C++中的原子操作,自旋锁
目录
C++11 原子操作
什么是原子操作?
std::atomic 变量的定义
std::atomic的成员函数
load() 和 store()
fetch_add() 和 fetch_sub()
exchange()
compare_exchange_strong()
原子操作 vs 互斥锁
原子操作的优点与适用场景
自旋锁
自旋锁是什么?
自旋锁的优/缺点
自旋锁的适用场景
利用C++11的原子操作构建自旋锁
C++11 原子操作
什么是原子操作?
在多线程环境中,如果一个操作在执行过程中不会被其他线程中断,那么这个操作就是原子性的。
想象一下对一个整数进行自增操作 i++。在底层,这通常不是一个原子操作,而是由以下三个步骤组成:
-
从内存中读取
i的值。 -
将值加 1。
-
将新值写回内存。
在单线程中,这没有问题。但在多线程环境中,如果两个线程同时执行 i++,可能会导致数据竞争:
-
线程 A 读取
i(假设为 0)。 -
线程 B 读取
i(也为 0)。 -
线程 A 将值加 1 (现在为 1)。
-
线程 B 将值加 1 (现在也为 1)。
-
线程 A 将 1 写回内存。
-
线程 B 将 1 写回内存。
最终 i 的值变成了 1,而不是我们期望的 2。这就是数据竞争。
原子操作就是为了解决这个问题而生。它保证整个操作(读取、修改、写入)是不可分割的。当一个线程在执行原子操作时,其他线程无法访问该变量。
std::atomic 变量的定义
定义 std::atomic 变量的方法很简单,就像定义普通变量一样,但需要包含 <atomic> 头文件。
1. 使用默认构造函数
默认情况下,原子变量会被初始化为零(对于数值类型)或 false(对于布尔类型)。
#include <atomic>
#include <iostream>int main() {std::atomic<int> counter; // counter 默认初始化为 0std::atomic<bool> is_ready; // is_ready 默认初始化为 falsestd::cout << "counter: " << counter.load() << std::endl;std::cout << "is_ready: " << std::boolalpha << is_ready.load() << std::endl;return 0;
}2. 使用初始化列表或直接初始化
你可以在定义时直接给原子变量一个初始值。
#include <atomic>
#include <iostream>int main() {std::atomic<int> counter{10}; // 使用花括号初始化std::atomic<bool> is_flag(true); // 使用小括号初始化std::cout << "counter: " << counter.load() << std::endl;std::cout << "is_flag: " << std::boolalpha << is_flag.load() << std::endl;return 0;
}
std::atomic的成员函数
C++11 引入了 <atomic> 头文件和 std::atomic 类模板,它允许你以原子方式操作内置类型和用户定义类型。
无锁(Lock-Free):在大多数现代处理器上,原子操作是通过特殊的 CPU 指令(如 lock 指令)实现的,而不是通过操作系统层面的互斥锁。这使得它们比使用 std::mutex 更加高效,尤其是在争用程度较低的情况下。
load() 和 store()
- load():原子地读取原子变量的当前值。
- store():原子地向原子变量写入一个新值。
这两个操作保证了读取和写入的完整性,不会被其他线程的操作打断。
#include <iostream>
#include <atomic>int main() {std::atomic<int> counter(10);// 原子地读取值int value = counter.load(); std::cout << "Initial value: " << value << std::endl; // 输出:Initial value: 10// 原子地写入新值counter.store(20);std::cout << "New value: " << counter.load() << std::endl; // 输出:New value: 20return 0;
}fetch_add() 和 fetch_sub()
fetch_add(T arg):原子地将 arg 加到原子变量上,并返回操作之前的值。
fetch_sub(T arg):原子地将 arg 从原子变量上减去,并返回操作之前的值。
这两个函数非常适合用来实现并发计数器。
#include <iostream>
#include <atomic>int main() {std::atomic<int> counter(0);// 原子地将1加到counter上,并返回操作前的值(0)int old_value = counter.fetch_add(1); std::cout << "Value before add: " << old_value << ", current value: " << counter.load() << std::endl;// 输出:Value before add: 0, current value: 1// 原子地从counter上减去5,并返回操作前的值(1)old_value = counter.fetch_sub(5);std::cout << "Value before sub: " << old_value << ", current value: " << counter.load() << std::endl;// 输出:Value before sub: 1, current value: -4return 0;
}exchange()
exchange(T new_value):原子地用 new_value 替换原子变量的当前值,并返回操作之前的值。
这个函数可以用来实现简单的“交换”逻辑,常用于一些无锁算法中。
#include <iostream>
#include <atomic>int main() {std::atomic<bool> flag(false);// 原子地将flag设置为true,并返回它之前的值(false)bool old_flag = flag.exchange(true); std::cout << "Old flag value: " << std::boolalpha << old_flag << std::endl; // 输出:Old flag value: falsestd::cout << "Current flag value: " << std::boolalpha << flag.load() << std::endl; // 输出:Current flag value: truereturn 0;
}compare_exchange_strong()
compare_exchange_strong(T& expected, T desired):这是原子操作中最复杂但也是最有力的一个函数,被称为比较并交换。
- 它首先比较原子变量的当前值是否等于 expected 的值。
- 如果相等,它会用 desired 的值替换原子变量,并返回 true。
- 如果不相等,它会将原子变量的当前值更新到 expected 中,并返回 false。
这个函数是实现无锁数据结构(如无锁队列、无锁栈)的基石。
#include <iostream>
#include <atomic>int main() {std::atomic<int> shared_value(10);int expected = 10;int desired = 20;// 第一次调用:当前值(10)等于expected(10),所以替换为desired(20),返回trueif (shared_value.compare_exchange_strong(expected, desired)) {std::cout << "Successfully changed value. Current value: " << shared_value.load() << std::endl;// 输出:Successfully changed value. Current value: 20} else {std::cout << "Failed to change value. Current value: " << shared_value.load() << ", expected value is now: " << expected << std::endl;}// 第二次调用:当前值(20)不等于expected(10),所以不会替换,返回false,并将shared_value的当前值(20)赋值给expectedexpected = 10; // 重新设置期望值if (shared_value.compare_exchange_strong(expected, desired)) {std::cout << "Successfully changed value." << std::endl;} else {std::cout << "Failed to change value. Current value: " << shared_value.load() << ", expected value is now: " << expected << std::endl;// 输出:Failed to change value. Current value: 20, expected value is now: 20}return 0;
}原子操作 vs 互斥锁
互斥锁是一种有锁(lock-based)的同步机制。它通过“锁定”临界区来确保同一时间只有一个线程可以访问共享资源。std::lock_guard 是一个 RAII风格的类,用于自动管理互斥锁,确保在作用域结束时自动解锁,即使发生异常也能安全解锁,这可以有效防止死锁。
下面是一个使用 std::mutex 和 std::lock_guard 来对整数变量进行递增操作的例子。
#include <iostream>
#include <thread>
#include <mutex>
#include <vector>int shared_counter = 0;
// 声明一个互斥锁
std::mutex mtx;// 线程函数,对共享变量进行递增
void increment_mutex() {for (int i = 0; i < 10000; ++i) {// 使用 std::lock_guard 锁定互斥锁// 在 lock_guard 对象构造时加锁std::lock_guard<std::mutex> lock(mtx);// 临界区:只有持有锁的线程才能进入shared_counter++; // lock_guard 对象在作用域结束时自动析构并解锁}
}int main() {std::vector<std::thread> threads;// 创建10个线程,每个线程都对 shared_counter 递增10000次for (int i = 0; i < 10; ++i) {threads.emplace_back(increment_mutex);}for (auto& t : threads) {t.join();}// 最终结果是10 * 10000 = 100000std::cout << "Mutex counter final value: " << shared_counter << std::endl;return 0;
}使用原子操作(Atomic Operations)
原子操作是无锁(lock-free)的,它们通过底层硬件指令,来确保操作的不可分割性。这通常比互斥锁的开销小,特别是在竞争不激烈的情况下。
下面是一个使用 std::atomic 来对整数变量进行递增操作的例子,最终实现的效果和上面的
#include <iostream>
#include <thread>
#include <atomic>
#include <vector>// 使用 std::atomic<int> 声明一个原子整数
std::atomic<int> shared_counter(0);// 线程函数,对原子变量进行递增
void increment_atomic() {for (int i = 0; i < 10000; ++i) {// 使用 fetch_add 方法,这是一个原子操作// 它会先获取当前值,然后将其加1,最后将新值写回// 整个过程是不可分割的shared_counter.fetch_add(1);}
}int main() {std::vector<std::thread> threads;// 创建10个线程,每个线程都对 shared_counter 递增10000次for (int i = 0; i < 10; ++i) {threads.emplace_back(increment_atomic);}for (auto& t : threads) {t.join();}// 最终结果是10 * 10000 = 100000std::cout << "Atomic counter final value: " << shared_counter.load() << std::endl;return 0;
}示例分析:
- std::atomic<int> shared_counter(0);:我们使用 std::atomic<int> 模板类来声明一个原子整数。
- shared_counter.fetch_add(1);:这个操作是原子的,它保证了即使多个线程同时调用这个函数,shared_counter 的值也会被正确地、一次一个地递增,不会出现丢失更新(lost update)的问题。
- shared_counter.load():这是一个原子读取操作,用于获取当前原子变量的值。
原子操作的优点与适用场景
1. 对原子变量保护更加简便,不需要额外定义一个互斥锁:在多线程环境中,对一个原子变量的读、写或修改操作是不可中断的。这意味着即使多个线程同时对它进行操作,也不会发生数据竞争,从而保证了数据的正确性和一致性。相比于使用互斥锁(std::mutex),它能更直接、更高效地解决单变量的并发访问问题。使用互斥锁不当可能会导致死锁,原子操作是无锁的,因此天然地避免了这些问题。
2. 高性能(通常是无锁的):大多数原子操作在底层是通过特殊的硬件指令(如CAS,即“比较并交换”)来实现的。这些指令可以确保操作的原子性,而无需操作系统层面的调度或线程切换。这使得原子操作的开销通常比加锁、解锁互斥锁要小得多。在争用较少的情况下,原子变量能提供比互斥锁更高的性能。
原子变量的适用场景
原子变量非常适合以下单变量场景:
-
计数器:这是原子变量最经典的用途。当多个线程需要对一个共享计数器进行增加或减少操作时,使用
std::atomic<int>可以非常高效地实现,例如,统计并发任务的完成数量。
-
标志位(Flag):当一个线程需要通过一个布尔变量来通知另一个线程某个事件发生时,可以使用
std::atomic<bool>。例如,一个线程可以通过设置一个原子布尔变量来告诉另一个线程“可以停止了”。这比使用条件变量(std::condition_variable)更简单、更高效。
总而言之,原子变量是处理单变量并发访问的利器,它以其高效、无锁的特性,让程序更简便,更优雅,当你发现你的并发问题仅仅涉及对一个变量的简单操作时,优先考虑使用原子变量会是一个更好的设计。
自旋锁
自旋锁是什么?
“自旋”可以理解为“自我旋转”,这里的“旋转”指“循环”,比如 while 循环或者 for 循环。“自旋”就是自己在这里不停地循环,直到目标达成。而不像普通的锁那样,如果获取不到锁就进入阻塞。
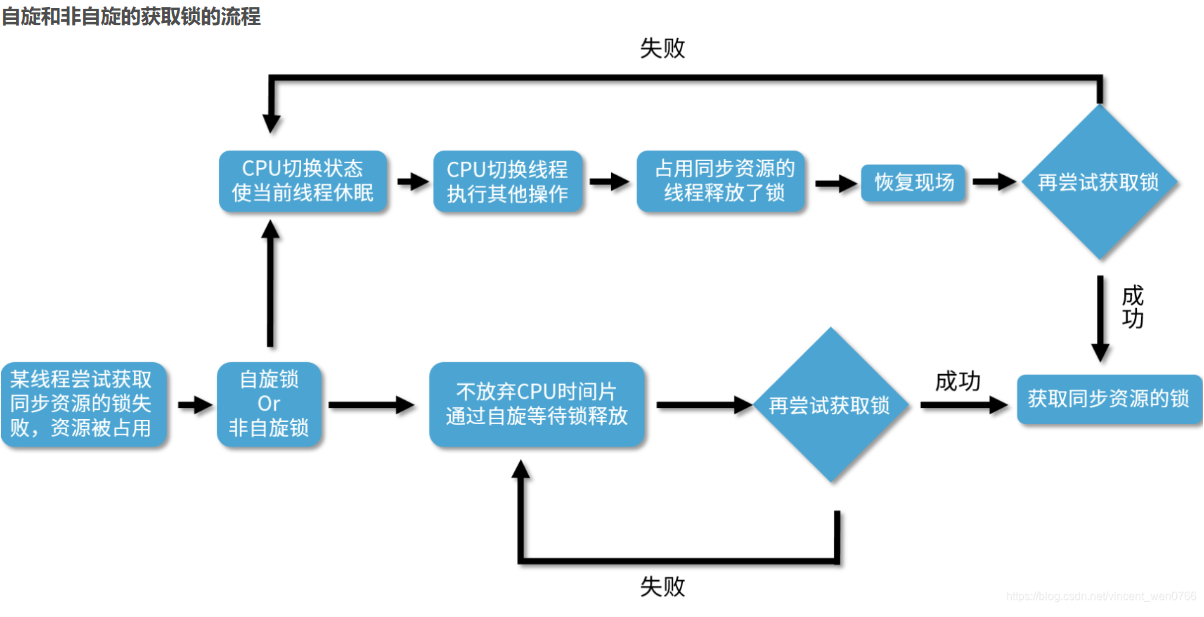
自旋锁,它并不会放弃 CPU 时间片,而是通过自旋等待锁的释放,也就是说,它会不停地再次地尝试获取锁,如果失败就再次尝试,直到成功为止。
非自旋锁,非自旋锁和自旋锁是完全不一样的,如果它发现此时获取不到锁,它就把自己的线程切换状态,让线程休眠,然后 CPU 就可以在这段时间去做很多其他的事情,直到之前持有这把锁的线程释放了锁,于是 CPU 再把之前的线程恢复回来,让这个线程再去尝试获取这把锁。如果再次失败,就再次让线程休眠,如果成功,一样可以成功获取到同步资源的锁。
非自旋锁和自旋锁最大的区别,就是如果它遇到拿不到锁的情况,它会把线程阻塞,直到被唤醒。而自旋锁会不停地尝试。
自旋锁的优/缺点
自旋锁最大的优点在于性能,尤其是在锁被持有的时间非常短的情况下。它的核心优势体现在以下几点:
-
避免上下文切换开销:当一个线程试图获取一个已经被占用的互斥锁时,操作系统通常会暂停(阻塞)这个线程,并进行一次上下文切换,将CPU分配给另一个可以运行的线程。当锁被释放后,操作系统需要再次进行上下文切换,将之前阻塞的线程重新唤醒。上下文切换是一个昂贵的操作,会消耗宝贵的CPU周期。自旋锁则完全避免了这一开销,它让线程持续占用CPU并“自旋”等待,一旦锁可用就立即获取,没有任何切换成本。
-
更低的延迟:由于没有上下文切换,一旦锁被释放,自旋的线程能够立即响应并获取锁,这使得它在短时锁定场景下的延迟极低。
自旋锁最大的缺点就在于虽然避免了线程切换的开销,但是它在避免线程切换开销的同时也带来了新的开销。
因为它需要不停得去尝试获取锁。如果这把锁一直不能被释放,那么这种尝试只是无用的尝试,会白白浪费处理器资源。也就是说,虽然一开始自旋锁的开销低于线程切换,但是随着时间的增加,这种开销也是水涨船高,后期甚至会超过线程切换的开销,得不偿失
自旋锁的适用场景
基于这些优缺点,自旋锁通常用于以下情况:
-
锁的持有时间极短:这是使用自旋锁的关键前提。例如,当你在多核处理器上保护一个简单的计数器或者一个简单的布尔标志时,自旋锁的性能会比互斥锁好得多。
-
需要避免调度开销的内核或系统级编程:在操作系统内核等对性能要求极高的底层编程中,自旋锁是常见的选择。因为在某些内核操作中,线程阻塞是不可接受的。
简单来说,如果你的锁只需被持有几微秒甚至更短的时间,使用自旋锁可能会带来性能提升。但如果锁的持有时间相对较长(比如涉及到文件I/O、网络通信或复杂计算),那么使用互斥锁会让等待线程进入休眠,从而避免浪费CPU资源,是更明智的选择。
利用C++11的原子操作构建自旋锁
C++11标准库没有提供一个现成的自旋锁实现。标准库中只提供了像 std::mutex 这样的互斥锁。
但是,我们可以利用C++11提供的原子操作来实现一个简单的自旋锁。最简单且最常用的方法是使用 std::atomic_flag。
下面是一个使用 std::atomic_flag 实现自旋锁的简单示例。
#include <iostream>
#include <thread>
#include <vector>
#include <atomic>// 自旋锁类
class Spinlock {
private:std::atomic_flag flag = ATOMIC_FLAG_INIT;public:// 获取锁void lock() {// test_and_set() 在设置标志前会返回其旧值。// 如果旧值为 true,说明锁已被占用,线程继续自旋等待。// 当返回 false 时,表示获取到了锁。while (flag.test_and_set(std::memory_order_acquire)) {// 线程在这里自旋,占用CPU}}// 释放锁void unlock() {// 清除标志,允许其他线程获取锁flag.clear(std::memory_order_release);}
};Spinlock spinlock;
int counter = 0;void increment_counter() {for (int i = 0; i < 100000; ++i) {// 在临界区代码前后加上锁和解锁操作spinlock.lock();counter++;spinlock.unlock();}
}int main() {const int num_threads = 10;std::vector<std::thread> threads;for (int i = 0; i < num_threads; ++i) {threads.emplace_back(increment_counter);}for (auto& t : threads) {t.join();}std::cout << "Final counter value: " << counter << std::endl;return 0;
}代码解析
- std::atomic_flag flag = ATOMIC_FLAG_INIT;: 这是声明 std::atomic_flag 并进行初始化的标准方式。它确保标志的初始状态是 false(未上锁)。
- lock() 方法:
- flag.test_and_set(std::memory_order_acquire): 这个调用是自旋锁的核心。它会尝试将 flag 设置为 true,并原子地返回之前的值。
- std::memory_order_acquire: 这是一个内存序(memory order),它确保在获取到锁之后的所有内存访问操作,都会在 test_and_set 之前完成。这对于保证临界区内的代码正确执行至关重要。
- while 循环: 如果 test_and_set 返回 true,说明标志之前就是 true,即锁已经被其他线程持有。当前线程就会进入循环,不断地尝试获取锁,这就是“自旋”的过程。
- flag.test_and_set(std::memory_order_acquire): 这个调用是自旋锁的核心。它会尝试将 flag 设置为 true,并原子地返回之前的值。
- unlock() 方法:
- flag.clear(std::memory_order_release): 这个操作原子地将 flag 设置为 false,释放锁。
- std::memory_order_release: 这是一个内存序,它确保在 clear 操作之前的所有内存访问操作,都会被其他线程在获取锁之后看到。这保证了临界区内的数据修改对其他线程可见。
- flag.clear(std::memory_order_release): 这个操作原子地将 flag 设置为 false,释放锁。
参考文章:
什么是自旋锁?自旋的好处和后果是什么呢?-CSDN博客