所帮助,也麻烦给博主点个收藏和赞噢,谢谢☆噜~☆