参考
https://zhuanlan.zhihu.com/p/622212228
背景
目前大模型的参数以及计算量越来越大,如果放在多卡上处理成为关键,这里简单记录一下每种并行策略的概念。目前大模型核心就是gemm、FFN(MLP)、attention, 所以下面的说明也以这三个算子作为说明。
数据并行
每个gpu上储存一份模型参数,通过切分batch来实现并行推理
张量并行
gemm乘法
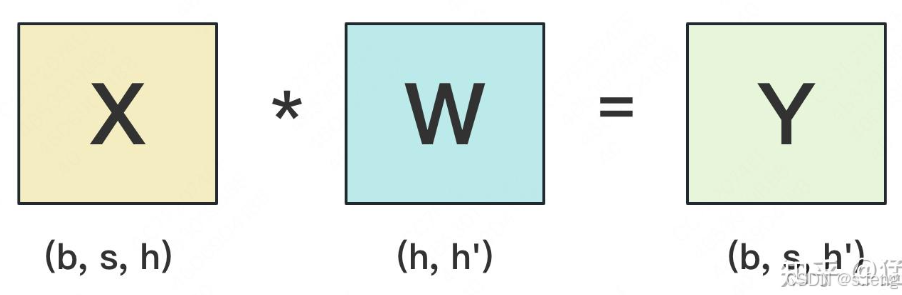
如果分到不同的gpu上的时候有两种方式:
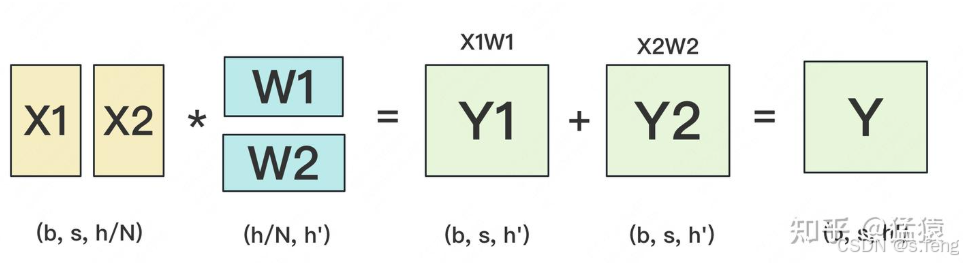
第一种:
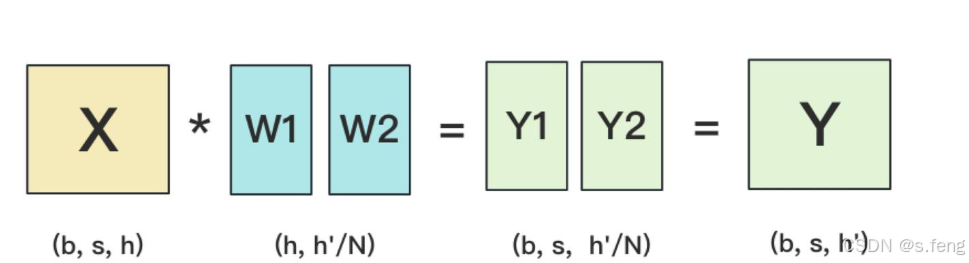
第二种:
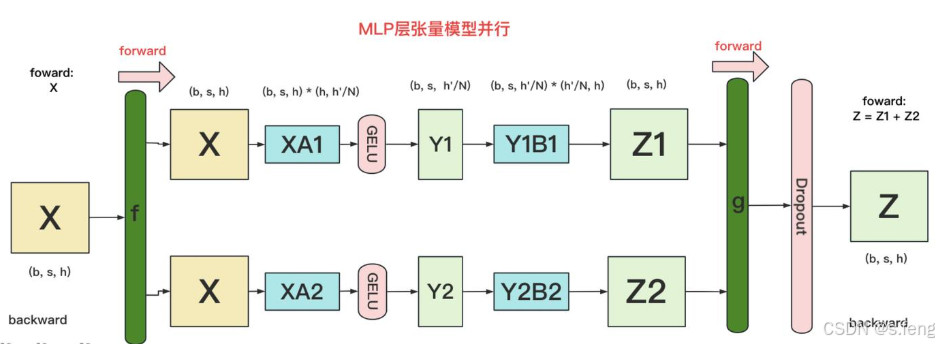
FFN
原始算法:
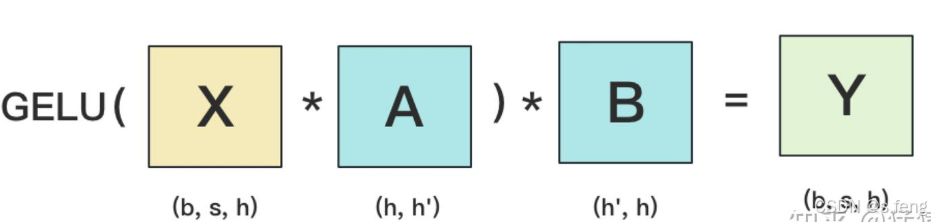
并行方式:
其实就是上面两个gemm的综合: