阿里云大模型应用实战:从技术落地到业务提效
一、前言
老周这次受邀作为嘉宾参加了AICon全球人工智能开发与应用大会,后续会对自己的听完的一些思考与总结分享给大家。
本文将基于阿里云智能蒋林泉老师在AICon大会的演讲内容,深入探讨企业级大模型应用的实战经验,分享从技术落地到业务提效的全过程方法论。

二、企业AI应用的现状与挑战
当前企业AI应用面临两大核心矛盾:
1、技术相对过剩:AI技术快速发展,各种模型和工具层出不穷
2、落地严重不足:真正能产生业务价值的应用案例仍然有限
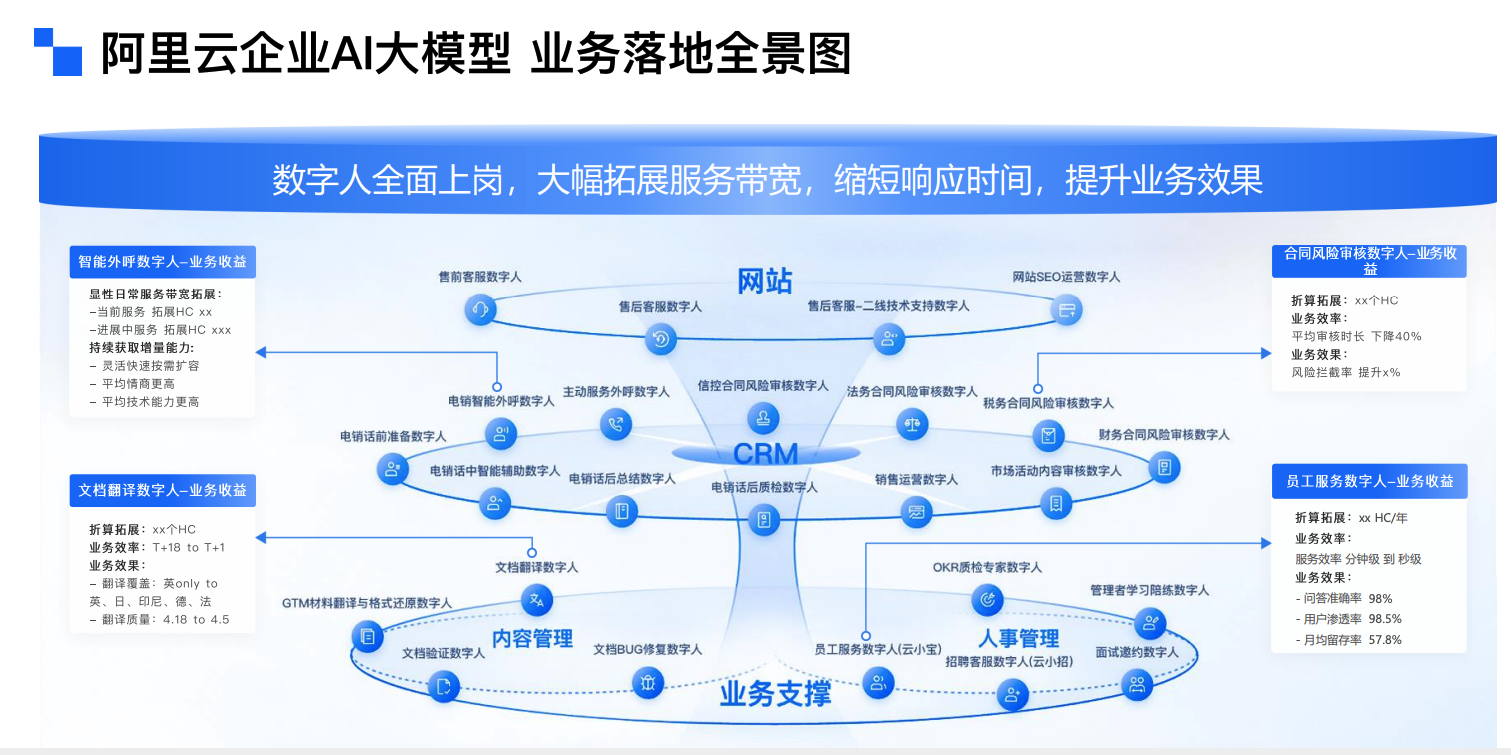
以阿里云员工服务数字人应用为例,成功落地后可以带来显著效益:
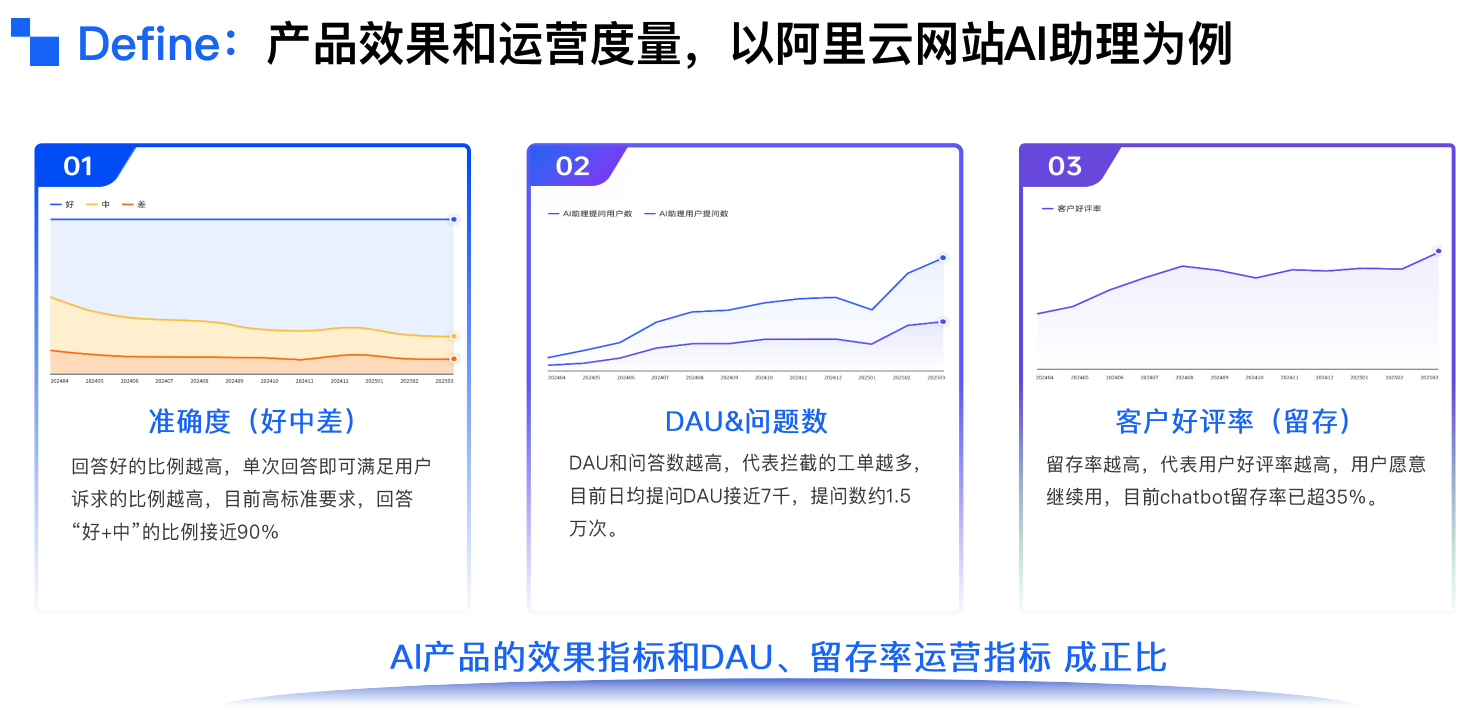
- 问答准确率达到98%
- 用户渗透率98.5%
- 月均留存率57.8%
这些数据证明,当AI应用真正解决业务痛点时,能够创造巨大价值。数字人倒是一个好落地的应用场景,业界落地成功的应用实践无非就是ChatBox、ChatBI、数字人等。但我认为更重要的是那些核心的应用场景还没完全落地,比如AI与医疗、自动驾驶,如果哪天自动驾驶能全民应用的话,那我可以说AI真正走到了顶峰的阶段。
三、RIDE方法论:企业级大模型落地的完整框架
