定时任务——ElasticJob原理
摘要
文章主要介绍了ElasticJob的原理和源码解析。ElasticJob是一个分布式任务调度框架,使用Zookeeper作为协调器,支持任务分片和分布式锁机制。文章还探讨了ElasticJob的作业流程、任务分配、Leader选举、任务触发和执行机制,以及如何在Spring Boot中使用ElasticJob。
1. ElasticJob基本原理
1.1. ElasticJob的背景
ElasticJob 是面向互联网生态和海量任务的分布式调度解决方案,由两个相互独立的子项目 ElasticJob-Lite 和 ElasticJob-Cloud 组成。它通过弹性调度、资源管控、以及作业治理的功能,打造一个适用于互联网场景的分布式调度解决方案,并通过开放的架构设计,提供多元化的作业生态。它的各个产品使用统一的作业 API,开发者仅需一次开发,即可随意部署。
主要通过 jar 包方式嵌入到业务系统中,利用 ZooKeeper 作为注册协调中心来完成任务的分布式管理和调度。使用 ElasticJob 能够让开发工程师不再担心任务的线性吞吐量提升等非功能需求,使他们能够更加专注于面向业务编码设计;同时,它也能够解放运维工程师,使他们不必再担心任务的可用性和相关管理需求,只通过轻松的增加服务节点即可达到自动化运维的目的。
ElasticJob-Lite:定位为轻量级无中心化解决方案,使用 jar 的形式提供分布式任务的协调服务。
1.2. ElasticJob的作用
| 类别 | 作用 | 说明 |
| 任务调度 | 分布式任务调度 | 基于时间表达式(Cron)实现分布式任务执行,支持多节点水平扩展。 |
| 任务分片 | 任务拆分执行 | 将一个大任务拆分成若干子任务,由不同节点分片执行,提高并行度和性能。 |
| 高可用 | 任务容错 | 当某个节点宕机时,其分片任务会被自动转移到其他存活节点执行,保证任务不中断。 |
| 协调管理 | 去中心化协调 | 基于 ZooKeeper 做注册中心,保证任务分配、状态一致性和节点协调。 |
| 运行监控 | 任务状态监控 | 提供任务运行状态、分片分配情况、执行结果监控,支持事件追踪。 |
| 弹性扩缩容 | 节点动态管理 | 新增或减少调度节点时,任务分片会自动重新分配,支持动态伸缩。 |
| 运维管理 | 任务运维接口 | 提供任务禁用、启用、重分片、手动触发等运维功能。 |
| 轻量无中心化 | Jar 引入即可用 | 不依赖外部调度中心,应用通过引入 jar 包即可集成,降低部署和运维成本。 |
1.3. ElasticJob架构图
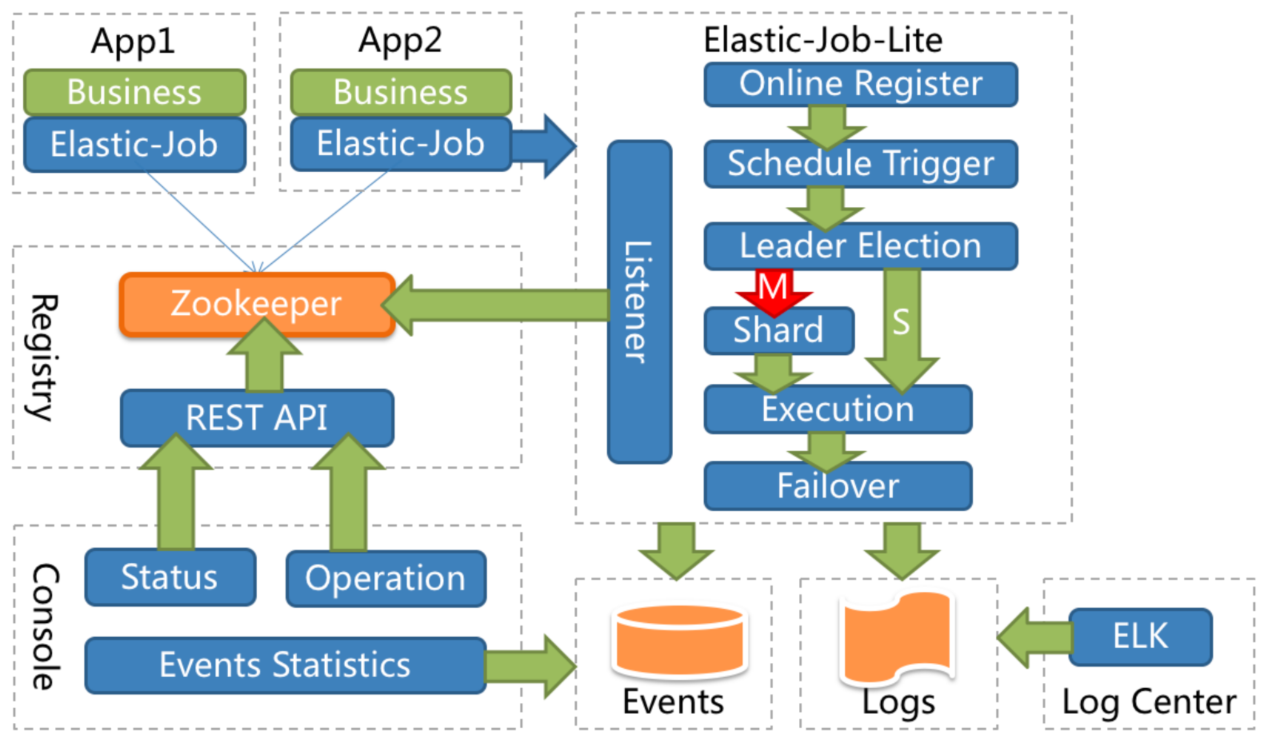
1.4. ElasticJob任务类型
ElasticJob的作业分类基于class和type两种类型。
- 基于class的作业需要开发者自行通过实现接口的方式织入业务逻辑;
- 基于class的作业接口的方法参数shardingContext包含作业配置、片和运行时信息。可通过getShardingTotalCount()、getShardingItem()等方法分别获取分片总数和运行在本作业服务器的分片序列号等。
- 基于type的作业则无需编码,只需要提供相应配置即可。
ElasticJob目前提供 Simple、Dataflow这两种基于 class的作业类型,并提供 Script、HTTP这两种基于 type的作业类型,用户可通过实现 SPI接口自行扩展作业类型。
ElasticJob 的任务类型主要分为三大类(Lite 和 Cloud 都是一样的 Job 类型):
| Job 类型 | 特点 | 使用场景 |
| SimpleJob | 最简单的任务类型。每次执行时,都会调用一次 | 定时清理缓存、发送消息、简单数据同步等。 |
| DataflowJob | 数据流式任务。可配置为 流式处理 或 批量处理: - 流式(streaming): 有数据就不停拉取并处理。 - 批处理(one-off): 拉取一次数据处理后结束。 | 日志收集、数据同步、ETL 等需要不断处理数据的场景。 |
| ScriptJob | 通过调用脚本(如 Shell、Python、Groovy 等)来执行任务,ElasticJob 只负责调度。 | 系统运维脚本、已有脚本迁移,无需改写为 Java 的任务。 |
1.5. ElasticJob原理说明
应用启动↓
任务注册 → ZooKeeper↓
Leader 选举↓
任务分片(分配给实例)↓
Cron 触发调度↓
各实例执行分片任务↓
执行结果写回 ZooKeeper↓
失效转移(节点宕机 → 分片重新分配)1.5.1. 作业注册
- 应用启动时,任务类(如
SimpleJob、DataflowJob)被 Spring 或原生容器加载。 - ElasticJob会将任务的元信息(任务名、cron 表达式、分片数、分片参数等)注册到 ZooKeeper。
- 每个作业在 ZooKeeper 中都有自己的节点,例如:
/elasticjob/{jobName}/├── config # 作业配置├── instances # 运行实例├── sharding # 分片信息└── leader # 主节点选举1.5.2. Leader 选举
- ElasticJob-Lite 内部会使用 ZooKeeper 的临时节点机制,进行 Leader 选举。
- Leader节点负责分片分配和协调任务执行。
- 当Leader宕机时,ZooKeeper 会自动触发新 Leader 选举。
1.5.3. 作业分片
Leader 根据任务的分片数(shardingTotalCount)和当前存活实例数(instances),将任务拆分并分配。例如:
shardingTotalCount = 4- 有 2 个实例 A、B
- 那么可能分片结果是:
-
- A 执行分片
0,1 - B 执行分片
2,3
- A 执行分片
1.5.4. 触发调度
- ElasticJob 使用 Cron 表达式 或 手动触发 方式来调度任务。
- 每个实例会监听 ZooKeeper 中的 作业触发事件。
- 当触发时,各实例根据分片信息,只执行自己负责的分片。
1.5.5. 任务执行
执行入口一般是 JobExecutor,它会调用用户实现的 Job 接口:
SimpleJob#execute(ShardingContext context)DataflowJob#fetchData(ShardingContext context)和processData(List<T> data)
ShardingContext 包含:
-
- 作业名
- 分片总数
- 当前分片项(shardingItem)
- 分片参数
1.5.6. 失效转移(Failover)
- 如果某个实例宕机,ZooKeeper 会删除对应的
instance节点。 - Leader 立即感知,并将宕机实例的分片重新分配给存活的实例,保证任务继续执行。
1.5.7. 作业完成 & 状态回写
- 执行完成后,任务会在 ZooKeeper 中记录执行状态(成功/失败)。
- 如果开启了监控,ElasticJob-Console 可以查询这些信息,进行可视化展示。
1.6. ElasticJob框架说明
api 暴露给用户调用的类
bootstrap 作业启动类OneOffJobBootstrap 一次性调度ScheduleJobBootstrap 定时调度
listener 作业监听器AbstractDistributeOnceElasticJobListener 分布式作业监听器
registerJobInstanceRegistry
internal 内部核心功能,按功能分包config 配置election 选举instance 实例 | JobInstanceserver 服务器 | ipsharding 分片failover 故障转移reconcile 自诊断修复(重新分片)setup 启动设置schedule 调度器 | 作业调度器,作业类型,作业生命周期storage 存储 | 默认zksnapshot dump 任务快照trigger 手动触发listener 配置变更监听器guarantee 分布式作业监听器幂等保障2. ElasticJob源码解析
2.1. AbstractDistributeOnceElasticJobListener源码解析
ElasticJob 的任务调度是 分布式并行 的,比如一个 Job 被分成 10 个分片,可能跑在 3 台机器上。如果我们在 beforeJobExecuted 或 afterJobExecuted 里写逻辑,那么 每个分片都会执行一次,这就可能造成重复。为了解决这个问题,AbstractDistributeOnceElasticJobListener 做了两个关键动作:
2.1.1. 基于 Zookeeper 分布式锁/Barrier(栅栏机制)
- ElasticJob 使用 Zookeeper 作为协调器。
- 监听器在执行
beforeJobExecuted和afterJobExecuted时,会通过 Zookeeper 临时节点 来竞争锁。 - 只有 第一个获得锁的 Job 实例 才会执行对应的逻辑,其他实例会被阻塞或跳过。
// 伪代码示例
if (zkClient.tryLock("/job/once_listener_lock")) {// 只有一个实例能拿到锁doBeforeOrAfterLogic();
}2.1.2. 全局执行标记
- 监听器会在 Zookeeper 上设置一个状态标记,表示某个 Job 本次调度已经执行过一次。
- 其他实例检测到这个标记,就不会再执行。
例如:
/elasticjob/jobName/listener/started
/elasticjob/jobName/listener/completed2.1.3. 使用方式
开发者继承 AbstractDistributeOnceElasticJobListener,实现两个方法:
public class MyOnceListener extends AbstractDistributeOnceElasticJobListener {public MyOnceListener(long startedTimeoutMilliseconds, long completedTimeoutMilliseconds) {super(startedTimeoutMilliseconds, completedTimeoutMilliseconds);}@Overridepublic void doBeforeJobExecutedAtLastStarted(ShardingContexts shardingContexts) {// 分布式环境下只执行一次System.out.println("任务执行前,初始化资源(只执行一次)");}@Overridepublic void doAfterJobExecutedAtLastCompleted(ShardingContexts shardingContexts) {// 分布式环境下只执行一次System.out.println("任务执行后,清理资源(只执行一次)");}
}参数说明:
startedTimeoutMilliseconds:所有作业启动的超时时间。completedTimeoutMilliseconds:所有作业完成的超时时间。
AbstractDistributeOnceElasticJobListener 依赖 Zookeeper 分布式锁 + 状态节点标记,确保:
- Job 开始前的准备逻辑 在所有分片执行前只执行一次。
- Job 完成后的清理逻辑 在所有分片执行完后只执行一次。
2.2. ElasticJob作业流程图
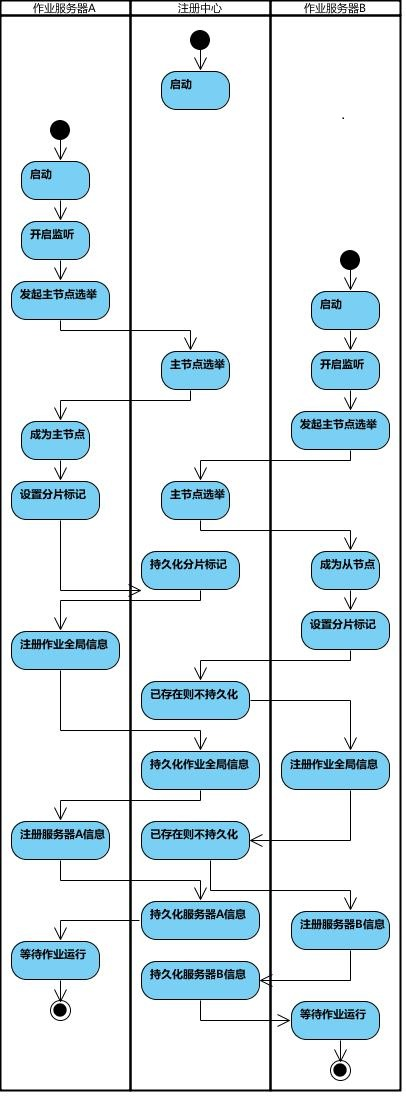
2.3. ElasticJob作业执行
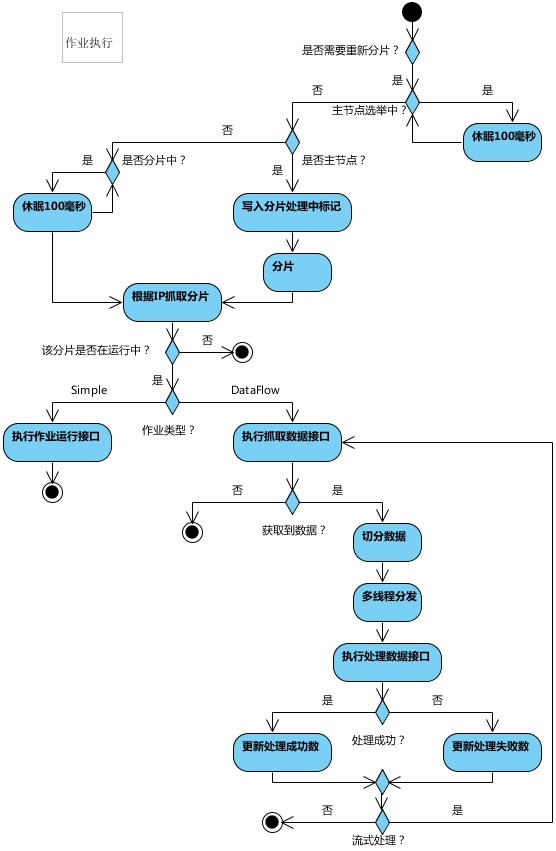
3. ElasticJob源码思考问题
3.1. 多个Elastic-Job springboot服务是什么进行Leader选举的? Leader节点是指的是Elastic-Job 服务吗? leader是怎么实现任务分配的?
3.1.1. 谁负责 Leader 选举?
