基于YOLO11的手机违规使用检测模型训练实战
基于YOLO11的手机违规使用检测模型训练实战
项目背景
在现代社会,手机的普及带来了便利,但在某些场景下(如课堂、会议、驾驶等),手机的不当使用可能造成安全隐患或影响效率。本项目基于深度学习技术,开发了一个能够自动检测手机违规使用行为的智能系统。
技术方案
模型选择
我们选择了YOLO11n作为基础模型,这是YOLO系列的最新版本,具有以下优势:
- 高效性:推理速度快,适合实时检测
- 准确性:在目标检测任务上表现优异
- 轻量化:模型体积小,便于部署
- 易用性:支持多种部署方式,API简洁
算法原理
YOLO(You Only Look Once)是一种单阶段目标检测算法,其核心思想是将目标检测问题转化为回归问题。YOLO11在前代基础上进行了以下改进:
- 网络架构优化:采用更高效的骨干网络
- 损失函数改进:引入DFL(Distribution Focal Loss)
- 数据增强策略:更智能的Mosaic和MixUp
- 后处理优化:改进的NMS算法
环境配置
# 安装依赖
pip install ultralytics
pip install torch torchvision
pip install opencv-python
pip install matplotlib# 验证安装
import ultralytics
print(f"Ultralytics版本: {ultralytics.__version__}")
数据集构建
数据组织结构
data/
├── train/
│ ├── 0_phone/ # 包含手机使用行为的图片
│ │ ├── JPEGImages/ # 原始图片
│ │ ├── labels/ # YOLO格式标注文件
│ │ └── Annotations/ # XML格式标注文件
│ └── 1_no_phone/ # 不包含手机使用行为的图片
