学习python第12天
今日任务:
DataFrame
DataFrame的构造
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)参数说明:
data:DataFrame 的数据部分,可以是字典、二维数组、Series、DataFrame 或其他可转换为 DataFrame 的对象。如果不提供此参数,则创建一个空的 DataFrame。index:DataFrame 的行索引,用于标识每行数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。columns:DataFrame 的列索引,用于标识每列数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。dtype:指定 DataFrame 的数据类型。可以是 NumPy 的数据类型,例如np.int64、np.float64等。如果不提供此参数,则根据数据自动推断数据类型。copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。
DataFrame的创建
- 用列表
import pandas as pddata = [
['Google', 10],
['Runoob', 12],
['Wiki', 13]]# 创建DataFrame
df = pd.DataFrame(data, columns=['Site', 'Age'])# 使用astype方法设置每列的数据类型
df['Site'] = df['Site'].astype(str)
df['Age'] = df['Age'].astype(float)print(df)- 用数组
import numpy as np
import pandas as pd# 创建一个包含网站和年龄的二维ndarray
ndarray_data = np.array([['Google', 10],['Runoob', 12],['Wiki', 13]
])# 使用DataFrame构造函数创建数据帧
df = pd.DataFrame(ndarray_data, columns=['Site', 'Age'])# 打印数据帧
print(df)- 用字典,按列
import pandas as pddata = {
'Site':['Google', 'Runoob', 'Wiki'],
'Age':[10, 12, 13]
}df = pd.DataFrame(data)print (df)
- 用字典,按行,没有对应的部分数据为 NaN。
import pandas as pddata = [{'a': 1, 'b': 2},
{'a': 5, 'b': 10, 'c': 20}]df = pd.DataFrame(data)print (df)返回指定数据
- 按索引名
返回单行,结果其实是一个Series,该Series的索引名是DataFrame的列名,列名是DataFrame的索引名
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]
}# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])结果:
calories 420
duration 50
Name: 0, dtype: int64
calories 380
duration 40
Name: 1, dtype: int64
返回多行,结果其实是一个DataFrame,列名索引名不变
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]
}# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)# 返回第一行和第二行
print(df.loc[[0, 1]])结果:
calories duration
0 420 50
1 380 40如果索引名不是默认的从0开始的整数:
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]
}df = pd.DataFrame(data, index = ["day1", "day2", "day3"])# 指定索引
print(df.loc["day2"])- 按列名
import pandas as pddata = {"calories": [420, 380, 390],"duration": [50, 40, 45]"others": [123, 22, 66]
}df = pd.DataFrame(data)# 指定索引
print(df[['calories','duration']])- 访问单个元素
先列,后行
print(df['Name'][0])先行,后列,表示所有的行,列名为'Column1'
print(df.loc[:, 'Column1']).loc[]和.iloc[]的区别
.loc[]是按索引名
.iloc[]是按位置
import pandas as pddata = [
['amy','tony']
]df=pd.DataFrame(data, index=['girl','boy'], columns='name')#第一行
print(df.loc['girl'])#第一行
print(df.iloc[0])
# 索引和切片
print(df[['Name', 'Age']]) # 提取多列
print(df[1:3]) # 切片行
print(df.loc[:, 'Name']) # 提取单列
print(df.loc[1:2, ['Name', 'Age']]) # 标签索引提取指定行列
print(df.iloc[:, 1:]) # 位置索引提取指定列DataFrame常用方法,与Seires类似
head(n) | 返回 DataFrame 的前 n 行数据(默认前 5 行) |
tail(n) | 返回 DataFrame 的后 n 行数据(默认后 5 行) |
info() | 显示 DataFrame 的简要信息,包括列名、数据类型、非空值数量等 |
describe() | 返回 DataFrame 数值列的统计信息,如均值、标准差、最小值等 |
shape | 返回 DataFrame 的行数和列数(行数, 列数) |
columns | 返回 DataFrame 的所有列名 |
index | 返回 DataFrame 的行索引 |
dtypes | 返回每一列的数值数据类型 |
sort_values(by,ascending) | 按照指定列排序,by=列名,ascending=True(升序) or False(降序) |
sort_index() | 按行索引排序 |
dropna() | 删除含有缺失值(NaN)的行或列 |
fillna(value) | 用指定的值填充缺失值 |
isnull() | 判断缺失值,返回一个布尔值 DataFrame |
notnull() | 判断非缺失值,返回一个布尔值 DataFrame |
loc[] | 按标签索引选择数据 |
iloc[] | 按位置索引选择数据 |
at[] | 访问 DataFrame 中单个元素(比 loc[] 更高效) |
iat[] | 访问 DataFrame 中单个元素(比 iloc[] 更高效) |
apply(func) | 对 DataFrame 或 Series 应用一个函数 |
applymap(func) | 对 DataFrame 的每个元素应用函数(仅对 DataFrame) |
groupby(by) | 分组操作,用于按某一列分组进行汇总统计 |
pivot_table() | 创建透视表 |
merge() | 合并多个 DataFrame(类似 SQL 的 JOIN 操作) |
concat() | 按行或按列连接多个 DataFrame |
to_csv() | 将 DataFrame 导出为 CSV 文件 |
to_excel() | 将 DataFrame 导出为 Excel 文件 |
to_json() | 将 DataFrame 导出为 JSON 格式 |
to_sql() | 将 DataFrame 导出为 SQL 数据库 |
query() | 使用 SQL 风格的语法查询 DataFrame |
duplicated() | 返回布尔值 DataFrame,指示每行是否是重复的 |
drop_duplicates() | 删除重复的行 |
set_index() | 设置 DataFrame 的索引 |
reset_index() | 重置 DataFrame 的索引 |
transpose() | 转置 DataFrame(行列交换) |
数据修改
修改列数据:重新赋值
df['Column1'] = [10, 11, 12]添加新列:给新列赋值
df['NewColumn'] = [100, 200, 300]合并行/列