云计算服务模型的三大基础范式:SaaS(软件即服务)、PaaS(平台即服务)、IaaS(基础设施即服务);而新兴服务范式,像MaaS(模型即服务)、RaaS(结果即服务)开始快速崛起了。
阿里智能云提出了RIDE方法论,系统化指导大模型在企业中的落地应用:
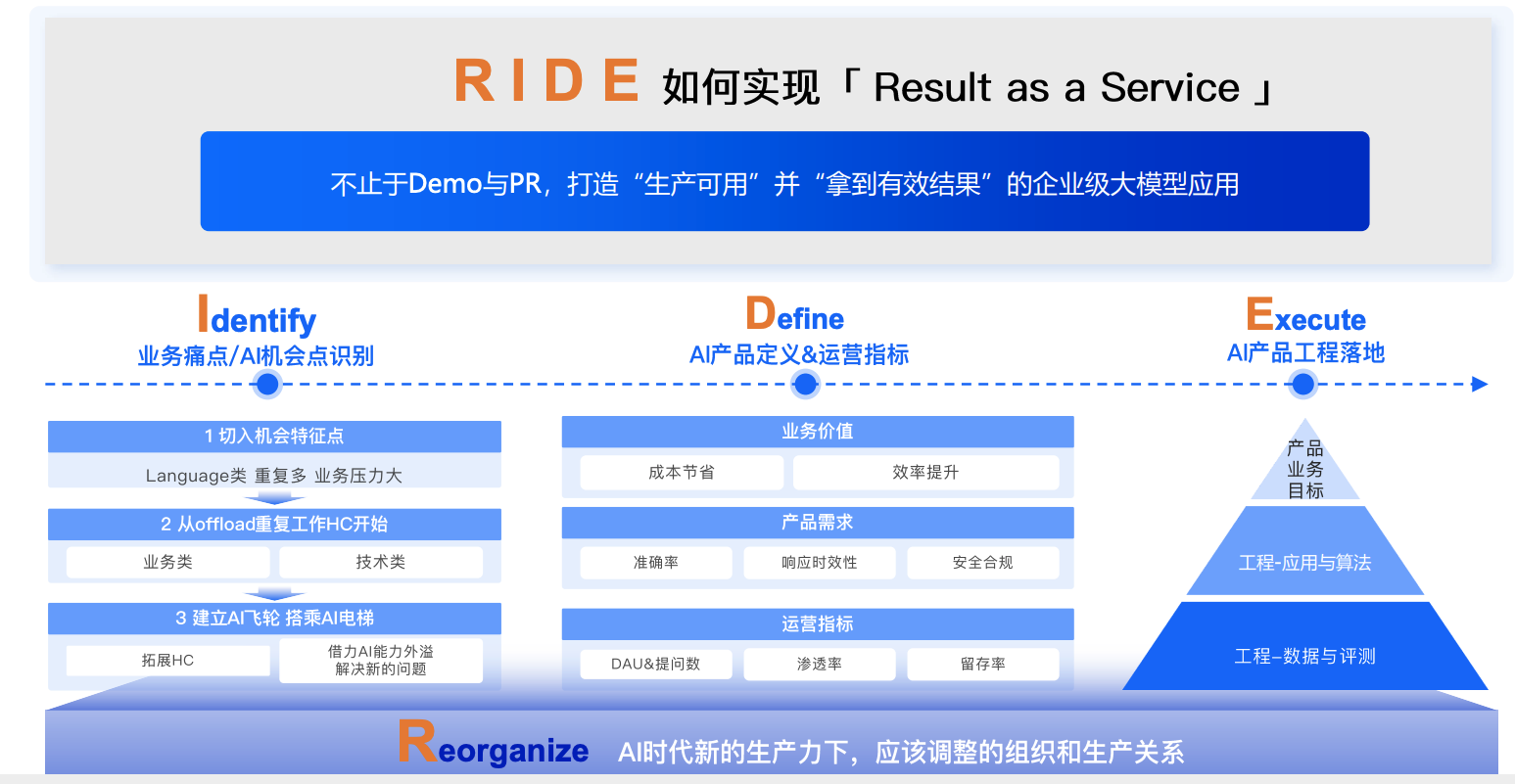
1、Identify(识别机会)
- 深入业务场景,识别真正能产生价值的AI应用点
- 避免为了AI而AI,确保每个项目都有明确的业务目标
2、Define(定义产品)
- 明确产品形态和核心功能
- 制定可量化的运营指标
- 确定技术实现路径

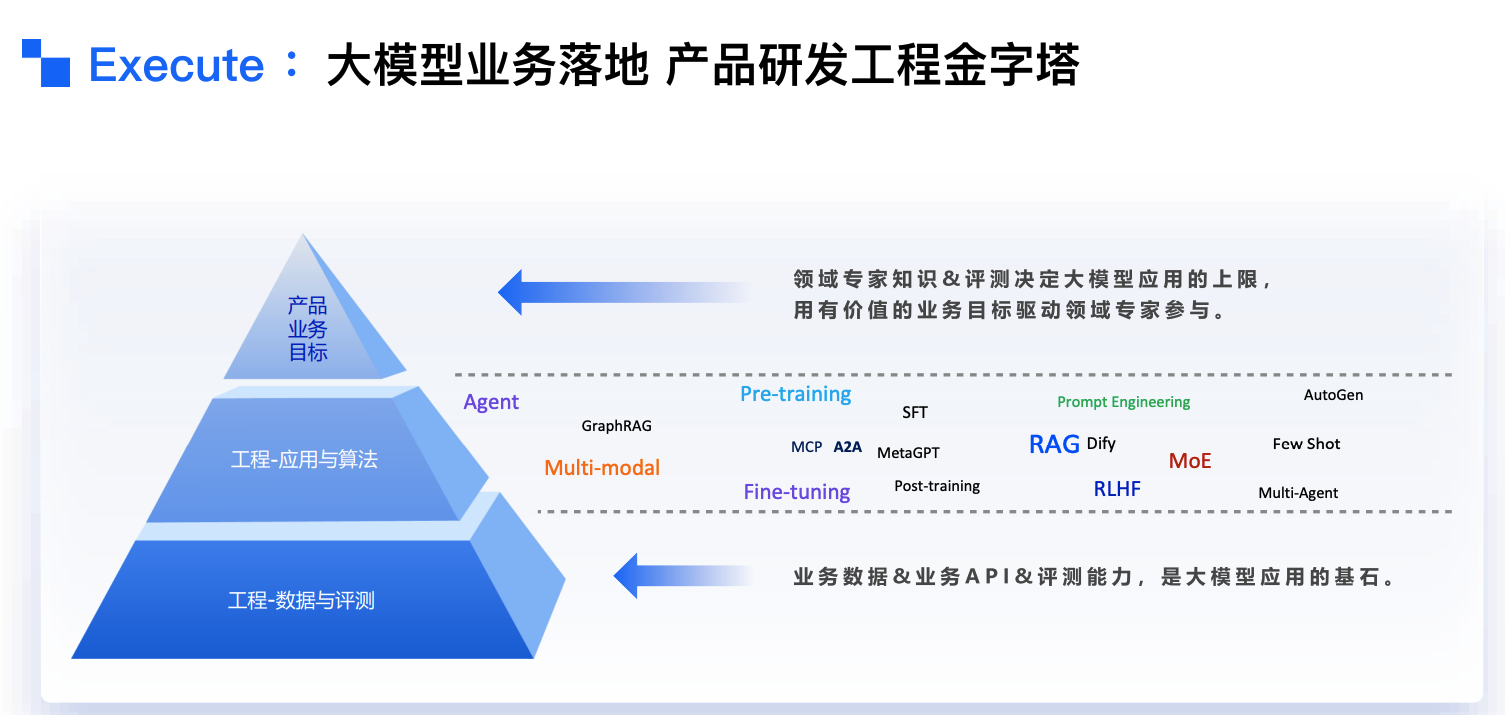
3、Execute(工程实现)
包含两大技术方向:
- 工程-应用与算法:Agent、GraphRAG、Multi-modal等技术应用
- 工程-数据与评测:Pre-training、SFT、RLHF等模型优化方法
4、Reorganize(组织重构)
- 调整组织架构适应AI转型
- 建立跨部门协作机制
- 培养员工AI技能
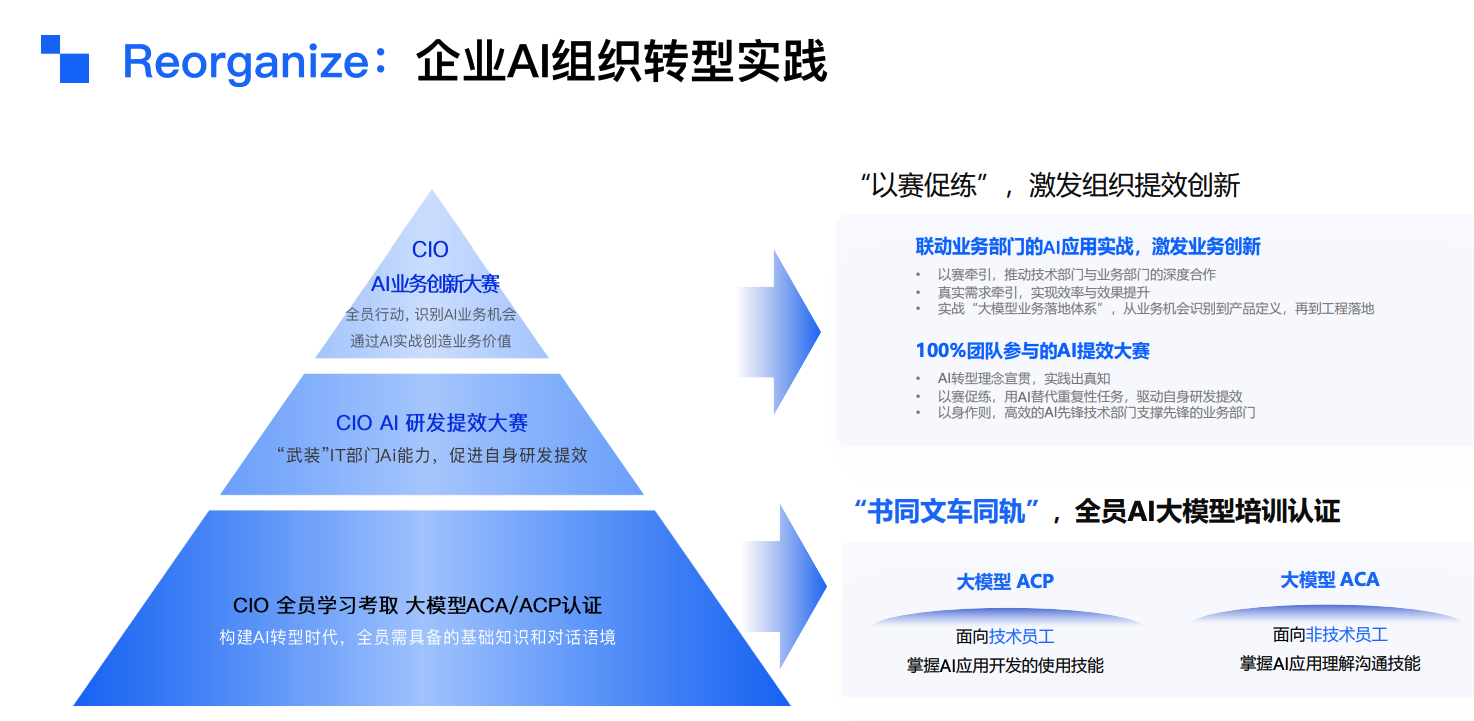
这里我不太苟同,全员学习考取大模型ACA/ACP认证、“书同文车同轨”,理念都没有错,只不过不适合小公司,小公司哪有那么多人力、物力、财力去搞这些东西,基本上都是先生存下来再说。
四、技术落地实战:从简单到复杂的两种模式
