Redis 部署模式深度对比与选型指南
🚀 Redis 部署模式深度对比与选型指南(含场景与最佳实践 | 可直接发布到 CSDN)
适用人群:后端/中间件工程师、运维 SRE、架构师、DevOps 团队
文章亮点:一图速览、对比表、典型场景、配置清单、迁移路线、容灾与运维要点
📌 目录
- 🧐 一、为什么需要不同的 Redis 部署模式?
- 📊 二、模式总览与对比表
- 💻 三、单机模式(Standalone)
- 🔁 四、主从复制(Replication,非哨兵)
- 🛡️ 五、哨兵模式(Sentinel + 主从)
- 🌐 六、Redis Cluster 集群模式
- 🧩 七、其他常见方案与形态
- ⚖️ 八、如何选型?(决策流)
- 📦 九、容量规划与部署建议
- ❗ 十、常见问题与误区
- 🔄 十一、迁移与演进路线
- 📝 十二、关键配置清单(可直接参考)
- 📡 十三、运行监控与压测要点
- ❓ 十四、FAQ 速答
- 🏁 十五、结语
🧐 一、为什么需要不同的 Redis 部署模式?
Redis 是内存型数据结构服务,具有极致性能与丰富数据类型。但随着业务发展,单机可用性、容量与吞吐无法满足需求,需要不同的部署模式来解决:
- 可用性:避免单点故障(SPOF),提供自动故障转移。
- 扩展性:单机内存/CPU/QPS上限有限,需要水平扩容。
- 一致性与数据安全:在故障时尽量减少数据丢失,权衡性能与可靠性。
- 跨地域容灾:满足同城双活/两地三中心/跨云等需求。
下文从单机 → 主从 → 哨兵 → Cluster逐级展开,并给出选型建议与最佳实践。
📊 二、模式总览与对比表
| 模式 | 核心能力 | 可用性 | 扩展性 | 一致性/数据安全 | 复杂度 | 典型成本 | 适合场景 | 不适合 |
|---|---|---|---|---|---|---|---|---|
| 单机(Standalone) | 简单、低成本 | ★☆☆ | ☆☆☆ | 取决于持久化策略(RDB/AOF) | ★☆☆ | 低 | 开发/测试、小型单体/边缘缓存 | 任何要求高可用的生产 |
| 主从复制(无哨兵) | 读写分离、手动切换 | ★★☆(手动) | ☆☆☆ | 有复制延迟,故障需人工干预 | ★★☆ | 低 | 读多写少、对短期中断容忍 | 无人值守、强 SLA |
| 哨兵(Sentinel + 主从) | 自动故障转移、主从感知 | ★★★ | ☆☆☆ | 可能丢少量写(极端故障窗口) | ★★★ | 中 | 中小型生产、单分片高可用 | 数据量或 QPS 超大、需横向扩容 |
| Cluster | 多分片水平扩展、槽迁移 | ★★★ | ★★★ | 分区容忍,Failover 同样有小窗口 | ★★★★ | 中~高 | 大型/超大规模、需要横向扩容 | 需要跨键事务/脚本跨槽 |
| 代理分片(Twemproxy/Codis 等) | 客户端无感分片 | ★★☆ | ★★★ | 取决于后端实例/代理 | ★★★ | 中 | 旧系统改造、客户端不支持 Cluster | 需要强一致或低延迟极限 |
| 托管服务(云/企业版) | 一站式 HA/监控/扩缩容 | ★★★★ | ★★★★ | 提供企业级容灾能力 | ★★★ | 中~高 | 快速上云、团队人手有限 | 成本敏感、私有化刚需 |
结论速记:
- 低成本+简单:单机/主从。
- 高可用但不扩容:哨兵。
- 既要高可用又要水平扩容:Cluster。
- 改造成本低:代理分片。
- 省心省力:云托管/企业版。
💻 三、单机模式(Standalone)
架构示意
特点
- ✔ 部署最简单,成本最低。
- ✔ 适合开发/测试、功能性小服务、边缘缓存或临时任务队列。
- ✖ 单点故障,一旦进程/主机挂掉即中断。
- ✖ 容量受限于单机内存,吞吐受限于单核性能(Redis 单线程为主,I/O 多路复用 + 多线程 I/O 辅助)。
使用场景
- POC、功能验证、小工具服务、缓存命中不敏感的非关键路径。
关键注意
- 开启合理的持久化(AOF everysec + RDB 周期)。
- 开启
protected-mode yes、访问控制 ACL、及必要的rename-command(隐藏高危命令)。
🔁 四、主从复制(Replication,非哨兵)
架构示意
特点
- ✔ 简单读写分离:写入 Master,读取可打到 Slave。
- ✔ 从节点可做只读扩展、备份导出、离线计算。
- ✖ 故障需要人工切换(修改客户端/域名/配置)。
- ✖ 存在复制延迟,强一致读需读主。
使用场景
- 可容忍短时中断的小型生产;夜间有人工值守;读多写少。
常见配置
- 从节点:
replicaof <master-ip> 6379,replica-read-only yes。 - 主节点:建议
min-replicas-to-write、min-replicas-max-lag防止脑裂时继续写入。
🛡️ 五、哨兵模式(Sentinel + 主从)
架构示意
核心价值
- ✔ 自动故障转移:主挂了,哨兵选举某个从为新主。
- ✔ 客户端通过 Sentinel API/事件订阅获取新主地址,业务自动恢复。
- ✖ 仍是单分片能力,不能水平扩容容量/槽位。
- ✖ 故障窗口内可能丢少量写(取决于 AOF 策略/复制确认/网络)。
使用场景
- 中小型生产:单实例内存 <= 50~100GB、单分片即可承载;对 RTO/RPO 有基本要求。
最佳实践
- 部署 ≥3 个哨兵,奇数个以防止投票僵局。
quorum(仲裁数)合理配置;跨机房/跨可用区分布哨兵和数据节点。- Docker/Compose 环境:若使用主机名监控,建议
sentinel resolve-hostnames yes以解析容器名;或直接使用固定 IP/服务发现(K8s Service)。 - 客户端务必使用支持 Sentinel 的连接方式(或经中间层做主从感知)。
典型 sentinel.conf 片段
port 26379
bind 0.0.0.0
sentinel monitor mymaster 10.0.0.10 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 10000
sentinel parallel-syncs mymaster 1
# 在容器/内网 DNS 环境下,使用主机名监控时启用:
sentinel resolve-hostnames yes
🌐 六、Redis Cluster 集群模式
架构与槽位
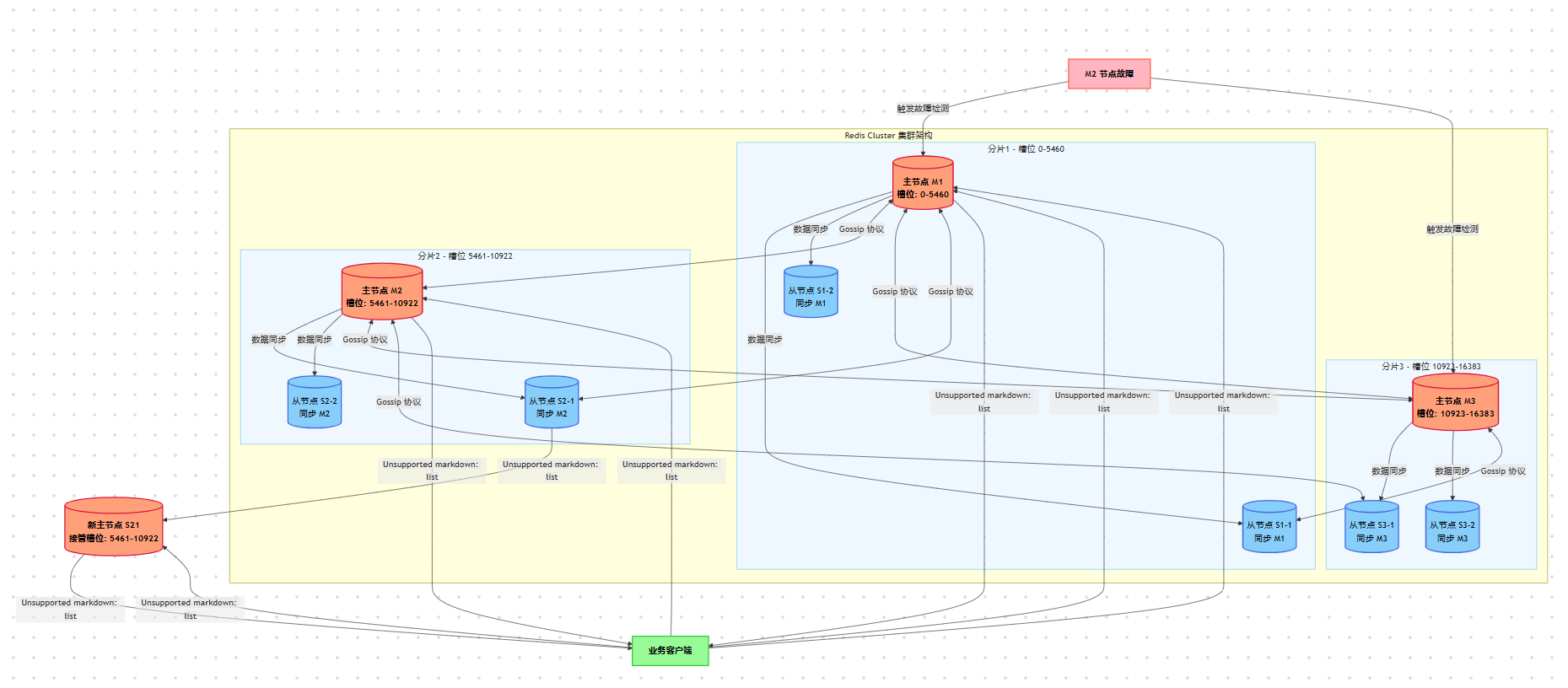
核心价值
- ✔ 水平扩容:基于 16384 个 hash slot 分片,按槽位均衡到多个主节点。
- ✔ 高可用:主从复制 + 自动 Failover;可按需增加副本。
- ✔ 在线扩/缩容:槽位迁移(reshard/rebalance)。
- ✖ 多键操作限制:只有同槽(或使用
{tag})才能原子多键操作/事务/Lua。 - ✖ 只支持 DB 0;某些特性在集群下有差异(如脚本跨槽、
KEYS慎用)。
使用场景
- 大容量(百 GB ~ TB 级)、高 QPS、水平扩展、增长不可预测的核心业务缓存/会话/排行榜/计数。
