知识蒸馏 - 各类概率分布
知识蒸馏 - 各类概率分布
flyfish
一、离散概率分布
离散分布描述的是取值为离散值(如0,1,2,…)的随机变量的概率规律,通常用概率质量函数(PMF) 表示某一取值的概率。
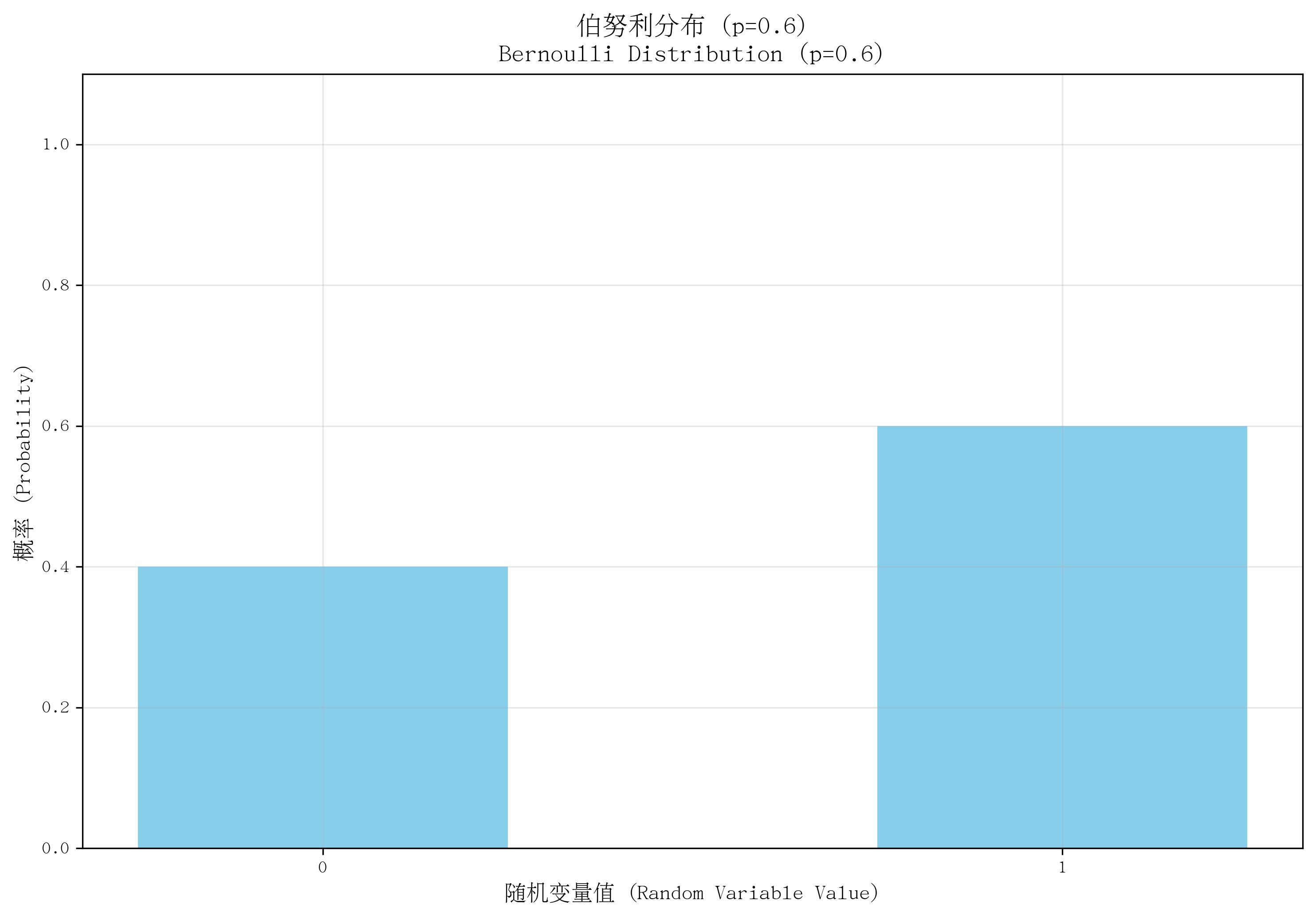
1. 伯努利分布(Bernoulli Distribution)
- 定义:描述单次随机试验的结果,仅有两种可能(“成功”或“失败”),是最简单的离散分布。
- 核心参数:成功概率 ppp(0≤p≤10 \leq p \leq 10≤p≤1),失败概率为 1−p1-p1−p。
- 概率质量函数(PMF):
P(X=k)=pk(1−p)1−kP(X=k) = p^k (1-p)^{1-k}P(X=k)=pk(1−p)1−k,其中 k=0k=0k=0(失败)或 k=1k=1k=1(成功)。 - 适用场景:单次试验的二元结果,如“抛一次硬币是否正面朝上”“一次抽奖是否中奖”。
- 特点:仅含一次试验,结果非0即1;是所有离散分布的基础,多次独立伯努利试验可扩展为其他分布(如二项分布)。
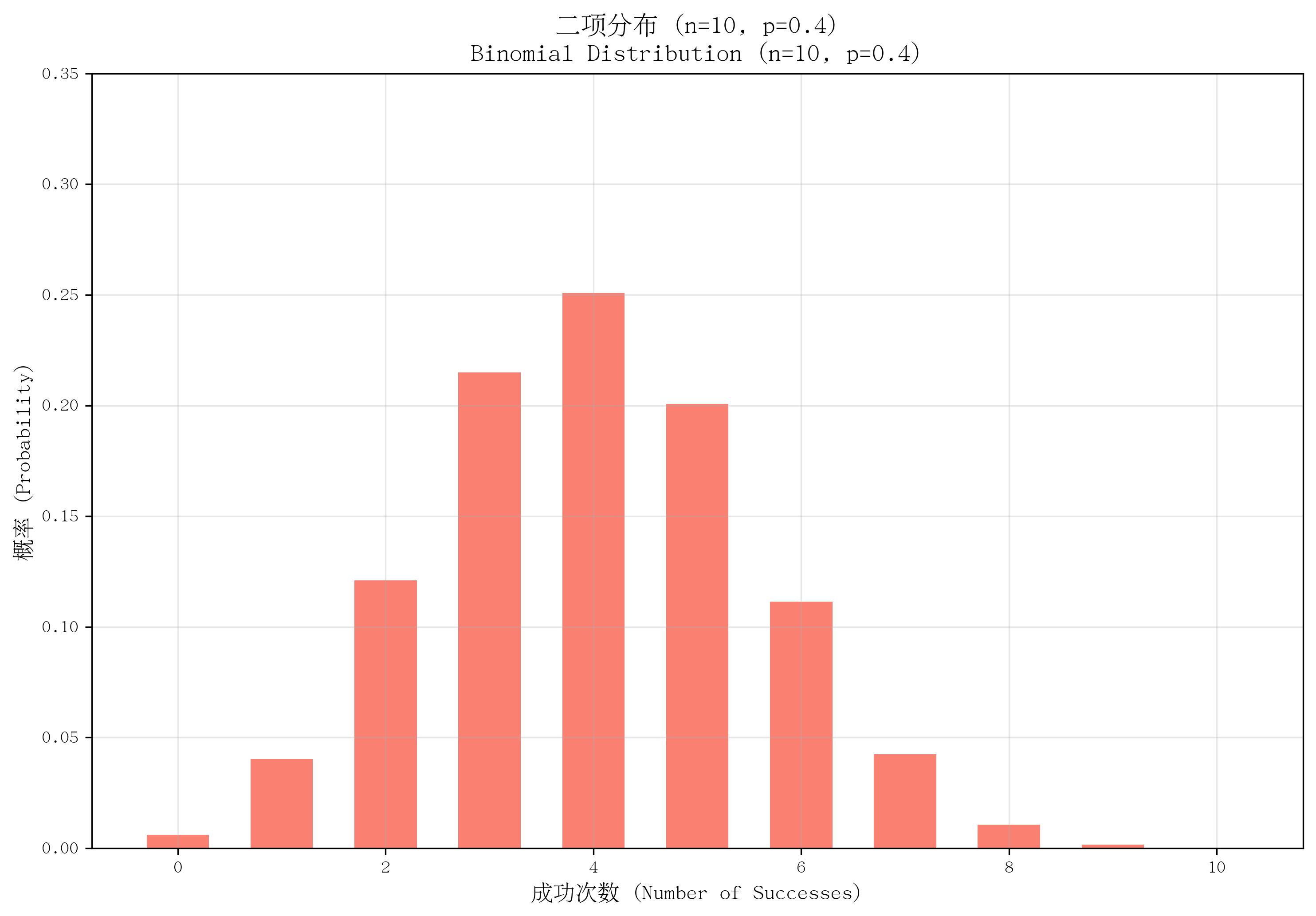
2. 二项分布(Binomial Distribution)
- 定义:描述 nnn 次独立重复的伯努利试验中,“成功”次数的概率分布。
- 核心参数:试验次数 nnn(正整数)、单次成功概率 ppp(0≤p≤10 \leq p \leq 10≤p≤1)。
- 概率质量函数(PMF):
P(X=k)=(nk)pk(1−p)n−kP(X=k) = \binom{n}{k} p^k (1-p)^{n-k}P(X=k)=(kn)pk(1−p)n−k,其中 k=0,1,...,nk=0,1,...,nk=0,1,...,n,(nk)\binom{n}{k}(kn) 为组合数(从n次中选k次成功的方式数)。 - 适用场景:多次独立试验的成功次数,如“抛10次硬币正面朝上的次数”“100件产品中不合格品的数量”。
- 特点:试验独立且每次成功概率相同;当 n=1n=1n=1 时,退化为伯努利分布;均值为 npnpnp,方差为 np(1−p)np(1-p)np(1−p)。
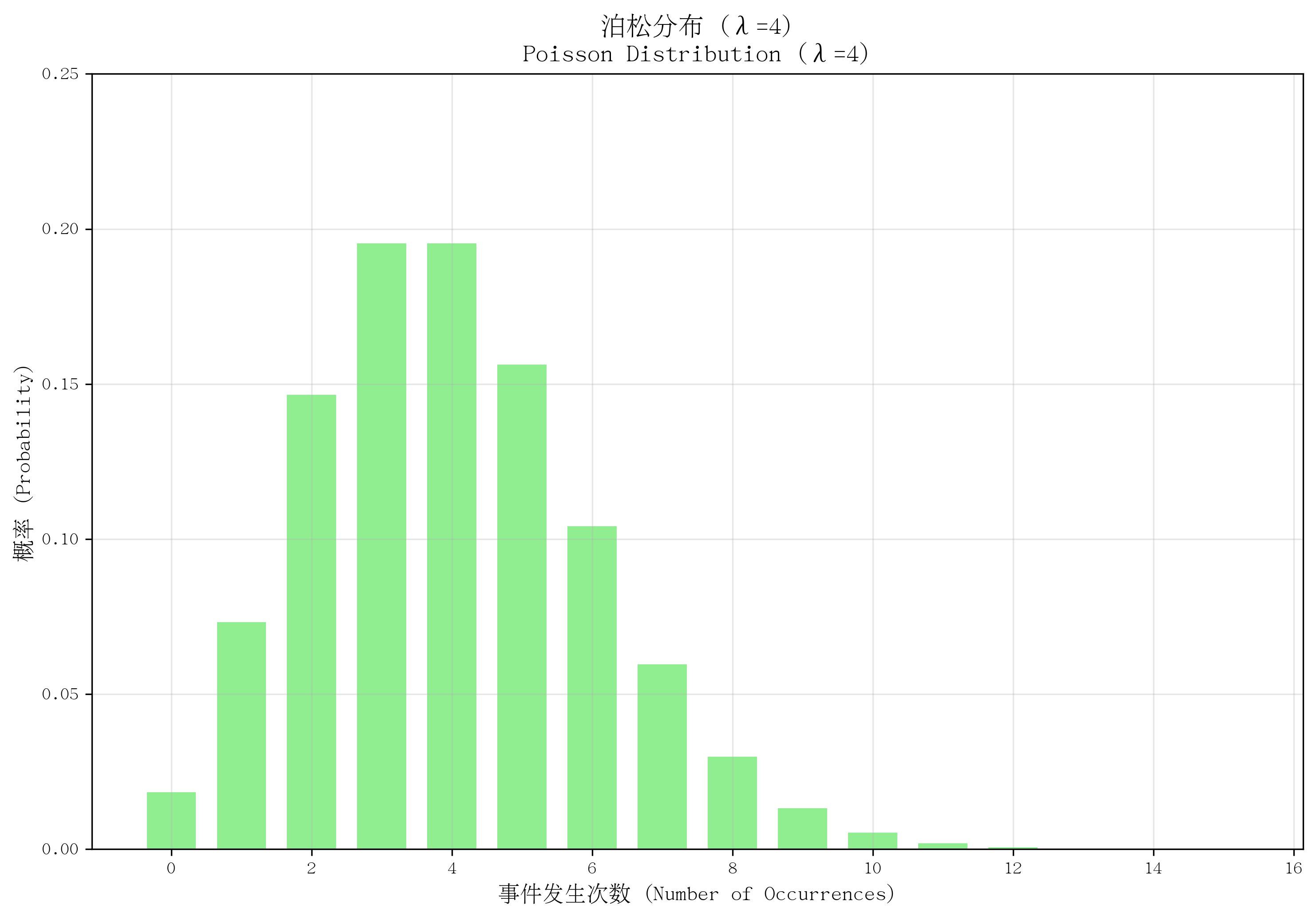
3. 泊松分布(Poisson Distribution)
- 定义:描述“一定时间/空间内,某随机事件发生次数”的概率分布。
- 核心参数:发生率 λ\lambdaλ(λ>0\lambda > 0λ>0,表示单位时间/空间内事件的平均发生次数)。
- 概率质量函数(PMF):
P(X=k)=λke−λk!P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!}P(X=k)=k!λke−λ,其中 k=0,1,2,...k=0,1,2,...k=0,1,2,...(事件发生次数),eee 为自然常数,k!k!k! 为k的阶乘。 - 适用场景:稀有事件的发生次数,如“1小时内客服接到的电话次数”“1平方米布料上的瑕疵数”“一天内医院的急诊人数”。
- 特点:事件独立发生,且发生率恒定;均值和方差均为 λ\lambdaλ;当二项分布中 nnn 很大、ppp 很小时(np≈λnp \approx \lambdanp≈λ),可近似为泊松分布。
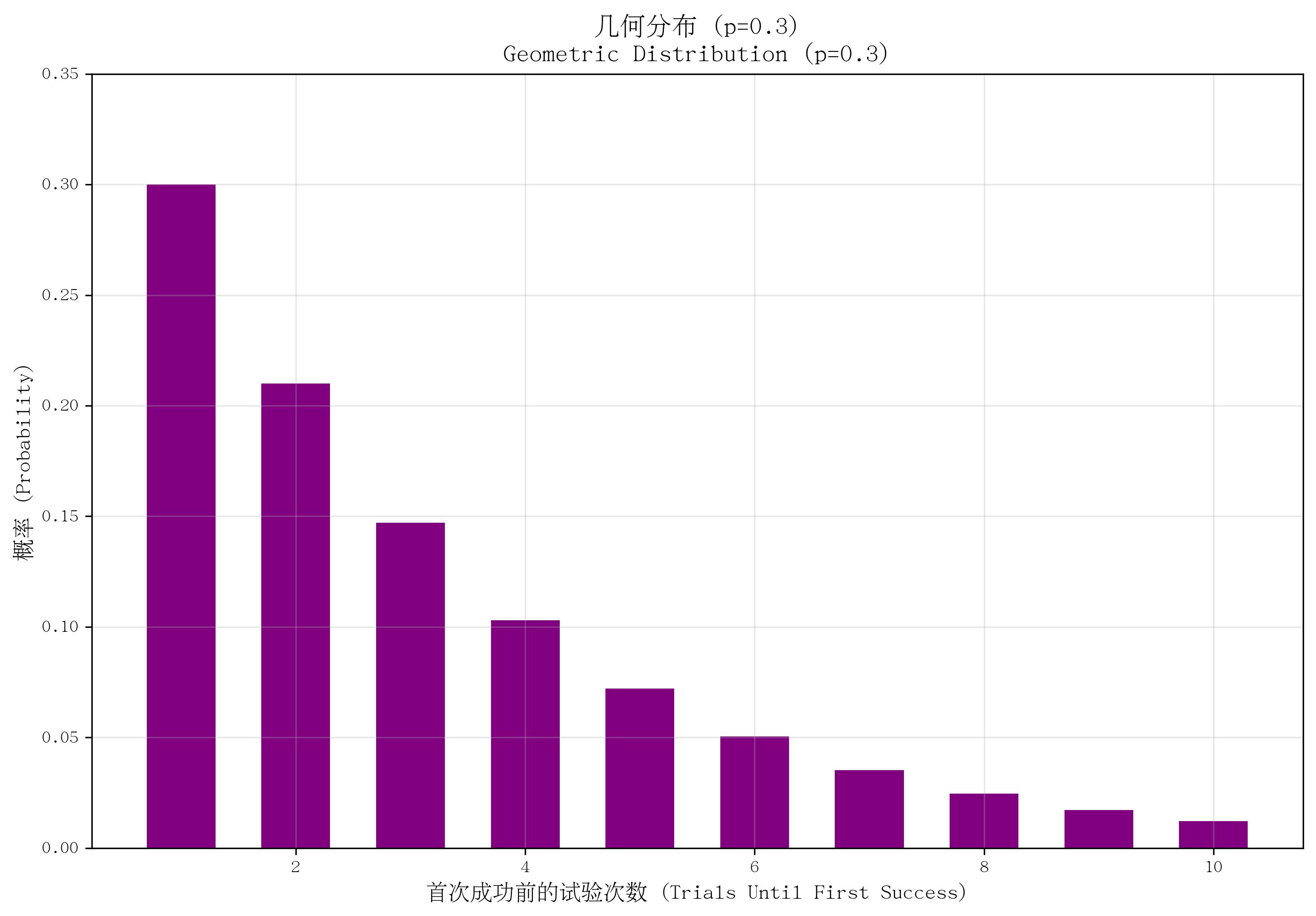
4. 几何分布(Geometric Distribution)
- 定义:描述“在一系列独立伯努利试验中,首次获得成功所需要的试验次数”的概率分布。
- 核心参数:单次试验成功概率 ppp(0<p≤10 < p \leq 10<p≤1)。
- 概率质量函数(PMF):
P(X=k)=(1−p)k−1pP(X=k) = (1-p)^{k-1} pP(X=k)=(1−p)k−1p,其中 k=1,2,...k=1,2,...k=1,2,...(首次成功时的试验次数,至少为1)。 - 适用场景:首次成功前的试验次数,如“首次命中目标前的射击次数”“首次抽到红球前的抽奖次数”。
- 特点:无记忆性(即“前k次失败不影响后续成功的概率”);均值为 1/p1/p1/p(平均需要 1/p1/p1/p 次试验才能首次成功),方差为 (1−p)/p2(1-p)/p^2(1−p)/p2。
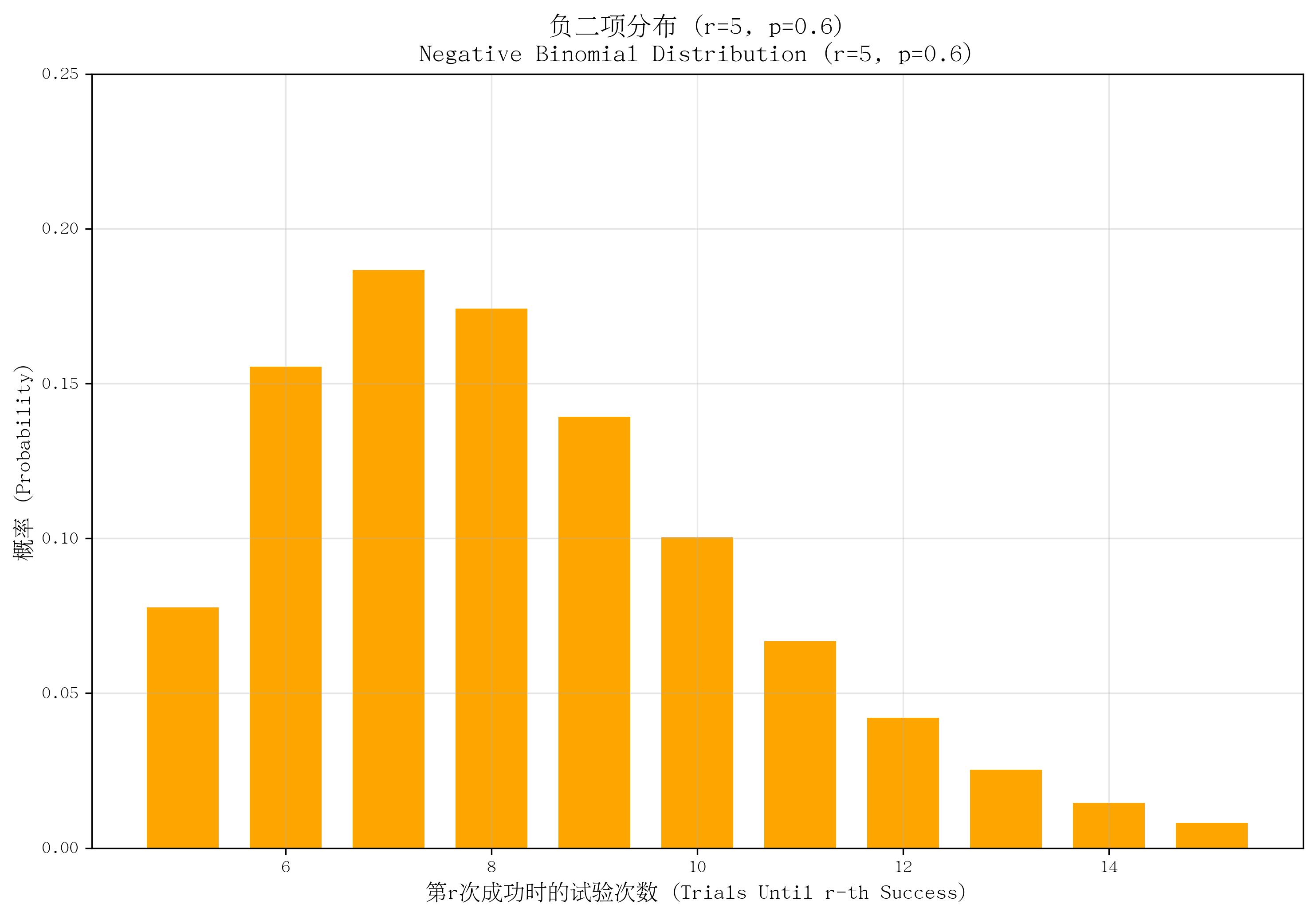
5. 负二项分布(Negative Binomial Distribution)
- 定义:描述“在一系列独立伯努利试验中,获得第 rrr 次成功时所需要的总试验次数”的概率分布(几何分布是其 r=1r=1r=1 时的特例)。
- 核心参数:目标成功次数 rrr(正整数)、单次试验成功概率 ppp(0<p≤10 < p \leq 10<p≤1)。
- 概率质量函数(PMF):
P(X=k)=(k−1r−1)pr(1−p)k−rP(X=k) = \binom{k-1}{r-1} p^r (1-p)^{k-r}P(X=k)=(r−1k−1)pr(1−p)k−r,其中 k=r,r+1,...k=r,r+1,...k=r,r+1,...(总试验次数,至少为 rrr)。 - 适用场景:需要多次成功的试验次数,如“第5次命中目标时的总射击次数”“第3次卖出产品时的总客户接待数”。
- 特点:可视为 rrr 个独立几何分布的和;均值为 r/pr/pr/p,方差为 r(1−p)/p2r(1-p)/p^2r(1−p)/p2。
二、连续概率分布
连续分布描述的是取值为连续区间(如实数域)的随机变量的概率规律,通常用概率密度函数(PDF) 表示某一区间内的概率密度(需通过积分计算区间概率)。
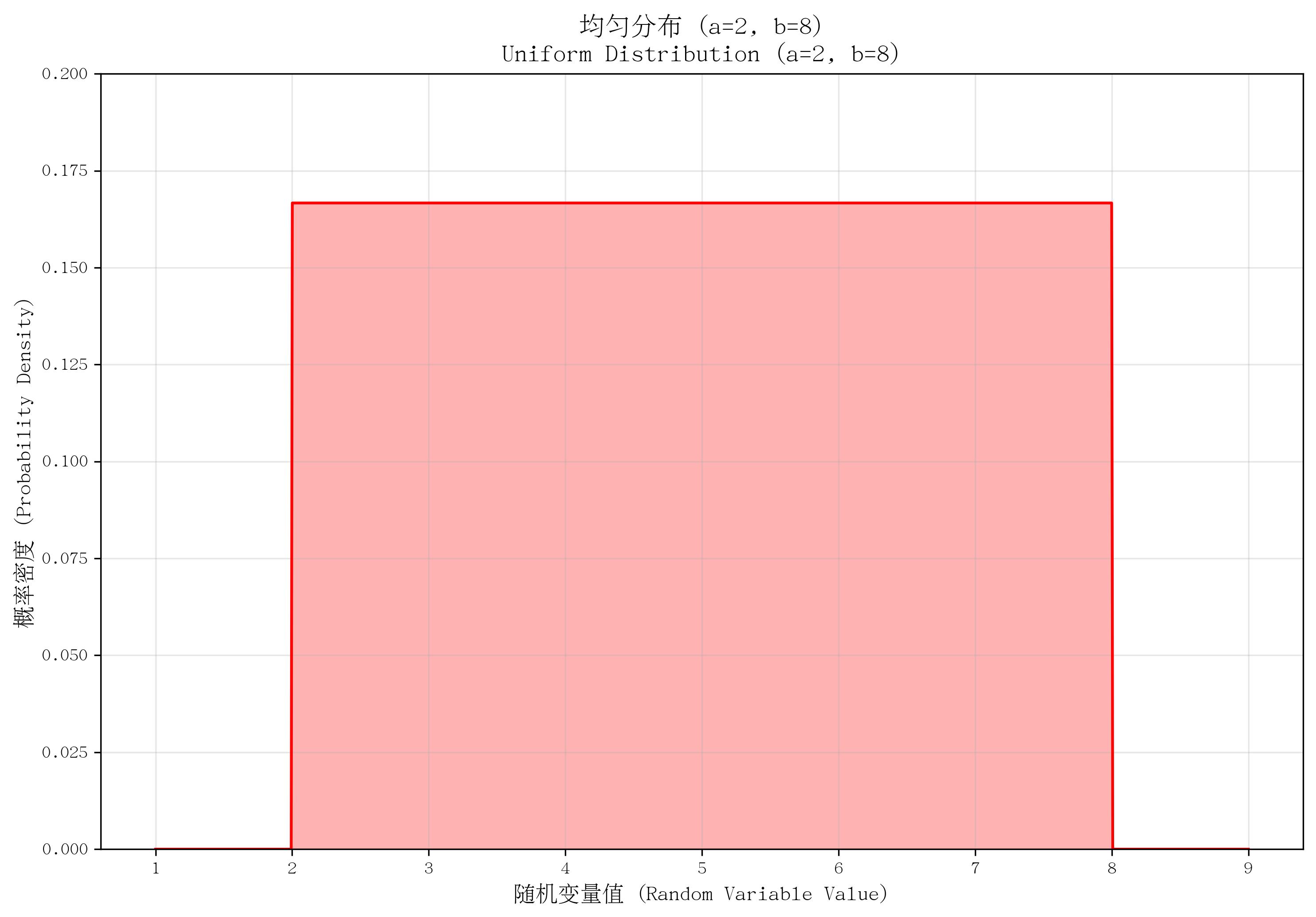
6. 均匀分布(Uniform Distribution)
- 定义:描述“随机变量在区间 ([a,b]) 内所有取值的概率密度均相等”的分布。
- 核心参数:区间下界 aaa 和上界 bbb(a<ba < ba<b)。
- 概率密度函数(PDF):
f(x)={1b−a若 a≤x≤b0其他 f(x) = \begin{cases} \frac{1}{b-a} & \text{若 } a \leq x \leq b \\ 0 & \text{其他} \end{cases} f(x)={b−a10若 a≤x≤b其他 - 适用场景:等可能结果的连续取值,如“随机选择的时间点在[0,24小时]内的分布”“随机测量的误差在[-0.5,0.5]内的分布”。
- 特点:概率密度恒定(矩形分布);均值为 (a+b)/2(a+b)/2(a+b)/2,方差为 (b−a)2/12(b-a)^2/12(b−a)2/12;区间内任意子区间的概率与子区间长度成正比。
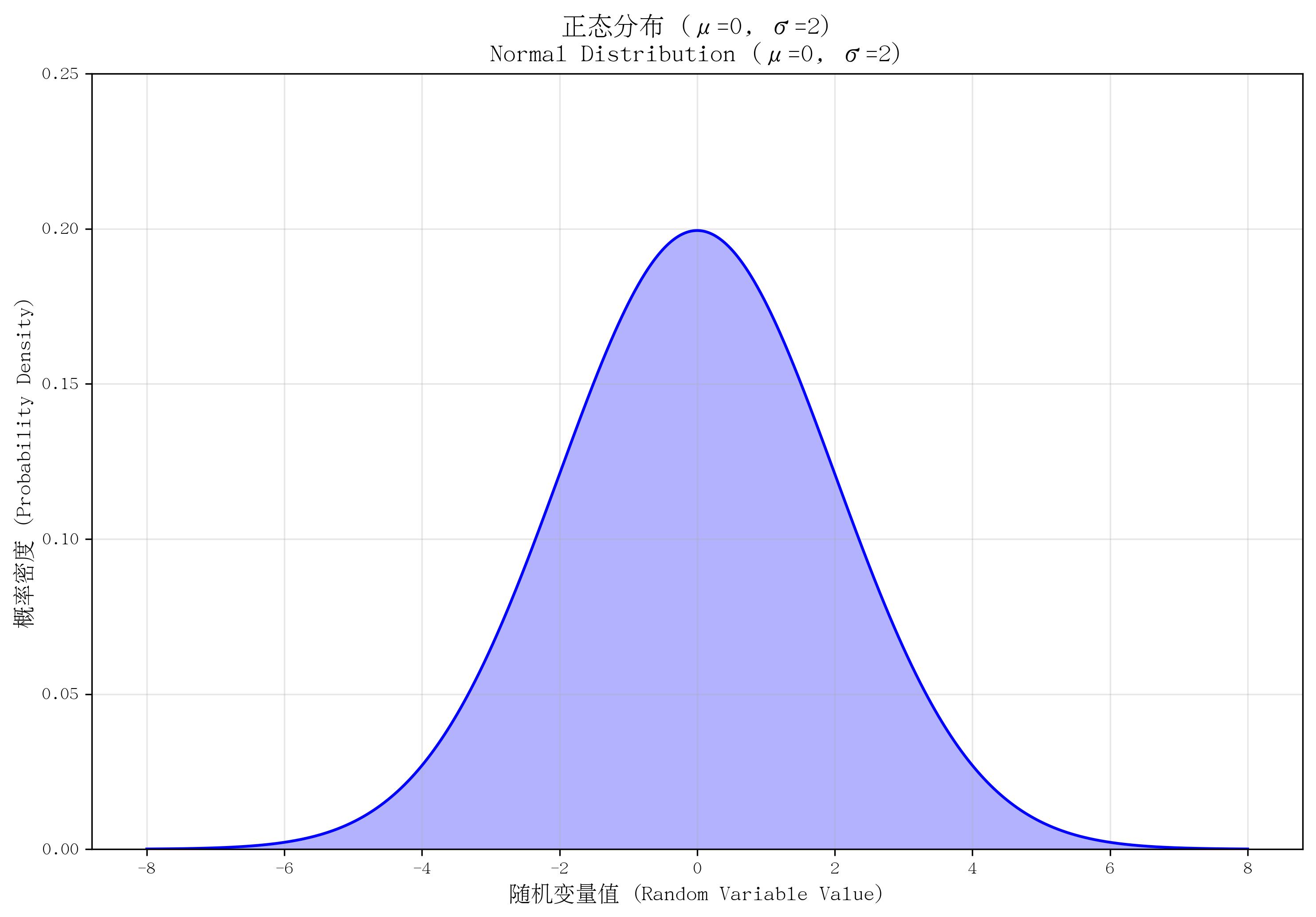
7. 正态分布(Normal Distribution)
- 定义:又称“高斯分布”,是自然界最常见的连续分布,呈对称的钟形曲线。
- 核心参数:均值 μ\muμ(曲线中心位置)、标准差 σ\sigmaσ(曲线宽窄,σ>0\sigma > 0σ>0)。
- 概率密度函数(PDF):
f(x)=1σ2πe−(x−μ)22σ2f(x) = \frac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}f(x)=σ2π1e−2σ2(x−μ)2,其中 xxx 为任意实数,eee 为自然常数。 - 适用场景:大量独立随机因素影响的结果,如“人群身高/体重分布”“测量误差分布”“考试分数分布”。
- 特点:对称性(关于 x=μx=\mux=μ 对称);“3σ法则”(约99.7%的取值落在 [μ−3σ,μ+3σ][\mu-3\sigma, \mu+3\sigma][μ−3σ,μ+3σ] 内);中心极限定理表明,大量独立随机变量的和近似服从正态分布;标准正态分布(μ=0,σ=1\mu=0, \sigma=1μ=0,σ=1)是基础,可通过标准化转换(Z=(X−μ)/σZ=(X-\mu)/\sigmaZ=(X−μ)/σ)将任意正态分布转化为标准正态分布。
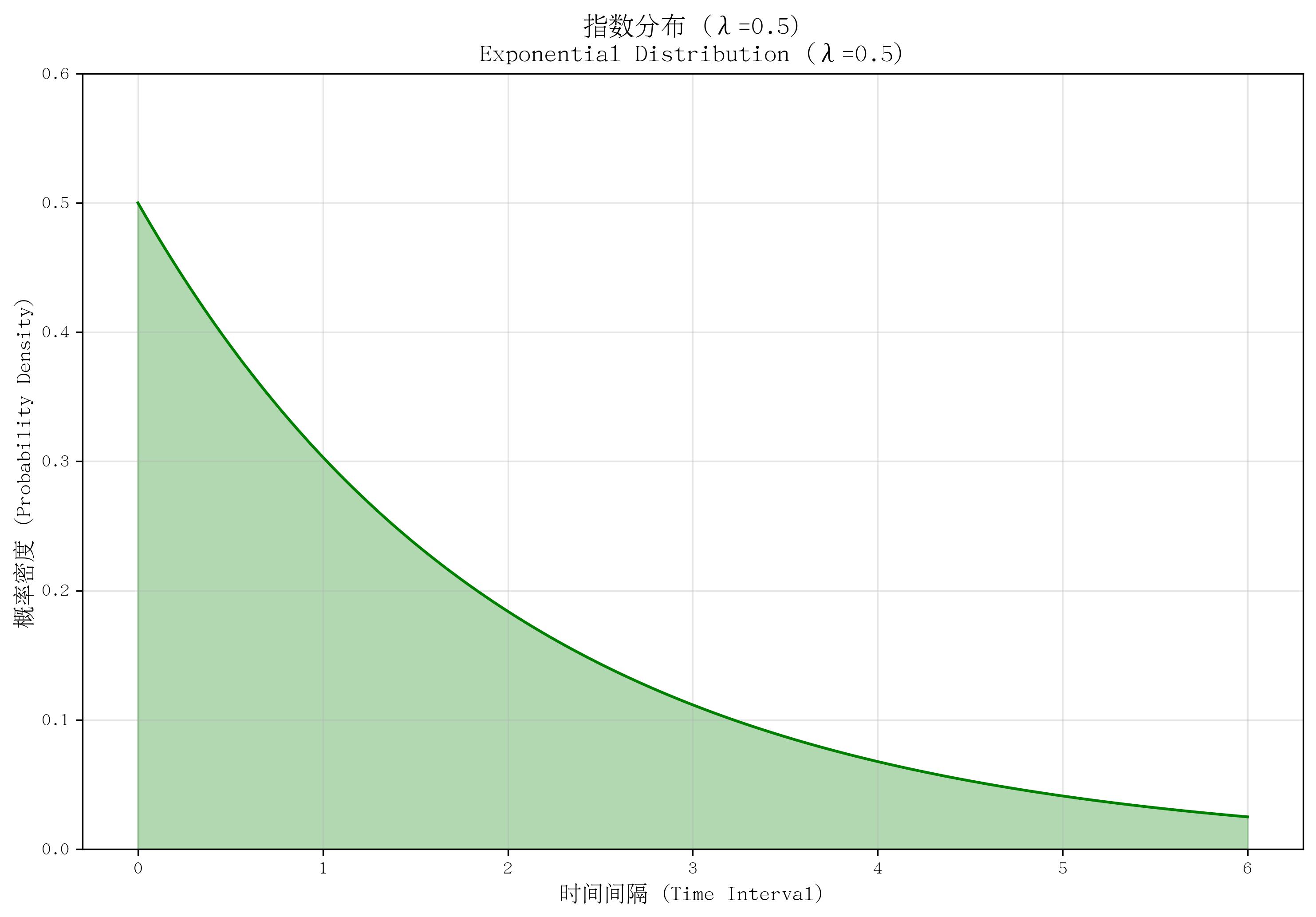
8. 指数分布(Exponential Distribution)
- 定义:描述“两次独立随机事件发生的时间间隔”的概率分布(与泊松分布对应:泊松分布描述事件发生次数,指数分布描述事件间隔时间)。
- 核心参数:率参数 λ\lambdaλ(λ>0\lambda > 0λ>0,表示单位时间内事件的平均发生次数,与泊松分布的 λ\lambdaλ 一致)。
- 概率密度函数(PDF):
f(x)={λe−λx若 x≥00若 x<0 f(x) = \begin{cases} \lambda e^{-\lambda x} & \text{若 } x \geq 0 \\ 0 & \text{若 } x < 0 \end{cases} f(x)={λe−λx0若 x≥0若 x<0 - 适用场景:事件间隔时间,如“两次设备故障的时间间隔”“两次客户到达的时间间隔”“电池寿命”。
- 特点:无记忆性(即“已使用t小时的设备,剩余寿命与新设备相同”);均值为 1/λ1/\lambda1/λ(平均间隔时间),方差为 1/λ21/\lambda^21/λ2;取值范围为非负实数。
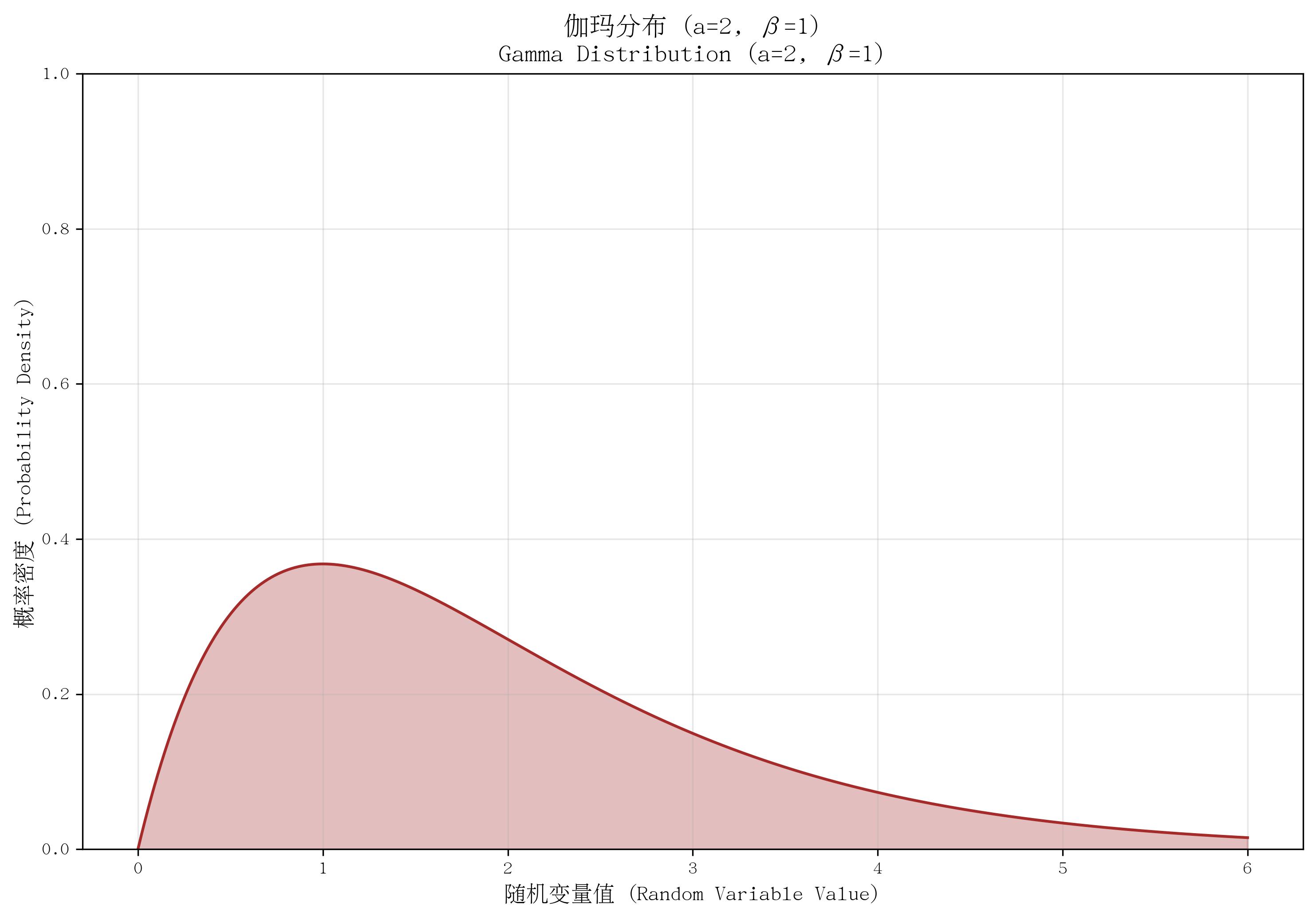
9. 伽玛分布(Gamma Distribution)
- 定义:描述“多个独立指数分布变量的总和”的概率分布(指数分布是其形状参数 a=1a=1a=1 时的特例)。
- 核心参数:形状参数 aaa(a>0a > 0a>0,可理解为“事件次数”)、率参数 β\betaβ(β>0\beta > 0β>0,与指数分布的 λ\lambdaλ 类似)。
- 概率密度函数(PDF):
f(x)={βaΓ(a)xa−1e−βx若 x≥00若 x<0 f(x) = \begin{cases} \frac{\beta^a}{\Gamma(a)} x^{a-1} e^{-\beta x} & \text{若 } x \geq 0 \\ 0 & \text{若 } x < 0 \end{cases} f(x)={Γ(a)βaxa−1e−βx0若 x≥0若 x<0
其中 Γ(a)\Gamma(a)Γ(a) 为伽玛函数(当 aaa 为整数时,Γ(a)=(a−1)!\Gamma(a)=(a-1)!Γ(a)=(a−1)!)。 - 适用场景:多个事件间隔的总和,如“3次电话呼叫的总时间”“5个零件的总寿命”;当 aaa 为整数时,也称为“爱尔朗分布”(Erlang Distribution),常用于排队论。
- 特点:形状随 aaa 变化(aaa 增大时逐渐接近正态分布);均值为 a/βa/\betaa/β,方差为 a/β2a/\beta^2a/β2。
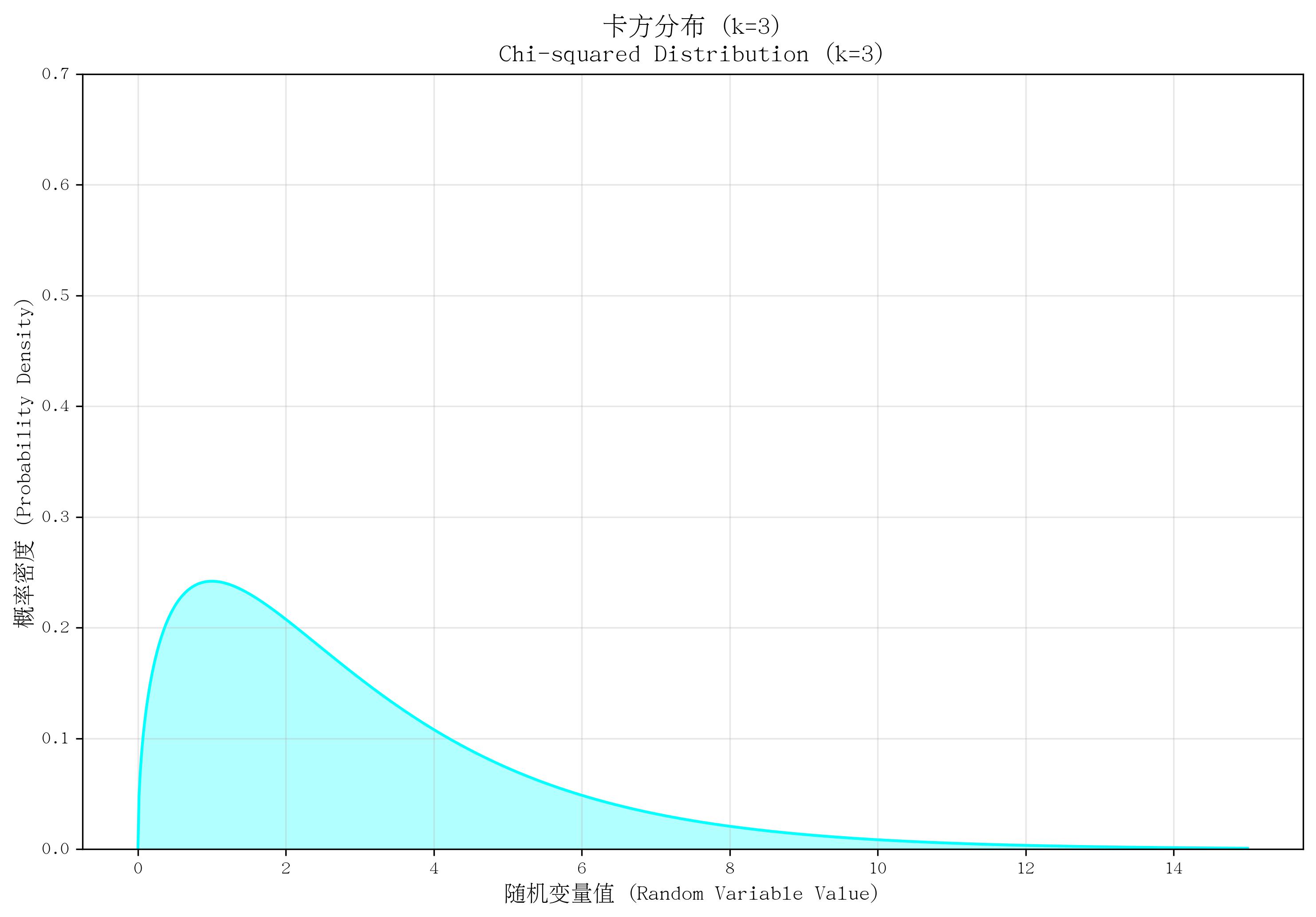
10. 卡方分布(Chi-Squared Distribution)
- 定义:描述“k个独立标准正态变量的平方和”的概率分布(是伽玛分布的特例:当形状参数 a=k/2a=k/2a=k/2、率参数 β=1/2\beta=1/2β=1/2 时)。
- 核心参数:自由度 kkk(正整数,对应标准正态变量的个数)。
- 概率密度函数(PDF):
f(x)={12k/2Γ(k/2)x(k/2)−1e−x/2若 x≥00若 x<0 f(x) = \begin{cases} \frac{1}{2^{k/2} \Gamma(k/2)} x^{(k/2)-1} e^{-x/2} & \text{若 } x \geq 0 \\ 0 & \text{若 } x < 0 \end{cases} f(x)={2k/2Γ(k/2)1x(k/2)−1e−x/20若 x≥0若 x<0 - 适用场景:统计检验中,如“方差的假设检验”“拟合优度检验”“独立性检验”;是t分布和F分布的基础。
- 特点:取值非负,右偏分布(随 kkk 增大逐渐对称);均值为 kkk,方差为 2k2k2k;若 X∼χ2(k1)X \sim \chi^2(k_1)X∼χ2(k1) 且 Y∼χ2(k2)Y \sim \chi^2(k_2)Y∼χ2(k2),则 X+Y∼χ2(k1+k2)X+Y \sim \chi^2(k_1+k_2)X+Y∼χ2(k1+k2)(可加性)。
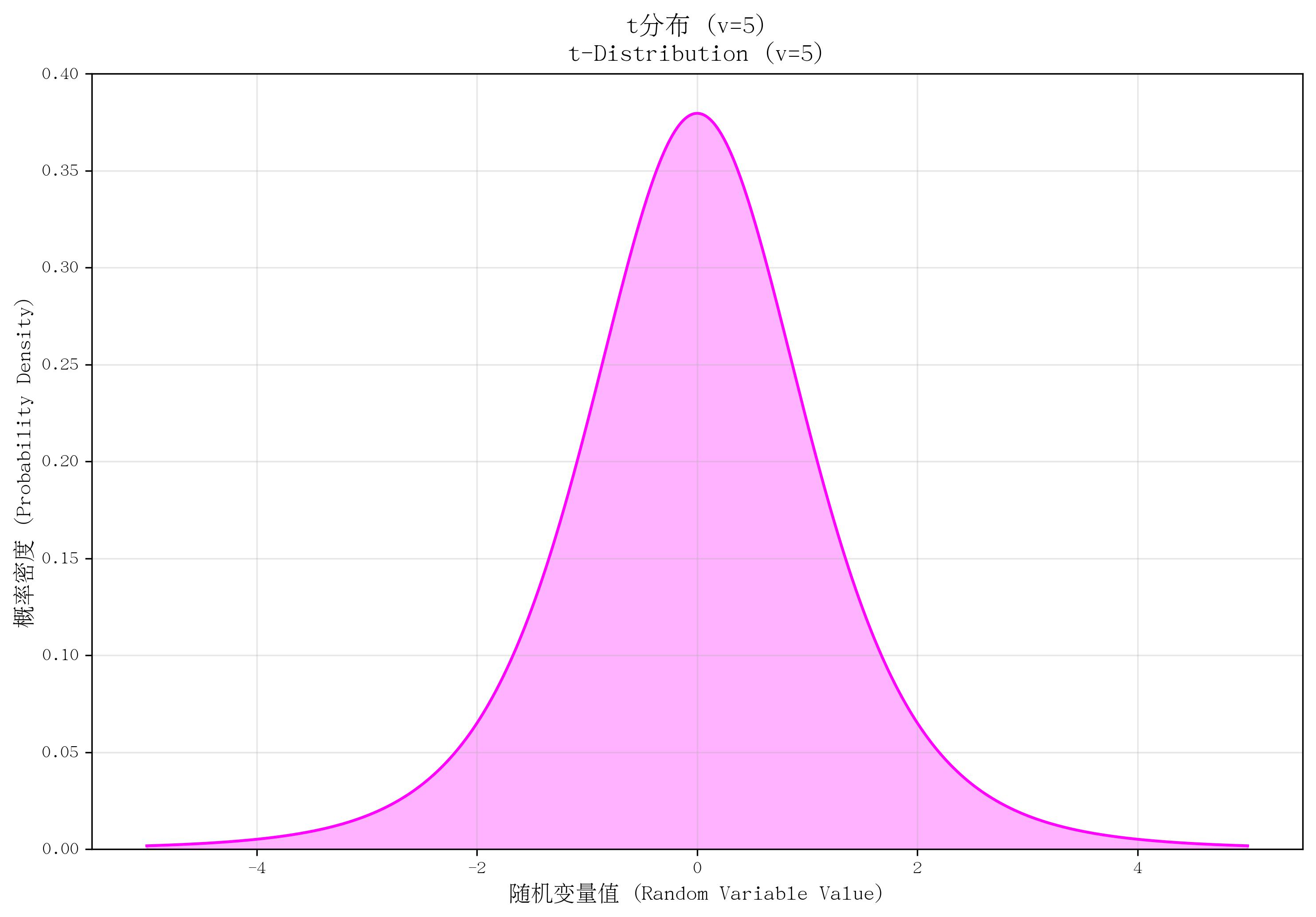
11. t分布(t-Distribution)
- 定义:描述“小样本均值标准化后”的概率分布,当总体标准差未知时,用样本标准差替代后推导得到。
- 核心参数:自由度 vvv(正整数,通常为样本量减1,v=n−1v = n-1v=n−1)。
- 概率密度函数(PDF):
f(x)=Γ((v+1)/2)vπΓ(v/2)(1+x2v)−(v+1)/2f(x) = \frac{\Gamma((v+1)/2)}{\sqrt{v\pi} \Gamma(v/2)} \left(1 + \frac{x^2}{v}\right)^{-(v+1)/2}f(x)=vπΓ(v/2)Γ((v+1)/2)(1+vx2)−(v+1)/2,其中 xxx 为任意实数。 - 适用场景:小样本(n<30n < 30n<30)的均值检验,如“小样本下总体均值的区间估计”“单样本t检验”“两独立样本t检验”。
- 特点:形状类似正态分布,但尾部更厚(对极端值更敏感);随自由度 vvv 增大,逐渐接近标准正态分布(v→∞v \to \inftyv→∞ 时完全一致);均值为0(v>1v > 1v>1 时),方差为 v/(v−2)v/(v-2)v/(v−2)(v>2v > 2v>2 时)。
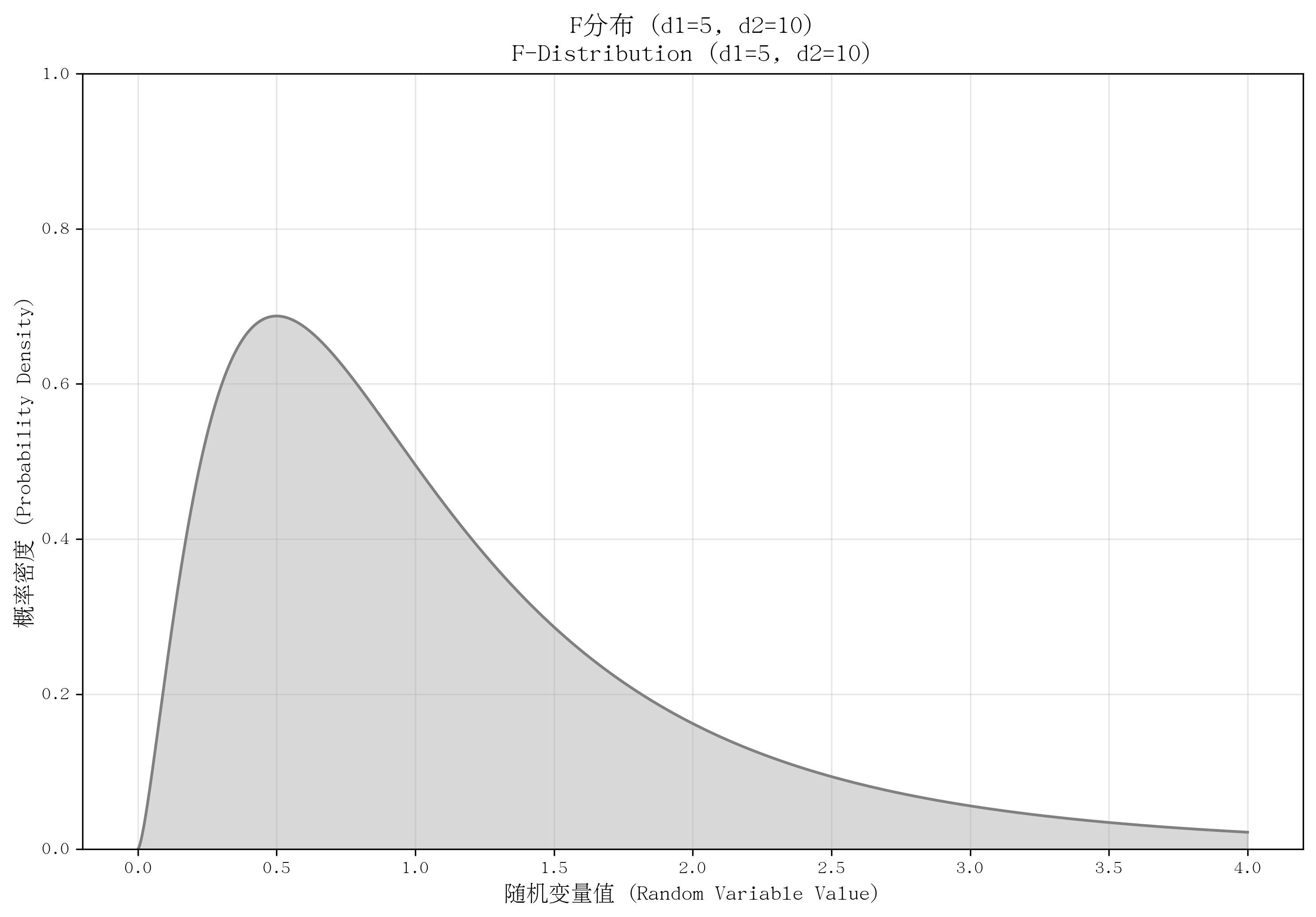
12. F分布(F-Distribution)
- 定义:描述“两个独立卡方分布变量分别除以各自自由度后的比值”的概率分布。
- 核心参数:分子自由度 d1d_1d1 和分母自由度 d2d_2d2(均为正整数)。
- 概率密度函数(PDF):
f(x)={Γ((d1+d2)/2)Γ(d1/2)Γ(d2/2)(d1d2)d1/2x(d1/2)−1(1+d1d2x)−(d1+d2)/2若 x≥00若 x<0 f(x) = \begin{cases} \frac{\Gamma((d_1+d_2)/2)}{\Gamma(d_1/2)\Gamma(d_2/2)} \left(\frac{d_1}{d_2}\right)^{d_1/2} x^{(d_1/2)-1} \left(1 + \frac{d_1}{d_2}x\right)^{-(d_1+d_2)/2} & \text{若 } x \geq 0 \\ 0 & \text{若 } x < 0 \end{cases} f(x)=⎩⎨⎧Γ(d1/2)Γ(d2/2)Γ((d1+d2)/2)(d2d1)d1/2x(d1/2)−1(1+d2d1x)−(d1+d2)/20若 x≥0若 x<0 - 适用场景:方差比较,如“方差分析(ANOVA)”(检验多组均值是否有差异)、“两总体方差比的假设检验”。
- 特点:取值非负,右偏分布;形状由两个自由度共同决定;若 F∼F(d1,d2)F \sim F(d_1,d_2)F∼F(d1,d2),则 1/F∼F(d2,d1)1/F \sim F(d_2,d_1)1/F∼F(d2,d1)(倒数性质)。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats# 设置中文显示
#plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams["font.family"] = ['AR PL UMing CN']#Linux
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题def save_distribution_plot(plot_func, params, title_cn, title_en, x_label, y_label,filename_cn, filename_en, params_str, is_discrete=True):"""生成并保存分布图像的通用函数(不含公式)"""plt.figure(figsize=(10, 7))plot_func(*params)# 标题组合中英文plt.title(f"{title_cn}\n{title_en}", fontsize=14)# 设置轴标签plt.xlabel(x_label, fontsize=12)plt.ylabel(y_label, fontsize=12)plt.grid(alpha=0.3)plt.tight_layout() # 紧凑布局,无需为公式预留空间# 生成包含中英文的文件名filename = f"{filename_cn}_{filename_en}_{params_str}.jpg"plt.savefig(filename, dpi=300, bbox_inches='tight')plt.close()# 1. 伯努利分布
def plot_bernoulli():x = [0, 1]p = 0.6pmf = [1 - p, p]plt.bar(x, pmf, color='skyblue', width=0.5)plt.xticks(x)plt.ylim(0, 1.1)return pp = plot_bernoulli()
save_distribution_plot(plot_bernoulli, [], f'伯努利分布 (p={p})', f'Bernoulli Distribution (p={p})','随机变量值 (Random Variable Value)', '概率 (Probability)','伯努利分布', 'bernoulli', f'p{p}', True
)# 2. 二项分布
def plot_binomial():n, p = 10, 0.4x = np.arange(0, n + 1)pmf = stats.binom.pmf(x, n, p)plt.bar(x, pmf, color='salmon', width=0.6)plt.ylim(0, 0.35)return n, pn, p = plot_binomial()
save_distribution_plot(plot_binomial, [], f'二项分布 (n={n}, p={p})', f'Binomial Distribution (n={n}, p={p})','成功次数 (Number of Successes)', '概率 (Probability)','二项分布', 'binomial', f'n{n}_p{p}', True
)# 3. 泊松分布
def plot_poisson():lambda_p = 4x = np.arange(0, 16)pmf = stats.poisson.pmf(x, lambda_p)plt.bar(x, pmf, color='lightgreen', width=0.7)plt.ylim(0, 0.25)return lambda_plambda_p = plot_poisson()
save_distribution_plot(plot_poisson, [], f'泊松分布 (λ={lambda_p})', f'Poisson Distribution (λ={lambda_p})','事件发生次数 (Number of Occurrences)', '概率 (Probability)','泊松分布', 'poisson', f'lambda{lambda_p}', True
)# 4. 几何分布
def plot_geometric():p = 0.3x = np.arange(1, 11)pmf = stats.geom.pmf(x, p)plt.bar(x, pmf, color='purple', width=0.6)plt.ylim(0, 0.35)return pp = plot_geometric()
save_distribution_plot(plot_geometric, [], f'几何分布 (p={p})', f'Geometric Distribution (p={p})','首次成功前的试验次数 (Trials Until First Success)', '概率 (Probability)','几何分布', 'geometric', f'p{p}', True
)# 5. 负二项分布
def plot_negative_binomial():r, p = 5, 0.6x = np.arange(5, 16)pmf = stats.nbinom.pmf(x - r, r, p)plt.bar(x, pmf, color='orange', width=0.7)plt.ylim(0, 0.25)return r, pr, p = plot_negative_binomial()
save_distribution_plot(plot_negative_binomial, [], f'负二项分布 (r={r}, p={p})', f'Negative Binomial Distribution (r={r}, p={p})','第r次成功时的试验次数 (Trials Until r-th Success)', '概率 (Probability)','负二项分布', 'negative_binomial', f'r{r}_p{p}', True
