Transformer在文本、图像和点云数据中的应用——经典工作梳理
摘要
最近在整一些3D检测和分割的任务,接触了一下ptv3,在之前梳理的工作owlv2中用到了vit,去年年假阅读《多模态大模型:算法、应用与微调》(刘兆峰)时学习了Transformer网络架构及其在文本数据中的应用,细数下来,似乎各方面都多多少少了解和应用过一些,但是直到昨天跟别人讨论起Transformer在多模态数据中的应用,发现自己了解的不太系统,基于这个大背景,我希望借助闲暇时间梳理一下相关的代表性工作,后面如果有机会,也会做一些实践记录,希望自己学会的同时也可以帮助到一些有需要的小伙伴。
Transformer基础知识
网络架构
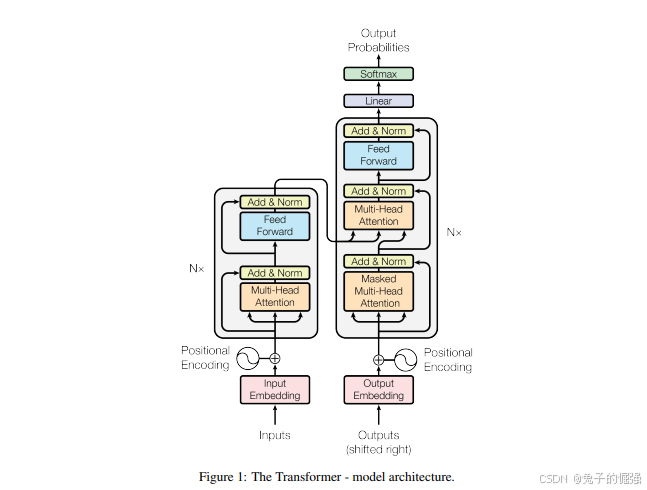
Transformer在nlp中的应用
Transformer在image处理中的应用
Transformer在point clouds处理中的应用
20250820:因为最近在整一些3d相关的工作,所以从该部分开始梳理。如果大家对pointnet系列的点云分割工作感兴趣的话,可以去看一下我之前整理的这篇文章3D分割系列论文梳理,欢迎一起讨论。
PT
参考链接:https://zhuanlan.zhihu.com/p/681682833
贡献
We design a highly expressive Point Transformer layer for point cloud processing. The layer is invariant to permutation and cardinality and is thus inherently suited to point cloud processing.
在pointnet中有提到,3d点云实际上是一种集合,在点云网络结构的设计中,由于点云是无序的,所以设计与点云排序和点数量无关的网络至关重要。而transformer的自注意力机制天生具有排序和点个数不变性,使得它非常适合用来提取点集的特征。
而本文也是聚焦在对点云局部特征提取结构的改造,将自注意力机制应用在了局部特征提取上。
Based on the Point Transformer layer, we construct high-performing Point Transformer networks for classification and dense prediction on point clouds. These networks can serve as general backbones for 3D scene understanding.
We report extensive experiments over multiple domains and datasets. We conduct controlled studies to examine specific choices in the Point Transformer design and set the new state of the art on multiple highly competitive benchmarks, outperforming long lines of prior work.
相关工作梳理
第一类,将不规则点云转换成规则表示:
Projection-based networks
将点云投影成图片,利用2D CNN进行处理,最后利用多视角特征融合构建最终的输出特征表示。
在基于投影的框架中,点云中的几何信息会在投影阶段被压缩。这些方法在投影平面上构建密集像素网格时,可能未能充分利用点云的稀疏特性。投影平面的选择会显著影响识别性能,而三维场景中的遮挡现象也可能导致精度下降。
Voxel-based networks
3D体素+3D 卷积
该类方法,如果直接简单粗暴的使用3D卷积的话,计算量和内存占用会随着分辨率增加导致体素块数量呈三次方增长而增加,解决方式是使用稀疏卷积或者非平衡八叉树结构,一定程度上减少计算量和内存占用。此外,由于体素网格上的量化处理,仍可能丢失部分几何细节。
第二类,直接操作不规则点云
Point-based networks.
研究人员没有将不规则点云投影或量化到二维或三维的规则网格上,而是设计了深度网络结构,直接将点云作为嵌入连续空间的集合来吸收。(pointnet/pointnet++)
许多方法将点集连接成一个图,并在此图上进行信息传递。(此类目前了解的比较少)
许多方法基于直接应用于三维点集的连续卷积,而无需量化。(此类目前了解的比较少)
本文的研究灵感
在序列处理和二维图像任务中,Transformer和自注意力网络的表现可与卷积网络相媲美甚至更胜一筹。自注意力机制在本研究中具有特殊意义,因其本质上属于集合运算:位置信息作为元素属性被处理为集合形式。由于三维点云本质上是具有空间属性的点集,这种机制特别适合此类数据类型。为此,开发了专门针对三维点云的点变换器层,实现了自注意力机制的应用。
Point Transformer
background
Self-attention operators can be classified into two types: scalar attention [39] and vector attention [54]. 此处文章中公式很清晰,如果还是看不懂的话,可以问问豆包,并让它给举个例子,很清晰。
Point Transformer layer
数学运算:

在局部邻域应用vector self-attention,对特征所做的数学运算见上图公式(3),对应的网络架构见下图。(确定提局部邻域特征的运算是关键,后续搭建网络是水到渠成的事情)
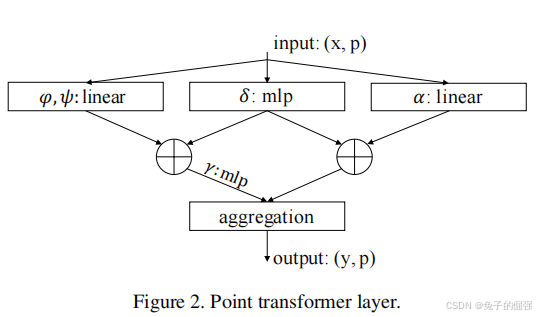
Position Encoding

Network Architecture
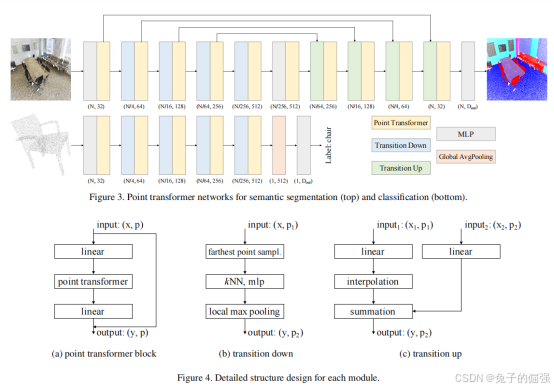
Backbone structure
The feature encoder in point transformer networks for semantic segmentation and classification has five stages that operate on progressively downsampled point sets. The downsampling rates for the stages are [1, 4, 4, 4, 4], thus the cardinality of the point set produced by each stage is [N, N/4, N/16, N/64, N/256], where N is the number of input points.
Transition down
见网络架构图
Transition up
见网络架构图
Output head
见网络架构图
问题及解答
问题1:TransitionDown与PointTransformerLayer都是做局部特征提取的,它俩有什么不同?并且两个块之间的数据是怎么流动的?
参考了openpoints库中的代码:
class TransitionDown(nn.Module):def __init__(self, in_planes, out_planes, stride=1, nsample=16):super().__init__()self.stride, self.nsample = stride, nsampleif stride != 1:self.linear = nn.Linear(3 + in_planes, out_planes, bias=False)self.pool = nn.MaxPool1d(nsample)else:self.linear = nn.Linear(in_planes, out_planes, bias=False)self.bn = nn.BatchNorm1d(out_planes)self.relu = nn.ReLU(inplace=True)# 如果self.stride != 1会减少点数,通过最大池化获取每个分组的全局特征。def forward(self, pxo):p, x, o = pxo # (n, 3), (n, c), (b)if self.stride != 1:n_o, count = [o[0].item() // self.stride], o[0].item() // self.stridefor i in range(1, o.shape[0]):count += (o[i].item() - o[i - 1].item()) // self.striden_o.append(count)n_o = torch.cuda.IntTensor(n_o)# print(n_o.device, p.device)idx = pointops.furthestsampling(p, o, n_o) # (m)n_p = p[idx.long(), :] # (m, 3)x = pointops.queryandgroup(self.nsample, p, n_p, x, None, o, n_o, use_xyz=True) # (m, nsample,3+c)x = self.relu(self.bn(self.linear(x).transpose(1, 2).contiguous())) # (m, out_planes, nsample)x = self.pool(x).squeeze(-1) # (m, out_planes)p, o = n_p, n_oelse:x = self.relu(self.bn(self.linear(x))) # (n, out_planes)return [p, x, o]class PointTransformerLayer(nn.Module):def __init__(self, in_planes, out_planes, share_planes=8, nsample=16):super().__init__()self.mid_planes = mid_planes = out_planes // 1self.out_planes = out_planesself.share_planes = share_planesself.nsample = nsampleself.linear_q = nn.Linear(in_planes, mid_planes)self.linear_k = nn.Linear(in_planes, mid_planes)self.linear_v = nn.Linear(in_planes, out_planes)self.linear_p = nn.Sequential(nn.Linear(3, 3), nn.BatchNorm1d(3), nn.ReLU(inplace=True),nn.Linear(3, out_planes))self.linear_w = nn.Sequential(nn.BatchNorm1d(mid_planes), nn.ReLU(inplace=True),nn.Linear(mid_planes, mid_planes // share_planes),nn.BatchNorm1d(mid_planes // share_planes), nn.ReLU(inplace=True),nn.Linear(out_planes // share_planes, out_planes // share_planes))self.softmax = nn.Softmax(dim=1)# 不会减少点数,只是会对每个点,计算其邻域的self-attentiondef forward(self, pxo) -> torch.Tensor:p, x, o = pxo # (n, 3), (n, c), (b)# 点特征分别经过三个线性层,获得q,k,vx_q, x_k, x_v = self.linear_q(x), self.linear_k(x), self.linear_v(x) # (n, c)# 查找最近邻x_k = pointops.queryandgroup(self.nsample, p, p, x_k, None, o, o, use_xyz=True) # (n, nsample, 3+c)x_v = pointops.queryandgroup(self.nsample, p, p, x_v, None, o, o, use_xyz=False) # (n, nsample, c)p_r, x_k = x_k[:, :, 0:3], x_k[:, :, 3:]for i, layer in enumerate(self.linear_p): p_r = layer(p_r.transpose(1, 2).contiguous()).transpose(1,2).contiguous() if i == 1 else layer(p_r) # (n, nsample, c)w = x_k - x_q.unsqueeze(1) + p_r.view(p_r.shape[0], p_r.shape[1], self.out_planes // self.mid_planes,self.mid_planes).sum(2) # (n, nsample, c)for i, layer in enumerate(self.linear_w): w = layer(w.transpose(1, 2).contiguous()).transpose(1,2).contiguous() if i % 3 == 0 else layer(w)w = self.softmax(w) # (n, nsample, c)n, nsample, c = x_v.shapes = self.share_planes# w.unsqueeze(2)广播机制x = ((x_v + p_r).view(n, nsample, s, c // s) * w.unsqueeze(2)).sum(1).view(n, c) # (n, out_planes)return x
由上述开源代码可以看出来,TransitionDown是对输入点集进行最远点采样,分组,逐点特征提取以及组内最大池化后输出各个邻域的特征。
而PointTransformerLayer是对输入的点集中的每一个点查找k近邻,然后对每个邻域做自注意力,获得每个点的聚合特征,并不会减少点的数量。(自注意力机制的核心是 “同一组数据内部元素之间的注意力交互”(即查询、键、值均来自同一组输入)。)