MySQL学习记录-基础知识及SQL语句
目录
概述-数据模型
1、关系型数据库(RDBMS)
概念
特点
2、MySQL数据库
数据模型
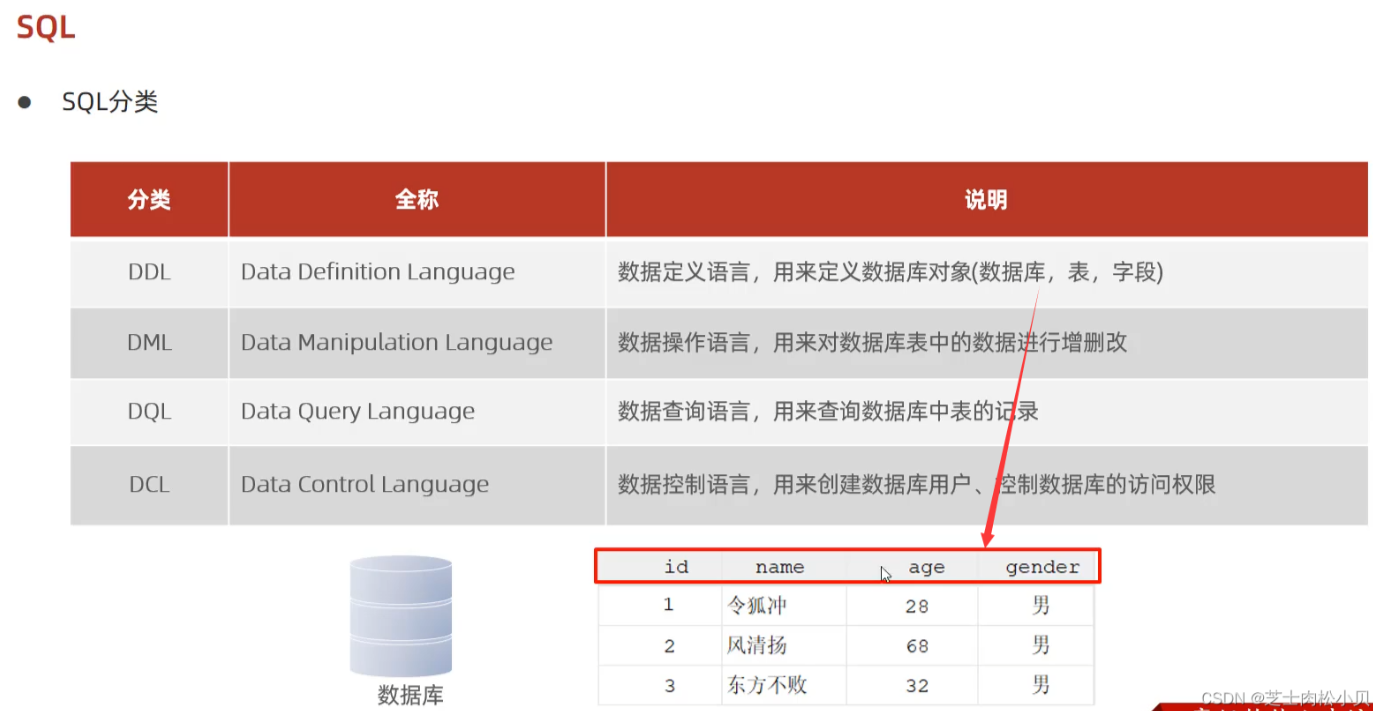
3、SQL通用语法及分类
SQL语句分类
4、DDL
数据库操作(用来定义数据库、表、字段的语句)
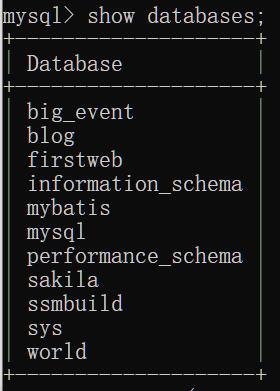
查询所有数据库
使用指定的数据库
表操作
表操作—创建
表操作—查询
表操作—数据类型
表操作—修改&删除
小结
4、DQL
基础查询
条件查询
聚合函数
分组查询
排序查询
分页查询
小结
5、DCL
用户管理
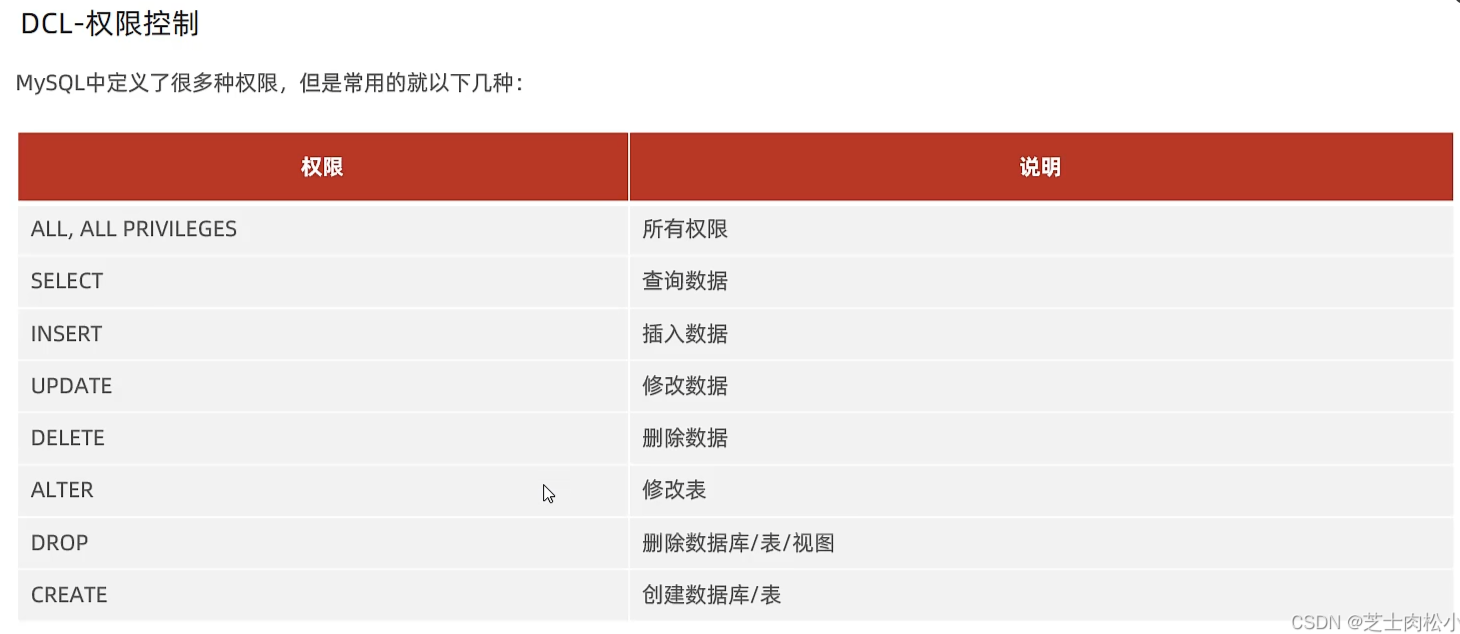
权限控制
小结
6、函数
字符串函数
数值函数
日期函数
流程函数编辑
小结编辑
7、约束
演示
外键约束
小结
8、多表查询
多表关系
编辑一对多编辑
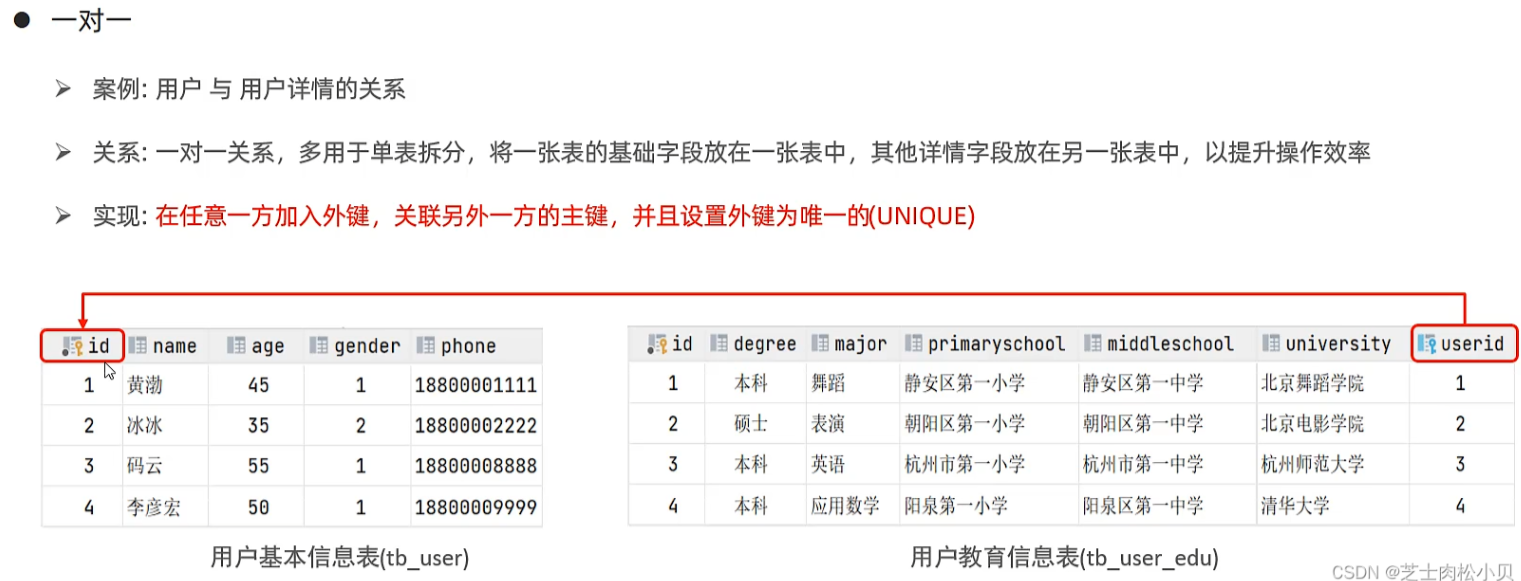
概述
内连接
外连接
自连接
联合查询- union, union all
子查询
标量子查询
列子查询编辑
行子查询
表子查询
小结
9、事务
简介
操作演示
四大特性ACID
并发事务问题
事务隔离级别
小结编辑
概述-数据模型
1、关系型数据库(RDBMS)
概念
建立在关系模型基础上,由多张相互连接的二维表组成的数据库
特点
- 使用表存储结构,格式统一,便于维护
- 使用SQL语言操作,标准统一,使用方便
2、MySQL数据库
数据模型
客户端通过SQL语句连接DBMS(数据库管理系统)来创建数据库或者在数据库里面创建表
- 一个数据服务器当中可以创建多个数据库
- 一个数据库当中可以创建多个表
- 一个表当中可以存储多个记录
3、SQL通用语法及分类
通用语法(所有的关系型数据库的通用语法,不同数据库会存在部分聚合函数的不一致)
1、SQL语句可以单行或者多行书写,以分号结尾
2、SQL语句可以使用空格/缩进来增强语句的可读性
3、MySQL数据库的SQL语句不区分大小写,关键字建议使用大写
4、注释:
- 单行注释:-- 注释内容 或 # 注释内容
- 多行注释:/*注释内容*/
分大小写,关键字建议使用大写
4、注释:
单行注释:-- 注释内容 或 # 注释内容
多行注释:/*注释内容*/
SQL语句分类
4、DDL
数据库操作(用来定义数据库、表、字段的语句)
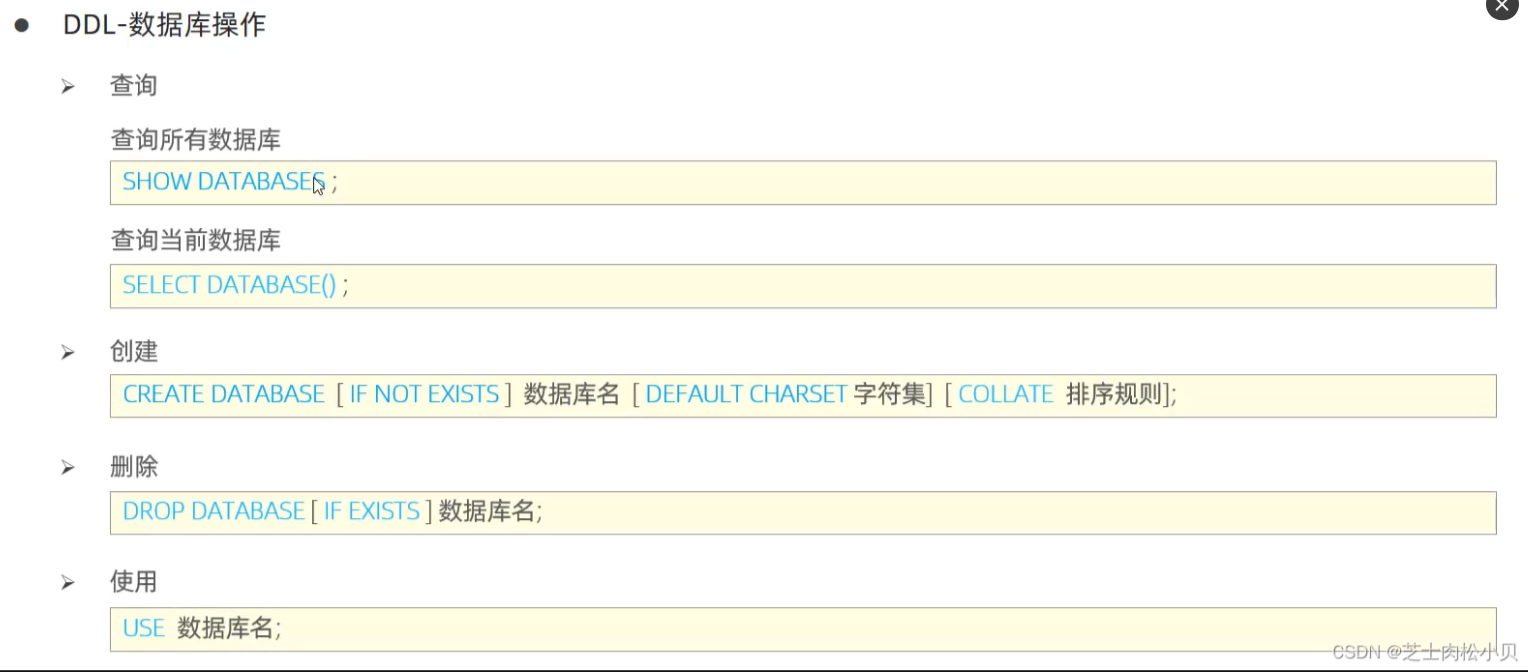
注:
- [ IF NOT EXISTS]:如果库不存在,则进行创建,否则,不进行操作
- [ ]的内容都是可选的
查询所有数据库
创建数据库

数据库已经存在的情况下也会执行成功,但是不会再次创建数据库(这里的 default chatset utf8mb4 为指定字符集,至于为什么后续再做研究)
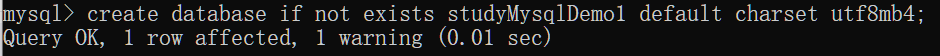
创建不重名数据库即可创建成功
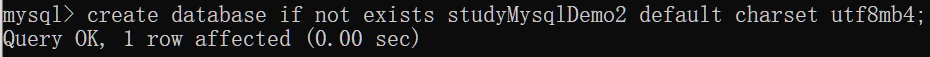
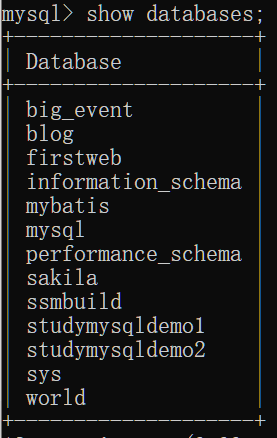
查看所有数据库
删除数据库

确认删除完成
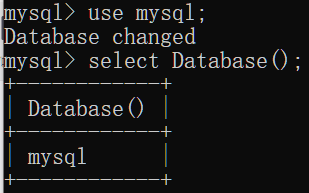
使用指定的数据库
表操作
表操作—创建
 尝试创建表完成
尝试创建表完成
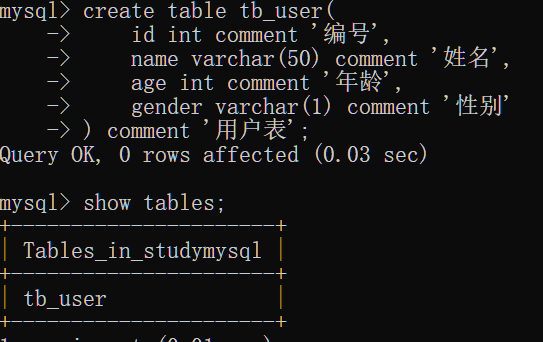
表操作—查询
查询当前数据所有表
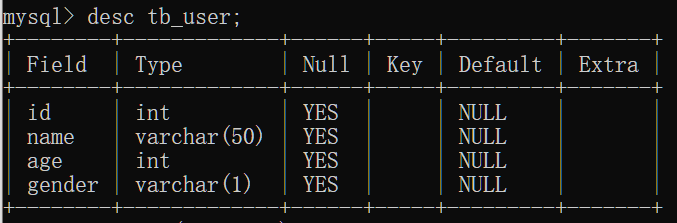
查询表结构
查看建表语句
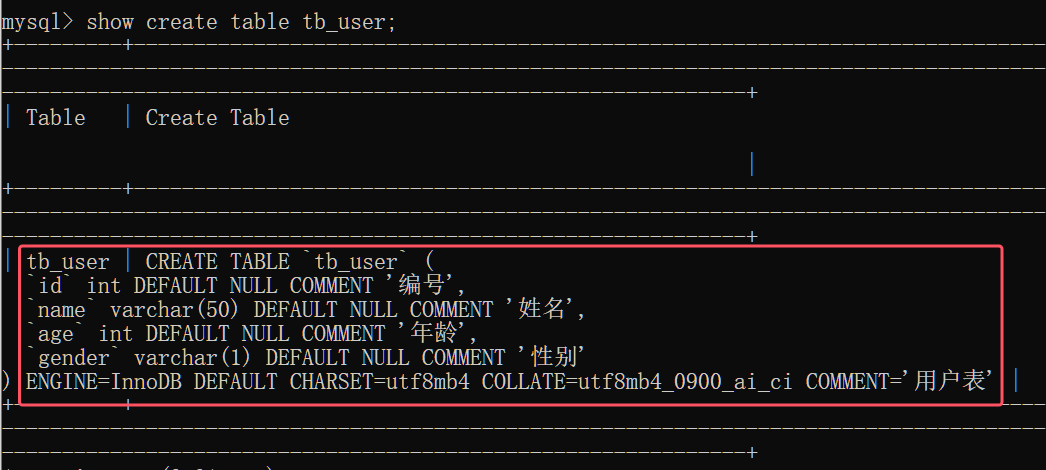
表操作—数据类型
数值类型
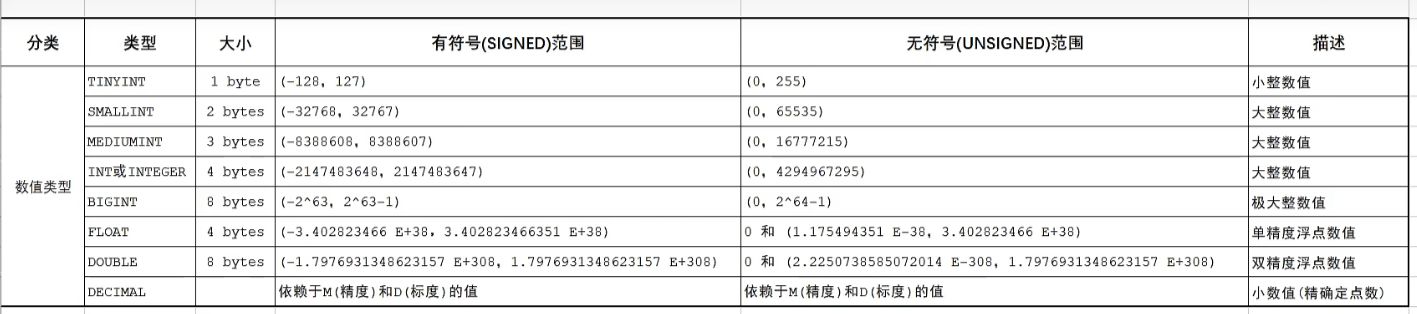
注:有符号范围:允许出现负数,它的取值范围
无符号范围:不允许出现负数,它的取值范围
对应Java内的数据类型:
- TINYINT -> Java中的byte
- SMALLINT -> Java中的short
- INT/INTEGER -> Java中的int
- BGIINT -> Java中的long
小数:123.45的精度(长度)为5,标度(小数点后面的位数)为2
例:score double(4,1)(分数最大100.0,标度设为1)
age TINYINT UNSIGNED表示年龄为TINYINT,UNSIGNED为无符号
字符串类型
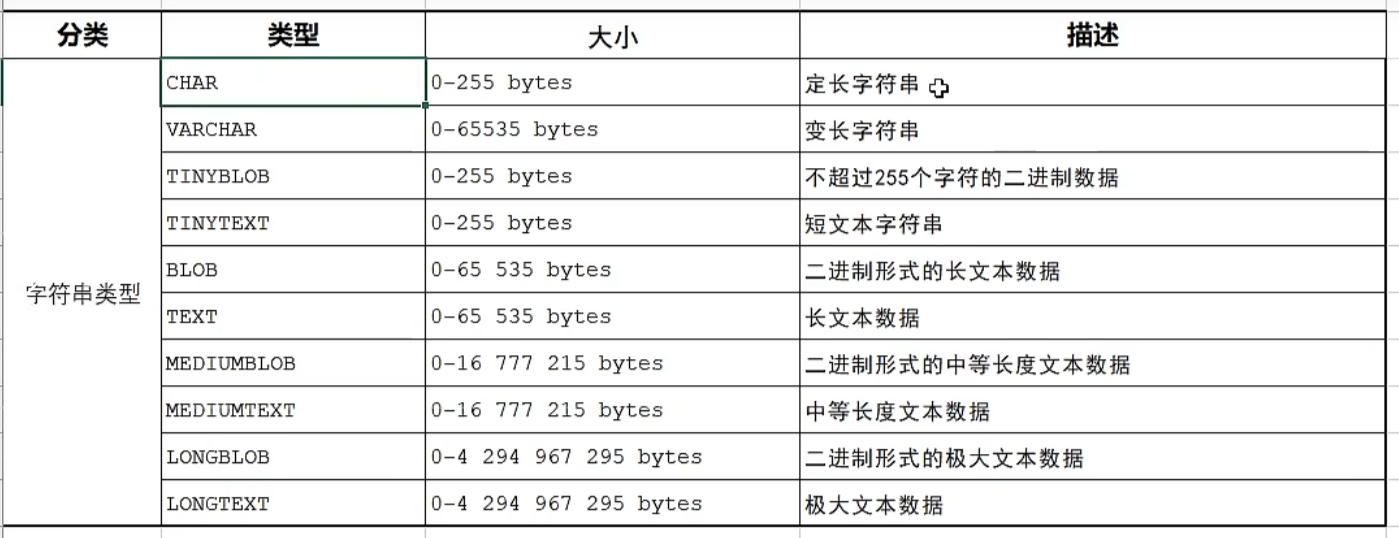
例:char(10) ➡指定数据固定长度为10,用在已知数据长度的场景:手机号、身份证等。。。
varchar(50)➡指定数据长度为0-50,用于数据长度的不明确的场景:姓名、籍贯等。。。
注:二进制数据主要为视频、音频、软件包等,用得不多
日期时间类型

注:DATE、TIME、DATETIME用得更多
案例

创建表完成

查看表结构

表操作—修改&删除
添加字段

添加字段完成

查看表结构

修改字段名、字段属性
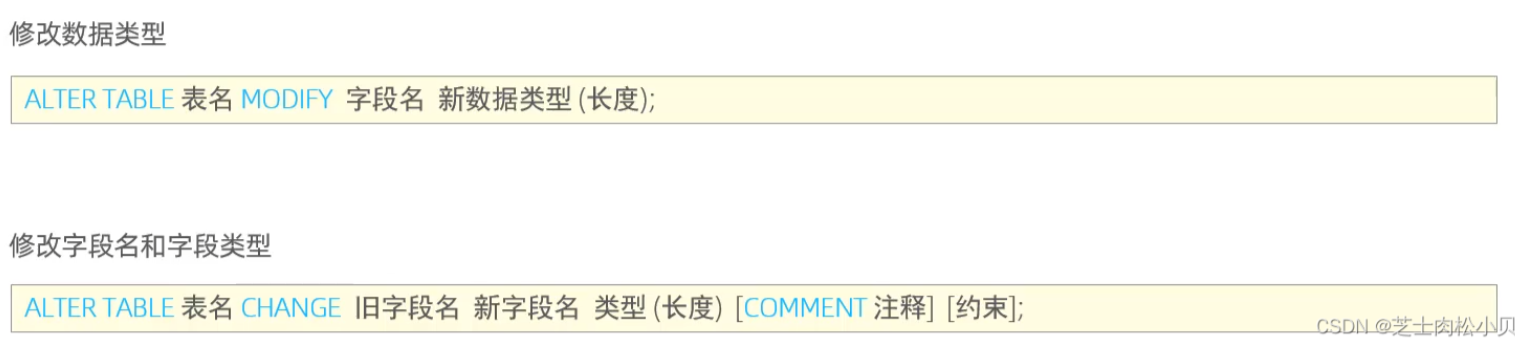
例:将emp表的nickname字段修改为username,类型为varchar(30)
 查看表结构,确认修改完成
查看表结构,确认修改完成

修改表名

例:将emp表的表名修改为employee

查看表结构,确认修改完成

删除字段

例:将emp表中字段username删除

查看表结构,确认修改完成

删除表
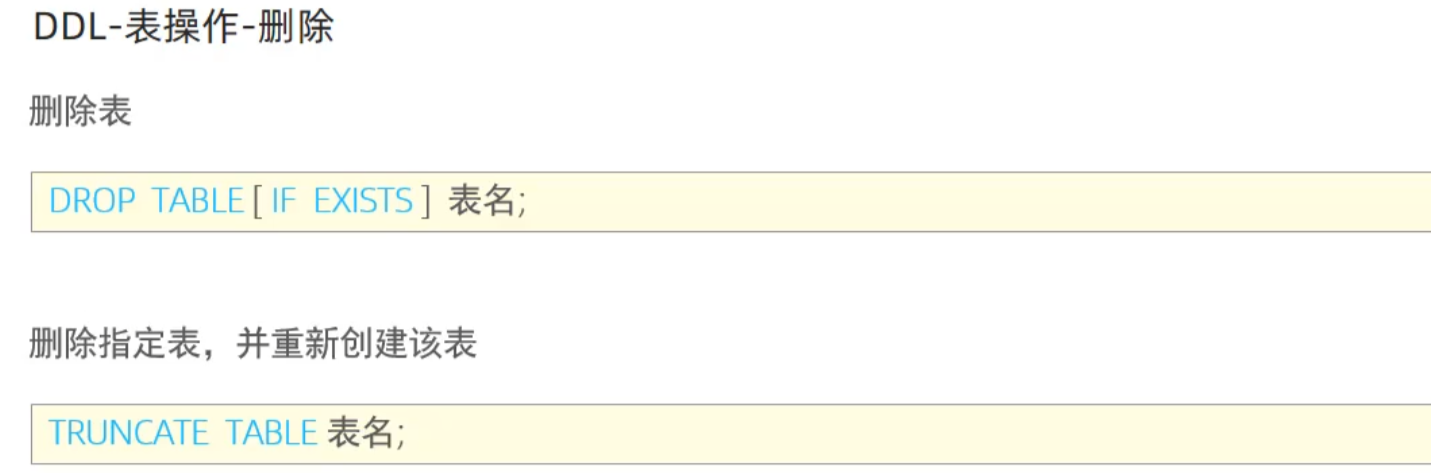
eg:
- drop(删除表结构及其数据)


- truncate(只删除表数据,不删除表结构)


小结

4、DQL
数据查询语言,DQL(Data Query Language),日常生活中,查询的行为比增删改操作更多。其中分组查询常配合聚合函数使用,所以在讲解分组查询之前先讲解聚合函数。

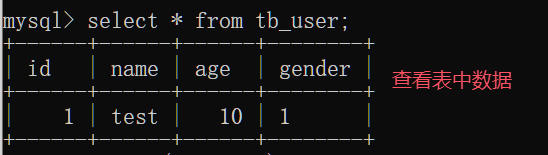
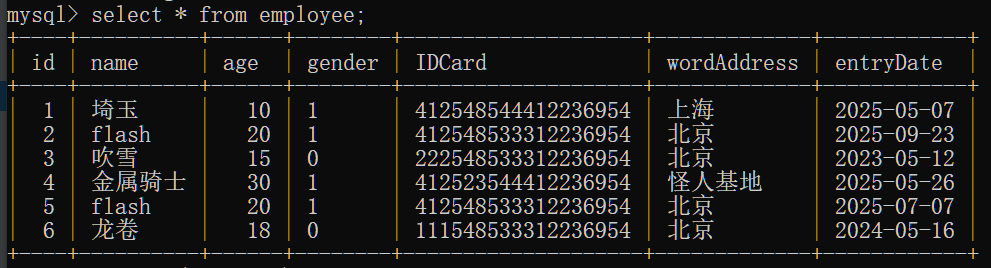
数据准备
基础查询
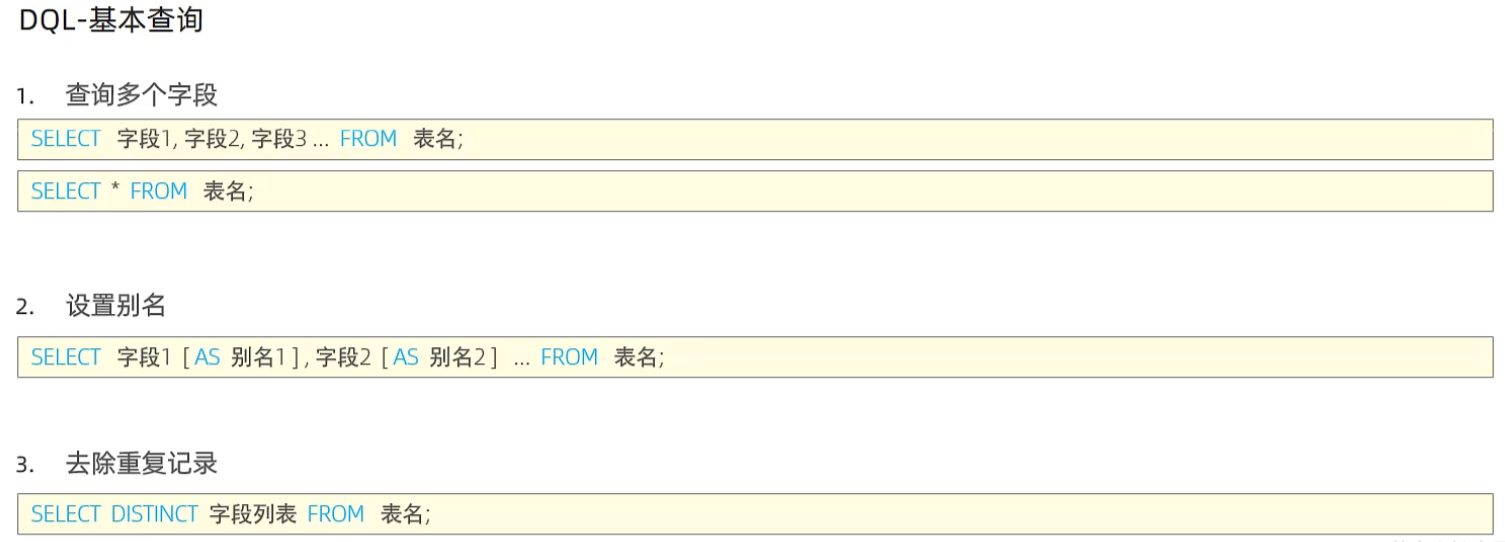
查询字段
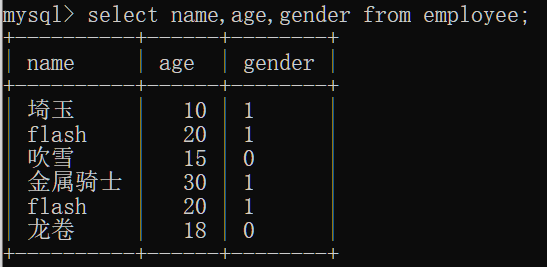
设置别名
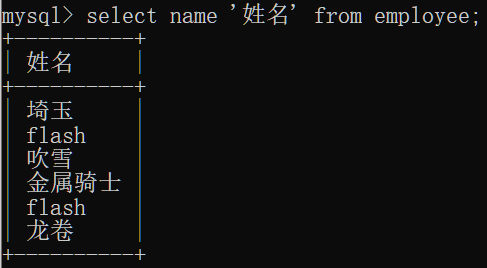
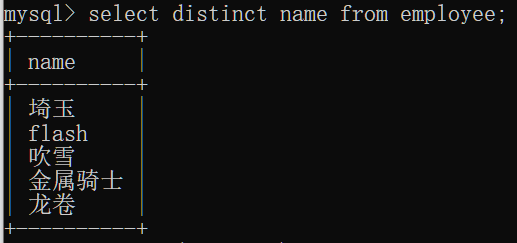
去除指定列的重复数据
条件查询

聚合函数

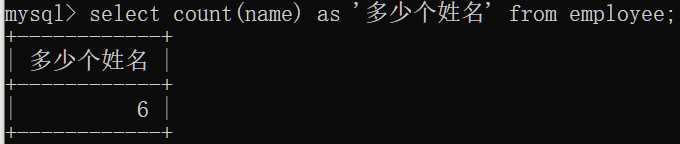
注:null 值不参与所有聚合函数运算,在统计数量是不会被记录。
测试null不参与聚合函数
统计id
统计name,实际测试确实不会统计null
分组查询

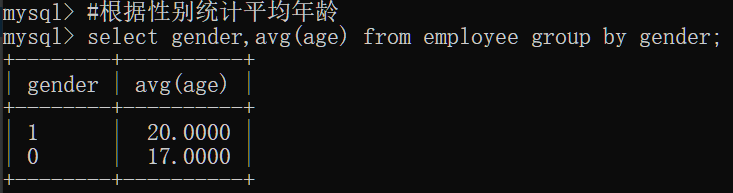
根据性别统计平均年龄
查询年龄小于20的员工,并根据性别分组,查询员工数量大于2的性别

虽然上面也查出了我们想要的结果,但是我们只想要性别的数据怎么办呢?那么可以参考下面这种写法。(核心就是聚合函数可以直接在having条件中使用)

注:
- 执行顺序:where > 聚合函数 > having #分组的时候执行聚合函数;
- 分组之后,查询的一段一般为聚合函数和分组字段,查询其他字段无意义。
排序查询

根据员工年龄降序排列显示
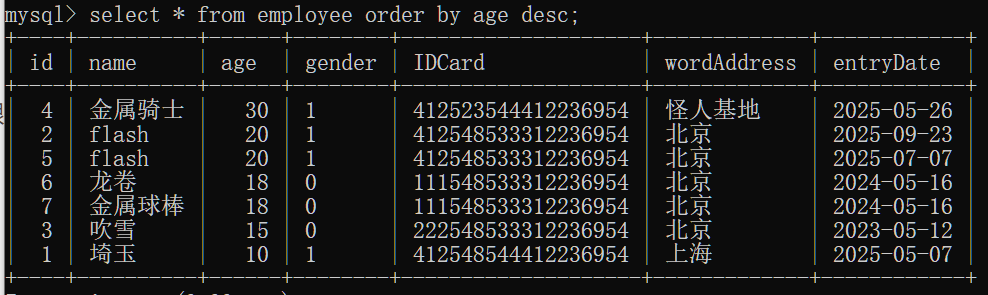
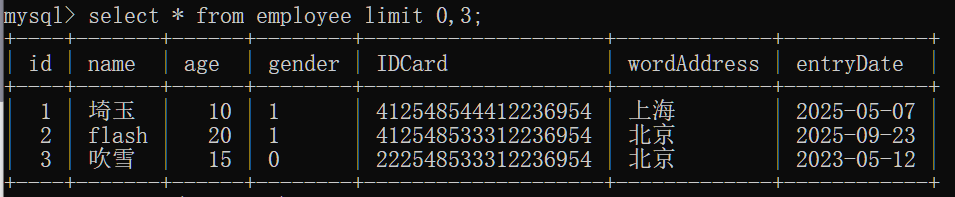
分页查询

注:在MySQL中实现分页为limit,在SQL Server中为 top
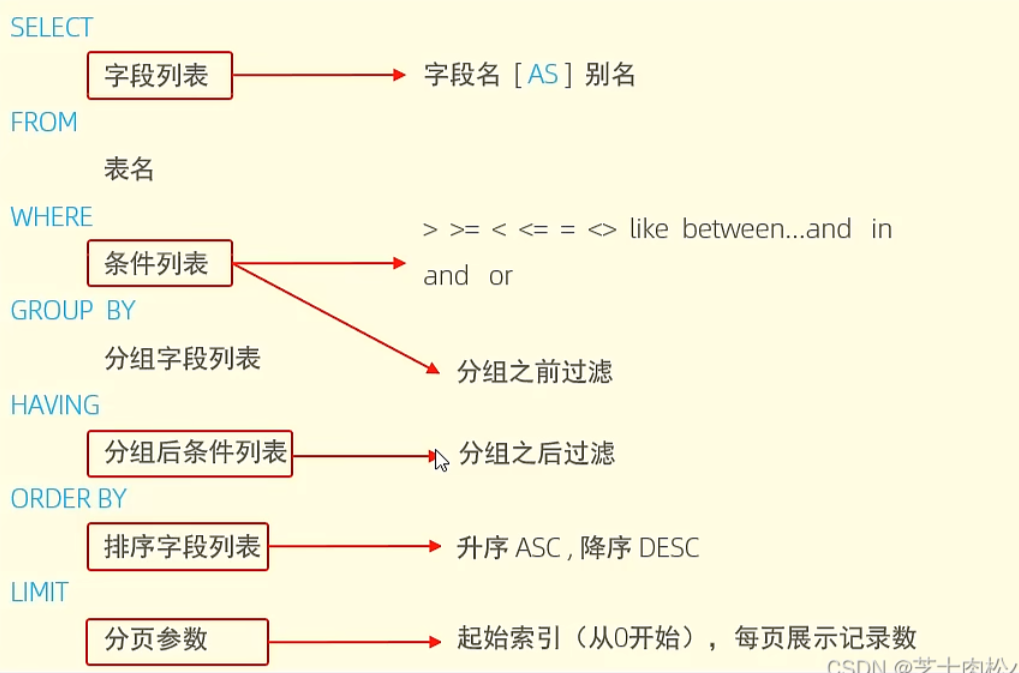
SQL执行顺序

小结
5、DCL
用来管理数据库用户、控制数据库的访问权限。
用户管理
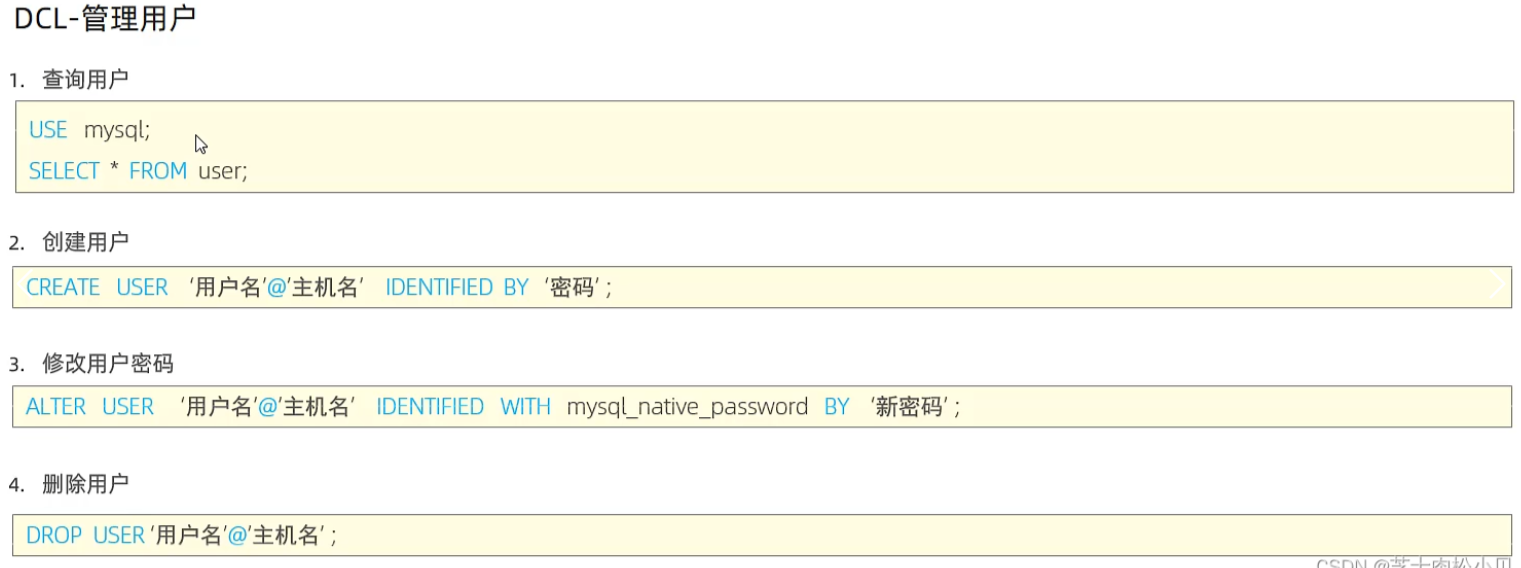
注:在MySQL中,用户的信息及用户所具有的权限的信息都是存放在 mysql 库中的 user 表里,同时知道主机地址和用户名才能完整的定位一个用户。
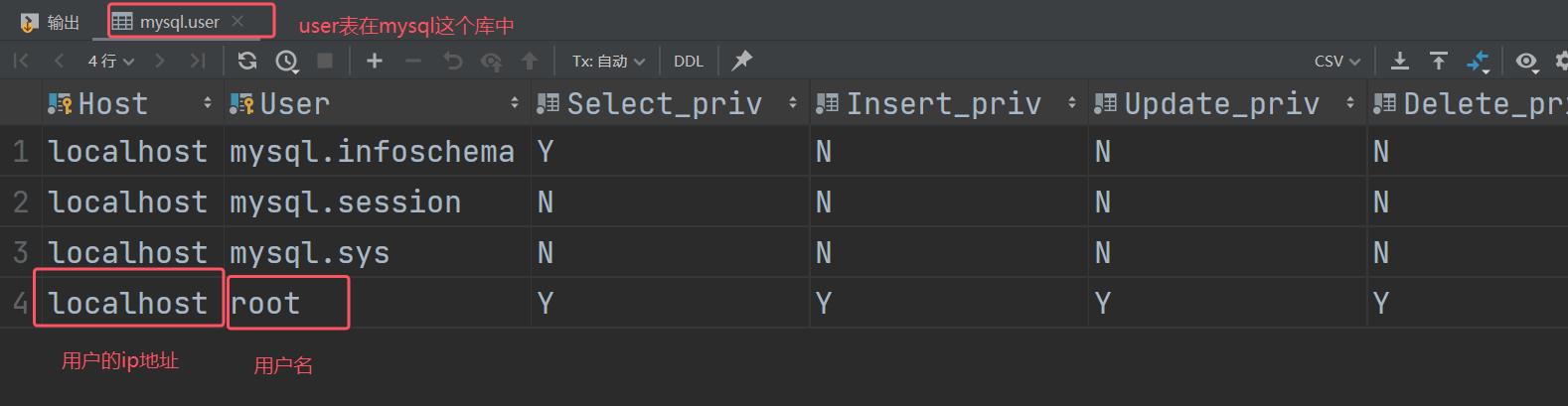
# 创建用户 itcast, 只能在当前主机 localhost 访问, 密码123456;
create user 'itcast'@'localhost' identified by '123456'; # 这里只是创建了用户,但是并没有给他分配权限!# 创建用户 heima, 可以在任意主机访问该数据库, 密码123456;
create user 'heima'@'%' identified by '123456';# 修改用户 heima 密码1234;
alter user 'heima'@'%' identified with mysql_native_password by '1234';# 删除 itcast@localhost 用户
drop user 'itcast'@'localhost';注:
- 主机名可以使用 % 通配,使用%后表示任意ip地址
- 这类SQL开发人员操作较少,主要是DBA(Database Administrator 数据库管理员)使用。
权限控制

# --查询权限
show grants for 'heima'@'%'; # GRANT USAGE ON *.* TO `heima`@`%`# --授予权限
grant all on itcast.* to 'heima'@'%'; # GRANT ALL PRIVILEGES ON `itcast`.* TO `heima`@`%`# --撤销权限
revoke all on itcast.* from 'heima'@'%'; # GRANT USAGE ON *.* TO `heima`@`%`注:
- 多个权限之间,使用逗号分隔;
- 授权时,数据库名和表名可以使用* 进行通配 ,代表所有。
小结

6、函数
一段可以直接被另一段程序调用的程序或代码。
字符串函数
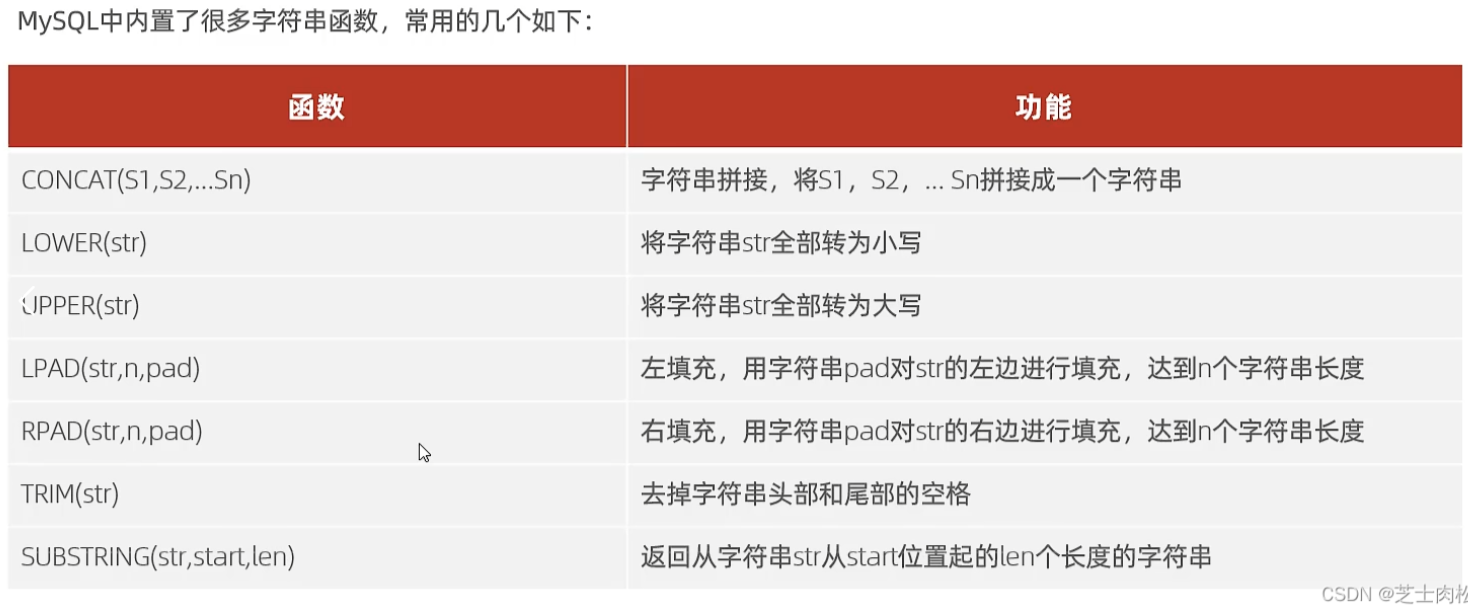
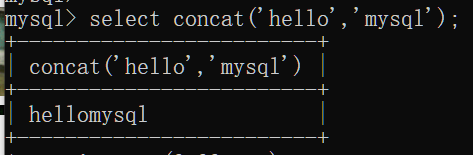
concat(str1,str2):拼接字符串
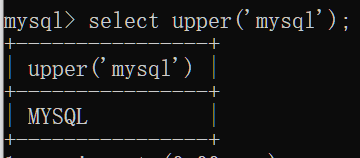
lower(str):将英文字母全部转换为小写
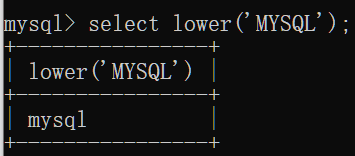
upper(str):将英文字母全部转换为大写
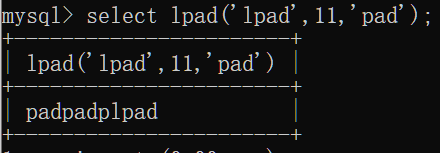
lpad(str,n,pad):左填充,用字符串pad,填充到str左边直到长度为n
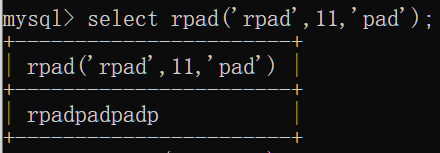
rpad(str,n,pad):左填充,用字符串pad,填充到str右边直到长度为n
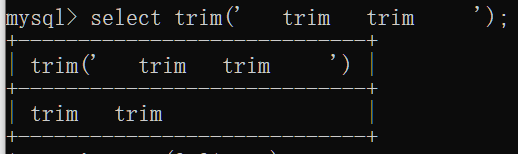
trim(str):去除字符串头尾的空格
substring(str,n,len):截取字符串从n开始截取len长度,下标从1开始,左闭

