【ElasticSearch实用篇-03】QueryDsl高阶用法以及缓存机制
一,queryDsl高阶用法
上一篇已经完成了es基础数据的查询,接下来主要讲解一下es的高阶查询queryDsl ,es中基本上所有的语法都能通过querydsl来进行代替,在实际开发中也往往用这种方式进行数据的筛选和查询
在学习这篇之前,依旧是需要先来到官网,看一下官网对这个queryDsl的基本使用,首先直接看这个组合过滤器 https://www.elastic.co/guide/cn/elasticsearch/guide/current/combining-filters.html ,queryDsl的高阶语法就是指的对以下几个关键字进行的灵活组合操作:must、should、must_not、filter
1,布尔过滤器
queryDsl指的就是对布尔过滤器的操作,在query内使用bool方式查询,内部通过must、must_not、should三种方式实现,这三个内部包含的都是数组,里面就是一些基本的查询构造。这三个也不是说必须同时出现,可以出现一个或者多个。
GET /user/_search
{"query": {"bool": {"must":[],"should":[],"must_not":[],"filter":[]}}
}
接下来用sql来表示一下和这三种对应的关系。
- must对应的就是and,如果子句是全文检索查询类型,比如内部包含有match、multi_match和query_string等子句则会影响打分,如果是纯term、range、exist,那么不会产生打分影响
- should就是可选匹配项,比如生活城市在北京市或者身高180以上,只要满足一个即可,满足两个分会更高
- must_not对应的就是sql的not,必须不满足条件,比如筛选的用户必须不是注销的用户,或者黑名单用户
- filter就是会走缓存的筛选,属于是高性能筛选,如果不涉及到打分,优先考虑使用filter而不是must
| es | sql | 描述 |
|---|---|---|
| must | and | 必须匹配,存在全文检索时也会影响打分 |
| should | or | 可选匹配,匹配越多分越高 |
| must_not | not | 必须不匹配,但不会影响打分 |
| filter | 必须匹配,缓存过滤,不影响打分 |
需要注意的是:在must中,即使子句本身不算分,放在must 中时score也可能不是 1.0,这是因为 bool 查询在内部仍会累加一个固定分值。如果完全不想要打分,推荐改用 filter,查询filter的效率也高于must
接下来分别对这4个关键字进行初步的了解和使用
1.1,must
首先看must。比如遇到一个需求,其内容如下
- 1,老家城市必须满足是 北京市、上海市、广州市、深圳市
- 2,当前必须居住的城市必须是在广州市
- 3,该用户的学历必须是博士
