【字节拥抱开源】字节豆包团队开源豆包OSS大模型

简介
Seed-OSS是由字节跳动Seed团队研发的一系列开源大语言模型,具备强大的长文本处理、推理、智能体及通用能力,并支持多种开发者友好特性。尽管训练仅消耗了12T tokens,Seed-OSS在多个主流开源基准测试中表现优异。
我们依据Apache-2.0许可证向开源社区发布这一系列模型。
[!注意]
Seed-OSS主要针对国际化(i18n)使用场景进行了优化。
核心特点
- 思维预算灵活控制:允许用户根据需要灵活调整推理长度。这种动态控制推理长度的能力,在实际应用场景中提升了推理效率。
- 强化推理能力:在保持均衡且优秀的通用能力的同时,针对推理任务进行了专项优化。
- 智能体能力:在工具调用、问题解决等智能体任务中表现卓越。
- 研究友好性:由于预训练时加入合成指令数据可能影响训练后研究,我们同步发布了包含和不包含指令数据的预训练模型,为研究社区提供更丰富的选择。
- 原生长上下文:原生支持长达512K的长上下文训练。
模型概述
Seed-OSS采用流行的因果语言模型架构,包含旋转位置编码(RoPE)、分组查询注意力(GQA)、RMSNorm归一化及SwiGLU激活函数。
| Seed-OSS-36B | |
| Parameters | 36B |
| Attention | GQA |
| Activation Function | SwiGLU |
| Number of Layers | 64 |
| Number of QKV Heads | 80 / 8 / 8 |
| Head Size | 128 |
| Hidden Size | 5120 |
| Vocabulary Size | 155K |
| Context Length | 512K |
| RoPE Base Frequency | 1e7 |
评估结果
Seed-OSS-36B-Base
在预训练中融入合成指令数据可提升多数基准测试性能。我们采用经合成指令数据增强的版本(即含合成数据)作为Seed-OSS-36B-Base。同时发布未使用此类数据训练的Seed-OSS-36B-Base-woSyn(即不含合成数据),为社区提供一个不受合成指令数据影响的高性能基础模型。
| Benchmark | Seed1.6-Base | Qwen3-30B-A3B-Base-2507* | Qwen2.5-32B-Base* | Seed-OSS-36B-Base (w/ syn.) | Seed-OSS-36B-Base-woSyn (w/o syn.) |
|---|---|---|---|---|---|
| Knowledge | |||||
| MMLU-Pro | 70 | 59.8 | 58.5 (55.1) | 65.1 | 60.4 |
| MMLU | 88.8 | 82.7 | 84 (83.3) | 84.9 | 84.8 |
| TriviaQA | 91 | 76.2 | 76 | 82.1 | 81.9 |
| GPQA-D | 43.4 | 37 | 29.3 | 31.7 | 35.2 |
| SimpleQA | 17.1 | 7.2 | 6.1 | 5.8 | 7.4 |
| Reasoning | |||||
| BBH | 92.1 | 81.4 | 79.1 (84.5) | 87.7 | 87.2 |
| AGIEval-en | 78 | 66.4 | 65.6 | 70.7 | 70.1 |
| Math | |||||
| GSM8K | 93.1 | 87 | 87.5 (92.9) | 90.8 | 90.3 |
| MATH | 72.9 | 61.1 | 63.5 (57.7) | 81.7 | 61.3 |
| Coding | |||||
| MBPP | 83.6 | 78.8 | 77.8 (84.5) | 80.6 | 74.6 |
| HumanEval | 78 | 70.7 | 47.6 (58.5) | 76.8 | 75.6 |
- "*"表示该列结果以"复现结果(如有报告结果则标注)"的格式呈现。
Seed-OSS-36B-Instruct
| Benchmark | Seed1.6-Thinking-0715 | OAI-OSS-20B* | Qwen3-30B-A3B-Thinking-2507* | Qwen3-32B* | Gemma3-27B | Seed-OSS-36B-Instruct |
|---|---|---|---|---|---|---|
| Knowledge | ||||||
