Python 项目里的数据预处理工作(数据清洗步骤与实战案例详解)
目录
一、数据清洗的需求
1、完整性
2、全面性
3、合法性
4、唯一性
5、类别是否可靠
二、实战案例--矿物数据的分析的数据预处理
编辑
1、数据读取与筛选
2、缺失值检测
编辑
3、规范标签编码
4、数据类型转换
5、数据标准化
6、缺失值处理
1.完整数据保留
2.平均值填充
3.中位数填充:
4.众数填充
高级填充方法
7、样本不平衡处理
一、数据清洗的需求

数据清理是指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。换句话说,数据清洗的目的是删除重复信息、纠正存在的错误,并提供数据一致性。在进行数据清洗时,需要按照一定的规则把"脏数据""洗掉",以确保数据的准确性和可靠性。
1、完整性
在 Python 中,常用 pandas 库处理数据。对于检查单条数据是否存在空值,可以使用 isnull() 方法。例如,有一个名为data的 csv:
import pandas as pd
data = pd.read_csv('data.csv')
# 检查每列的空值数量
print(data.isnull().sum())
# 检查某一行是否有空值
print(data.iloc[0].isnull().any())2、全面性
通过 describe() 方法获取数据的统计摘要,包括最大值、最小值、平均值等,以此判断数据是否全面。
# 获取数据的统计摘要
print(data.describe())如果需要自定义检查,比如判断某列数据是否都在合理范围内:
column_name = 'your_column'
max_value = data[column_name].max()
min_value = data[column_name].min()
if max_value > upper_limit or min_value < lower_limit:print(f"{column_name}的数据可能不全面,最大值{max_value},最小值{min_value}")3、合法性
检查数据的合法性可以使用条件判断。比如检查年龄列:
if (data['age'] > 1000).any():print("存在不合法的年龄数据")if (data['PH'] >= 14 or (data['PH'] <= 0).any():print("存在不合法的年龄数据")也可以使用正则表达式等方式检查数据格式是否正确,例如检查邮箱格式:
import re
email_pattern = re.compile(r'^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$')
data['is_valid_email'] = data['email'].apply(lambda x: bool(email_pattern.match(x)))
if (data['is_valid_email'] == False).any():print("存在不合法的邮箱格式数据")有些字符看起来是数字,但却是文本类型的,需要将其转化格式才能用来训练
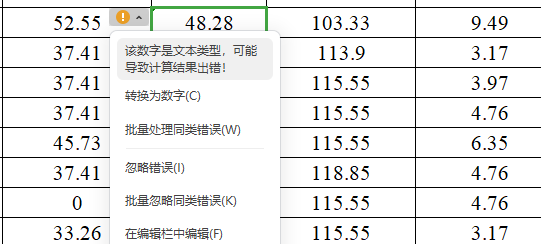
4、唯一性
使用 duplicated() 方法可以检查数据是否重复记录,删除重复记录可以使用 drop_duplicates() 方法。
# 检查是否存在重复行
print(data.duplicated().any())
# 删除重复行
data = data.drop_duplicates()5、类别是否可靠
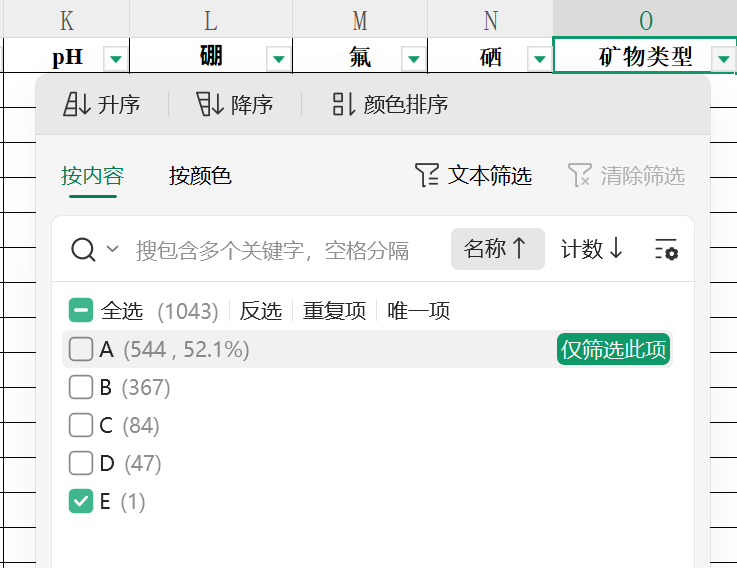
有些类别的数据量较少,可能只有一条数据,这样的数据就不适合训练了,在数据处理的时候需要将其删除。
二、实战案例--矿物数据的分析的数据预处理
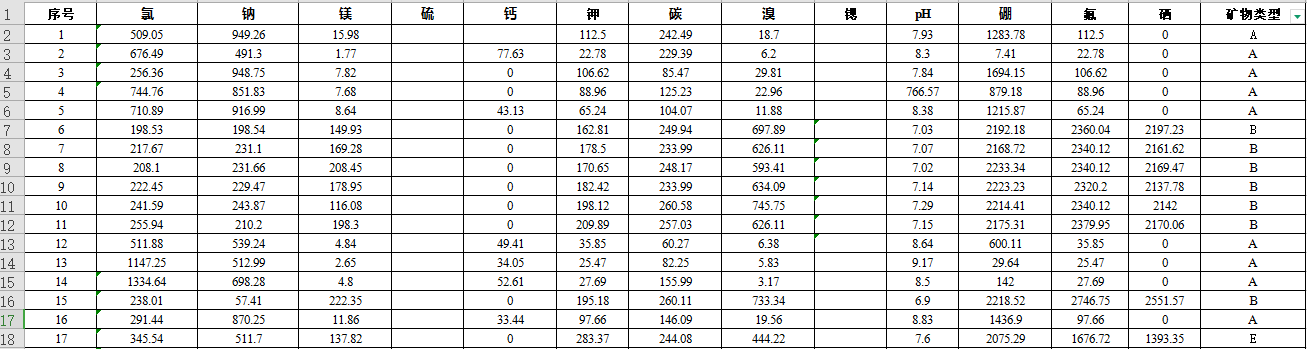
现在我们有一些矿物数据(部分数据如下图所示),需要通过各个元素的含量来分类矿物。
来跟着我的思路实践一下数据清理的流程
1、数据读取与筛选
- 读取 Excel 格式的矿物数据
- 移除不可靠数据,这里 "矿物类型" 为 'E' 的样本数据量过少,实现数据筛选
data = pd.read_excel("矿物数据.xls")
data = data[data["矿物类型"] != 'E']2、缺失值检测
- 检测数据中的缺失值情况
- 计算每列的缺失值总数
# 检测缺失值
null_num = data.isnull() # 生成布尔值DataFrame,缺失值为True
null_total = null_num.sum() # 计算每列的缺失值总数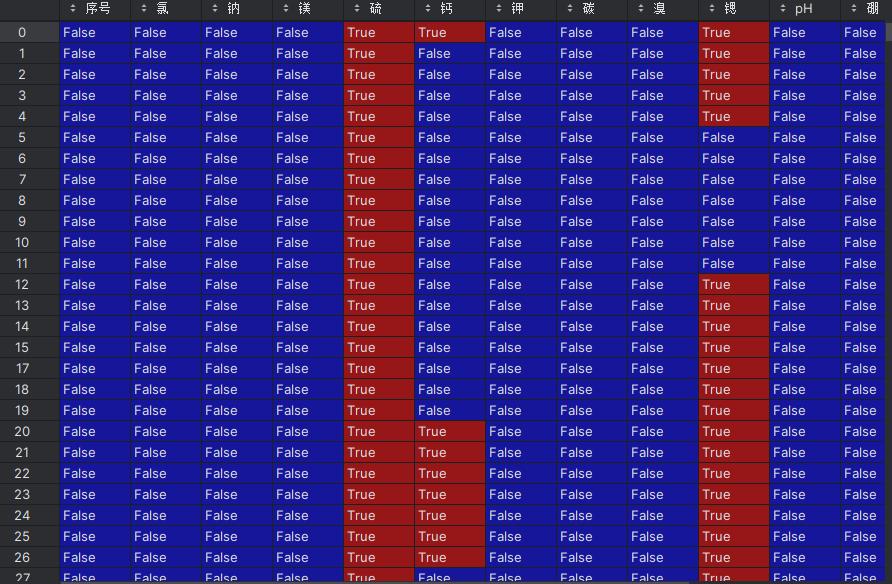
需要注意,有些数据并不是None,而是空格,无法由缺失值检测来剔除
3、规范标签编码
- 将特征数据 (X_whole) 与标签数据 (y_whole) 分离
- 移除 "序号" 列,只保留特征和标签
- 便于后续机器学习算法处理
- 中文 / 字符标签转换为数字编码(A→0, B→1, C→2, D→3)(大多数机器学习算法只能处理数值型数据,因此将字符型标签(A/B/C/D)转换为数字编码(0/1/2/3)。)
# 获取全部特征数据(移除标签列"矿物类型"和无关列"序号")
X_whole = data.drop("矿物类型", axis=1).drop("序号", axis=1)
# 获取全部标签数据(矿物类型)
y_whole = data.矿物类型# 定义标签映射字典,将字符标签转换为数字
label_dict = {"A": 0, "B": 1, "C": 2, "D": 3}# 批量转换标签
encoded_labels = [label_dict[label] for label in y_whole]
y_whole = pd.DataFrame(encoded_labels, columns=["矿物类型"])4、数据类型转换
- 确保所有特征都是数值类型,为后续的数值计算和模型训练做准备,(数据里面会有,4..3,\,/,等异常数据)
- 无法转换的非数值数据会被标记为缺失值。
确保所有特征都是数值类型:
# 将所有特征列转换为数值类型,无法转换的值设为NaN
for column_name in X_whole.columns:X_whole[column_name] = pd.to_numeric(X_whole[column_name], errors='coerce')5、数据标准化
- 使用 StandardScaler 对特征数据进行 Z-score 标准化
- 使各特征具有相同的尺度,避免算法受特征尺度(量纲)敏感的问题
# 初始化标准化器
scaler = StandardScaler()# 对特征数据进行Z-score标准化(均值为0,标准差为1)
X_whole_z = scaler.fit_transform(X_whole)
X_whole = pd.DataFrame(X_whole_z, columns=X_whole.columns)6、缺失值处理
- 将数据分为训练集 (70%) 和测试集 (30%)
- 固定 random_state =0 确保结果可复现
- 有多种缺失值填充方法:完整数据保留、平均值填充、中位数填充、众数填充等常规方法,还有knn算法,逻辑回归,svm支持向量机和贝叶斯等机器学习方法
1.完整数据保留
这是最简单直接的方法,直接删除包含缺失值的样本行。
# 按7:3比例拆分训练集和测试集,固定随机种子确保结果可复现
x_train_w, x_test_w, y_train_w, y_test_w = train_test_split(\X_whole, y_whole, test_size=0.3, random_state=0)x_train_fill,y_train_fill = fill_data.cca_train_fill(x_train_w,y_train_w)
x_test_fill, y_test_fill = fill_data.cca_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)def cca_train_fill(train_data,train_label):data = pd.concat([train_data, train_label], axis=1)df_filled = data.dropna()return df_filled.drop('矿物类型', axis=1),df_filled.矿物类型
def cca_test_fill(train_data,train_label, test_data,test_label):data = pd.concat([test_data, test_label], axis=1)df_filled = data.dropna()return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型def cca_train_fill(train_data, train_label):"""训练集完整数据保留处理"""data = pd.concat([train_data, train_label], axis=1)df_filled = data.dropna() # 删除含有缺失值的行return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型def cca_test_fill(train_data, train_label, test_data, test_label):"""测试集完整数据保留处理"""data = pd.concat([test_data, test_label], axis=1)df_filled = data.dropna()return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型# 应用完整数据保留方法
x_train_fill, y_train_fill = fill_data.cca_train_fill(x_train_w, y_train_w)
x_test_fill, y_test_fill = fill_data.cca_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)实现步骤:
- 合并特征和标签数据
- 删除含有缺失值的行
- 分离特征和标签
2.平均值填充
用该类别特征的均值填充缺失值,适用于数值型特征。
x_train_fill,y_train_fill = fill_data.mean_train_fill(x_train_w,y_train_w)
x_test_fill, y_test_fill = fill_data.mean_test_fill(x_train_fill, y_train_fill, x_test_w, y_test_w)def mean_train_method(data):# 使用该类别每列的均值替换缺失值return data.fillna(data.mean())def mean_train_fill(train_data, train_label):# 合并特征和标签,方便按照类别分组处理data = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)# 遍历每个类别(假设类别编号为 0,1,2,3),# 对每个类别单独进行均值填充filled = [mean_train_method(data[data['矿物类型'] == i]) for i in range(4)]# 将所有类别数据拼接在一起,并重新排序索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回特征数据和对应标签return df_filled.drop('矿物类型', axis=1), df_filled['矿物类型']def mean_test_method(train_data, test_data):# 用训练集该类别的均值填充对应类别的测试集缺失值return test_data.fillna(train_data.mean())def mean_test_fill(train_data, train_label, test_data, test_label):# 合并特征和标签,方便操作train_all = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)test_all = pd.concat([test_data, test_label], axis=1).reset_index(drop=True)# 按类别分别取出训练集和测试集,并进行均值填充filled = [mean_test_method(train_all[train_all['矿物类型'] == i], # 当前类别的训练数据test_all[test_all['矿物类型'] == i] # 当前类别的测试数据)for i in range(4)]# 拼接所有类别的数据,并重新排序索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的测试特征数据和标签return df_filled.drop('矿物类型', axis=1), df_filled['矿物类型']def mean_train_method(data):"""训练集均值填充方法"""return data.fillna(data.mean()) # 使用该类别每列的均值替换缺失值def mean_train_fill(train_data, train_label):"""训练集均值填充"""data = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)# 遍历每个类别(0-3),对每个类别单独进行均值填充filled = [mean_train_method(data[data['矿物类型'] == i]) for i in range(4)]df_filled = pd.concat(filled).reset_index(drop=True)return df_filled.drop('矿物类型', axis=1), df_filled['矿物类型']def mean_test_method(train_data, test_data):"""测试集均值填充方法"""return test_data.fillna(train_data.mean()) # 用训练集该类别的均值填充def mean_test_fill(train_data, train_label, test_data, test_label):"""测试集均值填充"""train_all = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)test_all = pd.concat([test_data, test_label], axis=1).reset_index(drop=True)filled = [mean_test_method(train_all[train_all['矿物类型'] == i],test_all[test_all['矿物类型'] == i]) for i in range(4)]df_filled = pd.concat(filled).reset_index(drop=True)return df_filled.drop('矿物类型', axis=1), df_filled['矿物类型']3.中位数填充:
