[论文阅读] 人工智能 + 软件工程 | 从用户需求到产品迭代:特征请求研究的全景解析
从用户需求到产品迭代:特征请求研究的全景解析
论文信息
- 原标题:Feature Request Analysis and Processing: Tasks, Techniques, and Trends
- 主要作者:Feifei Niu, Chuanyi Li, Haosheng Zuo, Jionghan Wu(南京大学);Xin Xia(浙江大学)
- 研究机构:南京大学计算机软件新技术国家重点实验室;浙江大学计算机科学与技术学院
- 引文格式(APA):Niu, F., Li, C., Zuo, H., Wu, J., & Xia, X. (2025). Feature Request Analysis and Processing: Tasks, Techniques, and Trends. In Proceedings of [Conference Title]. ACM, New York, NY, USA.
一段话总结
该论文通过系统综述131项相关研究,全面梳理了软件特征请求(用户提出的新功能或功能增强需求)的分析与处理领域,将研究主题分为12类(如识别、优先级排序、质量审查等),从需求工程视角剖析了各阶段的技术方法,总结了现有工具和数据集,并指出了确保请求质量、优化LLM驱动任务基准等关键挑战与机会,为该领域的研究和实践提供了全景式参考。
思维导图

研究背景
在软件产品的生命周期中,用户的声音往往是产品进化的核心驱动力。例如,当你在应用商店给某款APP留言“希望增加夜间模式”,或在开源项目的Issue区提出“建议优化API响应速度”时,这些内容都属于“特征请求”。
据研究统计,约23.3%的应用评论包含特征请求,而在Twitter等社交平台上,24%的用户评论是对软件功能的需求。这些请求蕴含着用户对产品的真实期待,但它们通常混杂在海量的用户反馈中,形式杂乱(可能是一句吐槽、一段建议,甚至是一个表情包搭配文字)。
传统上,开发者需要手动筛选、理解这些请求,这不仅耗时耗力,还可能遗漏关键信息。例如,某音乐APP曾因未及时处理“离线下载进度显示”的高频请求,导致用户流失。此外,现有研究多聚焦于单一任务(如从评论中提取请求),缺乏对特征请求全生命周期的整体分析——这正是该论文要解决的核心问题。
创新点
- 全景式视角:首次从需求工程全生命周期出发,将特征请求研究划分为12个关键任务,覆盖从识别到代码实施的完整流程。
- LLM技术整合:系统分析了大语言模型(如GPT-4、BERT)在特征请求处理中的应用,包括识别、摘要生成等场景。
- 资源整合:整理了公开工具(如用于评论分类的MARC2.0)和数据集(如包含40,000条增强报告的Bugzilla数据集),为后续研究提供便利。
- 挑战-机会框架:提出了特征请求质量保证、多语言处理等7大未来研究方向,针对性强。
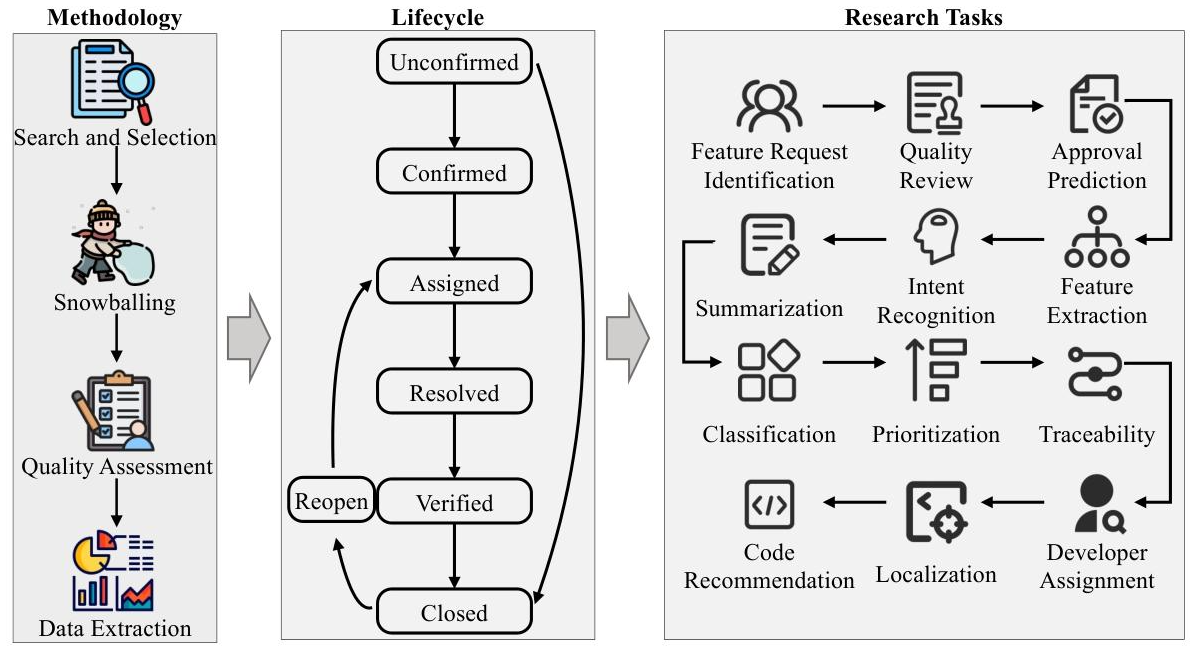
研究方法和思路
论文采用系统文献综述方法,具体步骤如下:
-
确定研究问题:提出4个核心问题(RQ1-RQ4),分别关注研究 demographics、处理方法、可用资源、挑战与机会。
-
文献搜索:
- 数据库:涵盖IEEE Xplore、ACM Digital Library等9个平台。
- 关键词:使用“feature request”“user requirement”等6个关键词组合。
- 初始检索得到17,381篇论文,去重后进入筛选阶段。
-
筛选与评估:
- 纳入标准:英文、2025年8月前发表、聚焦需求工程中的特征请求。
- 排除标准:非软件领域、仅讨论bug报告、技术报告等。
- 经3轮滚雪球法和质量评估(从数据、方法、评估3维度打分),最终保留131篇高质量研究。
-
数据提取:4位作者独立提取文献信息(如发表年份、研究主题、方法等),通过讨论解决分歧。
主要贡献
| 类别 | 具体内容 |
|---|---|
| 研究主题分类 | 将特征请求研究分为12类,其中“特征请求识别”(56篇)、“优先级排序”(17篇)、“质量审查”(17篇)是研究热点 |
| 技术方法总结 | 识别任务中,监督学习(如SVM、BERT)和LLM(如GPT-4)表现突出;优先级排序则结合用户投票、情感分析等多维度指标 |
| 资源整理 | 公开工具15+(如用于代码定位的CHANGEADVISOR)、数据集20+(如包含App评论的Mast数据集) |
| 挑战与机会 | 指出“提升请求质量”“开发LLM基准测试”等关键方向,为未来研究提供路线图 |
关键问题
-
Q:特征请求与bug报告有何区别?
A:特征请求聚焦“新增或增强功能”(如“希望添加指纹登录”),而bug报告关注“现有功能错误”(如“登录按钮点击无反应”)。 -
Q:如何从海量用户反馈中自动识别特征请求?
A:主流方法包括:①基于规则的模式匹配(如识别“希望”“建议”等关键词);②机器学习分类(如用SVM区分请求与普通评论);③LLM提示工程(如让GPT-4直接标注请求内容)。 -
Q:特征请求的优先级是如何确定的?
A:结合用户投票、请求频率、情感倾向(如负面评论中提到的功能)、开发成本等因素,常用方法有Kano模型、AHP层次分析法,以及基于聚类的自动排序。 -
Q:有哪些公开资源可以用于相关研究?
A:工具如LLM-Cure(用于竞品分析)、数据集如Bugzilla增强报告(含40,000条请求)。 -
Q:未来研究的核心挑战是什么?
A:①提升请求质量(减少模糊、冗余内容);②优化LLM在多语言场景的表现;③建立标准化的基准测试数据集。
总结
该论文通过系统梳理131项研究,为软件特征请求的分析与处理提供了全面指南。它不仅分类总结了从识别到代码实施的12大任务及对应技术,还整理了实用工具和数据集,更指出了LLM应用、多语言处理等前沿方向。无论是研究者还是开发者,都能从中获取如何高效将用户需求转化为产品迭代的关键 insights。