层在init中只为创建线性层,forward的对线性层中间加非线性运算。且分层定义是为了把原本一长个代码的初始化和运算放到一个组合中。
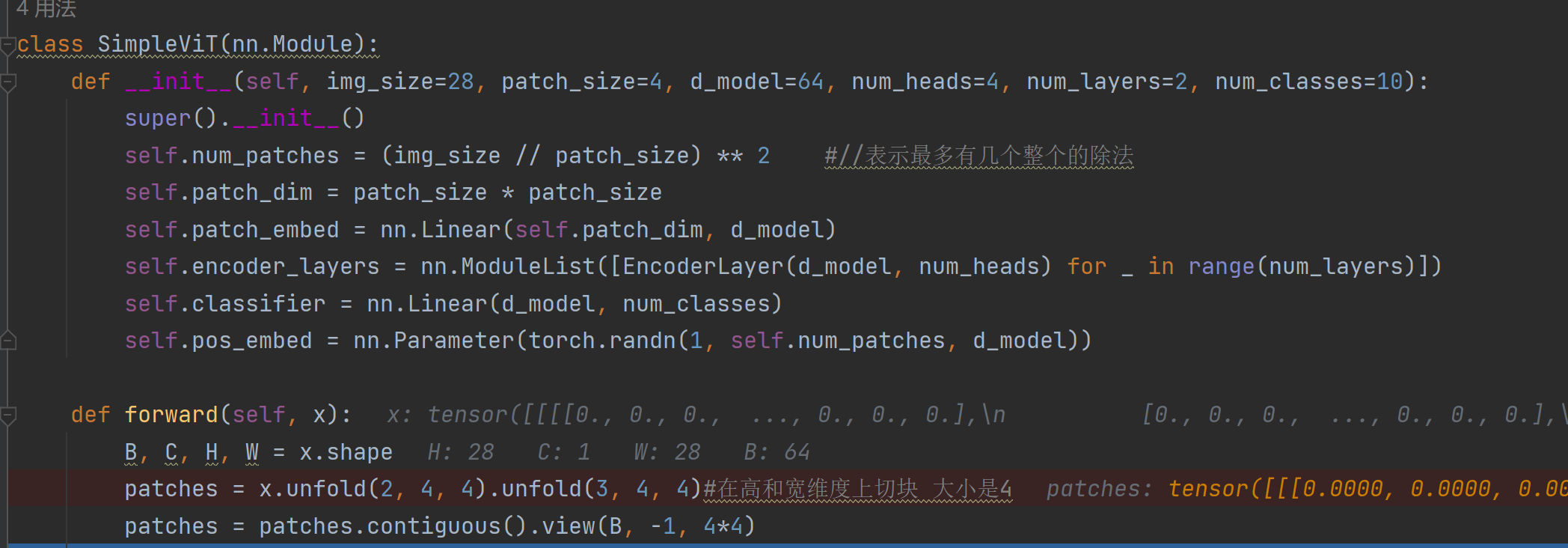
init注意有几个层,这里有四个层,接下来在forward函数中会把这四个层都用上
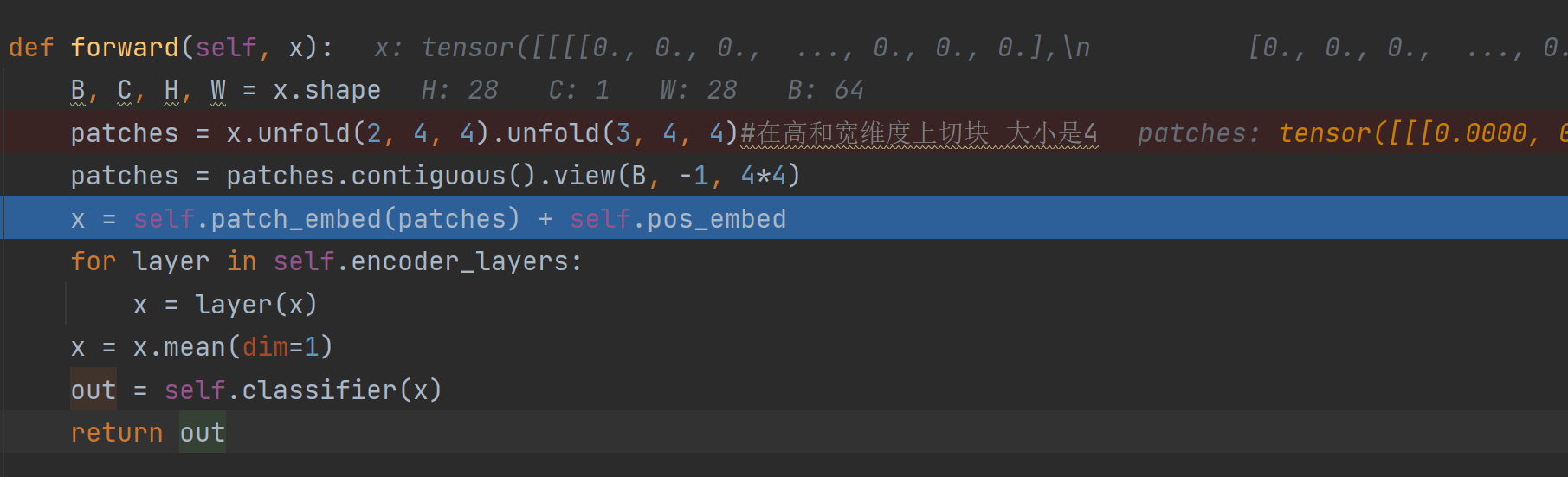
model = SimpleViT().to(device),创建模型的时候,会弄出所有层
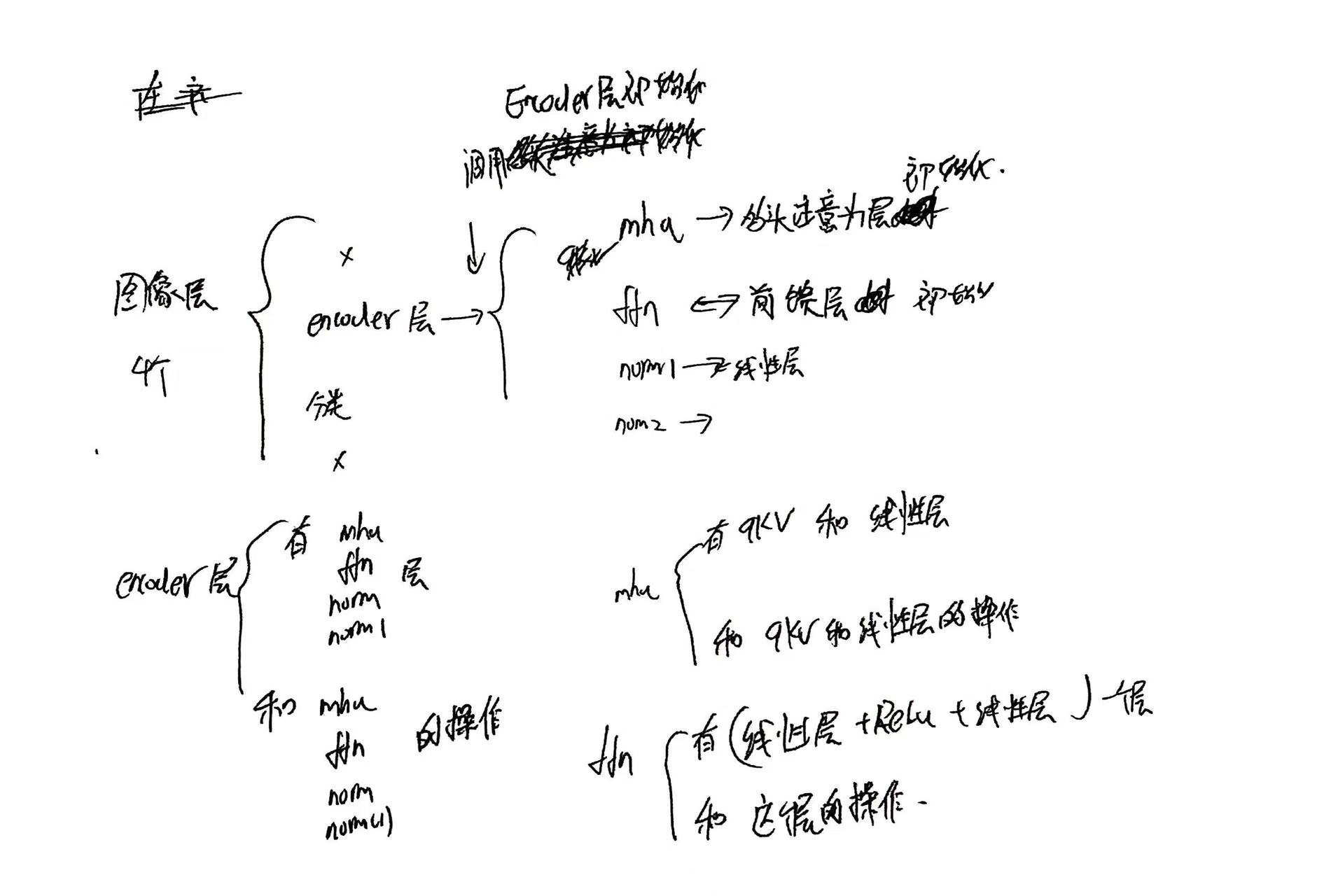
当outputs = model(images),模型被使用的时候才调用各个定义层时的forward函数,调用顺序如下,注意,每个forward都完全使用了这些层,且以mha多头注意力层为例,其中包含把输入变成qkv大矩阵的性层和其他线性层,线性层之间还有其他的非线性操作,会在forward使用,所以forward不是简单的把线形层组合,其中层与层之间的非线性运算就在这里

为什么要定义这么多类和forward函数呢?就是为了把一长串代码中的初始化放到整个类的初始化中,然后操作放到这个类定义的方法中
举例
对于这个类
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()assert d_model % num_heads == 0self.head_dim = d_model // num_headsself.num_heads = num_headsself.qkv = nn.Linear(d_model, d_model * 3)self.out = nn.Linear(d_model, d_model)def forward(self, x, *_):B, seq_len, d_model = x.shapeqkv = self.qkv(x)qkv = qkv.view(B, seq_len, 3, self.num_heads, self.head_dim)q, k, v = qkv.unbind(dim=2)q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)scores = torch.matmul(q, k.transpose(-2, -1)) / (self.head_dim ** 0.5)attn = torch.softmax(scores, dim=-1)context = torch.matmul(attn, v)context = context.transpose(1, 2).reshape(B, seq_len, d_model)return self.out(context)
可以直接使用
mha = MultiHeadAttention(d_model=d_model, num_heads=num_heads)
y_class = mha(x)
这等效为代码,
# 线性层
qkv_linear = nn.Linear(d_model, d_model*3)
out_linear = nn.Linear(d_model, d_model)# ----------------------------
# Multi-Head Attention 流程
# ----------------------------# 1. 线性映射得到 QKV
qkv = qkv_linear(x) # (B, seq_len, 3*d_model)# 2. reshape 成 (B, seq_len, 3, num_heads, head_dim)
qkv = qkv.view(B, seq_len, 3, num_heads, head_dim)# 3. 拆分 q, k, v
q, k, v = qkv.unbind(dim=2) # 每个 (B, seq_len, num_heads, head_dim)# 4. 转置到 (B, num_heads, seq_len, head_dim)
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)# 5. 注意力分数
scores = torch.matmul(q, k.transpose(-2, -1)) / (head_dim ** 0.5) # (B, num_heads, seq_len, seq_len)# 6. softmax 得到注意力权重
attn = torch.softmax(scores, dim=-1)# 7. 加权求和得到上下文
context = torch.matmul(attn, v) # (B, num_heads, seq_len, head_dim)# 8. 转置回 (B, seq_len, num_heads, head_dim)
context = context.transpose(1, 2)# 9. 拼回 d_model
context = context.reshape(B, seq_len, d_model)# 10. 输出线性映射
out = out_linear(context) # (B, seq_len, d_model)