ChipCamp探索系列 -- 4. Intel CPU的十八代微架构
进阶到CPU/RISC-V/GPU芯片设计之前,先梳理一下CPU架构的关键技术名词和术语,为此梳理了Intel CPU的十八代微架构。这些不是它的全部芯片,但却足以反映出现代高性能(面向桌面/服务器/通用应用的)处理器的微架构主流套路和技术术语。
以下链接是本次梳理的脉络参考:
https://en.wikipedia.org/wiki/List_of_Intel_CPU_microarchitectures
一、8086:显然没有流水线,但是对从第一性原理出发学习“如何制造计算机/CPU”却是一个很好的参考----计算机/CPU芯片,从架构原理这一级别,就是这样的/就是这么简单/要先无畏地看淡它----40多年前就可以造出计算机芯片现在应该人人都可以造出芯片&更不用说学习芯片设计。这里很有意思的一个地方是3和9,它们都是加法器,但一个是adderss加法器(对地址加一个立即数的偏移量获得新的地址),一个是用户数据的加法器,此前的关于RISC-V CPU的Chisel实现中就有这个问题/困惑/疑问。现在看来,这两者是公用,还是不共用,都是可以的&有先例的,后面还可以看到ALU和AGU的概念区分,也和这个有关。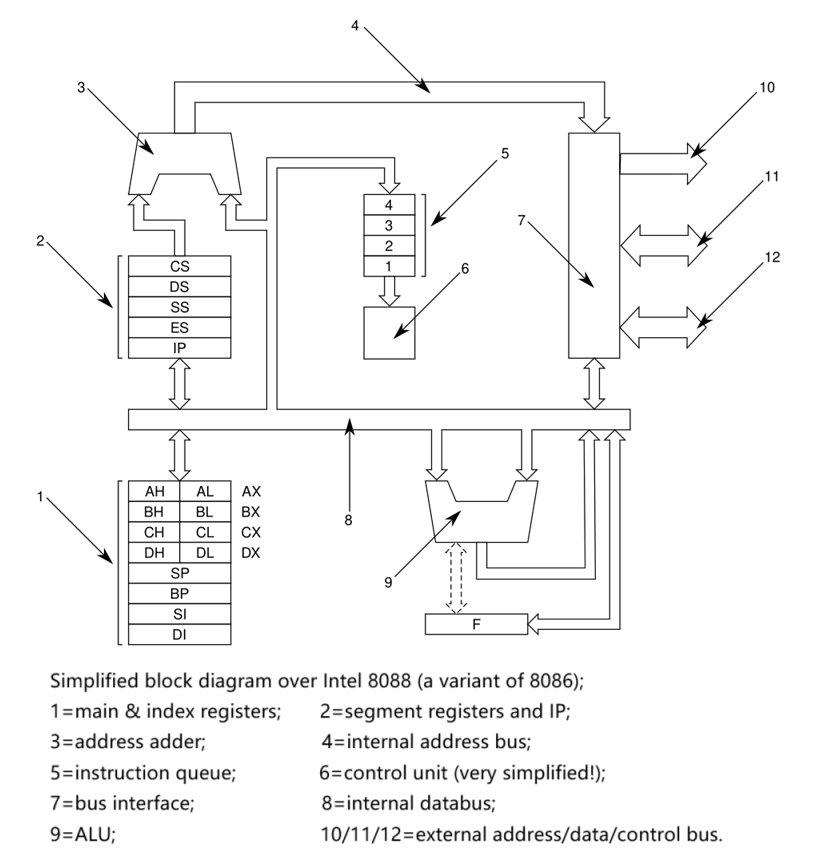
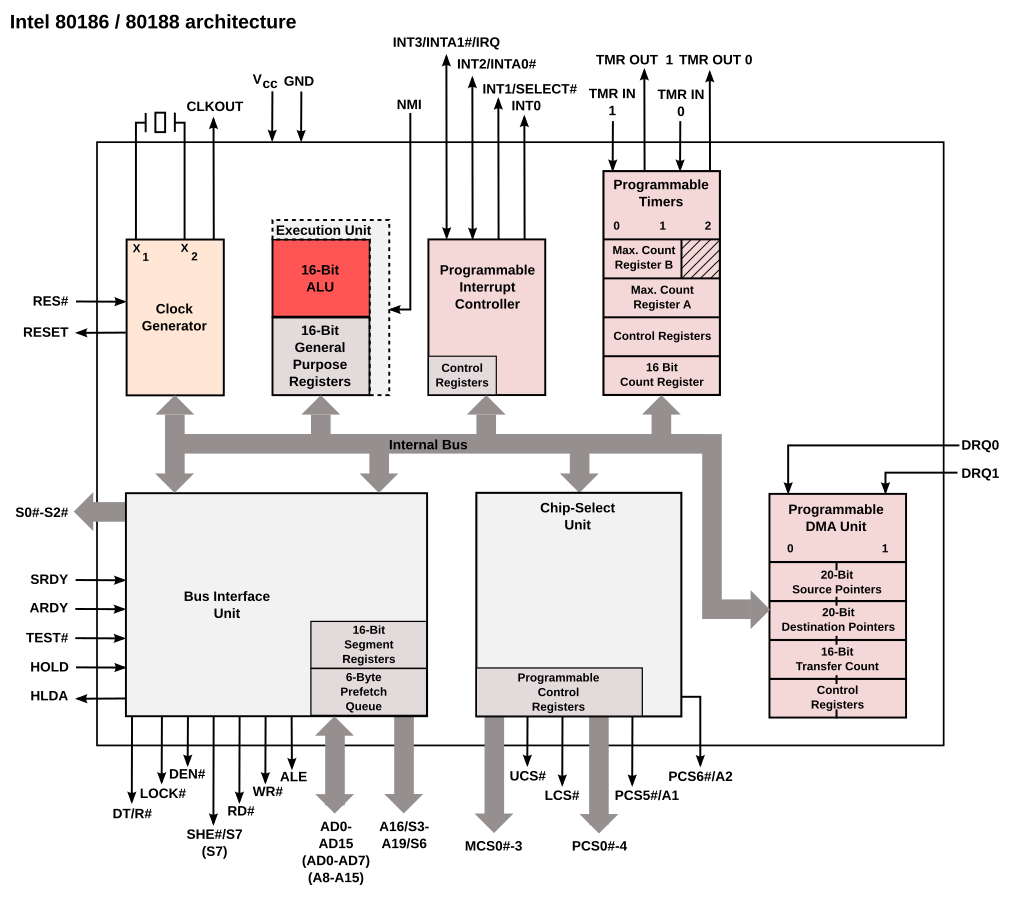
二、80186:虽然没有看到流水线,但是外设接口+中断控制器+DMA的概念已经可以看出“通用计算”和“PC”的特征了。
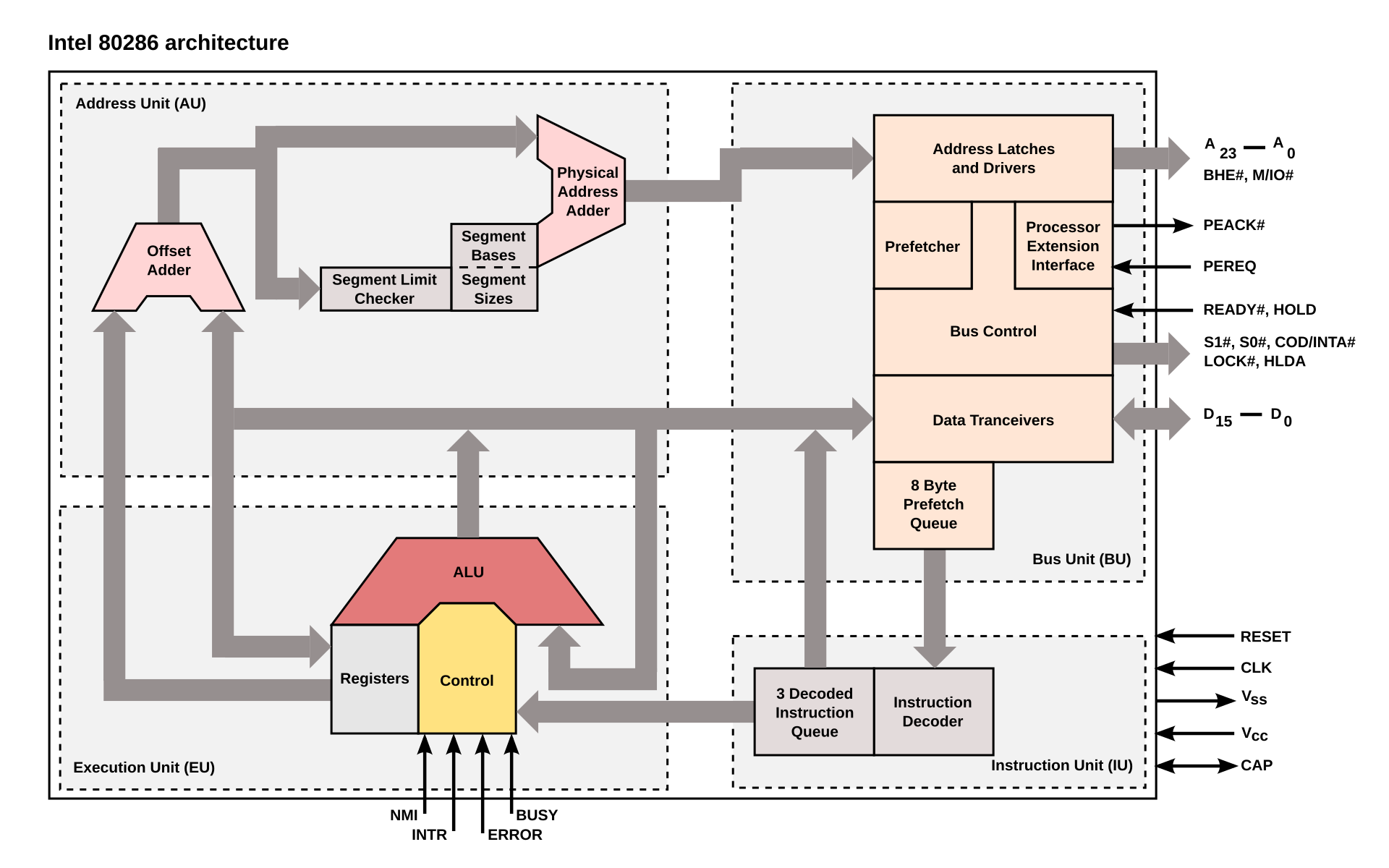
三、80286:很清晰的模块划分,取指令-解码-执行-内存访问-写回这些流水线 特征已然可见。
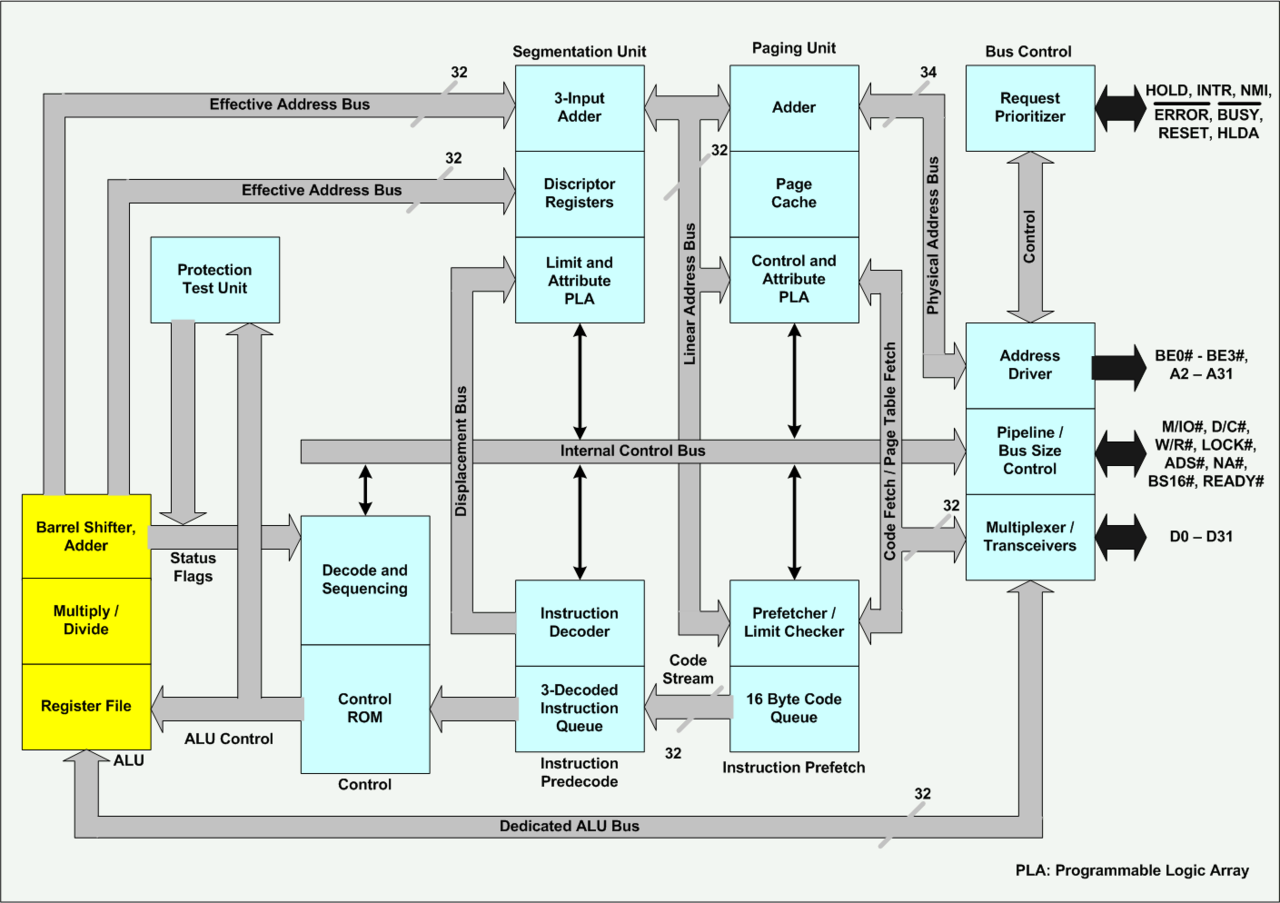
四、80386:32位地址总线+32位数据总线+ALU里已经包含了乘除法。
五、80486:ALU+FPU亮点1。Cache亮点2。Micro-Instruction(即uop)亮点3。
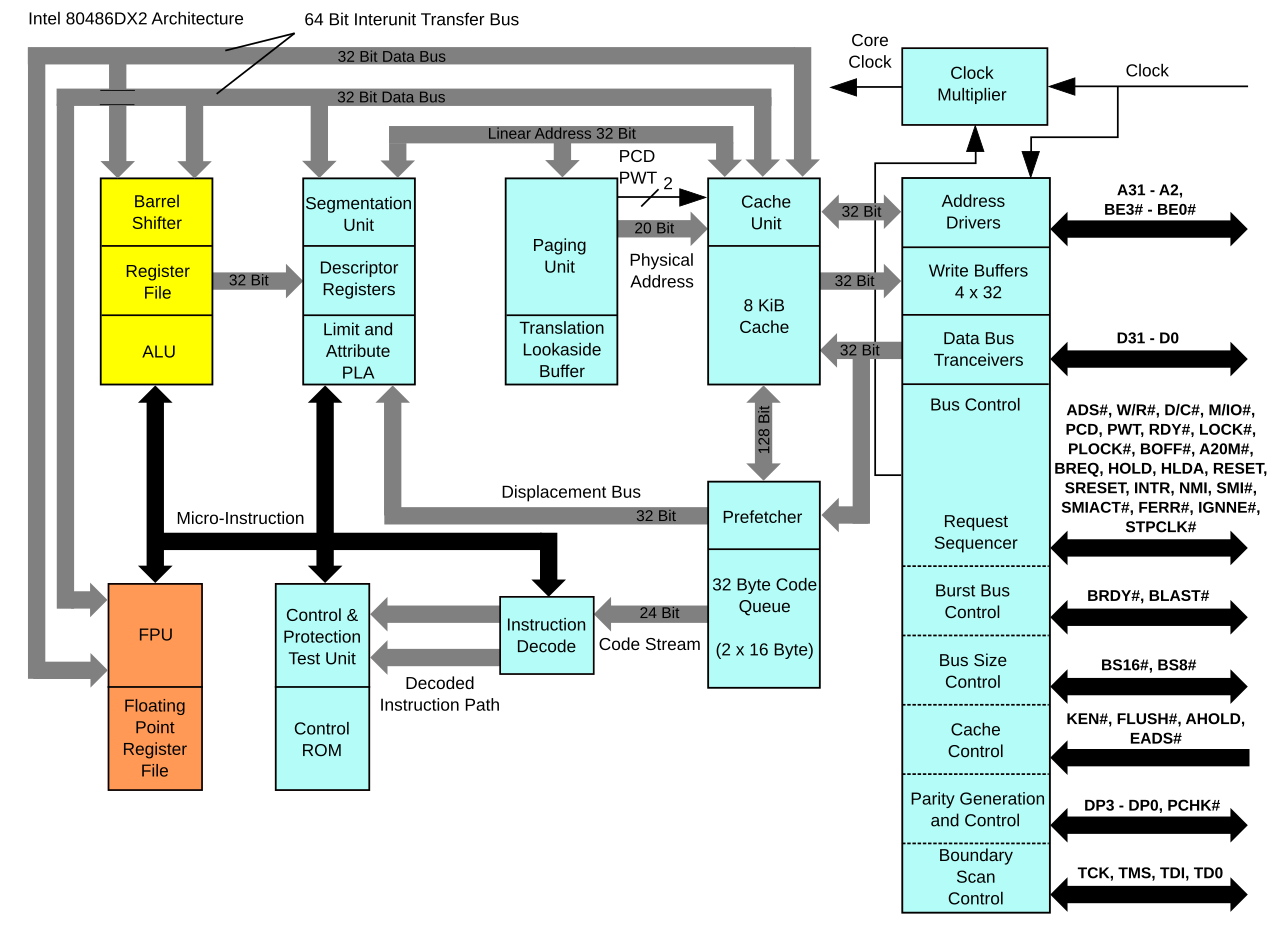
六、Pentium(P5):64bit数据宽度。Branch-Target-Buffer预示着分支预测。
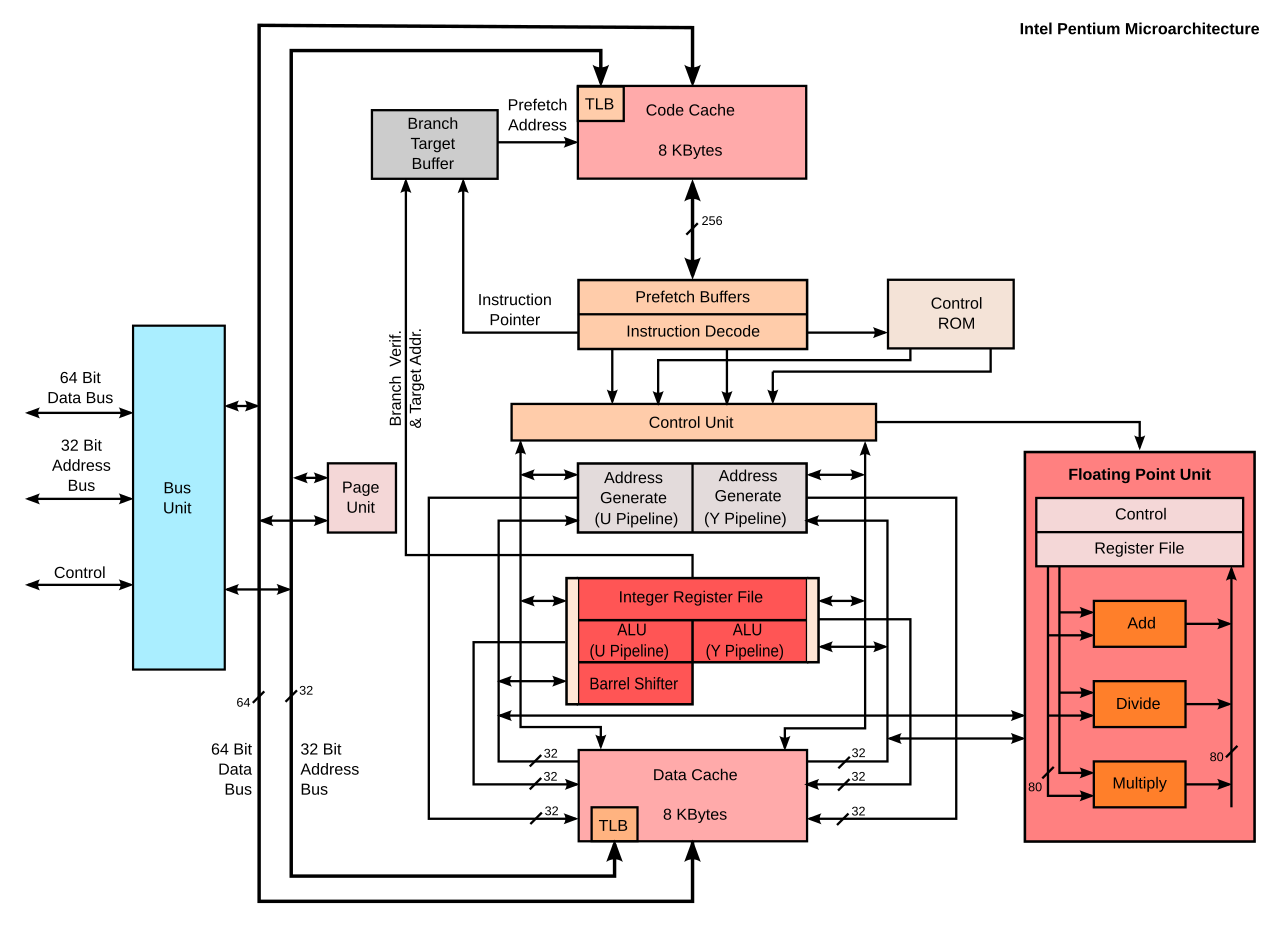
七、Pentium(P5) MMX:ALU+FPU+MMX Unit(整数+浮点数+向量)并列的计算部件!!
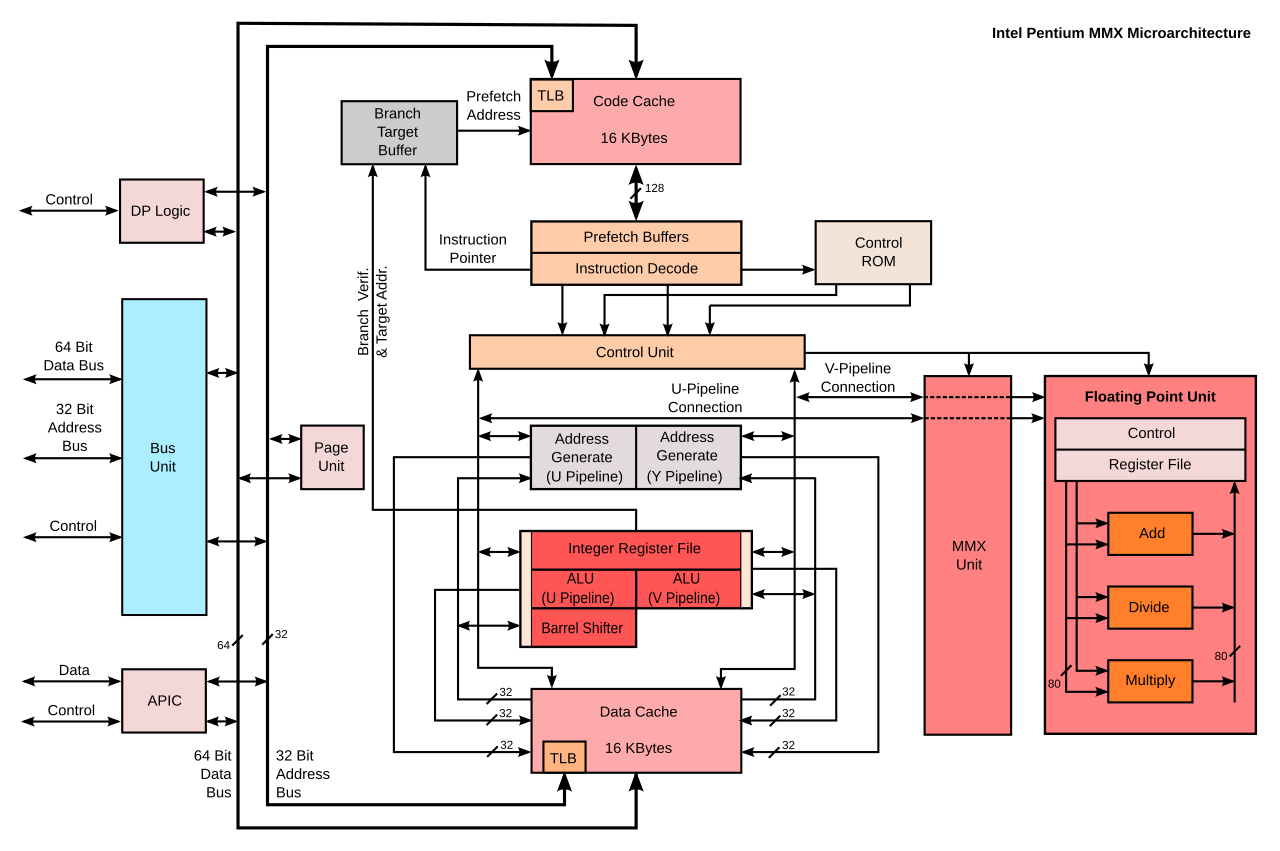
八、NetBurst (Pentium 4):ucode/uop亮点1。rename/dispatch/ROB亮点2。LoadStore和ExeEngine的“并列”关系,可能和后面AGU的概念是类似的,从内存到缓存的控制越发重要。
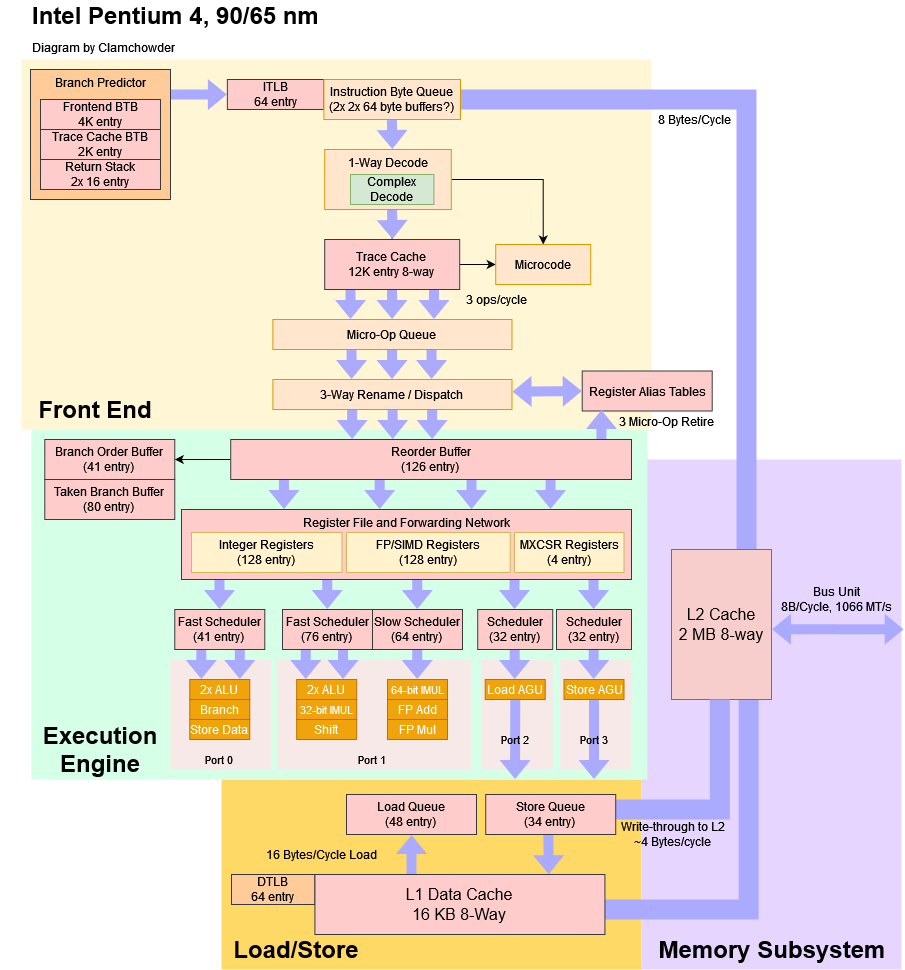
九:Core2(始于2006年的多核处理器微架构):保留站RS。L2共享缓存+L1分离缓存。
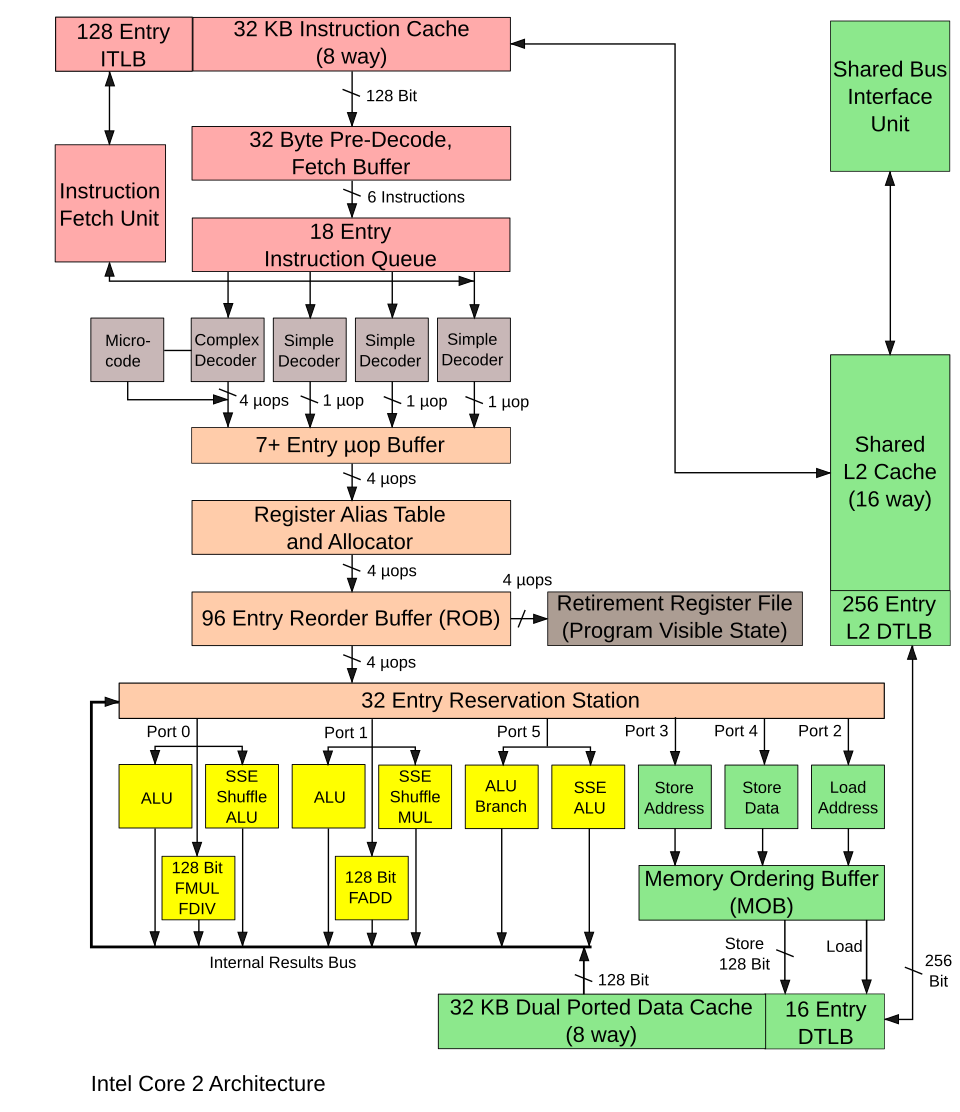
十、Nehalem微架构2008:uOP中的RAT+Retirement。MOB在上一幅图也有!
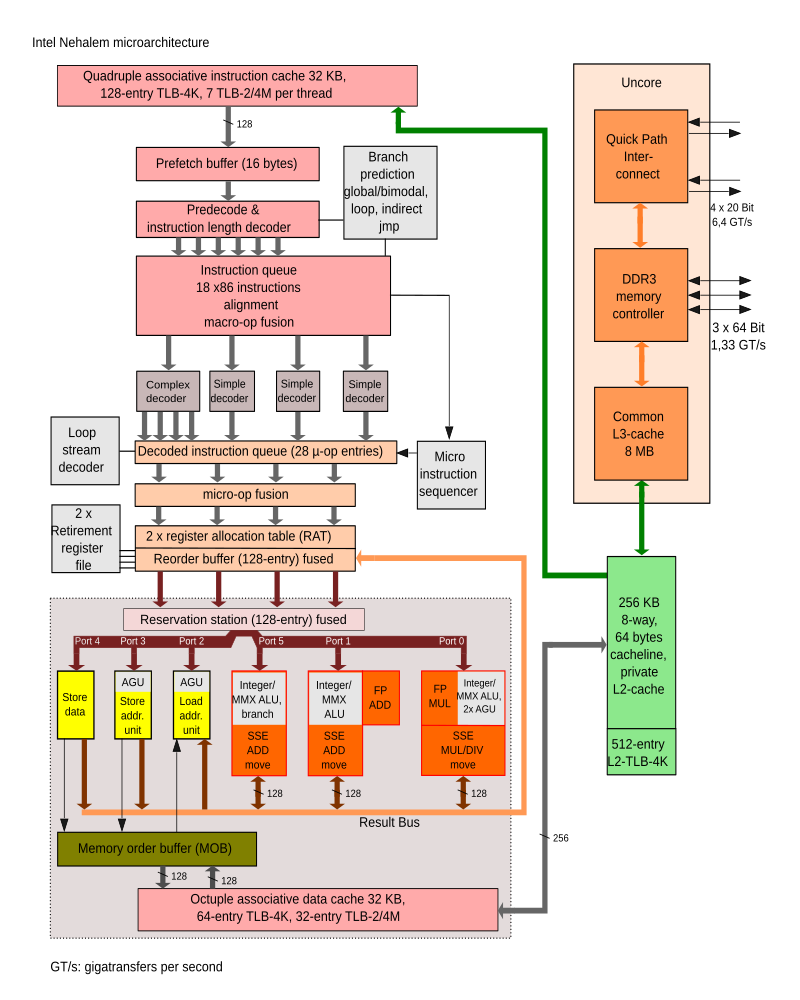
十一、Westmere微架构2010年:集成了GPU(显卡而非AI)。
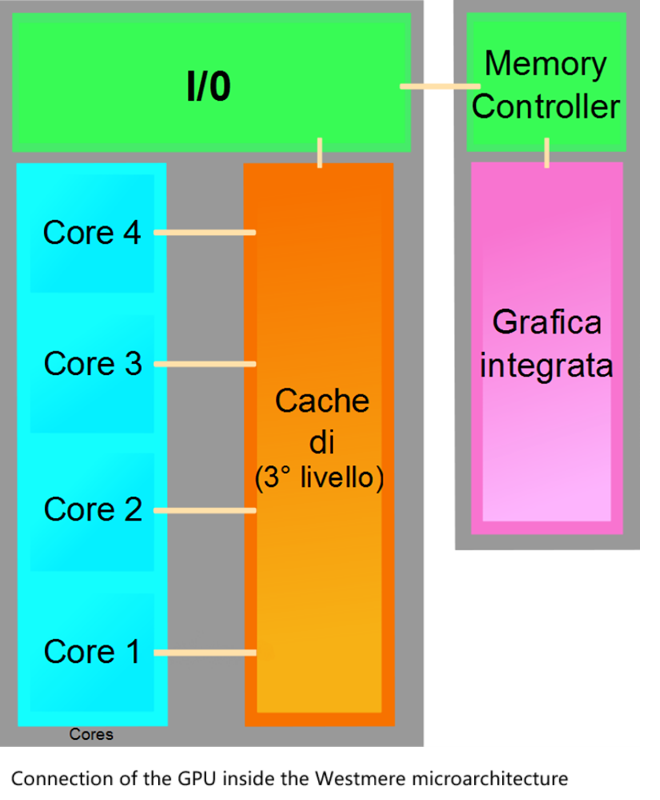
十二、Sandy Bridge微架构2011:似乎和前面的一个图一样只是指标变大了。
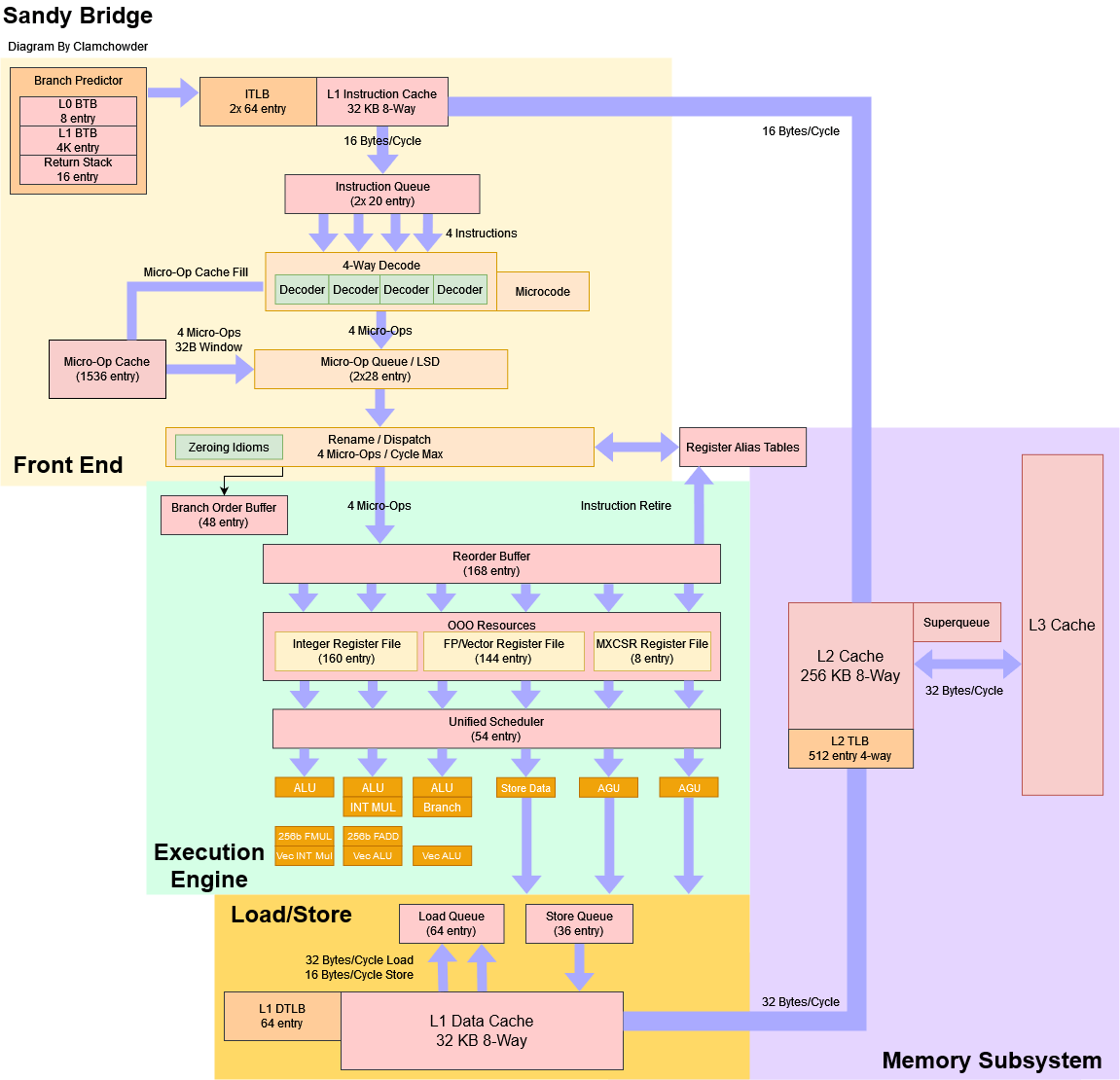
十三、Ivy Bridge微架构2012:似乎和前面的一个图一样只是指标变更大了(L2Cache->L1ICache)。
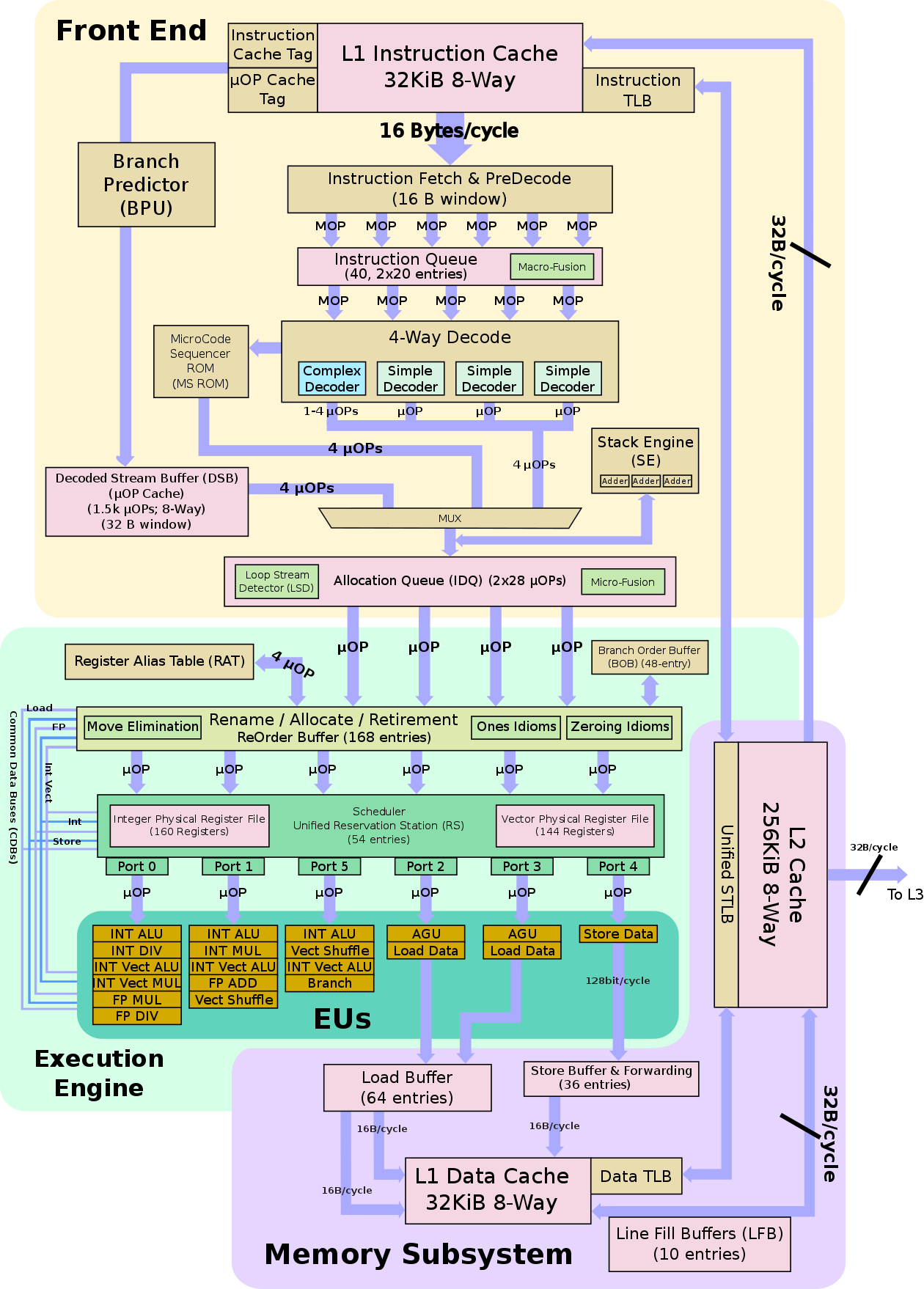
换一个风格的图:
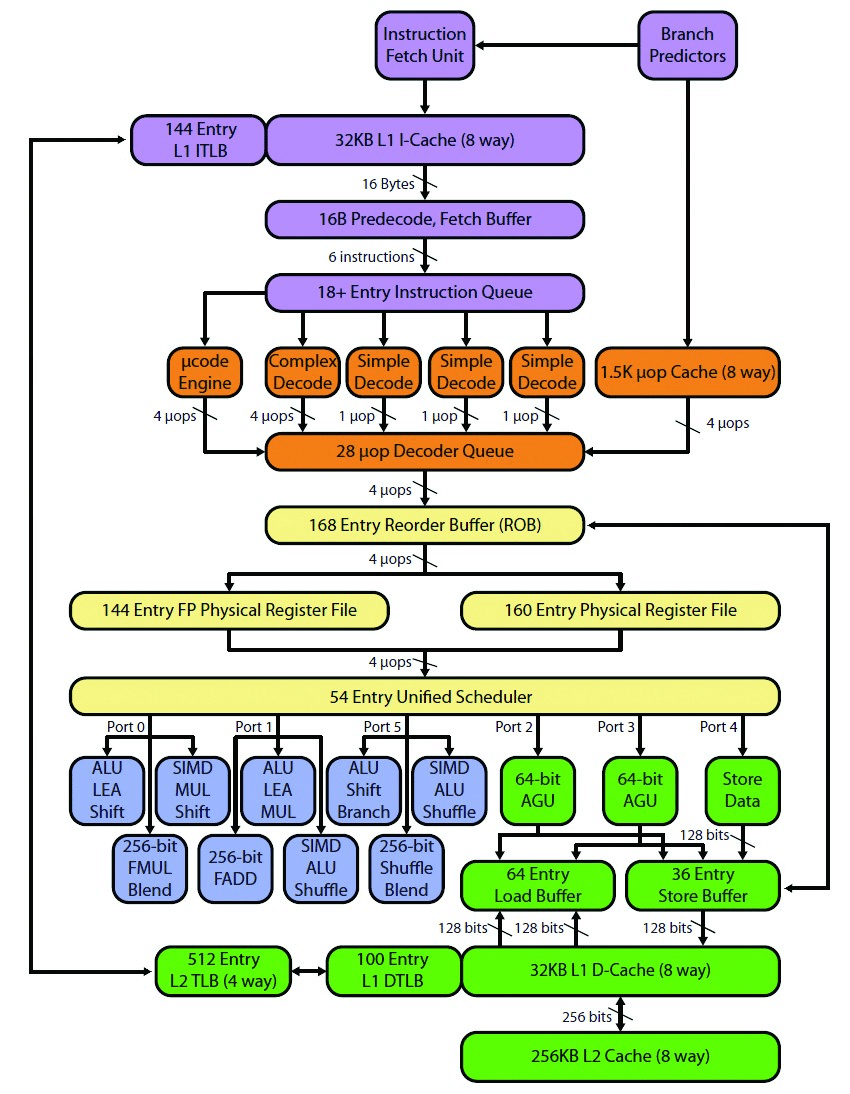
十四:SkyLake微架构2015:又又又变大了L2Cache->L1ICache之间的吞吐。
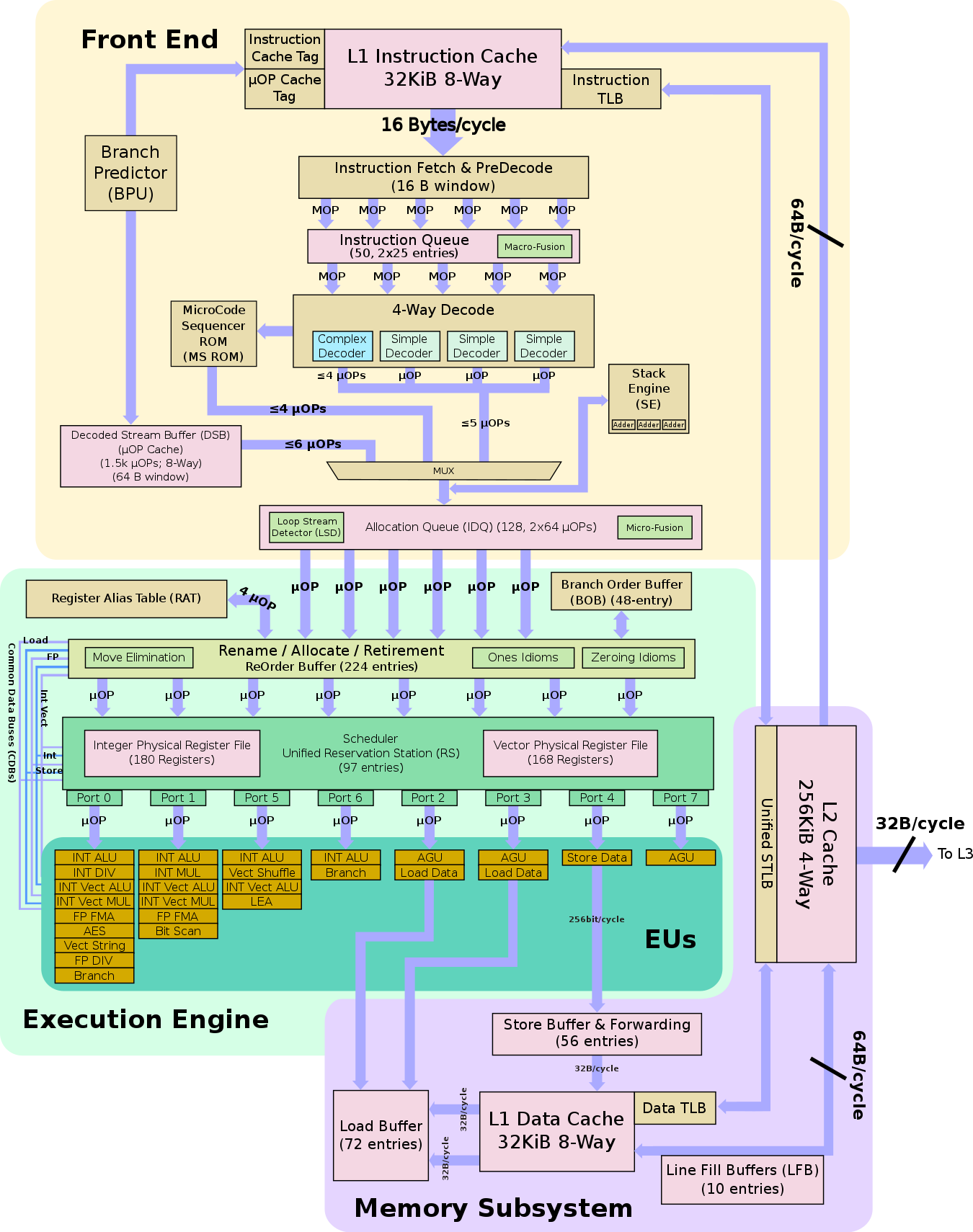
十五、Sanny Core微架构2019年(9代i7这样的):AVX-512单拎出来高亮。
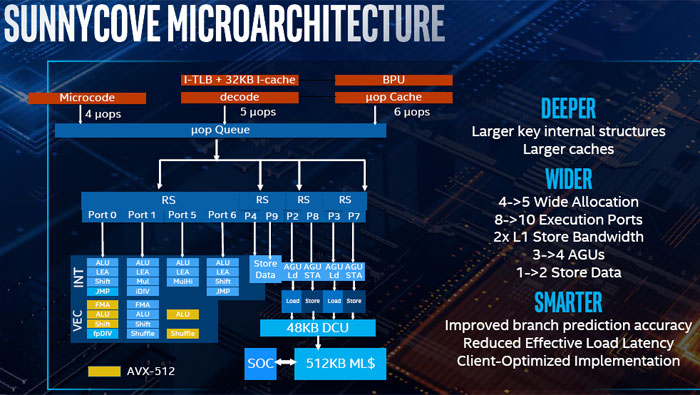
十六、Golden Cove微架构2021:从图上看Vector Execution分离出来了。
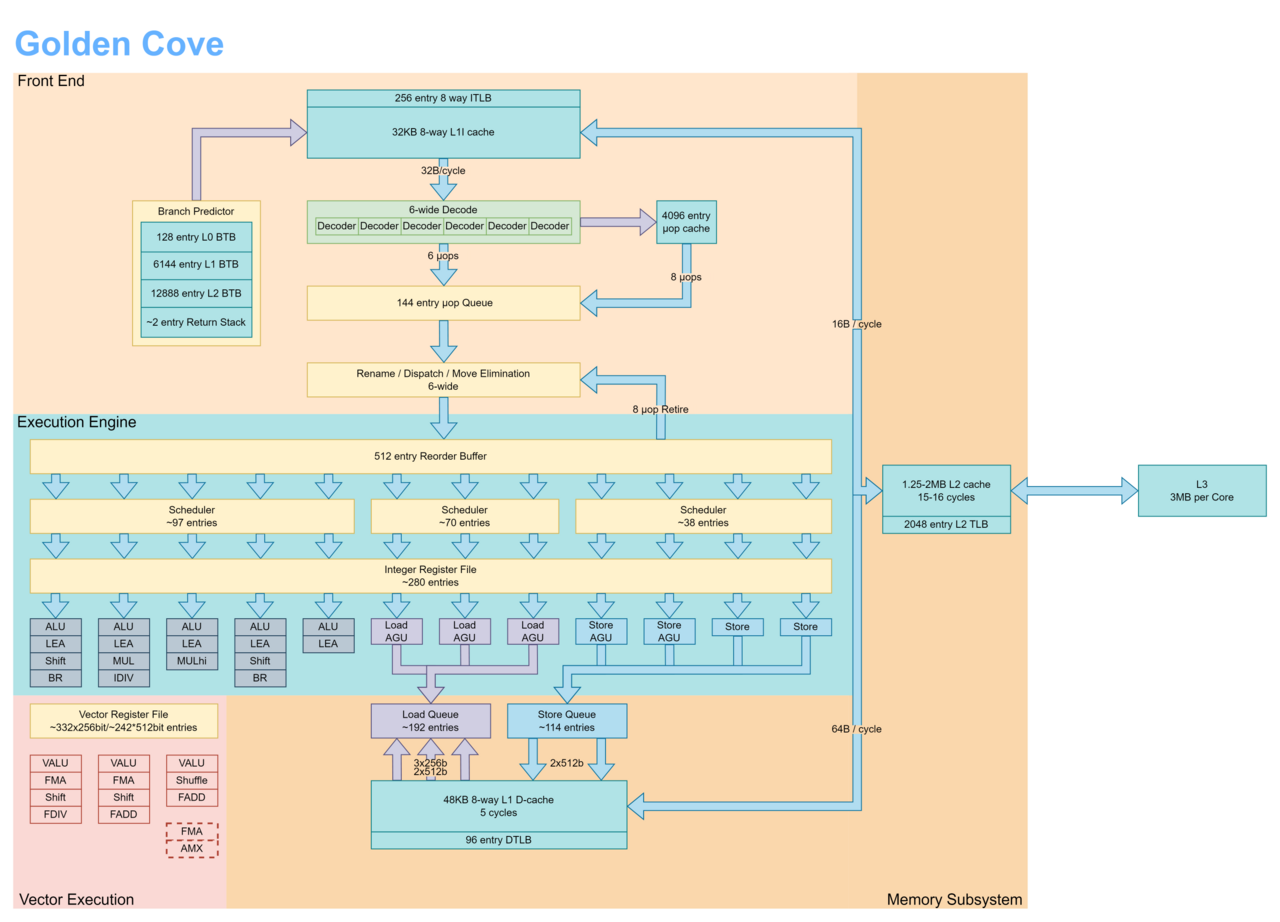
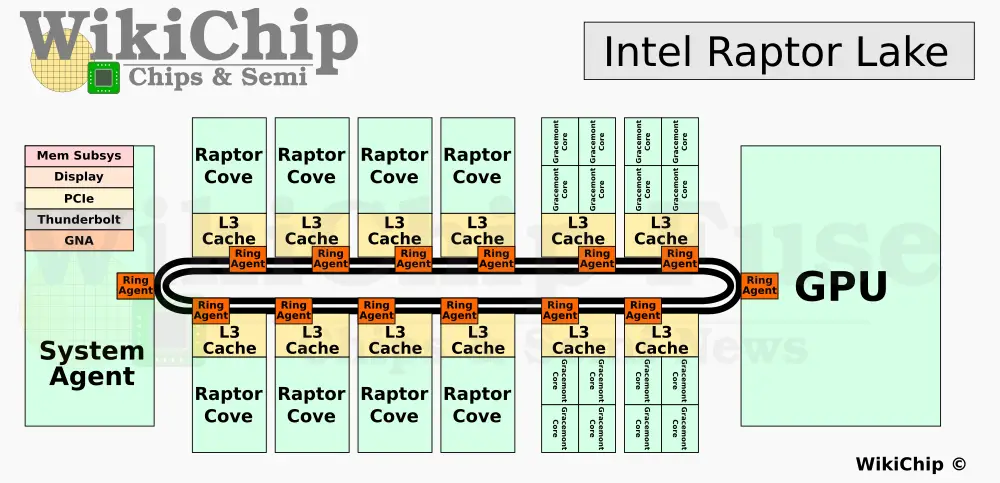
十七、Raptor Lake微架构2022:这个GPU大概也是显卡而非AI。
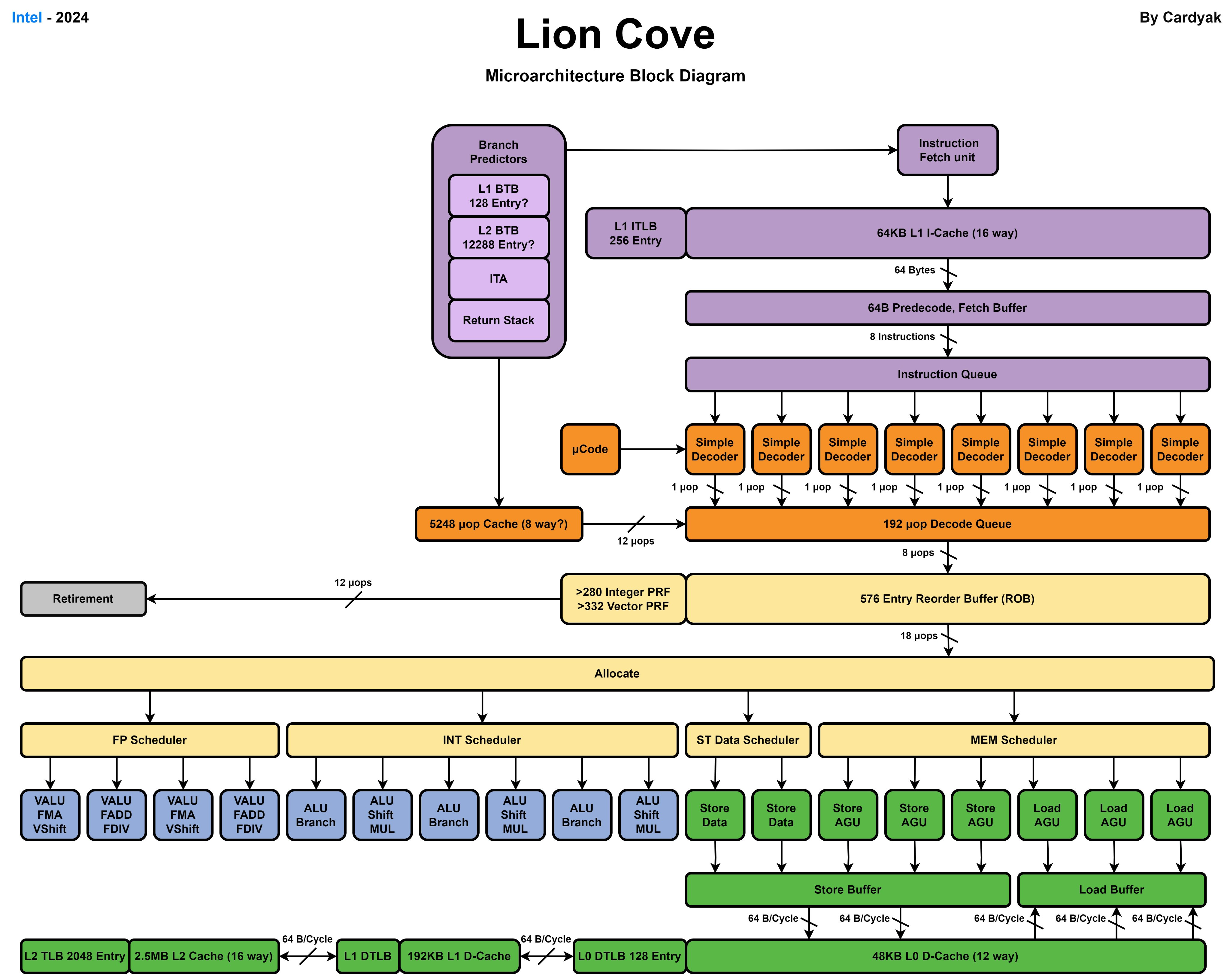
十八、Lion Cove微架构2024:
从远古到现代的CPU微架构的核心技术名词总结和预告:
五级流水线:IF(取值),ID(指令解码),EX(指令执行),MEM(内存访问),WB(写回)。
超标量流水线:uCode(微码),uop(微操作),X Way(多路),ROB(重排序缓冲),Scheduler(调度器),Rename(重命名)、Dispatch(分发)、Issue(发射)、RS(保留站)、Retirement(退休)。
计算单元:ALU(算术裸机单元)、FPU(浮点处理单元)、Vector(向量处理单元)、AGU(地址生成单元)、LSU(加载和存储单元)、MUL/DIV(乘法/除法)。
内存和缓存:L2 Cache通常是统一缓存(地址和指令不分开),而L1 Cache则是指令和数据分开的(I Cache和D Cache)。L2-L1的Cache搬移带宽吞吐有“挤牙膏”的空间。
这些将成为下一步探讨“如何设计出/如何造出”高性能超标量CPU芯片,以及为此要理解CPU芯片的代码,做一个铺垫。Cheers。