- 4,该用户的身高必选高于180
- 5,改用户的体重需要低于140
GET /user/_search
{"query": {"bool": {"must": [{"terms": { "regCity.keyword": ["北京市","深圳市","上海市","广州市"]}},{"term": { "liveCity.keyword":"广州市"}},{"term": {"eduLevel": 7}},{"range": {"height": {"gte": 180}}},{"range": {"weight": {"lte": 140}}}]}}
}
其对应的java代码如下,代码地址
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 必须满足老家城市是在北京市、上海市、广州市、深圳市
String[] cityArray = {"北京市", "上海市", "广州市", "深圳市"};
boolQueryBuilder.must(QueryBuilders.termsQuery("regCity.keyword", cityArray));
// 必须满足当前生活城市是在广州市
boolQueryBuilder.must(QueryBuilders.termQuery("liveCity.keyword", "广州市"));
// 必须满足用户学历是博士 学历: 3=大专以下,4=大专,5=大学本科,6=硕士,7=博士
boolQueryBuilder.must(QueryBuilders.termQuery("eduLevel", 7));
// 必须满足用户用户身高大于180
boolQueryBuilder.must(QueryBuilders.rangeQuery("height").gte(180));
// 必须满足用户体重小于140
boolQueryBuilder.must(QueryBuilders.rangeQuery("weight").lte(140));
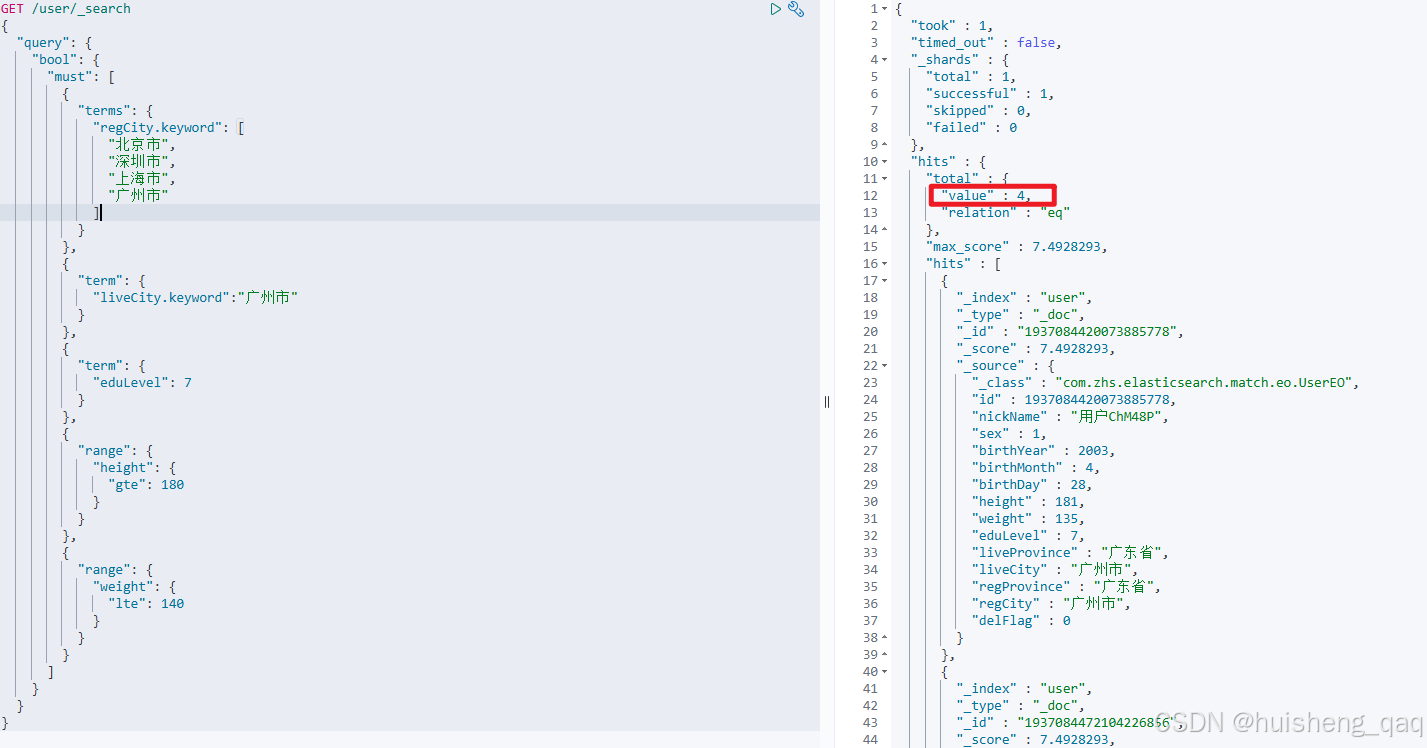
最终过滤出4个优质用户,这里面有男有女,性别暂时未做处理。并且可以发现score字段虽然未有显示的打分操作,但是现在的分数已经超过了默认分数1.0,说明must确实会影响打分,并且会随着命中条件的个数增多其分数也会增加
1.2,should
接下来讲解一下should,依旧是通过需求来描述should的使用,其需求如下
- 1,查找出生年为2002-2003区间段得到用户
- 2,查找学历为硕士或者博士学历的用户
- 3,查找身高为180-185区间段的用户
其sql如下,根据should的特性,其本质就相当于mysql的or,所以上面上个需求其实也是or的关系,只需要满足一个或者多个即可。可以通过 minimum_should_match 这个参数来指定至少需要满足的个数,如下面至少满足两个
