AI 向量库:从文本到数据的奇妙之旅
目录
一、向量库扮演啥角色
二、向量库中的词向量如何进阶而来
2.1、词袋法:文本向量化的蹒跚学步
2.2、TF-IDF 法:筛选关键词的进阶之路
2.3、Word Embedding 之 Word2Vec 算法:探索语义关系的开端
2.4、Transformer 的 Attention 机制与 BGE 模型:突破语义理解的局限
一、向量库扮演啥角色
在人工智能的世界里,有许多神秘而又强大的概念,今天咱们就来聊聊其中一个重要角色 —— 向量库,以及它背后那些有趣的知识。
咱们先从大语言模型(LLM)说起。你可以把 LLM 想象成一个聪明但知识储备有限的孩子,虽然脑袋瓜灵活,可专业知识就像幼儿园小朋友一样,不够丰富。这时候,RAG(Retrieval Augmented Generation,检索增强生成)就登场啦,它像是一个专业书籍(外挂知识库),更准确地说,是一个能让 LLM 获取更多知识的框架。有了专业数据( RAG),LLM 就能从里面 “吸收” 专业知识,变得更厉害。而在 RAG 这个 “外挂” 里,向量库又起着关键作用。
那啥是向量库呢?简单来讲,向量库就是一个存向量的地方。可问题来了,文本、文字怎么就变成向量了呢?
这得从计算机的 “语言” 说起,计算机只能理解数字,文本没法直接在它那儿进行计算,所以得把文本转换成计算机能懂的数据形式,这个过程就叫文本向量化。
接下来,让我们一步步揭开文本向量化的神秘面纱,看看它是如何从简单走向复杂,不断升级的。
二、向量库中的词向量如何进阶而来
2.1、词袋法:文本向量化的蹒跚学步
最开始,人们想出了词袋法。这就好比有一个超级大的袋子,咱们把一句话里的词都拿出来,像 “我喜欢吃苹果”,就把 “我”“喜欢”“吃”“苹果” 这些词拿出来,然后去重,得到一个独一无二的词表。接着,拿其他文字去和这个词表比对,如果词表里有这个词,就标记为 1,没有就标记为 0。这样一来,这句话转换后的向量可能就是【1,1,0,1,……】,这里的 1 代表词表中有这个词,0 代表没有。
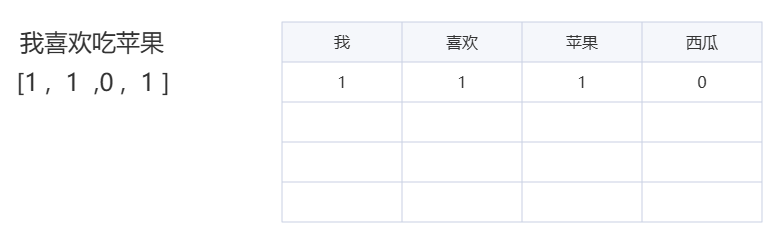
这种方法简单直接,就像小孩子刚开始学走路,虽然步伐不稳,但好歹迈出了第一步,成功地将文本中的词语与数字建立了初步联系,让计算机能对文本有了最基础的 “理解”,可以应用在一些简单的文本分类、检索等任务中 。就如同你刚刚学会识字,老师让你把一篇文章里所有不同的字找出来,组成一个 “字表”,然后看看另一篇文章里有没有这些字,有的就打个勾,没有的就空着,通过这种简单的方式,初步对文章的内容有个了解。
2.2、考虑词频的词袋法升级:更丰富的文本信息捕捉
但很快大家发现,这样不太准确,因为同样一个词,在不同句子里出现的频率不一样,可按之前的方法,不管出现多少次,标记都是 1,这就忽略了词频的信息也就是这个词出现的频率。于是,升级版出现了,不仅要知道有没有这个词,还要知道有多少个,像 “我喜欢苹果,我非常喜欢苹果”,转换后的向量可能就是【2,2,2,1,0,2,2……】,前面的 “2” 就表示 “我” 和 “喜欢” 出现了两次。
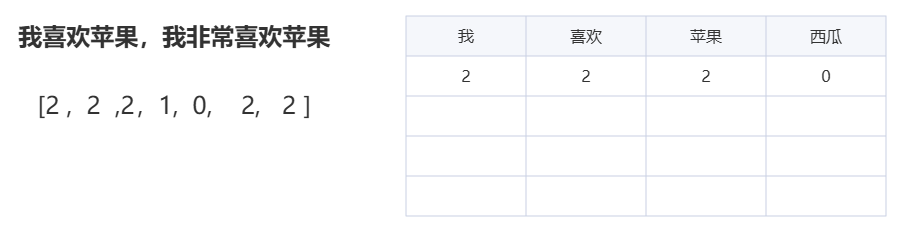
这两种方法,一个是去重词袋法,一个是无去重词袋法。这次升级就如同孩子学会了观察周围环境,意识到不同词语出现的频率不同,所携带的信息量也不一样,通过记录词频,能够让计算机获取到更丰富的文本信息,在一定程度上提升了文本向量化的准确性,使得基于词袋法的文本处理在更多场景下能够发挥作用 。这就好比你在统计班级同学喜欢的水果时,不仅要知道有多少同学喜欢苹果、香蕉、橘子,还要知道每个同学对每种水果的喜爱程度,是非常喜欢、一般喜欢,还是偶尔喜欢,这样统计出来的结果就更能反映大家对水果的喜好情况,计算机通过记录词频,也能更准确地了解文本的重点内容。
2.2、TF-IDF 法:筛选关键词的进阶之路
可新问题又冒出来了,怎么从这些词里选出关键词呢,也就是我怎么抓住话里的重点呢?一开始有人想,要不随机选,或者按频率选?但按频率选的话,如果有人说话一直重复某个词,那这个词不就成关键词了?
显然不行。所以,更科学的方法诞生了。出现的次数除以句子中词语的总数,这就表示词频;


同时,关键词一般也是稀有性的代表,稀有性则用在整个文档集合中的数量来表示,当总文档数一定时,含有某个词语越多,这个词语的稀有性就越低,也就越普通。不过,这样计算容易受极端值影响,所以在数据处理中,会通过 log 函数来让数据更平滑、结果更稳定。
把词频和稀有性相乘,就得到了 TF-IDF 法,这可是词袋法的超级升级版。

用 TF-IDF 法算出来的向量,数值高的对应的词,往往就是关键词,从简单的 “有没有”,到 “有多少”,再到 “有多稀缺”,包含的信息量越来越大。
TF-IDF 法如同为孩子配备了一个智能筛选器,不仅能看到词频,还能考虑词语在整个文档集合中的稀有程度,从而更精准地找出能够代表文本核心内容的关键词,极大地提升了文本处理中对重要信息的提取能力,广泛应用于信息检索、文本分类、关键词提取等众多领域 。
打个比方,在一个超级大的图书馆里,每本书都可以看作是一篇文档,每个词就像是书里的一个 “小零件”。有些词,比如 “的”“是”“了”,在很多书里都频繁出现,就像图书馆里到处都能看到的普通螺丝钉,虽然数量多,但并不特别重要。而有些专业术语,比如 “量子纠缠”,可能只在少数关于物理的书籍中出现,就像图书馆里那些珍贵的、独一无二的稀有文物。TF-IDF 法就像是一个智能寻宝器,它能帮我们在众多的 “词零件” 里,找到那些既在某篇文档中出现频率相对较高,又在整个图书馆(文档集合)里比较稀有的 “关键词宝物”,这些关键词能更好地代表某本书(文档)的独特内容。
2.3、Word Embedding 之 Word2Vec 算法:探索语义关系的开端
但词袋法和 TF-IDF 法都有个共同的问题,它们没有捕捉到词义,也就是词语的语义。因为在这些方法里,每个词都是孤立的,“苹果” 和 “水果” 之间的关系,它们根本不知道。为了解决这个问题,Word Embedding(词嵌入)出现了。这里不得不提谷歌的一个巧妙解法,谷歌认为,如果一些词经常一起出现,那它们很可能有相似的语义。
基于这个想法,提出了 Word2Vec 算法。它就像一个超级 “预言家”,使用神经网络,根据周围的词来预测中间的词,然后拿预测词和目标词比对,通过损失函数来调整预测的准确性。
Word2Vec 算法的出现,标志着文本向量化从单纯的词频、稀有性等统计特征,迈向了对词语语义关系的探索。它让计算机开始尝试理解词语之间的内在联系,例如知道 “汽车” 和 “轮胎”“方向盘” 等词存在某种关联,为后续更高级的自然语言处理任务奠定了基础,在语义相似度计算、文本聚类等方面展现出了强大的优势 。
想象一下,你来到了一个充满各种物品的魔法世界,每个物品都有一个对应的词语标签。词袋法和 TF-IDF 法只是在统计这些物品(词语)的数量和出现的位置,而 Word2Vec 算法就像是一个魔法小精灵,它发现如果 “汽车” 这个物品周围经常出现 “轮胎”“方向盘”“发动机” 等物品,那么这些物品之间很可能存在某种神秘的联系,就像它们是一个大家族的成员。
于是,小精灵通过不断地观察和学习(利用神经网络根据周围词预测中间词),把这些物品(词语)之间的关系找了出来,让计算机也能像我们人类一样,感受到词语之间的语义关联,比如知道 “香蕉”“苹果”“橙子” 都属于 “水果” 这个大家庭,这为计算机更好地理解语言打开了一扇新的大门。
2.4、Transformer 的 Attention 机制与 BGE 模型:突破语义理解的局限
可 Word2Vec 也不是完美无缺,它没有考虑词语的顺序,“我爱你” 和 “你爱我” 在它眼里可能没啥区别,而且也没法处理一词多意的情况,比如 “苹果”,既可以指水果,也可以指某家科技公司。怎么办呢?
这就得靠大模型的根基 ——Transformer 的 Attention 机制了,基于这个机制,现在有了像 BGE 模型这样更厉害的 embedding 模型。
这类模型训练的时候,需要正负样本,通过锚点来进行训练,能够根据语境动态计算词向量,这下,“苹果” 在不同语境下,就能有不同的向量表示啦。
Transformer 的 Attention 机制以及基于此发展出的 BGE 模型等,像是给孩子戴上了一副能洞察语义细微差别的 “超级眼镜”。它们不仅能捕捉词语顺序带来的语义变化,理解 “我爱你” 和 “你爱我” 的不同情感指向,还能根据上下文准确判断一词多义的具体含义,极大地提升了对文本语义的理解深度和准确性。
这些先进的模型在自然语言处理的各个领域,如机器翻译、智能问答、文本生成等,都发挥着核心作用,推动着人工智能在语言理解和交互方面不断向人类水平靠近 。
就好比你在读一本情节复杂的小说,Word2Vec 虽然能让你知道一些词语之间大概的联系,但遇到像 “他拿着苹果,走向了苹果专卖店” 这样的句子,它就有点迷糊了,不知道这里的 “苹果” 到底指的是水果还是品牌。
而 Transformer 的 Attention 机制和 BGE 模型就像是给你戴上了一副超级智能眼镜,当你读到这个句子时,眼镜能根据上下文的线索,比如前面提到的 “拿着”,后面提到的 “专卖店”,准确地告诉你这里第一个 “苹果” 指的是水果,第二个 “苹果” 指的是品牌。同时,对于像 “我喜欢她,她喜欢我” 和 “她喜欢我,我喜欢她” 这样词语顺序不同的句子,这副眼镜也能让你感受到其中情感表达的差异,帮助你更深入、准确地理解小说中的语义,而计算机借助这些模型,也能在处理自然语言时,达到类似人类理解语言的细腻程度,在各种语言相关的任务中表现得更加出色。
通过这些一步步的发展,文本终于能更准确地转化为向量,存进向量库,为人工智能的各种应用提供坚实的数据基础。你看,从简单的词袋法到复杂的 BGE 模型,这一路是不是像一场奇妙的冒险?