└── yolo_dataset/ # 自动生成的训练验证集├── images/└── labels/
数据统计
- 总图片数量:8,201张
- 训练集:6,560张(80%)
- 验证集:1,641张(20%)
- 标注目标数:1,676个手机目标
训练配置
核心参数设置
# 模型配置
model: models/yolo11n.pt
task: detect
mode: train# 训练参数
epochs: 100
batch: 16
imgsz: 640
device: '0' # GPU训练
workers: 4# 数据增强
cache: true
cos_lr: false
close_mosaic: 10# 验证设置
val: true
iou: 0.7
max_det: 300
数据预处理
图像预处理流程
def preprocess_image(image_path, target_size=640):"""图像预处理函数"""import cv2import numpy as np# 读取图像img = cv2.imread(image_path)h, w = img.shape[:2]# 计算缩放比例scale = min(target_size/w, target_size/h)new_w, new_h = int(w*scale), int(h*scale)# 缩放图像img_resized = cv2.resize(img, (new_w, new_h))# 填充到目标尺寸img_padded = np.full((target_size, target_size, 3), 114, dtype=np.uint8)img_padded[:new_h, :new_w] = img_resizedreturn img_padded, scale
标注格式转换
def xml_to_yolo(xml_path, img_width, img_height):"""将XML标注转换为YOLO格式"""import xml.etree.ElementTree as ETtree = ET.parse(xml_path)root = tree.getroot()yolo_annotations = []for obj in root.findall('object'):class_name = obj.find('name').textif class_name == 'phone':class_id = 0bbox = obj.find('bndbox')xmin = float(bbox.find('xmin').text)ymin = float(bbox.find('ymin').text)xmax = float(bbox.find('xmax').text)ymax = float(bbox.find('ymax').text)# 转换为YOLO格式x_center = (xmin + xmax) / 2.0 / img_widthy_center = (ymin + ymax) / 2.0 / img_heightwidth = (xmax - xmin) / img_widthheight = (ymax - ymin) / img_heightyolo_annotations.append(f"{class_id} {x_center} {y_center} {width} {height}")return yolo_annotations
- 图像尺寸:统一调整为640×640像素
- 数据增强:使用YOLO内置的数据增强策略
- 标注格式:YOLO格式(类别ID + 归一化边界框坐标)
模型训练实现
训练脚本核心代码
from ultralytics import YOLO
import os