1、翻译模式
- 相对简单的集成方式
- 依赖原有系统的良好基础(“蛋糕胚”)
- 适合已有成熟系统的场景优化
2、Agent模式
- 复杂的智能体系统
- 需要建立完整的度量体系
- 适合创新性业务场景

这里蒋林泉老师用的一个比喻我觉得还挺好,他把翻译比作“樱桃”,原来的系统比作“蛋糕坯”,比如我想要个樱桃蛋糕,不光要有LLM的翻译模式,而且还要有好的“蛋糕坯”,原来系统的语言处理能力不行的话,樱桃蛋糕你是大概率做不出来的,即使做出来了,也是一个残次品。
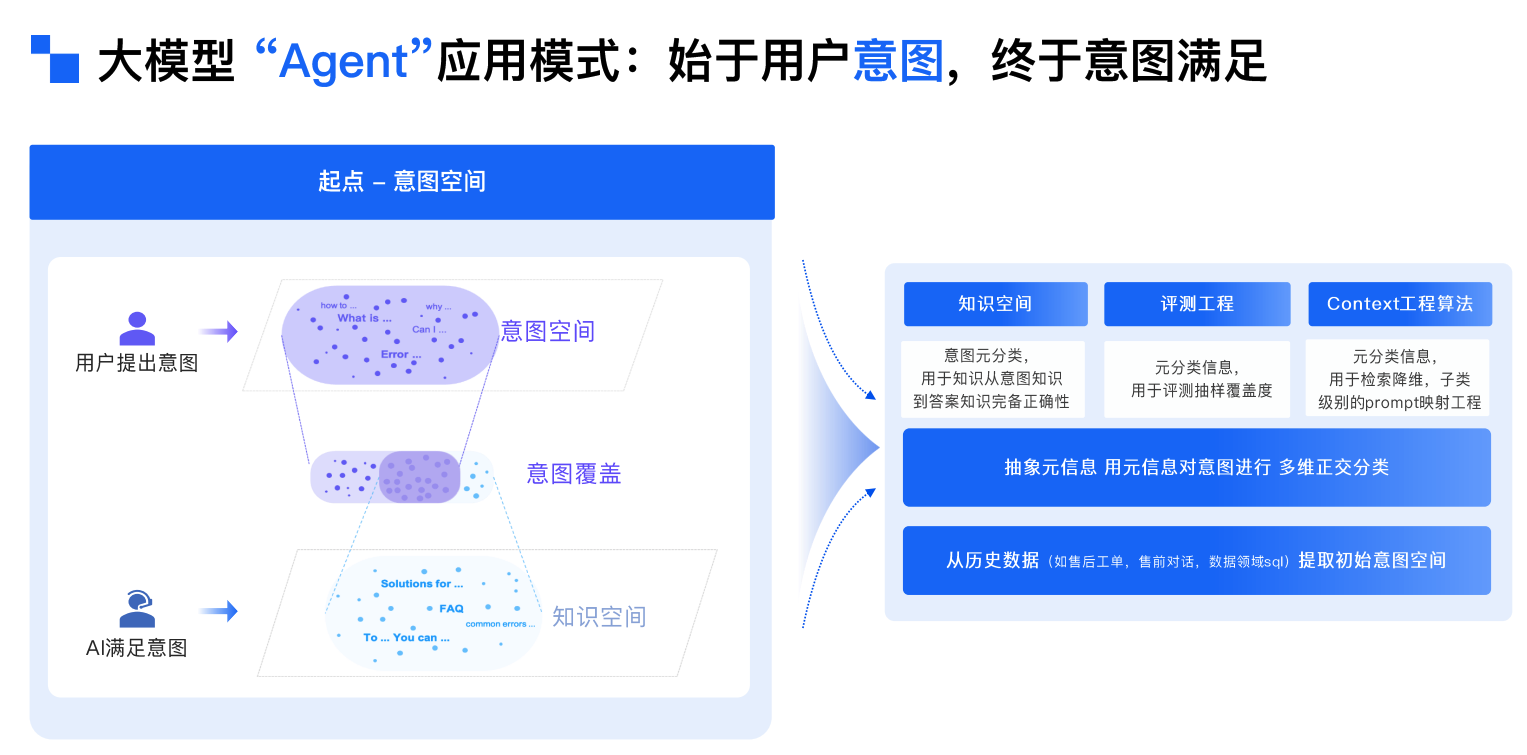
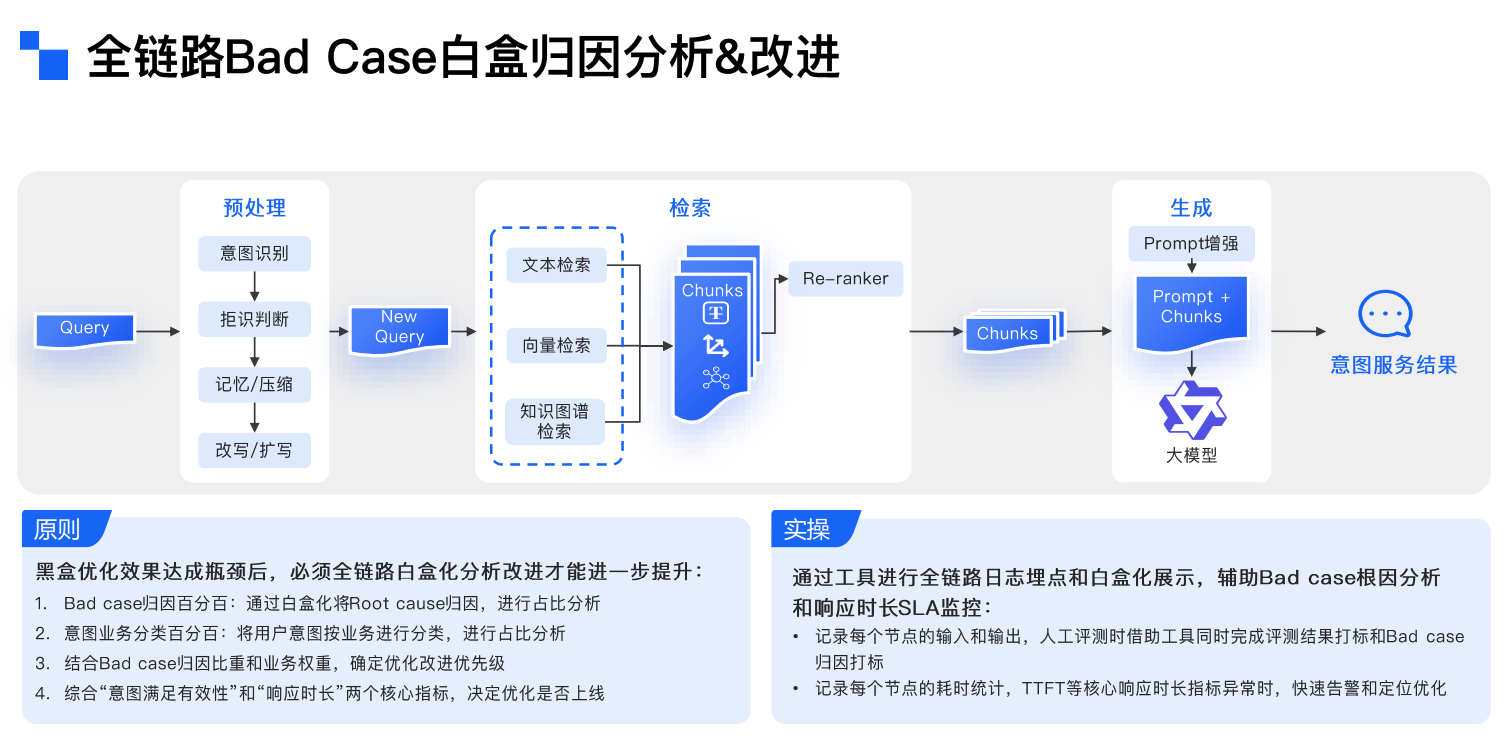
以Agent模式为例,落地过程效果不好的原因分布:
在Agent模式的落地实践中,效果不佳往往源于多环节的协同失效。尽管业务知识处理(如Markdown化、语义分段)和用户意图识别(含拒识、多路召回)各占15%工作量,大模型总结环节的Prompt优化与微调仅占10%,但真正的瓶颈在于业务知识体系构建与全链路归因分析,这一核心环节消耗了60%的精力——当知识库的完备性与准确性不足时,即使前端的意图识别再精准、模型微调再精细,最终输出的结果仍会偏离业务预期。这揭示了一个关键规律:Agent系统的效能上限取决于知识基建的扎实程度,而非单纯的技术堆砌。

五、关键决策:何时引入模型训练?