pd.concat():pandas 内部的一个方便的函数,用于垂直(按行)或水平(按列)连接 DataFrame。
objs 参数是一个要串联的 Series 或 DataFrame 对象的序列或映射。
axis 参数决定连接的方向:
axis=0 设置为缺省值(默认),这意味着它将垂直(按行)连接 DataFrame。
axis=1 将水平连接 DataFrame(按列)。
# 使用concat添加新行
new_row = pd.DataFrame([[4, 7]], columns=['A', 'B']) # 创建一个只包含新行的DataFrame
df = pd.concat([df, new_row], ignore_index=True) # 将新行添加到原始DataFrameprint(df)merge()
pd.merge(df1, df2, on='Column1')分割
pivot、melt
删除
删除列
df_dropped = df.drop('Column1', axis=1)删除行
df_dropped = df.drop(0) # 删除索引为 0 的行删除重复行
drop_duplicates(subset =, keep = 'first', inplace = False)drop_duplicates() 函数参数定义:
subset:此参数标识重复行时要考虑的列标签或标签序列。如果未提供,它将处理 DataFrame 中的所有列。
keep:此参数确定要保留的重复行。
'first': (默认) 删除除第一个匹配项以外的重复项。
'last': 删除除最后一个匹配项之外的重复项。
False: 删除所有重复项。
inplace: 如果设置为 True,则直接对对象进行更改,而不返回新的对象。如果设置为 False(默认),则返回丢弃重复的新对象。
删除缺失值
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)dropna 函数参数定义:
axis: 它可以是 {0 or 'index', 1 or 'columns'}。默认为 0。如果 axis=0,则丢弃包含缺失值的行;如果 axis=1,则丢弃包含缺失值的列。
how: 确定当我们至少有一个 NA 或全部 NA 时,是否从 DataFrame 中删除行或列。
how='any': 如果存在任何 NA 值,则删除该行或列(默认)。
how='all': 如果所有值都为 NA,则删除该行或列。
thresh: 需要多少非 NA 值。这是一个整型参数,需要最小数量的非 NA 值才能保留行/列。
subset: 要考虑的另一个轴上的标签,例如,如果您正在删除行,则这些标签将是要包括的列的列表。当您只想考虑某些列中的 NA 值时,这特别有用。
inplace: 这是一个布尔值,如果是 True,则对 DataFrame 本身进行更改。请记住,在使用 inplace=True 参数时,您修改的是原始的 DataFrame。如果出于任何原因需要保留原始数据,请避免使用 inplace=True,而是将结果赋给新的 DataFrame。
列/索引重命名
DataFrame.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None, errors='raise')
mapper, index, columns:可以传递以重命名索引或列的词典。在我们的示例中,我们使用 columns。
axis: 可以是 "index" 或 "columns"。确定是重命名索引还是重命名列。默认情况下,如果您提供 columns 参数,您将重命名列。
copy: 如果设置为 True,则创建一个新的 DataFrame。如果为 False,则修改原始 DataFrame。
inplace: 如果设置为 True,则重命名会原地修改 DataFrame,不会返回任何内容。如果为 False,则在不修改原有 DataFrame 的情况下,返回一个新的带有更名列的 DataFrame。
level: 对于具有多级索引的 DataFrame,应当重命名标签的级别。
errors: 如果是 'raise',如果尝试重命名不存在的项,则会引发错误。如果设置为 'ignore',任何重命名项目的失败都将被忽略。
我们关注'columns','index'参数就可以了