GET /user/_search
{"from":0,"size":5,"query": {"bool": {"should": [{"range": {"birthYear": {"gte": 2002,"lte": 2003}}},{"range": {"eduLevel": {"gte": 6,"lte": 7}}},{"range": {"height": {"gte": 180,"lte": 185}}}],"minimum_should_match": 2}}
}
对应的java代码如下,代码地址
// 构建should查询方式
BoolQueryBuilder buildShouldQuery = QueryBuilders.boolQuery()// 生日应该在2002-2003年区间.should(QueryBuilders.rangeQuery("birthYear").gte(2002).lte(2003))// 学历是硕士或者博士.should(QueryBuilders.rangeQuery("eduLevel").gte(6).lte(7))// 身高在180-185 区间.should(QueryBuilders.rangeQuery("height").gte(180).lte(185));
// 执行should,设置最少满足两个条件
boolQueryBuilder.should(buildShouldQuery).minimumShouldMatch(2);
minimum_should_match 的含义是至少需要满足条件的个数,除了个数之外,还可以设置百分比
"minimum_should_match": "80%"
也可以设置动态的百分比,案例如下,其详细解释如下
"minimum_should_match": "2<-25% 9<-3"
- should 子句 = 2 个 → 规则一生效 → 至少 25% ≈ 1 个
- should 子句 = 6 个 → 规则二生效 → 至少 3 个
- should 子句 = 12 个 → 没有更多规则 → 按最后规则 → 至少 3 个
1.3,must_not
接下来讲一下关于must_not的需求,其需求如下
- 1,必须不是被注销或者黑名单用户
- 2,出生年必须不是2000年前的用户
- 3,学历必须不是专科及以下
- 4,体重必须不能大于140
- 5,升高必须不能低于180
GET /user/_search
{"from":0,"size": 5,"query": {"bool": {"must_not": [{"term": {"delFlag": 1}},{"range": {"birthYear": {"lte": 2000}}},{"range": {"eduLevel": {"lte": 4}}},{"range": {"weight": {"gte": 140}}},{"range": {"height": {"lte": 180}}}]}}
}
其对应的java代码如下,代码地址
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 必须不是被注销或者黑名单用户
boolQueryBuilder.mustNot(QueryBuilders.termQuery("delFlag", 1));
// 必须不是00前用户
boolQueryBuilder.mustNot(QueryBuilders.termQuery("birthYear", 2000));
// 学历必须不是专科及一下 学历: 3=大专以下,4=大专,5=大学本科,6=硕士,7=博士
boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("eduLevel").lte(4));
// 体重必须不能大于140
boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("weight").gte(140));
// 身高必须不能低于180
boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("height").lte(180));
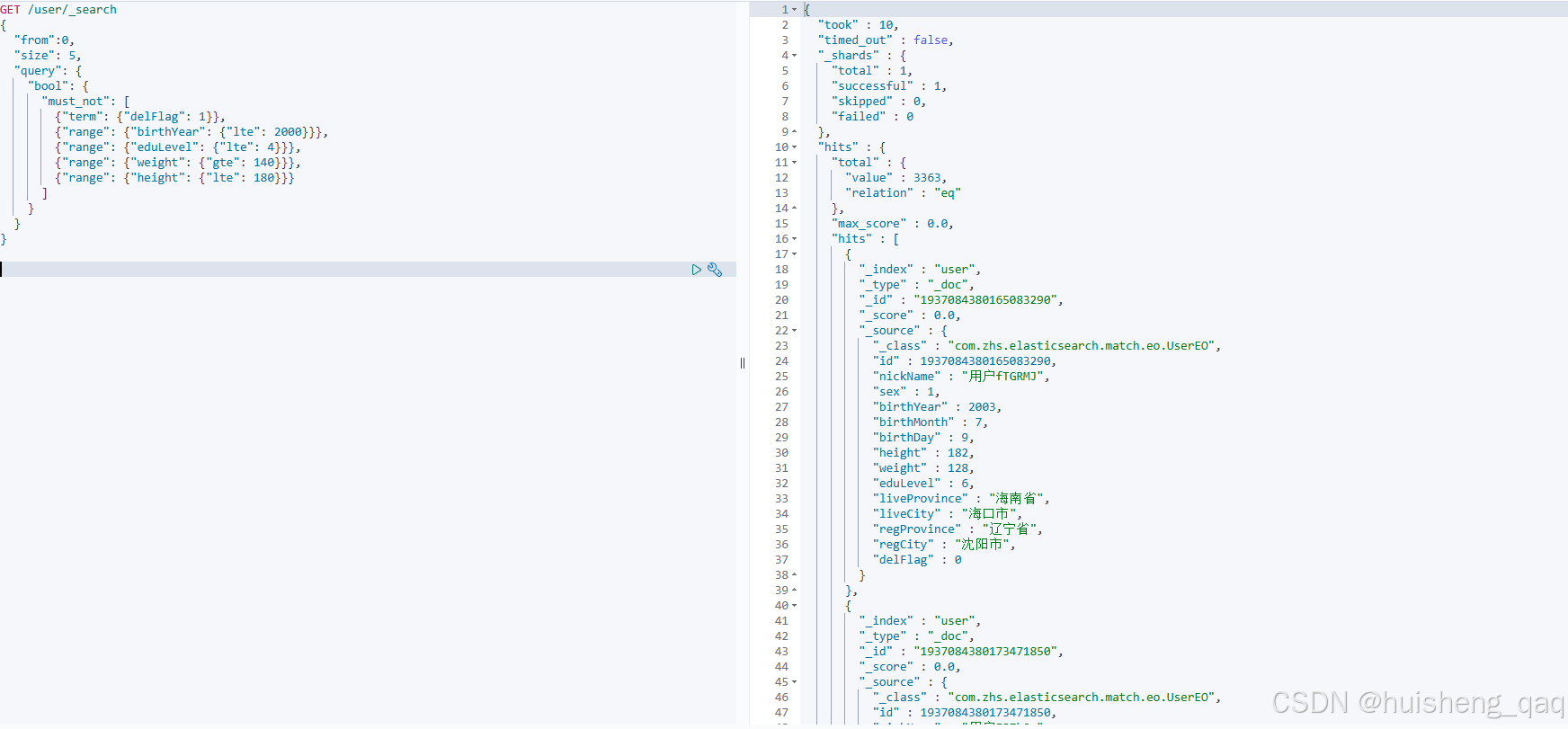
其查询结果如下,也能发现其score都是0,不会因为条件符合的个数影响score分数。
如果能在保证所有字段不为空的情况下,那么must_not会和must以及filter等价,如果产品给的需求以及明确了哪些字段给的哪些具体的规则,那么更加推荐使用正向的规则must或者filter
GET /user/_search
{"from":0,"size": 5,"query": {"bool": {"must": [{"term": {"delFlag": 0}},{"range": {"birthYear": {"gt": 2000}}},{"range": {"eduLevel": {"gt": 4}}},{"range": {"weight": {"lt": 140}}},{"range": {"height": {"gt": 180}}}]}}
}
其filter写法如下,就是替换must即可。如果只是做简单推荐不需要任何打分的话,比如没有同城异性这种优先级高的需求,那么就直接不需要打分的filter即可,他内部会有bieset的缓存机制
{"from": 0,"size": 5,"query": {"bool": {"filter": [{ "term": { "delFlag": 0 } },{ "range": { "birthYear": { "gt": 2000 } } },{ "range": { "eduLevel": { "gt": 4 } } },{ "range": { "weight": { "lt": 140 } } },{ "range": { "height": { "gt": 180 } } }]}}