关键参数与命令
# redis.conf(每个节点)
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
# 创建 3 主 3 从(示例)
redis-cli --cluster create \10.0.0.11:6379 10.0.0.12:6379 10.0.0.13:6379 \10.0.0.14:6379 10.0.0.15:6379 10.0.0.16:6379 \--cluster-replicas 1# 重新平衡/增删节点时进行槽位迁移
redis-cli --cluster rebalance 10.0.0.11:6379
开发注意
- 使用支持 Cluster 的客户端;处理
MOVED/ASK重定向。 - 多键/事务/脚本尽量使用哈希标签:
{user:123},保证落到同一槽。 - Redis 7+ 支持 Sharded Pub/Sub(
ssubscribe/spublish),在集群上更友好;传统 Pub/Sub 仍是节点内。
🧩 七、其他常见方案与形态
- 代理分片(Twemproxy、Codis 等)
- 通过代理实现分片,客户端无感,适合老系统改造。
- 缺点:代理成为额外跳数/潜在单点;功能对齐度不如原生 Cluster。
- 云托管/企业版(Redis Enterprise/云厂商)
- 一站式监控、扩缩容、跨 AZ/Region 容灾;通常支持持久化到盘/多副本/自动修复。
- 适合团队人手有限、快速交付;注意成本与配额边界。
- 跨地域容灾
- 常见:主动-被动(主 Region 写,异步复制到灾备)或 双活(多写,冲突解决复杂)。
- 可选:
redis-shake/psync/云厂商复制能力;强一致跨域难度高且昂贵。
⚖️ 八、如何选型?(决策流)
## 📦 九、容量规划与部署建议
- 节点内存:建议使用率 ≤ 70%,预留给 fork/RDB/AOF rewrite、碎片与缓冲。
- Key/Value 大小:避免 BigKey(>1MB 或超大集合),拆分/分页;避免阻塞指令(
SCAN代替KEYS)。 - 持久化策略:常用
appendonly yes+appendfsync everysec;重要业务考虑no-appendfsync-on-rewrite no与盘性能。 - 网络:低延迟优先,跨 AZ 至少 3 副本分散;哨兵/节点分散部署防同故障域。
- CPU:尽量独占 vCPU,避免与抖动型负载混部。
❗ 十、常见问题与误区
- “哨兵=集群”? ❌ 哨兵只解决主从高可用,不提供分片与横向扩容。
- “Cluster 不会丢数据”? ❌ 故障窗口内仍可能丢最近写;需结合 AOF、复制确认策略与业务幂等。
- “多键事务随便用” ❌ 集群下须同槽(
{}标签)才可原子执行。 - “从库可随便写” ❌ 默认应
replica-read-only yes,避免数据分叉。 - Docker/Compose 连通性:使用容器名监控时,注意
sentinel resolve-hostnames yes;或固定 IP/服务发现。 - 持久化与性能:
everysec是折中,always更安全但更慢;结合业务 RPO 选择。
🔄 十一、迁移与演进路线
- 单机 → 主从:添加从库,验证复制延迟与只读策略。
- 主从 → 哨兵:部署 3+ 哨兵,切换客户端为 Sentinel 发现,演练故障转移。
- 哨兵 → Cluster:按业务域设计 key 前缀/哈希标签;搭建并压测新集群;灰度迁移(双写或迁移工具)。
- 代理分片 → Cluster:分批替换后端为 Cluster,逐步下线代理。
📝 十二、关键配置清单(可直接参考)
redis.conf(通用)
bind 0.0.0.0
protected-mode yes
requirepass <your-strong-pass>
appendonly yes
appendfsync everysec
maxmemory <size>
maxmemory-policy allkeys-lru
# 复制一致性(主):
min-replicas-to-write 1
min-replicas-max-lag 5
sentinel.conf(要点)
port 26379
bind 0.0.0.0
sentinel monitor mymaster <master-host> 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 10000
sentinel parallel-syncs mymaster 1
sentinel auth-pass mymaster <your-strong-pass>
# Docker/K8s 使用主机名时:
sentinel resolve-hostnames yes
Cluster 节点(每个)
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
📡 十三、运行监控与压测要点
-
核心指标:
- 延迟:
latency,instantaneous_ops_per_sec。 - 复制:
master_link_status,slave_repl_offset差值。 - 持久化:
aof_current_size,aof_rewrite_in_progress, RDB 周期。 - 内存:
used_memory,mem_fragmentation_ratio, 命中率、淘汰速率。 - Cluster:槽位分布、节点状态、
cluster_state。
- 延迟:
-
常用工具:
redis-cli --latency,redis-benchmark,INFO,MONITOR(慎用)。 -
压测建议:使用相似数据分布与访问模式;关注增删键、集合操作、Pipeline 效果。
❓ 十四、FAQ 速答
Q1:哨兵切换慢/不稳定怎么办? 检查 down-after-milliseconds、网络丢包、NTP 时间、哨兵分布;提升副本质量(延迟/丢包)。
Q2:Cluster 中如何做多键事务? 使用哈希标签 {} 使相关 key 落到同一槽位;或改造为单键结构(如将多字段放入 Hash)。
Q3:如何避免数据丢失? 选择合适的 AOF 策略、开启复制确认、业务层幂等与补偿;必要时牺牲少量性能换更低 RPO。
Q4:读写分离下强一致读? 读主或使用“读后写一致性”策略(写后短暂读主/延迟读从/版本校验)。
Q5:集群是否支持多 DB? 不支持,仅 DB 0。
Q6:Docker 内 7000/7001 端口起不来? 检查宿主机映射、容器网络、IP 解析与 cluster-announce-ip/port 设置。
🏁 十五、结语
-
一个公式:
- 单机=极简;
- 主从=读扩展;
- 哨兵=高可用;
- Cluster=高可用 + 水平扩容。
根据业务容量/QPS/一致性/RTO/RPO/团队能力与预算,做出最合适的取舍,并用监控+演练确保方案落地。祝你把 Redis 用出工程化“质感”。💪
需要示例 Docker Compose / K8s YAML、或迁移演练脚本模板?可在评论区留言,我会补充到本文附录。