在 Elastic-Job-Lite(你用 Spring Boot 引入的就是这个)里:
- Leader 选举是由 Elastic-Job 内部基于 ZooKeeper 实现的。
- 它使用 ZooKeeper 的临时顺序节点(Ephemeral Sequential Node) 来实现选举机制。
- 具体逻辑:
- 所有 Elastic-Job 的执行器实例(也就是你的 Spring Boot 服务)启动时,都会在 ZooKeeper 上的一个固定路径下,去尝试创建一个“选举节点”。
- 谁最先成功创建,就成为 Leader 节点。
- 如果 Leader 宕机(临时节点消失),ZooKeeper 会通知其他存活的节点进行新一轮选举。
👉 所以:Leader 节点本质上就是集群里某一个 Elastic-Job 执行器实例。
3.1.2. Leader 节点是不是 Elastic-Job 服务?
是的 ✅。
- Leader 并不是 ZooKeeper 本身,而是 某一个 Elastic-Job Spring Boot 服务实例。
- 举例:你有 3 个服务(Job-Server-A、Job-Server-B、Job-Server-C),ZK 会选出其中 1 个作为 Leader。
- 这个 Leader 的职责就是做“任务协调员”,但它同时也可以自己执行分片任务。
3.1.3. Leader 怎么实现任务分配?
任务分配(Sharding)由 Leader 节点完成,核心逻辑大致是:
- 收集元数据
-
- Leader 从 ZooKeeper 读取当前有哪些 Job、每个 Job 的分片数(
shardingTotalCount)、以及有哪些存活的执行器实例。
- Leader 从 ZooKeeper 读取当前有哪些 Job、每个 Job 的分片数(
- 分片策略计算
-
- 根据配置的分片策略(默认是
AverageAllocationJobShardingStrategy平均分配策略),把分片号分配给不同实例。 - 比如:
- 根据配置的分片策略(默认是
-
-
- 任务 A:
shardingTotalCount = 3 - 存活实例:ServerA、ServerB
- 分片结果:ServerA → {0,1}, ServerB → {2}
- 任务 A:
-
- 写入分片结果
-
- Leader 把分片结果写入 ZooKeeper 的
/jobName/sharding/instanceId/节点下。
- Leader 把分片结果写入 ZooKeeper 的
- 各个实例感知分片
-
- 每个执行器(ServerA、ServerB)监听自己在 ZK 的分片信息变化,一旦发现有新的分配,就只执行自己负责的分片。
3.2. 多个Elastic-Job springboot服务 是不是可能同时触发三个相同的任务? 这三个任务也是由Leader 来统一处理?
3.2.1. 任务触发(Trigger)
- 在 每一个 Elastic-Job SpringBoot 服务实例 里,都内置了一个 Quartz 调度器。
- 所以,当 Cron 时间到达时,所有实例都会同时触发(Quartz 在各自节点本地都触发一次)。
👉 这就是你担心的「是不是多个服务会同时触发同一个任务」。答案是:是的,每个实例本地 Quartz 都会触发。
3.2.2. 任务执行(Execution)
虽然触发会在每个节点同时发生,但是否真正执行任务逻辑,要看分片分配:
- Leader 节点只负责分片分配,它不会统一收集任务然后自己跑,而是把“谁执行哪个分片”的规则写进 ZooKeeper。
- 每个节点触发后,都会先去 ZooKeeper 读取分片信息,只会执行分配给自己的分片任务。
- 没有被分配到分片的节点,即使触发了任务,也不会执行任何逻辑。
3.3. Leader 从zk 哪一个路径读取任务?怎么样将任务进行分配? 任务分配后将数据写入哪一个zk路径下? 服务是怎么样的监听路径变化的?
3.3.1. Zookeeper 的节点结构(Elastic-Job 每个任务在 ZK 上都会有一套目录)
假设有个作业:demoJob,在 ZK 上会生成如下节点结构(只列核心):
/demoJob # 作业根目录├── leader # Leader 选举相关│ └── election # Leader 节点标识(临时节点)├── servers # 存活的 Job 执行器实例│ ├── ip:port # 每个实例在这里注册(临时节点)│ └── ...├── sharding # 分片信息存储│ ├── 0 # 分片0分配信息│ ├── 1 # 分片1分配信息│ ├── 2 # 分片2分配信息│ └── ...└── config # 任务配置(cron、分片数、分片参数等)3.3.2. Leader 从哪里读取任务?
Leader的职责是分片分配。
- Leader 先去读取
/demoJob/config节点,拿到:
-
- cron 表达式
shardingTotalCount(分片总数)- 分片参数
- 再去读取
/demoJob/servers,知道当前有哪些存活的实例(执行器)。
3.3.3. Leader 怎么分配任务?
Elastic-Job 内置了分片策略(可自定义,默认是平均分配策略):
- 举例:
-
shardingTotalCount = 3- 存活实例:ServerA、ServerB
Leader 会计算:
- ServerA → {0,1}
- ServerB → {2}
这个计算发生在 Leader 节点的内存中,然后写回 ZooKeeper。
3.3.4. 分配结果写到哪里?
分配完成后,Leader 会把分片信息写入/demoJob/sharding/ 路径下:
/demoJob/sharding/0 = ServerA
/demoJob/sharding/1 = ServerA
/demoJob/sharding/2 = ServerB(在 ZK 里存的是 JSON,包含执行器 ID、分片参数、运行状态等元数据)
3.3.5. 其它服务实例怎么知道分配变化?
Elastic-Job 框架在每个执行器里,对 ZK 节点注册了 Watcher 监听器:
- 每个服务都会监听:
-
/demoJob/sharding/下对应自己分片的数据变化/demoJob/config的变化(比如 cron 修改)/demoJob/servers的变化(实例上下线)
一旦分配有更新:
- ZK 通知所有监听的实例
- 每个实例只会读取属于自己的分片数据,然后执行对应的任务
3.4. Elastic-Job分布式能力体现在哪里?
ElasticJob 的分布式能力是它的核心卖点,主要体现在 任务调度、分片执行、容错和协调 等几个方面。可以分点解释如下:
| 能力点 | 体现方式 | 说明 |
| 1. 任务分片执行 | 分片策略(如平均分配、轮询、自定义) | 一个任务可以拆分成 N 个分片,分布在多个节点并行执行,提高处理能力。例如:一个日志清理任务分片为 10 份,3 台机器可分别执行不同分片。 |
| 2. 分布式协调(基于注册中心) | 使用 ZooKeeper 或 Etcd 作为协调中心 | 所有 Job 信息、服务器状态、分片分配等都存储在注册中心,保证多节点任务执行的一致性和协调性。 |
| 3. 主节点选举(Leader 选举) | 通过 ZK 临时节点实现 Leader 选举 | 在多节点环境中,ElasticJob 通过 LeaderService选举出 Leader 节点,用于分配分片、触发任务,避免并发冲突。 |
| 4. 高可用与容错 | 节点宕机检测与任务转移 | 如果某个节点宕机,ZK 会立即感知,ElasticJob 会触发 重新分片,未完成的任务会分配给存活节点执行。 |
| 5. 动态扩缩容 | 节点上线/下线自动感知 | 当新增机器时,ElasticJob 会自动进行分片重分配;机器下线后,其分片也会自动迁移到存活节点。 |
| 6. 分布式协调状态管理 | 基于注册中心的任务执行状态节点 | 每个任务分片的执行状态(运行中、完成、失败)都会写入 ZK,保证多节点协同一致。 |
| 7. 弹性调度 | 在线动态调整分片数和参数 | 支持在不重启任务的情况下修改分片数、参数等,注册中心会实时下发配置到各执行节点。 |
3.4.1. 一个任务可以拆分成 N 个分片 这个怎么理解?
3.4.1.1. 什么是“一个任务”?
在 ElasticJob 里,一个任务就是你定义的某个 Job 类,比如:
public class LogCleanJob implements SimpleJob {@Overridepublic void execute(ShardingContext shardingContext) {// 执行逻辑}
}这个 LogCleanJob 就是一个“任务”。
3.4.1.2. 什么是“分片(Sharding)”?
- ElasticJob 提供了
shardingTotalCount参数(分片总数)。 - 你可以把一个任务拆分成多个 分片(Shard),每个分片有一个分片编号(0,1,2,…,N-1)。
- ElasticJob 会把这些分片分配到不同的节点去执行。
这样,一个任务就能被多个机器/线程 并行执行,而不是单节点串行跑。
3.4.1.3. 举个例子:日志清理任务
假设你要做一个“日志清理”任务,删除数据库里的旧日志。
- 不分片的情况:一个任务直接全表扫描,一台机器执行,速度很慢。
- 分片的情况(shardingTotalCount=10):
任务被拆成 10 个子任务:
-
- 分片0:清理 user_id % 10 = 0 的日志
- 分片1:清理 user_id % 10 = 1 的日志
- …
- 分片9:清理 user_id % 10 = 9 的日志
如果有 3 台机器:
- 节点 A 执行分片 0,1,2
- 节点 B 执行分片 3,4,5
- 节点 C 执行分片 6,7,8,9
这样整个日志清理就能 并行跑,快很多。
3.4.1.4. ElasticJob 里的参数
在 Job 配置时,可以这样设置:
job:logCleanJob:cron: 0/30 * * * * ?shardingTotalCount: 10shardingItemParameters: 0=A,1=B,2=C,3=D,4=E,5=F,6=G,7=H,8=I,9=JshardingTotalCount=10表示拆分成 10 份。shardingItemParameters给每个分片绑定参数(可选),这样每个分片能执行不同的逻辑。
3.5. ElasticJob其中一个分片某一个任务执行失败,这个任务会被重新执行吗?
ElasticJob 的设计理念是:调度可靠,执行结果业务自己兜底。如果你要保证“失败必须重跑”,就得在任务里加 重试/补偿机制(例如:失败落库 + 补偿任务,或失败投递 MQ 再消费)。
- 业务执行失败(抛异常) → 不会重试,只等下一次调度。
- 节点宕机 → 分片会重新分配,但本次失败不会自动补偿。
3.5.1. 情况一:任务正常触发,但某个分片里的业务执行报错(抛异常)
- 不会自动重试。:ElasticJob 只是调度触发器,分片任务抛出异常后,它只会记录日志或走你自定义的
JobErrorHandler。 - 下次会不会执行?:只有等到 下一次调度周期(下一次 cron 触发),这个分片任务才会再次执行。
- 结论:这次失败的分片不会立即重跑。
3.5.2. 情况二:分片所在的节点宕机(机器挂掉/进程崩溃)
- ElasticJob 会通过注册中心(Zookeeper)检测到节点下线。
- 失效转移机制会把这个分片重新分配给存活节点。
- 但是注意:如果是在执行中宕机,这个分片本次执行结果就丢了,不会自动恢复执行。重新分配后,只有下一次调度才会在新节点正常跑。
3.6. ElasticJob 那执行的任务数据是从哪里来?
ElasticJob 本身只是一个 分布式调度框架,它负责的是:
- 什么时候触发任务(基于 cron 表达式)
- 如何把任务切分成 N 个分片
- 如何把分片分配到不同节点去执行
至于每个分片要处理的数据,是业务代码自己决定的,ElasticJob 不会帮你准备数据。
3.6.1. 举个例子:数据库数据处理
假设你要处理一张大表 order,有 1000 万条订单数据,你配置:
shardingTotalCount = 10(分 10 片)- ElasticJob 会在调用
execute()时传入shardingItem = 0 ~ 9
那么你的代码可以这样分配数据:
@Override
public void execute(ShardingContext context) {int shardingItem = context.getShardingItem();int totalShards = context.getShardingTotalCount();// 假设 orderId 是连续的List<Order> orders = orderRepository.findByMod(shardingItem, totalShards);// 处理数据for (Order order : orders) {process(order);}
}比如:
- 分片 0 处理
orderId % 10 == 0的数据 - 分片 1 处理
orderId % 10 == 1的数据 - ……
- 分片 9 处理
orderId % 10 == 9的数据
这样所有数据就被均匀拆分给 10 个分片并行处理了。
3.6.2. 其他常见数据来源
除了数据库,还可以:
- 消息队列:每个分片订阅不同的 topic/partition
- 文件系统:每个分片处理不同目录/文件
- 缓存/Redis:分片对应不同的 key 前缀
- API 分页:每个分片负责不同的页码区间
ElasticJob 只负责调度和分片信息,分片要处理的业务数据由你自己定义和加载。所以你可以理解为:ElasticJob 负责“告诉你第几片”,你负责“拿第几片的数据并执行”。
3.7. 业务代码获取任务通过elasticjob来执行?任务执行的结果业务带代码还是写回数据库?
