AI计算提效关键。自适应弹性加速,基于存算架构做浮点运算
一、自适应弹性加速是提升芯片能效比的有力手段
自适应弹性加速技术是现代芯片设计中提升能效比的关键路径之一。它摒弃了传统芯片在设计时采用的静态、固化的资源分配与功能设定模式,通过引入动态调整机制,使得芯片能够根据实时的应用需求和负载变化,智能地调配其计算资源、功耗模式和硬件功能。这种“按需服务”的设计哲学,不仅极大地提升了资源的利用效率,也显著降低了不必要的能量消耗,从而在整体上实现了性能与功耗的最佳平衡。以下将从资源、功耗和功能三个层面,结合实际应用场景,深入分析自适应弹性加速的优势。
- 资源层面:动态激活与高效共享
在资源层面,自适应弹性的核心在于动态的资源管理与高效的硬件共享。其最具代表性的实现方式就是异构计算(Heterogeneous Computing),即在一颗芯片上集成不同类型的处理器核心,以应对不同性质的工作负载。
这一理念的典范是ARM公司的big.LITTLE技术(现已演进为DynamIQ),它被广泛应用于全球几乎所有的智能手机SoC中,例如高通的骁龙(Snapdragon)系列和联发科的天玑(Dimensity)系列。图1为所有弹性的设计架构的核心DynamIQ Shared Unit(DSU)。DSU构建了CPU、L3 cache、Snoop Filter、外围设备总线buses、power management features之间异步通信的桥梁,同时也起到了节省功耗和时间的作用。这些芯片内部集成了用于处理高强度任务的大核(Performance Cores)和多个用于处理轻量级任务的小核(Efficiency Cores)。操作系统能够智能地将大型游戏等高负载任务调度到大核,而将消息接收等后台活动放在小核上运行,甚至在待机时完全关闭大核,从而极大延长电池续航。这一成功模式也延伸到了PC领域,英特尔(Intel)的酷睿(Core)处理器全面采纳了类似的性能混合架构,并辅以硬件线程调度器(Intel Thread Director)技术,向Windows 11等操作系统提供精准的调度建议,确保不同类型的任务总能在最合适的P-core(性能核)或E-core(能效核)上执行,实现了能效与性能的优化。
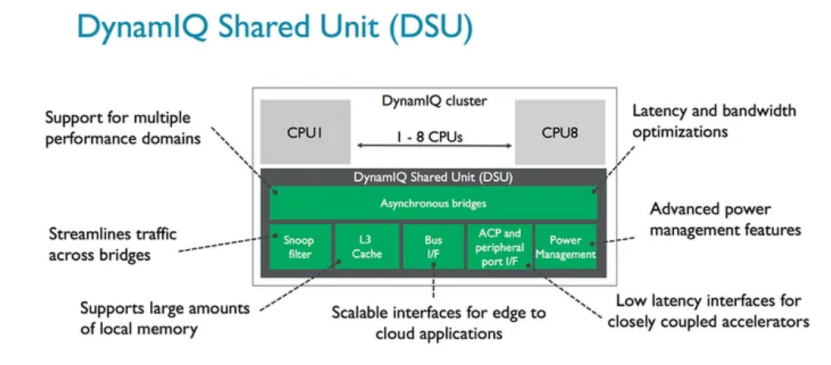
图1 DSU架构示意图[1]
- 功耗层面:精细化电源管理
功耗是制约芯片性能发挥的核心瓶颈。自适应弹性技术通过与PMIC(电源管理集成电路)的协同设计,实现了对芯片功耗的毫秒级、毫瓦级精细控制。
苹果的M系列芯片(Apple Silicon) 是展现这一优势的极致案例。得益于其强大的垂直整合能力,苹果自主设计了从处理器核心到PMIC乃至macOS操作系统的所有关键环节。这使得其PMIC能为芯片上成百上千个独立的电压域提供极其精准和迅速的动态电压与频率调整(DVFS)。当用户仅浏览网页时,核心可以低频运行;一旦开始视频剪辑,相关单元的电压和频率会瞬间拉满以保证性能。这种软硬件的无缝配合是其实现业界领先能效比的关键。同样,在其他高端移动SoC中,PMIC也将CPU、GPU、NPU等众多功能单元划分为独立电源域,在不使用时可通过电源门控(Power Gating)技术彻底切断供电,杜绝静态功耗,确保每一毫瓦电量都用在刀刃上。以M1 Pro/M1 Max芯片为例,如图2所示,M1 Pro和M1 Max内部集成多达10核中央处理器,同等功耗水平下的运行速度比最新款的8核PC笔记本电脑芯片快达1.7倍,达到其峰值水平性能所需功耗却少了70%。
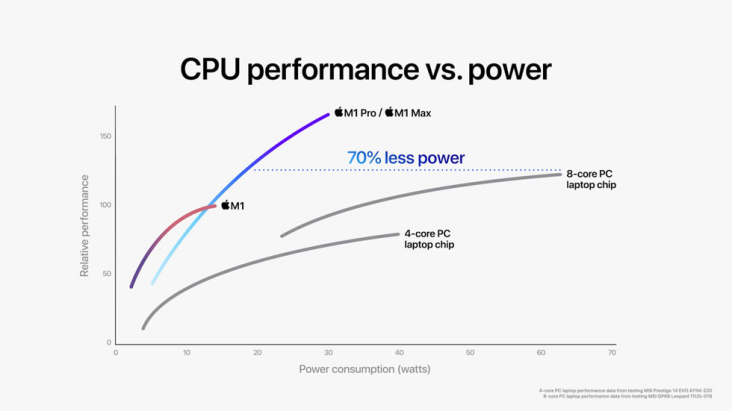
图2 M1 Pro/M1 Max及PC笔记本电脑的功耗、性能比较[2]
- 功能层面:多模态与可重构加速
在功能层面,自适应弹性计算通过硬件的可重构性,打破了专用集成电路(ASIC)功能固化与通用处理器(CPU)效率低下的两难困境,赋予了芯片“随需而变”的能力。
现场可编程门阵列(FPGA)是这一理念的经典代表,以AMD(原Xilinx)和Intel的产品为首,被大规模部署于云数据中心。例如,微软在其全球数据中心利用FPGA构建了“Catapult”加速平台,可根据业务需求,将FPGA重构为网络处理器以分担CPU负载,或重构为AI加速器执行必应搜索模型,通过软件推送即可完成芯片升级。面向未来,为应对AI算法的快速迭代,SambaNova Systems等公司研发了可重构数据流单元(RDU)。其编译器能将不同神经网络模型的数据流图直接映射到硬件上,通过软件配置“塑造”出最适合当前算法的硬件结构。这使得同一块芯片能高效处理从CNN到Transformer等各类模型,真正实现了“以软件定义硬件”,极大地扩展了芯片的通用性和生命周期。国内知存公司具有自研的用于神经网络映射的编译软件栈WITIN_MAPPER,如图3所示,可以将量化后的神经⽹络模型映射到WTM2101 MPU加速器上,是⼀种包括RISCV和MPU的完整解决⽅案,可以完成多种算子和图级别的转换和优化,将预训练权重编排到存算阵列中,并针对网络结构和算子给出存算优化方案,是自适应弹性计算的一个典型例子。
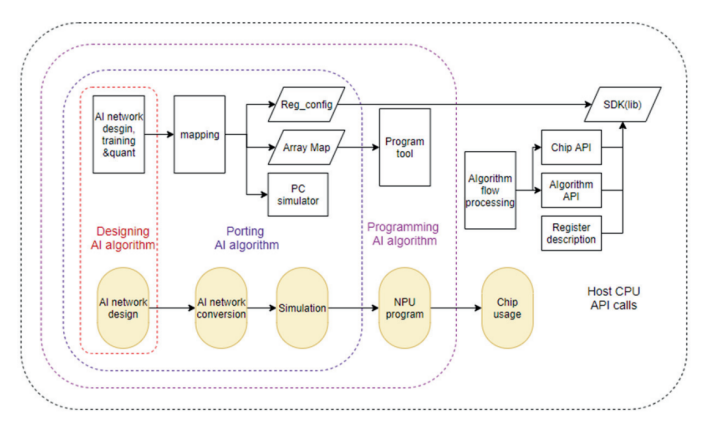
图3 编译软件栈WITIN_MAPPER架构图[3]
二、自适应弹性计算是优化浮点存内计算的方法论
为应对现代AI模型日益增长的复杂性与多样性,浮点存内计算技术的优化进入了新的阶段,其核心方法论便是自适应弹性计算。该方法论旨在打破传统计算硬件“一招鲜吃遍天”的僵化设计,赋予存算单元根据算法需求动态调整自身计算特性的能力,从而在各种应用场景下实现能效与性能的最优化。在本文中,我们将这一理念通过两个关键维度展开:自适应精度和可重构功能。
1.自适应精度
深度神经网络在推理和训练过程中,不同网络层对计算精度的要求存在显著差异。例如,一些层可能需要高精度的浮点(Floating-Point, FP) 运算来保留关键特征信息,而许多其他层的计算则可以在较低精度的定点或整数(Integer, INT)格式下完成,且对模型整体准确率的影响微乎其微。传统的固定精度硬件设计无法适应这种多样性,往往导致功耗和面积的冗余。自适应精度技术通过使CIM宏单元支持多种数据格式(如FP32、FP16、BF16、INT8、INT4等),并允许在运行时动态切换,实现了计算资源与算法需求的高度匹配,显著提升了芯片的能效与吞吐率。
目前,学术界与工业界提出了许多方式来实现浮点存内计算的自适应精度方案。台积电Khwa和Wu等人提出一种高精度的整数/浮点数双模存算宏[4],通过消除指数计算中的减法、重用INT模式中的对齐电路、指数加和与加法器树融合等方案,设计双模可复用的存内计算单元,使存算宏可在同时支持INT8、BF16计算的同时下保持高硬件资源复用。
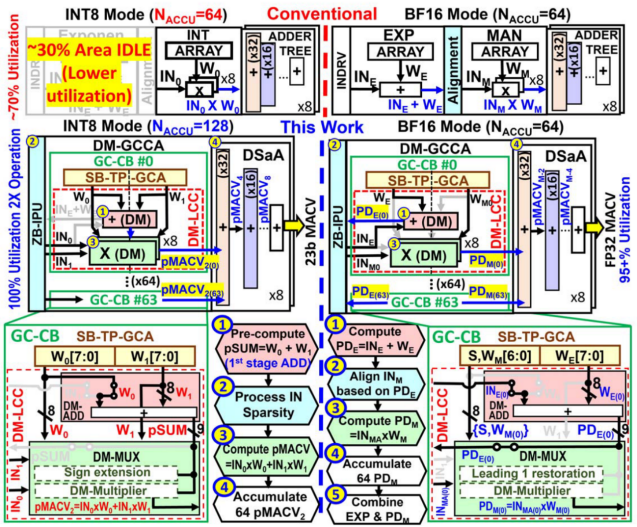
图4 ISSCC 24 34.2提出的双模计算宏
清华大学Yue和Xiang等人提出一种支撑复合AI(Compound AI)应用的存算宏,支持INT8、FP8、FP16精度计算[5]。通过提出并行尾数乘积和指数和的异质CIM宏,并在计算过程中设计混合精度计算模式,并通过稀疏感知进行计算加速,与先前的工作相比性能提升2.7倍以上,并且在能效与面效上达到了新的突破。
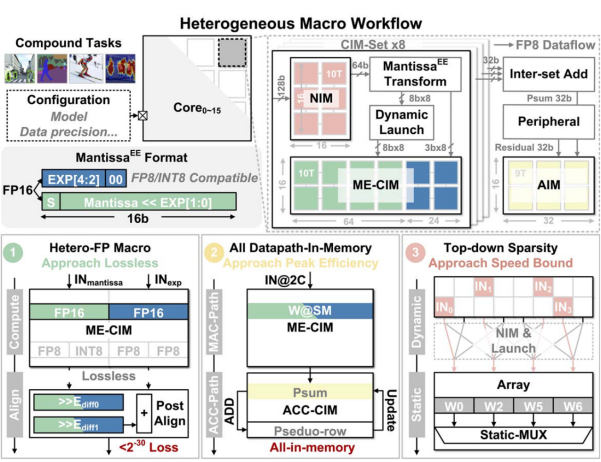
图5 ISSCC 25 14.4提出的稀疏感知存算宏
2.可重构计算
如果说自适应精度是从数据层面赋予了存算单元灵活性,那么可重构功能则是从硬件架构的维度,通过重塑计算模式与数据路径,将存内计算的“弹性”提升至全新高度。现代AI模型的计算图谱远比单纯的矩阵乘法复杂,其中交织着大量的非线性激活、归一化、池化乃至更复杂的逐元素运算。在传统设计中,这些非MAC(乘加)操作往往需要中断存内计算流程,将数据在存储阵列与外部独立的数字处理单元之间来回搬运,这构成了显著的性能与功耗瓶颈。
可重构功能旨在打破这种化的“存储-计算”分离模式,其核心思想是使CIM宏单元的物理结构能够根据当前计算任务的需求,动态地改变其功能与内部数据流。这种重构体现在多个层次:
1)算子可重构: 使同一套硬件电路既能执行高并行的乘加运算,也能被配置执行非线性函数等其他关键算子。
2)计算模式与路径可重构:允许CIM宏根据不同类型的神经网络层(如卷积层、全连接层)或不同的数据复用需求,动态切换其内部的数据分发、累加路径与工作模式(如权重固定、输出固定数据流),以实现最优的计算效率。
普林斯顿大学N. Verma团队于2021年在ISSCC上发表的一项研究设计了一种可扩展、可重构的数字存算核阵列[6]。该存内计算芯片在架构设计时引入2×2核心阵列模块(CIMU),通过控制模块间的数据流通路、改变输入输出扩展等方法动态调整存算核的计算模式,以支持神经网络模型内不同层的空间映射。清华大学尹首一教授团队于2022年在ISSCC上发表的一项研究提出了一种可兼顾能效比、精度和灵活性的可重构数字存内计算芯片新范式[7]。如下图所示,该存内计算芯片在架构设计时引入不同层次的可重构计算,算力高达29.2TFLOPS/W(BF16浮点精度下)和26.5TOPS/W(INT8精度下)。
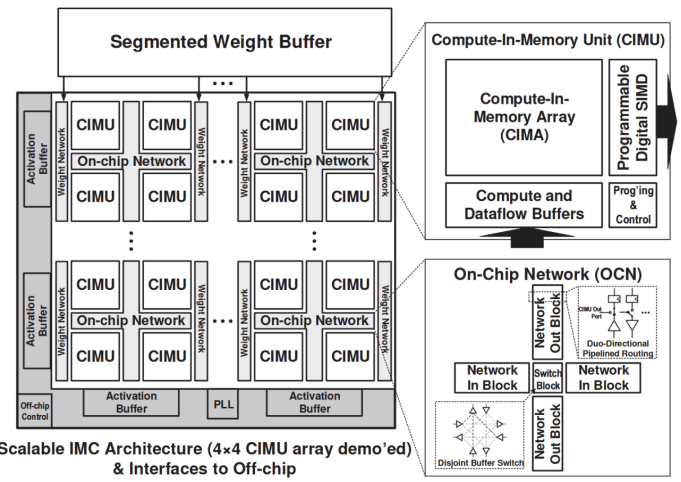
图6 ISSCC 21 15.1提出的可重构计算宏
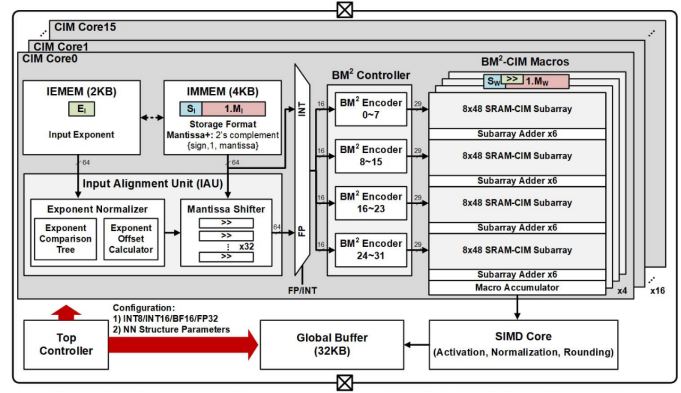
图7 ISSCC 22 15.5提出的可重构计算宏
三、自适应弹性计算和浮点存算结合的优势与风险
总的来说,自适应弹性加速与浮点存内计算的结合,旨在将存内计算强大的并行处理能力与弹性架构的智能适应性融为一体,为芯片的能效比、吞吐量、实用性带来显著提升,同时延长芯片的生命周期,从而设计出兼具极致能效、强大性能与广泛通用性的AI芯片。
首先,存内计算从物理层面极大减少了数据在存储与计算单元间“往返跑”的巨大能耗,构筑了高能效的基石,自适应弹性架构则扮演了精明的管理者的角色,进一步优化能效表现。其次,存内计算天然具备大规模并行计算的能力,理论峰值性能极高。但不代表其处理复杂多变任务时拥有优秀的有效性能,自适应弹性正是提升有效性能的关键。此外,AI领域的发展一日千里,算法的迭代速度远超硬件的更新周期。正如前文所述,可重构功能使得当新的神经网络算子或模型架构出现时,无需重新设计芯片,只通过更新编译器和固件,就能重新配置硬件的数据通路和计算模式,高效地适应新算法。这赋予了芯片未来适应性,使其免于“一代算法,一代芯片”的窘境。
然而,为了实现这一美好愿景,当前在芯片设计和制造上,还面临诸多挑战。
存内计算高能效的前提是数据尽可能地存储在片上存储单元中,这使得存内计算芯片相比于传统芯片,拥有更大的片上存储容量。在此基础上,浮点计算单元、可重构单元和弹性控制相关的电路会进一步增加芯片面积,提升流片成本,并且片上逻辑的复杂化也会影响流片成功率。此外,自适应弹性计算为芯片提供了高灵活性,为了充分利用它,编译器需要建立一个能精确预测所有弹性状态下(不同精度、不同数据流、不同资源配置)性能和功耗的模型,对“如何进行最优的数据映射、指令调度和精度选择”等问题进行决策,这是一个巨大的组合优化问题。
因此,我们应在实现高精度存内计算的路上努力拥抱自适应弹性计算等先进设计理念,同时积极应对其带来的风险。
参考资料
- big.LITTLE&DynamIQ-阿里云开发者社区
- M1 Pro 与 M1 Max 隆重登场:Apple 迄今打造的最强芯片 - Apple (中国大陆)
- 知存官网
- Khwa, Win-San, et al. "34.2 a 16nm 96Kb integer/floating-point dual-mode-gain-cell-computing-in-memory macro achieving 73.3-163.3 TOPS/W and 33.2-91.2 TFLOPS/W for AI-edge devices." 2024 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 67. IEEE, 2024.
- Yue, Zhiheng, et al. "14.4 A 51.6 TFLOPs/W Full-Datapath CIM Macro Approaching Sparsity Bound and< 2-30 Loss for Compound AI." 2025 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 68. IEEE, 2025.
- Jia, Hongyang, et al. "15.1 a programmable neural-network inference accelerator based on scalable in-memory computing." 2021 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 64. IEEE, 2021.
- Tu, Fengbin, et al. "A 28nm 29.2 TFLOPS/W BF16 and 36.5 TOPS/W INT8 reconfigurable digital CIM processor with unified FP/INT pipeline and bitwise in-memory booth multiplication for cloud deep learning acceleration." 2022 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 65. IEEE, 2022.