from datetime import datetimedef train_phone_detection():"""手机检测模型训练主函数"""# 检查GPU可用性import torchdevice = 'cuda' if torch.cuda.is_available() else 'cpu'print(f"使用设备: {device}")# 加载预训练模型model = YOLO('models/yolo11n.pt')# 训练参数配置results = model.train(data='data/data.yaml',epochs=100,imgsz=640,batch=16,device=device,project='phone_results',name=f'yolo11n_phone_{datetime.now().strftime("%Y%m%d_%H%M%S")}',save=True,plots=True,val=True)return resultsif __name__ == '__main__':train_phone_detection()
数据集配置文件
# data.yaml
path: data/yolo_dataset
train: images/train
val: images/valnc: 1 # 类别数量
names: ['phone'] # 类别名称
训练过程与结果
训练进度监控
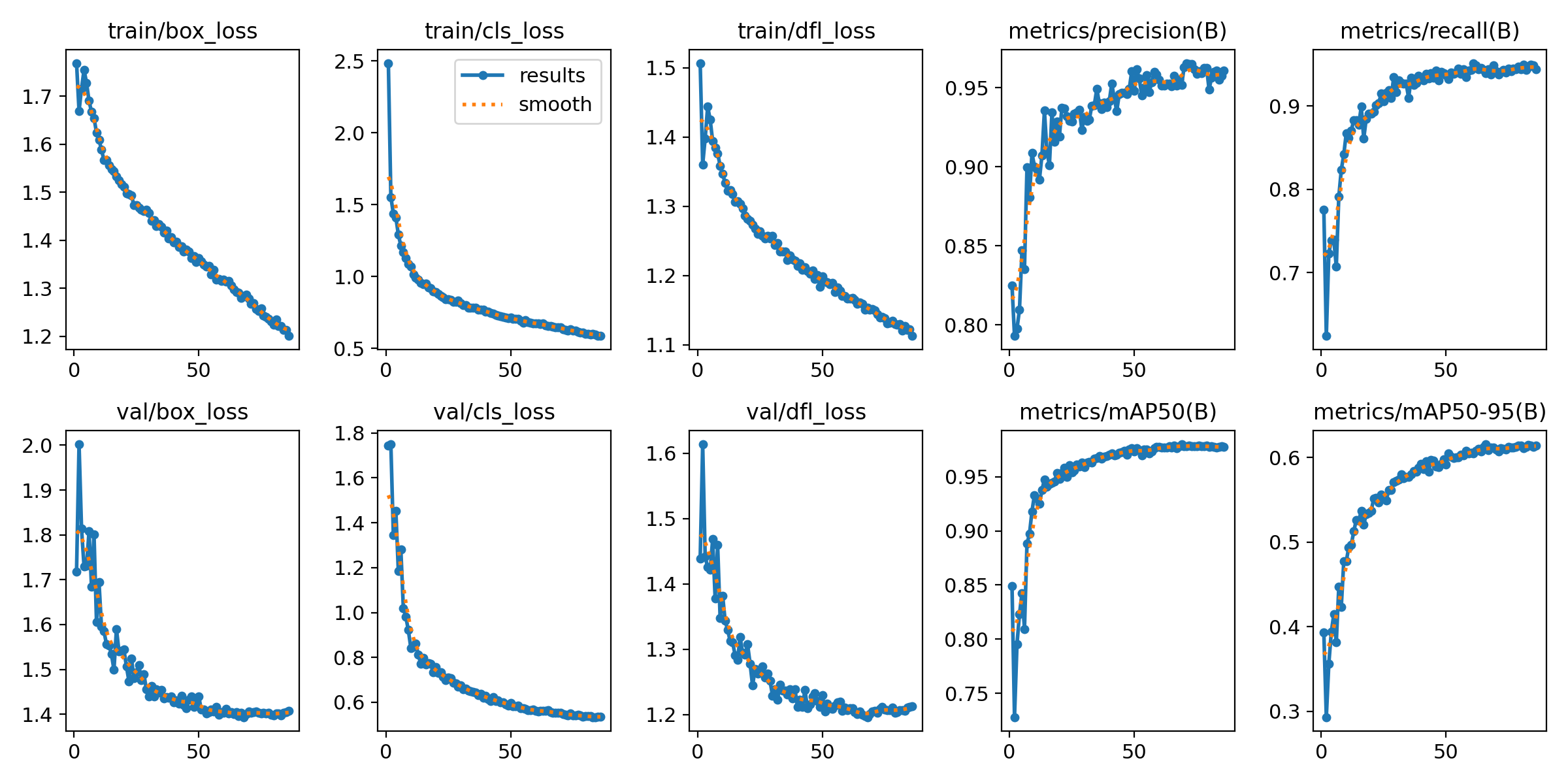
从训练曲线可以看出:
- 损失函数:各项损失(box_loss、cls_loss、dfl_loss)均稳定下降
- 精度指标:mAP50在训练过程中持续提升
- 收敛性:模型在100个epoch内达到良好收敛
关键性能指标
最终训练结果(第100轮)
- Precision(精确率):0.960
- Recall(召回率):0.939
- mAP50:0.976
- mAP50-95:0.598
性能分析
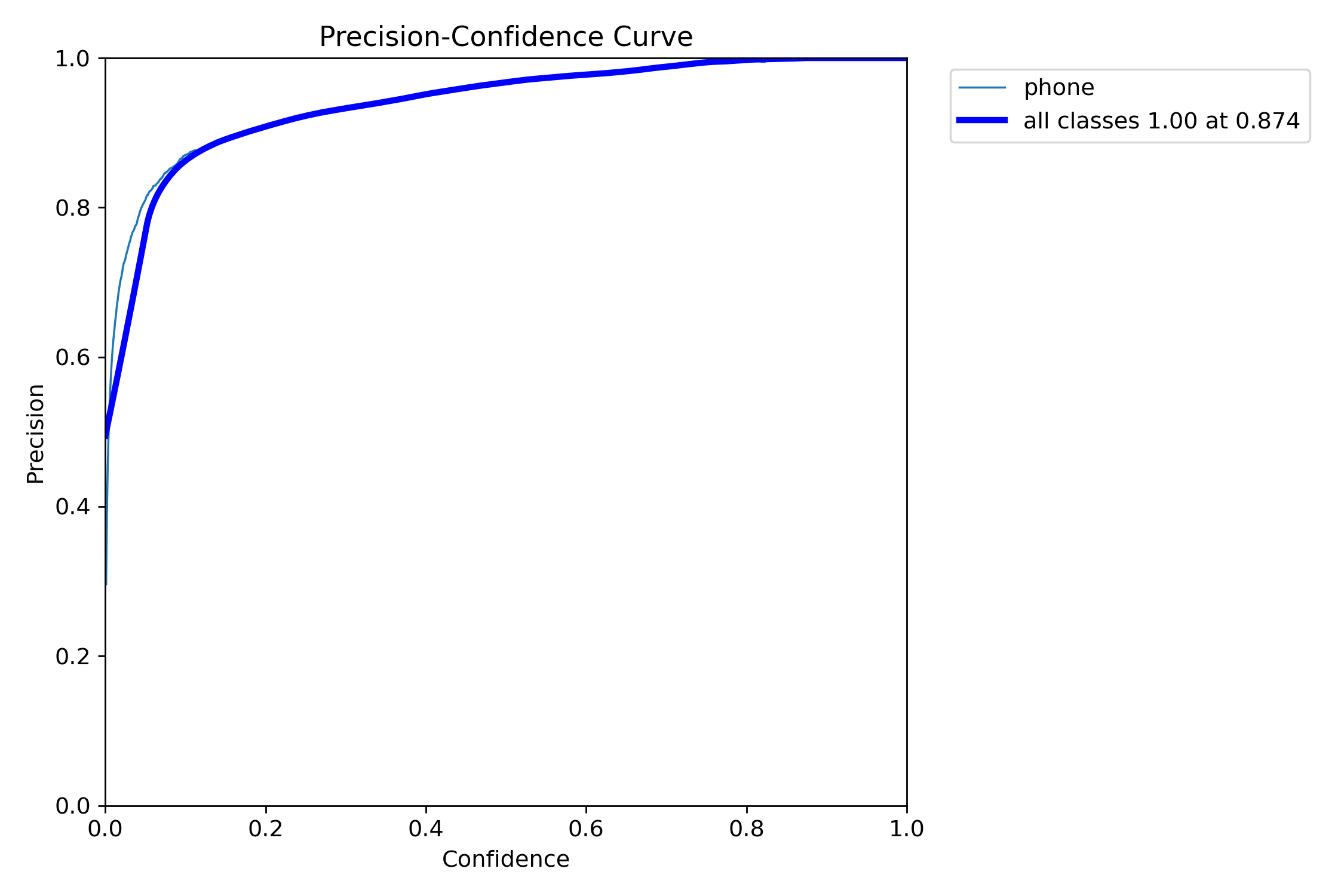
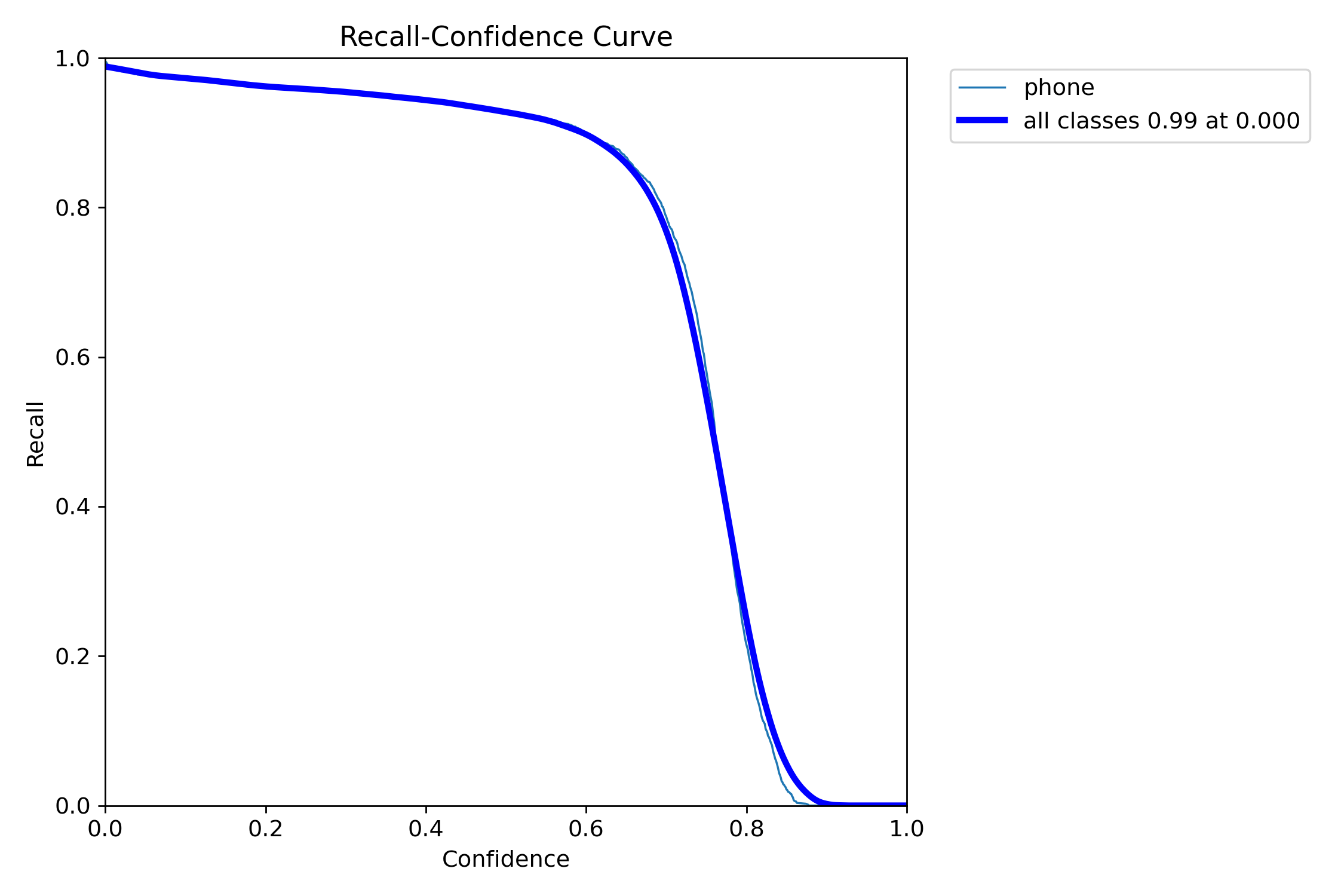
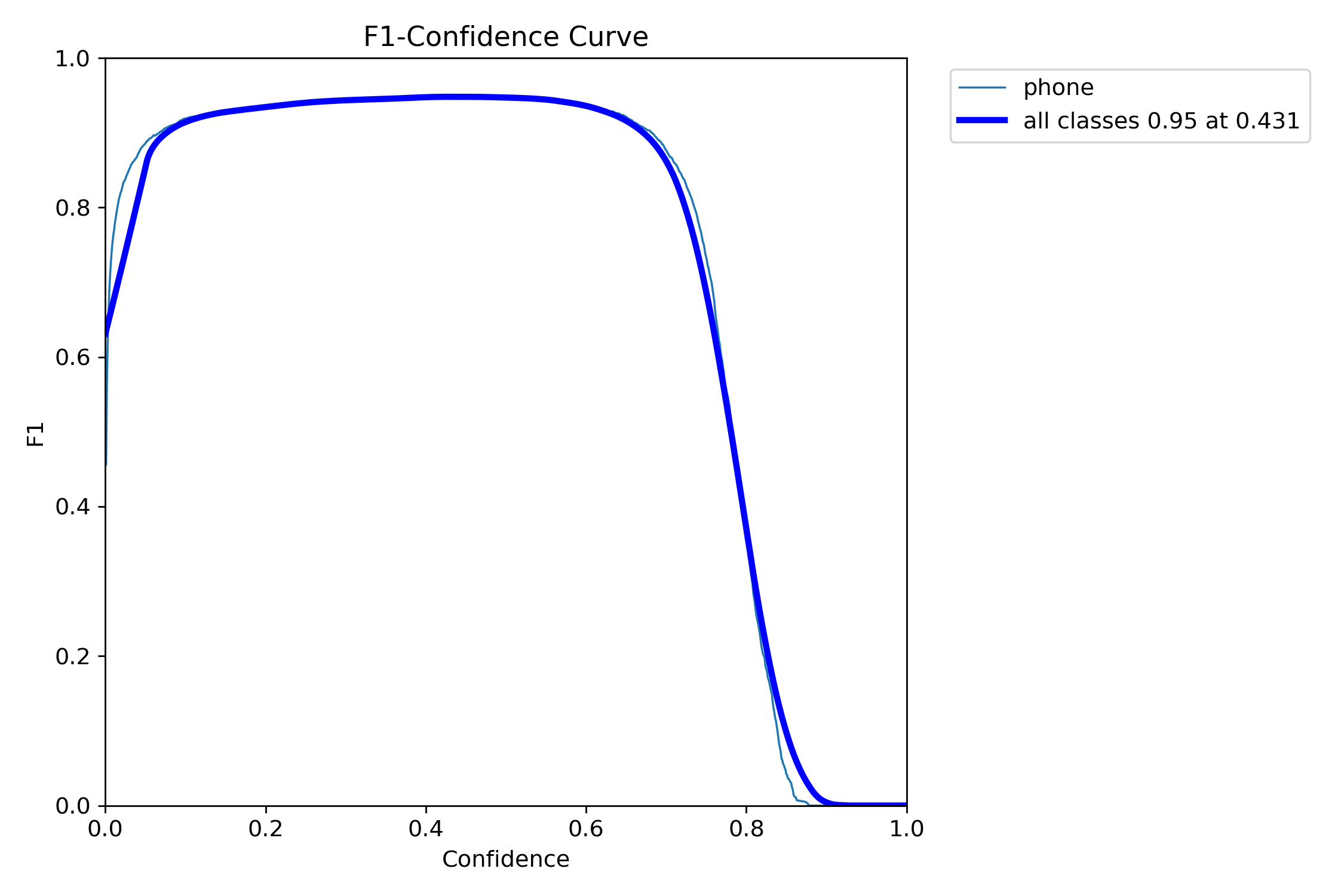
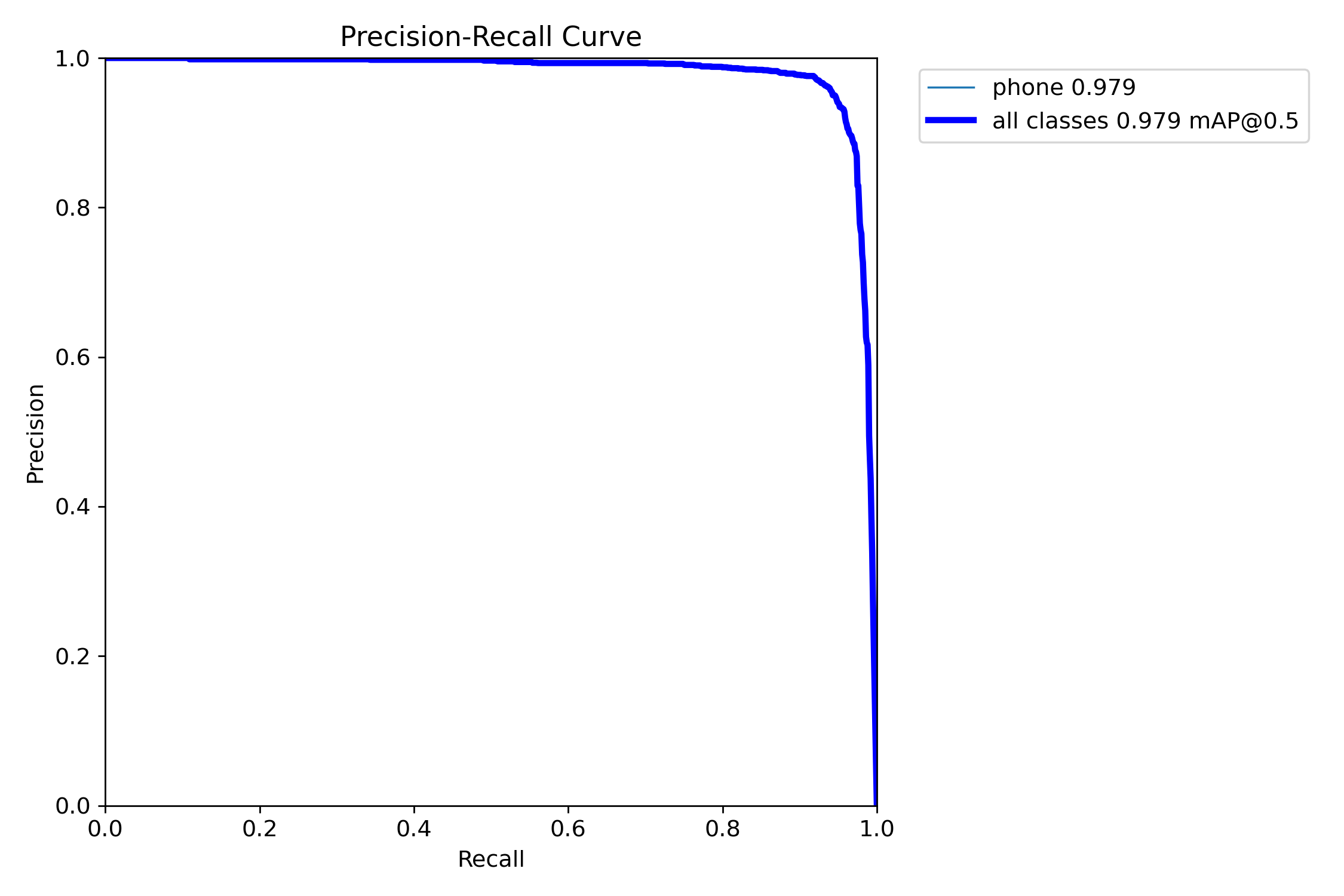
混淆矩阵分析
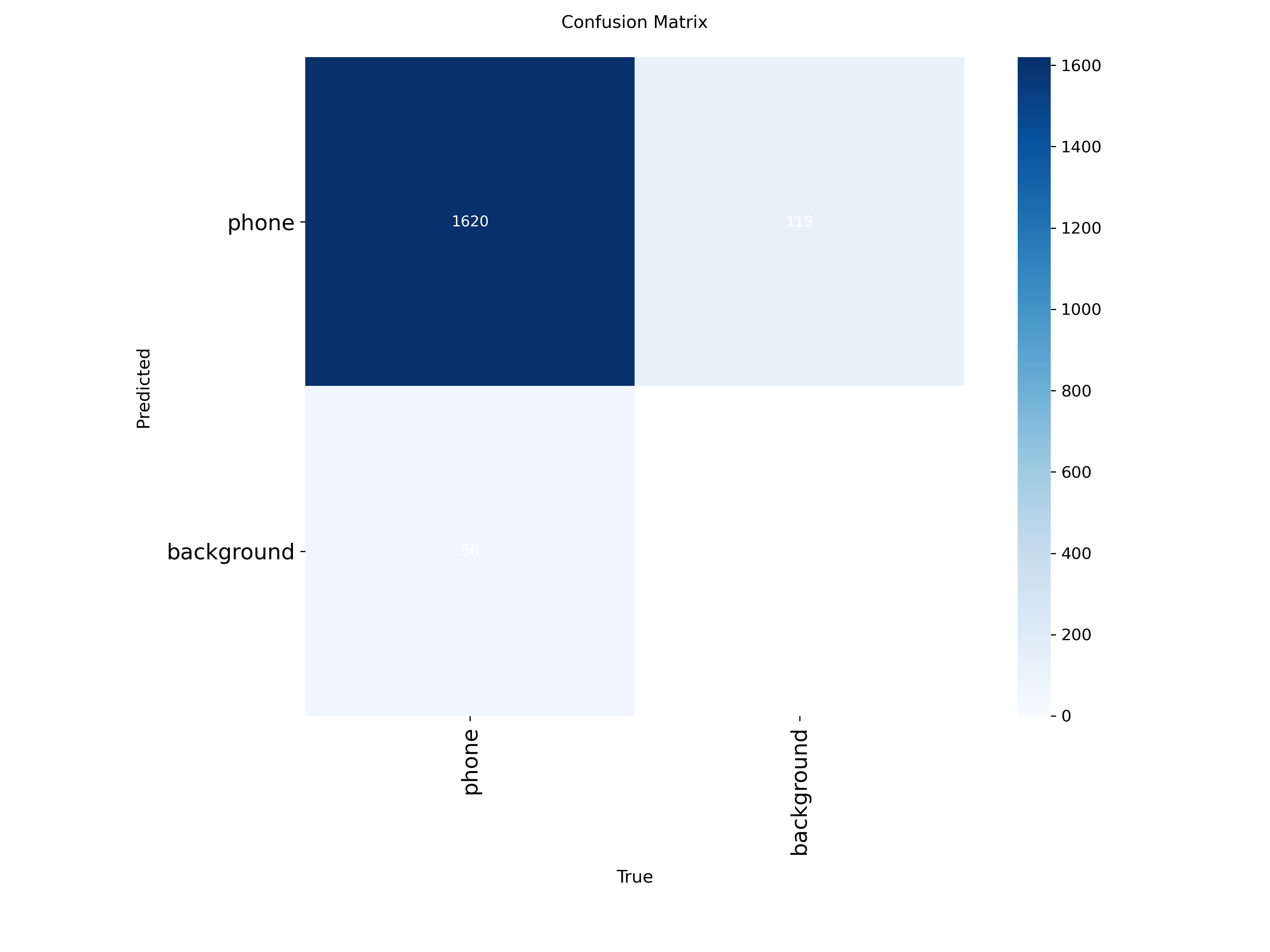
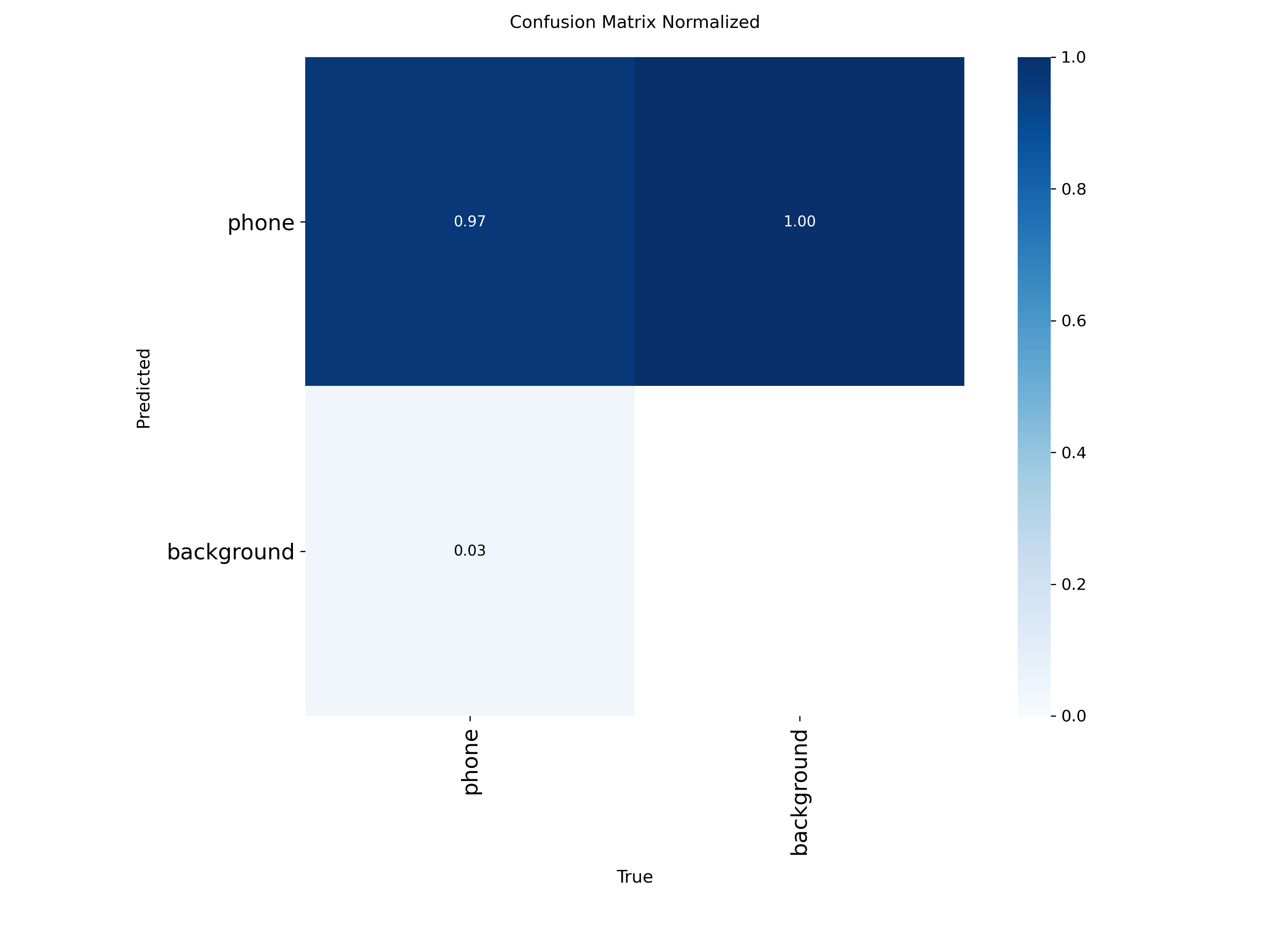
混淆矩阵显示模型具有优秀的分类性能,误检率和漏检率都控制在较低水平。
训练样本可视化
训练批次样本



验证结果对比
真实标签 vs 预测结果
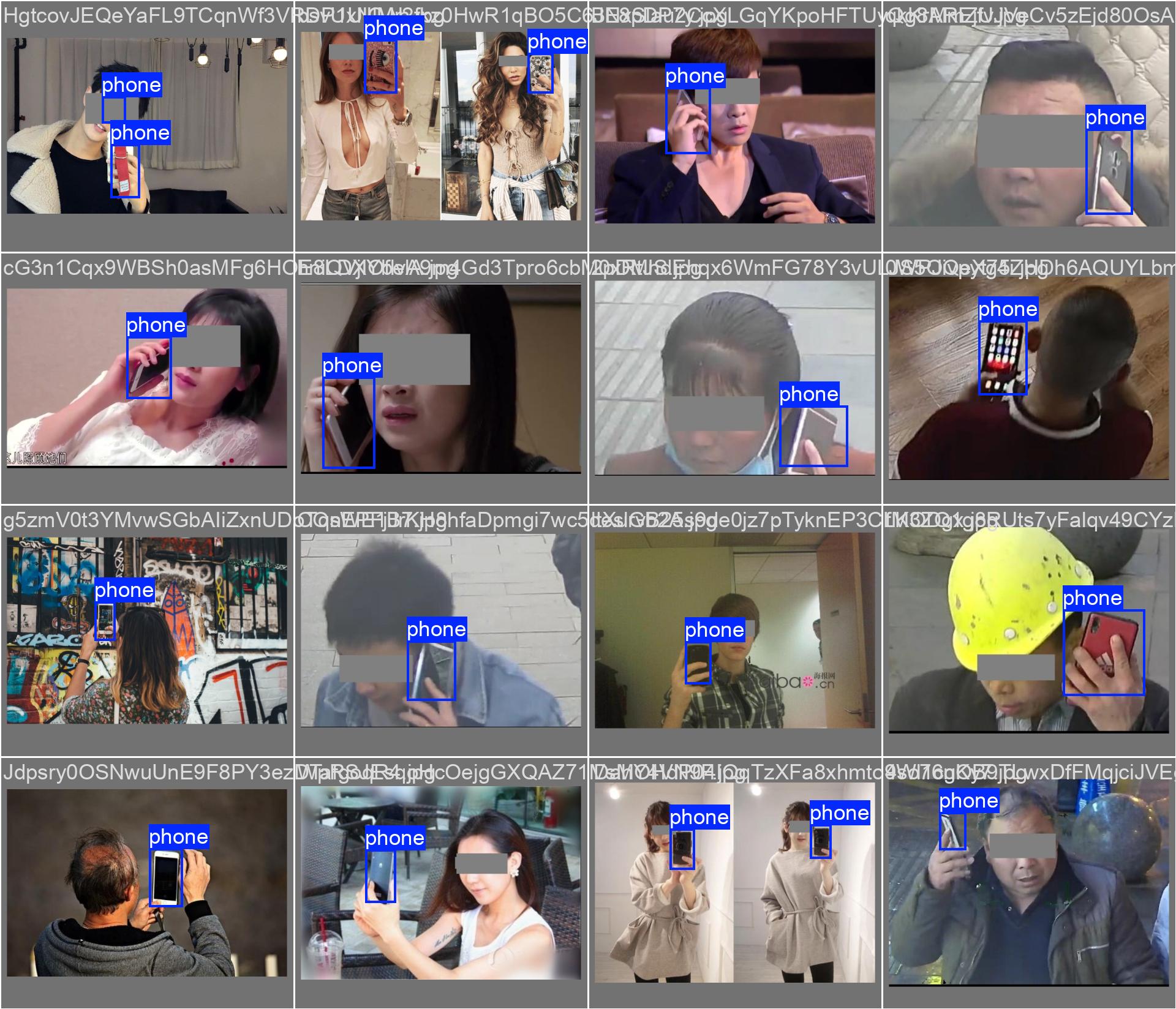
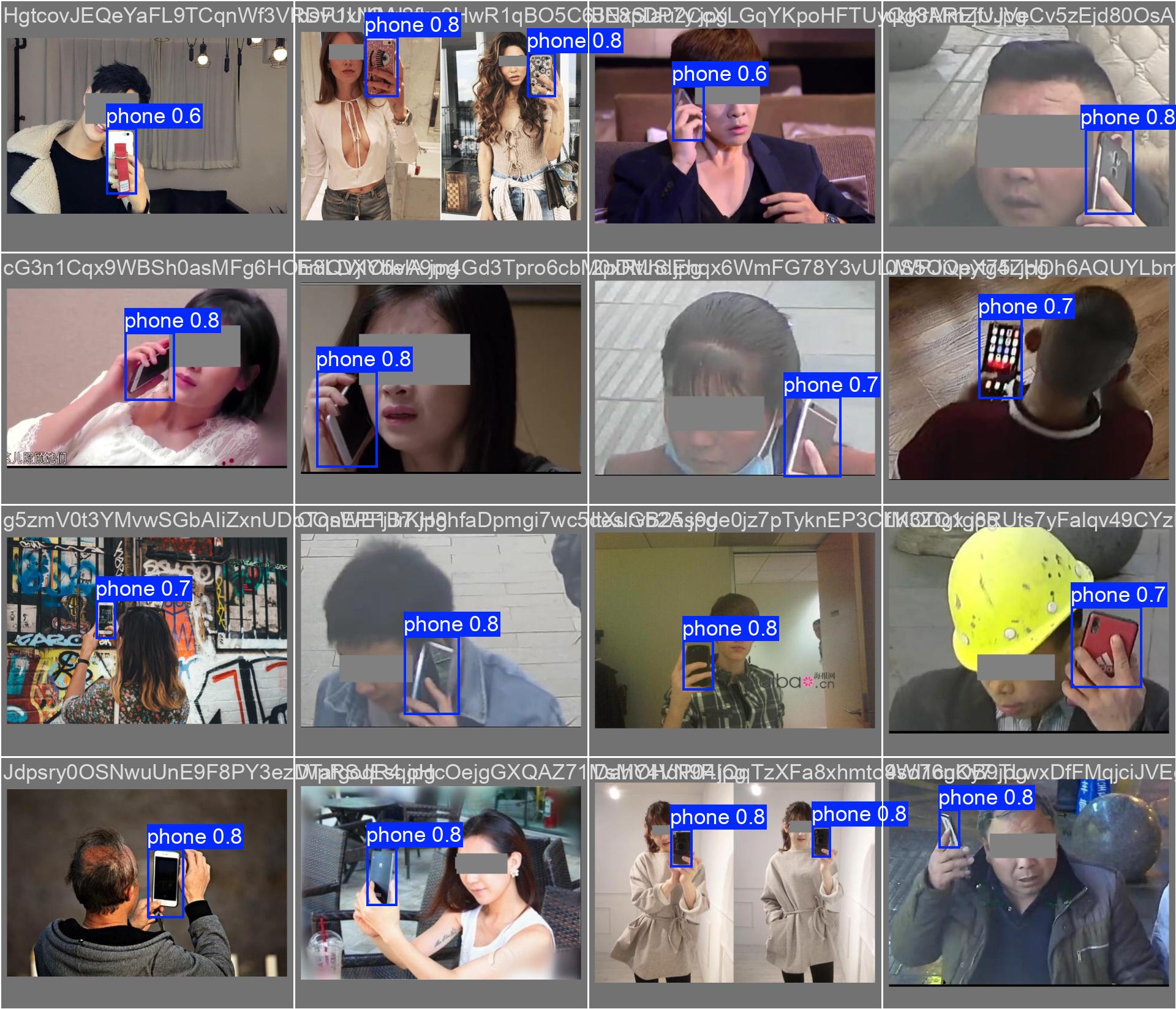




从对比图可以看出,模型的预测结果与真实标签高度一致,证明了训练的有效性。
数据分布分析
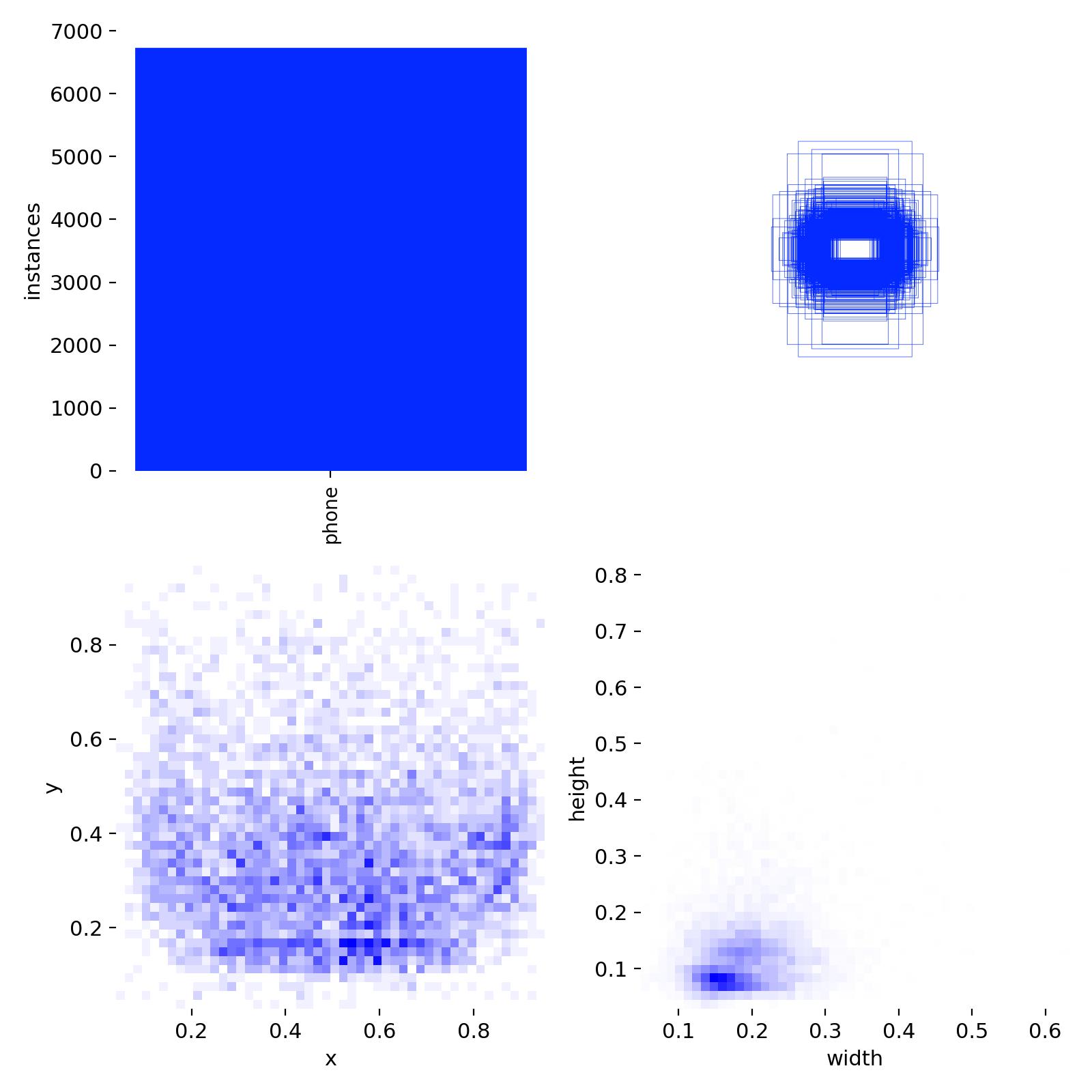
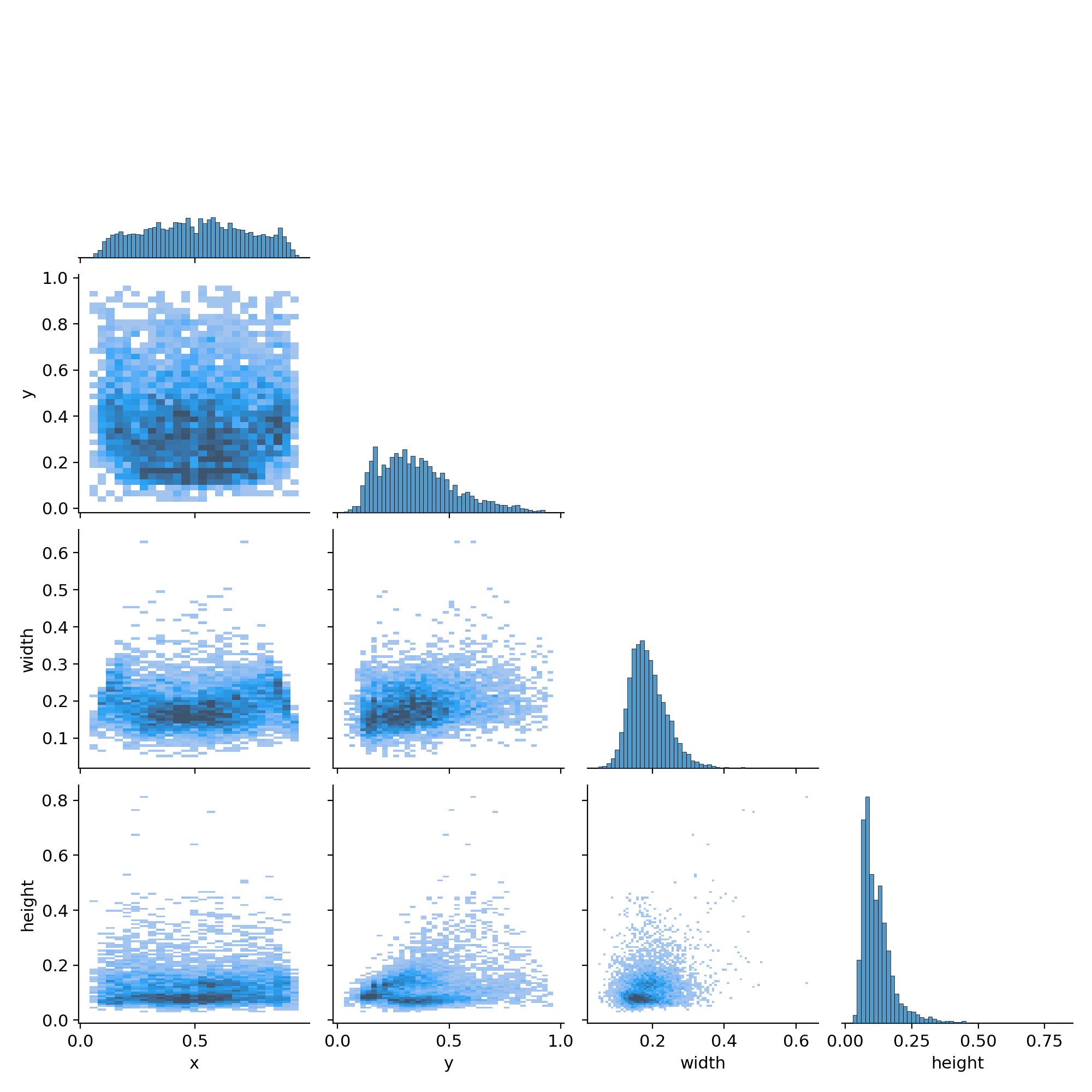
技术亮点
1. 智能数据分割
- 自动将数据集按8:2比例分割为训练集和验证集
- 确保数据分布的均衡性
2. 多格式标注支持
- 支持XML和YOLO格式标注文件
- 自动转换和验证标注格式
3. 完整的训练流程
- 从数据预处理到模型训练的端到端解决方案
- 详细的训练日志和可视化结果
4. 模型优化
- 使用预训练权重加速收敛
- 合理的学习率调度策略
- 有效的数据增强技术
部署与应用
模型文件
- 最佳模型:
phone_best.pt - 最后模型:
weights/last.pt - 模型大小:约6MB(YOLO11n)
模型推理代码
from ultralytics import YOLO
import cv2def detect_phone_usage(image_path, model_path='phone_best.pt'):"""手机使用检测推理函数"""# 加载训练好的模型model = YOLO(model_path)# 进行推理results = model(image_path)# 处理结果for result in results:boxes = result.boxesif boxes is not None:for box in boxes:# 获取边界框坐标x1, y1, x2, y2 = box.xyxy[0].cpu().numpy()confidence = box.conf[0].cpu().numpy()print(f"检测到手机,置信度: {confidence:.2f}")print(f"位置: ({x1:.0f}, {y1:.0f}, {x2:.0f}, {y2:.0f})")return results# 批量检测示例
def batch_detection(image_folder):"""批量检测文件夹中的图片"""model = YOLO('phone_best.pt')for filename in os.listdir(image_folder):if filename.lower().endswith(('.jpg', '.jpeg', '.png')):image_path = os.path.join(image_folder, filename)results = model(image_path)# 保存检测结果for i, result in enumerate(results):result.save(f'output/{filename}_result.jpg')
应用场景
- 教育场景:课堂手机使用监控
- 交通安全:驾驶时手机使用检测
- 工作场所:会议室手机使用管理
- 公共场所:图书馆等安静区域监控
- 考试监控:考场违规行为检测
- 安全驾驶:车载系统集成应用
性能特点
- 检测精度:mAP50达到97.6%
- 推理速度:支持实时检测
- 部署灵活:支持CPU和GPU推理
总结与展望
本项目成功构建了一个高精度的手机违规使用检测模型,主要成果包括:
- 高精度检测:在测试集上达到97.6%的mAP50
- 完整工程化:从数据处理到模型训练的完整流程
- 可视化分析:丰富的训练过程可视化和结果分析
- 实用性强:模型轻量化,适合实际部署
模型优化技巧
1. 数据增强策略
# 自定义数据增强
from albumentations import Compose, HorizontalFlip, RandomBrightnessContrastaugmentations = Compose([HorizontalFlip(p=0.5),RandomBrightnessContrast(p=0.3),# 更多增强策略...
])
2. 超参数调优
- 学习率调度:使用余弦退火策略
- 批次大小:根据GPU内存调整
- 图像尺寸:平衡精度和速度
3. 模型集成
# 多模型集成推理
def ensemble_predict(image_path, models):predictions = []for model in models:result = model(image_path)predictions.append(result)# 结果融合逻辑return merge_predictions(predictions)
性能监控与分析
训练监控脚本
import matplotlib.pyplot as plt
import pandas as pddef plot_training_metrics(results_csv):"""绘制训练指标曲线"""df = pd.read_csv(results_csv)fig, axes = plt.subplots(2, 2, figsize=(12, 8))# 损失曲线axes[0,0].plot(df['epoch'], df['train/box_loss'], label='Box Loss')axes[0,0].plot(df['epoch'], df['train/cls_loss'], label='Class Loss')axes[0,0].set_title('Training Loss')axes[0,0].legend()# 精度指标axes[0,1].plot(df['epoch'], df['metrics/precision(B)'], label='Precision')axes[0,1].plot(df['epoch'], df['metrics/recall(B)'], label='Recall')axes[0,1].set_title('Precision & Recall')axes[0,1].legend()# mAP指标axes[1,0].plot(df['epoch'], df['metrics/mAP50(B)'], label='mAP50')axes[1,0].plot(df['epoch'], df['metrics/mAP50-95(B)'], label='mAP50-95')axes[1,0].set_title('mAP Metrics')axes[1,0].legend()# 学习率axes[1,1].plot(df['epoch'], df['lr/pg0'], label='Learning Rate')axes[1,1].set_title('Learning Rate Schedule')axes[1,1].legend()plt.tight_layout()plt.savefig('training_analysis.png', dpi=300)plt.show()
未来改进方向
- 多类别扩展:支持更多电子设备的检测
- 行为分析:结合姿态估计进行更精细的行为分析
- 边缘部署:针对移动设备和嵌入式系统的优化
- 实时预警:集成报警系统,实现实时违规提醒
- 模型压缩:使用知识蒸馏和量化技术
- 多模态融合:结合音频信号进行综合判断