def median_train_method(data):# 获取每列的中位数,并用其填充缺失值fill_values = data.median()return data.fillna(fill_values)def median_train_fill(train_data, train_label):# 合并特征数据和标签数据data = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)# 按照“矿物类型”分类,每一类数据使用中位数填充filled = [median_train_method(data[data['矿物类型'] == i]) for i in range(4)]# 将填充后的数据拼接起来,并重置索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的数据和矿物类型标签return df_filled.drop('矿物类型', axis=1), df_filled['矿物类型']def median_test_method(train_data, test_data):# 使用训练集的中位数填充测试集的缺失值fill_values = train_data.median()return test_data.fillna(fill_values)def median_test_fill(train_data, train_label, test_data, test_label):# 合并训练集和测试集的特征数据和标签train_all = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)test_all = pd.concat([test_data, test_label], axis=1).reset_index(drop=True)# 按“矿物类型”进行分类filled = [median_test_method(train_all[train_all['矿物类型'] == i], # 当前类别的训练数据test_all[test_all['矿物类型'] == i] # 当前类别的测试数据)for i in range(4)]# 拼接所有类别的数据,并重新索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的测试数据和矿物类型标签return df_filled.drop('矿物类型', axis=1), df_filled['矿物类型']4.众数填充
def mode_train_method(data):# 获取每列的众数,如果有多个众数,选择第一个fill_values = data.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)# 使用众数填充缺失值return data.fillna(fill_values)def mode_train_fill(train_data, train_label):# 合并特征数据和标签数据data = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)# 按照“矿物类型”分类并分别填充filled = [mode_train_method(data[data['矿物类型'] == i]) for i in range(4)]# 将填充后的数据拼接起来,并重置索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的数据和矿物类型标签return df_filled.drop('矿物类型', axis=1), df_filled['矿物类型']def mode_test_method(train_data, test_data):# 使用训练集的众数填充测试集的缺失值fill_values = train_data.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)return test_data.fillna(fill_values)def mode_test_fill(train_data, train_label, test_data, test_label):# 合并训练集和测试集的特征数据和标签train_all = pd.concat([train_data, train_label], axis=1).reset_index(drop=True)test_all = pd.concat([test_data, test_label], axis=1).reset_index(drop=True)# 按“矿物类型”进行分类filled = [mode_test_method(train_all[train_all['矿物类型'] == i], # 当前类别的训练数据test_all[test_all['矿物类型'] == i] # 当前类别的测试数据)for i in range(4)]# 拼接所有类别的数据,并重新索引df_filled = pd.concat(filled).reset_index(drop=True)# 返回填充后的测试数据和矿物类型标签return df_filled.drop('矿物类型', axis=1), df_filled['矿物类型']上述代码有多层嵌套,可以看下面的代码来理解(功能相同)
import pandas as pd#--------------------------考虑包含完整行的数据------------------------------#