}1.4,filter
接下来谈一下filter的需求,如果不涉及到算分,那么可以将过滤条件优先加入到filter里面。来一个简单需求:
- 1,过滤出正常的用户
- 2,过滤出性别为男的用户
- 3,过滤出学历为本科的用户
- 4,过滤出居住在广州市的用户
- 5,过滤出体重在120-130的用户
- 6,过滤出身高在180-185的用户
GET /user/_search
{"from": 0,"size": 5,"query": {"bool": {"filter": [{"term": {"delFlag": 0}},{"term": {"sex": 1}},{"term": {"eduLevel": "5"}},{"term": {"liveCity.keyword": "广州市"}},{"range": {"weight": {"gte": 120,"lte": 130}}},{"range": {"height": {"gte": 180,"lte": 185}}}]}}
}
其对应的java代码如下,代码地址
// 过滤出正常的用户
boolQueryBuilder.filter(QueryBuilders.termQuery("delFlag", 0));
// 过滤出性别为男的用户
boolQueryBuilder.filter(QueryBuilders.termQuery("sex", 1));
// 过滤出学历为本科的用户
boolQueryBuilder.filter(QueryBuilders.termQuery("eduLevel", 5));
// 过滤出居住在广州市的用户
boolQueryBuilder.filter(QueryBuilders.termQuery("liveCity.keyword", "广州市"));
// 过滤出体重在120-130的用户
boolQueryBuilder.filter(QueryBuilders.rangeQuery("weight").gte(120).lte(130));
// 过滤出身高在180-185的用户
boolQueryBuilder.filter(QueryBuilders.rangeQuery("height").gte(180).lte(185));
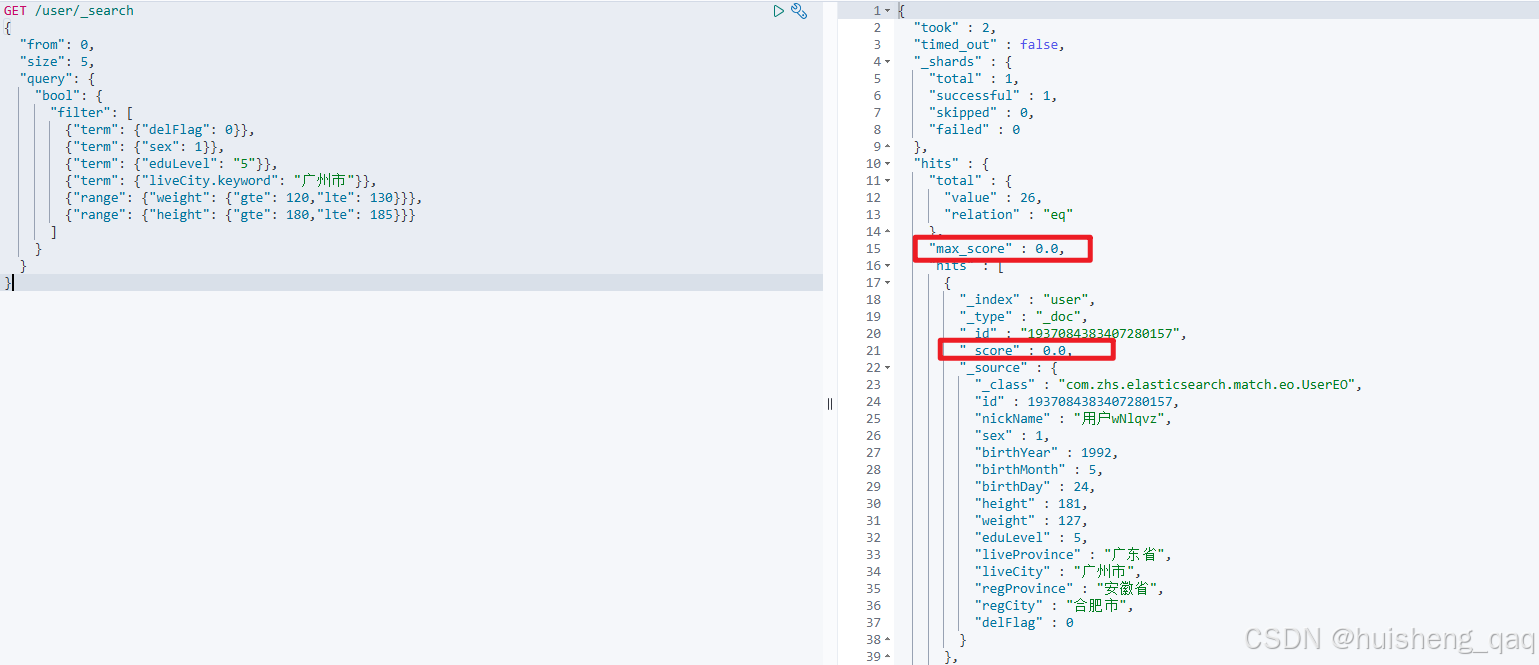
从以下结果来看,filter不参与打分
接下来还是得看一下官网,他的内部缓存设计到底是咋样的,关于缓存的设计
其官网的原话是这样的说的:其核心实际是采用一个 bitset 记录与过滤器匹配的文档。Elasticsearch 积极地把这些 bitset 缓存起来以备随后使用。一旦缓存成功,bitset 可以复用 任何 已使用过的相同过滤器,而无需再次计算整个过滤器 。
