GaussDB 数据库架构师修炼(十八) SQL引擎-统计信息
1 什么是GaussDB统计信息
统计信息描述了用户表中数据的分布特征为行数估算,代价估算提供数据基础。
2 表统计信息分级
1)表级别统计信息
reltuples总元组数:描述表对应的元组数
relpages总页面数:描述表对应的磁盘页数
relallvisible可见页的数量:被标识为全可见 的页数
- 2)列级别统计信息
Distinct值:用于描述字段里唯一的非NULL数据值的数目,一般用于估算集合分组之后的大小,join结果集大小
NULLFrac:用于描述当前列中 NULL值在总数中的占比
MCV( most common value):描述出现频率大于一定百分比的值的集合,表征高频值
Histogram直方图:描述除了NULL值, MCV 值以外的值的分布情况,GaussDB使用的是等高直方图,一般用于估算选择率
3)扩展统计信息
Multi-Column Statistics 多列统计信息
View-Statistics 视图统计信息
举证:
假设有t1.c1数据(表A ),有统计信息如(表 B,表C) 表B:表级别统计信息
表B:表级别统计信息
| 类型 | 数值 | 说明 |
| reltuples行数 | 150000 | 当前表中共计15W条元组 |
| relpages页面数 | 200 | 总共有200个数据页面 |
表C:列级别统计信息
| 类型 | 数值 | 说明 |
| NULL值比例 | 0 | 示例中没有NULL值,因此NULL值的比例为0 |
| DISTINCT唯一值数量 | 11 | 示例中的0有重复值,去掉重复之后还有11个数字, 因此DISTINCT值的数量为11 |
| MCV高频值 | [0],[0.33] | 示例中出现频率最高的值是0,出现了5次,因此MCV值是0,MCV由两个等长数组表示。其一是实际数值,其二是对应的频率 |
| 直方图 | [1, 5, 100] | 直方图首先排除MCV值,所以这里没有0。每个区间包含的元素个数相同, 1至5(含) 之间共有5个数, 5 (不含)至100之间共5个数。 |
3 多列统计信息
当谓词条件或者连接条件选取多个列进行过滤或者连接时,多列之间相关性较大,则不能使用独 立性假设去计算选择率。这里就需要收集多列统计信息。

4 行数估算
有了丰富的统计信息,优化器能够较为准确估算出表的基数和join中间结果集的大小,为代价估算做准备,从而选择更优的执行路径。
估算逻辑
在实际做基数估计时,会有一些基本假设:
除了高频值mcv值外,其余值为均匀分布
数据遵从主外键约束, join尽可能match
单表行数:
NULL值比例, MCV高频值,直方图
join行数:
表行数, distinct值
5 行数估算-谓词选择率
等值谓词选择率估算方式如下:
对于接收到的常量等值谓词查询,分为4种情况计算选择率:
1) 常量为NULL,直接使用 NULL值比例
2)常量落在MCV中,直接使用对应值频率
3) 常量落在直方图中,需要通过公式进行计算:
记NULL值比例为pn,
记MCV频率总和为pm ,
记distinct值为Nd,
直方图中每两个数之间为一个桶,桶的Ns则平均每个桶distinct值
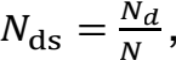 ,
,
则有选择率:
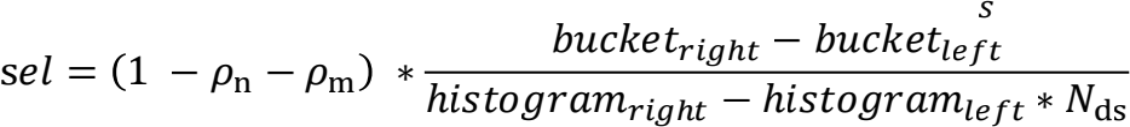
若桶的左右边界相等,记Neq表示和左右边界等值的桶的数量,则有
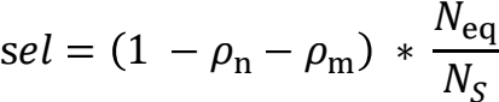
4)非以上情况则认为选择率为1/总数:
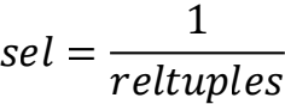
6 谓词选择率计算举证
select * from pg_stats where tablename='t1' and attname=Ia’;
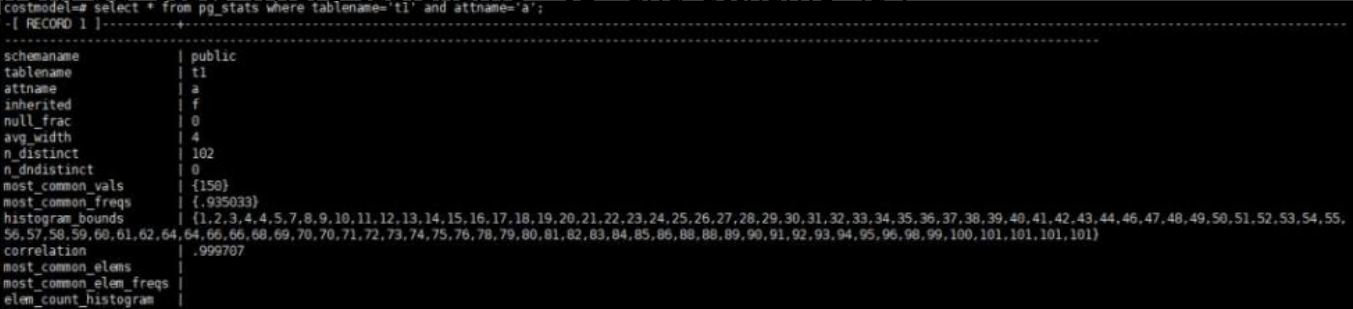
1)Null_frac为0,该表没有NULL值
2)mcv选择率:可以看到该表有一个mcv值为150,频率为0.935033,则sela = 150 = 0.93503
3)不等边界桶:参考公式有
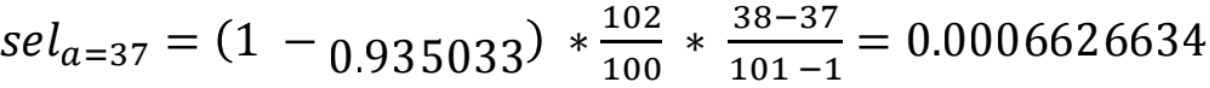
4)低频值:首先获取表总行数

则有
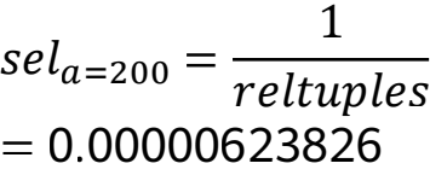
7 行数估算-连接估算
两表join的行数估计主要通过基表的行数和 两表的distinct值来实现。
记n1和n2是两张表的行数, d1和d2是两张表 的join列的distinct值, RPV1和RPV2是两列 中,每个值有多少行,则有join结果行数:
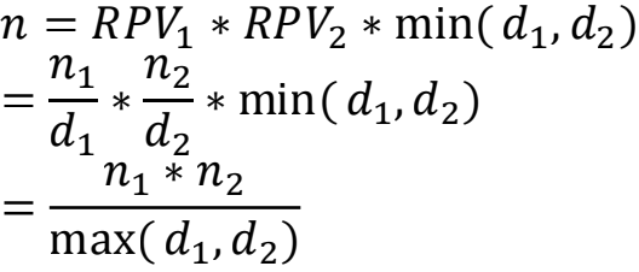
举证:
有两张表的统计信息如下:
表1:总行数

表1:n_distinct值

表2:总行数

表2:n_distinct值

则有d1 = 0.2 * 10000 = 2000, d2 = 0.25 * 12000 = 3000,估算结果集为:
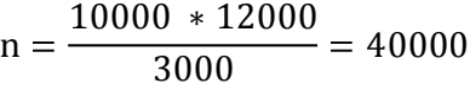
执行计划中行数:

8 自动收集统计信息
GaussDB 提供自动收集统计信息的功能,通过autovacuum相关参数控制,如果表中数据量发生较大变化达到阈值时,会触发自动收集统 计信息。
- 对于空表而言,当表中插入数据的行数大于50时,会触发表自动进行analyze 。
- 对于表中已有数据的情况,触发自动收集的阈值设定公式计算如下:autovacuum_analyze_threshold+autovacuum_analyze_scale_factor * reltuples
其中reltuples是表的总行数;
autovacuum_analyze_threshold是触发自动收集的最小阈值,默认值为50;autovacuum_analyze_scale_factor是触发自动收集时表的规模因子,默认为10%