)# 6. 均匀分布
def plot_uniform():a, b = 2, 8x = np.linspace(a - 1, b + 1, 1000)pdf = stats.uniform.pdf(x, loc=a, scale=b - a)plt.plot(x, pdf, color='red')plt.fill_between(x, pdf, alpha=0.3, color='red')plt.ylim(0, 0.2)return a, ba, b = plot_uniform()
save_distribution_plot(plot_uniform, [], f'均匀分布 (a={a}, b={b})', f'Uniform Distribution (a={a}, b={b})','随机变量值 (Random Variable Value)', '概率密度 (Probability Density)','均匀分布', 'uniform', f'a{a}_b{b}', False
)# 7. 正态分布
def plot_normal():mu, sigma = 0, 2x = np.linspace(mu - 4*sigma, mu + 4*sigma, 1000)pdf = stats.norm.pdf(x, mu, sigma)plt.plot(x, pdf, color='blue')plt.fill_between(x, pdf, alpha=0.3, color='blue')plt.ylim(0, 0.25)return mu, sigmamu, sigma = plot_normal()
save_distribution_plot(plot_normal, [], f'正态分布 (μ={mu}, σ={sigma})', f'Normal Distribution (μ={mu}, σ={sigma})','随机变量值 (Random Variable Value)', '概率密度 (Probability Density)','正态分布', 'normal', f'mu{mu}_sigma{sigma}', False
)# 8. 指数分布
def plot_exponential():lambda_exp = 0.5x = np.linspace(0, 6, 1000)pdf = stats.expon.pdf(x, scale=1/lambda_exp)plt.plot(x, pdf, color='green')plt.fill_between(x, pdf, alpha=0.3, color='green')plt.ylim(0, 0.6)return lambda_explambda_exp = plot_exponential()
save_distribution_plot(plot_exponential, [], f'指数分布 (λ={lambda_exp})', f'Exponential Distribution (λ={lambda_exp})','时间间隔 (Time Interval)', '概率密度 (Probability Density)','指数分布', 'exponential', f'lambda{lambda_exp}', False
)# 9. 伽玛分布