-- 1、企业员工工号统一为五位数,不足五位的前面补0update emp set workno = lpad(workno, 5, '0');数值函数
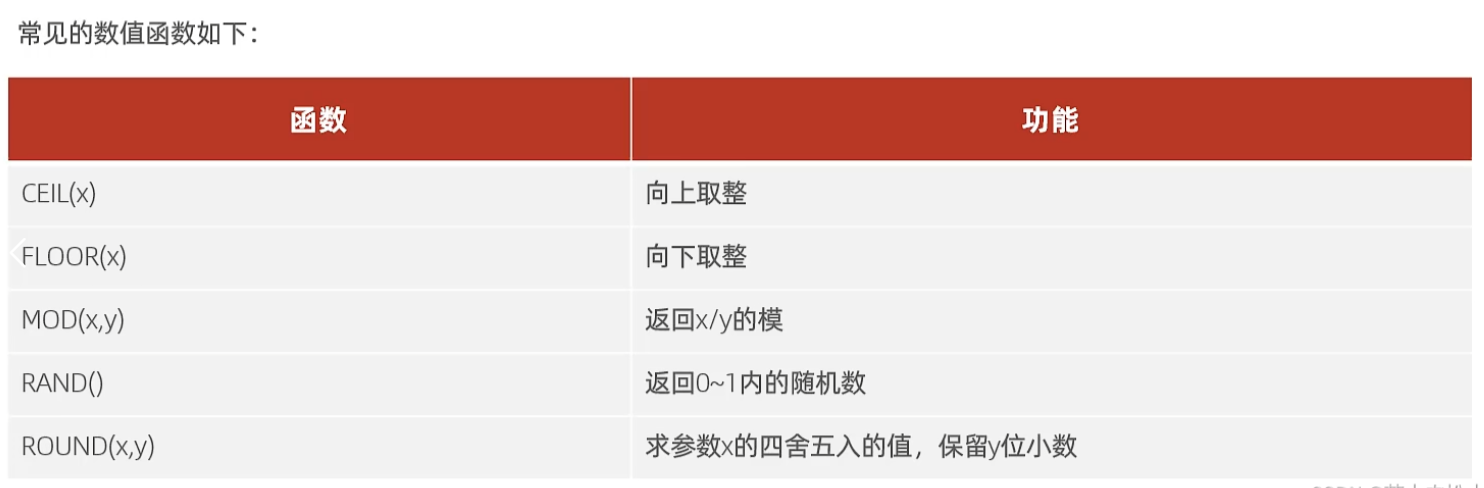
ceil(x):向上取整
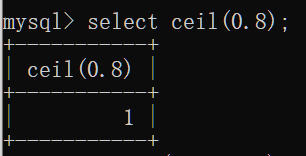
floor(x):向下取整
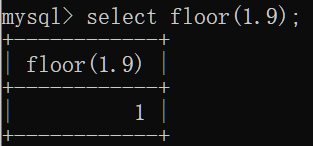
mod(x):取模
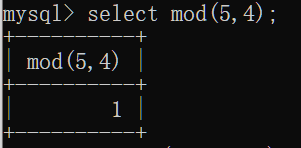
rand():0-1的随机数
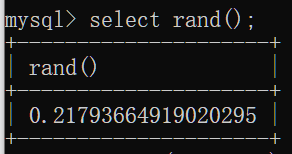
round(x,y):求x四舍五入的值,保留y为小数,这里的四舍五入是相对于需要保留位数之后的数字
-- 2、通过数据库函数,生成一个六位数的随机验证码select lpad(round(rand() * 1000000, 0), 6, '0');日期函数
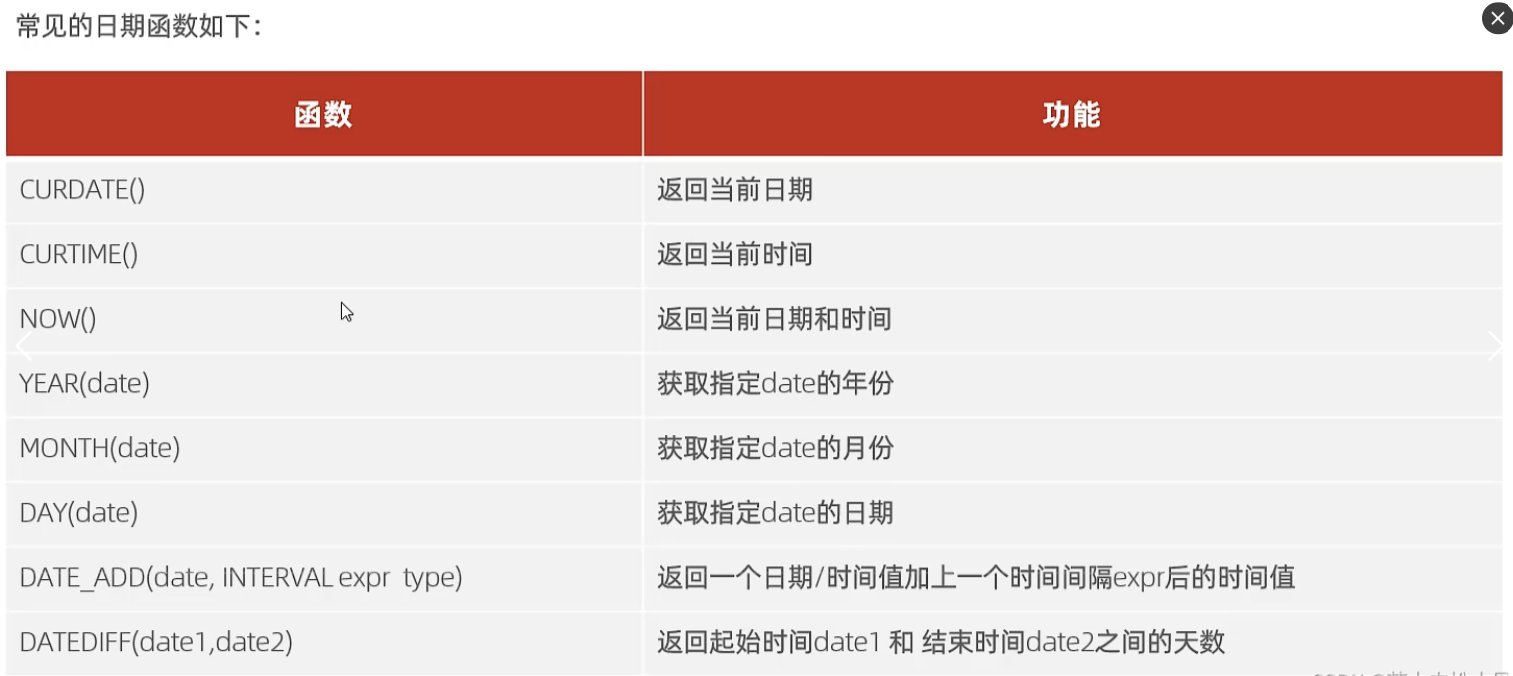
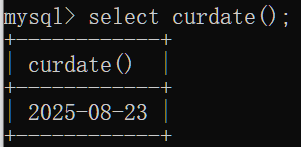
curdate():返回当前年月日
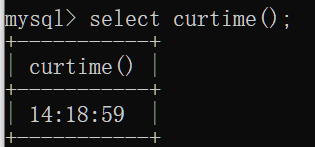
curtime():返回当前时分秒
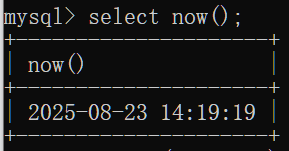
now():返回当前年月日时分秒
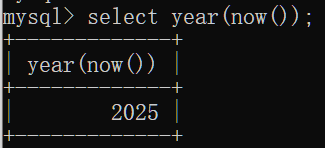
year(date):获取指定date的年份
month(date):获取指定date的月份
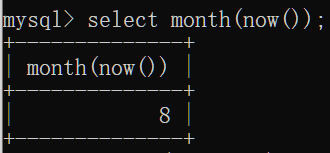
day(date):获取指定date的日期
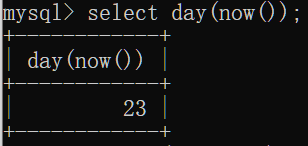
date_add(date,interval expr type):返回一个日期/时间值加上一个时间间隔expr后的时间值
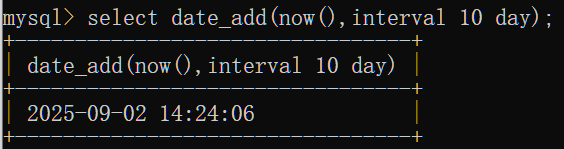
datediff(date1,date2):返回开始时间date1和结束时间date2之间的天数
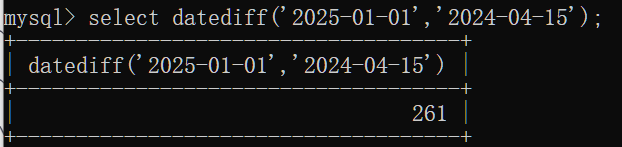
流程函数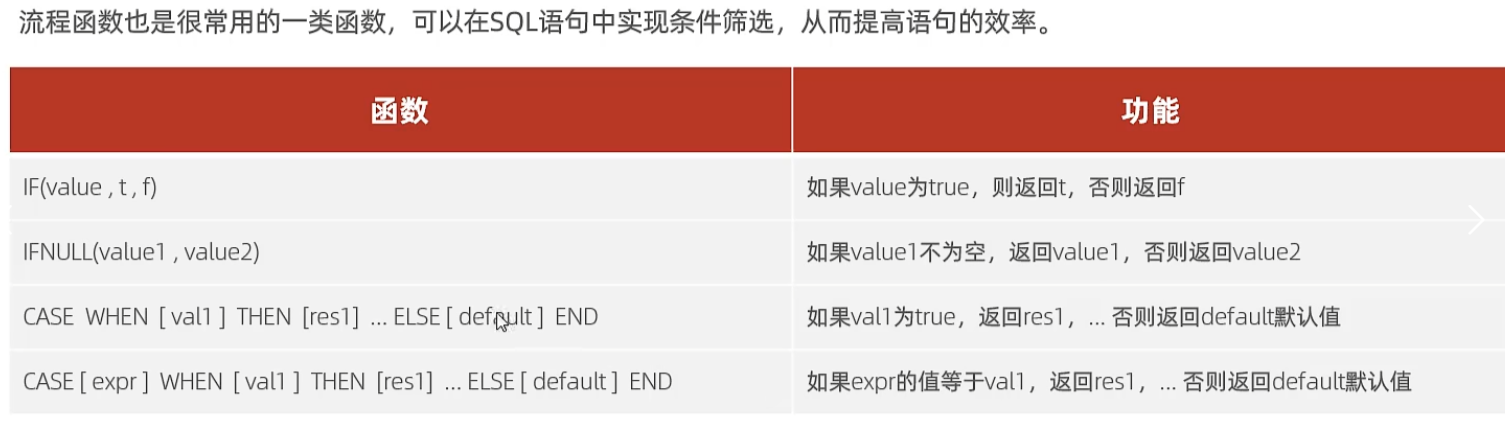
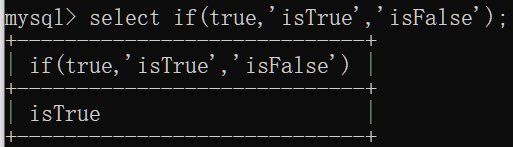
if(value,t,f):如果value为true,返回t,否则返回f
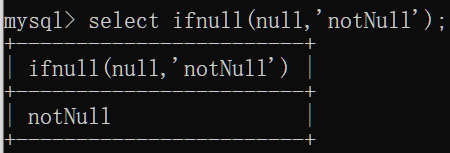
ifnull(value1,value2):如果value1不为空,返回value1,否则返回value2
小结
7、约束

演示
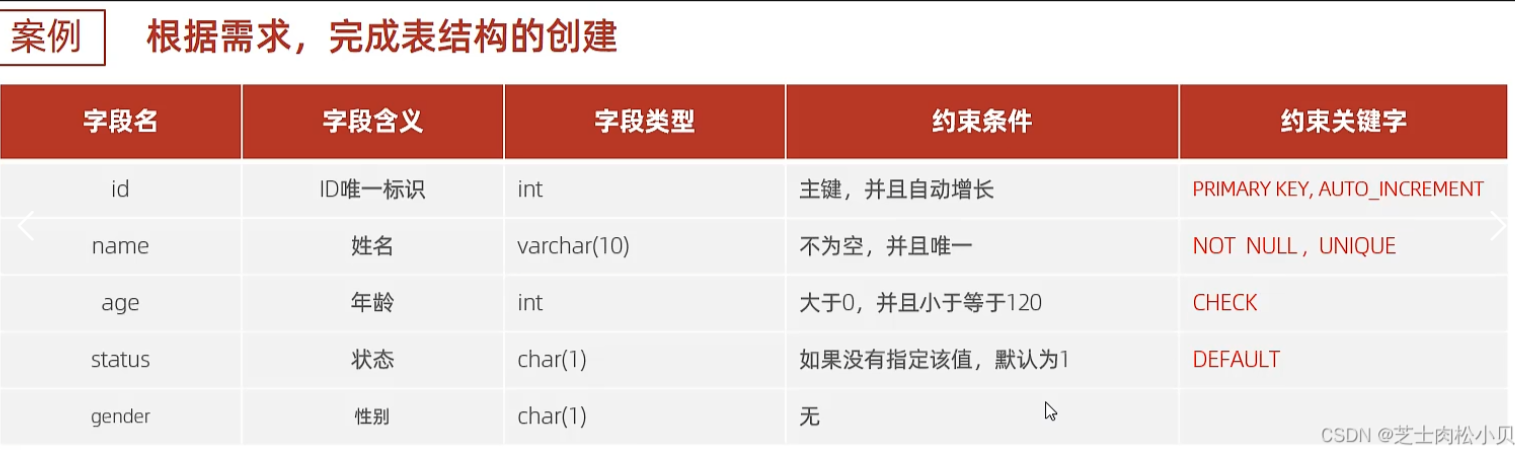
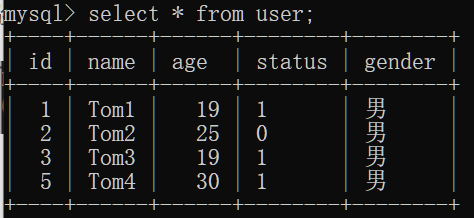
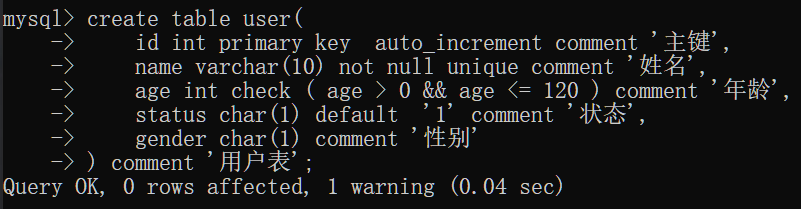 验证name不能为空
验证name不能为空

验证name唯一

验证age合法

验证status

外键约束
用来让两张表的数据之间建立连接,从而保证数据的一致性和完整性

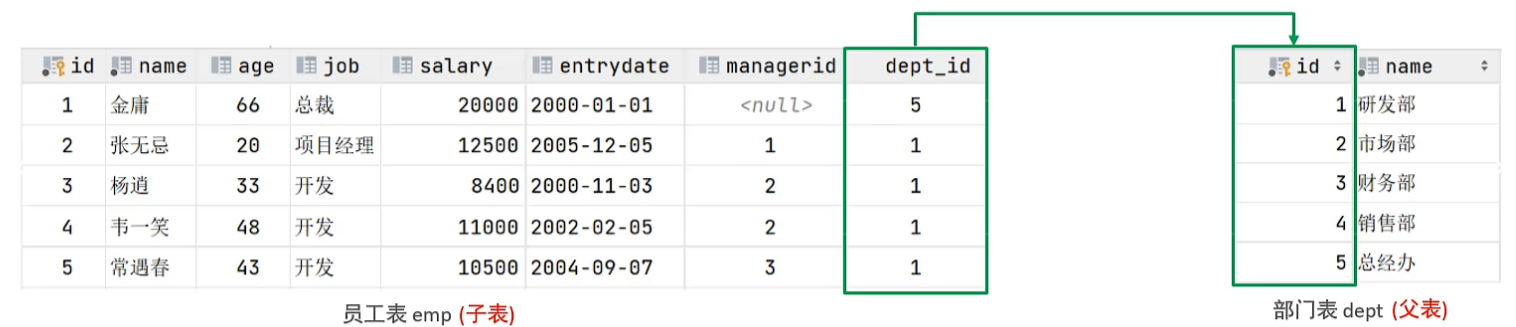
-- 添加外键
alter table 表_name add constraint fk_表_name_status foreign key (status) references user(id);
-- 删除外键
alter table 表_name drop foreign key fk_表_name_status;
-- 删除更新行为
alter table 表_name add constraint fk_表_name_status foreign key (status) references user(id) on update cascade on delete cascade ;
alter table 表_name add constraint fk_表_name_status foreign key (status) references user(id) on update set null on delete set null ;小结

8、多表查询
多表关系
一对一
 一对多
一对多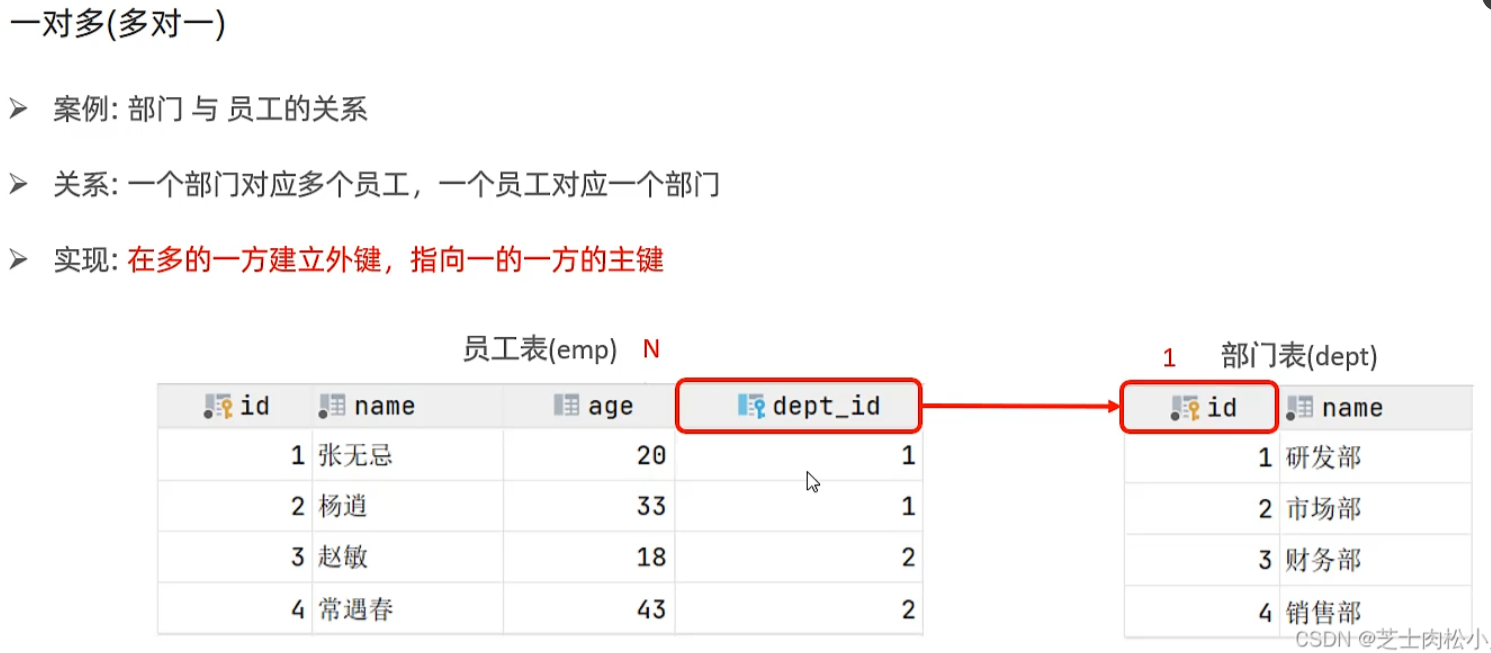
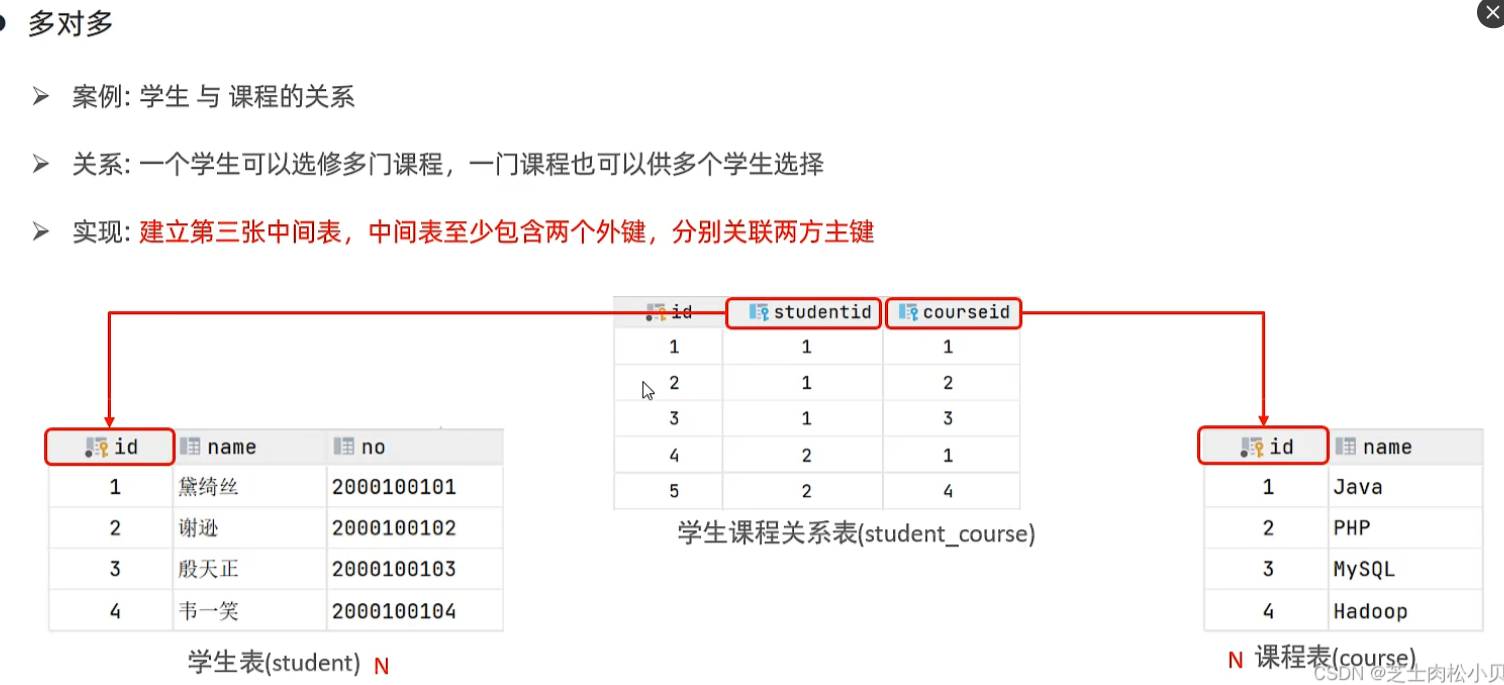
多对多
概述
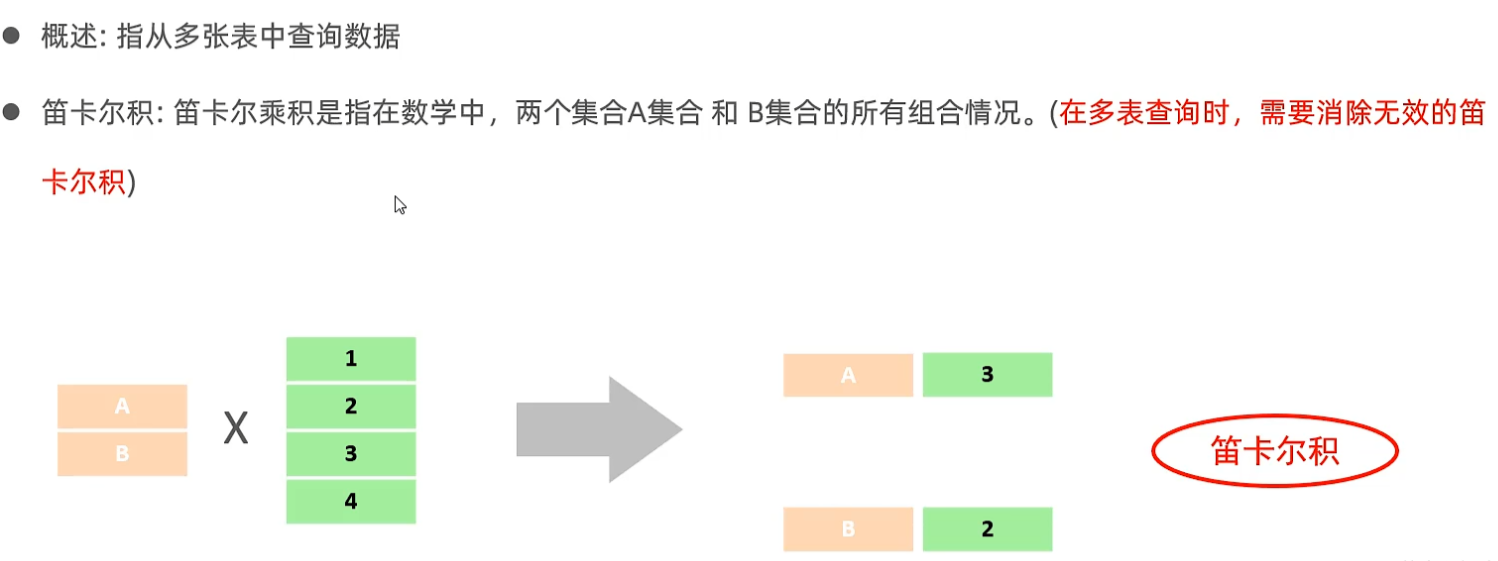
注:要消除笛卡尔积,只需要在查询语句的后面加一个where条件即可。
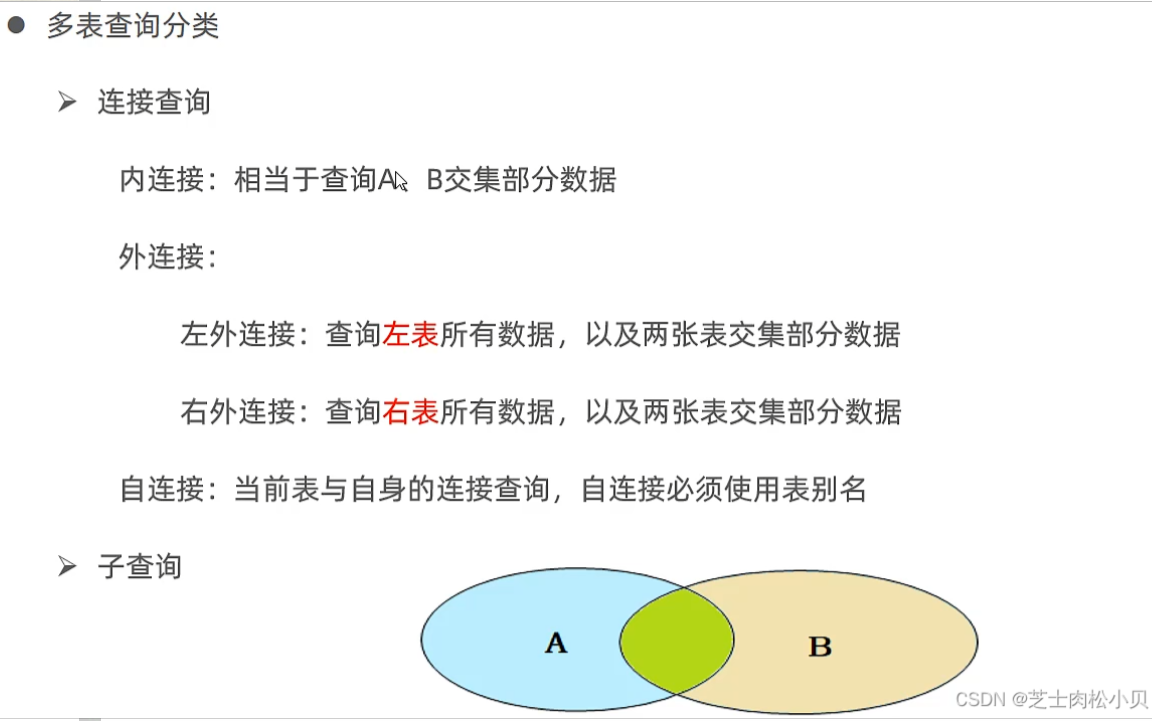
内连接