ElasticJob 本质上只是调度容器,它只管:
- 定时触发(cron 表达式)
- 分片分配(告诉你这是第几片,总共有多少片)
- 分布式协调(哪个节点执行哪个分片)
至于 任务的执行逻辑 和 执行结果的处理,完全是 业务代码来决定的。
3.7.1. 业务代码获取任务数据
- ElasticJob 调用你实现的
SimpleJob/DataflowJob/ScriptJob等接口。 - 在
execute()方法里,你用ShardingContext拿到分片信息,然后去 业务数据库 / MQ / Redis / 文件 / API 拿数据。
例子(数据库按分片查询):
@Override
public void execute(ShardingContext context) {int shardingItem = context.getShardingItem();int totalShards = context.getShardingTotalCount();// 按分片从数据库拉取任务List<Task> tasks = taskRepository.findByShard(shardingItem, totalShards);for (Task task : tasks) {try {process(task);// ✅ 执行成功 -> 业务代码更新数据库taskRepository.updateStatus(task.getId(), "SUCCESS");} catch (Exception e) {// ❌ 执行失败 -> 业务代码更新数据库taskRepository.updateStatus(task.getId(), "FAILED");}}
}3.7.2. 任务执行结果的存放
ElasticJob自己不会存任务执行的结果,它只在 ZooKeeper里维护分片分配信息、作业运行状态(运行中/完成/失效),不会保存你的业务数据。所以,任务的结果存哪里完全由你决定:
- 数据库表:最常见,执行成功/失败写回表里
- 消息队列:执行结果发 MQ,供下游消费
- 缓存/Redis:临时存储,后续再处理
- 日志:只打印出来,不做持久化
3.7.3. 总结
- ElasticJob = 调度器 + 分片协调器
- 业务代码 = 取数 + 处理 + 写回结果
3.8. ElasticJob 不会帮你保存执行结果,你必须在业务代码里明确写回(一般是数据库)。
3.8.1. ElasticJob
- 定位是分布式调度框架。
- 不存储业务任务数据,只依赖 ZooKeeper 存放:
-
- 作业元信息(作业名、分片数、cron 等配置)
- 分片运行状态(哪个节点在跑哪片)
- 作业运行时的临时状态(正在运行、完成等)
任务数据(要处理什么、结果存哪)完全交给你的业务系统(数据库/MQ/Redis),ElasticJob 不管。它更像是 Quartz + 分布式协调 + 分片执行。
3.8.2. XXL-JOB
- 定位是 分布式任务调度平台。
- 有 调度中心(xxl-job-admin) + 执行器(xxl-job-executor)。
- 调度中心用了数据库(默认 MySQL),存放的表有:
| 表名 | 作用 |
|
| 存储任务元信息(任务名、cron、路由策略、执行器、阻塞策略等),不是业务任务数据 |
|
| 存储每次调度的执行日志、执行状态(成功/失败)、耗时等 |
|
| 记录执行器心跳,用于服务发现 |
|
| 分布式锁 |
注意:xxl_job_info并不是业务待处理任务的数据表,而是 调度任务的配置表。真正的业务任务数据(比如订单表、待处理任务表)还是要你自己维护。
3.9. ElasticJob的中springboot 怎么一开始就想zk 中的注册自己? 源码是怎么样?
3.9.1. Spring Boot + ElasticJob 的启动流程
在 Spring Boot中使用elasticjob-lite-spring-boot-starter(或手动配置 elasticjob-lite-core)时:
- SpringBoot 启动 → 加载 ElasticJob 的 自动配置类(
ElasticJobLiteAutoConfiguration)。 ElasticJobLiteAutoConfiguration会扫描所有带有@ElasticJob注解(或配置文件中声明的)的任务类。- 创建
SpringJobScheduler对象(这是 ElasticJob 的核心调度器)。 SpringJobScheduler构造方法里,会调用JobScheduler→CoordinatorRegistryCenter(Zookeeper 注册中心) → 注册任务元数据 & 服务实例。
3.9.2. 注册中心核心类ZookeeperRegistryCenter
初始化时会和 ZooKeeper 建立连接,并提供 持久节点(配置用)和 临时节点(实例注册用)的 API。
public final class ZookeeperRegistryCenter implements CoordinatorRegistryCenter {private ZookeeperClient client;@Overridepublic void init() {client = new ZookeeperClient(serverLists, namespace, sessionTimeout, connectionTimeout, maxRetries);client.start();}@Overridepublic void persist(final String key, final String value) {client.createPersistent(key, value);}@Overridepublic void persistEphemeral(final String key, final String value) {client.createEphemeral(key, value);}