def plot_gamma():a, beta = 2, 1x = np.linspace(0, 6, 1000)pdf = stats.gamma.pdf(x, a, scale=1/beta)plt.plot(x, pdf, color='brown')plt.fill_between(x, pdf, alpha=0.3, color='brown')plt.ylim(0, 1.0)return a, betaa, beta = plot_gamma()
save_distribution_plot(plot_gamma, [], f'伽玛分布 (a={a}, β={beta})', f'Gamma Distribution (a={a}, β={beta})','随机变量值 (Random Variable Value)', '概率密度 (Probability Density)','伽玛分布', 'gamma', f'a{a}_beta{beta}', False
)# 10. 卡方分布
def plot_chi2():k = 3x = np.linspace(0, 15, 1000)pdf = stats.chi2.pdf(x, k)plt.plot(x, pdf, color='cyan')plt.fill_between(x, pdf, alpha=0.3, color='cyan')plt.ylim(0, 0.7)return kk = plot_chi2()
save_distribution_plot(plot_chi2, [], f'卡方分布 (k={k})', f'Chi-squared Distribution (k={k})','随机变量值 (Random Variable Value)', '概率密度 (Probability Density)','卡方分布', 'chi2', f'k{k}', False
)# 11. t分布
def plot_t():v = 5x = np.linspace(-5, 5, 1000)pdf = stats.t.pdf(x, v)plt.plot(x, pdf, color='magenta')plt.fill_between(x, pdf, alpha=0.3, color='magenta')plt.ylim(0, 0.4)return vv = plot_t()
save_distribution_plot(plot_t, [], f't分布 (v={v})', f't-Distribution (v={v})','随机变量值 (Random Variable Value)', '概率密度 (Probability Density)','t分布', 't_distribution', f'v{v}', False
)# 12. F分布
def plot_f():d1, d2 = 5, 10x = np.linspace(0, 4, 1000)pdf = stats.f.pdf(x, d1, d2)plt.plot(x, pdf, color='gray')plt.fill_between(x, pdf, alpha=0.3, color='gray')plt.ylim(0, 1.0)return d1, d2d1, d2 = plot_f()
save_distribution_plot(plot_f, [], f'F分布 (d1={d1}, d2={d2})', f'F-Distribution (d1={d1}, d2={d2})','随机变量值 (Random Variable Value)', '概率密度 (Probability Density)','F分布', 'f_distribution', f'd1{d1}_d2{d2}', False
)