Qwen2.5-vl源码解读系列:LLM的Embedding层
参考视频:Qwen2.5-VL源码解读-大模型的Embedding层_哔哩哔哩_bilibili
什么是Embedding?
Embedding(嵌入)在自然语言处理(NLP)、计算机视觉等领域中是一种将离散对象(如词、句子、图片、用户等)映射为连续向量空间的表示方法。它的核心思想是把原本无法直接用于计算的符号或离散数据,转化为可计算、可度量的稠密向量(通常是低维的实数向量),使得相似的对象在向量空间中距离较近。
在多模态大模型中,分为文本嵌入和图像嵌入,图像嵌入可以直接理解为使用Vision Transformer等视觉特征提取出来的结果。下面细说LLM中的文本嵌入。
文本Embedding
可以先查看这两篇博文理解NLP的基础概念:
《BERT:Pre-training of Deep Bidirectional Transformers forLanguage Understanding》论文精读笔记-CSDN博客
BERT代码简单笔记_bert 源代码-CSDN博客
分词器
作用:将一段文本拆分成更小的基本单位(通常是词、子词或字符)。
以BERT中WordPiece分词手段为例:将词拆分为更小的子词单元,"unhappiness" → ["un", "##happiness"]
Tokenizer
在NLP邻域,tokenizer的功能基本等同于分词器+映射为编号。
- Text → Tokens:将原始文本分割成最小的处理单元,称为“token”。token可以是单词、子词甚至字符。
例如:"unhappiness" 可能分为 ["un", "happiness"],甚至 ["un", "##happy", "##ness"]。- Tokens → Token IDs:每个token对应一个唯一的编号(通常叫token id),以便在神经网络中的embedding查找和后续处理。 例如:["I", "love", "NLP"] → [101, 2001, 37005]
Tokenizer 通常包含分词、映射token到id、加特殊符号([CLS], [SEP])、填充、截断等多重功能,所以比单纯的分词更“全套”。
Embedding
文本embedding 是指将token id输入到embedding查找表(即Embedding层),输出一组可用于计算的稠密向量。
- 输入:token id序列(如 [101, 2001, 37005])
- 过程:Embedding层将每个token id查找对应的向量(如每个都是768维),再形成一个句子的embedding矩阵。
- 输出:一个形如 [seq_len, embedding_dim] 的向量序列,或者经过池化/模型进一步处理后得到的整个句子的向量
通俗理解,Embedding就是将Tokenizer后的子词voc,映射到向量空间,也就是生成一个[vocab_size,embedding_dim]形状的大型可学习参数矩阵,每一行代表一个token的嵌入向量,刚开始随机初始初始化。
模型训练过程就是在不断更新这个矩阵的权重参数,使得更新后的向量更精准表达子词内在含义与规律。
后面将ids输入embedding的过程就是利用id在这个embedding矩阵中查找对应的向量。
源码解析
Qwen2.5vl模型分为了视觉部分和语言部分。
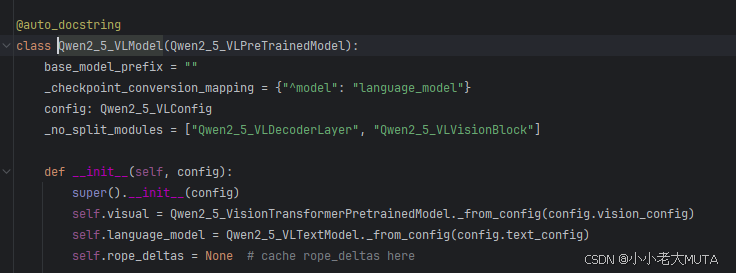
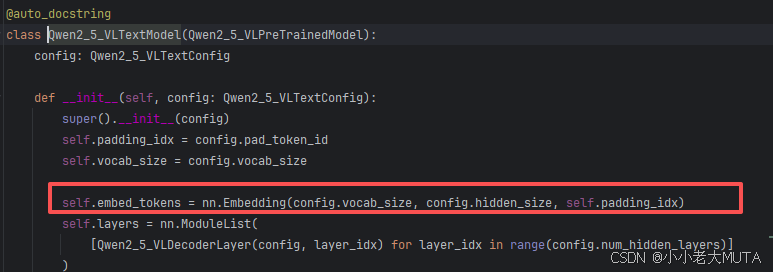
在语言模型中,初始化传入子词长度和嵌入维度大小,构成Embedding矩阵[vocab_size,embedding_dim],Qwen中是[152064,3584]
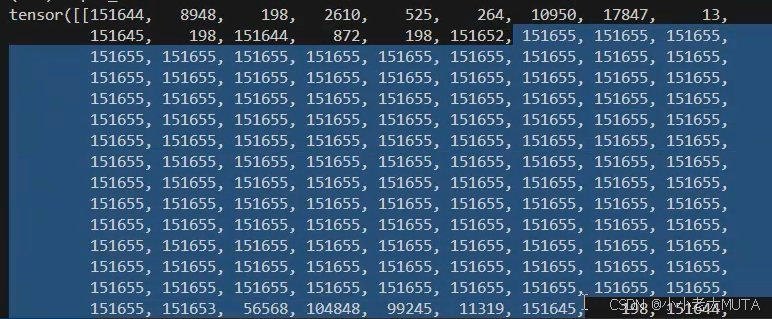
对inputs_ids做嵌入操作(LLM的input是图像+文本的concat,图像部分id用占位符表示):
这里举例input_ids=[1,137],最后输出inputs_embeds=[1,137,3584]

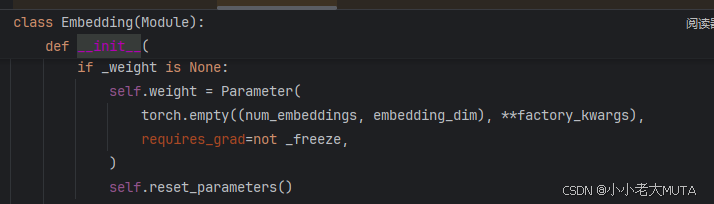
nn.Embedding
构造weight可学习参数矩阵,全零的[num_embeddings,embedding_dim]二维矩阵。