}
3.9.3. JobScheduler 初始化时JobScheduler做了什么?
在 SpringJobScheduler 的构造函数里:
public JobScheduler(final CoordinatorRegistryCenter regCenter, final LiteJobConfiguration jobConfig, final ElasticJobListener... elasticJobListeners) {this.regCenter = regCenter;this.jobConfig = jobConfig;this.listenerManager = new ListenerManager(regCenter, jobName, elasticJobListeners);this.schedulerFacade = new SchedulerFacade(regCenter, jobConfig.getJobName());this.jobSchedulerController = new JobScheduleController(scheduler, jobDetail, triggerIdentity);
}调用链:
- 初始化 ZK 节点
-
schedulerFacade.registerStartUpInfo(true)- 内部会在 ZooKeeper 上创建:
-
-
/jobName/config(任务配置,持久节点)/jobName/servers/ip:port(服务实例,临时节点)/jobName/leader(Leader 选举,临时节点)
-
- 完成注册 & 选举
-
- 服务实例节点:
/jobName/servers/{ip:port} - 内容一般是
"ONLINE",表示当前节点可执行任务。 - 通过 临时节点保证服务宕机时自动删除。
- 服务实例节点:
3.9.4. 服务实例注册源码示例
public void persistServerOnline(final boolean enabled) {String serverNode = JobNodePath.getServerNode(jobName, IpUtils.getIp());regCenter.persistEphemeral(serverNode, enabled ? "ONLINE" : "DISABLED");
}3.10. 为什么 ElasticJob 用 CommandLineRunner 而不是 InitializingBean?
因为 ElasticJob 要在 所有 Bean 都准备好后再统一启动调度(否则可能任务启动了但依赖的 Bean 还没就绪)。如果用 InitializingBean,只保证某个 bean 初始化完成,不保证全局容器准备好。
所以可以这么理解:
InitializingBean/@PostConstruct= Bean 级别初始化。CommandLineRunner= 应用级别启动逻辑。
3.11. JobScheduleController 内部基于 Quartz 实现定时调度。 怎么理解?
3.11.1. JobScheduleController 的作用
JobScheduleController 是 ElasticJob 的 调度控制器,它的职责是:
- 封装调度逻辑(什么时候触发任务)。
- 调用执行器(ElasticJob 本身的业务任务逻辑)。
也就是说,它是连接 ElasticJob 框架 和 底层调度引擎 Quartz 的桥梁。
换句话说:JobScheduleController 就是 把 ElasticJob 的任务包装成 Quartz 能识别的 Job + Trigger,然后交给 Quartz 去执行。
public final class JobScheduleController {private final Scheduler scheduler; // Quartz Schedulerprivate final JobDetail jobDetail;private final Trigger trigger;public void scheduleJob() {// 把任务注册到 Quartzscheduler.scheduleJob(jobDetail, trigger);}public void rescheduleJob(Cron cron) {// 修改任务调度scheduler.rescheduleJob(trigger.getKey(), newTrigger);}public void pauseJob() {scheduler.pauseJob(jobDetail.getKey());}public void resumeJob() {scheduler.resumeJob(jobDetail.getKey());}public void shutdown() {scheduler.shutdown();}
}
3.11.2. Quartz 在里面的角色
ElasticJob自己并没有完全实现“定时调度引擎”,而是复用了 Quartz。
Quartz 是一个成熟的定时调度框架,支持:
- Cron 表达式调度;
- Misfire(错过调度补偿策略);
- Trigger、JobDetail、JobExecutionContext 等机制;
- 并发控制;
- 分布式集群(但 ElasticJob 自己会基于注册中心来做分布式协调)。
所以,ElasticJob 里的 JobScheduleController 并不会自己去算 “5 秒一次” 什么时候执行,而是把任务交给 Quartz 的 Scheduler 去调度。
Quartz 的调度基石就是 Scheduler + Job + Trigger 三大件:
- Job:任务逻辑(要干什么),实现
org.quartz.Job接口。 - JobDetail:任务描述信息(Job 的定义、参数)。
- Trigger:触发器,定义什么时候触发任务。常用的是
CronTrigger。 - Scheduler:调度器,负责管理 JobDetail 和 Trigger 的注册,并在合适的时间执行任务。
可以理解为:
- JobDetail = 任务的定义
- Trigger = 任务的调度规则
3.11.3. Quartz 定时调度的执行流程
Quartz 的定时调度是通过调度主线程维护 Trigger 的优先队列,不断计算“下一个最近的触发时间”,到点后把任务丢到线程池去执行。Quartz 内部其实是一个调度线程池 + 时间轮/优先队列的机制,主要步骤如下:
3.11.3.1. 任务注册
- 你调用
scheduler.scheduleJob(jobDetail, trigger)时,Quartz 会把 JobDetail 和 Trigger 放进调度器的内存结构中(JobStore)。 Trigger会转换成一个 下次触发时间(nextFireTime)。
3.11.3.2. 调度线程监控
- Quartz 有一个调度主线程(QuartzSchedulerThread),它会不断从 JobStore 里拉取 最近要执行的 Trigger。
- 内部用 时间优先队列(时间小顶堆) 存储触发器。
3.11.3.3. 等待与唤醒
- 调度线程会计算最近一次要执行的 Trigger 的 nextFireTime,然后
Thread.sleep(…)一段时间。 - 到点后被唤醒,取出要执行的 Trigger。
3.11.3.4. 任务调度
- 找到需要触发的 Trigger 以后,Quartz 会:
-
- 取出对应的 JobDetail;
- 包装成一个 JobRunShell(执行外壳);
- 提交到 Quartz 的 线程池(QuartzSchedulerThreadPool) 执行。
3.11.3.5. 任务执行
- 线程池中的线程调用
job.execute(JobExecutionContext context),执行具体任务逻辑。
3.11.3.6. 更新 Trigger
- 执行完后,Trigger 会更新它的 nextFireTime,再丢回 JobStore,等待下一轮调度。
- 如果 Trigger 是一次性任务,则执行完会被移除。
3.12. ElasticJob 通过Curator 和zk 建立什么连接?长连接还是短连接? 还是Netty 的连接?建立连接就一直等的通信? 不会断链了?
3.12.1. ElasticJob 使用 Curator 连接 ZooKeeper
你看到的 client = builder.build(); client.start(); 实际上就是创建了 CuratorFramework 客户端。Curator 底层是对 ZooKeeper 原生客户端(ZK Client) 的封装,而 ZK Client 本身就是基于 Netty NIO 的长连接。
3.12.2. 连接类型
- ZooKeeper Client → ZooKeeper Server 是长连接
一旦建立成功,客户端会和 ZooKeeper 服务器保持 TCP 长连接(通常基于 Netty 实现)。 - 不是短连接(不像 HTTP 一次请求就断开)。
- 心跳机制:ZooKeeper 会通过 心跳(ping) 维持 session 的有效性。客户端如果长时间没有响应,服务器会认为 session 过期,断开连接。
3.12.3. 为什么是长连接?
因为:
- ElasticJob 要把 作业信息、调度信息 注册到 ZK 上;
- ZK 里大量依赖 临时节点(EPHEMERAL node) 来标记 Job 是否存活、分布式锁等;
- 临时节点依赖会话(session),如果断开连接,session 过期 → 临时节点会自动删除 → ElasticJob 就会认为作业实例挂了。
所以必须是 长连接,并且通过心跳维持 session。
3.12.4. 断链情况
- 正常情况:客户端和服务端通过心跳保持通信,连接不会主动断掉。
- 异常情况:网络抖动、ZK 服务不可用,连接可能中断。
-
- Curator 会自动重试(你看到的
ExponentialBackoffRetry就是指数退避重试策略)。 - 如果重连成功,Curator 会重新建立 session(或新的 session),并尽可能恢复 watcher。
- 如果长时间连不上,会触发
KeeperException.OperationTimeoutException。
- Curator 会自动重试(你看到的
3.13. SpringBoot项目ElasticJob代码从启动在哪里? 启动过程哪些步骤流程? 代码入口是哪里? 项目怎么调度ElasticJob任务?
你的问题可以分成两块:
- ElasticJob 在 Spring Boot 项目中的启动入口和流程
- Spring Boot 项目中具体怎么调度 ElasticJob 的任务
3.13.1. ElasticJob 在 Spring Boot 中的启动入口和流程
Spring Boot 项目里引入 ElasticJob Starter(比如 elasticjob-lite-spring-boot-starter)后,启动过程大致是这样:
3.13.1.1. Spring Boot 启动时加载配置
application.yml / application.properties 中配置 Zookeeper 注册中心和 Job 相关信息,例如:
elasticjob:regCenter:serverLists: 127.0.0.1:2181namespace: elastic-job-demojobs:mySimpleJob:elasticJobClass: com.example.job.MySimpleJobcron: 0/5 * * * * ?shardingTotalCount: 2shardingItemParameters: 0=A,1=B这些配置会被 ElasticJob 的 AutoConfiguration 读取。
3.13.1.2. 注册中心初始化
- 代码入口在
ZookeeperRegistryCenter→init()方法(你前面发的那段CuratorFrameworkFactory.builder()的代码)。 - 它会建立 ZK 客户端连接,并在
namespace下创建持久节点,作为任务协调的注册中心。
3.13.1.3. Leader 选举机制启动
SchedulerElectionService会通过 ZK 的 LeaderLatch 进行 Leader 选举。- 当某个节点成为 Leader 时,它会负责调度任务,其他节点则作为备用。
- 你之前看到的
executeInLeader(...)就是这部分逻辑。
3.13.1.4. Job 注册 & 调度器启动
- Spring Boot 会扫描到
@ElasticJobConf(或配置的elasticJobClass),并把你的 Job 类注册到JobScheduler。 JobScheduler内部会创建SchedulerFacade→JobScheduleController,最终调用 Quartz 来执行任务调度。
-
- Quartz 用来做 定时触发。
- ElasticJob 在 Quartz 的基础上加了 分片、失效转移、弹性扩缩容、分布式协调。
3.13.1.5. 任务开始调度
- 一旦 Quartz 触发了某个任务,ElasticJob 内部会根据 分片策略 计算当前节点是否应该执行对应分片。
- 如果当前节点负责某些分片,就会调用你实现的
SimpleJob/DataflowJob/ScriptJob的execute()方法。
3.13.2. 在 Spring Boot 项目中调度 ElasticJob 任务
3.13.2.1. 定义一个任务类
@Component
public class MySimpleJob implements SimpleJob {@Overridepublic void execute(ShardingContext shardingContext) {System.out.println("分片项: " + shardingContext.getShardingItem() + " 参数: " + shardingContext.getShardingParameter());}
}3.13.2.2. 配置任务
方式一:YAML 配置(推荐)
elasticjob:jobs:mySimpleJob:elasticJobClass: com.example.job.MySimpleJobcron: 0/10 * * * * ?shardingTotalCount: 2shardingItemParameters: 0=A,1=B方式二:手动注入 JobScheduler
@Bean(initMethod = "init")
public JobScheduler myJobScheduler(ZookeeperRegistryCenter regCenter, MySimpleJob job) {LiteJobConfiguration jobConfig = LiteJobConfiguration.newBuilder(new SimpleJobConfiguration(JobCoreConfiguration.newBuilder("mySimpleJob", "0/5 * * * * ?", 2).shardingItemParameters("0=A,1=B").build(),job.getClass().getCanonicalName())).overwrite(true).build();return new SpringJobScheduler(job, regCenter, jobConfig);
}3.13.2.3. 启动后调度流程
- Spring Boot 启动 → Zookeeper 注册中心建立连接。
- Leader 选举 → 选出一个节点做调度器。
- Quartz 定时触发 → ElasticJob 判断分片。
- 分片分配给不同实例 → 调用
execute()执行业务逻辑。
博文参考
- ElasticJob - Distributed scheduled job solution
- Elasticjob 3.x 最新版本源码解读(含备注源码) - ityml - 博客园