Spring AI 学习笔记(2)
大家好!在上一篇文章中,已经初步认识了 Spring AI 这个 Spring 官方推出的 AI 能力集成框架,从它的核心特性讲起,涵盖了跨 AI 供应商的可移植 API、结构化输出、工具调用等基础功能,还通过实际案例演示了如何搭建项目、对接不同大模型、实现流式响应、运用对话记忆与结构化输出转换等实用操作。而今天,我们将进一步深入这个强大的框架,聚焦向量数据库、检索增强生成(RAG)、模型上下文协议(MCP)等进阶核心知识,看看它们如何与 Spring AI 结合,帮助我们构建更智能、更精准的 AI 应用。
向量数据库
大家可以参考视频大致的了解一下什么是向量,什么是向量数据库以及在实际中的应用。
向量化Embedding
Embedding 嵌入是将高维离散数据(如文字、图片)转换为低维连续向量的过程。这些向量能在数学空间中表示原始数据的语义特征,使计算机能够理解数据间的相似性。
Embedding 模型是执行这种转换算法的机器学习模型,如 Word2Vec(文本)、ResNet(图像)等。不同的 Embedding模型产生的向量表示和维度数不同,一般维度越高表达能力更强,可以捕获更丰富的语义信息和更细微的差别,但同样占用更多存储空间。接下通过使用阿里云百炼平台提供的text-embedding-v4嵌入模型结合Spring AI来实现文本数据向量化。
第一步获取api-key
登录阿里云百炼平台,点击密钥管理
点击创建API-KEY
创建成功后可以获取到对应账号的api-key

点击模型广场,搜索对应的模型
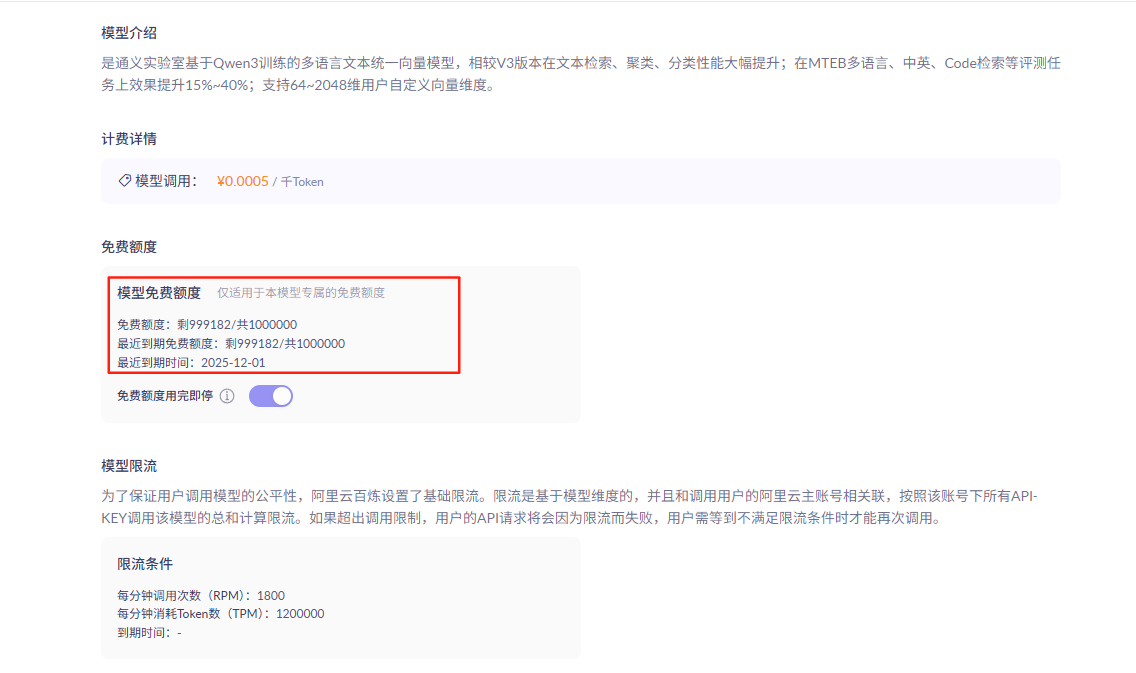
点击查看详情,可以看到模型介绍以及收费标准。阿里云百炼平台给与每个账号都提供了一定额度的免费使用次数,学习完全够用。
点击API参考查看如何在代码中接入模型,可以看到兼容OpenAI模式
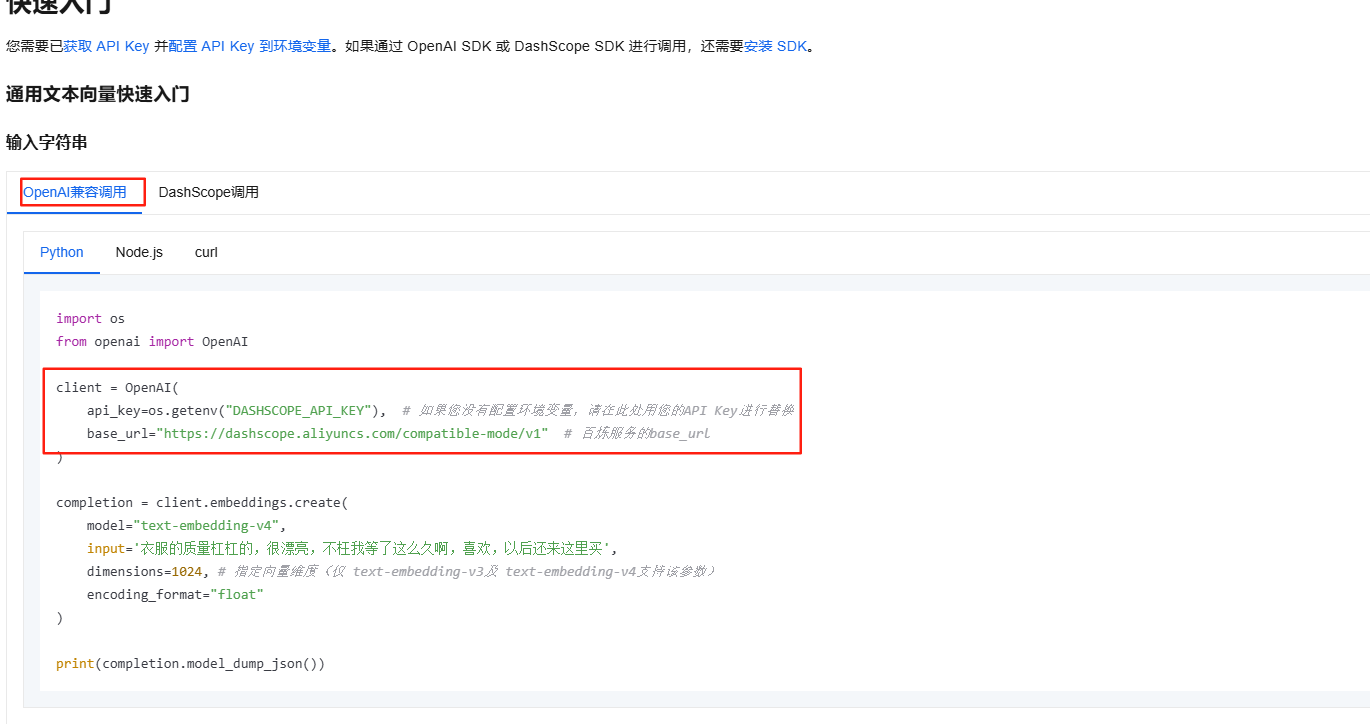
第二步添加配置信息
阿里云百炼 text-embedding-v4 模型兼容 OpenAI Embedding API 协议,因此可复用 Spring AI 的 OpenAI Starter 依赖,无需额外引入百炼专属依赖
spring:ai:chat:client:enabled: trueopenai:api-key: sk-94d1060f95e54da7b7e6fa0dde6c682f #这里的key可以是OpenAI API key也可以是Deepseek API keybase-url: https://api.deepseek.com #跟上面保持一致就行chat:options:model: deepseek-chatembedding: #嵌入模型api-key: sk-f7fdfee83ef04388bac5bb4def74093f #你的api-keyoptions:model: text-embedding-v4 #模型dimensions: 1024 #维度base-url: https://dashscope.aliyuncs.com/compatible-mode #这里要把v1去掉deepseek:api-key: sk-94d1060f95e54da7b7e6fa0dde6c682f #Deepseek API keychat:options:model: deepseek-chat #可以不指定使用的模型,默认为deepseek-chat 还可以选择 usedeepseek-coder模型ollama:base-url: http://localhost:11434 #默认http://localhost:11434chat:options:model: deepseek-r1:latest官方给的例子中
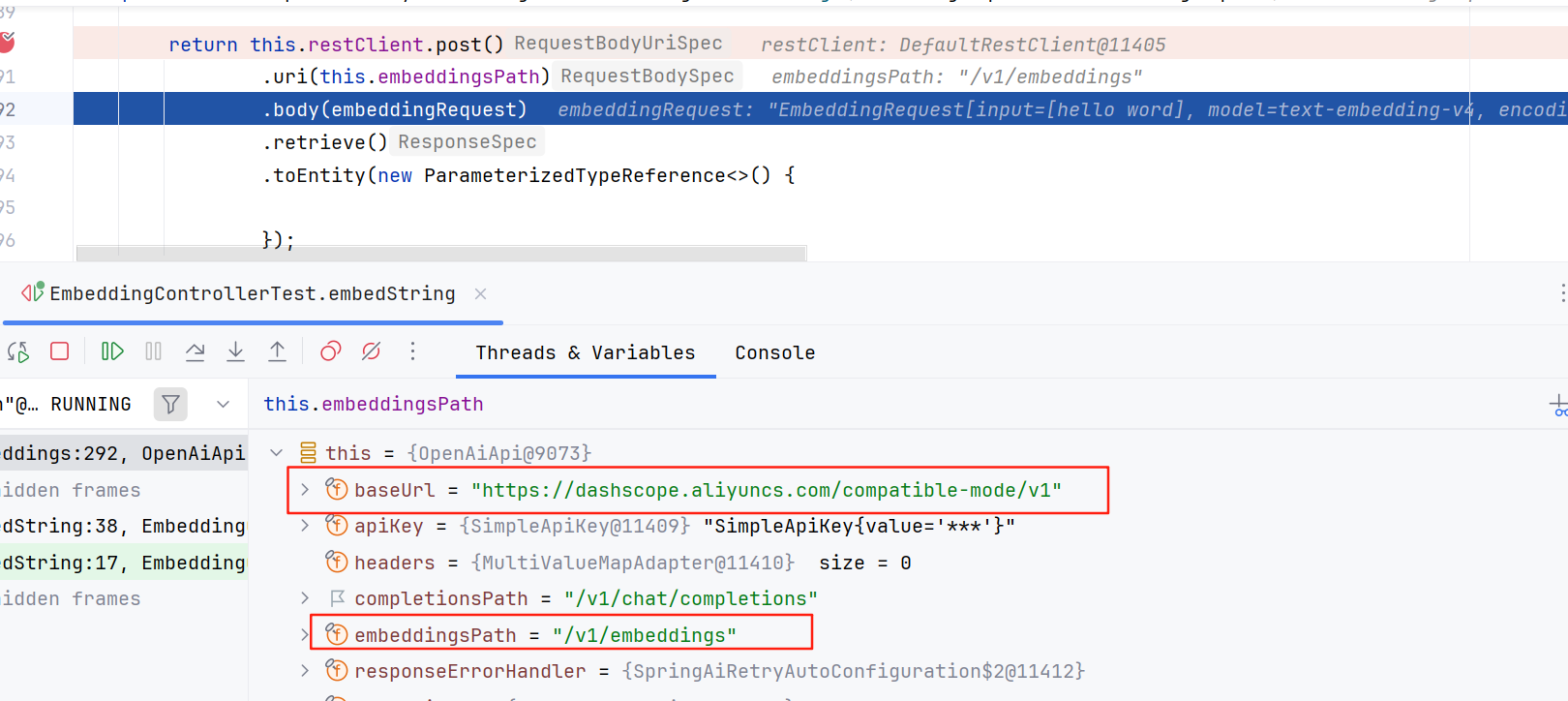
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 百炼服务的base_url实际运行项目会报错

通过调试源码我猜测可能是base_url最后多了个v1,后续去掉配置文件中base_url的/v1运行就正常了。
第三步编写controller
@RestController
@RequestMapping("/embedding")
@Slf4j
