LangChain RAG系统开发基础学习之文档切分
文章目录
- 说明
- 一 Naive RAG 基础架构
- 二 LangChain RAG API
- 2.1 基础环境准备
- 2.2 接入基础大模型
- 三 Source 与 data loaders
- 3.1 在线文档加载流程
- 3.2 txt文档加载器
- 3.3 文档加载器实现逻辑
- 3.4 加载JSON数据格式
- 3.5 自定义JSON文档加载器
- 3.6 PDF文档加载器
- 3.6.1 普通PDF文档加载
- 3.6.2 LangChain PDF文件加载
- 四 RAG系统的文档切分策略
- 4.1 根据句子切分
- 4.2 根据固定字符数切分
- 4.3 按固定字符数来切分+结合重叠窗口
- 4.4 递归方法
- 4.4.1 LangChain中的Text Splitters工具调用
- 4.4.2 CharacterTextSplitter
- 4.4.3 RecursiveCharacterTextSplitter
- 4.4.4 MarkdownTextSplitter
- 4.5 根据语义切割
- 4.6 总结
说明
- 本文学自赋范课堂九天老师公开课,仅用于学习和技术交流使用,不用作任何商业用途,最终著作权归九天老师及其团队所有!
一 Naive RAG 基础架构
- RAG:从知识库中检索出最相关的信息,并将其作为上下文输入到Prompt中,从而提高大模型回答的准确性和相关性。
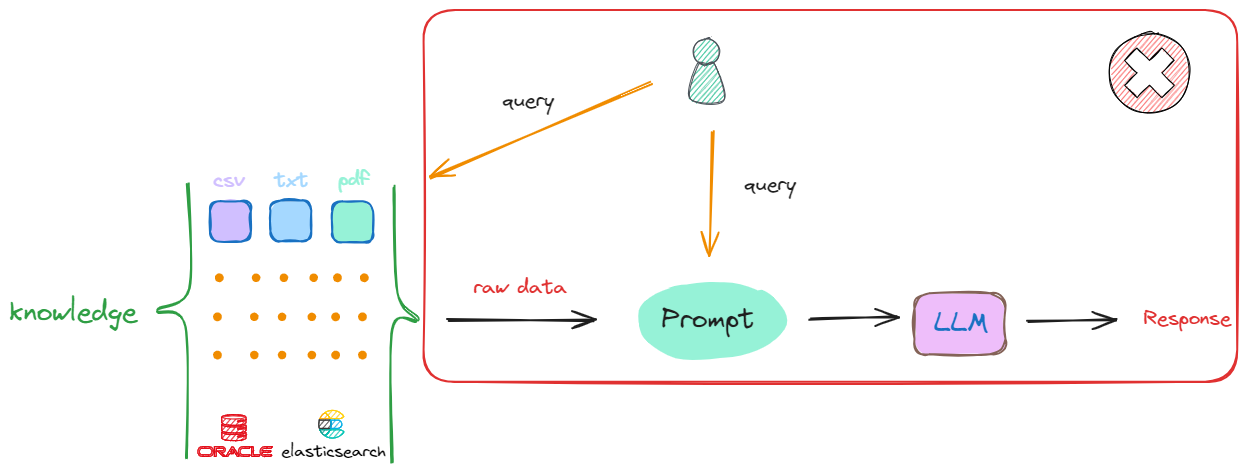
- 把存放着原始数据的知识库(
Knowledge)中的每一个raw data,切分成一个一个的小块。小块可以是一个段落,也可以是数据库中某个索引对应的值。这个切分过程被称为“分块”(chunking),流程如下:
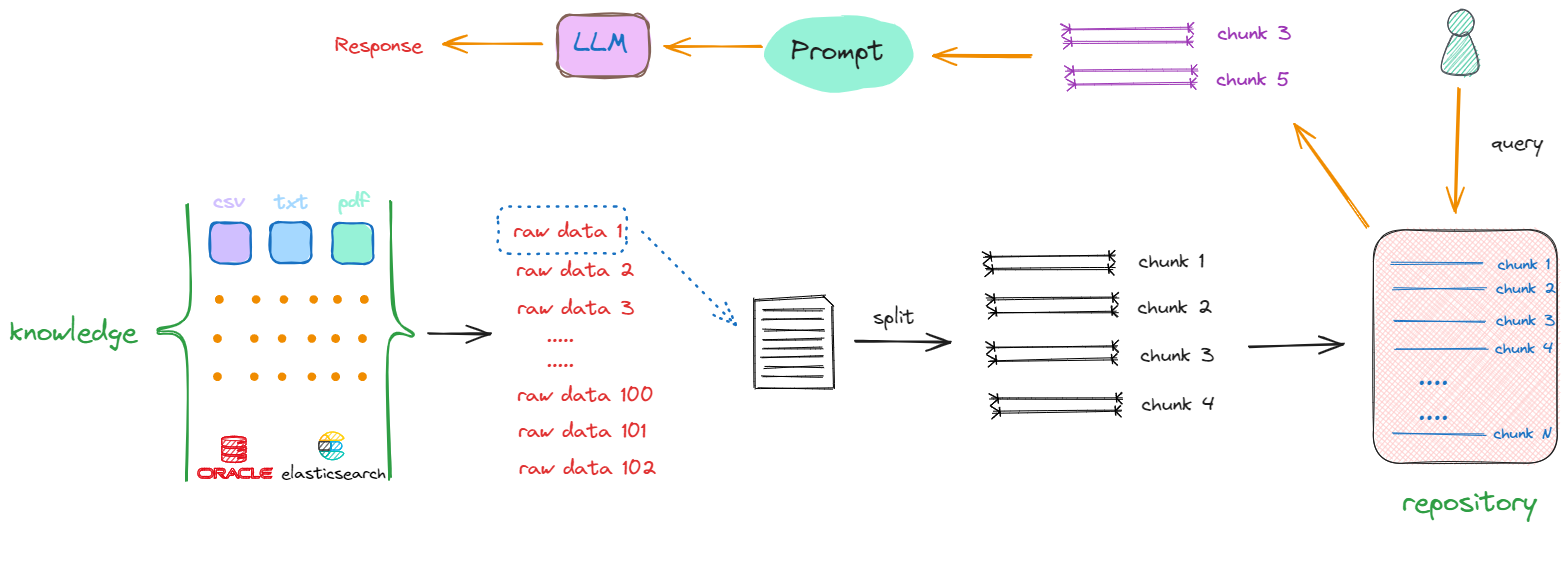
- 全流程如下:
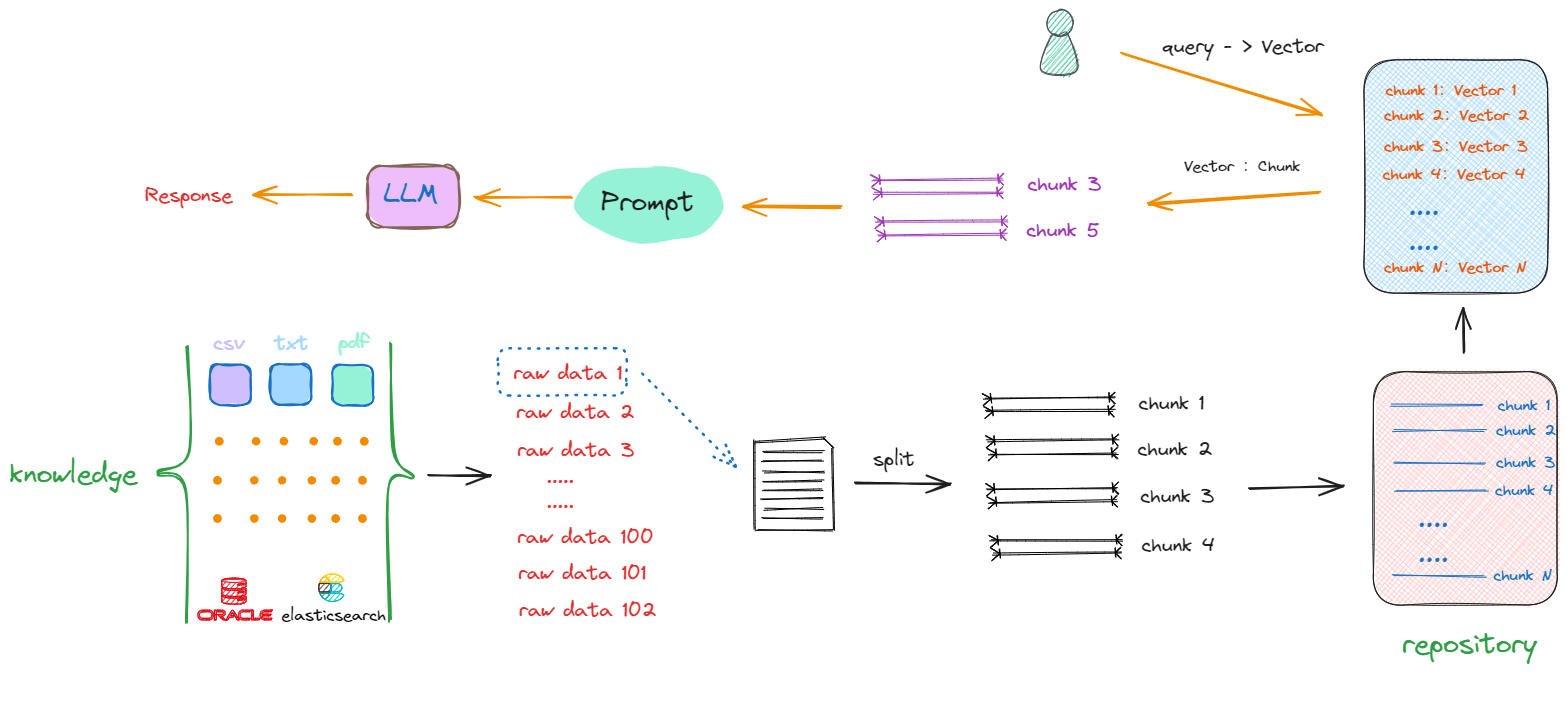
- 一个基础的RAG架构会只要包含以下几方面的开发工作:
- 如何将原始数据转化成
chunks; - 如何将
chunks转化成Vector; - 如何选择计算向量相似度的算法;
- 如何利用向量数据库提升搜索效率;
- 如何把找到的
chunks与原始query拼接在一起,产生最终的Prompt;
- 如何将原始数据转化成
二 LangChain RAG API
- 在
LangChain框架中,RAG作为一个模块独立存在,langchain rag说明文档
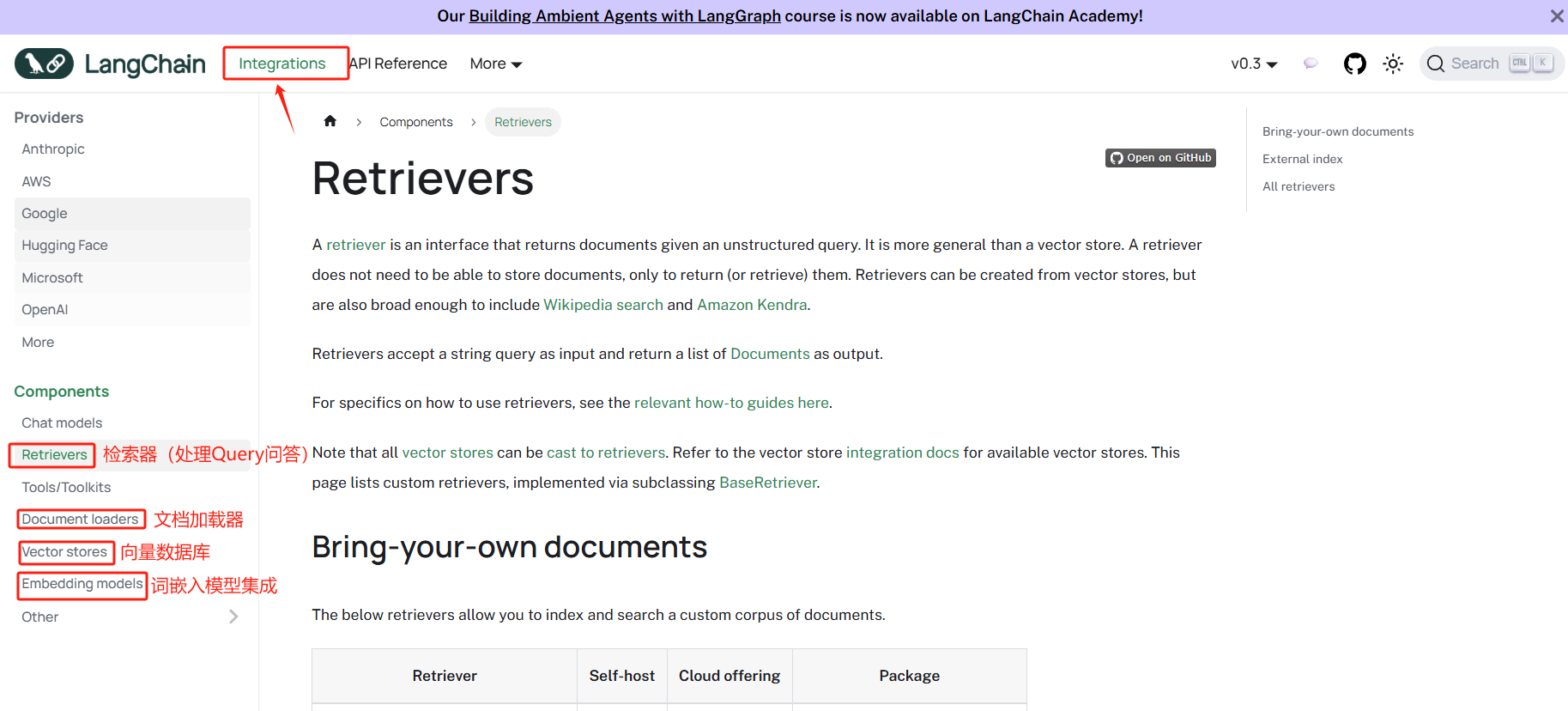
- langchain为rag的每个子流程都提供了通用的实现方法,可以将不同来源、形式的数据切分为小块,使用Embeddding模型进行向量化,将向量存储进向量数据库,提供快速检索的优化算法。每个环节的基础技术,都作为一个独立抽象模块存在,最终将各个环节像链条一样串联起来进行数据交互,形成完整的rag系统。
LangChain抽象的data connection数据处理流,如下:
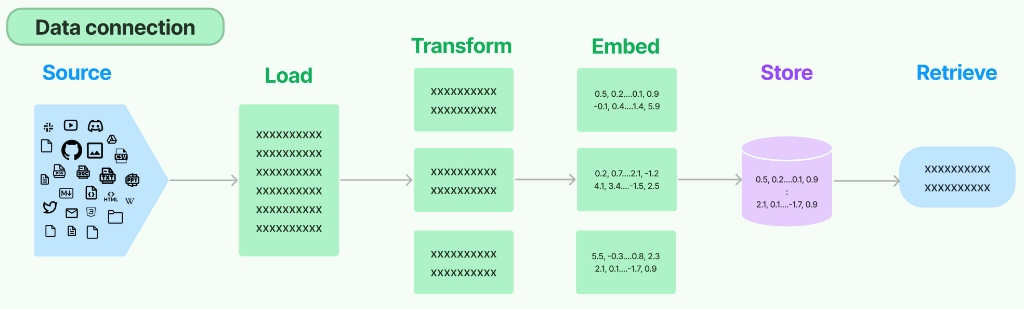
data connecting是Langchain框架原生的数据处理流,RAG是涉及多个处理环节的一个架构,它不是个体,而是一个整体,所以虽然不同环节、不同模块间所做的事情是不一样的,但它们之间是需要链接的,需要进行数据的交换,那这一部分工作,就是交给data connection来统一管理。例如,在上述流程中,"Source"阶段指的是附加的数据库,它能够整合来自不同数据源的信息。通过"Load"组件,这些数据可以被统一管理。"Transform"组件则负责进行数据切分等一系列前文提到的构建RAG所需的开发任务,提供了各种不同的解决方案。
2.1 基础环境准备
pip install langchain langchain-deepseek langchain-openai
pip show langchain langchain-deepseek langchain-openai
Name: langchain
Version: 0.3.27
Summary: Building applications with LLMs through composability
Home-page:
Author:
Author-email:
License: MIT
Requires: langchain-core, langchain-text-splitters, langsmith, pydantic, PyYAML, requests, SQLAlchemy
Required-by: jupyter_ai_magics, langchain-community
---
Name: langchain-deepseek
Version: 0.1.4
Summary: An integration package connecting DeepSeek and LangChain
Home-page:
Author:
Author-email:
License: MIT
Requires: langchain-core, langchain-openai
Required-by:
---
Name: langchain-openai
Version: 0.3.31
Summary: An integration package connecting OpenAI and LangChain
Home-page:
Author:
Author-email:
License: MIT
Requires: langchain-core, openai, tiktoken
Required-by: langchain-deepseek
2.2 接入基础大模型
from langchain_openai import ChatOpenAImodel = ChatOpenAI(model="gpt-5-mini",base_url="https://api.openai-hk.com/v1",api_key="hk-xxx"
)question = "你好,请你介绍一下你自己。"
result = model.invoke(question)
print(result.content)
你好!我是 ChatGPT,一个由 OpenAI 训练的大型语言模型,基于 GPT-4 架构。我的知识截至 2024-06(当前日期:2025-08-24),可以用中文或多种语言交流。我能做的事(示例):
- 回答问题、解释概念、做知识梳理与总结;
- 帮写或润色文章、邮件、报告、演讲稿;
- 帮你编程、调试、写代码片段与注释(多种编程语言);
- 翻译、改写、生成创意文案、写诗与故事;
- 制定学习计划、旅行行程、项目计划和步骤分解;
- 数据分析思路、表格处理建议(但不能直接访问你的文件或网络资源,除非你粘贴内容)。我有的限制:
- 无法实时上网抓取最新数据或个人隐私信息(除非你提供相关内容);
- 可能会不准确或生成错误信息,涉及重要决策(法律、医疗、财务等)请咨询专业人士并核实;
- 不会记住你在会话外的个人信息(单次会话内可以保持上下文)。如何获得更好结果(小建议):
- 给出具体背景和目标;
- 提供示例或你已有内容(如要润色、改写时);
- 如果需要代码或步骤,说明运行环境或约束条件。你现在想让我帮你做什么?
from langchain_deepseek import ChatDeepSeek
model = ChatDeepSeek(model="deepseek-chat",api_key="sk-xxx"
)
question = "你好,请你介绍一下你自己。"result = model.invoke(question)
print(result.content)
你好!我是 **DeepSeek-V3**,由 **深度求索(DeepSeek)** 公司开发的智能 AI 助手。我擅长理解和处理自然语言,能够帮助你解答各种问题、提供信息、协助写作、分析数据,甚至进行代码编写和调试。 ### 我的特点:
1. **知识丰富** 📚:我的知识截止到 **2024 年 7 月**,可以为你提供广泛的专业知识和最新信息。
2. **超长上下文支持** 🧠:支持 **128K** 上下文长度,可以更好地理解复杂问题,并保持对话的连贯性。
3. **免费可用** 💡:目前无需付费,你可以随时向我提问,我会尽力帮助你!
4. **多文档解析** 📂:支持上传 **PDF、Word、Excel、PPT、TXT** 等文件,并能帮助提取和分析文本内容。
5. **多语言支持** 🌍:可以用 **中文、英文** 等多种语言交流,方便不同用户使用。无论是学习、工作,还是日常生活遇到难题,你都可以来找我聊聊!😊 有什么我可以帮你的吗?
三 Source 与 data loaders
-
Source概念指的是RAG架构中所外挂的知识库。在实际场景中,私有数据通常具有多种不同的形式,可以是上百个.csv文件,可以是上千个.json文件,也可以是上万个.pdf文件。如果对接到具体的业务,可以是某一个业务流程外放的API,可以是某个网站的实时数据等多种情况。所以LangChain首先做的就是:将常见的数据格式和数据来源使用LangChain的规范,抽象出一个一个的单独的集成模块,称为文档加载器(Document loaders),用于快速加载某种形式下的文本数据。
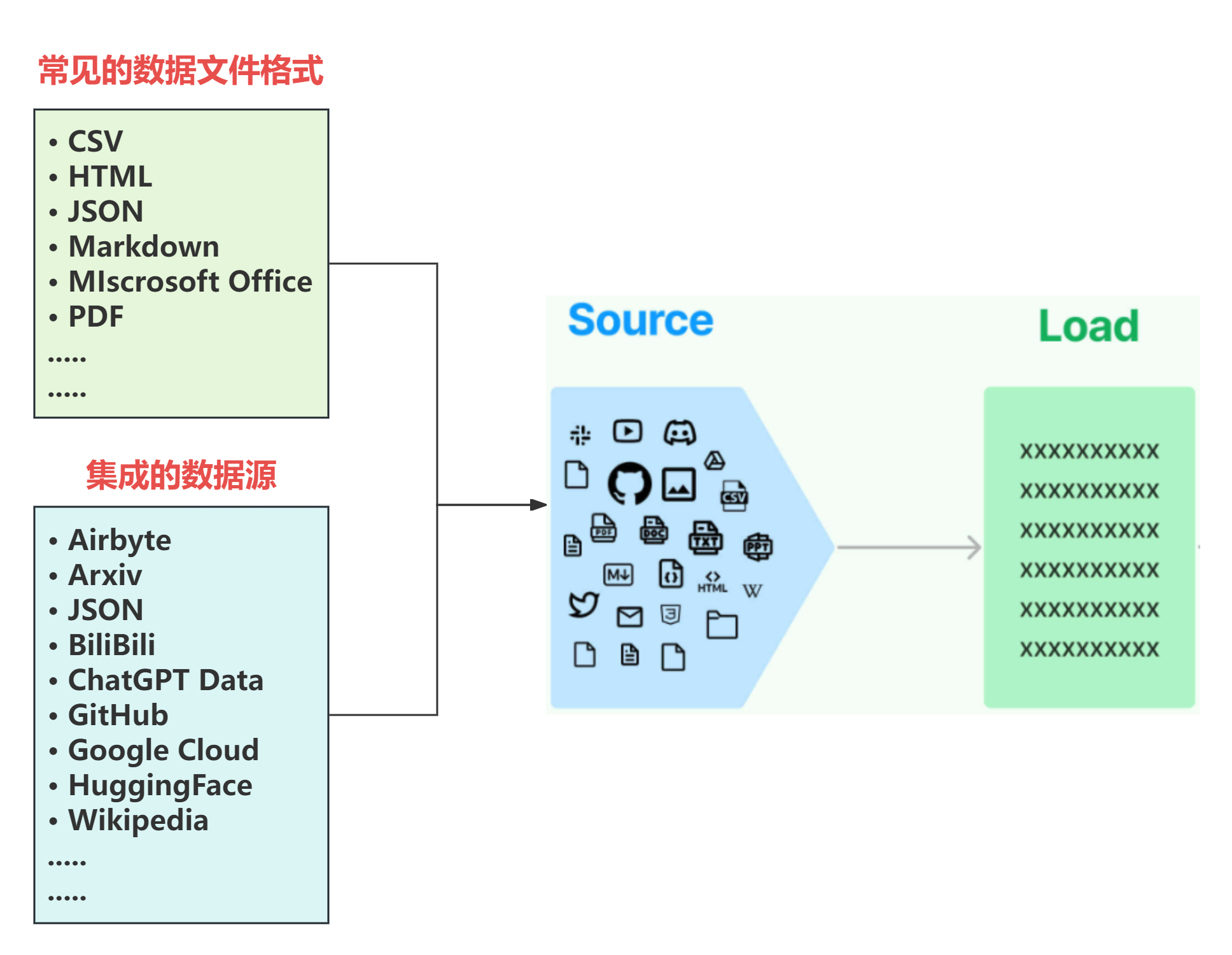
-
通过调用
LangChain抽象的方法直接处理私有数据,无需手动编写中间的处理流程,并且每一种文档的加载器,在LangChain官方文档中都有基本的调用示例,具体位置。 -
不同类型的文档加载器经过
langChain的高度封装后,可以直接调用load_documents方法,传入文件路径,就可以加载出对应的文档。 -
在LangChain技术生态中,文档加载(Document Loaders)**是支撑检索增强生成(RAG)流程的核心组件之一。LangChain已原生集成了丰富的加载器模块,覆盖**本地文件、在线网页、数据库、云存储、第三方应用及多媒体资源等多样化数据来源,极大降低了异构知识接入的开发成本。
-
加载器可分为七大类:本地文件加载、网页抓取、API集成、数据库连接、云端存储、特定格式解析以及自定义扩展。每类加载器均封装了数据读取、文档分块、元数据生成等常用操作,开发者只需在配置中指定路径或凭据,即可将不同来源的内容标准化为LangChain可处理的Document对象,为后续Embedding、检索和问答链条提供高质量的输入。
-
下表列举LangChain已集成的部分典型加载器,按类别分类展示(并非穷尽所有):
| 分类 | 加载器名称(部分示例) |
|---|---|
| 本地文件加载器 | TextLoader, CSVLoader, PDFLoader, UnstructuredLoader, JSONLoader, Docx2txtLoader |
| 网页加载器 | WebBaseLoader, SitemapLoader, TrafilaturaLoader, RecursiveUrlLoader |
| API/第三方数据加载器 | NotionDBLoader, SlackLoader, ConfluenceLoader, GitHubIssuesLoader, GoogleDriveLoader |
| 数据库加载器 | SQLDatabaseLoader, PandasDataFrameLoader, FAISSLoader, MilvusLoader |
| 云存储加载器 | S3DirectoryLoader, GCSDirectoryLoader, AzureBlobStorageLoader |
| 多媒体/特定格式加载器 | YouTubeLoader, AudioLoader, EPubLoader, EverNoteLoader |
| 自定义/通用加载器 | DirectoryLoader, BSHTMLLoader, iFixitLoader |
3.1 在线文档加载流程
Wikipedia是一个多语言免费在线百科全书,当LangChain集成后,就可以按照文档说明直接调用。https://python.langchain.com/docs/integrations/document_loaders/wikipedia/
pip install -U langchain_community wikipedia
- 构造方法支持自定义的参数
- query :用于在维基百科中查找文档的自由文本。
- 可选 lang :默认=“en”。用它来搜索维基百科的特定语言部分。
- 可选 load_max_docs :默认=100。用它来限制下载文档的数量。下载所有 100 个文档需要时间,因此请使用少量进行实验。目前硬性限制为 300。
- 可选 load_all_available_meta :默认=False。
- 默认情况下,仅下载最重要的字段: Published (文档发布/上次更新的日期)、 title 、 Summary 。如果为 True,则还会下载其他字段。
from langchain_community.document_loaders import WikipediaLoader
docs = WikipediaLoader(query="LangChain", lang="zh",load_max_docs=2).load()
print(len(docs))
print(docs[0].metadata)
print(docs[0].metadata["summary"])
2
{'title': 'LangChain', 'summary': 'LangChain 是一个应用框架,旨在简化使用大型语言模型的应用程序。作为一个语言模型集成框架,LangChain 的用例与一般语言模型的用例有很大的重叠。 重叠范围包括文档分析和总结摘要, 代码分析和聊天机器人。 \nLangChain提供了一个标准接口,用于将不同的语言模型(LLM)连接在一起,以及与其他工具和数据源的集成。LangChain还为常见应用程序提供端到端链,如聊天机器人、文档分析和代码生成。 LangChain是由Harrison Chase于2022年10月推出的开源软件项目。它已成为LLM开发中最受欢迎的框架之一。LangChain支持Python和JavaScript语言,并与各种LLM一起使用,如GPT-4、BERT和T5。', 'source': 'https://zh.wikipedia.org/wiki/LangChain'}
LangChain 是一个应用框架,旨在简化使用大型语言模型的应用程序。作为一个语言模型集成框架,LangChain 的用例与一般语言模型的用例有很大的重叠。 重叠范围包括文档分析和总结摘要, 代码分析和聊天机器人。
LangChain提供了一个标准接口,用于将不同的语言模型(LLM)连接在一起,以及与其他工具和数据源的集成。LangChain还为常见应用程序提供端到端链,如聊天机器人、文档分析和代码生成。 LangChain是由Harrison Chase于2022年10月推出的开源软件项目。它已成为LLM开发中最受欢迎的框架之一。LangChain支持Python和JavaScript语言,并与各种LLM一起使用,如GPT-4、BERT和T5。
3.2 txt文档加载器
- 将文件作为文本读入,并将其全部放入一个文档中,这是最简单的一个文档加载程序.
- langchain.txt
LangChain 是一个用于开发由大型语言模型 (LLMs) 驱动的应用程序的框架。LangChain简化了LLM应用程序生命周期的每个阶段:- 开发:使用LangChain的开源构建块和组件构建您的应用程序。使用第三方集成和模板开始运行。- 生产化:使用 LangSmith 检查、监控和评估您的链,以便您可以充满信心地持续优化和部署。- 部署:使用 LangServe 将任何链转变为 API。具体来说,该框架由以下开源库组成:- langchain-core :基础抽象和LangChain表达式语言。- langchain-community :第三方集成。- 合作伙伴包(例如 langchain-openai 、 langchain-anthropic 等):一些集成已进一步拆分为自己的轻量级包,仅依赖于 langchain-core 。- langchain :构成应用程序认知架构的链、代理和检索策略。- langgraph:通过将步骤建模为图中的边和节点,使用 LLMs 构建健壮且有状态的多角色应用程序。- langserve:将 LangChain 链部署为 REST API。更广泛的生态系统包括:- LangSmith:一个开发者平台,可让您调试、测试、评估和监控LLM应用程序,并与LangChain无缝集成。
from langchain.document_loaders import TextLoader
docs = TextLoader('LangChain.txt', encoding="utf-8").load()
print(docs)
type(docs[0])
print(docs[0].page_content)
[Document(
metadata={'source': 'LangChain.txt'},
page_content='LangChain 是一个用于开发由大型语言模型 (LLMs) 驱动的应用程序的框架。\n\nLangChain简化了LLM应用程序生命周期的每个阶段:\n\n\t- 开发:使用LangChain的开源构建块和组件构建您的应用程序。使用第三方集成和模板开始运行。\n\t- 生产化:使用 LangSmith 检查、监控和评估您的链,以便您可以充满信心地持续优化和部署。\n\t- 部署:使用 LangServe 将任何链转变为 API。\n\t\n具体来说,该框架由以下开源库组成:\n\n\t- langchain-core :基础抽象和LangChain表达式语言。\n\t- langchain-community :第三方集成。\n\t\t- 合作伙伴包(例如 langchain-openai 、 langchain-anthropic 等):一些集成已进一步拆分为自己的轻量级包,仅依赖于 langchain-core 。\n\t- langchain :构成应用程序认知架构的链、代理和检索策略。\n\t- langgraph:通过将步骤建模为图中的边和节点,使用 LLMs 构建健壮且有状态的多角色应用程序。\n\t- langserve:将 LangChain 链部署为 REST API。\n\t\n更广泛的生态系统包括:\n\t- LangSmith:一个开发者平台,可让您调试、测试、评估和监控LLM应用程序,并与LangChain无缝集成。'
)]
langchain_core.documents.base.Document
'LangChain 是一个用于开发由大型语言模型 (LLMs) 驱动的应用程序的框架。\n\nLangChain简化了LLM应用程序生命周期的每个阶段:\n\n\t- 开发:使用LangChain的开源构建块和组件构建您的应用程序。使用第三方集成和模板开始运行。\n\t- 生产化:使用 LangSmith 检查、监控和评估您的链,以便您可以充满信心地持续优化和部署。\n\t- 部署:使用 LangServe 将任何链转变为 API。\n\t\n具体来说,该框架由以下开源库组成:\n\n\t- langchain-core :基础抽象和LangChain表达式语言。\n\t- langchain-community :第三方集成。\n\t\t- 合作伙伴包(例如 langchain-openai 、 langchain-anthropic 等):一些集成已进一步拆分为自己的轻量级包,仅依赖于 langchain-core 。\n\t- langchain :构成应用程序认知架构的链、代理和检索策略。\n\t- langgraph:通过将步骤建模为图中的边和节点,使用 LLMs 构建健壮且有状态的多角色应用程序。\n\t- langserve:将 LangChain 链部署为 REST API。\n\t\n更广泛的生态系统包括:\n\t- LangSmith:一个开发者平台,可让您调试、测试、评估和监控LLM应用程序,并与LangChain无缝集成。'
- 使用
LangChain定义的加载器加载得到的数据类型是Document对象,和使用WikipediaLoader加载器得到的对象类型一致。
docs[0].metadata
{'source': 'LangChain.txt'}
- 对于
TextLoader,依然使用.page_content和.metadata去访问数据。每一个文档加载器虽然代码逻辑不同,应用需求不同,但使用方式是相同的。
3.3 文档加载器实现逻辑
- 对于
Source中多种不同的数据源,要想能在接下来的流程中可以用一种统一的形式检索、调用,至少要保证的是:把它们以一种相对统一的方式读取出来。所以LangChain的设计就是对于每一个在LangChain中集成的文档加载器,都要继承自BaseLoaderandDocument Class基类,当不同来源的数据通过load方法加载进来后,全部转化成Documents对象。实现逻辑如下所示: BaseLoader类定义如何从不同的数据源加载文档,每个基于不同数据源实现的loader,都需要集成BaseLoader。Baseloader要求对于任何具体实现的loader,最少都要实现 load方法。BaseLoader把数据加载成Documentsobject,存到Documents类中的page_content中。class BaseLoader(ABC):"""文档加载器接口。实现应当使用生成器实现延迟加载方法,以避免一次性将所有文档加载进内存。`load` 方法仅供用户方便使用,不应被重写。"""# 子类不应直接实现此方法。而应实现延迟加载方法。def load(self) -> List[Document]:"""将数据加载为 Document 对象。"""return list(self.lazy_load())def load_and_split(self, text_splitter: Optional[TextSplitter] = None) -> List[Document]:"""加载文档并将其分割成块。块以 Document 形式返回。不要重写此方法。它应被视为已弃用!参数:text_splitter: 用于分割文档的 TextSplitter 实例。默认为 RecursiveCharacterTextSplitter。返回:文档列表。""".........._text_splitter: TextSplitter = RecursiveCharacterTextSplitter()else:_text_splitter = text_splitterdocs = self.load()return _text_splitter.split_documents(docs)Document允许用户与文档的内容进行交互,可以查看文档内容。class Document(Serializable):"""用于存储文本及其关联元数据的类。"""page_content: str"""字符串文本。"""metadata: dict = Field(default_factory=dict)"""关于页面内容的任意元数据(例如,来源、与其他文档的关系等)。"""type: Literal["Document"] = "Document"def __init__(self, page_content: str, **kwargs: Any) -> None:"""将 page_content 作为位置参数或命名参数传入。"""super().__init__(page_content=page_content, **kwargs)@classmethoddef is_lc_serializable(cls) -> bool:"""返回此类是否可序列化。"""return True@classmethoddef get_lc_namespace(cls) -> List[str]:"""获取 langchain 对象的命名空间。"""return ["langchain", "schema", "document"]- 通过 存 + 读的两个基类的抽象,满足不同类型加载器在数据形式上的统一。除此之外,其中的