def cca_train_fill(train_data,train_label):'''CCA(Complete Case Analysis)只考虑包含完整数据的行'''data = pd.concat([train_data, train_label], axis=1)data = data.reset_index(drop=True)#用于重置索引的。当你对数据进行了排序、筛选或其他操作后索引可能会变得不连续或混df_filled = data.dropna()#用于删除(或过滤掉)包含缺失值(NaN)的行或列。pandas里面有大量和数据清洗相关的函数return df_filled.drop('矿物类型', axis=1),df_filled.矿物类型
def cca_test_fill(train_data,train_label, test_data,test_label):data = pd.concat([test_data, test_label], axis=1)data = data.reset_index(drop=True) # 用于重置索引的。当你对数据进行了排序、筛选或其他操作后索引可能会变得不连续或混df_filled = data.dropna() # 用于删除(或过滤掉)包含缺失值(NaN)的行或列。pandas里面有大量和数据清洗相关的函数return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型#----------------使用平均值的方法对数据进行填充----------------
def mean_train_method(data):'''平均值的计算方法'''fill_values = data.mean()return data.fillna(fill_values) # 使用均值填充缺失值,pandas读取表格数据
def mean_train_fill(train_data,train_label):'''使用平均值的方法 数据进行填充'''data = pd.concat([train_data,train_label], axis=1)data = data.reset_index(drop=True)A = data[data['矿物类型'] == 0]B = data[data['矿物类型'] == 1]C = data[data['矿物类型'] == 2]D = data[data['矿物类型'] == 3]A = mean_train_method(A) # 按照每个类别的数据进行填充B = mean_train_method(B) # 按照每个类别的数据进行填充C = mean_train_method(C) # 按照每个类别的数据进行填充D = mean_train_method(D) # 按照每个类别的数据进行填充df_filled = pd.concat([A, B, C, D])df_filled = df_filled.reset_index(drop=True)return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型def mean_test_method(train_data, test_data):'''根据训练集获取每个类别的平均值,并将训练集的每个类别平均值填充到测试中'''fill_values = train_data.mean()return test_data.fillna(fill_values) # 使用均值填充缺失值
def mean_test_fill(train_data,train_label, test_data,test_label):'''使用平均值的方法对数据进行填充'''train_data_all = pd.concat([train_data, train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)test_data_all = pd.concat([test_data, test_label], axis=1)test_data_all = test_data_all.reset_index(drop=True)A_train = train_data_all[train_data_all['矿物类型'] == 0]B_train = train_data_all[train_data_all['矿物类型'] == 1]C_train = train_data_all[train_data_all['矿物类型'] == 2]D_train = train_data_all[train_data_all['矿物类型'] == 3]A_test = test_data_all[test_data_all['矿物类型'] == 0]B_test = test_data_all[test_data_all['矿物类型'] == 1]C_test = test_data_all[test_data_all['矿物类型'] == 2]D_test = test_data_all[test_data_all['矿物类型'] == 3]A = mean_test_method(A_train, A_test) # 按照每个类别的数据进行填充B = mean_test_method(B_train, B_test) # 按照每个类别的数据进行填充C = mean_test_method(C_train, C_test) # 按照每个类别的数据进行填充D = mean_test_method(D_train, D_test) # 按照每个类别的数据进行填充df_filled = pd.concat([A, B, C, D])df_filled = df_filled.reset_index(drop=True)return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型#-------------------------------使用中位数的方法对数据进行填充-----------------------------------