一个常见问题是:什么时候该引入模型训练?
什么时候该引入模型训练?什么时候要做SFT,什么时候要搞RL? 一个常被讨论的问题 : 要不要搞Pre-training ?
对于常规业务场景,建议优先采用白盒RAG(检索增强生成)和Context Engineering(上下文工程)等无需模型微调的技术方案,这类方法能快速响应需求且成本可控。当遇到特殊业务场景或拥有充足领域数据时,可考虑Pre-training(预训练),但需评估其高昂的计算资源消耗是否与预期收益匹配。针对特定任务优化需求,SFT(监督微调)能有效提升模型在细分领域的表现;而在需要复杂决策交互的场景(如对话策略优化),RL(强化学习)则能通过环境反馈实现更智能的响应。整体而言,应遵循"能用非训练方案则不用,必须训练时按需选择"的原则,平衡效果与成本。
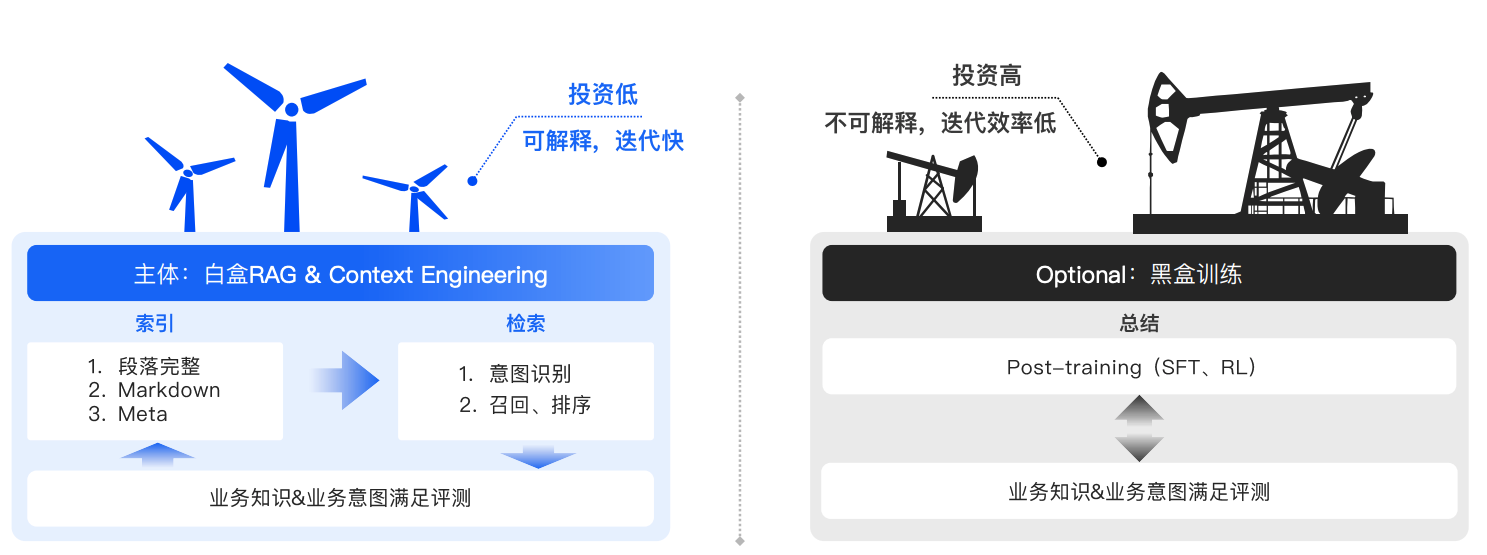
建议采取以下策略:
1、主体:优先采用白盒RAG和Context Engineering
2、可选:根据需求考虑黑盒训练
- 当业务需求特殊且数据充足时考虑Pre-training
- 特定场景优化考虑SFT
- 复杂交互场景考虑RL
六、结语:AI驱动的企业未来
下面是阿里智能云提供的一站式关于AI创新的业务整体架构:
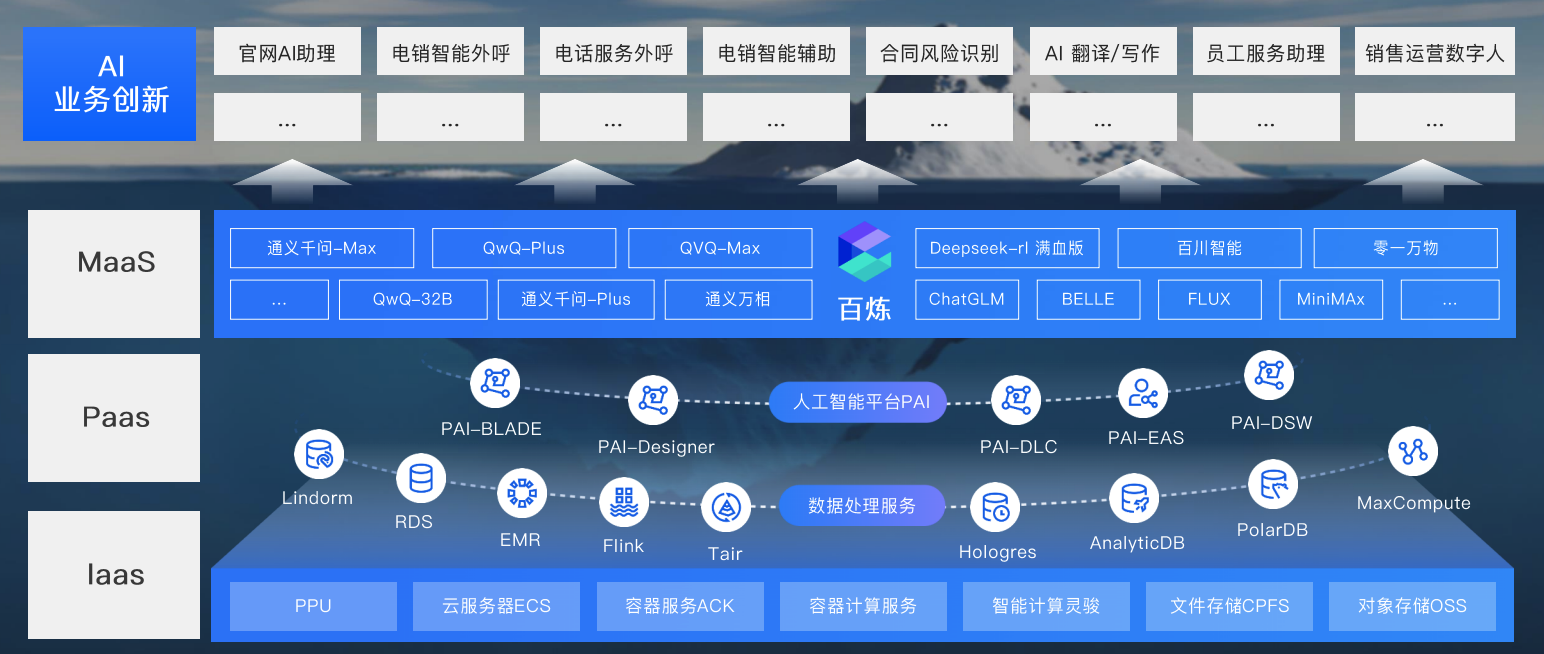
这里还是小结下:
企业级大模型应用已经从概念验证阶段进入实际生产阶段。通过RIDE方法论的系统指导,结合翻译模式和Agent模式的灵活选择,企业可以有效地将AI技术转化为业务价值。同时,组织层面的全员AI转型和人才培养同样重要,只有技术与组织双轮驱动,才能真正实现AI时代的数字化转型。
未来,随着技术的不断进步,企业AI应用将更加深入和广泛。我们期待看到更多企业通过大模型技术实现业务创新和效率提升,共同推动产业智能化进程。
PS:文中的图片均来自现场拍摄以及PPT中的内容