异常值检测:孤立森林模型(IsolationForest)总结
目录
- 一、前言
- 二、孤立森林算法
- 2.1 算法简介
- 2.2 基本原理
- 2.3 算法步骤
- 2.4 异常分数计算方式
- 2.5 python调用方式
- 三、python代码示例
- 四、小结
- 五、参考学习

一、前言
近期在研究构建寿命预测模型,相信很多数据人都懂建模的过程,其实有80%的时间都是在和数据处理打交道。
在数据处理过程中,一种常见的处理场景即异常值处理。日常常用的异常值处理,最常用的几种方式: 西格玛法则、四分位距、指定阈值 来识别检测异常值,其它使用过的方法主要是基于距离或者密度的方法来识别,不过这类方法小数据量还行,大数据量就很很影响检测效率。调研发现一种以前没用过的一种方法:孤立森林算法(Isolation Forest),因此作一记录学习。
二、孤立森林算法
2.1 算法简介
孤立森林(Isolation Forest)是一种用于异常检测的无监督学习算法,属于ensemble的方法,由 Fei Tony Liu、Kai Ming Ting 和 Zhi-Hua Zhou 于 2008 年提出。它通过构建多棵孤立树(Isolation Tree)来识别数据中的异常点,具有线性时间复杂度和高精准度,计算效率高、能够处理高维数据等优点,广泛应用于网络安全、金融欺诈检测、工业设备故障检测等领域。
2.2 基本原理
孤立森林算法的核心思想基于这样一个事实:异常点通常是数据集中少数且与其他数据点差异较大的点,因此它们更容易被孤立出来。该算法通过递归地随机划分数据空间,将异常点快速地隔离到树的浅层节点,而正常点则需要更多的划分才能被隔离,从而根据数据点在孤立树中的路径长度来判断其是否为异常点。
2.3 算法步骤
- 步骤一:构建孤立树(iTree)
- 从原始数据集中随机选择一部分样本(通常为固定数量,记为 sample_size)作为当前树的训练样本。
- 随机选择一个特征和该特征上的一个分割值,将样本集划分为两个子集。
- 对每个子集重复上述步骤,直到满足停止条件(例如,子集中只有一个样本或达到最大树深度)。
- 步骤二:构建孤立森林
重复步骤一,构建多棵孤立树(通常记为 n_estimators),这些树构成了孤立森林。
- 步骤三:计算路径长度
对于每个数据点,将其输入到孤立森林中的每棵树中,记录该数据点在每棵树中从根节点到叶节点所经过的路径长度。
- 步骤四:计算异常分数
根据数据点在所有孤立树中的平均路径长度,计算其异常分数。异常分数的取值范围在 0 到 1 之间,分数越接近 1 表示该数据点越可能是异常点,分数越接近 0 表示该数据点越可能是正常点。
2.4 异常分数计算方式
为了量化异常程度,孤立森林定义了异常分数 s(x,n)s(x,n)s(x,n),公式如下:
s(x,n)=2−E(h(x))c(n)s(x,n)=2^{-\frac{E(h(x))}{c(n)}}s(x,n)=2−c(n)E(h(x))
其中:
- h(x):样本x在iTree上的路径长度;
- E(h(x)):样本 x 在所有 iTree 中的平均路径长度;
- c(n):样本量为 n 时的 “平均路径长度期望”(作为归一化因子,由理论推导得出,与 n 近似成对数关系);
- n:构建 iTree 时的样本子集大小。
分数解读:
- s≈1:样本极可能是异常点(路径长度远短于平均);
- s≈0:样本极可能是正常点(路径长度接近平均);
- s≈0.5:样本处于正常与异常的边界(路径长度接近随机划分的平均水平)。
2.5 python调用方式
python中有现在的算法库,通过下述方式即可导入使用。
from sklearn.ensemble import IsolationForest
** 函数关键参数解析:**
- n_estimators:iTree 的数量(默认 100)。树越多,结果越稳定,但计算成本越高;
- max_samples:每棵 iTree 处理的样本量(默认 256)。过小可能导致异常点漏检,过大则降低效率;
- max_depth:iTree 的最大深度(默认随样本量动态调整)。限制深度可避免过拟合(尤其是样本量小时)。
三、python代码示例
# 导入必要的库
import pandas as pd # 数据处理库
import numpy as np # 数值计算库
import matplotlib.pyplot as plt # 数据可视化库
from sklearn.model_selection import train_test_split # 数据集划分工具
from sklearn.preprocessing import StandardScaler # 数据标准化工具
from sklearn.ensemble import IsolationForest # 异常检测模型
from sklearn.metrics import mean_squared_error, r2_score ,root_mean_squared_error # 模型评估指标
from itertools import groupby
from operator import itemgetter# 生成一些示例数据
np.random.seed(42)
X_inliers = 0.3 * np.random.randn(100, 2)
X_inliers = np.r_[X_inliers + 2, X_inliers - 2]
X_outliers = np.random.uniform(low=-4, high=4, size=(20, 2))
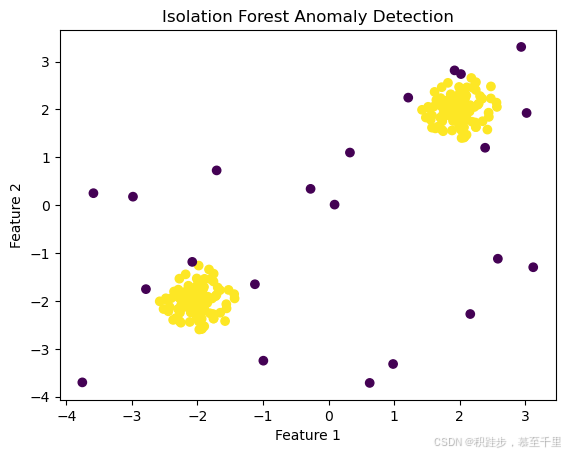
X = np.r_[X_inliers, X_outliers]# 创建并训练孤立森林模型
clf = IsolationForest(n_estimators=100, contamination=0.1)
clf.fit(X)# 预测每个数据点的异常标签
y_pred = clf.predict(X)# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=y_pred, cmap='viridis')
plt.title('Isolation Forest Anomaly Detection')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
四、小结
以前,有问题,找百度;现在有个更快捷的方式,有问题找chatgpt。不得不说,各类gpt工具,确实助力工作效率得到了很大的提升,相比百度搜索查找信息更加精准。最后,底层算法虽重要,但上层的思维逻辑更重要,作为数据分析师,千锤百炼自己思考问题、定义问题、解决问题的方式方法,思维逻辑尤其重要!
五、参考学习
- 孤立森林异常值评分公式推导
- 【异常检测】孤立森林(Isolation Forest)算法简介
- 孤立森林(isolation):一个最频繁使用的异常检测算法