public class EmbeddingController {private final EmbeddingModel embeddingModel;public EmbeddingController(OpenAiEmbeddingModel embeddingModel) {this.embeddingModel = embeddingModel;}@GetMapping("/embed/string")public void embedString(){float[] embed = embeddingModel.embed("hello word");log.info("vector: {}", embed);log.info("length: {}", embed.length);}
}这里需要指定使用OpenAiEmbeddingModel类型进行注入,否则会提示:Could not autowire. There is more than one bean of 'EmbeddingModel' type.
Beans:
ollamaEmbeddingModel (OllamaEmbeddingAutoConfiguration.class) openAiEmbeddingModel (OpenAiEmbeddingAutoConfiguration.class)
测试类
@SpringBootTest
class EmbeddingControllerTest {@ResourceEmbeddingController embeddingController;@Testvoid embedString() {embeddingController.embedString();}
}执行测试,可以看到控制台输出了转换后的向量数据以及向量维度

更多例子
@GetMapping("/embed/document")public void embedDocument(){float[] embed = embeddingModel.embed(new Document("hello world"));log.info("vector: {}", embed);log.info("length: {}", embed.length);}@GetMapping("/embed/list")public void embedList(){List<float[]> embed = embeddingModel.embed(Arrays.asList("hello world", "hello world"));log.info("size: {}", embed.size());for (float[] floats : embed) {log.info("vector: {}", floats);log.info("length: {}", floats.length);}}@GetMapping("/embed")public void embed(){OpenAiEmbeddingOptions options = new OpenAiEmbeddingOptions();options.setDimensions(2048);EmbeddingRequest embeddingRequest = new EmbeddingRequest(List.of("hello world"), options);float[] output = embeddingModel.call(embeddingRequest).getResult().getOutput();log.info("embedding: {}", output);log.info("embedding: {}", output.length);}向量数据的数据源可以是文件、图片、音频等资源,这里为了简单演示整体执行流程,使用了更简单直观的文本作为数据源。
向量存储VectorStore
向量存储是指将转换后的向量数据存储到向量数据库中。要将数据插入向量数据库,需将其封装在 Document 对象中。Document 类封装来自数据源(如 PDF 或 Word 文档)的内容,包含表示为字符串的文本。它还以键值对形式包含元数据,例如文件名等详细信息。
当插入向量数据库时,文本内容通过嵌入模型(如 Word2Vec、 GLoVE、 BERT 或 OpenAI 的 text-embedding-ada-002)转换为数值数组(即 float[]),称为向量嵌入(Embedding)。这些模型用于将单词、句子或段落转换为向量嵌入。
向量数据库的作用是存储这些嵌入并促进其相似性搜索,它本身不生成嵌入。要创建向量嵌入,应使用 EmbeddingModel。
Spring AI 提供了一个 VectorStore 接口,用于存储和检索 Embedding。目前,Spring AI 提供的 VectorStore 实现包括 SimpleVectorStore、ChromaVectorStore、Neo4jVectorStore、PgVectorStore、RedisVectorStore 等。这里演示使SimpleVectorStore来实现向量存储。
第一步配置VectorStore
@Configuration
public class VectorStoreConfig {@Beanpublic VectorStore vectorStore(OpenAiEmbeddingModel embeddingModel) {return SimpleVectorStore.builder(embeddingModel).build();}
}第二步编写controller
@Resource
private VectorStore vectorStore;@GetMapping("/store")public void store(){// 1. 为每个文档创建元数据(键值对形式)Map<String, Object> liShiMinMeta = new HashMap<>();liShiMinMeta.put("person", "李世民");liShiMinMeta.put("dynasty", "唐朝");liShiMinMeta.put("role", "皇帝");liShiMinMeta.put("type", "历史人物");Map<String, Object> qinShiHuangMeta = new HashMap<>();qinShiHuangMeta.put("person", "嬴政(秦始皇)");qinShiHuangMeta.put("dynasty", "秦朝");qinShiHuangMeta.put("role", "开国皇帝");qinShiHuangMeta.put("type", "历史人物");Map<String, Object> zhuYuanZhangMeta = new HashMap<>();zhuYuanZhangMeta.put("person", "朱元璋");zhuYuanZhangMeta.put("dynasty", "明朝");zhuYuanZhangMeta.put("role", "开国皇帝");zhuYuanZhangMeta.put("type", "历史人物");var documents = List.of(new Document("李世民是唐朝的皇帝,他是唐朝的第二位君主,年号 “贞观”,史称 “唐太宗”。",liShiMinMeta),new Document("秦始皇(公元前 259 年 — 公元前 210 年),嬴姓,赵氏,名政,是中国历史上第一个皇帝,被誉为 “千古一帝”。",qinShiHuangMeta),new Document("朱元璋是明朝的开国皇帝,字国瑞,原名朱重八,后改名朱兴宗,濠州钟离(今安徽凤阳)人。",zhuYuanZhangMeta));// 3. 存储带有元数据的文档vectorStore.add(documents);}这样就实现了将嵌入后的向量存储到数据库中,以便后续检索。
向量检索Search
第一步编写controller
@GetMapping("/search")public List<Document> search(@RequestParam(name = "query",defaultValue = "皇帝") String query) {List<Document> search = vectorStore.similaritySearch(query);log.info("search: {}", search);return search;}测试
首先访问http://localhost:8080/embedding/store存储数据
接着访问http://localhost:8080/embedding/search查询数据

返回的结果会按相似度排序返回。
测试复杂查询
@GetMapping("/search/top")public List<Document> searchTop(@RequestParam(name = "query",defaultValue = "皇帝") String query,@RequestParam(name = "topK",defaultValue = "2") int topK) {SearchRequest searchRequest = SearchRequest.builder().query(query).topK(topK).filterExpression("role=='开国皇帝'").build();List<Document> search = vectorStore.similaritySearch(searchRequest);log.info("search: {}", search);return search;}query查询字符串,topk返回前k个结果,filterExpression按标签过滤对应元数据中的标签。

可以看到结果不包含李世民。再将topK改为1
@RequestParam(name = "topK",defaultValue = "1") int topK测试

这下结果只包含秦始皇了。
在了解了如何将文档转换为 Embedding 并存储到向量数据库中,以及如何使用自然语言检索相关文档后,下面来看看如何实现 RAG。
RAG
什么是RAG
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术和 Al 内容生成的混合架构,可以解决大模型的知识时效性限制和幻觉问题。
简单来说,RAG 就像给 AI 配了一个“小抄本”,让 AI 回答问题前先查一查特定的知识库来获取知识,确保回答是基于真实资料而不是凭空想象。
从技术角度看,RAG 在大语言模型生成回答之前,会先从外部知识库中检索相关信息,然后将这些检索到的内容作为额外上下文提供给模型,引导其生成更准确、更相关的回答。
通过 RAG 技术改造后,AI 就能:
- 准确回答关于特定内容的问题
- 在合适的时机推荐相关课程和服务费
- 用特定的语气和用户交流季
- ·提供更新、更准确的建议
可以简单了解下 RAG 和传统 AI 模型的区别:
| 特性 | 传统大语言模型 | RAG增强模型 |
| 知识时效性 | 受训练数据截止日期限制 | 可接入最新知识库 |
| 领域专业性 | 泛化知识,专业深度有限 | 可接入专业领域知识 |
| 响应准确性 | 可能产生 “幻觉” | 基于检索的事实依据 |
| 可控性 | 依赖原始训练 | 可通过知识库定制输出 |
| 资源消耗 | 较高(需要大模型参 数) | 模型可更小,结合外部知识 |
RAG工作流程
RAG 技术实现主要包含以下 4 个核心步骤:
- 文档收集和切割
- 向量转换和存储
- 文档过滤和检索
- 查询增强和关联
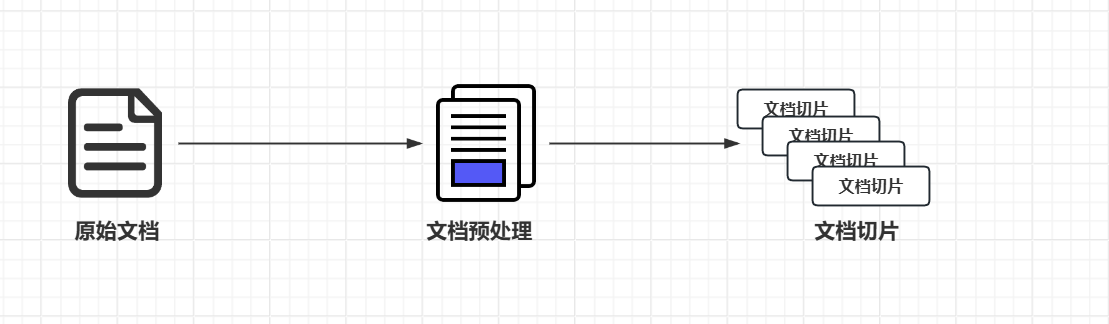
第一步文档收集和切割
文档收集:从各种来源(网页、PDF、数据库等)收集原始文档
文档预处理:清洗、标准化文本格式
文档切割:将长文档分割成适当大小的片段(俗称 chunks)
- 基于固定大小(如 512 个 token)
- 基于语义边界(如段落、章节)
- 基于递归分割策略(如递归字符 n-gram 切割)
第二步向量转换和存储
向量转换:使用 Embedding 模型将文本块转换为高维向量表示,可以捕获到文本 的语义特征
向量存储:将生成的向量和对应文本存入向量数据库,支持高效的相似性搜索
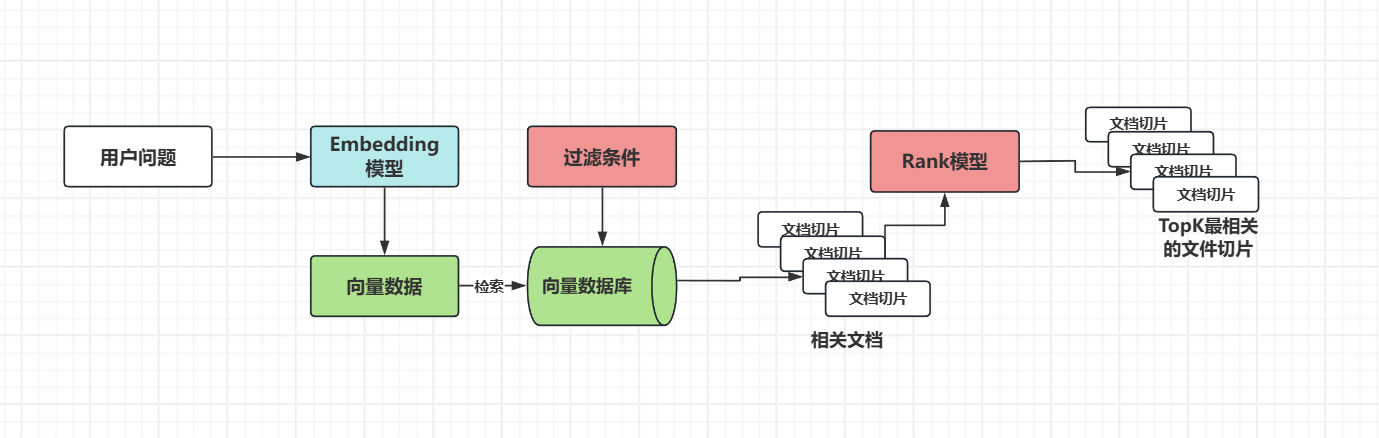
第三步文档过滤和检索
查询处理:将用户问题也转换为向量表示
过滤机制:基于元数据、关键词或自定义规则进行过滤
相似度搜索:在向量数据库中查找与问题向量最相似的文档块,常用的相似度搜索算法有余弦 相似度、欧氏距离等
上下文组装:将检索到的多个文档块组装成连贯上下文
第四步查询增强和关联
提示词组装:将检索到的相关文档与用户问题组合成增强提示
上下文融合:大模型基于增强提示生成回答
源引用:在回答中添加信息来源引用
后处理:格式化、摘要或其他处理以优化最终输出
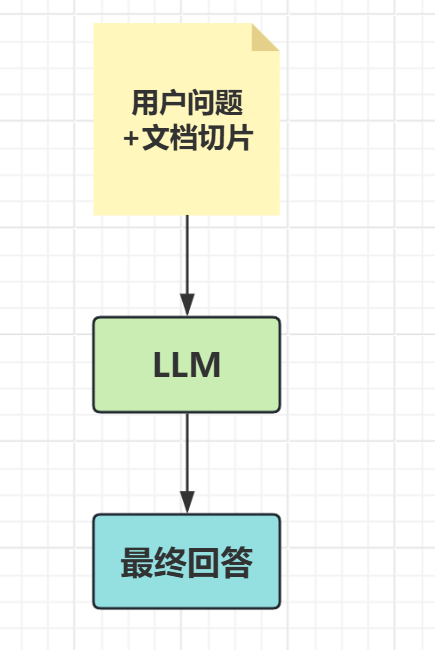
完整流程
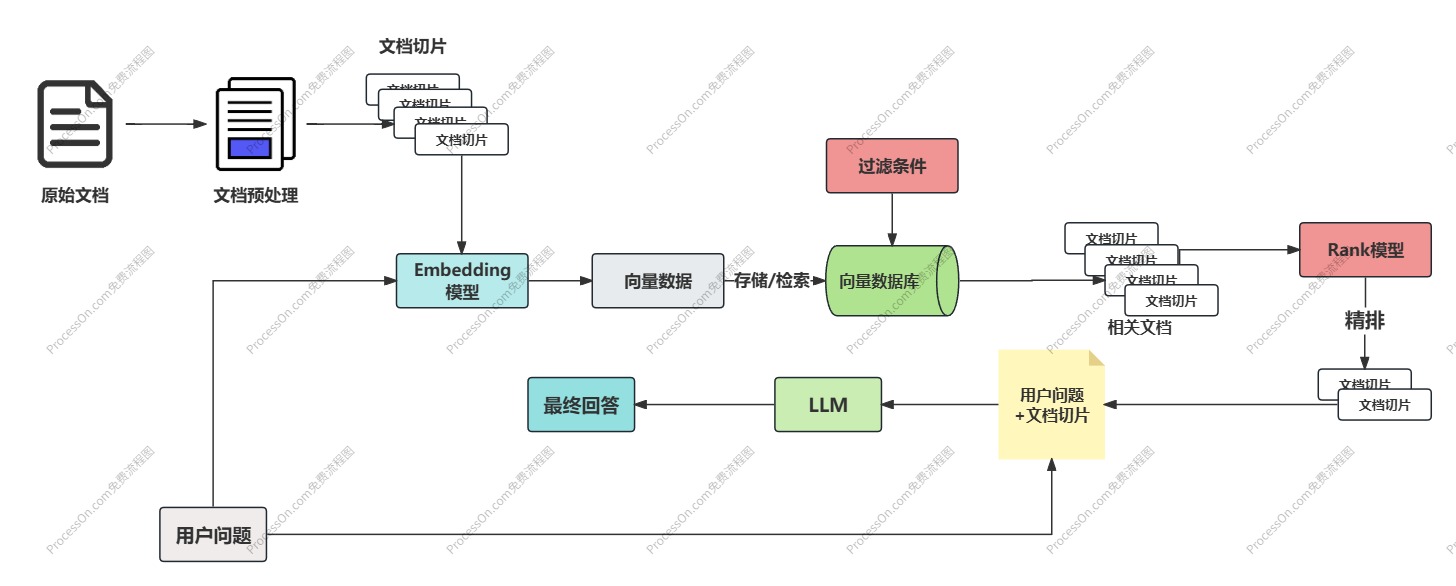
Spring AI + 本地知识库实现 RAG
1.文档准备
首先准备用于给 AI 知识库提供知识的文档,推荐 Markdown 格式,尽量结构 化。
这里我准备了2篇文档,一篇是关于俄乌冲突最新进展的介绍,另外一篇是《黑神话,钟馗》相关介绍,两篇文档的内容都很新颖前沿。
2.文档读取
首先,我们要对自己准备好的知识库文档进行处理,然后保存到向量数据库中。这个过程俗称 ETL(抽取、转换、加载),Spring AI 提供了对 ETL 的支持,官方文档
ETL 的 3 大核心组件,按照顺序执行:
- DocumentReader:读取文档,得到文档列表
- DocumentTransformer:转换文档,得到处理后的文档列表
- DocumentWriter:将文档列表保存到存储中(可以是向量数据库,也可以是其他存储)

添加依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-markdown-document-reader</artifactId></dependency>编写文档加载器
@Slf4j
@Component
public class DocumentLoader {private final ResourcePatternResolver resourcePatternResolver;public DocumentLoader(ResourcePatternResolver resourcePatternResolver) {this.resourcePatternResolver = resourcePatternResolver;}public List<Document> loadDocuments() {List<Document> docs = new ArrayList<>();try {Resource[] resources = resourcePatternResolver.getResources("classpath:document/*.md");for (Resource resource : resources) {String filename = resource.getFilename();MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder().withHorizontalRuleCreateDocument(true).withIncludeCodeBlock(false).withIncludeBlockquote(false).withAdditionalMetadata("filename", filename).build();MarkdownDocumentReader reader = new MarkdownDocumentReader(resource, config);docs.addAll(reader.read());}} catch (IOException e) {log.error("Markdown 文档加载失败");}return docs;}
}上述代码中,我们通过 MarkdownDocumentReaderConfig 文档加载配置来指定读取文档的细节,比如是否读取代码块、引用块等。特别需要注意的是,我们还指定了额外的元信息配置,提取文档的文件名(fileName)作为文档的元信息 ,可以便于后续知识库实现更精确的检索。
3.向量转换和存储
@Configuration
public class VectorStoreConfig {@Resourceprivate DocumentLoader documentLoader;@Beanpublic VectorStore vectorStore(OpenAiEmbeddingModel embeddingModel) {SimpleVectorStore vectorStore = SimpleVectorStore.builder(embeddingModel).build();List<Document> documents = documentLoader.loadDocuments();vectorStore.add(documents);return vectorStore;}
}4.查询增强
Spring AI 通过 Advisor 特性提供了开箱即用的 RAG 功能。主要是 QuestionAnswerAdvisor 问答拦截器和 RetrievalAugmentationAdvisor 检索增强拦截器 ,前者更简单易用、后者更灵活强大。
查询增强的原理其实很简单。向量数据库存储着 AI 模型本身不知道的数据,当用户问题发送给 AI 模型时,QuestionAnswerAdvisor 会查询向量数据库,获取与用户问题相关的文档。然后从向量数据库返回的响应会被附加到用户文本中,为 AI 模型提供上下文,帮助其生成回答。
添加依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-advisors-vector-store</artifactId></dependency>编写controller
@RestController
@RequestMapping("/rag")
@Slf4j
public class RagController {@Resourceprivate ChatClient openAiChatClient;@Resourceprivate VectorStore vectorStore;@RequestMapping("/chatWithRag")public String chatWithRag(String message,String chatId) {ChatResponse response = openAiChatClient.prompt().user(message).advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId)).advisors(new QuestionAnswerAdvisor(vectorStore)).call().chatResponse();String result = response.getResult().getOutput().getText();log.info("result: {}", result);return result;}@RequestMapping("/chat")public String chat(String message,String chatId) {ChatResponse response = openAiChatClient.prompt().user(message).call().chatResponse();String result = response.getResult().getOutput().getText();log.info("result: {}", result);return result;}
}测试
首先测试没有使用RAG增强的接口


可以很明显看到AI回答的都不是最新的数据,接下测试使用了RAG增强的接口
AI回答数据


原始文档数据
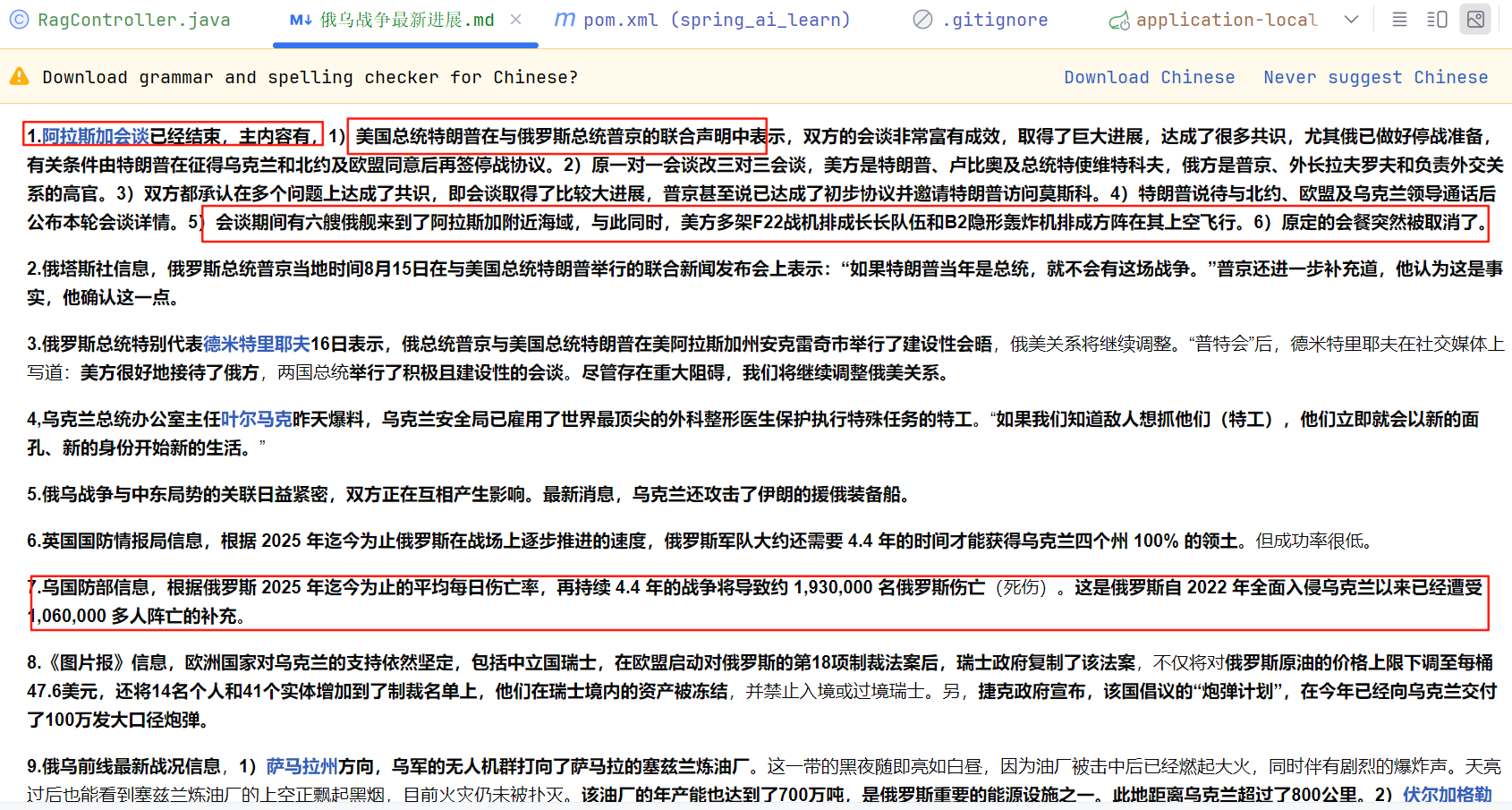
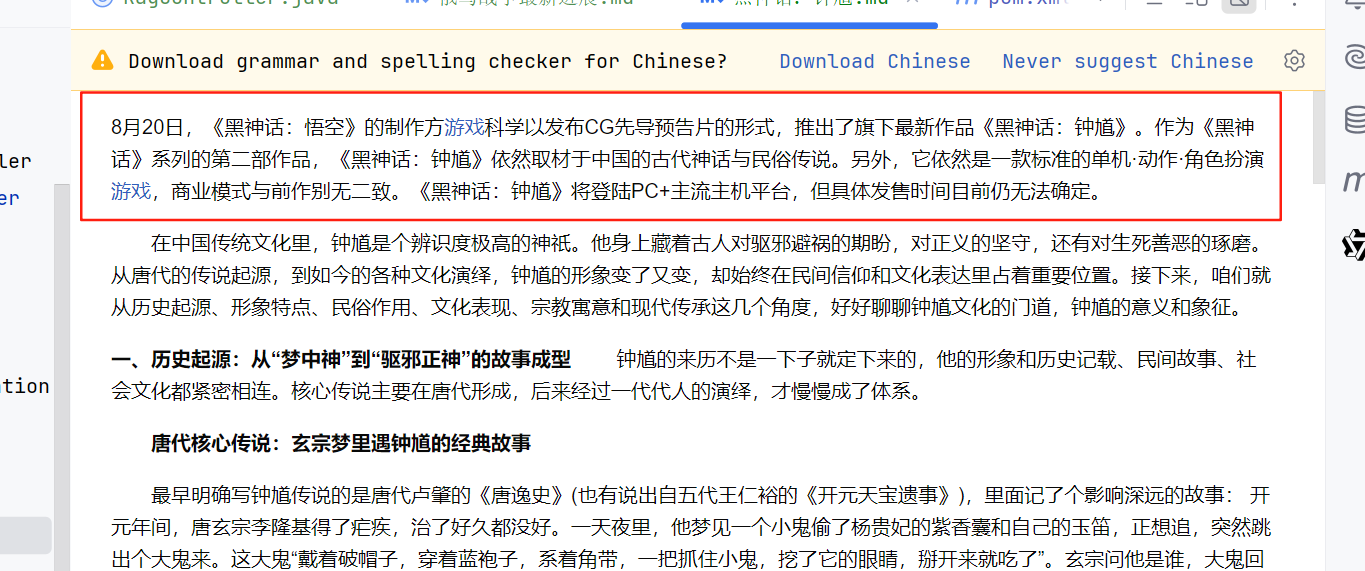
可以看到AI的回答内容都是出自我们提供的文档内容
MCP
什么是MCP
MCP(Model Context Protocol,模型上下文协议)是一种开放标准,目的是增强 AI 与外部系统的交互能力。MCP 为 AI 提供了与外部工具、资源和服务交互的标准化方式,让 AI 能够访问最新数据 、执行复杂操作,并与现有系统集成。
根据 官方定义,MCP 是一种开放协议,它标准化了应用程序如何向大模型提供上下文的方式。可以将 MCP 想象成 AI 应用的 USB 接口。就像 USB 为设备连接各种外设和配件提供了标准化方式一样,MCP 为 AI 模型连接不同的数据源和工具提供了标准化的方法。
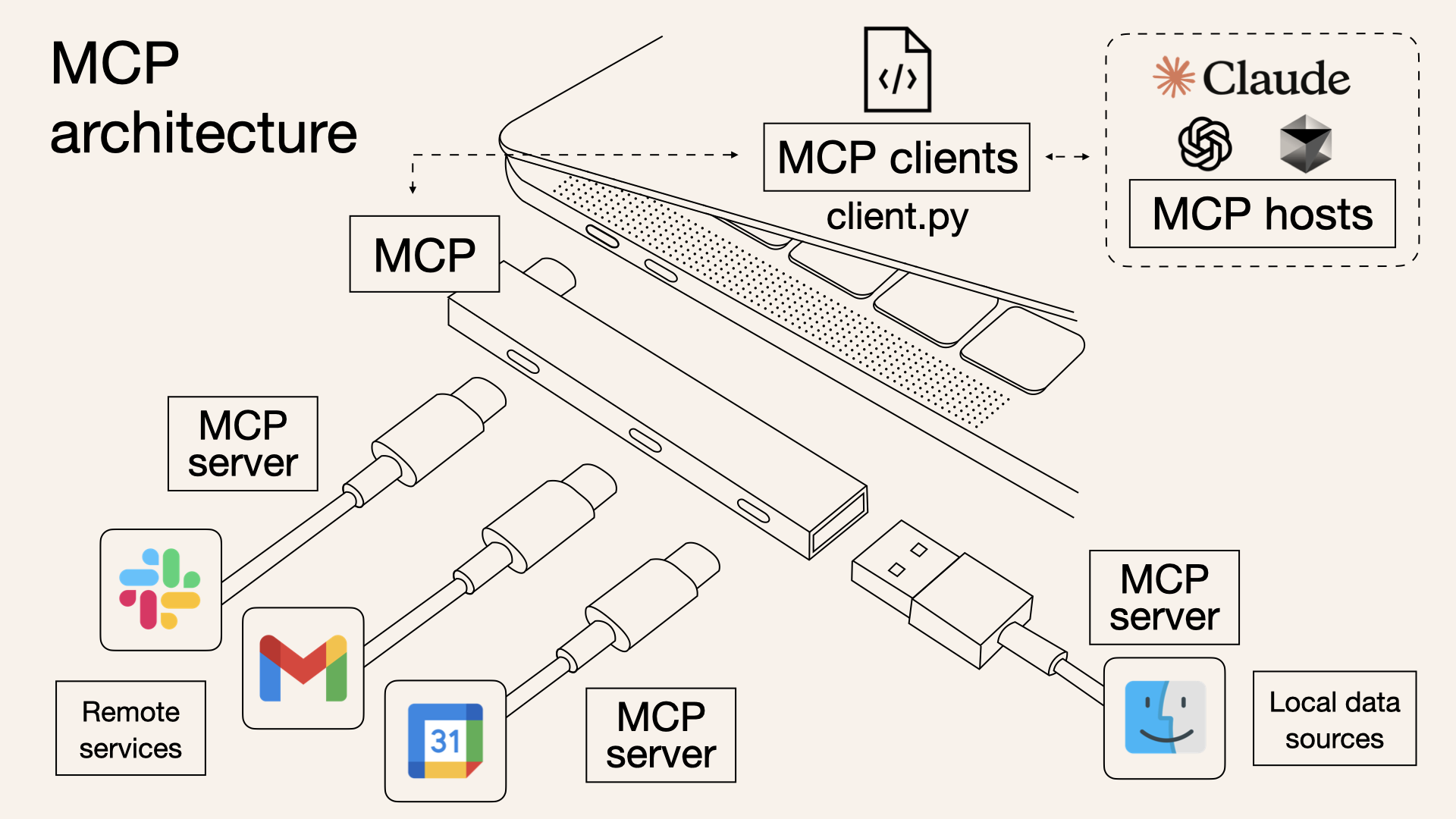
MCP架构
1.宏观架构
MCP 的核心是 “客户端 - 服务器” 架构,其中 MCP 客户端主机可以连接到多个服务器。客户端主机是指希望访问 MCP 服务的程序,比如 Claude Desktop、IDE、AI 工具或部署在服务器上的项目
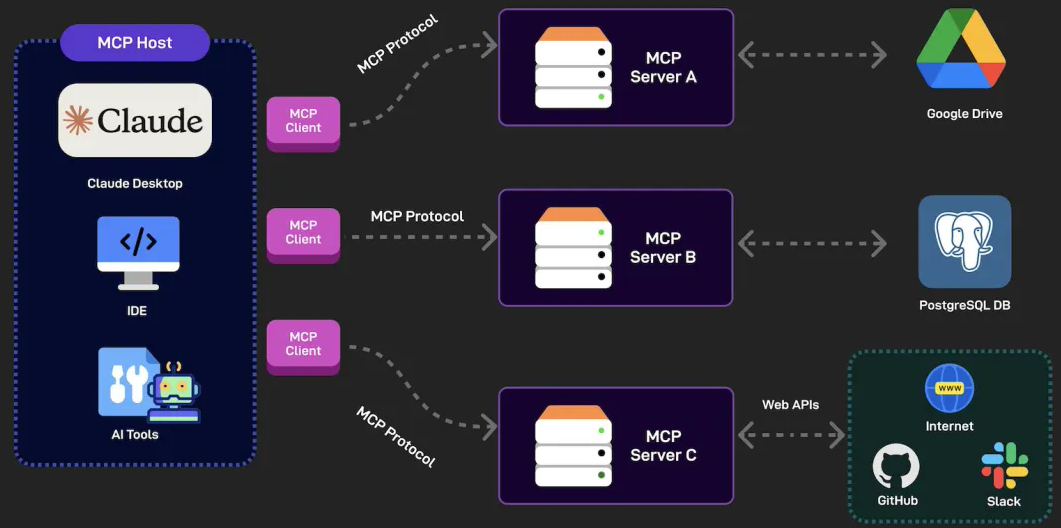
2.SDK 3 层架构
如果我们要在程序中使用 MCP 或开发 MCP 服务,可以引入 MCP 官方的 SDK,比如 Java SDK。让我们先通过 MCP 官方文档了解 MCP SDK 的架构,主要分为 3 层:
分别来看每一层的作用:
- 客户端 / 服务器层:McpClient 处理客户端操作,而 McpServer 管理服务器端协议操作。两者都使用 McpSession 进行通信管理。
- 会话层(McpSession):通过 DefaultMcpSession 实现管理通信模式和状态。
- 传输层(McpTransport):处理 JSON-RPC 消息序列化和反序列化,支持多种传输实现,比如 Stdio 标准 IO 流传输和 HTTP SSE 远程传输。
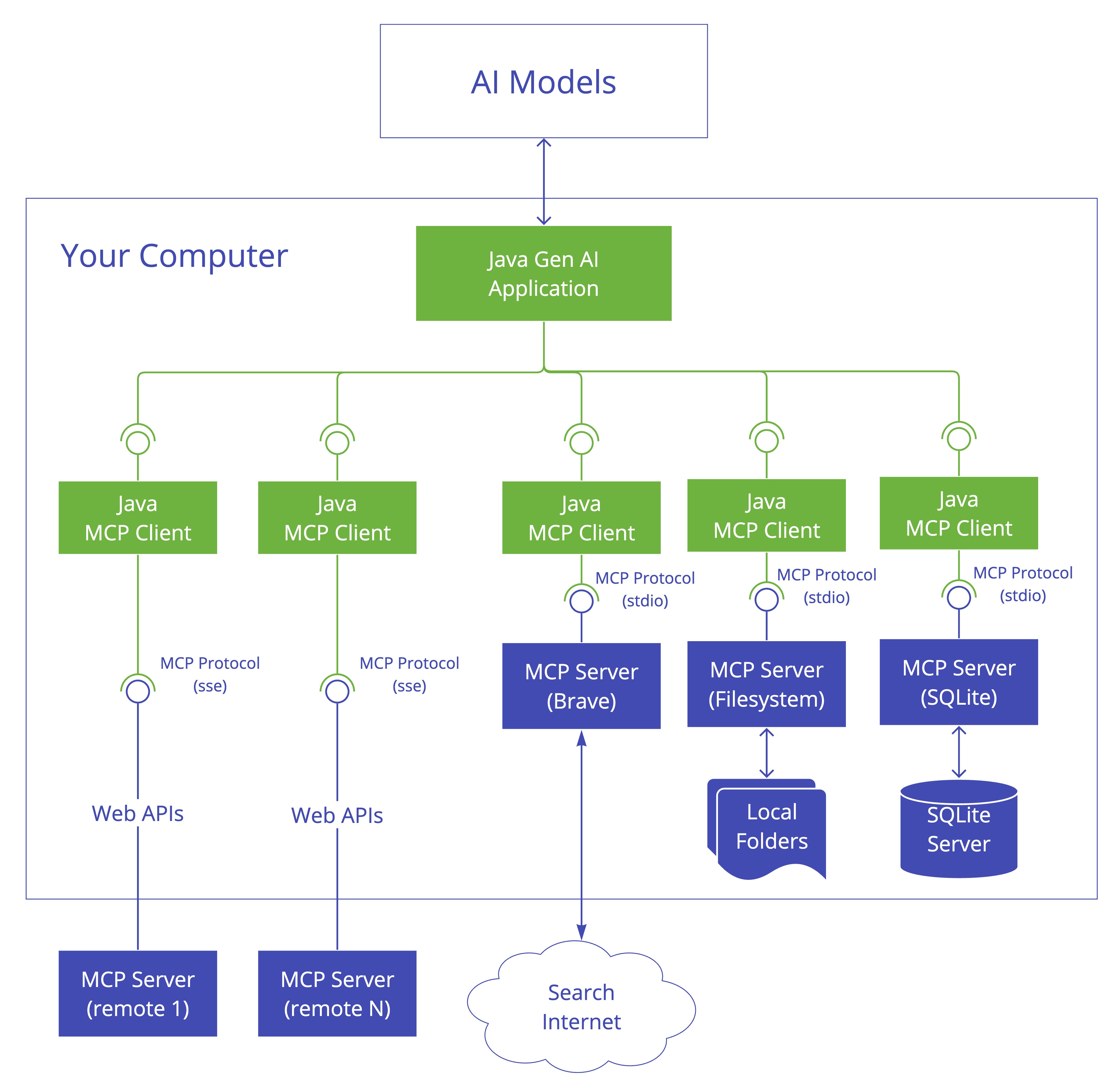
3.MCP 客户端
MCP Client 是 MCP 架构中的关键组件,主要负责和 MCP 服务器建立连接并进行通信。它能自动匹配服务器的协议版本、确认可用功能、负责数据传输和 JSON-RPC 交互。此外,它还能发现和使用各种 工具、管理资源、和提示词系统进行交互。
除了这些核心功能,MCP 客户端还支持一些额外特性,比如根管理、采样控制,以及同步或异步操作。为了适应不同场景,它提供 了多种数据传输方式,包括:
- Stdio 标准输入 / 输出:适用于本地调用
- 基于 Java HttpClient 和 WebFlux 的 SSE 传输:适用于远程调用
客户端可以通过不同传输方式调用不同的 MCP 服务,可以是本地的、也可以是远程的。 如图:
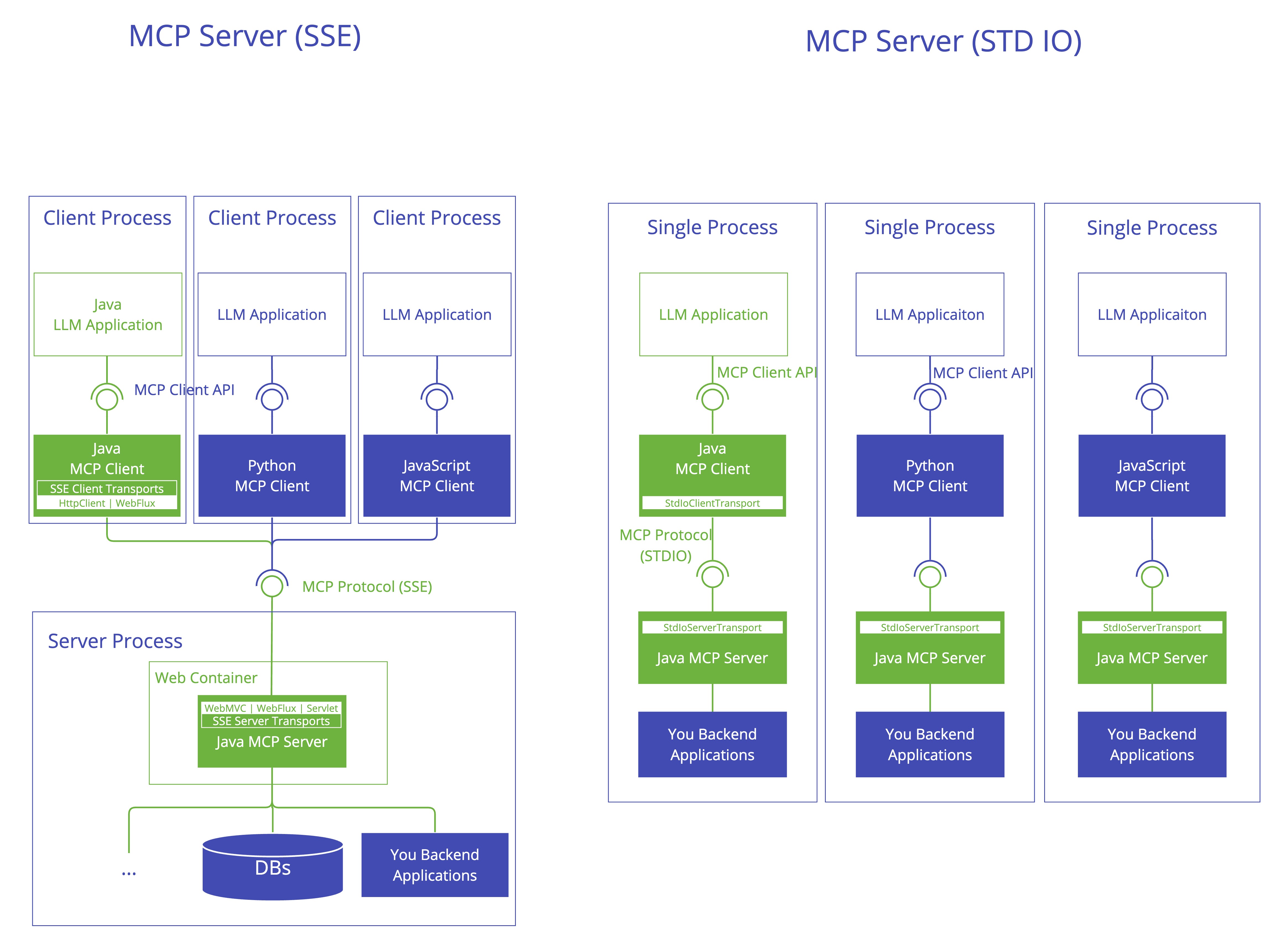
4.MCP 服务端
MCP Server 也是整个 MCP 架构的关键组件,主要用来为客户端提供各种工 具、资源和功能支持。
它负责处理客户端的请求,包括解析协议、提供工具、管理资源以及处理各种交互信息。同时,它还能记录日志、发送通知,并且支持多个客户端同时连接 ,保证高效的通信和协作。
和客户端一样,它也可以通过多种方式进行数据传输,比如 Stdio 标准输入 / 输出、基于 Servlet / WebFlux / WebMVC 的 SS E 传输,满足不同应用场景。
这种设计使得客户端和服务端完全解耦,任何语言开发的客户端都可以调用 MCP 服务。 如图:
Spring AI 使用 MCP 服务
接下实战接入高德地图 MCP 服务
第一步添加依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-client</artifactId></dependency>第二步获取api-key
登录高德地图开放平台
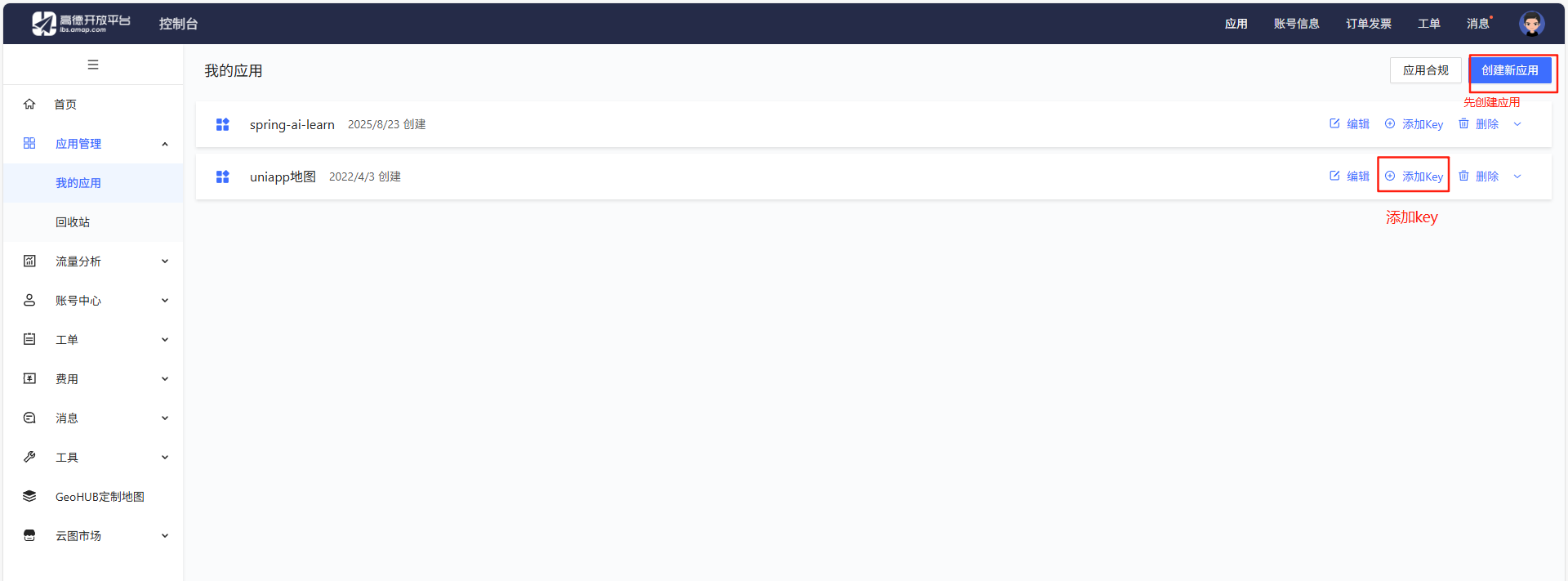
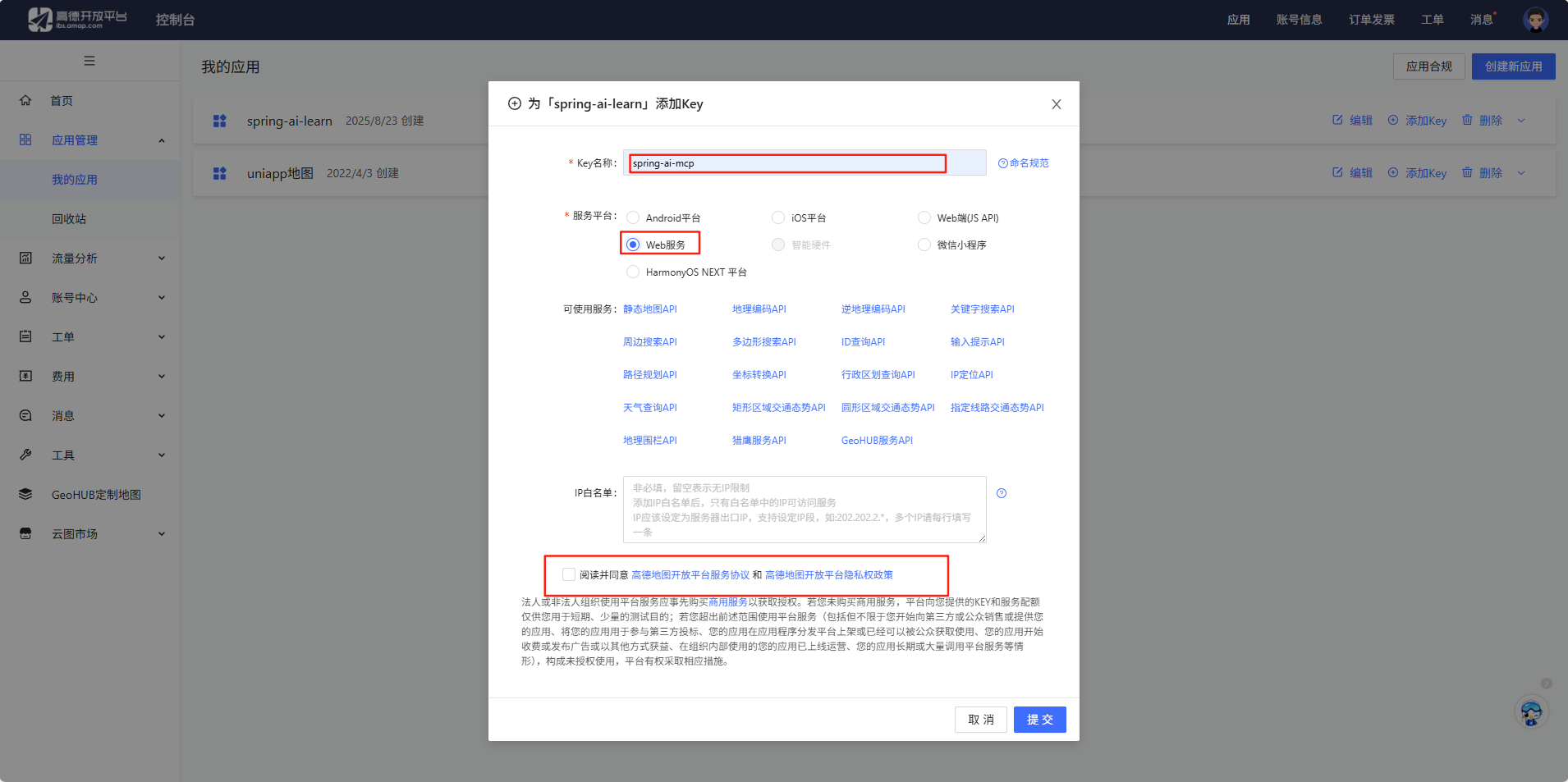
最后点提交就创建完成了
第三步编写配置文件
新建 mcp-servers.json 文件
{"mcpServers": {"amap-maps": {"command": "npx.cmd","args": ["-y","@amap/amap-maps-mcp-server"],"env": {"AMAP_MAPS_API_KEY": "e4ce1e74399e2135dd92ce8e8d0897c1"}}}
}修改 Spring 配置文件,编写 MCP 客户端配置。由于是本地运行MCP 服务,所以使用 stdio 模式,并且要指定 MCP服务配置文件的位置。
spring:ai:mcp:client:stdio:servers-configuration: classpath:mcp-servers.json第四步编写controller
通过自动注入的 ToolCallbackProvider 获取到配置中定义的 MCP 服务提供的 所有工具,并提供给 Chatclient。
@RestController
@RequestMapping("/mcp")
@Slf4j
public class McpController {@Resourceprivate ChatClient openAiChatClient;@Resourceprivate ToolCallbackProvider toolCallbackProvider;@RequestMapping("/chat")public String chat(String message) {ChatResponse response = openAiChatClient.prompt().user(message).call().chatResponse();String result = response.getResult().getOutput().getText();log.info("result: {}", result);return result;}@RequestMapping("/chatWithMcp")public String chatWithMcp(String message) {ChatResponse response = openAiChatClient.prompt().user(message).advisors(new MySimpleLogAdvisor()).toolCallbacks(toolCallbackProvider).call().chatResponse();String result = response.getResult().getOutput().getText();log.info("result: {}", result);return result;}
}第五步测试
不使用 MCP 服务的调用
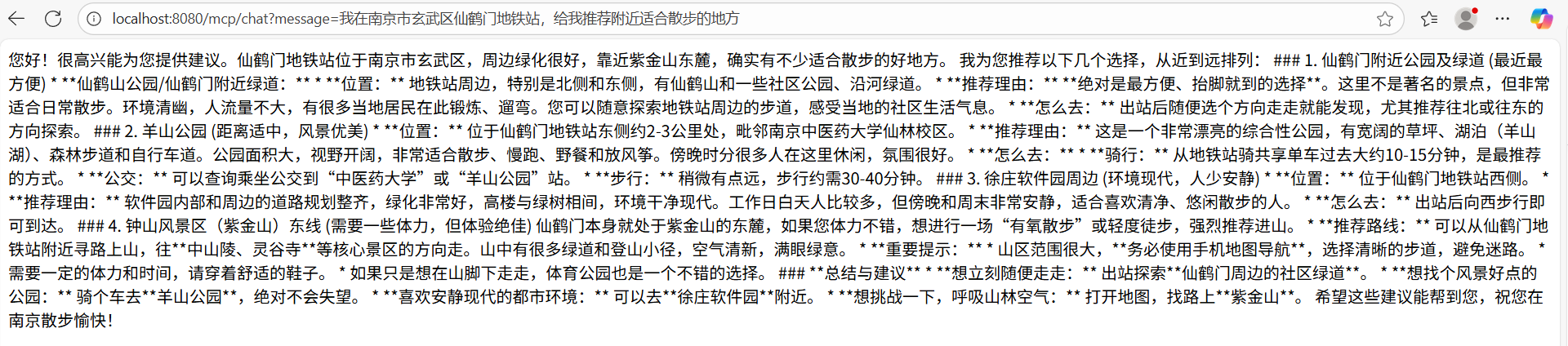
使用 MCP 服务的调用

尽管两次调用 AI 都能给出相关的回答,但是可以明显看到第二次使用 MCP 服务的调用,AI 的回答更加精确一些。
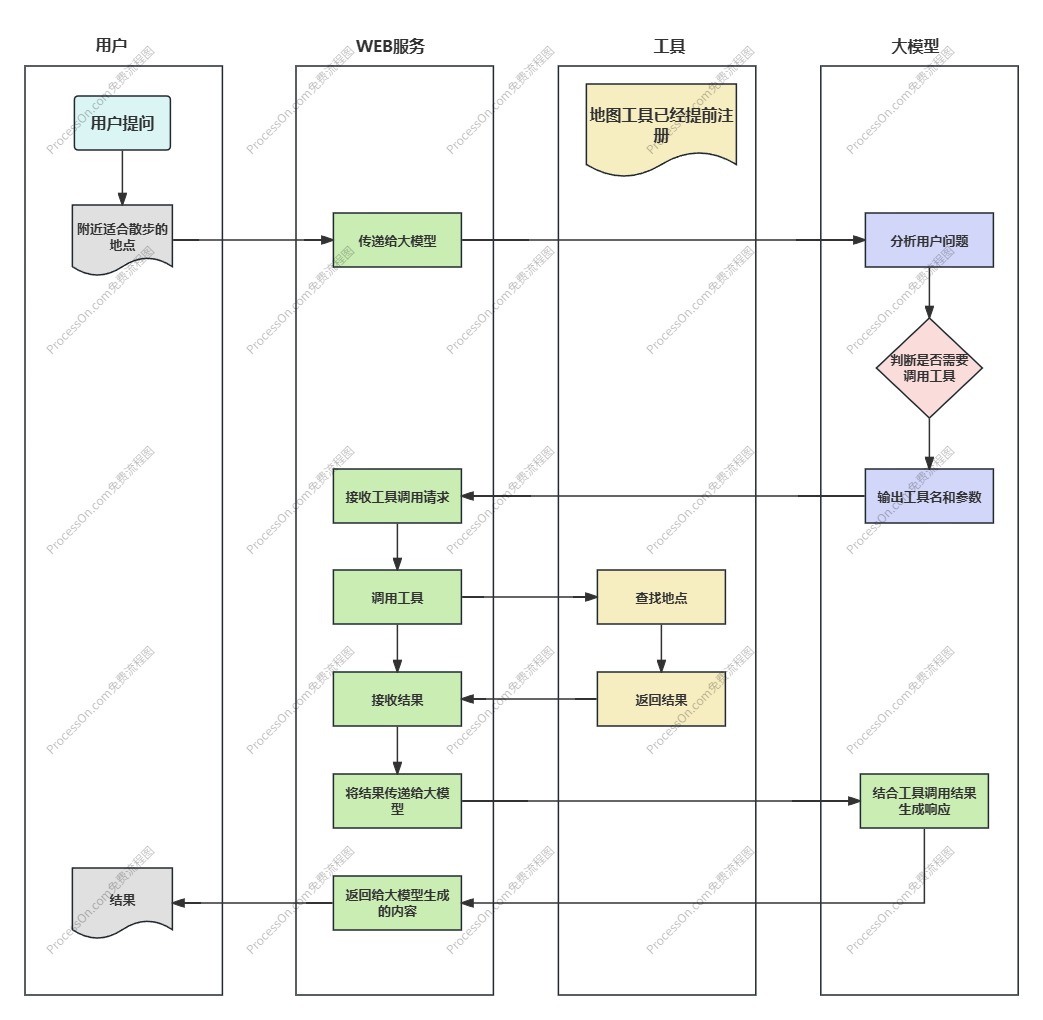
MCP 调用的本质就是类似工具调用,并不是让 AI 服务主动去调用 MCP 服务,而是告诉 AI "MCP 服务提供了哪些工具”,如果 AI 想要使用这些工具完成任务,就会告诉我们的后端程序,后端程序在执行工具后将结果返回给 AI,最后由 AI 总结并回复。
Spring AI 开发 MCP 服务
第一步引入依赖
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>这里选择基于Spring MVC的SSE传输实现实现方式。
第二步添加配置文件
mcp:server:name: weather-mcp-serversse-message-endpoint: /mcp/weatherversion: 1.0.0type: sync第三步开发服务
开发 MCP 服务的过程跟开发工具调用一样,直接使用 @Tool 注解标记服务类中的方法。
@Service
public class WeatherService {@Tool(description = "获取指定城市的天气信息")public String getWeather(@ToolParam(description = "城市名称,如北京、上海") String cityName) {// 实现天气查询逻辑return "城市" + cityName + "的天气是晴天,温度22°C";}
}第四步注册服务
@Configuration
public class ToolCallbackProviderConfig {@Beanpublic ToolCallbackProvider weatherCallbackProvider(WeatherService weatherService) {return MethodToolCallbackProvider.builder().toolObjects(weatherService).build();}
}第五步使用服务
@Resource@Qualifier("mcpToolCallbacks")private ToolCallbackProvider toolCallbackProvider;@Resource@Qualifier("weatherCallbackProvider")private ToolCallbackProvider weatherCallbackProvider;一定要这么写,否则启动项目会报错
@RequestMapping("/chatWithMcp")public String chatWithMcp(String message) {ChatResponse response = openAiChatClient.prompt().user(message).advisors(new MySimpleLogAdvisor()).toolCallbacks(weatherCallbackProvider) //注意这里改了.call().chatResponse();String result = response.getResult().getOutput().getText();log.info("result: {}", result);return result;}测试

文章中的所有代码都可以在代码仓库中获取