| MMLU-Pro | 86.6 | 76.2 | 81.9 (80.9) | 81.8 | 67.5 | 82.7 |
| MMLU | 90.6 | 81.7 (85.3) | 86.9 | 86.2 | 76.9 | 87.4 |
| GPQA-D | 80.7 | 72.2 (71.5) | 71.4 (73.4) | 66.7 (68.4) | 42.4 | 71.4 |
| SuperGPQA | 63.4 | 50.1 | 57.3 (56.8) | 49.3 | - | 55.7 |
| SimpleQA | 23.7 | 6.7 | 23.6 | 8.6 | 10 | 9.7 |
| Math | ||||||
| AIME24 | 90.3 | 92.7 (92.1) | 87.7 | 82.7 (81.4) | - | 91.7 |
| AIME25 | 86 | 90.3 (91.7) | 81.3 (85) | 73.3 (72.9) | - | 84.7 |
| BeyondAIME | 60 | 69 | 56 | 29 | - | 65 |
| Reasoning | ||||||
| ArcAGI V2 | 50.3 | 41.7 | 37.8 | 14.4 | - | 40.6 |
| KORBench | 74.8 | 72.3 | 70.2 | 65.4 | - | 70.6 |
| HLE | 13.9 | 12.7 (10.9) | 8.7 | 6.9 | - | 10.1 |
| Coding | ||||||
| LiveCodeBench v6 (02/2025-05/2025) | 66.8 | 63.8 | 60.3 (66) | 53.4 | - | 67.4 |
| Instruction Following | ||||||
| IFEval | 86.3 | 92.8 | 88 (88.9) | 88.4 (85) | 90.4 | 85.8 |
| Agent | ||||||
| TAU1-Retail | 63 | (54.8) | 58.7 (67.8) | 40.9 | - | 70.4 |
| TAU1-Airline | 49 | (38) | 47 (48) | 38 | - | 46 |
| SWE-Bench Verified (OpenHands) | 41.8 | (60.7) | 31 | 23.4 | - | 56 |
| SWE-Bench Verified (AgentLess 4*10) | 48.4 | - | 33.5 | 39.7 | - | 47 |
| Multi-SWE-Bench | 17.7 | - | 9.5 | 7.7 | - | 17 |
| Multilingualism | ||||||
| MMMLU | 84.3 | 77.4 (75.7) | 79 | 79 (80.6) | - | 78.4 |
| Long Context | ||||||
| RULER (128K) | 94.5 | 78.7 | 94.5 | 77.5 | - | 94.6 |
| Safety | ||||||
| AIR-Bench | - | - | - | - | - | 75.6 |
- "*"表示该列结果以"复现结果(报告结果_如有)"的格式呈现。部分结果因评估运行失败已被省略。
- Gemma3-27B的结果直接引自其技术报告。
- ArcAGI-V2的结果是在官方训练集上测量的,该数据集未参与训练过程。
- Seed-OSS-36B-Instruct的生成配置:temperature=1.1,top_p=0.95。特别地,对于Taubench,temperature=1,top_p=0.7。
[!NOTE]
我们推荐使用temperature=1.1和top_p=0.95进行采样。
思考预算
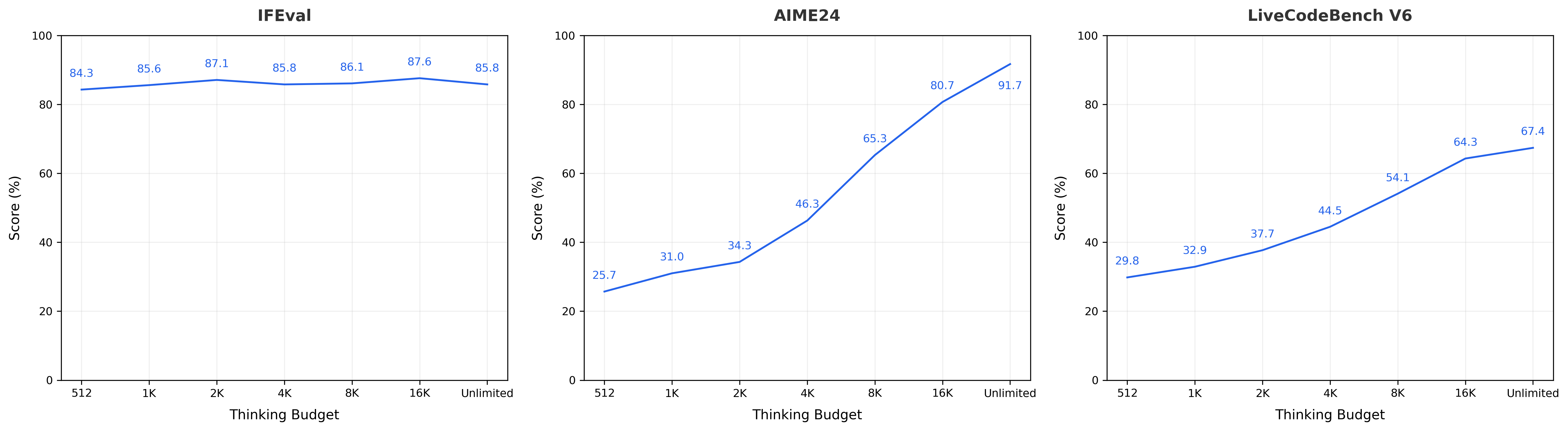
用户可以灵活指定模型的思考预算。下图展示了不同任务下随着思考预算变化的表现曲线。对于较简单的任务(如IFEval),模型的思维链(CoT)较短,且随着思考预算的增加,分数会出现波动。对于更具挑战性的任务(如AIME和LiveCodeBench),模型的思维链较长,且分数会随着思考预算的增加而提升。
以下是一个思考预算设为512的示例:在推理过程中,模型会定期触发自我反思来估算已消耗和剩余的预算,并在预算耗尽或推理结束时给出最终回应。
<seed:think>
Got it, let's try to solve this problem step by step. The problem says ... ...