# 注意,一定得是连接的另一个表的主键才可以
alter table emp add constraint fk foreign key (dep_id) references dep(id) on update cascade on delete cascade ;-- 内连接
-- 1、查询每一个员工的姓名,及关联的部门的名称(隐式内连接实现)
-- 表结构:emp, dep
-- 连接条件:emp.dep_id = dep.id
select emp.name, dep.dep from emp, dep where emp.dep_id = dep.id;# 一旦对表起了别名,就不能再通过表明来限定字段
select e.name,d.dep from emp e, dep d where e.id = d.id ;-- 2、查询每一个员工的姓名,及关联的部门的名称(显示内连接实现) ---INNER JOIN ... ON ...
-- 表结构:emp, dep
-- 连接条件:emp.dep_id = dep.id
select e.name, d.dep from emp e inner join dep d on e.dep_id = d.id;select e.name, d.dep from emp e join dep d on e.dep_id = d.id;外连接
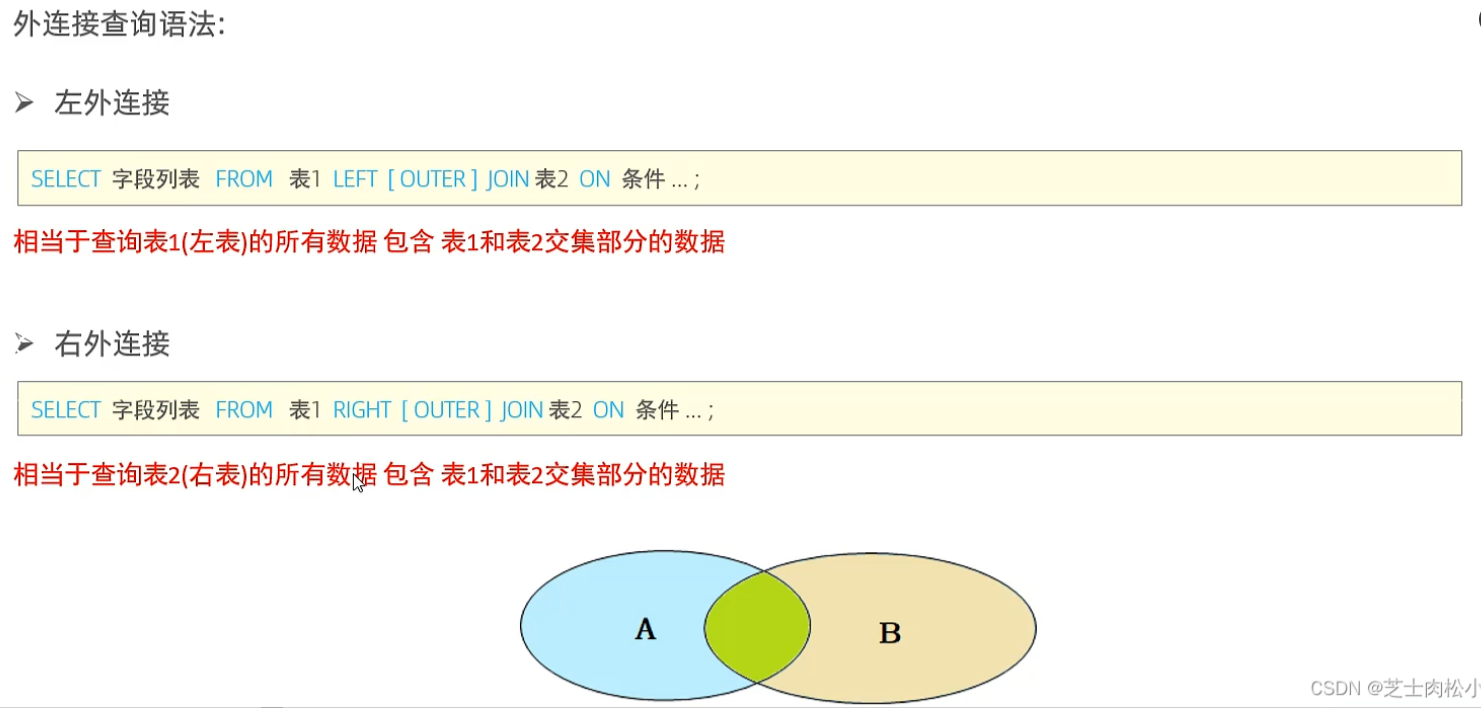
-- 外连接
-- 1、查询emp表所有的数据,和对应的部门信息(左外连接)
-- 表结构:emp, dep
-- 连接条件:emp.dep_id = dep.id
select e.*, d.dep from emp e left join dep d on d.id = e.dep_id;-- 2、 查询dep表所有的数据,和对应的员工信息(右外连接)
select e.*, d.* from emp e right join dep d on d.id = e.dep_id;注:实际开发中,左外用得更多,因为右外可以改为左外。
自连接

-- 自连接
-- 1、查询员工及其所属工作地址
-- 表结构: emp
select a.name, b.name from emp a, emp b where a.manageid = b.id;-- 2、查询所有员工 emp 及其 领导的 名字,如果员工没有领导,也要查询出来
select a.name '员工', b.name '领导' from emp a left join emp b on a.manageid = b.id;联合查询- union, union all
对于 union 查询,就是把多次查询的结果合并起来,形成一个新的查询结果集。
-- union all ,union
-- 1、将地址在北京的, 和年龄大于 20 岁的员工全部查询
select * from emp where workaddress = '北京'
# union all # 查询结果直接合并
union #查询结果合并并去重
select * from emp where age > 20;# 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致子查询

标量子查询

列子查询
-- 列子查询
-- 1、 查询“销售部” 和“研发部” 的所有员工信息
select * from emp where dep_id in (select id from dep where dep = '销售部' or dep = '研发部');-- 2、 查询比销售部所有人工资都高的员工信息
select * from emp where salary > all((select salary from emp where dep_id = (select id from dep where dep = '销售部')));
# all 返回回来的结构都需要满足-- 3、查询比研发部其中任意一人工资高的员工信息
select * from emp where salary > any (select salary from emp where dep_id = (select id from dep where dep = '研发部'));
# any = some行子查询

-- 行子查询 一行多列
-- 1、查询与“刘艳”的薪资及直属领导相同的员工信息
select * from emp where (salary,manageid) = (select salary,manageid from emp where name = '刘艳');表子查询

注:表子查询通常在 from 之后。
-- 表子查询
-- 1、 查询与“李四”,“杨工”的工作地点和薪资相同的员工信息
select * from emp where (workaddress,salary) in (select workaddress,salary from emp where name = '李四' or name = '杨工');-- 2、 查询入职日期是 “2002-01-01” 之后的员工信息,及其部门信息
select e.*, d.dep from (select * from emp where entrydate > '2002-01-01') e left join dep d on e.dep_id = d.id;小结

9、事务
简介
一组操作的集合,它是不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySQL会立即隐式的提交事务。
操作演示
-- 数据准备
create table account(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',monney int comment '余额'
) comment '账户表';insert into account (id, name, monney)
values (null,'张三',2000),(null,'李四',2000);-- 恢复数据
update account set monney = 2000 where name = '张三' or name = '李四';-- 张三给李四转账1000
select * from account where name = '张三';
update account set monney = monney - 1000 where name = '张三';
程序抛出异常...
update account set monney = monney + 1000 where name = '李四';扣除张三余额之后sql异常,李四的余额没有添加成功,会导致数据缺失。
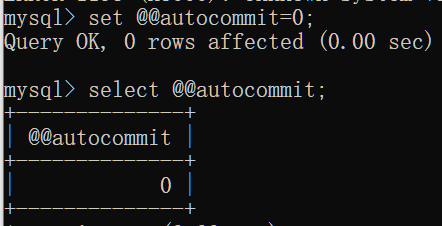
事务操作:解决一: @@autocommit = 0 为手动提交:
MySQL事务默认自动提交
设置为手动提交事务
事务操作: 解决二:
提交事务
-- 张三给李四转账1000
start transaction ;
select * from account where name = '张三';
update account set monney = monney - 1000 where name = '张三';
update account set monney = monney + 1000 where name = '李四';
commit ;回滚事务,回滚后原数据不会被修改。
-- 张三给李四转账1000
start transaction ;
select * from account where name = '张三';
update account set monney = monney - 1000 where name = '张三';
error
update account set monney = monney + 1000 where name = '李四'
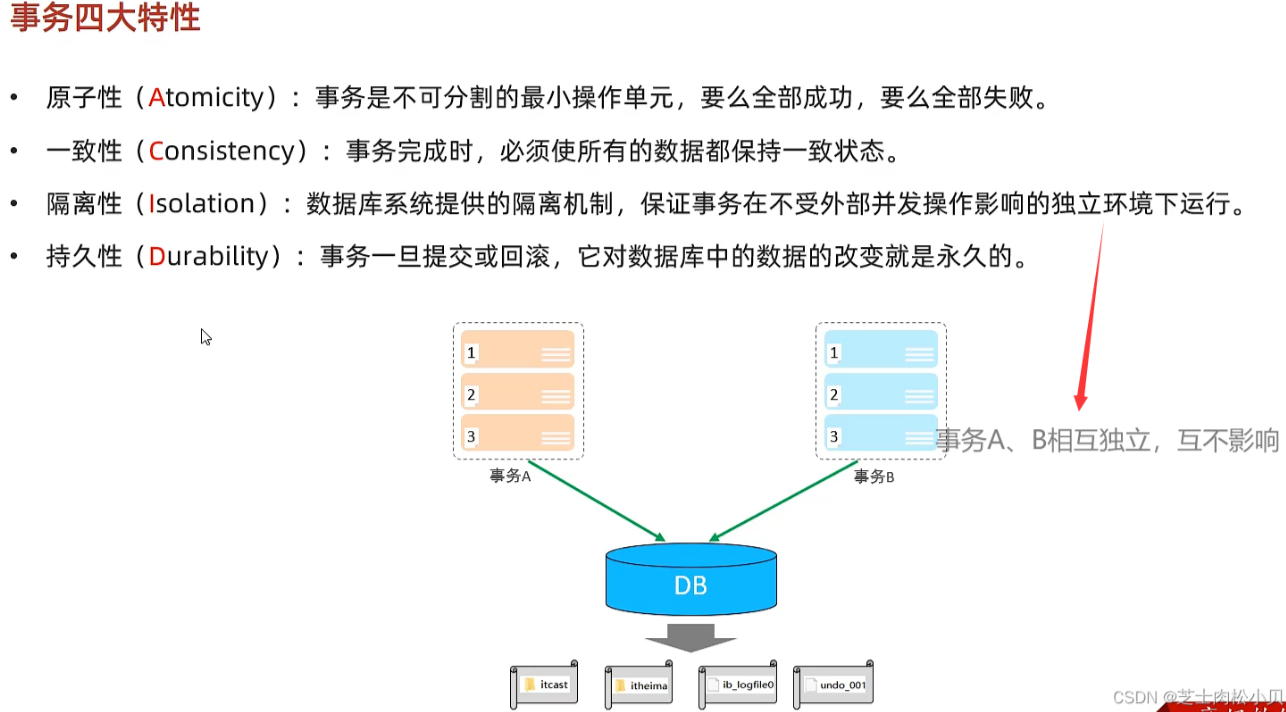
rollback ;四大特性ACID
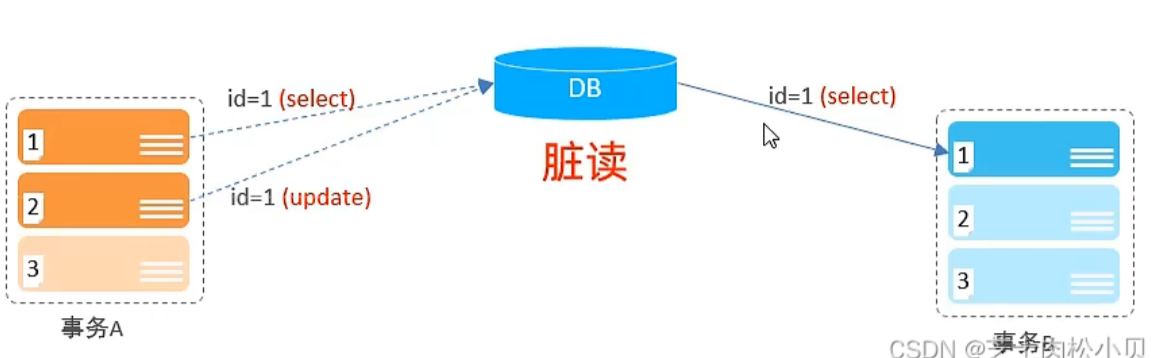
并发事务问题

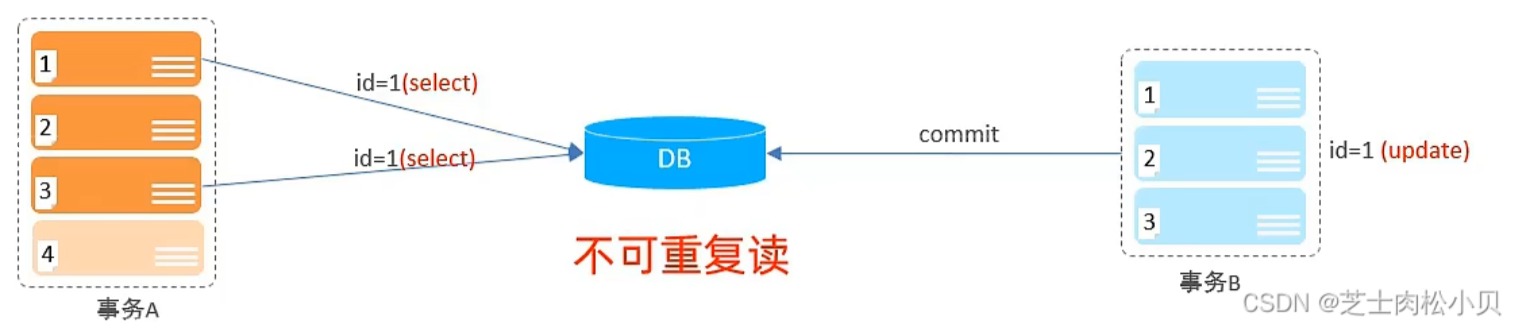
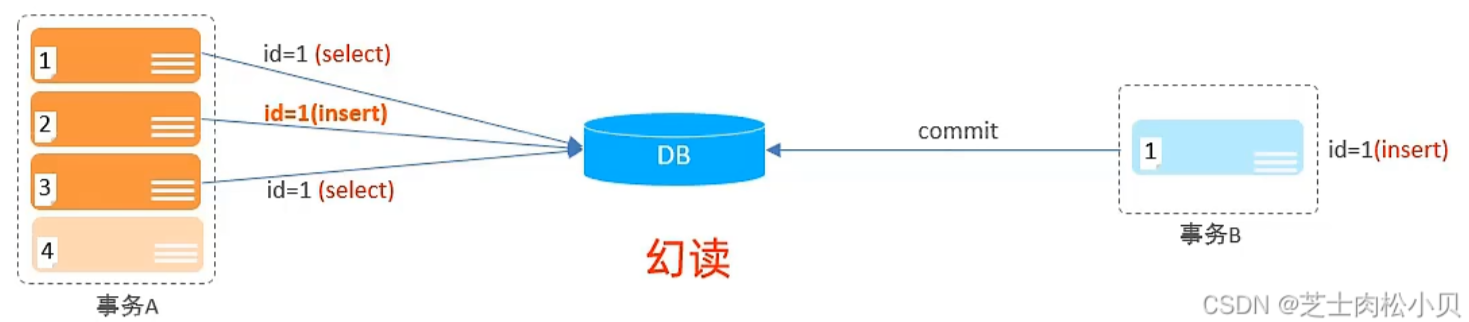
事务隔离级别
为解决并发事务问题,设置来了事务隔离级别,下表中从上到下隔离级别越来越高,但是性能越来越差,实际开发中,二者加以权衡使用。
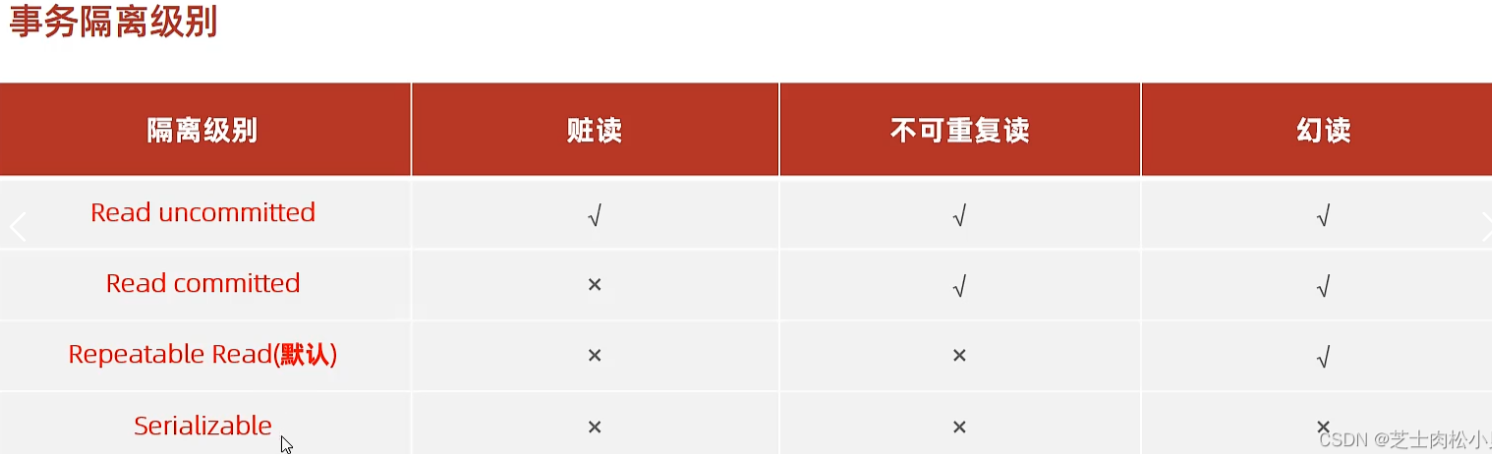

默认隔离级别为可重复读
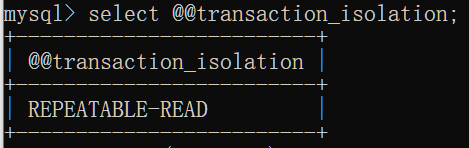
注:事务隔离级别越高,数据越安全,但是性能越低 。
小结
学完这里MySQL就入门了
至此鸣谢:黑马MySQL基础篇笔记整理——超详细_黑马mysql笔记-CSDN博客