BeyondWeb:大规模预训练合成数据的启示
论文: BeyondWeb:大规模预训练合成数据的启示
由 K2 预训练策略回顾海量语料重写技术(202508)
动机:如何做出更好的、匹配预训练数据规模的合成数据
以往大规模数据合成工作可以分为
基于模型(prompt 让模型产生种子,基于种子再 prompt 模型产生大量语料)和基于源数据的改写方法,
代表工作分别是
tiny stories->phi,cosmopedia
WRAP 和 Nemotron-CC 中的 Nemotron-Synth 1.5T token 数据集
Tiny Stories 的开创性工作表明,高质量、精心提示的合成数据(如由 GPT-4 创作的简化叙事)可以有效地从零开始训练小型语言模型
Phi 模型家族通过在合成数据和原始网络数据上联合训练小型(<2B 参数)模型,进一步推进了生成器驱动方法,并能够使用一小部分训练计算量超越多达 10 倍的模型。Cosmopedia 通过利用开源 LLM 和多样化的一组精选种子主题来提示它,进一步推动了这一方向,引入了一个大规模的开源合成数据集。
2025 年,改写已成为主导范式,像 Kimi K2、Qwen-2.5、Grok 和 GPT-5 这样的最先进 LLM 报告了来源改写的大量使用和/或有意义的收益。
但是这些工作并不全面和彻底,没有回答以下关键问题,本文全面研究和回答如下:
Questions 与结论
- 合成数据如何改进预训练效果?
有一种简单解释是教师模型提高了 token 的信息密度,本工作发现,最简单的摘要 prompt 可以实现与 cosmopedia 类似的性能- 能否持续 scaling 从而突破现有数据墙的限制?
简单续写提升有限,精心构造、填补分布中的信息空白更有用- 改写什么数据?如何改写?
源数据质量很重要,改写 high quality 样本带来更多增益,但仅依赖 rephrase 得不到最高质量(下游验证最佳的数据集)分布风格匹配很重要。例如网页数据中只有 2.7% 的对话数据,与 chatbot 的用例不符。但只做对话改写的收益很快见顶扩大到万亿级别 token 时,多样的策略尤其重要- 让什么样的模型来执行改写?
不同模型的效用基本一致,且模型本身的下游性能并不能预测其合成数据的质量。改写应当是一种通用能力让更大的模型进行改写,收益也很快见顶
总结:
高质量的合成数据来自多样化的策略和科学的实验设计,没有万能的方法;
如果在方法上省力,则会带来若干弊端;
源数据选择、合成方法、多样性、质量控制都是 pipeline 中的关键变量
花絮
本工作来自 datology AI,该工作是 Saas 初创 Arcee AI 发布的 AFM 4.5B 模型数据部分的副产品
提到前沿实验室在数据这块都是猛猛投入人力做但不说方法,还特别强调 GPT-4 技术报告里有至少69位研究者的工作与数据直接相关
报告在种子数据收集部分引用了 datologyAI 发布过的 blog,也可以作为比较新的预训练数据收集管线参考 https://blog.datologyai.com/technical-deep-dive-curating-our-way-to-a-state-of-the-art-text-dataset/ 但跟本工作一样,只有方法,没有任何可以用来复现的 artifacts
相关工作梳理
动机中提到的两种思路,
本文称为生成器驱动 generator-driven 和源数据改写 source rephrase 两种思路,
前者的缺陷在于可扩展性差,依赖模型本身的知识边界并集成 bias,多样性、覆盖范围不足,且容易代入大量幻觉
BeyondWeb 方法
没说任何具体做法。
但读者可以根据下面的消融实验/RQs 倒推出都有哪些环节数据集:
原始数据为 RPJV1,
合成数据种子来自 DCLM subset(筛选方法见上方博客链接),6:4 混合
基线:cosmopedia,WRAP,Nemotron-Synth直接上评估效果
BeyondWeb 采用多种生成策略,包括格式转换(例如将网络内容转换为问答对)、风格修改(例如增强教学语气)和内容重构,以提高信息密度和可访问性
训练三种规模的 LLM:
1B 参数模型,训练 1 万亿个 token。
3B 模型,训练 1800 亿个 token。
8B 模型,训练 1800 亿个 token。
使用 LLAMA-3.2 架构(1B 和 3B 模型)和 LLAMA-3.1 架构(8B 模型)。除了在基线 RPJ 数据上的早期搜索外,未广泛调整超参数,目标是仅通过数据干预提高模型性能。
评估设置
在 14 个基准任务上评估模型,使用 0-shot 和 5-shot 提示,报告所有设置和任务的平均准确率。多项选择题使用相对评分方法评估,如 Hugging Face 对 OpenLLM 排行榜的分析所述,称为“填空形式”(CF)。
- 性能提升
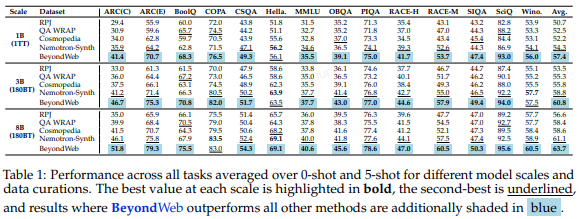
BeyondWeb 在所有评估的模型规模上均表现出一致的改进。
在 1B 参数时,平均准确率为 57.4%(比 RPJ 高 6.7pp),为 3B 和 8B 模型奠定了坚实基础。
随着规模增加,性能提升更加显著:3B 模型达到 60.8% 准确率(比 RPJ 高 7.3pp),8B 模型准确率升至 63.7%(比 RPJ 高 7.1pp)。B
eyondWeb 还在所有规模上一致超越 Nemotron-Synth(+3.1pp、+2.0pp、+2.6pp)。这些结果表明,BeyondWeb 在不同规模上均有效,并在更大模型中提供显著优势。- 训练速度提升
BeyondWeb 在预训练期间显著节省计算成本。对于 8B 模型,BeyondWeb 仅用 232 亿个 token 就达到或超过 RedPajama 1800 亿个 token 的性能(7.7× 速度提升),仅用 662 亿个 token 就达到 Nemotron-Synth 1800 亿个 token 的性能(2.7× 速度提升)。更快的收敛直接降低训练成本、能源消耗和迭代时间,使固定计算预算内能进行更多实验。这种效率不仅对大型工业实验室优化成本有价值,也对受基础设施限制的较小组织有价值,有助于普及高性能 LLM 的访问。- 建立新的 Pareto 前沿
BeyondWeb 的结果为语言模型预训练的速度 - 准确率权衡建立了新的 Pareto 前沿,如图 1 所示。值得注意的是,3B 模型(60.8% 准确率)除了最强的 8B 基线模型外,均超越了所有训练相同 token 数量(1800 亿)的模型,表明高质量合成数据可以用显著更少的参数实现更优结果。这突显了高质量合成数据解锁的可扩展性和潜力,使更大模型在更低计算成本下实现更强性能,挑战了对更大架构的常规依赖。- 任务一致性改进
如表 1 所示,BeyondWeb 在每个模型规模上均实现最高平均准确率,并且在 1B、3B 和 8B 模型中分别在 13、12 和 13 个任务中超越基线。这表明性能提升不仅局限于少数突出基准,而是广泛分布,反映了高质量、多样化合成数据实现的泛化能力。
消融实验
本文最有价值的章节。但不得不说,很多业界工作限于人员精力和成本,在大规模模型训练和数据验证上面并不严谨,因此以下结论有可参考性但并不能作为严谨论证;另外为了 PR 效果还有点逆天地把最佳综合方案放进了每一张图里,因此下方摘录结论时会忽略 BeyondWeb 曲线。
RQ1:生成器驱动方法是否可被简单总结方法近似?——是的
摘要使用的 prompt:
Summarize the following text. Directly start with the summary. Do not say anything else.
总结以下文本。直接从总结开始。不要说其他任何话。
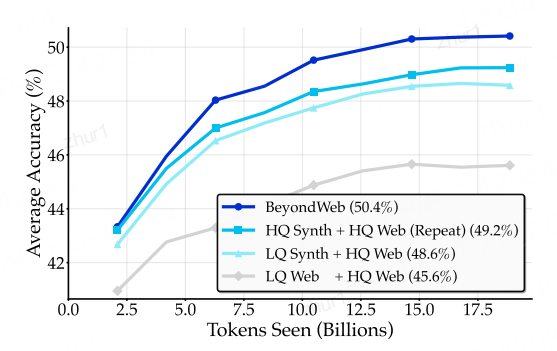
简单摘要与 cosmopedia 的效果近似,且摘要所使用的计算资源远少于 cosmopedia
HQ 表示高质量的网络数据,LQ 表示低质量的网络数据。深蓝色的线表示 BeyondWeb(50.4%),深青色的线表示 HQ Synth + HQ Web(49.2%),其中合成数据是高质量网络样本的改写版本,浅青色的线表示 LQ Synth + HQ Web(48.6%)。灰色的基线对应于 LQ Web + HQ Web(45.6%)
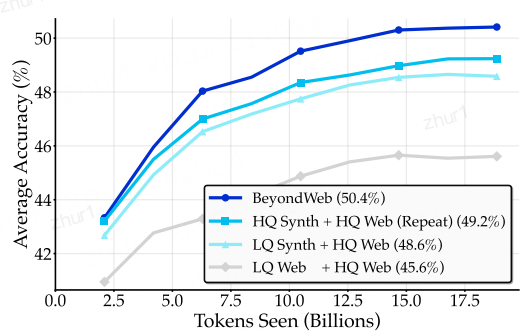
RQ2:合成数据能否打破数据墙——有希望
合成数据的有效性:合成数据可以在一定程度上弥补有限的高质量真实数据,但其效果取决于合成数据的质量和生成方式。
数据瓶颈的突破:是否能够突破数据瓶颈取决于合成数据的类型。高质量的合成数据可以显著提高模型的性能,而低质量的合成数据则可能无法达到理想的效果。
合成数据的局限性:即使使用高质量的合成数据,也难以完全替代真实的高质量数据。在某些情况下,合成数据可能会引入噪声或偏差,从而影响模型的性能。
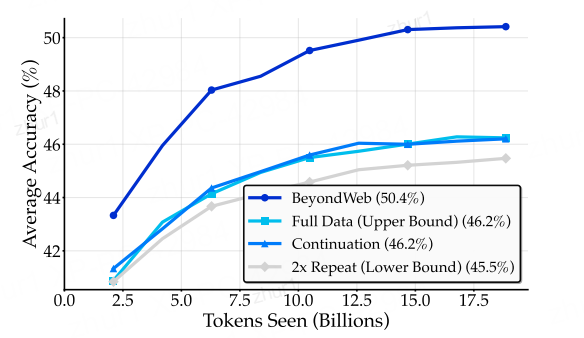
简单的续写合成≈原始数据>机械重复
不同数据增强策略在训练过程中的性能比较。深蓝色的线代表 BeyondWeb(50.4%),它显著超过了所有其他方法。浅蓝色的线表示 Continuation(46.2%),青色的线表示 Full Data Upper Bound(46.2%),灰色的线表示 2x Repeat Lower Bound(45.5%)。这种显著的视觉分离强调了 BeyondWeb 相对于 Full Data Upper Bound 的 +4.2 个百分点的提升。这反映了在使用合成数据打破数据瓶颈时,意图性的重要性,而不仅仅是任何合成数据都能带来好处。
RQ3:种子数据质量对 rephrase 的重要性——高质量数据 is all you need
结论:高质量种子合成收益最显著,低质量数据似无太大利用的必要
在高质量数据有限的情况下,使用高质量数据作为合成改写的种子数据比使用低质量数据更有益,尽管这可能会重复高质量源中的知识。然而,仅靠高质量的输入数据还不足以生成最高质量的合成数据。高质量的合成数据需要结合高质量的种子数据和精心设计的合成策略,以实现知识的放大和性能的提升。
RQ4:与用户用例做分布风格匹配重要吗?——有用但没有那么大用处
这里先是估计了 RPJ 中的对话比例(GPT4o 作为标注员),10K 抽样得到大概 2.7%;
再用 organize the web 中的风格过滤器验证,20 种 CC 内容风格中的四种可以看成对话,过滤后大概 3.67%。
两个统计结果接近,因此网页中对话类数据的分布大概是2~4%这个量级
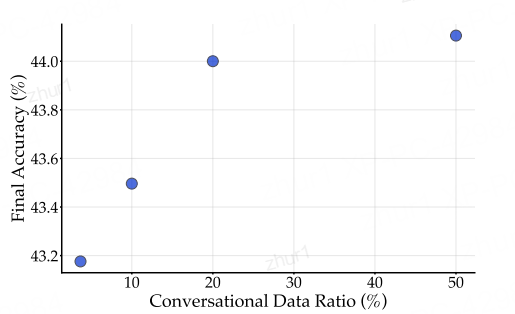
对比:对话内容按原始分布、占10%/20%/50%
结论:有提升但很快达到瓶颈(XX 式坐标轴是吧)
对话式数据在网络数据中所占比例较小(3.67%),但聊天和上下文学习是现代语言模型的主要应用领域。通过增加对话式数据的比例,可以显著提升模型在下游任务中的性能,但这种提升存在收益递减的现象。这表明风格匹配虽然重要,但不足以最大化合成数据的质量。为了实现最佳性能,需要结合高质量的种子数据和优化的合成策略,以及更复杂的模型架构。
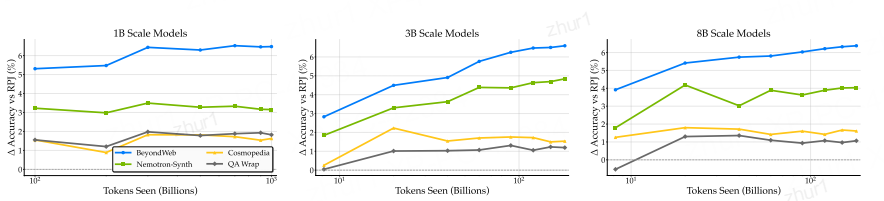
RQ5:大数据集中的多样性很重要
实验比较:
cosmopedia 的教科书类型
QA WRAP 将网页改写为对话
Nemotron-Synth 多样化策略,扩展到各种考试题型和文本类任务
发现:多样性策略的收益持续提升
在大规模训练中,合成数据的多样性对于模型性能的持续提升至关重要。虽然单一策略的合成数据生成方法在初期可以提供一定的性能提升,但它们最终会达到平台期。
相比之下,强调多样性的方法(如BeyondWeb)不仅在训练初期提供显著的性能提升,而且在整个训练过程中都能持续提供学习信号,即使在极端的训练条件下也能保持性能的提升。这表明多样性是实现大规模训练中持续学习的关键因素。
RQ6:使用什么模型、多大的 size 是否有影响?——影响不大,且效果很难预测
在两个维度上比较:
模型系列(family)和 size(1B、3B、8B),分别跑了olmo2 7B、Mistral 7B、phi4 14B、Llama3.1 8BLlama3 系列的 1B、3B、8B
结果:不同模型系列的差距在 1% 以内,且下游性能无法预测合成数据的质量模型增大有收益,但很快遇到瓶颈
在合成数据生成中,选择特定的生成器家族并不关键。
不同的生成器家族都能生成高质量的合成数据,即使它们在一般语言建模能力上存在差异。
这表明,合成数据的质量更多地取决于模型的改写和数据转换能力,而不是其一般语言建模能力。
因此,组织可以灵活选择现有的模型家族来部署合成数据管道,而不必担心特定生成器的优化问题,从而降低资源使用并提高开源和可接受模型的可行性。
RQ7:改写器的大小重要吗?——有一定影响,小模型更经济
改写器模型的大小对合成数据的质量有一定影响,但这种影响在模型大小达到3B时逐渐减弱。
即使是较小的模型(如1B)也能生成高质量的合成数据,而较大的模型(如8B)提供的额外增益有限。
这表明在许多应用中,小模型是成本高效且实用的选择,能够提供高质量的合成数据,同时保持较低的计算开销