<seed:cot_budget_reflect>I have used 129 tokens, and there are 383 tokens remaining for use.</seed:cot_budget_reflect>
Using the power rule, ... ...
<seed:cot_budget_reflect>I have used 258 tokens, and there are 254 tokens remaining for use.</seed:cot_budget_reflect>
Alternatively, remember that ... ...
<seed:cot_budget_reflect>I have used 393 tokens, and there are 119 tokens remaining for use.</seed:cot_budget_reflect>
Because if ... ...
<seed:cot_budget_reflect>I have exhausted my token budget, and now I will start answering the question.</seed:cot_budget_reflect>
</seed:think>
To solve the problem, we start by using the properties of logarithms to simplify the given equations: (full answer omitted).
如果未设置思考预算(默认模式),Seed-OSS将以无限长度启动思考。若指定了思考预算,建议用户优先选择512的整数倍数值(例如512、1K、2K、4K、8K或16K),因为模型已针对这些区间进行过大量训练。当思考预算为0时,模型会直接输出响应,我们建议将任何低于512的预算值设为0。
快速入
pip3 install -r requirements.txt
pip install git+ssh://git@github.com/Fazziekey/transformers.git@seed-oss
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
import remodel_name_or_path = "ByteDance-Seed/Seed-OSS-36B-Instruct"tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto") # You may want to use bfloat16 and/or move to GPU here
messages = [{"role": "user", "content": "How to make pasta?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt", thinking_budget=512 # control the thinking budget
)outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=2048)output_text = tokenizer.decode(outputs[0])
推理
下载模型
将Seed-OSS检查点下载到./Seed-OSS-36B-Instruct目录下
Transformers
generate.py脚本提供了一个可配置选项的简单模型推理接口。
基础用法
cd inference
python3 generate.py --model_path /path/to/model
关键参数
| 参数 | 说明 |
|---|---|
--model_path | 预训练模型目录路径(必填) |
--prompts | 输入提示词(默认:示例烹饪/编程问题) |
--max_new_tokens | 最大生成token数(默认:4096) |
--attn_implementation | 注意力机制:flash_attention_2(默认)或eager |
--load_in_4bit/8bit | 启用4位/8位量化(减少内存占用) |
--thinking_budget | 思考预算token数(默认:-1表示无限制) |
量化示例
# 8-bit quantization
python3 generate.py --model_path /path/to/model --load_in_8bit True# 4-bit quantization
python3 generate.py --model_path /path/to/model --load_in_4bit True
自定义提示
python3 generate.py --model_path /path/to/model --prompts "['What is machine learning?', 'Explain quantum computing']"
vLLM
使用 vllm 0.10.0 或更高版本进行推理。
- 首先安装支持 Seed-OSS 的 vLLM 版本:
VLLM_USE_PRECOMPILED=1 VLLM_TEST_USE_PRECOMPILED_NIGHTLY_WHEEL=1 pip install git+ssh://git@github.com/FoolPlayer/vllm.git@seed-oss
- 启动vLLM API服务器:
python3 -m vllm.entrypoints.openai.api_server \--host localhost \--port 4321 \--enable-auto-tool-choice \--tool-call-parser seed_oss \--trust-remote-code \--model ./Seed-OSS-36B-Instruct \--chat-template ./Seed-OSS-36B-Instruct/chat_template.jinja \--tensor-parallel-size 8 \--dtype bfloat16 \--served-model-name seed_oss
- 使用OpenAI客户端进行测试:
Chat
# no stream
python3 inference/vllm_chat.py --max_new_tokens 4096 --thinking_budget -1
# stream
python3 inference/vllm_chat.py --max_new_tokens 4096 --thinking_budget -1 --stream
Tool Call
# no stream
python3 inference/vllm_tool_call.py --max_new_tokens 4096 --thinking_budget -1
# stream
python3 inference/vllm_tool_call.py --max_new_tokens 4096 --thinking_budget -1 --stream
模型卡
查看 模型卡文件。
许可证
本项目采用 Apache-2.0 许可证,详情请参阅 许可证文件。