Day13_【DataFrame数据组合concat连接】【案例】
concat【案例】
1.加载并查看数据
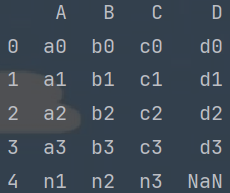
import pandas as pd# 1. 加载数据 查看数据
df1 = pd.read_csv('data/concat_1.csv')
print(df1)
df2 = pd.read_csv('data/concat_2.csv')
print(df2)
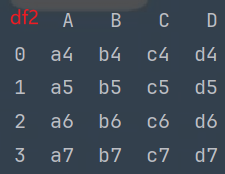
df3 = pd.read_csv('data/concat_3.csv')
print(df3)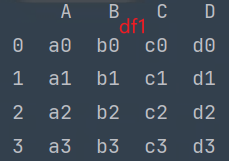
2.通过concat()函数, 拼接上述的3个df对象
# 按行拼接
r1 = pd.concat([df1, df2, df3], axis=0)
# r1 = pd.concat([df1, df2, df3], axis='rows')
print(r1)# 按列拼接
r2 = pd.concat([df1, df2, df3], axis=1)
# r2 = pd.concat([df1, df2, df3], axis='columns')
print(r2)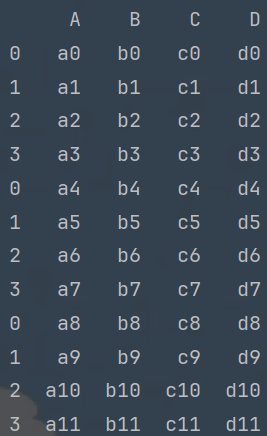
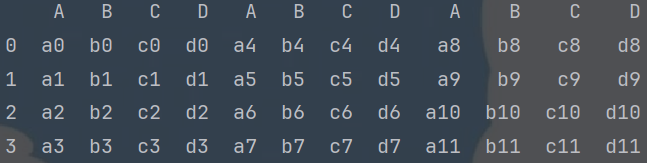
# 通过设置 ignore_case参数, 可以实现: 重置索引
# 将['n1','n2','n3','n4']作为行连接到df1后,创建DataFrame,并指定列名
df5 = pd.DataFrame([['n1', 'n2', 'n3', 'n4']], columns=['A', 'B', 'C', 'D'])
print(df5)
# 通过设置 ignore_case参数, 可以实现: 重置索引
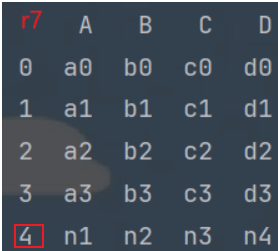
# 行拼接, 重置索引, 结果为: 行索引变为 0 ~ n
r7 = pd.concat([df1, df5], ignore_index=True)
print(r7)
# 列拼接, 重置索引, 结果为: 列名变为 0 ~ n
r8 = pd.concat([df1, df5], axis=1, ignore_index=True)
print(r8)
3.通过concat()函数, 拼接df与series
1.按行 拼接
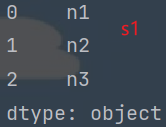
s1 = pd.Series(['n1', 'n2', 'n3'])
print(s1)
# 添加行
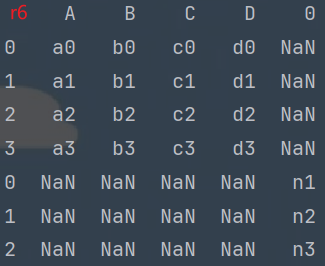
r6 = pd.concat([df1, s1], axis=0)
# r6 = pd.concat([df1, s1], axis="rows")
print(r6)由于Series是列数据(没有行索引), concat()默认是添加行, 所以 它们拼接会新增一列. 缺值用NaN填充
2.按列 拼接
r6 = pd.concat([df1, s1], axis=1)
# r6 = pd.concat([df1, s1], axis="columns")
print(r6)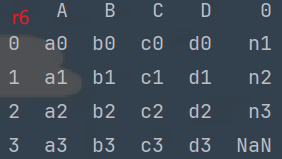
_append【案例】
concat可以用来连接多个对象 ,现连接一个对象,可以使用_append()
# 演示 append函数, 实现: 追加1个df2对象 到 另一个df1对象中
# 只能行拼接, 且没有axis参数
print(df1._append(df2))
# ignore_index: 忽略索引, 即: 索引会重置
df1.append(df2, ignore_index=True)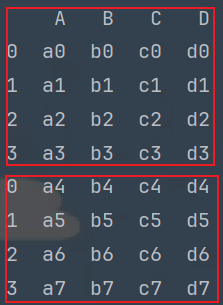
# df对象 使用append追加一个字典时, 必须传入 ignore_index=True 参数
data_dict = {'A': 'n1', 'B': 'n2', 'C': 'n3'}
print(data_dict)
print(df1._append(data_dict, ignore_index=True))![]()