使用 LangGraph + Zep 打造一款有记忆的心理健康关怀机器人
在构建对话式 AI 时,我们常常会遇到一个难题:如何让机器人真正记住用户的历史对话和个人信息,从而提供更贴心、更个性化的交流体验?
这篇文章将带你一步步解析,如何结合 LangGraph、Zep 和 阿里云通义千问(ChatTongyi),打造一个有长期记忆、能够提供 心理健康关怀 的聊天机器人。
项目背景
一个简单的 ChatBot 往往是「无记忆的」:
每次对话都像重新开始;
用户需要不断重复自己的情况;
机器人无法积累上下文,显得生硬。
而在心理健康场景中,这样的体验显然不够好。我们希望机器人能够:
1. 记住用户的名字和历史对话
2. 从对话中提取事实和知识点
3. 在回应时体现理解和共情
技术选型
本项目使用的技术栈包括:
LangGraph:基于有向图的对话编排工具,可以灵活定义 Agent 流程。
Zep:AI 对话的长期记忆存储库,支持对话存档、事实提取、语义搜索。
ChatTongyi(通义千问):强大的中文大模型,用于生成 empathetic(有同理心的)回复。
LangChain 工具机制:将搜索、检索等功能包装为工具,Agent 可根据需要调用。
核心代码解析
1. 定义对话状态
我们通过 TypedDict 定义状态 State,包括消息列表、用户基本信息和线程 ID:
class State(TypedDict):messages: Annotated[list, add_messages]first_name: strlast_name: strthread_id: struser_name: str
这里 messages 会保存当前对话轮次,thread_id 和 user_name 则确保了每个用户的上下文独立。
2. 接入工具:Zep 搜索
Zep 提供了强大的记忆功能,可以从历史对话中提取 事实 (facts) 和 节点 (nodes)。
@tool
async def search_facts(state: State, query: str, limit: int = 5) -> list[str]:search_result= zep.graph.search(user_id=state["user_name"], query=query, limit=limit, scope="edges")edges = search_result.edgesreturn [edge.fact for edge in edges]
当 Agent 需要查询用户的历史对话时,可以调用这些工具进行知识检索。
3. 定义聊天逻辑
核心的 chatbot 函数会:
从 Zep 中加载用户上下文;
加入系统提示(强调心理健康关怀语气);
调用大模型生成回复;
将新的对话保存到 Zep;
截断历史消息,避免无限膨胀。
async def chatbot(state: State):memory = zep.thread.get_user_context(state["thread_id"])system_message = SystemMessage(content=f"""You are a compassionate mental health bot and caregiver...{memory.context}""")messages = [system_message] + state["messages"]response = await llm.ainvoke(messages)# 保存对话zep.thread.add_messages(thread_id=state["thread_id"], messages=messages_to_save)# 截断历史消息,依赖 Zep 提取的 Facts 维持长期记忆state["messages"] = trim_messages(state["messages"], ...)return {"messages": [response]}
这种做法的好处是:
👉 历史消息不会无限增长(节省内存 & 提高性能);
👉 长期记忆交给 Zep 来维护,机器人依然能「记住」过去。
4. LangGraph 组装对话流程
我们用 StateGraph 将 Agent 和工具节点拼接成一个完整的工作流:
graph_builder = StateGraph(State)
graph_builder.add_node("agent", chatbot)
graph_builder.add_node("tools", tool_node)graph_builder.add_edge(START, "agent")
graph_builder.add_conditional_edges("agent", should_continue, {"continue": "tools", "end": END})
graph_builder.add_edge("tools", "agent")graph = graph_builder.compile(checkpointer=memory)
用户发消息 → 进入
agent节点(大模型回复);如果模型调用了工具 → 跳转到
tools节点;工具执行完后再回到
agent;如果没有工具调用 → 对话结束。
这种编排方式非常灵活,便于扩展。
5. 启动对话
最后,通过 graph_invoke 运行完整对话:
async def graph_invoke(message: str, first_name: str, last_name: str, thread_id: str):r = await graph.ainvoke({"messages": [{"role": "user", "content": message}],"first_name": first_name,"last_name": last_name,"thread_id": thread_id,})return r["messages"][-1].content
控制台交互效果如下:
🧑 User: 我最近压力很大,总是睡不好。
🤖 Assistant: 我理解你的感受,失眠确实让人很难受。也许可以尝试一些放松的呼吸练习,我愿意陪你一起慢慢改善。
总结与展望
通过 LangGraph + Zep + ChatTongyi,我们成功实现了一个带长期记忆的心理健康机器人,它不仅能记住用户,还能用共情的语气进行支持性回应。
未来可以继续扩展的方向包括:
集成情绪分析(Sentiment Analysis),动态调整回复语气;
支持多模态输入(语音、表情);
与心理健康资源库对接,提供更专业的建议。
这类机器人并不能替代心理医生,但它们可以作为 24/7 的温暖陪伴,为用户带来一份安心。
完整代码
import asyncio
import traceback
import uuid
from typing import Annotatedfrom dotenv import load_dotenv
from typing_extensions import TypedDict