metadata会根据loader实现的不同写入不同的数据,同样是一个必要的基础属性。
3.4 加载JSON数据格式
LangChain提供的JSON格式的文档加载器是JSONLoader,根据其说明,JSONLoader使用指定的jq架构来解析JSON文件。
jq是一个轻量级的命令行JSON处理器,可以通过特定的语法在命令行中对JSON格式的数据进行各种复杂的处理,包括数据过滤、映射、减少和转换。
JsonLoader的官方文档地址JSONLoader是使用jq来解析JSON文件,所以在使用前,就必须进行jq库的安装。pip install jq- LangChain实现的
JSONLoader支持的JSON解析结构。class JSONLoader(BaseLoader):"""Load a `JSON` file using a `jq` schema.Example:[{"text": ...}, {"text": ...}, {"text": ...}] -> schema = .[].text{"key": [{"text": ...}, {"text": ...}, {"text": ...}]} -> schema = .key[].text["", "", ""] -> schema = .[] """ - 只有当我
JSON数据符合上述需求时,才能够正常的加载和使用JSONLoader。这里使用tsest用于测试,包含了7854个中文体育在线评论文档与对应的新闻报道。[{"_id": "4759","commentary": [["2'","鲍里索夫球员Nikolai Signevich拼抢犯规,对手获得控球权.","0-0"],...]} ]
-
普通json格式加载:
import json from pathlib import Path from pprint import pprintfile_path='./test.json' data = json.loads(Path(file_path).read_text(encoding="utf-8"))pprint(data[0]["_id"]) pprint(data[0]["commentary"][:5])'4759' [["2'", '鲍里索夫球员Nikolai Signevich拼抢犯规,对手获得控球权.', '0-0'],["2'", '拉波尔特为毕尔巴鄂竞技在对方半场,赢得一个任意球.', '0-0'],["2'", '毕尔巴鄂竞技球员贝尼亚特大禁区外尝试左脚射门,可惜皮球稍稍偏出了右球门.', '0-0'],["4'", '鲍里索夫球员波利亚科夫拼抢犯规,对手获得控球权.', '0-0'],["4'", '阿杜里斯为毕尔巴鄂竞技在左路,赢得一个任意球.', '0-0']] -
使用
JSONLoader文档加载器加载:from langchain_community.document_loaders import JSONLoader loader = JSONLoader(file_path='test.json', jq_schema='.[].commentary',text_content=False, )data = loader.load() print(data[0].metadata) print(data[0].page_content){'source': 'D:\\BaiduNetdiskDownload\\【5周年庆·限时免费学】Part 4.RAG&GraphRAG系统开发\\01《RAG技术实战》\\课件&代码\\test.json', 'seq_num': 1} [["2'", "\u9c8d\u91cc\u7d22\u592b\u7403\u5458Nikolai Signevich\u62fc\u62a2\u72af\u89c4,\u5bf9\u624b\u83b7\u5f97\u63a7\u7403\u6743.", "0-0"], ]
3.5 自定义JSON文档加载器
LangChain中构造自定义文档加载器涉及创建Document对象,该对象封装提取的文本 (page_content) 以及元数据——包含文档详细信息的字典,例如作者姓名或发布日期。而在随后的流程中,Document对象会被格式化为输入到LLM中的提示,允许LLM使用Document中的信息来生成期望的回应(如,总结文档)。Documents可以直接使用,也可以索引到矢量存储中以供将来检索和使用。- 对于文档加载器必须实现的的抽象方法
| 组件 | 描述 | 中文描述 |
|---|---|---|
| Document | Contains text and metadata | 包含文本和元数据 |
| BaseLoader | Use to convert raw data into Documents | 用于将原始数据转换为文档 |
-
在实现时,需要编写自定义文档加载和文件解析逻辑,具体来说,要通过 BaseLoader 子类化来创建标准文档加载器,其必须实现的方法是:
load。 -
这里使用一个新的不同JSON格式的数据集,这是一个哈利波特角色化对话数据集,为了研究如何在虚拟世界中构建角色化智能对话机器人,如智能游戏NPC等,数据存储为json形式。主要内容包括
- 对话所在位置(在书中的第几章节以及第几事件)
- 说话人
- 对话场景
- 对话内容
- 参与对话的角色属性
- 参与对话的角色与哈利的关系
- 答案正例(仅测试集)
- 答案负例(仅测试集)
-
具体实现代码如下:
import json from pathlib import Path from typing import Any, Callable, Dict, List, Optional, Union from langchain_core.documents import Document from langchain_community.document_loaders.base import BaseLoaderclass CustomJSONLoader(BaseLoader):"""Load a `JSON` file using a `jq` schema."""def __init__(self,file_path: Union[str, Path],jq_schema: str,):"""Initialize the JSONLoader.参数:file_path (Union[str, Path]): JSON 或 JSON Lines 文件的路径。jq_schema (str): 用来从 JSON 中提取数据或文本的 jq 模式。"""import jqself.file_path = Path(file_path).resolve()self._jq_schema = jq.compile(jq_schema)def load(self) -> List[Document]:"""从 JSON 文件中加载并返回文档。"""docs: List[Document] = []self._parse(self.file_path.read_text(encoding="utf-8"), docs)return docsdef _parse(self, content: str, docs: List[Document]) -> None:"""将给定内容转换为文档。"""# content : 原始的JSON# json.loads(content):JSON 格式的字符串 content 转换为 Python 的数据结构。#具体转换为哪种形式的数据结构取决于原始 JSON 字符串的内容:# 根据jq编译查找到的结果data = self._jq_schema.input(json.loads(content)).all()for i, sample in enumerate(data, len(docs) + 1):metadata={"result": "\n".join(sample), "source": self.file_path}docs.append(Document(page_content="\n".join(sample), metadata=metadata))import json from pathlib import Path from pprint import pprintloader = CustomJSONLoader(file_path='./cn_test_set.json', jq_schema='."Session-3"."对话历史"',)data = loader.load()pprint(data)[Document( metadata={'result': '哈利说:这是什么?\n佩妮说:你的新校服呀。\n哈利说:哦,我不知道还得泡得这么湿。\n佩妮说:别冒傻气,我把达力的旧衣服染好给你用。等我染好以后,穿起来就会跟别人的一模一样。', 'source': WindowsPath('D:/code/rag/cn_test_set.json')}, page_content='哈利说:这是什么?\n佩妮说:你的新校服呀。\n哈利说:哦,我不知道还得泡得这么湿。\n佩妮说:别冒傻气,我把达力的旧衣服染好给你用。等我染好以后,穿起来就会跟别人的一模一样。')] -
整体上看,在
LangChain的抽象下,接入一个自定义的文档加载器并不复杂复杂,通过一个较为简单和基础的示例构建自定义文档加载器,只要覆盖到核心过程,需要修改的就只是具体情境下数据的处理逻辑。包括继承自BaseLoader基类,将内容写入Document对象中的page_content,并重新定义metadata。
3.6 PDF文档加载器
3.6.1 普通PDF文档加载
- 安装python pdf操作工具包
pip install pypdf - pdf输入导入代码
from langchain_community.document_loaders import PyPDFLoaderfile_path = './layout-parser-paper.pdf'loader = PyPDFLoader(file_path) pages = [] async for page in loader.alazy_load():pages.append(page)print(f"{pages[0].metadata}\n") print(pages[0].page_content)
3.6.2 LangChain PDF文件加载
-
在LangChain的文档解析生态中,
langchain-unstructured是一个功能全面且高度灵活的文件加载组件,专门用于对多种复杂格式文件进行结构化切分与内容抽取**。它基于知名的Unstructured开源库进行深度集成,支持将不同文件类型(包括PDF、Word、HTML、电子书、PPT、Markdown等)统一转化为LangChain标准的Document对象。相比传统的简单文本加载器,langchain-unstructured能够智能识别段落、标题、表格、列表和图片注释等元素,并保留内容的结构层次信息,从而在后续向量化和检索阶段提供更高质量的语义分块。 -
在使用方式上,开发者仅需通过
UnstructuredFileLoader类或其衍生加载器(例如UnstructuredPDFLoader、UnstructuredHTMLLoader等)即可对目标文件进行加载。加载器内部会调用Unstructured的处理管道,自动完成版面分析、元素提取、文本清洗与分段。典型的使用流程仅需指定文件路径和分块策略,即可返回带有元数据和结构标记的文档集合。例如,通过配置mode="elements",用户可以将文档拆分为基于内容类型的精细粒度块,显著提升对复杂文档的检索准确性。此外,该加载器还支持可选的OCR处理,用于解析扫描版PDF和图片型文档。 -
总体来看,
langchain-unstructured为LangChain生态提供专业级的多格式文档解析能力,不仅降低了大规模非结构化内容接入的技术门槛,也为RAG(检索增强生成)系统的高质量知识构建奠定了坚实的基础。

四 RAG系统的文档切分策略
- 分块(Chunking)是将长文档拆分为较小的块的过程,目的是在检索时能够准确地找到最直接和最相关的段落。
- 一个有效的分块策略,可以确保搜索结果精确地反映用户查询的实际需求。如果分块过小或过大,都可能导致搜索结果不准确或提取不到最相关的内容。理想的文本块应尽可能语义独立,即不过度依赖上下文,这样的文本是语言模型最易于理解的。因此,为文档确定最佳的块大小是确保搜索结果准确性和相关性的关键。这涉及多个决策因素,如块的大小;如果句子太短,模型可能难以理解其意义,且句子越短,包含的有效信息就越少。
- 比较常用的有如下五种不同的方法来优化分块策略:
- 根据句子切分:这种方法按照自然句子边界进行切分,以保持语义完整性。
- 根据固定字符数切分:这种策略根据特定的字符数量来划分文本,但可能会在不适当的位置切断句子。
- 按固定字符数来切分,结合重叠窗口(overlapping windows):此方法与按字符数切分相似,但通过重叠窗口技术避免切分关键内容,确保信息连贯性。
- 递归方法:通过递归方式动态确定切分点,这种方法可以根据文档的复杂性和内容密度来调整块的大小。
- 根据语义切割:这种高级策略依据文本的语义内容来划分块,旨在保持相关信息的集中和完整,适用于需要高度语义保持的应用场景。
- 这些方法各有优势和局限,选择适当的分块策略取决于具体的应用需求和预期的检索效果。
4.1 根据句子切分
- 按照句子切分,其实就是通过标点符号来进行文本切分(分割)。一种简单的方法是使用
re模块,它提供了正则表达式的支持,可以方便地根据标点符号来分割文本。使用re.split()函数来根据中文和英文的标点符号进行文本切分。 - 函数会根据中文和英文的标点符号来分割文本,并移除空字符串。
import redef split_text_by_punctuation(text):# 定义一个正则表达式,包括常见的中英文标点# pattern = r"[。!?。"#$%&'()*+,-/:;<=>@[\]^_`{|}~\s、]+"pattern = r"[。!?。]+"# 使用正则表达式进行分割segments = re.split(pattern, text)# 过滤掉空字符串return [segment for segment in segments if segment]
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"# 调用函数进行分割
segments = split_text_by_punctuation(text)# 使用循环来打印每个chunk
for i, segment in enumerate(segments):print("Chunk {}: {}".format(i + 1, segment))
Chunk 1: 春节的脚步越来越近,大街小巷都布满了节日的气氛
Chunk 2: 商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年
Chunk 3: 小明回到家乡,感受到了浓浓的过年氛围
Chunk 4: 他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏
Chunk 5: 夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待
Chunk 6: 老人们聚在一起,回忆过去,展望未来
Chunk 7: 而年轻人则在夜市享受美食,放松心情
Chunk 8: 这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日
4.2 根据固定字符数切分
- 按照固定字符数来切分文本,按照给定的字符数来切分文本。
- 仅依据长度进行切分,切分后的片段可能无法保持完整的语义。但并不意味着它不适用于文本切分任务。例如,这种方法非常适合于处理日志文件或代码块,其中文本通常以固定长度或格式出现,或者在处理来自传感器或其他实时数据源的流数据时,固定长度切分可以确保数据被均匀地处理和分析。这些应用场景中,数据的结构和形式通常是预定和规范的,因此即便是按固定长度进行切分,反而会更有利于对数据的理解和使用。
def split_text_by_fixed_length(text, length):# 使用列表推导式按固定长度切分文本return [text[i:i + length] for i in range(0, len(text), length)]# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"# 定义每个片段的长度
chunk_length = 106# 调用函数进行分割
result = split_text_by_fixed_length(text, chunk_length)# 打印结果
for i, segment in enumerate(result):print(f"Chunk {i+1}: {segment}")
Chunk 1: 春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。
Chunk 2: 夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。
4.3 按固定字符数来切分+结合重叠窗口
- 重复窗口的意义是:块之间保持一些重叠,以确保语义上下文不会在块之间丢失。在文本处理和其他数据分析领域,“重叠”(overlap)指的是连续数据块之间共享的部分。这种方法特别常见于信号处理、语音分析、自然语言处理等领域,其中数据的连续性和上下文信息非常重要。
def split_text_by_fixed_length_with_overlap(text, length, overlap):# 使用列表推导式按固定长度及重叠长度切分文本return [text[i:i + length] for i in range(0, len(text) - overlap, length - overlap)]
# 文本
text = "春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。\
小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。\
夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。\
而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。"# 定义每个片段的长度和重叠长度
chunk_length = 100
overlap_length = 30# 调用函数进行分割
result = split_text_by_fixed_length_with_overlap(text, chunk_length, overlap_length)# 打印结果
for i, segment in enumerate(result):print(f"Chunk {i+1}: {segment}")
Chunk 1: 春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑
Chunk 2: 了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食
Chunk 3: 老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食,放松心情。这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。
- 每个文本片段长度为100个字符,并且每个片段与下一个片段有30个字符的重叠。这样,每个窗口实际上是在上一个窗口向前移动30个字符的基础上开始的。
- 这种方法特别适用于需要数据重叠以保持上下文连续性的情况,能够较好的在某一个chunk中保存某个完整的语义信息,比如在第一个Chunk中的:'他在街上走着,看到小朋友们手持烟花棒,欢笑’被截断,但是完整的语义能够在Chunk2中被存储:‘他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。’ 那么当这条语义信息是有关于Query的上下文,就可以在chunk2中被检索出来。
4.4 递归方法
- 前三种方法涉及的是对数据静态字符的切分,这些方法基本上只会将文本分割成固定数量字符的片段,而不考虑其内容或结构。这些是最基本且相对简单实现的文本切分方式。
- 相比之下,递归方法的切分策略更为通用且常用,但实现上稍显复杂。为了简化实现过程,可以直接利用LangChain提供的封装类来进行实践。
4.4.1 LangChain中的Text Splitters工具调用
- LangChain框架构造
Data connection这一原生的数据处理流来统一管理RAG的处理流程。在这个架构中,文档切分的过程对应于Transformer环节,这一部分的任务是将整个Document对象转化(或“转换”)成多个小块(chunks)。这一转化步骤确立了文档从完整对象到
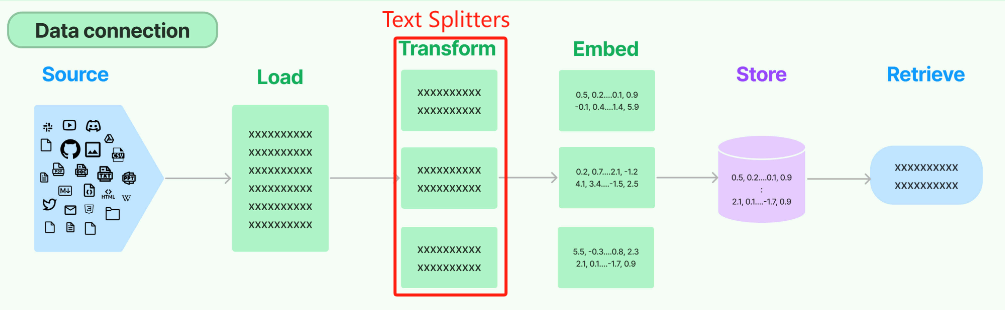
- 在
Transform流程中,LangChain有很多内置的文档转换器,可以轻松地拆分、组合、过滤和以其他方式操作文档,说明文档位置。 - LangChain文档切分工具概览:在LangChain的内容处理体系中,Text Splitters是至关重要的组件,用于将长文本划分为可检索和可嵌入的小块(chunks),以适配检索增强生成(RAG)或其他下游任务。不同的分块方法可以根据输入内容的格式(如纯文本、HTML、代码或JSON)以及应用场景(例如语义分块或基于字符的固定分割)进行灵活选用。通过合理的Text Splitter配置,开发者可以在上下文保留和分块粒度之间取得平衡,从而显著提升问答系统的精确性和响应速度。下表汇总了LangChain官方文档中列出的主要分块方式及其适用场景。
| 分块方法 | 简要说明 |
|---|---|
| Recursively split text | 按照一系列规则(段落 > 行 > 句子 > 字符)递归地将纯文本拆分为块 |
| Split HTML | 专门针对HTML内容,依据标签结构分块 |
| Split by character | 根据固定字符长度进行等分,适合对结构要求不高的场景 |
| Split code | 针对代码文件,按照函数、类、注释等语法单位进行智能拆分 |
| Split Markdown by headers | 根据Markdown标题层级进行分块,保留章节结构 |
| Recursively split JSON | 递归解析JSON数据结构,将其拆解为逻辑最小单位(键值对或数组元素) |
| Split text into semantic chunks | 基于语义理解,将文本自动切分为含义完整的片段(需依赖模型或规则库) |
| Split by tokens | 按照模型Tokenizer的Token数进行分块,便于控制输入上下文长度 |
- 在实际应用中,灵活组合这些分块器,针对不同的内容类型采取最优的策略。例如,针对技术文档,可以先用Markdown Header Splitter保留章节层次,再使用Recursive Character Splitter对较长片段进行二次切分;而在代码检索场景,Code Splitter可以根据函数或类边界划分逻辑单元,从而提高查询的精准性和可读性。
4.4.2 CharacterTextSplitter
- CharacterTextSplitter是最简单的方法,基于字符(默认为“”)进行分割,并通过字符数来测量块长度。
pip install -qU langchain-text-splitters
- CharacterTextSplitter初始化方法中需要传递一个
separator,默认是以"\n\n"进行分割。虽然它并没有定义额外的初始化参数,但因为其继承了TextSplitter,所以在TextSplitter类中定义的参数,在CharacterTextSplitter类中都可以直接使用。
- 在
TextSplitter类(基类)的初始化函数中,确保 chunk_overlap 必须小于 chunk_size。这是为了确保文本分块的逻辑正常运行,因为重叠区域不能大于整个块的大小。这样的设计是为了确保每个块之间有足够的内容重叠,但又不会导致块之间的界限不明确或重叠区域过大。