并且后面也对缓存进行了优化:如果一个非评分查询在最近的 256 次查询中被使用过(次数取决于查询类型),那么这个查询就会作为缓存的候选。但是,并不是所有的片段都能保证缓存 bitset 。只有那些文档数量超过 10,000 (或超过总文档数量的 3% )才会缓存 bitset 。因为小的片段可以很快的进行搜索和合并,这里缓存的意义不大。 也就是说想要进入这个缓存里面,需要的热点数据,即超过256次查询,并且文档的数量也有一定的限制,这样才能存入到bitset中。缓存的过期规则使用的是LRU的规则,即最少使用次数的被淘汰
1.5,基本子句算分与缓存
接下来通过上面的案例,对常用的子句的缓存和算分进行总结,当然这里的算分只是表明是否会参与上分,算分后续的详情,会在后文输出。
- 首先如果是整个查询只有 term / range ,那么不管是must还是filter都会进入缓存,在filter中不进行算分,在must中本身不进行算分,但是会受到这个 constant_score 累计算分的影响,是的_score可能会稍大于1
- match、multi_match和query_string 三个全文检索类型,不管上下文有一个还是有多个,都会参与算分在must中,但是不会进入缓存,filter默认就是不算分的,所以放到filter不算分
- exists 用于表明字段是否存在,属于filter的类型查询,一次会进入缓存,因为具有filter特性,因此也是不管在哪都不会进行算分。
| 子句类型 | 放在must里 | 放在filter里 | 是否算分 | 是否缓存(bieset) |
|---|---|---|---|---|
| term / range | 不参与算分(会影响) | 不算分 | 否 | 是 |
| match / multi_match | 参与 BM25 算分 | 不算分 | 是 | 否 |
| query_string | 参与 BM25 算分 | 不算分 | 是 | 否 |
| exists | 不参与算分 | 不算分 | 否 | 是 |
1.6,综合应用
如写一个综合应用,其筛选的条件如下
- 1,必须满足是男性,用户是正常用户,不能是注销用户或者黑名单用户
- 2,需要满足这个用户是生活在北京市或者身高在180以上,上面两个条件至少需要满足一个
- 3,筛选的用户学历不能低于本科,体重不能超过140
- 4,过滤出生日再2000年后出生的用户,并且老家必须是一线城市,即北上广深
在深入的了解了上面的四个基本语法的使用之后,接下来处理这个需求,同时使用这四个关键字来配合使用
GET /user/_search
{"query": {"bool": {"must": [{"term": {"sex": 1}},{"term": {"delFlag": 0}}],"should": [{"term": {"liveCity": "北京市"}},{"range": {"height": {"gte": 180}}}], "must_not": [{"range": {"eduLevel": {"lte": 4}}},{"range": {"weight": {"gte": 140}}}],"filter": [{"range": {"birthYear": {"gte": 2000}}},{"terms": {"regCity.keyword": ["北京市","上海市","广州市","深圳市"]}}], "minimum_should_match": 1}}
}
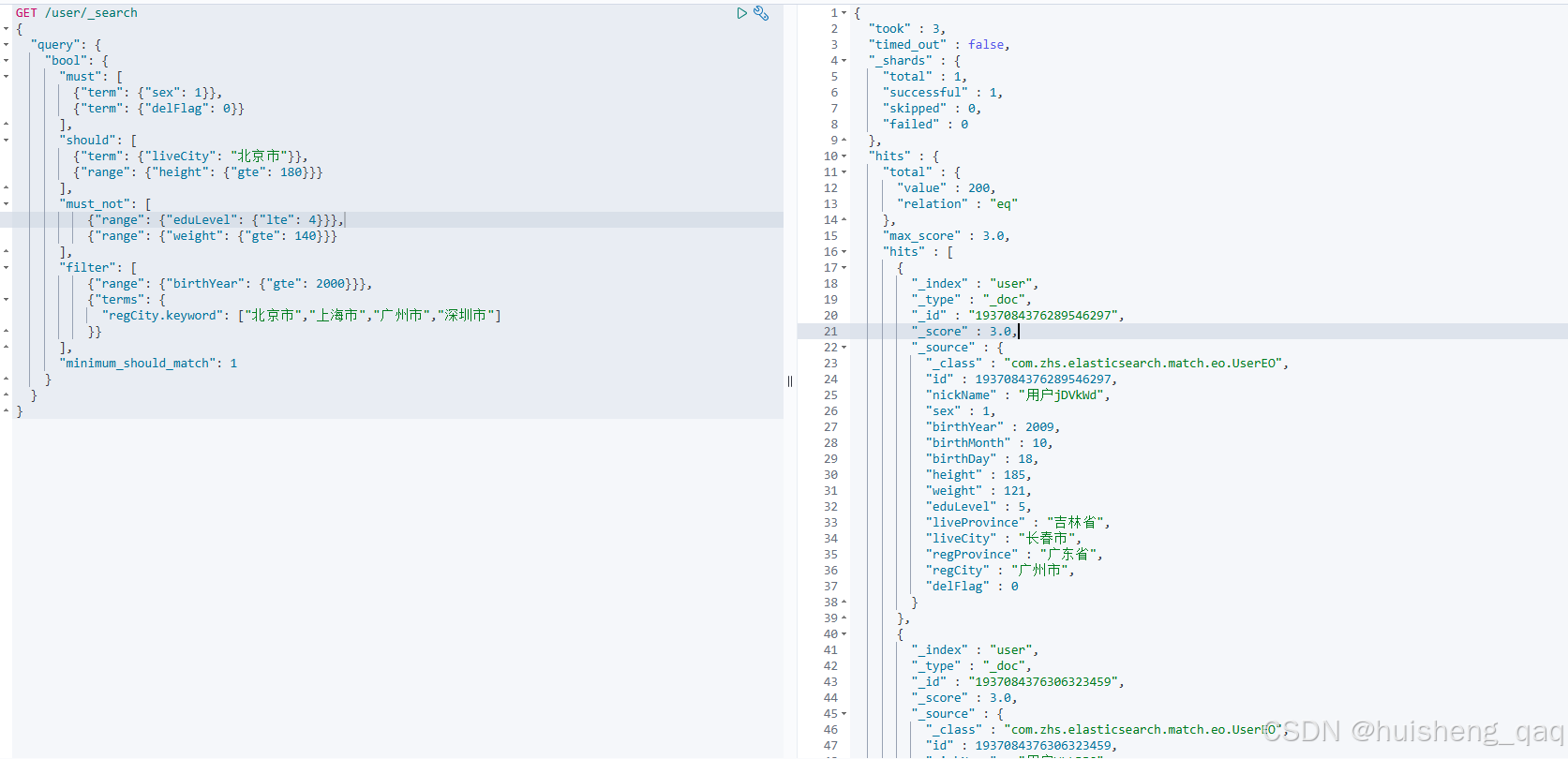
筛选后的结果如下,10万条数据最终筛选出来了200条数据满足
java构建的项目如下,springboot项目,git地址如下:代码地址 ,或者看前两篇文章,有详细写
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 必须满足是男性,用户是正常用户,不能是注销用户或者黑名单用户
boolQueryBuilder.must(QueryBuilders.termQuery("sex", 1));
boolQueryBuilder.must(QueryBuilders.termQuery("delFlag", 0));
// 需要满足这个用户是生活在北京市或者身高在180以上,上面两个条件至少需要满足一个
BoolQueryBuilder buildShouldQuery = QueryBuilders.boolQuery().should(QueryBuilders.termsQuery("liveCity", "北京市")).should(QueryBuilders.rangeQuery("height").gte(180));
boolQueryBuilder.should(buildShouldQuery).minimumShouldMatch(1);
// 筛选的用户学历不能低于本科,体重不能超过140
boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("eduLevel").lte(4));
boolQueryBuilder.mustNot(QueryBuilders.rangeQuery("weight").gte(140));
// 过滤出生日再2000年后出生的用户,并且老家必须是一线城市,即北上广深
boolQueryBuilder.filter(QueryBuilders.rangeQuery("birthYear").gte(2000));
String []cityArray = {"北京市","上海市","广州市","深圳市"};
boolQueryBuilder.filter(QueryBuilders.termsQuery("regCity.keyword", cityArray));