def median_train_method(data):'''数据集中的空值使用每列的中位数替代'''fill_values = data.median()return data.fillna(fill_values)
def median_train_fill(train_data,train_label):'''使用中位数的方法对数据进行填充'''data = pd.concat([train_data, train_label], axis=1)data = data.reset_index(drop=True)A = data[data['矿物类型'] == 0]B = data[data['矿物类型'] == 1]C = data[data['矿物类型'] == 2]D = data[data['矿物类型'] == 3]A = median_train_method(A) # 按照每个类别的数据进行填充B = median_train_method(B) # 按照每个类别的数据进行填充C = median_train_method(C) # 按照每个类别的数据进行填充D = median_train_method(D) # 按照每个类别的数据进行填充df_filled = pd.concat([A, B, C, D])df_filled = df_filled.reset_index(drop=True)return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型def median_test_method(train_data, test_data): # test_data: 气'''根据训练集获取每个类别的中位数,并将训练集的每个类别中位数填充到测试中'''fill_values = train_data.median()return test_data.fillna(fill_values) # 使用均值填充缺失值
def median_test_fill(train_data, train_label, test_data, test_label):'''使用中位数的方法对数据进行填充'''train_data_all = pd.concat([train_data, train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)test_data_all = pd.concat([test_data, test_label], axis=1)test_data_all = test_data_all.reset_index(drop=True)A_train = train_data_all[train_data_all['矿物类型'] == 0]B_train = train_data_all[train_data_all['矿物类型'] == 1]C_train = train_data_all[train_data_all['矿物类型'] == 2]D_train = train_data_all[train_data_all['矿物类型'] == 3]A_test = test_data_all[test_data_all['矿物类型'] == 0]B_test = test_data_all[test_data_all['矿物类型'] == 1]C_test = test_data_all[test_data_all['矿物类型'] == 2]D_test = test_data_all[test_data_all['矿物类型'] == 3]A = median_test_method(A_train, A_test) # 按照每个类别的数据进行填充B = median_test_method(B_train, B_test) # 按照每个类别的数据进行填充C = median_test_method(C_train, C_test) # 按照每个类别的数据进行填充D = median_test_method(D_train, D_test) # 按照每个类别的数据进行填充df_filled = pd.concat([A, B, C, D])df_filled = df_filled.reset_index(drop=True)return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型#----------------使用众数的方法对数据进行填充----------------
def mode_method(data):'''数据集中的空值使用每列的众数替代,pandas中的mode方法获取众数'''fill_values = data.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)# data.apply对DataFrame的每一列应用一个函数,用于找出每列中出现次数最多的值(即众数)a = data.mode()#获取每列的众数,氯中的众数比较多,一共10个,因此会列出10行,其他列不够return data.fillna(fill_values) # 使用均值填充缺失值
def mode_train_fill(train_data,train_label):'''使用众数的方法对数据进行填充'''data = pd.concat([train_data, train_label], axis=1)data = data.reset_index(drop=True)A = data[data['矿物类型'] == 0]B = data[data['矿物类型'] == 1]C = data[data['矿物类型'] == 2]D = data[data['矿物类型'] == 3]A = mode_method(A) # 按照每个类别的数据进行填充B = mode_method(B) # 按照每个类别的数据进行填充C = mode_method(C) # 按照每个类别的数据进行填充D = mode_method(D) # 按照每个类别的数据进行填充df_filled = pd.concat([A, B, C, D])df_filled = df_filled.reset_index(drop=True)return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型def mode_test_method(train_data, test_data):''' 数据集中的空值使用每列的众数替代'''fill_values =train_data.apply(lambda x: x.mode().iloc[0] if len(x.mode()) > 0 else None)return test_data.fillna(fill_values) # 使用众数填充缺失值
def mode_test_fill(train_data,train_label, test_data,test_label):'''使用众数方法对数据进行填充'''train_data_all = pd.concat([train_data, train_label], axis=1)train_data_all = train_data_all.reset_index(drop=True)test_data_all = pd.concat([test_data, test_label], axis=1)test_data_all = test_data_all.reset_index(drop=True)A_train = train_data_all[train_data_all['矿物类型'] == 0]B_train = train_data_all[train_data_all['矿物类型'] == 1]C_train = train_data_all[train_data_all['矿物类型'] == 2]D_train = train_data_all[train_data_all['矿物类型'] == 3]A_test = test_data_all[test_data_all['矿物类型'] == 0]B_test = test_data_all[test_data_all['矿物类型'] == 1]C_test = test_data_all[test_data_all['矿物类型'] == 2]D_test = test_data_all[test_data_all['矿物类型'] == 3]A = mode_test_method(A_train, A_test) # 按照每个类别的数据进行填充B = mode_test_method(B_train, B_test) # 按照每个类别的数据进行填充C = mode_test_method(C_train, C_test) # 按照每个类别的数据进行填充D = mode_test_method(D_train, D_test) # 按照每个类别的数据进行填充df_filled = pd.concat([A, B, C, D])df_filled = df_filled.reset_index(drop=True)return df_filled.drop('矿物类型', axis=1), df_filled.矿物类型高级填充方法
除了上述常规方法外,还可以使用更复杂的机器学习方法进行缺失值填充:
- KNN算法:基于最近邻样本的特征值进行填充
- 逻辑回归:预测缺失值
- SVM支持向量机
- 贝叶斯方法
这些方法通常能获得更好的填充效果,但计算成本较高,适合对数据质量要求较高的场景。
我将在下一章节详细介绍.
7、样本不平衡处理
- 样本再缺失值处理后,可能会让数据不平衡
- 为了使模型更准确,对数据进行过采样处理
# 使用SMOTE算法进行过采样,解决样本不平衡问题
oversampler = SMOTE(k_neighbors=1, random_state=42)
os_x_train, os_y_train = oversampler.fit_resample(x_train_fill, y_train_fill)经过上述的七个步骤就能完成大部分数据的预处理工作,将使模型训练的准确率大大提高。
希望这篇文章对你在数据处理的过程中有所帮助!