Java 集合超详细教程
目录
一、集合的介绍
二、集合的框架
三、核心接口和常用实现类
1、Collection体系核心类
1.1、List接口(有序、可重复)
1.2、Set接口(无序、不可重复)
1.3、Queue接口(先进先出,FIFO)
2、Map体系核心类
四、集合常见问题
1、集合遍历
1、Collection和Collections的区别
2、集合遍历的方法
2、List
1、ArrayList的LinkedList的区别,
2、ArrayList和LinkedList的线程安全吗,如何保证线程安全?
3、ArrayList的扩容机制
3、Map
1、HashMap的实现原理
2、什么是哈希冲突,以及解决办法
3、HashMap是线程安全的嘛?
4、HashMap的put过程
5、HashMap的扩容机制
6、ConcurrentHashMap是怎么实现的,线程安全嘛(详细介绍ConcurrentHashMap的内部实现原理)
7、HashTable实现原理,是否是线程安全的
8、ConcurrentMap和HashTable的区别
本文不仅有常见集合的介绍,后面也有对HashMap以及ConcurrentHashMap的原理的详细介绍以及相关知识。
一、集合的介绍
集合是Java中用于存储多个数据元素的容器,并且相对于数组提供了动态扩容,元素增删改查、排序、筛选等便捷操作,提高了开发效率
和数组的区别?
| 对比维度 | 数组(Array) | 集合(Collection) |
|---|---|---|
| 长度 | 初始化后固定,无法动态扩容 | 长度动态变化,自动调整容量 |
| 存储元素类型 | 只能存同一种数据类型(或其子类) | 可存不同类型(泛型出现后建议统一类型,更安全) |
| 功能 | 仅支持通过索引访问,无内置工具方法 | 自带增删(add/remove)、查询(contains)、排序(sort)等方法 |
| 存储对象 | 基本类型(如 int)和对象都可存 | 只能存对象(基本类型需用包装类,如 Integer) |
二、集合的框架
java集合框架主要分为两大体系(Collection和Map),先记清顶层接口和核心分支,避免后续混淆
Java 集合框架
├─ 1. Collection 接口(存储“单个元素”的集合)
│ ├─ List 子接口:有序、可重复、有索引(如 ArrayList、LinkedList)
│ ├─ Set 子接口:无序、不可重复(如 HashSet、TreeSet)
│ └─ Queue 子接口:队列(先进先出,FIFO),如 LinkedList(实现了 Queue)、PriorityQueue
│
└─ 2. Map 接口(存储“键值对(Key-Value)”的集合)├─ 普通 Map:如 HashMap(无序)、TreeMap(按 Key 排序)└─ 特殊 Map:如 Hashtable(线程安全,已过时)、ConcurrentHashMap(线程安全,推荐)对应详细的结构如下:
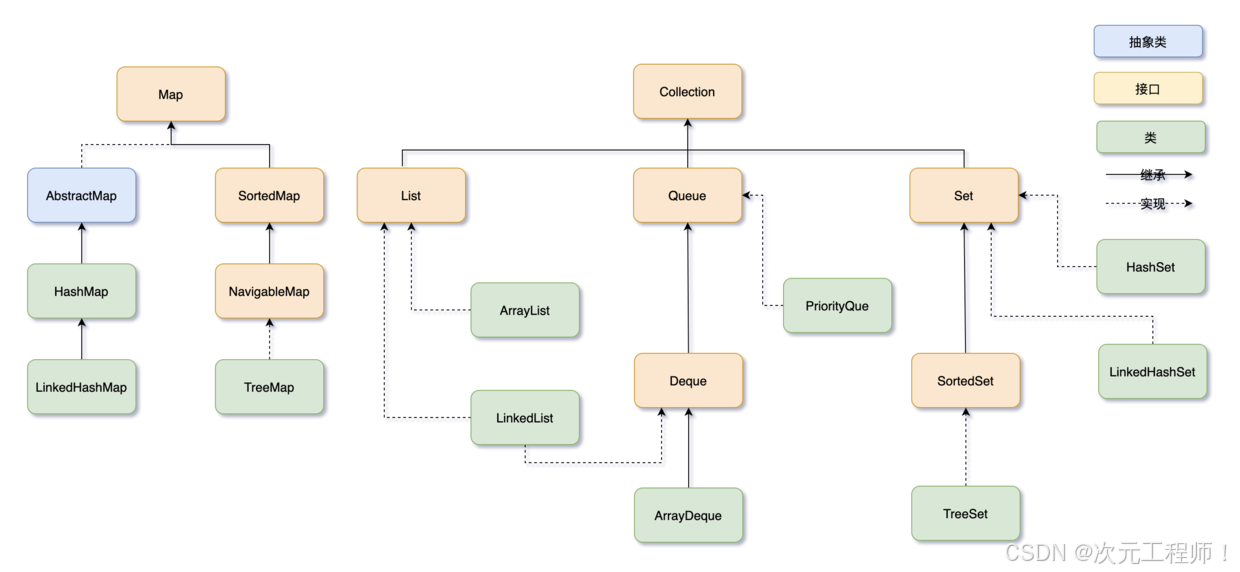
(图片来源于网络)
关键区分 :Collection 存 “单个元素”,Map 存 “键值对”,这是两大体系的核心差异。
三、核心接口和常用实现类
1、Collection体系核心类
1.1、List接口(有序、可重复)
核心特性:元素有固定顺序(按插入顺序),支持通过索引(如 get(0))访问,允许存重复元素。
该接口有两个实现类:ArrayList,LinkedList
| 实现类 | 底层结构 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| ArrayList | 动态数组 | 随机访问快(通过索引直接定位) | 增删(尤其是中间位置)慢(需移动元素) | 频繁查、少增删的场景(如列表展示) |
| LinkedList | 双向链表 | 增删快(只需改指针,无需移动元素) | 随机访问慢(需从头 / 尾遍历) | 频繁增删、少查询的场景(如队列) |
下面是简单的使用,具体其他api的使用,请参照文档~
ArrayList:
import java.util.ArrayList;
import java.util.List;public class ListExample {public static void main(String[] args) {// 创建一个 ArrayList 对象List<String> list = new ArrayList<>();// 添加元素list.add("apple");list.add("banana");list.add("cherry");// 访问元素System.out.println(list.get(1)); // 输出: banana// 修改元素list.set(2, "date");// 删除元素list.remove(0);// 遍历元素for (String fruit : list) {System.out.println(fruit);}}
}LinkedList:
import java.util.LinkedList;public class LinkedListDemo {public static void main(String[] args) {// 1. 创建LinkedList(泛型为Integer,存整数)LinkedList<Integer> orderIds = new LinkedList<>();// 2. 核心操作(增删比ArrayList高效,查询仍用get,但效率低)orderIds.add(1001); // 末尾加orderIds.add(1002);orderIds.addFirst(1000); // 链表头部加(LinkedList特有方法)System.out.println("订单ID列表:" + orderIds); // 输出:[1000, 1001, 1002]orderIds.removeLast(); // 链表尾部删(特有方法)System.out.println("删除尾部后:" + orderIds); // 输出:[1000, 1001]// 3. 遍历(和ArrayList一致)System.out.println("遍历订单ID:");for (Integer id : orderIds) {System.out.println(id);}}
}1.2、Set接口(无序、不可重复)
核心特性:元素无固定顺序(HashSet 完全无序,TreeSet 按元素大小排序),不允许存重复元素(判断重复的核心是 equals() 和 hashCode() 方法)。
该接口有三个实现类:HashSet,LinkedHashSet,TreeSet
| 集合类型 | 有序性 | 排序规则 | 底层结构 | 适用场景 |
|---|---|---|---|---|
| HashSet | 无序 | 无(哈希表随机存储) | 哈希表(数组 + 链表 / 红黑树) | 仅需去重,不关心顺序 |
| LinkedHashSet | 有序 | 插入顺序 | 哈希表 + 双向链表 | 去重且需保留插入顺序 |
| TreeSet | 有序 | 自然排序 / 自定义排序 | 红黑树 | 需要排序 + 去重的场景(如按价格排序商品) |
特殊说明:HashSet 本身没有独立的哈希存储结构,而是内部持有一个 HashMap 实例,通过复用 HashMap 的功能实现 “去重集合” 的特性:对应的 Value 是一个固定的静态空对象(private static final Object PRESENT = new Object()),仅用于占位,不存储实际数据。
HashSet:
import java.util.HashSet;
import java.util.Set;public class HashSetDemo {public static void main(String[] args) {// 1. 创建HashSet(存用户手机号,自动去重)Set<String> phoneNumbers = new HashSet<>();// 2. 核心操作:add(重复元素会自动过滤)phoneNumbers.add("13800138000");phoneNumbers.add("13900139000");phoneNumbers.add("13800138000"); // 重复元素,不会存入System.out.println("去重后的手机号:" + phoneNumbers); // 输出(顺序不固定,因为无序):[13800138000, 13900139000]// 3. 查:判断是否包含(contains)boolean hasPhone = phoneNumbers.contains("13900139000");System.out.println("是否包含13900139000:" + hasPhone); // 输出:true// 4. 遍历(无索引,只能用增强for)System.out.println("遍历手机号:");for (String phone : phoneNumbers) {System.out.println(phone);}}
}TreeSet:
public class TreeSetDemo {public static void main(String[] args) {// 1. 场景1:存商品价格,按自然顺序(从小到大)排序Set<Double> productPrices = new TreeSet<>();productPrices.add(99.9);productPrices.add(59.9);productPrices.add(129.9);System.out.println("商品价格(自然排序):" + productPrices); // 输出:[59.9, 99.9, 129.9]// 2. 场景2:自定义排序(从大到小),需传ComparatorSet<Double> descPrices = new TreeSet<>((a, b) -> b.compareTo(a));descPrices.add(99.9);descPrices.add(59.9);descPrices.add(129.9);System.out.println("商品价格(倒序):" + descPrices); // 输出:[129.9, 99.9, 59.9]}
}Set<Double> descPrices = new TreeSet<>((a, b) -> b.compareTo(a)); 解释下这段代码:这段代码的核心是 给 TreeSet 指定设置自定义排序规则,让元素按 “从大到小” 排序(默认是从小到大)
如果想自定义排序(比如从大到小),需要在创建 TreeSet 时传入一个 比较器(Comparator),告诉集合 “如何比较两个元素的大小”。
Comparator 是一个接口,里面有一个核心方法 compare(a, b),用于定义两个元素 a 和 b 的比较规则:
- 若返回 正数,排序规则是a在后,b在前
- 若返回 负数,排序规则是a在前,b在后。
- 若返回 0:表示
a == b
代码中的 (a, b) -> b.compareTo(a) 是一个 lambda 表达式,等价于以下完整的 Comparator 实现:
// 完整写法(和lambda表达式效果完全一致)
Comparator<Double> descComparator = new Comparator<Double>() {@Overridepublic int compare(Double a, Double b) {// 核心逻辑:用 b 比 a(默认是 a 比 b)return b.compareTo(a); }
};
Set<Double> descPrices = new TreeSet<>(descComparator);
Double 类自带的 compareTo 方法默认是 a.compareTo(b)(返回 a - b 的符号),表示 a 比 b;若a > b,则返回正数,此时排序规则是a在后,b在前,意味着大的数排在后面,小的数排在前面,这就是降序排序了。
而 b.compareTo(a) 则是 b 比 a(返回 b - a 的符号),因此实现了 “从大到小” 的排序。
1.3、Queue接口(先进先出,FIFO)
核心特性:模拟 “队列” 数据结构,元素从队尾加入(offer()),从队头取出(poll()),默认先进先出。
该接口有两个实现类:LinkedList、PriorityQueue
LinkedList:同时实现了 List 和 Queue,可作为 “普通队列” 使用;
PriorityQueue:优先级队列,不按插入顺序,而是按元素优先级(自然顺序 / 自定义比较器)取出,底层是堆结构。
LinkedList:
public class QueueDemo {public static void main(String[] args) {// 1. 创建Queue(用LinkedList实现,存任务ID,FIFO)Queue<String> taskQueue = new LinkedList<>();// 2. 核心操作:入队(add,offer)、出队(poll)、看队首(peek)taskQueue.add("任务1"); // 入队taskQueue.offer("任务2");taskQueue.offer("任务3");System.out.println("队列当前:" + taskQueue); // 输出:[任务1, 任务2, 任务3]String firstTask = taskQueue.peek(); // 看队首(不删除)System.out.println("队首任务:" + firstTask); // 输出:任务1String doneTask = taskQueue.poll(); // 出队(删除并返回队首)System.out.println("完成的任务:" + doneTask); // 输出:任务1System.out.println("出队后队列:" + taskQueue); // 输出:[任务2, 任务3]}
}PriorityQueue:
public class PriorityQueueDemo {public static void main(String[] args) {// 1. 创建优先级队列,传入自定义比较器(成绩从高到低)// 泛型是 Student 类,存储学生姓名和成绩PriorityQueue<Student> studentQueue = new PriorityQueue<>(new Comparator<Student>() {@Overridepublic int compare(Student s1, Student s2) {// 核心规则:s2的成绩 - s1的成绩(高成绩优先)return s2.getScore() - s1.getScore();}});// 2. 添加学生(成绩不同)studentQueue.add(new Student("张三", 80));studentQueue.add(new Student("李四", 95));studentQueue.add(new Student("王五", 88));// 3. 出队(按优先级:成绩高的先出队)System.out.println("处理顺序(成绩从高到低):");while (!studentQueue.isEmpty()) {Student student = studentQueue.poll(); // 取出优先级最高的元素System.out.println(student.getName() + ",成绩:" + student.getScore());}}// 学生类(存储姓名和成绩)static class Student {private String name;private int score;public Student(String name, int score) {this.name = name;this.score = score;}// getter方法public String getName() { return name; }public int getScore() { return score; }}
}2、Map体系核心类
核心特性:
- 存储
Key-Value键值对,Key唯一(不允许重复,重复会覆盖旧值),Value可重复; - 定位
Value需通过Key(类似 “字典查字”,Key 是 “字”,Value 是 “释义”); - 核心方法:
put(Key, Value)(存)、get(Key)(取)、containsKey(Key)(判断键是否存在)。
该接口主要有五个实现类:HashMap、TreeMap、LinkedHashMap、ConcurrentHashMap、HashTable
| 实现类 | 底层结构 | 核心特点 | 线程安全? | 适用场景 |
|---|---|---|---|---|
| HashMap | 哈希表(数组 + 链表 / 红黑树) | 无序、查询 / 存值效率高(O (1)) | 否 | 单线程下,无需排序的键值对存储(如存用户 ID - 用户信息) |
| TreeMap | 红黑树 | 按 Key 自然顺序 / 自定义顺序排序 | 否 | 需要按 Key 排序的键值对(如按日期存日志) |
| LinkedHashMap | 哈希表+双链表 | 按插入顺序排序 | 否 | 需保留顺序的键值对(如 LRU 缓存) |
| ConcurrentHashMap | 哈希表(分段锁 / CAS) | 线程安全,效率比 Hashtable 高 | 是 | 多线程场景(如并发环境下的缓存) |
| Hashtable | 哈希表 | 线程安全(全表锁),已过时 | 是 | 不推荐,用 ConcurrentHashMap 替代 |
HashMap:
public class HashMapDemo {public static void main(String[] args) {// 1. 创建HashMap(存用户ID→用户姓名,Key是Integer,Value是String)Map<Integer, String> userIdToName = new HashMap<>();// 2. 核心操作:存(put)、取(get)、改(put覆盖)、删(remove)、判断Key存在userIdToName.put(101, "张三"); // 存键值对userIdToName.put(102, "李四");userIdToName.put(101, "张三三"); // Key重复,覆盖原ValueSystem.out.println("用户映射:" + userIdToName); // 输出(顺序不固定):{101=张三三, 102=李四}String userName = userIdToName.get(102); // 按Key取ValueSystem.out.println("用户102的姓名:" + userName); // 输出:李四boolean hasUserId = userIdToName.containsKey(103); // 判断Key是否存在System.out.println("是否有用户103:" + hasUserId); // 输出:false// 3. 遍历(推荐entrySet,一次取Key和Value)System.out.println("遍历用户:");for (Map.Entry<Integer, String> entry : userIdToName.entrySet()) {Integer id = entry.getKey();String name = entry.getValue();System.out.println("用户ID:" + id + ",姓名:" + name);}}
}TreeMap:
public class TreeMapDemo {public static void main(String[] args) {// 1. 创建TreeMap(存学生成绩,按Key(学号)自然排序)Map<String, Integer> studentScore = new TreeMap<>();// 2. 核心操作:put(按Key排序)studentScore.put("2024003", 95);studentScore.put("2024001", 88);studentScore.put("2024002", 92);System.out.println("学生成绩(按学号排序):" + studentScore); // 输出:{2024001=88, 2024002=92, 2024003=95}// 3. 遍历(按Key顺序)System.out.println("遍历学生成绩:");for (Map.Entry<String, Integer> entry : studentScore.entrySet()) {System.out.println("学号:" + entry.getKey() + ",成绩:" + entry.getValue());// 输出: 学号:2024001,成绩:88// 学号:2024002,成绩:92// 学号:2024003,成绩:95}}
}四、集合常见问题
以上是对常用集合基本的介绍,下面是集合中常见的常见的问题
1、集合遍历
1、Collection和Collections的区别
Collection是Java集合框架的接口,它是所有集合类的基础接口,它定义了一组通用的操作方法,如添加和删除遍历等。Collection有很多实现类,如List、Set、Queue等
Collections是Java提供的一个工具类,在java.util包中,它提供了一些静态方法,用于对集合进行操作和一些算法,包括排序,查找,替换、反转、随机化等。这些可以对实现了Collection接口的集合进行操作,如List和Set
2、集合遍历的方法
这里列举常用的三种方法:
1、普通for循环:可以使用带有索引的普通 for 循环来遍历 List。
适用场景:List 集合需按索引操作(如反向遍历、修改元素)
List<String> list = new ArrayList<>(Arrays.asList("A", "B", "C"));// 正向遍历
for (int i = 0; i < list.size(); i++) {System.out.println(list.get(i)); // 输出:A → B → C
}// 反向遍历(普通 for 循环优势)
for (int i = list.size() - 1; i >= 0; i--) {System.out.println(list.get(i)); // 输出:C → B → A
}2、增强for循环(最常用)
原理:基于迭代器(Iterator)实现,语法简化,无需手动处理索引或迭代器操作
缺点:遍历中不能修改集合结构(如 add/remove,会抛 ConcurrentModificationException)。
适用场景:仅需读取元素,不修改集合。
// List 示例
List<String> list = new ArrayList<>(Arrays.asList("A", "B", "C"));
for (String elem : list) {System.out.println(elem); // 输出:A → B → C
}// Set 示例(无索引,增强 for 是首选)
Set<Integer> set = new HashSet<>(Arrays.asList(1, 2, 3));
for (Integer num : set) {System.out.println(num); // 输出顺序不固定(HashSet 无序)
}3、Iterator迭代器遍历
原理:Collection 接口的 iterator() 方法返回迭代器,通过 hasNext()(判断是否有下一个元素)和 next()(获取下一个元素)遍历。
适用场景:遍历中需要删除元素。
List<String> list = new ArrayList<>(Arrays.asList("A", "B", "C"));
Iterator<String> iterator = list.iterator();while (iterator.hasNext()) {String elem = iterator.next(); // 必须先调用 next(),再调用 remove()if ("B".equals(elem)) {iterator.remove(); // 安全删除,不会抛异常}System.out.println(elem); // 输出:A → B → C
}
System.out.println("删除后 list:" + list); // 输出:[A, C]4、使用forEach方法
forEach 是 Java 8 引入的增强遍历方法,支持通过 lambda 表达式实现函数式编程风格的遍历
过程如下:
- 遍历
list中的每个元素(顺序与List一致,如ArrayList按插入顺序); - 把每个元素作为参数,传递给后面的 “处理逻辑”;
- 最终执行
System.out.println(元素),实现打印效果。
// 示例:遍历 List
List<String> list = Arrays.asList("A", "B", "C");
list.forEach(elem -> System.out.println(elem)); // 输出:A → B → C
list.forEach(System.out::println);//这种写法也可以,方法引用// 示例:遍历 Set
Set<Integer> set = new HashSet<>(Arrays.asList(1, 2, 3));
set.forEach(num -> System.out.println(num)); // 输出:1 → 2 → 3(HashSet 顺序不固定)2、List
1、ArrayList的LinkedList的区别,
- 底层数据结构:ArrayList是数组实现,LinkedList内部使用双链表实现
- 随机访问效率:ArrayList是数组实现,底层空间是连续的,随机访问效率高;LinkedList 低
- 增加和删除效率:ArrayList需要移动元素,效率低;LinkedList直接改变指针指向,效率高
- 空间占用:ArrayList只存储元素,占空间较小;LinkedList除了本身数据,还有前后指针,大
- 使用场景:ArrayList适合频繁随机访问场景;LinkedList适合频繁插入或删除的操作
2、ArrayList和LinkedList的线程安全吗,如何保证线程安全?
不安全
在高并发场景下:
1、数据不一致问题
如add,代码简化如下:
public boolean add(E e) {ensureCapacityInternal(size + 1); // 确定是否需要扩容elementData[size++] = e;return true;}假设此时size为5,线程A和B同时进行add操作,当线程A执行set 语句后,还没来得及执行size++,CPU让出执行权,线程B也执行set语句,此时会将线程A set的值给覆盖掉,但是线程A和B在此之后都会执行size++,所以size实际上是7,但两个线程实际上只操作了size=6时的值,造成了size=7的值是null,
2、数组索引越界异常
还是刚才的例子,假设此时size=6,容量为7时需要扩容。线程A经过扩容函数那里发现size=6,不需要扩容,cpu让出执行权,线程B也经过扩容那里,size=6也不需要扩容,这时候的数组容量就是7,线程A set完以后 size++,此时size=7;此时线程B在来set数据时便会出错,因为size=7,数组的大小也是7,所以线程B设置的下标索引为7的就会越界(因为数组下标索引从0开始)
3、扩容时的并发问题
如果一个线程在扩容,而另外一个线程还试图访问未完全复制的数据,可能会抛出ArrayIndexOutOfBoundsException或NullPointerException异常
如何保证线程安全:
1、使用Collections类中的synchronizedList方法将ArrayList包装成线程安全的List
List<String> synchronizedList = Collections.synchronizedList(arrayList);2、使用CopyOnWriteArrayList类替代ArrayList,它是一个线程安全的实现
它的原理是在写入操作(如 add、remove)时,会先复制一份原数组,在新数组上进行操作,操作完成后再将新数组赋值给原数组引用。读取操作则直接从原数组进行,由于读操作不需要加锁,所以读性能较高,适合读多写少的场景。
CopyOnWriteArrayList<String> copyOnWriteArrayList = new CopyOnWriteArrayList<>(arrayList);3、使用Vector类代替ArrayList,Vector是线程安全的List实现
Vector<String> vector = new Vector<>(arrayList);3、ArrayList的扩容机制
ArrayList 基于动态数组实现,默认初始容量为 10。添加元素时,若当前元素个数(size)加 1 超过数组容量,会触发扩容:
先计算新容量(原容量增加一半,即1.5倍原容量),若 新容量小于所需最小容量 则 取最小容量,再检查是否超过最大数组大小(超过则调整为 Integer.MAX_VALUE 或指定最大值),最后通过 Arrays.copyOf 复制原数组元素到新数组完成扩容。
新容量小于所需最小容量 则 取最小容量:如果是通过 addAll 一次性添加多个元素(比如当前容量 10,要添加 6 个元素,minCapacity = 10 + 6 = 16),此时默认扩容后的 15 小于 16,就会将新容量直接设为 16,确保能容纳所有新增元素。
3、Map
1、HashMap的实现原理
HashMap是基于数组 + 链表/红黑树来实现的(红黑树优化是jdk1.8以后才加上的)
底层结构是Node[] table(哈希数组),每个Node存储K-V键值对以及next指针(用于处理哈希冲突)
当桶中的链表长度 > 8 且数组容量 >=64时,桶中的链表会转化为红黑树(查询复杂度从o(N)变为O(logN),避免链表过长导致性能退化);同时当红黑树节点数<6时,会再转为链表
2、什么是哈希冲突,以及解决办法
哈希算法是将key通过算法映射到哈希桶中固定的索引,但不同key可能通过哈希运算得到相同的索引,这种现象叫做哈希冲突
主要下面两种方法:
- 链地址法(拉链法):这是hashmap的核心方法,当发生冲突时,将相同索引的Node以链表的形式串联,后续查询时遍历该索引下的链表/红黑树即可找到目标key
- 开放地址法:当冲突发生时,通过固定规则(如线性探测、二次探测)寻找数组中下一个空闲的位置存储数据
3、HashMap是线程安全的嘛?