from langchain_community.chat_models import ChatTongyi
import os
from langchain_core.messages import AIMessage, SystemMessage, trim_messages, HumanMessage
from langchain_core.tools import tool
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import END, START, StateGraph, add_messages
from langgraph.prebuilt import ToolNodefrom zep_cloud import AsyncZep, Message, Zepclass State(TypedDict):messages: Annotated[list, add_messages]first_name: strlast_name: strthread_id: struser_name: str@tool
def search_facts(state: State, query: str, limit: int = 5) -> list[str]:"""Search for facts in all conversations had with a user.Args:state (State): The Agent's state.query (str): The search query.limit (int): The number of results to return. Defaults to 5.Returns:list: A list of facts that match the search query."""print("starting to call search facts method", state)search_result = zep.graph.search(user_id=state["user_name"], query=query, limit=limit, scope="edges")edges = search_result.edgesreturn [edge.fact for edge in edges]@tool
async def search_nodes(state: State, query: str, limit: int = 5) -> list[str]:"""Search for nodes in all conversations had with a user.Args:state (State): The Agent's state.query (str): The search query.limit (int): The number of results to return. Defaults to 5.Returns:list: A list of node summaries for nodes that match the search query."""print("starting to call search node method", state)search_result = zep.graph.search(user_id=state["user_name"], query=query, limit=limit, scope="nodes")nodes = search_result.nodesreturn [node.summary for node in nodes]load_dotenv(override=True)
ZEP_API_KEY = os.getenv("ZEP_API_KEY")
# zep = AsyncZep(api_key=ZEP_API_KEY)
zep = Zep(api_key=ZEP_API_KEY)
TONGYI_API_KEY = os.getenv("TONGYI_API_KEY")llm = ChatTongyi( model="qwen-plus", api_key=TONGYI_API_KEY)tools = [search_facts, search_nodes]
tool_node = ToolNode(tools)
# llm = llm.bind_tools(tools)async def chatbot(state: State):memory = zep.thread.get_user_context(state["thread_id"])system_message = SystemMessage(content=f"""You are a compassionate mental health bot and caregiver. Review information about the user and their prior conversation below and respond accordingly.Keep responses empathetic, concise and supportive. And remember, always prioritize the user's well-being and mental health.{memory.context}""")messages = [system_message] + state["messages"]response = await llm.ainvoke(messages)if not response.tool_calls:# Add the new chat turn to the Zep graphmessages_to_save = []for message in messages:if isinstance(message, HumanMessage):messages_to_save.append(Message( role="user", name=state["user_name"], content=message.content,),)messages_to_save.append(Message(role="assistant", content=response.content))zep.thread.add_messages( thread_id=state["thread_id"], messages=messages_to_save,)# Truncate the chat history to keep the state from growing unbounded# In this example, we going to keep the state small for demonstration purposes# We'll use Zep's Facts to maintain conversation contextstate["messages"] = trim_messages( state["messages"], strategy="last", token_counter=len,max_tokens=3, start_on="human", end_on=("human", "tool"), include_system=True,)else:for tool_call in response.tool_calls:tool_call["args"]["state"]["first_name"] = state["first_name"]tool_call["args"]["state"]["last_name"] = state["last_name"]tool_call["args"]["state"]["user_name"] = state["user_name"]tool_call["args"]["state"]["thread_id"] = state["thread_id"]return {"messages": [response]}# Define the function that determines whether to continue or not
async def should_continue(state, config):messages = state["messages"]last_message = messages[-1]# If there is no function call, then we finish# print("tool calls",last_message.tool_calls)if not last_message.tool_calls:return "end"# Otherwise if there is, we continueelse:return "continue"graph_builder = StateGraph(State)memory = MemorySaver()graph_builder.add_node("agent", chatbot)
graph_builder.add_node("tools", tool_node)graph_builder.add_edge(START, "agent")
graph_builder.add_conditional_edges("agent", should_continue, {"continue": "tools", "end": END})
graph_builder.add_edge("tools", "agent")graph = graph_builder.compile(checkpointer=memory)
# print(graph.get_graph().draw_ascii())def get_user_thread():first_name = "Harry"last_name = "Liu"user_name = first_name + uuid.uuid4().hex[:4]thread_id = uuid.uuid4().hexzep.user.add(user_id=user_name, first_name=first_name, last_name=last_name)zep.thread.create(thread_id=thread_id, user_id=user_name)print(first_name, last_name, user_name, thread_id)return first_name, last_name, user_name, thread_iddef extract_messages(result):output = ""for message in result["messages"]:if isinstance(message, AIMessage):name = "assistant"else:name = result["user_name"]output += f"{name}: {message.content}\n"return output.strip()async def graph_invoke(message: str, first_name: str, last_name: str, user_name:str, thread_id: str, ai_response_only: bool = True,):r = await graph.ainvoke({"messages": [ { "role": "user", "content": message, } ],"first_name": first_name,"last_name": last_name,"user_name":user_name,"thread_id": thread_id,},config={"configurable": {"thread_id": thread_id}},)if ai_response_only:return r["messages"][-1].contentelse:return extract_messages(r)def chatbot():# first_name, last_name, user_name, thread_id = get_user_thread()first_name, last_name, user_name, thread_id = "Harry", "Liu", "Harry2dfc", "25f570725f6a4233ad8942d9d1c6cc79"while True:try:user_input = input("🧑 User: ")if user_input.lower() in ["quit", "exit", "q"]:print("Goodbye!")break# print("user input", user_input)response = asyncio.run(graph_invoke(user_input, first_name, last_name, user_name, thread_id, ))print(f"🤖 Assistant: {response}")except Exception as e:print("发生错误:")traceback.print_exc()break
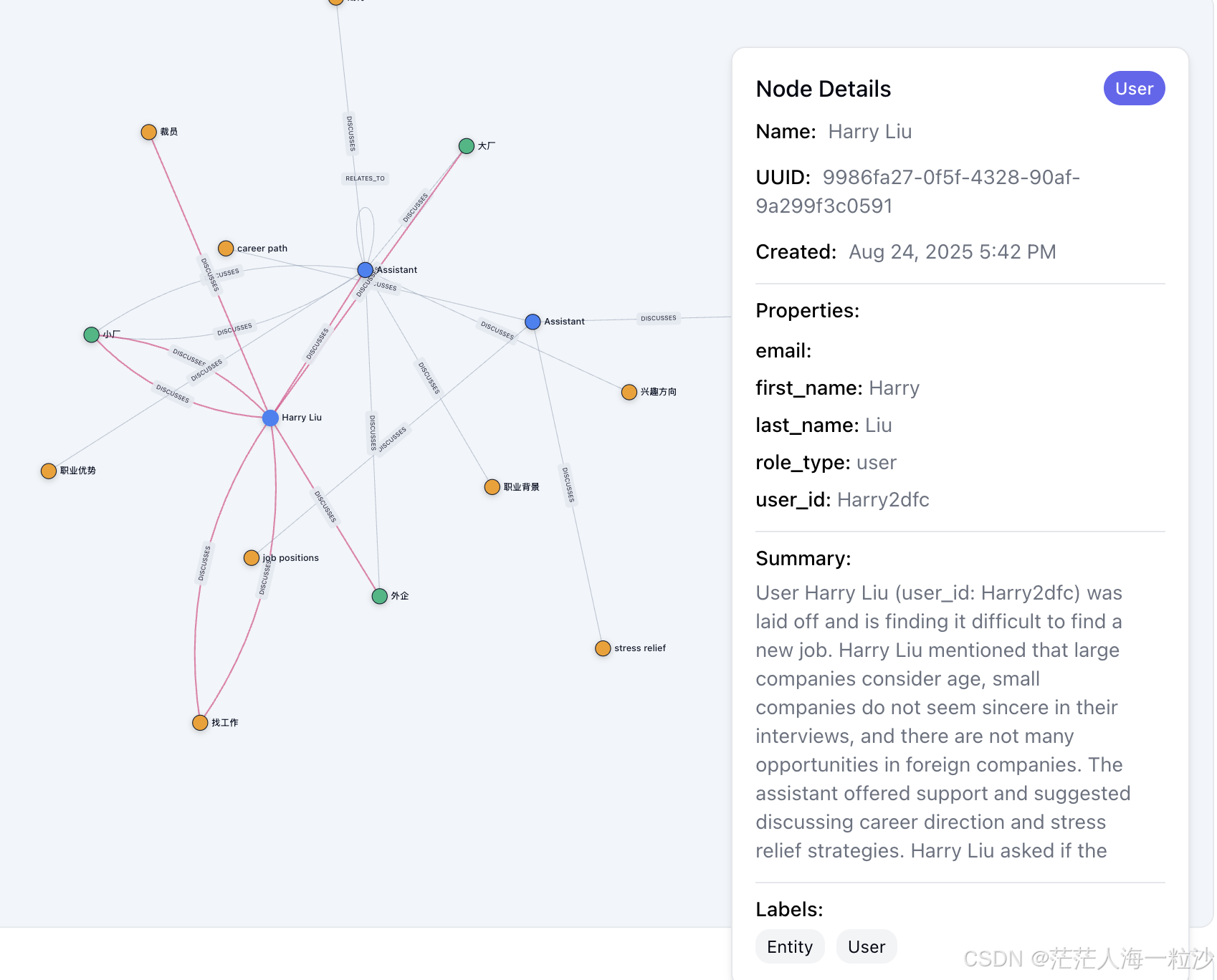
if __name__ == '__main__':chatbot()运行结果

然后重新运行一次测试一下它的长期记忆。
把上次的运行的first_name, last_name, user_name, thread_id 替换掉。
first_name, last_name, user_name, thread_id = get_user_thread()# first_name, last_name, user_name, thread_id = "Harry","Liu", "Harry2dfc", "25f570725f6a4233ad8942d9d1c6cc79"
zep 里生成的知识图谱如下: