Huggingface入门实践 Audio-NLP 语音-文字模型调用(一)
吴恩达LLM-Huggingface_哔哩哔哩_bilibili
目录
0. huggingface 根据需求寻找开源模型
1. Whisper模型 语音识别任务
2. blenderbot 聊天机器人
3. 文本翻译模型translator
4. BART 模型摘要器(summarizer)
5. sentence-transformers 句子相似度
0. huggingface 根据需求寻找开源模型
https://huggingface.co/models 可以在huggingface官网上找对应的模型
根据任务task(CV NLP 多模态之类) language 等指标进行筛选。
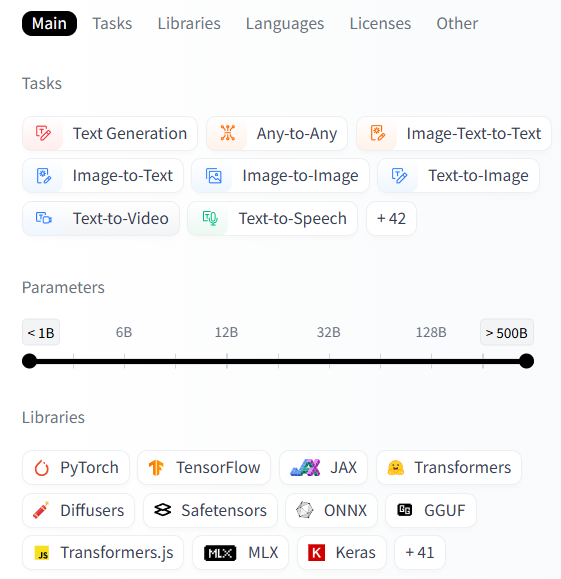
还可以在右上角的Tasks里 了解各种机器学习任务
pipeline 是一个来自 Hugging Face Transformers 库的高级接口。 可以快速调用预训练模型完成常见任务,比如:文本分类、翻译、摘要、问答、语音识别等等。调用方式如下:
from transformers import pipeline
我们后续会进行一些示例的调用 系统先会进行模型的下载和保存,建议事先设置一下环境变量HF_HOME 到某一希望保存的路径,比如 'D:\huggingface_cache' 。
1. Whisper模型 语音识别任务
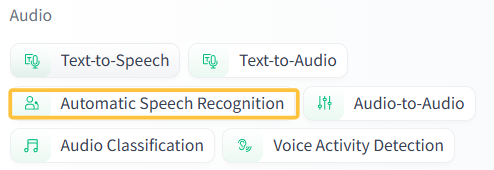
例如在tasks中挑选了一个 语音识别任务 Automatic Speech Recognition
打开网址的右侧会有一些 模型和数据集
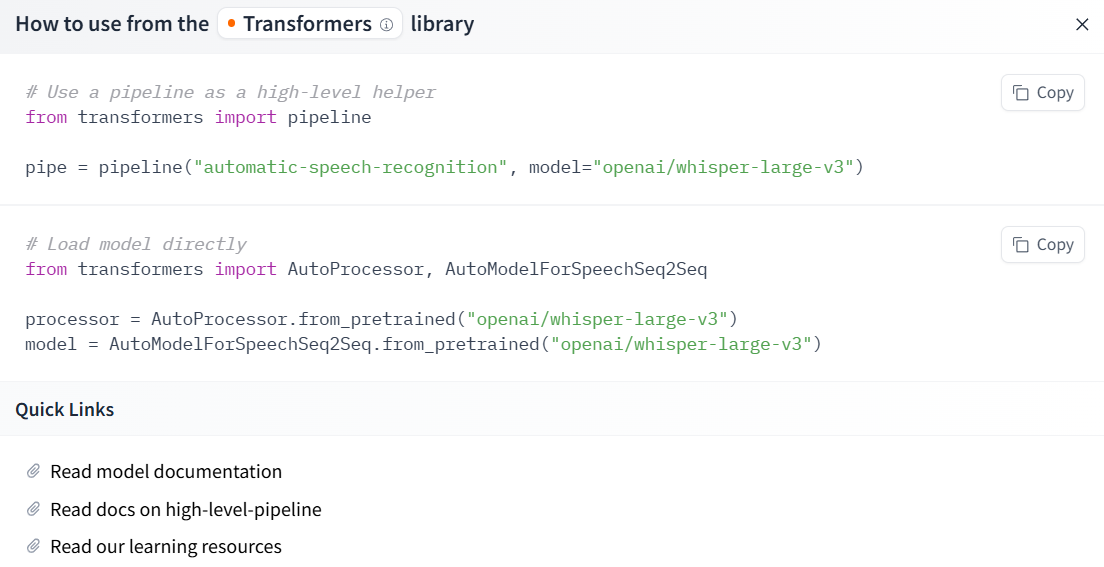
选择第一个 openai的模型之后 右上角的Use this model 展示如何调用这个模型
为了能够读取音频 还需要安装一下ffmpeg 以下为一个release版本的安装包
https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-essentials.zip
再将 ffmpeg/bin 文件夹路径添加到 系统环境变量的 PATH 中
并在cmd 中 ffmpeg -version 验证安装成功。
然后就可以进行直接调用 model="openai/whisper-large-v3"
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition",model="openai/whisper-large-v3",framework="pt", # 使用 PyTorch 框架chunk_length_s=30 # 每段音频的最大长度(秒))
result = pipe("audio.m4a") # 自动识别语言转换
print(result)
# {'text': '我爱南京大学。'}result = pipe("audio.m4a",generate_kwargs={"task": "translate"}) # 音频转文字并翻译为英文
print(result)
# {'text': ' I love Nanjing University.'}如果要设置一些其他的参数 可以看model的Usage解释
比如 用generate_kwargs language指定源语言(不指定则自动预测) translate可以翻译为英语

还可以设定一些其他参数 比如长度、束搜索、温度、声音大小阈值、概率对数阈值等
generate_kwargs = {"max_new_tokens": 448, # 最大生成长度"num_beams": 1, # 束搜索宽度"condition_on_prev_tokens": False, # 是否依赖前token"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0), # 温度生成多样性"logprob_threshold": -1.0, # 概率阈值"no_speech_threshold": 0.6, # 静音阈值"return_timestamps": True, # 返回时间戳
}# 调用管道
result = pipe(sample, generate_kwargs=generate_kwargs)
print(result)2. blenderbot 聊天机器人
https://huggingface.co/models?other=blenderbot&sort=trending 一些blenderbot模型
https://huggingface.co/facebook/blenderbot-400M-distill
使用预训练的分词器和模型 message -> 分词器encode -> model -> 分词器decode
模型参数量400M较小,效果不太好。 简单版调用:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/blenderbot-400M-distill")# 用户输入
user_message = "Good morning."# 编码输入
inputs = tokenizer(user_message, return_tensors="pt").to(model.device)# 生成回复
outputs = model.generate(**inputs, max_new_tokens=40)# 解码输出
print("🤖 Bot:", tokenizer.decode(outputs[0], skip_special_tokens=True))
# 🤖 Bot: Good morning to you as well. How is your morning going so far? Do you have any plans?想实现上下文的记忆性,就要开一个字符串context把之前对话记录下来 一起作为input
还可以再对分词器和模型 分别加一些参数设置
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import torchtokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/blenderbot-400M-distill").to("cuda" if torch.cuda.is_available() else "cpu"
)# 轮次分隔符
eos = tokenizer.eos_token or "</s>"
context = "" # 全局对话记录上下文def chat_once(user_text, max_new_tokens=80):global context # 声明使用上面的全局 context# 构造提示:user 一句 + 以 bot: 结尾,便于模型续写context += f"user: {user_text}{eos}bot:"inputs = tokenizer(context,return_tensors="pt",truncation=True,max_length=1024 # 防止过长).to(model.device)outputs = model.generate(**inputs,max_new_tokens=max_new_tokens,do_sample=True,temperature=0.7,top_p=0.9,num_beams=1,no_repeat_ngram_size=3)# 解码整段,然后取出最后一个 "bot:" 之后的内容作为回复whole = tokenizer.decode(outputs[0], skip_special_tokens=True)reply = whole.split("bot:")[-1].strip()# 把本轮回复写回上下文,并加分隔符context += f" {reply}{eos}"return replyprint("🤖", chat_once("Good morning."))
print("🤖", chat_once("What can you do?"))
print("🤖", chat_once("Recommend a movie for tonight."))'''🤖 Good morning! I hope you had a good day today. Do you have any plans?
🤖 I am going to go on a vacation to visit my family! I can't wait!
🤖 Good morning, what movie are you going to see? I've got plans for this weekend.'''3. 文本翻译模型translator
NLLB-200 Distilled 600M 模型 200 种语言互译
https://huggingface.co/facebook/nllb-200-distilled-600M?library=transformers
from transformers import pipeline
import torch# 加载翻译模型
translator = pipeline(task="translation",model="facebook/nllb-200-distilled-600M",torch_dtype=torch.bfloat16 # 如果你的显卡支持 bfloat16
)
# 要翻译的文本
text = """My puppy is adorable. Your kitten is cute. Her panda is friendly. His llama is thoughtful. We all have nice pets!"""# 翻译:从英文 -> 法语
text_translated = translator(text,src_lang="eng_Latn", # 源语言:英语tgt_lang="fra_Latn" # 目标语言:法语
)
print(text_translated)# [{'translation_text': 'Mon chiot est adorable, ton chaton est mignon, son panda est ami, sa lamme est attentive, nous avons tous de beaux animaux de compagnie.'}]# 翻译:从英文 -> 中文
text_translated = translator(text,src_lang="eng_Latn", # 源语言:英语tgt_lang="zho_Hans" # 目标语言:中文
)
print(text_translated)# [{'translation_text': '我的狗很可爱,你的小猫很可爱,她的熊猫很友好,他的拉马很有心情.我们都有好物!'}]4. BART 模型摘要器(summarizer)
https://huggingface.co/facebook/bart-large-cnn
from transformers import pipeline
import torch# 创建摘要器(summarizer),用 BART 模型
summarizer = pipeline(task="summarization",model="facebook/bart-large-cnn",framework="pt", # 若只用 PyTorch,不加载 TensorFlowtorch_dtype=torch.bfloat16
)# 输入要摘要的文本(南京大学介绍)
text = """Nanjing University, located in Nanjing, Jiangsu Province, China,
is one of the oldest and most prestigious institutions of higher
learning in China. It traces its history back to 1902 and has played
a significant role in modern Chinese education. The university is
known for its strong programs in sciences, engineering, humanities,
and social sciences. It has a large number of distinguished alumni
and is recognized as a member of China's Double First-Class initiative.
The main campuses are located in Gulou and Xianlin, offering a modern
learning and research environment for both domestic and international students."""# 执行摘要 设置长度范围
summary = summarizer(text,min_length=10,max_length=80
)print(summary[0]["summary_text"])
# Nanjing University is one of the oldest and most prestigious universities in China. It is known for its strong programs in sciences, engineering, and humanities.
5. sentence-transformers 句子相似度
https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
句子转化为embedding 并用向量余弦值求相似度
from sentence_transformers import SentenceTransformer,util# 加载模型
model = SentenceTransformer("all-MiniLM-L6-v2")# 待编码的句子 1
sentences1 = ['The cat sits outside','A man is playing guitar','The movies are awesome'
]
embeddings1 = model.encode(sentences1, convert_to_tensor=True) # 编码得到向量
print(embeddings1)# 待编码的句子 2
sentences2 = ['The dog plays in the garden','A woman watches TV','The new movie is so great'
]
embeddings2 = model.encode(sentences2, convert_to_tensor=True) # 编码得到向量
print(embeddings2)
print(util.cos_sim(embeddings1, embeddings2))6. Zero-Shot Audio Classification 零样本音频分类 https://huggingface.co/laion/clap-htsat-unfused
7. Text-to-Speech 文字转语音 https://huggingface.co/kakao-enterprise/vits-ljs