from langchain.text_splitter import CharacterTextSplitter
# This is a long document we can split up.
with open("LangChain.txt", encoding="utf-8") as f:langchain_desc = f.read()text_splitter = CharacterTextSplitter(separator='\n',chunk_size = 100,chunk_overlap=0,)
text_res = text_splitter.split_text(langchain_desc)
print(len(text_res))
print(text_res[0])
8
LangChain 是一个用于开发由大型语言模型 (LLMs) 驱动的应用程序的框架。
LangChain简化了LLM应用程序生命周期的每个阶段:
4.4.3 RecursiveCharacterTextSplitter
- 之前的切分方法完全忽视了文档的结构,只是单纯按固定字符数量进行切分。所以要更进一步地去做优化,那么一个更进阶的文本分割器应该具备:
- 能够将文本分成小的、具有语义意义的块(通常是句子)。
- 可以通过某些测量方法,将这些小块组合成一个更大的块,直到达到一定的大小。
- 一旦达到该大小,请将该块设为自己的文本片段,然后创建具有一些重叠的新文本块,以保持块之间的上下文。
- 用LangChain提供的文本切分可视化小工具进行直观的理解:https://langchain-text-splitter.streamlit.app/

- 按字符递归分割,就是使用一组分隔符以分层和迭代的方式将输入文本分成更小的块。默认使用**[“\n\n” ,“\n” ," “,”"]** 这四个特殊符号作为分割文本的标记,如果分割文本开始的时候没有产生所需大小或结构的块,那么这个方法会使用不同的分隔符或标准对生成的块递归调用,直到获得所需的块大小或结构。这意味着虽然这些块的大小并不完全相同,但它们仍然会逼近差不多的大小。其中的关键参数:
- separators:指定分割文本的分隔符
- chunk_size:被切割字符的最大长度
- chunk_overlap:如果仅仅使用chunk_size来切割时,前后两段字符串重叠的字符数量。
- length_function:如何计算块的长度。默认情况下,只计算字符数,也可以选择按照Token。
- length_function:用于计算切块长度的方法。默认只计算字符数,但通常这里会使用Token。
- chunk_size:切块的最大大小(由长度函数测量)。
- chunk_overlap:切块之间的最大重叠部分。保持一定程度的重叠可以使得各个切块之间保持连贯性(例如滑动窗口)。
- add_start_index:是否在元数据中包含每个切块在原始文档中的起始位置。
- 测试文本:
春节的脚步越来越近,大街小巷都布满了节日的气氛。商店门口挂满了红灯笼和春联,家家户户都在忙着打扫卫生,准备迎接新的一年。 小明回到家乡,感受到了浓浓的过年氛围。他在街上走着,看到小朋友们手持烟花棒,欢笑声此起彼伏。 夜幕降临,整个城市亮起了五彩缤纷的灯光,映照着人们脸上的喜悦与期待。老人们聚在一起,回忆过去,展望未来。而年轻人则在夜市享受美食,放松心情。 这是一个充满希望和喜悦的时刻,每个人都在以自己的方式庆祝这个特殊的节日。 - Text Splitter 关键参数设定:


- 切分的结果是由
length_function = len决定的,按照设置的切分规则,依次对文本进行分割; - 能不能进行分割,并不是由Chunk Size决定,超出Chunk Size只是触发条件,而真正会不会实际执行分割操作,取决于separator设置的关键词。
pip install --upgrade --quiet langchain-text-splitters tiktoken
from langchain.text_splitter import RecursiveCharacterTextSplitter
with open("./LangChain.txt", encoding="utf-8") as f:langchain_desc = f.read()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(model_name="gpt-4o",chunk_size=100, #块长度chunk_overlap=0, #重叠字符串长度)
texts = text_splitter.split_text(langchain_desc)
print(texts[0])
print(len(texts))
LangChain 是一个用于开发由大型语言模型 (LLMs) 驱动的应用程序的框架。LangChain简化了LLM应用程序生命周期的每个阶段:
4
- 在这段代码中,
model_name="gpt-4o"的作用是 指定一个用于文本分割的标记化(tokenization)方式,而 不需要实际连接到大模型。- 这段代码使用了
RecursiveCharacterTextSplitter.from_tiktoken_encoder依赖于 OpenAI 的tiktoken库来对文本进行标记化(tokenization)。 model_name参数指定了使用哪种模型的标记化规则(tokenizer)。这里设置为"gpt-4o",表示使用 GPT-4o 的标记化方式。- 标记化方式会影响如何计算文本的 token 数量(比如
chunk_size=100是指每个文本块的 token 数量上限)。
- 这段代码使用了
- 为什么需要指定
model_name?- 如果你计划将分割后的文本输入到 GPT-4o 或其他 OpenAI 模型,使用匹配的
model_name可以确保分割后的块不超过模型的 token 限制(如上下文窗口大小)。 - 如果只是普通的分割(不关心 token 数量),可以忽略
model_name或使用其他分句方法。
- 如果你计划将分割后的文本输入到 GPT-4o 或其他 OpenAI 模型,使用匹配的
4.4.4 MarkdownTextSplitter
- 如果遇到
markdown文档,需要使用MarkdownTextSplitter文档分割器 - 安装固定字符数进行markdown文件分割
from langchain.text_splitter import MarkdownTextSplitter markdown_text = """ # 主题:技术探讨## 第一部分:前言这是前言部分,简短介绍文档主旨。## 第二部分:技术分析### Python编程### 解释1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。 2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。 3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。 """ # 构造文档切割器的实例 splitter = MarkdownTextSplitter(chunk_size = 60, chunk_overlap=10) # 按照`MarkdownTextSplitter`定义的分隔符进行切分,调用`create_documents`方法 mardown_split = splitter.create_documents([markdown_text]) print(len(mardown_split)) pprint(mardown_split)5 [Document(metadata={}, page_content='# 主题:技术探讨\n\n## 第一部分:前言\n\n这是前言部分,简短介绍文档主旨。\n\n## 第二部分:技术分析'),Document(metadata={}, page_content='### Python编程\n\n### 解释'),Document(metadata={}, page_content='1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。'),Document(metadata={}, page_content='2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。'),Document(metadata={}, page_content='3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。')]
- LangChain封装的
MarkdownHeaderTextSplitter,它的切分逻辑是基于指定的标题来分割markdown文件。因为Markdown格式有特定的语法,一般整体内容由h1、h2、h3等多级标题组织,所以MarkdownHeaderTextSplitter得切分策略就是根据标题来分割文本内容。
from langchain_text_splitters import MarkdownHeaderTextSplittermarkdown_text = """
# 主题:技术探讨## 第一部分:前言这是前言部分,简短介绍文档主旨。## 第二部分:技术分析### Python编程### 解释1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。
2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。
3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。
"""headers_to_split_on = [("#", "Header 1"),("##", "Header 2"),("###", "Header 3"),
]markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_text)
print(md_header_splits)
[Document(metadata={'Header 1': '主题:技术探讨', 'Header 2': '第一部分:前言'}, page_content='这是前言部分,简短介绍文档主旨。'), Document(metadata={'Header 1': '主题:技术探讨', 'Header 2': '第二部分:技术分析', 'Header 3': '解释'}, page_content='1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。\n2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。\n3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。')]
-
CodeTextSplitter,可以按照代码进行分割,支持代码的语言包括[‘cpp’, ‘go’, ‘java’, ‘js’, ‘php’, ‘proto’, ‘python’, ‘rst’, ‘ruby’, ‘rust’, ‘scala’, ‘swift’, ‘markdown’, ‘latex’, ‘html’, ‘sol’],使用方法还是类似的,直接去实例化对应的文档分割器。from langchain.text_splitter import (RecursiveCharacterTextSplitter,Language, ) markdown_text = """ # 主题:技术探讨## 第一部分:前言这是前言部分,简短介绍文档主旨。## 第二部分:技术分析### Python编程### 解释1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。 2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。 3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。 """ md_splitter = RecursiveCharacterTextSplitter.from_language(language=Language.MARKDOWN, chunk_size=60, chunk_overlap=0 ) md_docs = md_splitter.create_documents([markdown_text]) pprint(md_docs)[Document(metadata={}, page_content='# 主题:技术探讨\n\n## 第一部分:前言\n\n这是前言部分,简短介绍文档主旨。\n\n## 第二部分:技术分析'),Document(metadata={}, page_content='### Python编程'),Document(metadata={}, page_content='### 解释'),Document(metadata={}, page_content='1. **标题**:使用不同级别的标题(从`#`到`###`)来组织文档结构。'),Document(metadata={}, page_content='2. **代码块**:分别用Python和JavaScript代码块来示例如何在Markdown中嵌入代码。'),Document(metadata={}, page_content='3. **水平线**:使用`***`和`---`创建水平线,用于文档中不同部分之间的视觉分隔。')]
4.5 根据语义切割
- 使用深度学习模型去做语义层面的Chunks,则选择方向会更大,使用方法也很简单,如可以在LangChain中使用已经抽象好的语义切分文档分割器
AI21SemanticTextSplitter,AI21SemanticTextSplitter相关文档地址 - 在Hugging Face 和 ModelScope中找到一些预训练好的通用文本分割模型,都会有比较详细的介绍,如BERT文本分割-中文-通用领域。bert模型魔塔地址
- 基于语义切割方法的特点是:模型非常多,直接下载即可使用,且使用方法会更加简单,但不同的数据和需求,所需的文本分割模型也不同,如果采用这种语义分割方法,需要在使用时做足够的调研工作和大量的效果测试。
4.6 总结
- 总的来说,没有最好的分块策略,只有最适合的分块策略,甚至有时间最简单的分块方式反而能起到最好的效果,这完全是由实际的数据和场景为驱动。但分块也是RAG整个流程中我们最能把控、最有机会做出高质量效果的一个环节,而这一调优的过程,考验的就是对数据的理解能力和对应变能力,需要具备根据检索反馈的效果快速的制定优化策略。
- 同时需要特别指出的是:在进行应用的切分策略之前,还有非常多数据预处理的工作,要通过清洗数据来确保数据的质量。比如,如果数据是通过爬虫获取的,就需要删除HTML标记或特定的元素,保证文本的“纯洁”,减少文本的噪音,文档数据不够干净,召回效果肯定也不会好。