不安全
1、数据覆盖:如两个线程同时执行put操作,若对同一索引的node修改,可能导致后写入的数据覆盖先写入的数据
因此,HashMap仅适用于单线程或无并发修改的场景,高并发场景需使用ConcurrentHashMap或通过Collections.synchronizedMap(new HashMap<>())包装(性能较低)
2、红黑树插入或删除进行旋转操作时,多线程情况下会造成结构混乱
3、jdk1.7以前由于采用数组+链表,且链表插入是头插,可能会造成链表死循环问题;而jdk1.8的链表采用了尾插法,不会再造成死循环了。
4、HashMap的put过程
整体流程是:定位索引——> 处理冲突 ——> 插入数据 ——>判断扩容
- 通过计算key的哈希值,定位到对应的索引
- 若索引位置为null,注解新建Node并插入到该位置
- 若不为null(发生冲突):1、若该Node是红黑树结点,则调用红黑树的insert方法插入结点
- 若该Node是链表,则直接尾插链表并判断链表长度是否大于8,若超过且数组长度>64, 则将链表转化为红黑树
- 判断扩容:插入完成后,若size超过 负载值(table.length × loadFactor),则进行扩容
5、HashMap的扩容机制
- 计算新容量:若原数组为0(未初始化),则新容量设为默认容量16;若已经初始化,则新容量设为设为 旧容量的2倍
- 创建新容量大小的数组
- 遍历原来的table数组,将其中每个键值对重新计算哈希码 并映射到新数组中
- 更新HashMap的数组引用,以及容量大小,完成扩容
6、ConcurrentHashMap是怎么实现的,线程安全嘛(详细介绍ConcurrentHashMap的内部实现原理)
在 JDK 1.7 中它使用的是数组加链表的形式实现的,而数组又分为:大数组 Segment 和小数组 HashEntry。
Segment 是一种可重入锁(ReentrantLock),在 ConcurrentHashMap 里扮演锁的角色;HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组,一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个Node类型链表结构的元素。
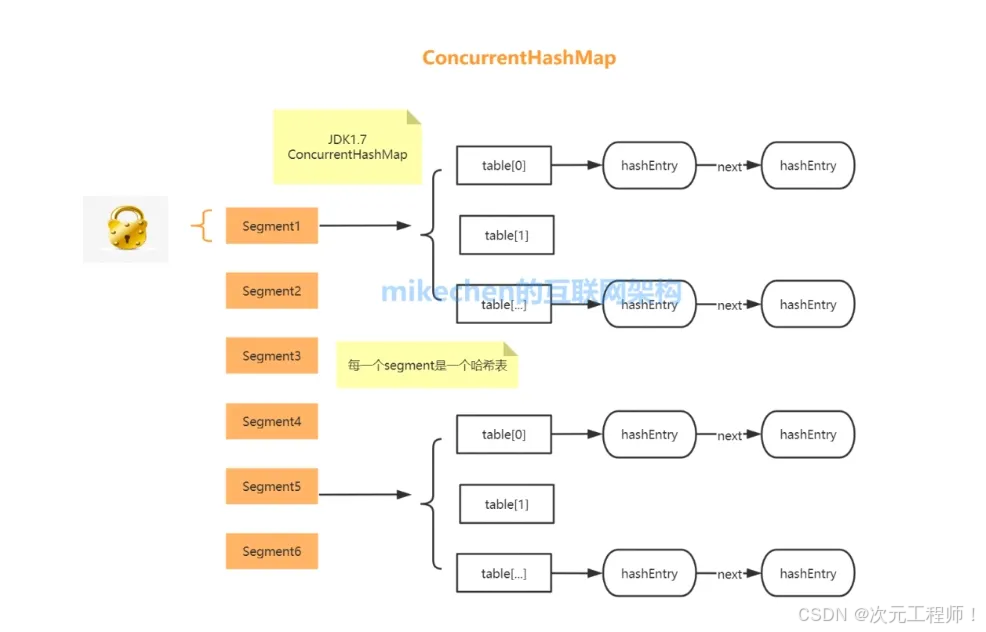
图片来源于网络
我们可以看到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作。
第一次Hash,定位到Segment;第二次Hash,定位到元素所在的链表的头部。
这样有好处也有坏处
好处:
写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上)。
坏处:
这一种结构的带来的副作用是Hash的过程要比普通的HashMap时间要长
在JDK1.8中,其内部结构发生了变化,参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,如下图所示:

ConcurrentHashMap摒弃了JDK 1.7的 “分段锁(Segment)” 机制,采用了“CAS+synchronized”实现更细粒度的锁,底层结构和HashMap类似,核心优化点:
JDK 1.8 的 ConcurrentHashMap,其实是靠 “只锁链表 / 红黑树的头节点” 来保证线程安全的。跟以前的 “分段锁” 比,锁的范围小很多,很少会出现多个线程抢同一把锁的情况,所以并发操作时速度更快。
具体怎么操作元素的呢?分两种情况:
- 如果要往某个位置放元素,先算好这个元素该放在哪个桶里。要是这个桶的位置是空的,就用 CAS 这种 “无锁操作” 直接把元素放进去,不用等锁;
- 要是算出来的桶位置不是空的(已经有元素了),就用 synchronized 把这个桶的 “头节点” 锁上 —— 这样其他线程就改不了这个桶里的内容了。接着遍历桶里的元素:该替换的替换,该加新元素的加,最后再检查桶里元素是不是太多,是否需要改成红黑树。
最后补个开头的小步骤:在加元素之前,还得先看看整个 ConcurrentHashMap 容器是不是空的。要是空的,就用 volatile 保证可见性,再用 CAS 无锁初始化容器,避免多个线程重复初始化。
CAS 是 “Compare-And-Swap”(比较并交换) 的缩写,它是一种并发编程中的原子操作机制。
CAS 负责保证多线程环境下对共享变量的修改是原子性的
它的工作逻辑很简单,包含三个核心参数:
- 内存地址 V:要修改的共享变量在内存中的位置;
- 预期值 A:线程认为当前变量应该有的值(修改前的 “快照”);
- 新值 B:线程想要把变量改成的值。
操作过程:
线程会先检查 “内存地址 V 中的实际值” 是否等于 “预期值 A”:
- 如果相等,说明没人改过这个变量,直接把它改成新值 B;
- 如果不相等,说明变量已经被其他线程改过了,当前线程放弃修改(或重试),不做任何操作。
volatile 是 Java 中的一个关键字,核心作用是保证共享变量在多线程环境下的 “可见性” 和 “有序性”,但不保证原子性
多线程下,CPU 和内存的交互有两个默认优化,会导致线程读不到变量的 “最新值”,volatile 就是用来禁止这些优化的:
-
CPU 缓存导致的 “可见性” 问题
每个线程运行时,会把共享变量从内存 “拷贝” 到自己的 CPU 缓存里操作。如果变量没加volatile,线程改完缓存里的值后,不会立刻同步回内存;其他线程也不会主动从内存刷新最新值,就会出现 “线程 A 改了值,线程 B 却读到老数据” 的情况。
volatile会强制:线程修改变量后,必须立刻把缓存同步回内存;其他线程读变量前,必须先从内存刷新最新值 —— 保证变量对所有线程 “实时可见”。 -
编译器 / CPU 导致的 “有序性” 问题
为了提高效率,编译器或 CPU 会对 “没有依赖关系” 的代码指令重排顺序(比如把int a=1; int b=2;改成int b=2; int a=1;)。单线程下没问题,但多线程下可能错乱:
比如代码逻辑是 “先初始化变量(init=true),再启动线程用变量”,指令重排后可能变成 “先启动线程,再初始化变量”,导致线程拿到未初始化的变量。
volatile会禁止这种重排,保证变量相关的指令 “按代码顺序执行”。
所以初始化ConcurrentHashMap时需要使用volatile和CAS共同保证。
7、HashTable实现原理,是否是线程安全的
1、实现原理:
HashTable是 Java 早期的哈希表实现(JDK 1.0 引入),底层基于数组 + 链表(无红黑树优化)
特点:不允许key或value为null(否则抛出NullPointerException),而HashMap允许key为null(仅 1 个)、value为null。
2、线程安全
线程安全,但并发效率低。HashTable的线程安全是通过在所有public方法上synchronized关键字实现的(如put、get、remove),这意味着:无论线程操作哪个索引的结点,都会锁定整个HashTable对象,导致多线程并发时大量线程阻塞,性能远低于ConcurrentHashMap。
8、ConcurrentMap和HashTable的区别
| 对比维度 | ConcurrentHashMap(JDK 1.8) | HashTable |
|---|---|---|
| 锁粒度 | 局部锁(锁定单个 Node / 红黑树根节点) | 全局锁(锁定整个对象) |
| 并发效率 | 高(多线程可操作不同索引,冲突少) | 低(多线程竞争同一把锁,易阻塞) |
| 底层结构 | 数组 + 链表 / 红黑树(JDK 1.8 优化) | 数组 + 链表(无红黑树优化) |
| 容量与扩容 | 初始容量 16(2 的幂),扩容为 2 倍 | 初始容量 11(非 2 的幂),扩容为 2 倍 + 1 |
| 空值支持 | 允许 value 为 null,不允许 key 为 null | 不允许 key 和 value 为 null |
| 同步机制 | CAS + synchronized + volatile | synchronized(方法级) |
| 适用场景 | 高并发场景(如分布式系统、秒杀业务) | 低并发场景(已逐渐被淘汰) |