import pandas as pdnewname={'id':'student_id','first':'first_name','last':'last_name','age':'age_in_years'}
students.rename(columns=newname,inplace=True)改变数据类型
DataFrame.astype(dtype, copy=True, errors='raise')dtype: 它是一种数据类型,或列名->数据类型的字典。
copy: 默认情况下,astype 总是返回新分配的对象。如果 copy 设置为 False,则只有在旧对象无法强制转换为所需类型的情况下才会创建新对象。
errors: 控制对提供的数据类型的无效数据引发异常。默认设置为 raise,表示会引发异常。
students = students.astype( {'grade':int})
return students填充缺失值
.fillna(value, method = None, axis, inplace)value: 标量,字典,Series 或 DataFrame。用于填充空洞的值(例如 0)。这就是我们在解决方案中使用的。
method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}。用于填充重新索引 Series 中的空洞的方法。默认为 None。
axis: {0 or ‘index’, 1 or ‘columns’}。沿其填充缺失值的轴。
inplace: 布尔值。如果为True,则原地填充。注意:这将修改此对象上的任何其他视图。默认值为 False。
由于这个函数无法制定列/行,所以如果想要对某一行/列填充缺失值,就要把fillna这个函数作用在这个列/行上
products['quantity'].fillna(0,inplace=True)长、宽表格转换(透视)
pivot 函数
在 pandas 中 pivot 函数被用来基于列的值重塑数据并且在外部得到一个新的 DataFrame。pivot 采用我们将使用的以下参数:
index: 确定新 DataFrame 中的行。
columns: 确定新 DataFrame 中的列。
values: 指定重塑表格时要使用的值。
举例:

将上面的表转换为下面的表:
weather.pivot(index='month',columns='city',values='temperature')melt 函数
pandas 的 melt 函数用于转换或重塑数据。它将 DataFrame 从宽格式(列表示多个变量)更改为长格式(每行表示一个唯一变量)。
举例解释:
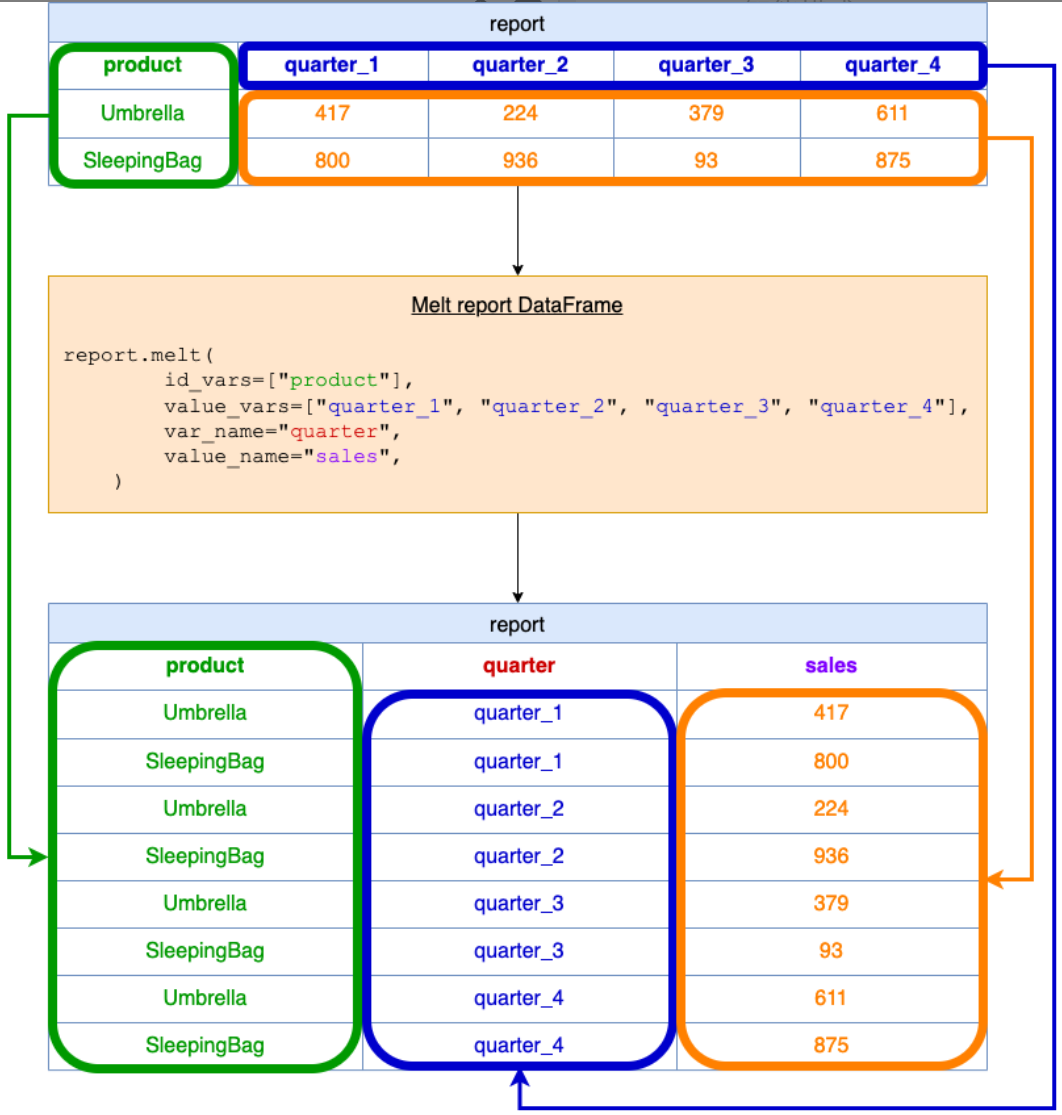
id_vars:这指定了应该保持不变的列。对于这个问题,只有 product 列保持不变,因为我们希望输出中的每一行都与一个产品相关联。
value_vars:这指定了我们想要“melt”或将其整形成行的列。在我们的示例中,以下是每个季度的销售数据列:quarter_1、quarter_2、quarter_3 和 quarter_4。
var_name:这是将存储来自 value_vars 的标头名称的新列的名称。在我们的问题中,这些是季度名称。
value_name:这是将存储 value_vars 中的值的新列的名称。在我们的问题中,这将是每个季度每种产品的销售数据。
pandas的方法真的太多了,靠人脑子真的记不过来。不过虽然平时在处理数据的时候,我一般都是让AI编写程序,因为这种清洗、处理数据的活,AI可以做的非常好,思路明确,不用人绞尽脑汁思考先处理什么,再处理什么,效率嘎嘎高。不太确定学习到的这些方法,过两天还能不能记得住,但总归有些印象,真工作的时候,还让AI干。今晚在力扣上刷了一些pandas的题目,还是感觉到自己的思路被拓宽了(os:原来数据还能这么分析),这也是学习pandas的一些收获吧。一边学基本的方法,一边刷力扣,我觉得是非常有用的,可以看到学习的这些方法,都可以怎么去处理实际问题,所以边学边干,进步飞快~
今晚周五同事们下班的都贼早,七点半的时候办公室就只有我一个人了(以往九点钟人都很多),+2不知道从哪里突然冒出来,吓了我一跳,催另一个同事下班,居然没催我下班,应该是看到我在学习pandas了。希望我不要被冠以卷王的名号(虽然我感觉在办公室已经有这个苗头了),没办法,我是苦逼实习生,白天实习,晚上秋招,时不时导师那边还要开组会,你们这些正式工就别和我卷了,真说卷,我也卷不过你们,你们晚上十点才下班的。。。。